
La scelta tra infrastruttura on-premises e cloud è una decisione architetturale fondamentale, non una semplice selezione del fornitore. Rappresenta un compromesso tra due forze opposte: controllo assoluto e agilità operativa.
L’architettura on-premises offre un controllo diretto e fisico su hardware e dati, un requisito non negoziabile per molti settori regolamentati. Il cloud, al contrario, fornisce scalabilità elastica e astrae la gestione dell’infrastruttura, consentendo cicli di sviluppo rapidi e una risposta veloce al mercato senza un significativo investimento di capitale iniziale.
Definire i compromessi architetturali fondamentali
Il dibattito on-premises vs. cloud è una decisione strategica che determina il modello finanziario di un’azienda, la struttura operativa e le capacità di conformità a lungo termine. Non si tratta di acquistare server rispetto ad affittarli; è un impegno architetturale che influisce sulla velocità di sviluppo, sulla postura di sicurezza e sulla resilienza.
Per i leader tecnici, questo richiede di andare oltre definizioni semplicistiche per affrontare le realtà pratiche della costruzione e gestione di sistemi software robusti.
La scelta ottimale dipende interamente dal contesto aziendale. Siete vincolati da quadri normativi rigorosi? I requisiti prestazionali richiedono una latenza minima? La rapidità di immissione sul mercato è il vostro principale vantaggio competitivo? Questa guida fornisce un framework pragmatico per CTO, founder e IT manager per orientarsi in questa decisione complessa con chiarezza architetturale.
Dimensioni chiave della decisione
Prima di analizzare implementazioni specifiche, dobbiamo inquadrare il confronto lungo dimensioni aziendali e tecniche critiche. Ciascun modello presenta una proposta di valore e un insieme di vincoli distinti:
- Modello finanziario: L’on-premises è caratterizzato da un significativo capital expenditure (CapEx) iniziale per hardware, seguito da operational expenses (OpEx) continui per manutenzione e personale. I servizi cloud ribaltano questo modello, operando quasi interamente con un modello OpEx pay-as-you-go.
- Controllo e sovranità: L’on-premises offre un controllo fisico e logico completo su dati e hardware. Questo è essenziale per i settori soggetti a rigorose normative sulla residenza dei dati o per quelli che gestiscono proprietà intellettuale altamente sensibile, dove l’accesso di terze parti rappresenta un rischio inaccettabile.
- Scalabilità e agilità: Il cloud offre una scalabilità delle risorse quasi istantanea per gestire carichi di traffico imprevedibili o una crescita rapida. La scalabilità on-premises è un processo manuale e lungo che comporta cicli di approvvigionamento, installazione e configurazione dell’hardware.
- Carico operativo: Con l’on-premises, il team interno è responsabile dell’intero stack—manutenzione hardware, configurazione di rete, sicurezza fisica e patching. I provider cloud astraggono questa complessità, consentendo ai team di ingegneria di concentrarsi sullo sviluppo a livello applicativo.
La decisione riguarda meno quale modello sia oggettivamente “migliore” e più quale insieme di vincoli e compromessi si allinei ai vostri obiettivi strategici. Una startup che dà priorità alla velocità di sviluppo accetterà rischi diversi rispetto a un istituto finanziario soggetto alle normative DORA.
Per chiarire queste distinzioni, la tabella seguente fornisce una panoramica di alto livello per guidare l’analisi più approfondita nelle sezioni successive.
Confronto a colpo d’occhio: modelli On-Premises vs. Cloud
| Dimensione | On-Premises | Cloud |
|---|---|---|
| Struttura dei costi | Alto CapEx iniziale, OpEx prevedibile | CapEx iniziale basso/assente, OpEx variabile |
| Controllo | Controllo fisico e logico completo sull’infrastruttura | Modello di responsabilità condivisa; controllo fisico limitato |
| Scalabilità | Manuale, pianificata e finita | Automatica, on-demand ed elastica |
| Sicurezza | Responsabilità completa per la sicurezza fisica e di rete | Il provider gestisce la sicurezza dell’infrastruttura; voi gestite applicazione/dati |
| Conformità | Il controllo diretto semplifica gli audit per normative specifiche | Richiede una configurazione attenta per soddisfare gli standard (ad es., GDPR, NIS2) |
| Manutenzione | Il team interno è responsabile di tutta la manutenzione hardware e software | Gestita dal provider cloud |
In definitiva, questa tabella evidenzia il compromesso architetturale centrale. L’on-premises offre controllo assoluto al costo di un sovraccarico operativo, mentre il cloud offre agilità e scalabilità astraendo tale complessità.
