
The choice between on-premises and cloud infrastructure is a foundational architectural decision, not a simple vendor selection. It represents a trade-off between two opposing forces: absolute control and operational agility.
On-premises architecture offers direct, physical control over hardware and data, a non-negotiable requirement for many regulated industries. The cloud, conversely, provides elastic scalability and abstracts away infrastructure management, enabling rapid development cycles and market response without significant upfront capital investment.
Defining the Core Architectural Trade-Offs
The on-premises vs. cloud debate is a strategic decision that dictates a company’s financial model, operational structure, and long-term compliance capabilities. This is not about buying servers versus renting them; it is an architectural commitment that impacts development velocity, security posture, and resilience.
For technical leaders, this requires moving beyond simplistic definitions to address the practical realities of building and operating robust software systems.
The optimal choice depends entirely on business context. Are you constrained by strict regulatory frameworks? Do performance requirements demand minimal latency? Is speed-to-market your primary competitive advantage? This guide provides a pragmatic framework for CTOs, founders, and IT managers to navigate this complex decision with architectural clarity.
Key Dimensions of the Decision
Before analyzing specific implementations, we must frame the comparison across critical business and technical dimensions. Each model presents a distinct value proposition and set of constraints:
- Financial Model: On-premises is defined by a significant initial capital expenditure (CapEx) for hardware, followed by ongoing operational expenses (OpEx) for maintenance and personnel. Cloud services invert this, operating almost entirely on a pay-as-you-go OpEx model.
- Control and Sovereignty: On-premises provides complete physical and logical control over data and hardware. This is essential for industries governed by strict data residency regulations or those managing highly sensitive intellectual property where third-party access is an unacceptable risk.
- Scalability and Agility: The cloud offers near-instantaneous resource scaling to handle unpredictable traffic loads or rapid growth. On-premises scaling is a manual, protracted process involving hardware procurement, installation, and configuration cycles.
- Operational Burden: With on-premises, your internal team is responsible for the entire stack—hardware maintenance, network configuration, physical security, and patching. Cloud providers abstract this complexity, allowing engineering teams to focus on application-level development.
The decision is less about which model is objectively “better” and more about which set of constraints and trade-offs aligns with your strategic objectives. A startup prioritizing development velocity will accept different risks than a financial institution subject to DORA regulations.
To clarify these distinctions, the following table provides a high-level overview to guide the deeper analysis in subsequent sections.
At-a-Glance Comparison: On-Premises vs. Cloud Models
| Dimension | On-Premises | Cloud |
|---|---|---|
| Cost Structure | High upfront CapEx, predictable OpEx | Low/no upfront CapEx, variable OpEx |
| Control | Full physical and logical control over infrastructure | Shared responsibility model; limited physical control |
| Scalability | Manual, planned, and finite | Automated, on-demand, and elastic |
| Security | Full responsibility for physical and network security | Provider manages infrastructure security; you manage application/data |
| Compliance | Direct control simplifies audits for specific regulations | Requires careful configuration to meet standards (e.g., GDPR, NIS2) |
| Maintenance | In-house team responsible for all hardware and software upkeep | Handled by the cloud provider |
Ultimately, this table highlights the core architectural trade-off. On-premises provides absolute control at the cost of operational overhead, while the cloud offers agility and scalability by abstracting that complexity away.
Deconstructing the Total Cost of Ownership
A superficial cost comparison between on-premises and cloud—framing it as a simple choice between capital expenditure (CapEx) and operational expenditure (OpEx)—is misleading and financially irresponsible. A sound architectural decision requires a rigorous analysis of the Total Cost of Ownership (TCO), accounting for all direct, indirect, and hidden costs over the infrastructure’s lifecycle.
A naive TCO analysis often leads to significant budget overruns and operational failures.
For predictable workloads running at high, constant utilization, on-premises infrastructure can offer a lower TCO over a multi-year horizon. Conversely, the cloud’s pay-as-you-go model delivers undeniable financial agility for systems with volatile demand or those in a rapid growth phase. To build a realistic financial model, you must move beyond the CapEx vs. OpEx binary.
The True Cost of On-Premises Infrastructure
On-premises TCO extends far beyond the initial server purchase. A comprehensive budget must account for the full range of direct and indirect expenses that accumulate over the hardware’s lifecycle. Miscalculating these costs is a common source of project failure.
The primary cost components include:
- Hardware Acquisition: Servers, storage arrays, and networking equipment represent a significant upfront capital investment.
- Software Licensing: Operating systems, virtualization platforms, databases, and enterprise applications often carry substantial licensing fees, which may be perpetual or subscription-based.
- Physical Infrastructure: Hardware requires a suitable environment. This includes data center space (or colocation fees), power distribution, redundant cooling systems, and physical access controls. These are material, recurring costs.
- Human Capital: A skilled IT team is required for management, maintenance, and security. The salaries for system administrators, network engineers, and security specialists constitute a major and continuous operational expense.
The most frequently underestimated cost in an on-premises model is the human element. The operational burden is not just a line item; it is a strategic drain on engineering resources that could otherwise be dedicated to product innovation.
Unpacking Cloud Economics and Hidden Fees
The cloud’s OpEx model appears simple, but its TCO is equally complex. While it eliminates upfront hardware costs, a lack of disciplined governance can lead to spiraling expenses, negating initial savings. Understanding these cost drivers is critical for financial predictability.
Key cloud cost components are:
- Subscription and Usage Fees: The core of the bill, based on consumed compute, storage, and database resources. Accurately forecasting this for dynamic workloads is a significant challenge.
- Data Egress Charges: A common cause of budget shock. Cloud providers typically charge for data transferred out of their network. For data-intensive applications, these fees can become a substantial portion of the monthly invoice.
- Ancillary Services: Monitoring, logging, load balancing, and advanced security features are rarely included in base pricing. They are billed as separate line items and can accumulate quickly.
- Budget Overruns: The ease of provisioning new resources is a double-edged sword. Without strict cost management and governance, engineers can inadvertently trigger massive, unexpected overruns.
For specialized workloads like AI, the financial models diverge sharply. For AI inference where low latency and data sovereignty are critical, on-premises demands a heavy upfront investment but can yield a rapid return. A TCO analysis for Generative AI reveals that on-premises systems can achieve breakeven in under four months for high-utilization workloads, delivering significant cost savings per million tokens compared to cloud APIs.
For example, one on-premises configuration with a CapEx of $277,897 has an hourly OpEx of just $8.79. The equivalent on-demand cloud rate is $84.81/hr. You can discover more insights about this IT infrastructure comparison.
Navigating the Realities of Security and Compliance
Security and compliance are not features; they are architectural properties that must be designed from the outset. The choice between on-premises and cloud is not about which is inherently “more secure,” but which responsibility model and set of trade-offs an organization is equipped to manage. A naive approach to either model exposes the business to significant regulatory penalties and reputational damage. For any B2B system processing sensitive data under regulations like GDPR, NIS2, or DORA, this is one of the most critical early architectural decisions.

The Cloud and the Shared Responsibility Model
A common misconception is that migrating to the cloud offloads security obligations. The reality is that you enter a shared responsibility model. While the cloud provider secures the foundational infrastructure—physical data centers, servers, and core networking—you are fully accountable for securing everything you build on that infrastructure.
This means your team is responsible for:
- Data Security: Implementing encryption for data in transit and at rest, including robust key management.
- Application-Level Controls: Protecting proprietary code from vulnerabilities like injection attacks and insecure deserialization.
- Identity and Access Management (IAM): Correctly configuring user permissions and roles. A single misconfigured IAM policy can lead to catastrophic data exposure.
- Network Configuration: Architecting Virtual Private Clouds (VPCs), security groups, and firewall rules to enforce network segmentation and control traffic flow.
The greatest risk in this model is a false sense of security. The provider offers secure primitives, but your team must use them correctly. Assuming the provider handles everything is a direct path to a data breach.
A cloud provider secures the building, but you are responsible for locking the doors to your own office. Forgetting this distinction is one of the most common and costly mistakes in cloud adoption.
On-Premises Control and the Burden of Ownership
The primary security advantage of an on-premises architecture is total control. You own the entire stack, from the physical server in a locked rack to the application code. For organizations in heavily regulated sectors or those safeguarding mission-critical intellectual property, this level of control is often a baseline requirement.