Scomporre il costo totale di proprietà
Un confronto superficiale dei costi tra on-premises e cloud—presentandolo come una semplice scelta tra capital expenditure (CapEx) e operational expenditure (OpEx)—è fuorviante e finanziariamente irresponsabile. Una decisione architetturale solida richiede un’analisi rigorosa del Total Cost of Ownership (TCO), che tenga conto di tutti i costi diretti, indiretti e nascosti lungo il ciclo di vita dell’infrastruttura.
Una valutazione TCO ingenua porta spesso a significativi sforamenti di budget e fallimenti operativi.
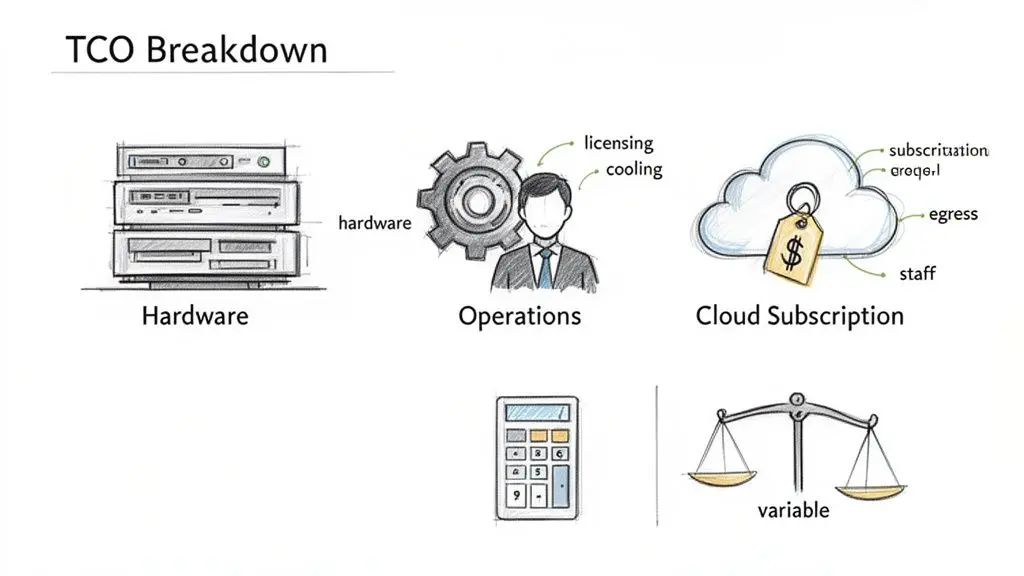
Per carichi di lavoro prevedibili che operano a utilizzo elevato e costante, l’infrastruttura on-premises può offrire un TCO inferiore su un orizzonte pluriennale. Al contrario, il modello pay-as-you-go del cloud offre un’indiscutibile agilità finanziaria per sistemi con domanda volatile o in una fase di crescita rapida. Per costruire un modello finanziario realistico, è necessario andare oltre il binomio CapEx vs. OpEx.
Il vero costo dell’infrastruttura on-premises
Il TCO dell’on-premises va ben oltre l’acquisto iniziale del server. Un budget completo deve considerare l’intera gamma di spese dirette e indirette che si accumulano לאורך il ciclo di vita dell’hardware. Sottostimare questi costi è una causa comune di fallimento dei progetti.
Le principali componenti di costo includono:
- Acquisizione hardware: server, array di storage e apparecchiature di rete rappresentano un significativo investimento di capitale iniziale.
- Licenze software: sistemi operativi, piattaforme di virtualizzazione, database e applicazioni enterprise spesso comportano costi di licenza sostanziali, che possono essere perpetui o basati su abbonamento.
- Infrastruttura fisica: l’hardware richiede un ambiente idoneo. Questo include spazio data center (o costi di colocation), distribuzione dell’alimentazione, sistemi di raffreddamento ridondanti e controlli di accesso fisico. Si tratta di costi materiali e ricorrenti.
- Capitale umano: è necessario un team IT qualificato per gestione, manutenzione e sicurezza. Gli stipendi di system administrator, network engineer e specialisti di sicurezza costituiscono una spesa operativa importante e continua.
Il costo più frequentemente sottovalutato in un modello on-premises è il fattore umano. Il carico operativo non è solo una voce di bilancio; è un drenaggio strategico di risorse di ingegneria che altrimenti potrebbero essere dedicate all’innovazione di prodotto.
Analizzare l’economia del cloud e i costi nascosti
Il modello OpEx del cloud appare semplice, ma il suo TCO è altrettanto complesso. Sebbene elimini i costi hardware iniziali, la mancanza di una governance disciplinata può portare a spese in rapido aumento, annullando i risparmi iniziali. Comprendere questi fattori di costo è fondamentale per la prevedibilità finanziaria.
Le principali componenti di costo del cloud sono:
- Canoni di abbonamento e costi di utilizzo: il cuore della fattura, basato sulle risorse di calcolo, storage e database consumate. Prevederlo con precisione per carichi di lavoro dinamici è una sfida significativa.
- Costi di data egress: una causa comune di shock da budget. I provider cloud in genere addebitano il trasferimento di dati fuori dalla propria rete. Per applicazioni data-intensive, queste tariffe possono diventare una parte sostanziale della fattura mensile.
- Servizi accessori: monitoraggio, logging, load balancing e funzionalità di sicurezza avanzate sono raramente inclusi nel prezzo base. Sono fatturati come voci separate e possono accumularsi rapidamente.
- Sforamenti di budget: la facilità di provisioning di nuove risorse è un’arma a doppio taglio. Senza un rigoroso controllo dei costi e una governance adeguata, gli ingegneri possono inavvertitamente generare sforamenti enormi e inattesi.
Per carichi di lavoro specializzati come l’AI, i modelli finanziari divergono in modo marcato. Per l’inference AI in cui bassa latenza e sovranità dei dati sono critiche, l’on-premises richiede un forte investimento iniziale ma può generare un ritorno rapido. Un’analisi TCO per la Generative AI rivela che i sistemi on-premises possono raggiungere il pareggio in meno di quattro mesi per carichi di lavoro ad alto utilizzo, offrendo risparmi significativi per milione di token rispetto alle API cloud.
Ad esempio, una configurazione on-premises con un CapEx di 277.897 $ ha un OpEx orario di soli 8,79 $. Il tasso cloud on-demand equivalente è 84,81 $/ora. Potete scoprire ulteriori approfondimenti su questo confronto dell’infrastruttura IT.
Affrontare le realtà di sicurezza e conformità
Sicurezza e conformità non sono funzionalità; sono proprietà architetturali che devono essere progettate fin dall’inizio. La scelta tra on-premises e cloud non riguarda quale sia intrinsecamente “più sicuro”, ma quale modello di responsabilità e insieme di compromessi un’organizzazione sia attrezzata a gestire. Un approccio ingenuo a entrambi i modelli espone l’azienda a significative sanzioni normative e danni reputazionali. Per qualsiasi sistema B2B che elabori dati sensibili sotto normative come GDPR, NIS2 o DORA, questa è una delle decisioni architetturali iniziali più critiche.

Il cloud e il modello di responsabilità condivisa
Un’idea errata comune è che il passaggio al cloud scarichi gli obblighi di sicurezza. In realtà, si entra in un modello di responsabilità condivisa. Mentre il provider cloud protegge l’infrastruttura di base—data center fisici, server e networking core—voi siete pienamente responsabili della sicurezza di tutto ciò che costruite su quell’infrastruttura.
Questo significa che il vostro team è responsabile di:
- Sicurezza dei dati: implementare la crittografia per i dati in transito e a riposo, includendo una robusta gestione delle chiavi.
- Controlli a livello applicativo: proteggere il codice proprietario da vulnerabilità come injection attack e insecure deserialization.
- Identity and Access Management (IAM): configurare correttamente permessi e ruoli degli utenti. Una singola policy IAM configurata in modo errato può portare a una catastrofica esposizione dei dati.
- Configurazione di rete: progettare Virtual Private Cloud (VPC), security group e regole firewall per imporre la segmentazione della rete e controllare il flusso del traffico.
Il rischio maggiore in questo modello è un falso senso di sicurezza. Il provider offre primitive sicure, ma il vostro team deve usarle correttamente. Supporre che il provider gestisca tutto è una strada diretta verso una violazione dei dati.
Un provider cloud mette in sicurezza l’edificio, ma voi siete responsabili di chiudere a chiave la porta del vostro ufficio. Dimenticare questa distinzione è uno degli errori più comuni e costosi nell’adozione del cloud.