A financial services firm subject to the Digital Operational Resilience Act (DORA) might choose on-premises to guarantee direct oversight and streamline audits. Similarly, a deep-tech company developing a proprietary algorithm may require that its IP remain completely air-gapped from any third-party infrastructure.
This control, however, comes with a significant operational burden. You are solely responsible for everything:
- Physical Security: Securing the data center against unauthorized access.
- Hardware and Firmware Patching: Maintaining a rigorous patch management schedule for every server, router, and switch.
- Network Defense: Implementing and managing firewalls, intrusion detection systems, and DDoS mitigation.
- 24/7 Monitoring and Incident Response: Staffing a security operations center (SOC) capable of responding to threats at any time.
Without adequate investment in these functions, physical ownership creates a false sense of security. Owning the hardware is meaningless without the specialized expertise to defend it. This is a primary failure mode for on-premises strategies: underestimating the true investment required in security personnel and tooling. You can learn more about embedding these principles from the ground up in our guide on implementing GDPR privacy by design.
Mapping Compliance to Infrastructure
Your infrastructure choice must map directly to your regulatory obligations. It is not enough to be secure; you must be able to prove compliance to auditors.
- GDPR: Requires strict controls over personal data and its geographic location. While major cloud providers offer EU regions to satisfy data residency requirements, an on-premises deployment provides unambiguous proof that data never leaves your physical control.
- NIS2: This EU directive for critical infrastructure imposes stringent security and incident reporting obligations. The direct control of an on-premises system can simplify compliance demonstrations to auditors by reducing the number of third-party dependencies.
Ultimately, both models can be architected to be secure and compliant. The decision rests on whether you prefer to manage the physical complexity of total ownership or the configuration and governance challenges of a shared responsibility model.
Balancing Performance, Scalability, and Operational Load
The core engineering trade-off between on-premises and cloud is not about hardware specifications; it is a strategic choice between predictable performance and on-demand scalability. This decision dictates how you allocate your most valuable resource: your engineering team’s time. Will they manage infrastructure, or will they build features?
An on-premises environment offers finite but highly predictable performance. You control the hardware, the network topology, and can tune every component for minimal latency. For workloads like high-frequency trading, real-time industrial automation, or large-scale scientific computing, that direct control is non-negotiable.
The cloud provides a different performance paradigm: near-infinite elasticity, designed for systems with unpredictable demand.
A core distinction in the on-premises vs cloud debate is how each model handles peak load. On-premises requires you to provision for the highest anticipated demand, meaning expensive hardware often sits idle. The cloud allows you to scale resources up and down dynamically, paying only for what you use.
The Dynamics of Cloud Elasticity
The cloud’s primary performance advantage is its ability to scale horizontally on demand. Consider a B2B SaaS platform launching a feature that experiences unexpected viral adoption. An on-premises system would likely fail under the load, leading to downtime while new hardware is procured and deployed—a process that can take weeks.
In a cloud-native architecture, this is addressed with auto-scaling groups. When a metric like CPU utilization exceeds a predefined threshold, the cloud provider automatically provisions new virtual machines to distribute the load. When demand subsides, those instances are terminated, and billing stops.
This elasticity is fundamental to modern software delivery, enabling:
- Rapid Growth: Startups can accommodate explosive user growth without forecasting hardware needs months in advance.
- Cost Efficiency: Resources are matched precisely to demand, eliminating the waste of over-provisioning for peak capacity.
- Resilience: The failure of a single instance is a non-event. The system automatically replaces it, ensuring high availability.
The operational benefit is immense. Engineers shift from racking servers and managing physical networks to defining infrastructure as code and refining auto-scaling policies. This operational model is a prerequisite for modern development practices, as detailed in our guide to building a CI/CD pipeline.
The Burden of On-Premises Operations
While on-premises provides total control, that control imposes a significant operational cost. The burden of managing the entire infrastructure lifecycle—from deployment to decommissioning—falls squarely on your internal team. This requires a continuous investment in specialized talent.
The operational load includes:
- Hardware Maintenance: Proactively replacing failing components like hard drives, power supplies, and fans.
- Software and Firmware Patching: Diligently updating every server, switch, and storage array to mitigate security vulnerabilities.