Controllo on-premises e peso della titolarità
Il principale vantaggio di sicurezza di un’architettura on-premises è il controllo totale. Possedete l’intero stack, dal server fisico in un rack chiuso a chiave al codice applicativo. Per le organizzazioni in settori fortemente regolamentati o per quelle che proteggono proprietà intellettuale mission-critical, questo livello di controllo è spesso un requisito di base.
Una società di servizi finanziari soggetta al Digital Operational Resilience Act (DORA) potrebbe scegliere l’on-premises per garantire una supervisione diretta e semplificare gli audit. Allo stesso modo, un’azienda deep-tech che sviluppa un algoritmo proprietario potrebbe richiedere che la propria IP rimanga completamente air-gapped da qualsiasi infrastruttura di terze parti.
Questo controllo, tuttavia, comporta un notevole onere operativo. Sei l’unico responsabile di tutto:
- Sicurezza fisica: Proteggere il data center da accessi non autorizzati.
- Patch di hardware e firmware: Mantenere un rigoroso programma di gestione delle patch per ogni server, router e switch.
- Difesa della rete: Implementare e gestire firewall, sistemi di rilevamento delle intrusioni e mitigazione DDoS.
- Monitoraggio e risposta agli incidenti 24/7: Dotarsi di un security operations center (SOC) in grado di rispondere alle minacce in qualsiasi momento.
Senza un investimento adeguato in queste funzioni, la proprietà fisica crea un falso senso di sicurezza. Possedere l’hardware non significa nulla senza l’expertise specializzata per difenderlo. Questo è un principale punto di fallimento delle strategie on-premises: sottovalutare il vero investimento richiesto in personale e strumenti per la sicurezza. Puoi approfondire come integrare questi principi fin dall’inizio nella nostra guida su implementare la privacy by design del GDPR.
Mappare la conformità sull’infrastruttura
La scelta della tua infrastruttura deve allinearsi direttamente ai tuoi obblighi normativi. Non basta essere sicuri; devi essere in grado di dimostrare la conformità agli auditor.
- GDPR: Richiede controlli rigorosi sui dati personali e sulla loro collocazione geografica. Sebbene i principali provider cloud offrano regioni UE per soddisfare i requisiti di data residency, una distribuzione on-premises fornisce una prova inequivocabile che i dati non escono mai dal tuo controllo fisico.
- NIS2: Questa direttiva UE per le infrastrutture critiche impone rigorosi obblighi di sicurezza e di segnalazione degli incidenti. Il controllo diretto di un sistema on-premises può semplificare le dimostrazioni di conformità agli auditor, riducendo il numero di dipendenze da terze parti.
In definitiva, entrambi i modelli possono essere progettati per essere sicuri e conformi. La decisione dipende dal fatto che tu preferisca gestire la complessità fisica della piena proprietà oppure le sfide di configurazione e governance di un modello a responsabilità condivisa.
Bilanciare prestazioni, scalabilità e carico operativo
Il trade-off ingegneristico fondamentale tra on-premises e cloud non riguarda le specifiche hardware; è una scelta strategica tra prestazioni prevedibili e scalabilità on-demand. Questa decisione determina come allochi la tua risorsa più preziosa: il tempo del tuo team di ingegneria. Gestiranno l’infrastruttura o costruiranno funzionalità?
Un ambiente on-premises offre prestazioni finite ma altamente prevedibili. Controlli l’hardware, la topologia di rete e puoi ottimizzare ogni componente per una latenza minima. Per carichi di lavoro come il trading ad alta frequenza, l’automazione industriale in tempo reale o il calcolo scientifico su larga scala, quel controllo diretto non è negoziabile.
Il cloud offre un paradigma di prestazioni diverso: elasticità quasi infinita, progettata per sistemi con domanda imprevedibile.
Una distinzione fondamentale nel dibattito on-premises vs cloud è il modo in cui ciascun modello gestisce i picchi di carico. L’on-premises richiede di dimensionare le risorse per la domanda massima prevista, il che significa che hardware costoso spesso resta inutilizzato. Il cloud consente di aumentare e ridurre dinamicamente le risorse, pagando solo per ciò che usi.
Le dinamiche dell’elasticità del cloud
Il principale vantaggio prestazionale del cloud è la capacità di scalare orizzontalmente su richiesta. Considera una piattaforma SaaS B2B che lancia una funzionalità che ottiene un’adozione virale inaspettata. Un sistema on-premises probabilmente crollerebbe sotto il carico, causando downtime mentre nuovo hardware viene acquistato e distribuito—un processo che può richiedere settimane.
In un’architettura cloud-native, questo viene affrontato con gli auto-scaling group. Quando una metrica come l’utilizzo della CPU supera una soglia predefinita, il provider cloud provisiona automaticamente nuove macchine virtuali per distribuire il carico. Quando la domanda diminuisce, quelle istanze vengono terminate e la fatturazione si interrompe.
Questa elasticità è fondamentale per la distribuzione moderna del software e consente:
- Crescita rapida: Le startup possono gestire una crescita esplosiva degli utenti senza prevedere con mesi di anticipo il fabbisogno hardware.
- Efficienza dei costi: Le risorse vengono allineate con precisione alla domanda, eliminando lo spreco di sovradimensionare per la capacità di picco.
- Resilienza: Il guasto di una singola istanza è un non-evento. Il sistema la sostituisce automaticamente, garantendo alta disponibilità.
Il beneficio operativo è enorme. Gli ingegneri passano dal montare server e gestire reti fisiche alla definizione dell’infrastruttura come codice e al perfezionamento delle policy di auto-scaling. Questo modello operativo è un prerequisito per le pratiche di sviluppo moderne, come dettagliato nella nostra guida su costruire una pipeline CI/CD.
L’onere delle operazioni on-premises
Sebbene l’on-premises offra il controllo totale, quel controllo impone un costo operativo significativo. L’onere di gestire l’intero ciclo di vita dell’infrastruttura—dalla distribuzione alla dismissione—ricade interamente sul tuo team interno. Questo richiede un investimento continuo in talenti specializzati.
Il carico operativo include:
- Manutenzione hardware: Sostituire in modo proattivo componenti guasti come dischi rigidi, alimentatori e ventole.
- Patch software e firmware: Aggiornare diligentemente ogni server, switch e array di storage per mitigare le vulnerabilità di sicurezza.
- Monitoraggio e alerting: Costruire e mantenere un robusto sistema di monitoraggio 24/7 per rilevare i problemi prima che causino interruzioni.
- Pianificazione della capacità: Analizzare continuamente i trend di utilizzo per prevedere e giustificare futuri acquisti di hardware.
Questa responsabilità operativa sottrae direttamente spazio all’innovazione. Ogni ora che un ingegnere dedica alla manutenzione dell’infrastruttura è un’ora non spesa nello sviluppo di funzionalità che generano valore per il cliente. C’è un motivo per cui il mercato globale del cloud computing è cresciuto fino a USD 781.27 billion: le aziende stanno strategicamente abbandonando le operazioni on-premises per ottenere scalabilità e ridurre i costi hardware iniziali. Le imprese hanno speso USD 330 billion in infrastruttura cloud in un solo anno, spinte in larga parte dalla necessità di sistemi pronti per l’AI che i modelli on-premises faticano a fornire senza un enorme CapEx.
Oltre il tutto-o-niente: modelli ibridi e repatriation strategica
Il dibattito on-premises vs. cloud viene spesso presentato come una scelta binaria, ma si tratta di un falso dilemma. Un approccio tutto-o-niente è raramente ottimale, poiché costringe i carichi di lavoro in ambienti che potrebbero essere inadatti al loro profilo di prestazioni, costi o conformità. Una strategia più matura prevede un’architettura ibrida, che combina entrambi i modelli per creare un sistema coerente.
Questo approccio ti consente di collocare ogni carico di lavoro nel suo ambiente ottimale, bilanciando costi, sicurezza e prestazioni. Un modello ibrido non è un compromesso temporaneo; è un pattern architetturale deliberato e sofisticato.
Il potere delle architetture ibride
Un’architettura cloud ibrida combina infrastruttura on-premises con servizi cloud pubblici, consentendo a dati e applicazioni di spostarsi tra i due. Il risultato è un ambiente unico e flessibile che sfrutta i punti di forza di ciascun modello mitigandone al tempo stesso le rispettive debolezze. Si tratta di progettare un sistema in cui ogni componente risieda nella posizione ideale.
I pattern ibridi più comuni includono:
- Separazione guidata dalla conformità: Archiviare i dati altamente sensibili (ad es. PII, IP critico) on-premises per soddisfare normative rigorose come GDPR o NIS2, mentre si eseguono front-end web stateless e scalabili nel cloud pubblico.
- Cloud bursting per i picchi di carico: Eseguire i workload di base su hardware on-premises economico e prevedibile. Quando si verifica un picco di traffico, il sistema “esplode” automaticamente nel cloud per capacità aggiuntiva, evitando la necessità di sovradimensionare i server on-premises che altrimenti resterebbero inattivi.