- Monitoring and Alerting: Building and maintaining a robust 24/7 monitoring system to detect issues before they cause outages.
- Capacity Planning: Continuously analyzing utilization trends to forecast and justify future hardware acquisitions.
This operational responsibility directly detracts from innovation. Every hour an engineer spends on infrastructure maintenance is an hour not spent on developing features that deliver customer value. There’s a reason the global cloud computing market grew to USD 781.27 billion: businesses are strategically shifting away from on-premises operations to achieve scalability and reduce upfront hardware costs. Enterprises spent USD 330 billion on cloud infrastructure in a single year, largely driven by the need for AI-ready systems that on-premises models struggle to deliver without massive CapEx.
Beyond All-or-Nothing: Hybrid Models and Strategic Repatriation
The on-premises vs. cloud debate is often framed as a binary choice, but this is a false dilemma. An all-or-nothing approach is rarely optimal, as it forces workloads into environments that may be ill-suited for their performance, cost, or compliance profile. A more mature strategy involves a hybrid architecture, blending both models to create a cohesive system.
This approach allows you to place each workload in its optimal environment, balancing cost, security, and performance. A hybrid model is not a temporary compromise; it is a deliberate and sophisticated architectural pattern.
The Power of Hybrid Architectures
A hybrid cloud architecture combines on-premises infrastructure with public cloud services, enabling data and applications to move between them. The result is a single, flexible environment that leverages the strengths of each model while mitigating their respective weaknesses. It is about architecting a system where every component resides in its ideal location.
Common hybrid patterns include:
- Compliance-Driven Separation: Storing highly sensitive data (e.g., PII, critical IP) on-premises to satisfy strict regulations like GDPR or NIS2, while running stateless, scalable web front-ends in the public cloud.
- Cloud Bursting for Peak Loads: Running baseline workloads on cost-effective, predictable on-premises hardware. When a traffic spike occurs, the system automatically “bursts” into the cloud for additional capacity, avoiding the need to over-provision on-premises servers that would otherwise sit idle.
- Disaster Recovery and Resilience: Using the cloud as a secondary site for disaster recovery is a highly cost-effective strategy for business continuity compared to building and maintaining a duplicate physical data center. Explore this further in our guide on designing a disaster recovery plan in the cloud.
Hybrid architecture is the practical acknowledgement that no single environment is perfect for every workload. It’s about making deliberate trade-offs to align infrastructure directly with specific business and technical requirements, from low-latency processing to global scalability.
Understanding Cloud Repatriation
Cloud repatriation—the process of moving applications from a public cloud back to on-premises infrastructure—was once viewed as a sign of a failed cloud strategy. Today, it is recognized as a mature response to evolving business needs, particularly when cloud costs for stable, predictable workloads become unsustainable.
The primary driver is almost always financial. While the cloud is excellent for variable demand, its pay-as-you-go model can become a significant financial liability for applications with high, consistent utilization. Beyond a certain scale, the TCO of running a stable workload on-premises can be substantially lower than paying perpetual cloud fees.
When to Consider Repatriation
Repatriation is not a simple reversal but a strategic realignment. It becomes viable once a workload’s characteristics stabilize, allowing for confident capacity planning.
Key triggers that should place repatriation on your roadmap include:
- Predictable Workloads: Applications with consistent, high-volume traffic that no longer benefit from the cloud’s elasticity.
- Mounting Egress Costs: For data-intensive applications, the fees for transferring data out of the cloud can become a crippling operational expense.
- Performance Bottlenecks: For systems requiring ultra-low latency, dedicated hardware in close physical proximity to users or other systems offers performance that the public cloud often cannot match.
This trend reflects a broader shift toward a hybrid paradigm where businesses leverage the cloud’s flexibility for development and burst capacity while using owned hardware for cost-predictable, stable workloads. As cloud spending matures, more organizations are repatriating specific workloads to private data centers or colocation facilities to regain cost control and escape per-gigabyte egress fees. For low-latency systems, on-premises remains the superior choice. By combining on-premises for stability with selective cloud adoption, companies build pragmatic and resilient architectures.