- Disaster recovery e resilienza: Usare il cloud come sito secondario per il disaster recovery è una strategia altamente conveniente per la business continuity rispetto alla costruzione e manutenzione di un data center fisico duplicato. Approfondisci in nostra guida su progettare un piano di disaster recovery nel cloud.
L’architettura ibrida è il riconoscimento pratico del fatto che nessun singolo ambiente è perfetto per ogni workload. Si tratta di fare trade-off deliberati per allineare direttamente l’infrastruttura a specifici requisiti business e tecnici, dall’elaborazione a bassa latenza alla scalabilità globale.
Comprendere la repatriation dal cloud
La repatriation dal cloud—il processo di spostare applicazioni da un cloud pubblico a un’infrastruttura on-premises—era un tempo vista come il segno di una strategia cloud fallita. Oggi è riconosciuta come una risposta matura all’evoluzione delle esigenze di business, in particolare quando i costi cloud per workload stabili e prevedibili diventano insostenibili.
Il principale driver è quasi sempre finanziario. Sebbene il cloud sia eccellente per la domanda variabile, il suo modello pay-as-you-go può diventare una notevole passività finanziaria per applicazioni con utilizzo elevato e costante. Oltre una certa scala, il TCO dell’esecuzione di un workload stabile on-premises può essere sostanzialmente inferiore rispetto al pagamento continuo delle tariffe cloud.
Quando considerare la repatriation
La repatriation non è una semplice inversione, ma un riallineamento strategico. Diventa praticabile una volta che le caratteristiche di un workload si stabilizzano, consentendo una pianificazione della capacità affidabile.
I principali fattori scatenanti che dovrebbero inserire la repatriation nella tua roadmap includono:
- Workload prevedibili: Applicazioni con traffico costante e ad alto volume che non beneficiano più dell’elasticità del cloud.
- Costi di egress in aumento: Per applicazioni ad alta intensità di dati, le tariffe per trasferire dati fuori dal cloud possono diventare una spesa operativa paralizzante.
- Colli di bottiglia prestazionali: Per sistemi che richiedono una latenza bassissima, hardware dedicato in stretta prossimità fisica agli utenti o ad altri sistemi offre prestazioni che il cloud pubblico spesso non può eguagliare.
Questa tendenza riflette un cambiamento più ampio verso un paradigma ibrido in cui le aziende sfruttano la flessibilità del cloud per sviluppo e capacità burst, utilizzando al contempo hardware di proprietà per workload stabili e con costi prevedibili. Con la maturazione della spesa cloud, sempre più organizzazioni stanno riportando specifici workload in data center privati o strutture di colocation per riottenere il controllo dei costi ed evitare le tariffe di egress per gigabyte. Per i sistemi a bassa latenza, l’on-premises rimane la scelta superiore. Combinando l’on-premises per la stabilità con un’adozione selettiva del cloud, le aziende costruiscono architetture pragmatiche e resilienti.
Un framework decisionale pratico per la tua azienda
La decisione on-premises vs. cloud non riguarda la scelta di una tecnologia superiore; riguarda l’allineamento dell’infrastruttura alla realtà aziendale. Un approccio valido per tutti porta inevitabilmente a sprechi di capitale e attriti operativi. È essenziale un chiaro framework decisionale che valuti sistematicamente i tuoi vincoli specifici e i tuoi obiettivi strategici.
Andando oltre le generiche liste di pro e contro, emerge il corretto percorso architetturale. Questo processo impone un confronto con i reali trade-off tra controllo, costi e agilità che definiranno il futuro tecnico della tua azienda. È un esercizio strategico, non una checklist tecnica.
Valutare i tuoi requisiti fondamentali
Inizia valutando le esigenze della tua organizzazione in cinque ambiti critici. Questa valutazione rivelerà rapidamente quali punti di forza di ciascun modello si allineano alle tue priorità reali.
-
Vincoli Normativi e di Conformità: Sei soggetto a rigide leggi sulla sovranità dei dati come il GDPR o a obblighi specifici di settore come DORA o NIS2? La conformità ad alto rischio spesso favorisce il controllo diretto di un ambiente on-premises o di un cloud sovrano configurato con estrema accuratezza.
-
Esigenze di Scalabilità e Prestazioni: I tuoi workload presentano pattern di traffico estremi e imprevedibili, oppure richiedono prestazioni costanti e a bassa latenza? Una piattaforma SaaS in rapida crescita richiede la scalabilità elastica del cloud. Un sistema di controllo industriale in tempo reale può trarre maggior beneficio da hardware on-premises dedicato.
-
Disponibilità di Capitale (CapEx vs OpEx): La tua organizzazione può assorbire un investimento iniziale significativo in hardware? Una startup in fase iniziale, finanziata da venture capital, preferirà quasi certamente il modello OpEx pay-as-you-go del cloud. Un’azienda matura con budget prevedibili può trovare più vantaggioso il TCO a lungo termine di un modello on-premises.
-
Competenza Tecnica Interna: Disponi di un team dedicato con le competenze specialistiche necessarie per gestire e mettere in sicurezza l’infrastruttura fisica 24/7? Il carico operativo dell’on-premises è considerevole. Se il tuo talento ingegneristico è meglio allocato allo sviluppo del prodotto, i servizi gestiti del cloud offrono un vantaggio distintivo.
Raccomandazioni Situazionali
La tua valutazione dovrebbe portare a una decisione chiara e difendibile, in linea con il profilo della tua attività.
La migliore architettura è il riflesso diretto della tua strategia aziendale. Per una startup SaaS in fase iniziale ossessionata dall’iterazione rapida, il cloud è la scelta predefinita. Per un istituto finanziario consolidato soggetto a DORA, una configurazione ibrida o on-premises offre un controllo e una verificabilità molto migliori.
Questo albero decisionale illustra come priorità quali costo, controllo e agilità influenzino direttamente la soluzione ottimale.
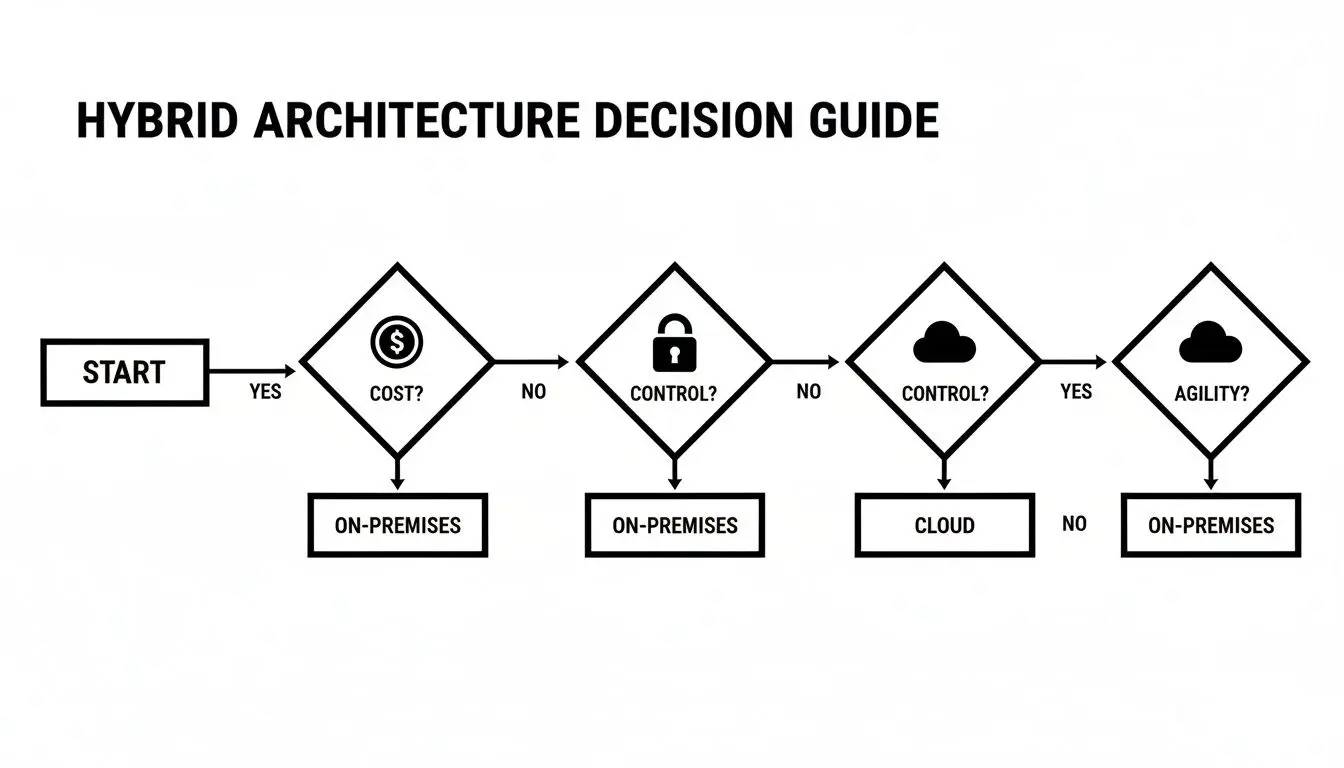
Come indica il diagramma di flusso, dare priorità alla prevedibilità dei costi e al controllo diretto orienta la decisione verso l’on-premises. Se la tua attività dipende da agilità e scalabilità rapida, il cloud è la scelta logica.