A Practical Decision Framework for Your Business
The on-premises vs. cloud decision is not about choosing a superior technology; it is about aligning infrastructure with business reality. A one-size-fits-all approach inevitably leads to capital waste and operational friction. A clear decision framework that systematically evaluates your specific constraints and strategic goals is essential.
By moving past generic pro-con lists, the correct architectural path emerges. This process forces a confrontation with the real-world trade-offs between control, cost, and agility that will define your company’s technical future. It is a strategic exercise, not a technical checklist.
Evaluating Your Core Requirements
Begin by assessing your organization’s needs across five critical domains. This evaluation will quickly reveal which model’s strengths align with your actual priorities.
-
Regulatory and Compliance Constraints: Are you subject to strict data sovereignty laws like GDPR or industry-specific mandates such as DORA or NIS2? High-stakes compliance often favors the direct control of on-premises or a meticulously configured sovereign cloud environment.
-
Scalability and Performance Demands: Do your workloads exhibit extreme, unpredictable traffic patterns, or do they require consistent, low-latency performance? A high-growth SaaS platform requires the elastic scaling of the cloud. A real-time industrial control system may derive greater benefit from dedicated on-premises hardware.
-
Capital Availability (CapEx vs OpEx): Can your organization absorb a significant upfront investment in hardware? An early-stage, venture-funded startup will almost certainly prefer the pay-as-you-go OpEx model of the cloud. A mature enterprise with predictable budgets may find the long-term TCO of an on-premises model more advantageous.
-
In-House Technical Expertise: Do you have a dedicated team with the specialized skills to manage and secure physical infrastructure 24/7? The operational burden of on-premises is substantial. If your engineering talent is better allocated to product development, the managed services of the cloud provide a distinct advantage.
Situational Recommendations
Your evaluation should lead to a clear, defensible decision that aligns with your business profile.
The best architecture is a direct reflection of your business strategy. For an early-stage SaaS startup obsessed with rapid iteration, the cloud is the default choice. For an established financial institution governed by DORA, a hybrid or on-premises setup offers far better control and auditability.
This decision tree illustrates how priorities such as cost, control, and agility directly influence the optimal solution.
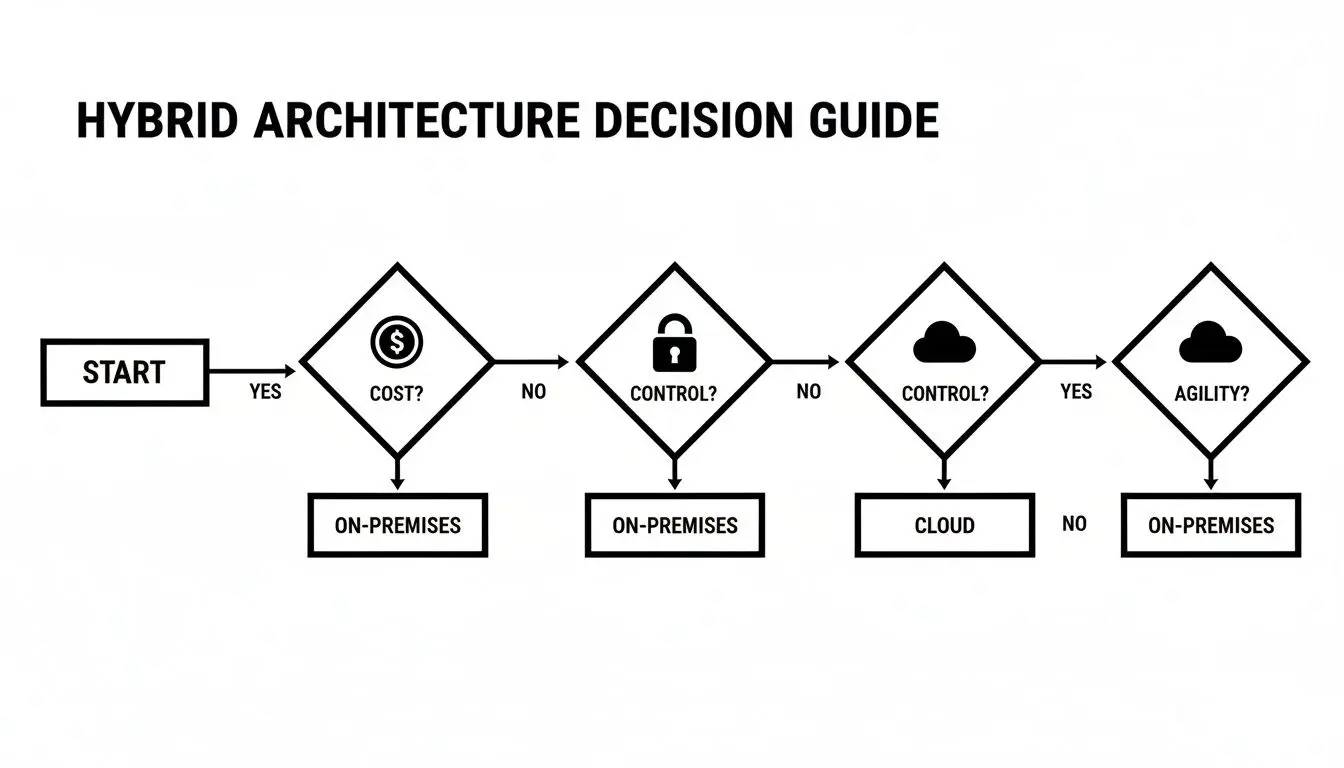
As the flowchart indicates, prioritizing cost predictability and direct control steers the decision toward on-premises. If your business depends on agility and rapid scaling, the cloud is the logical choice.
Using such a framework transforms the debate from a theoretical exercise into a practical, evidence-based strategy that supports your long-term objectives. It ensures you build on a foundation that enables growth rather than constraining it.