Utilizzare un framework di questo tipo trasforma il dibattito da esercizio teorico in una strategia pratica, basata su evidenze, che supporta i tuoi obiettivi a lungo termine. Ti assicura di costruire su una base che abilita la crescita anziché limitarla.
Domande Comuni, Risposte Pratiche
Quando si valuta l’on-premises rispetto al cloud, emergono costantemente alcune domande pratiche. Affrontare i quesiti più comuni su migrazione, workload specializzati e costi a lungo termine aiuterà a chiarire la tua decisione.
Vale la Pena Migrare da On-Premises al Cloud, Nonostante le Difficoltà?
La migrazione è un’impresa significativa e il suo valore è determinato dagli obiettivi di business, non dalla tecnologia. Una migrazione “lift-and-shift”, sebbene sembri semplice, spesso comporta costi operativi elevati perché non sfrutta i vantaggi cloud-native; stai semplicemente noleggiando server in un altro data center.
Un approccio più strategico consiste nel refactoring delle applicazioni per utilizzare servizi cloud-native come database gestiti o funzioni serverless. Pur richiedendo un maggiore sforzo ingegneristico iniziale, ciò genera notevoli benefici in termini di TCO e scalabilità nel lungo periodo. La chiave è giustificare la migrazione con un chiaro caso di business — come accelerare i cicli di sviluppo o ridurre l’attrito operativo — invece di migrare per il solo gusto di farlo.
Il Cloud Può Davvero Gestire Workload AI Specializzati?
Sì, ma con compromessi importanti. I cloud pubblici offrono accesso immediato a potenti GPU e TPU, ideali per sperimentare con modelli AI o gestire workload di inferenza variabili senza un grande investimento iniziale in hardware.
Tuttavia, per workload AI costanti e ad alto volume — come l’inferenza di modelli su larga scala, 24/7 — i costi di data egress e i costi di calcolo orari possono diventare proibitivi. In questi scenari, un’implementazione on-premises dedicata o ibrida offre spesso un TCO inferiore. La decisione dipende dal fatto che la tua domanda di AI sia prevedibile o volatile.
La vera domanda per l’AI non è se il cloud possa gestire il workload, ma a quale costo nel lungo periodo. Per sistemi AI stabili e con utilizzo elevato, il caso finanziario per riportarli on-prem spesso diventa convincente in pochi mesi, non in anni.
Come Posso Prevedere i Costi del Cloud ed Evitare un Sforamento del Budget?
Una gestione efficace dei costi cloud richiede un passaggio dal budgeting statico a un modello di governance dinamico, spesso definito FinOps. Il rischio maggiore è l’assegnazione non controllata di risorse da parte dei team di engineering, che porta a bollette mensili inattese e significative.
Per mantenere il controllo dei costi, implementa i seguenti guardrail finanziari fondamentali:
- Politiche di Tagging: Imporre il tagging di ogni risorsa per progetto, team e ambiente. Le risorse non taggate sono non tracciabili e incontrollabili.
- Avvisi di Budget: Configura avvisi automatici che si attivano quando la spesa si avvicina a soglie predefinite, per evitare sorprese a fine mese.
- Istanze Riservate: Per workload prevedibili e di lunga durata, acquista istanze riservate o piani di risparmio. Questi possono generare sconti fino al 70% rispetto al pricing on-demand.
Senza una governance disciplinata, il principale punto di forza del cloud — l’elasticità — può diventare la sua più grande passività finanziaria.
In Devisia, consideriamo l’infrastruttura una scelta architettonica deliberata che deve servire gli obiettivi del tuo business, non una decisione predefinita. Progettiamo e realizziamo sistemi software affidabili e manutenibili — che ciò significhi on-premises, nel cloud o una soluzione ibrida pragmatica in linea con la tua realtà operativa. Trasforma la visione del tuo business in un prodotto digitale robusto.