Common Questions, Practical Answers
When evaluating on-premises versus cloud, several practical questions consistently arise. Addressing the most common queries about migration, specialized workloads, and long-term costs will help clarify your decision.
Is Migrating from On-Premises to Cloud Worth the Headaches?
Migration is a significant undertaking, and its value is determined by business goals, not technology. A “lift-and-shift” migration, while appearing simple, often results in high operational costs because it fails to leverage cloud-native advantages; you are merely renting servers in a different data center.
A more strategic approach is to refactor applications to utilize cloud-native services like managed databases or serverless functions. While requiring more upfront engineering effort, this yields substantial long-term TCO and scalability benefits. The key is to justify the migration with a clear business case—such as accelerating development cycles or reducing operational drag—rather than migrating for its own sake.
Can the Cloud Really Handle Specialized AI Workloads?
Yes, but with critical trade-offs. Public clouds provide immediate access to powerful GPUs and TPUs, ideal for experimenting with AI models or handling variable inference workloads without a large upfront hardware investment.
However, for consistent, high-volume AI workloads—such as large-scale, 24/7 model inferencing—data egress fees and hourly compute costs can become prohibitive. In these scenarios, a dedicated on-premises or hybrid deployment often provides a lower TCO. The decision hinges on whether your AI demand is predictable or volatile.
The real question for AI isn’t if the cloud can handle the workload, but at what cost long-term. For stable, high-utilisation AI systems, the financial case for bringing them back on-prem often becomes compelling within months, not years.
How Do I Forecast Cloud Costs and Avoid a Budget Blowout?
Effective cloud cost management requires a shift from static budgeting to a dynamic governance model, often referred to as FinOps. The greatest risk is uncontrolled resource provisioning by engineering teams, which leads to unexpected and significant monthly bills.
To maintain cost control, implement fundamental financial guardrails:
- Tagging Policies: Mandate the tagging of every resource by project, team, and environment. Untagged resources are untraceable and uncontrollable.
- Budget Alerts: Configure automated alerts that trigger when spending approaches predefined thresholds to prevent end-of-month surprises.
- Reserved Instances: For predictable, long-running workloads, purchase reserved instances or savings plans. These can yield discounts of up to 70% compared to on-demand pricing.
Without disciplined governance, the cloud’s primary strength—elasticity—can become its greatest financial liability.
At Devisia, we treat infrastructure as a deliberate architectural choice that must serve your business goals, not as a default decision. We design and build reliable, maintainable software systems—whether that means on-premises, in the cloud, or a pragmatic hybrid solution that aligns with your operational reality. Turn your business vision into a robust digital product.