
Under the GDPR, privacy by design is a legal requirement, not a best-practice recommendation. For CTOs, architects, and product leaders, this mandate transforms privacy from a last-minute compliance checkbox into a foundational engineering principle. It dictates that data protection must be embedded into the architecture of software systems from the very beginning of the development lifecycle.
Why Privacy by Design Is a Core Engineering Challenge
GDPR’s Article 25 places the responsibility for data protection squarely on the shoulders of the teams building the software. The problem many organizations face is treating privacy as an afterthought—a feature to be “bolted on” before launch. This reactive approach is a high-risk strategy that consistently leads to brittle systems, security vulnerabilities, and a significant accumulation of technical and compliance debt.
When privacy isn’t architected into a system, the consequences are tangible. Engineering teams must resort to inefficient manual processes or costly system overhauls to handle fundamental data subject rights, such as the right to erasure. This not only diverts resources from product innovation but also creates operational bottlenecks and erodes customer trust. The failure to build privacy into the core design is the root cause of many preventable data breaches and compliance failures.
The Real Cost of Non-Compliance
Ignoring GDPR privacy by design exposes a business to significant financial penalties and reputational damage. Since its implementation in 2018, data protection authorities (DPAs) have demonstrated a willingness to enforce the regulation with substantial fines. An analysis by the Future of Privacy Forum (FPF) revealed over 630 enforcement actions resulting in €283 million in fines within the first few years. High-profile cases, such as Google’s €57 million penalty, underscore the financial risks. You can learn more about DPA enforcement trends and their impact on IT.
However, regulatory fines are only one part of the cost. A design-related data breach triggers a cascade of expensive consequences:
- Emergency Engineering Sprints: Diverting senior engineers from strategic product development to urgent, reactive incident response.
- Reputational Damage: The loss of customer trust directly impacts user acquisition and retention, inflicting long-term commercial harm.
- Operational Disruption: Halting product development or core business operations to address a compliance failure.
For a CTO, the argument for privacy by design is one of pragmatic risk management. It is an investment in building a resilient, maintainable, and trustworthy product—one better equipped for long-term growth and less susceptible to regulatory disruption.
From Legal Mandate to Competitive Advantage
Viewing GDPR privacy by design solely through the lens of compliance is a missed opportunity. A product built on a robust privacy foundation is inherently more secure, reliable, and better aligned with modern user expectations.
Teams that integrate privacy principles from the outset build systems that are easier to scale, audit, and adapt to future regulations. They are not merely compliant; they are building a competitive advantage. Demonstrating a tangible commitment to data protection through thoughtful engineering builds the deep, lasting trust that separates market leaders from their competitors. This positions privacy as a core product feature, not just an operational burden.
From Legal Principles to Engineering Reality
To implement GDPR Privacy by Design effectively, engineering leaders must translate legal language into concrete technical requirements. Article 25 is fundamentally about two distinct but related concepts: Privacy by Design and Privacy by Default. Confusing the two is a common and costly implementation mistake.
Privacy by Design (PbD) is an architectural philosophy. It requires that data protection measures are embedded into the system’s core design from the earliest stages. Just as a skyscraper’s structural safety features are part of the initial blueprint, not added as an afterthought, privacy controls must be integral to the software’s architecture.
Privacy by Default (PbbD) is about configuration. It mandates that the most privacy-protective settings are enabled by default, without any user intervention. This means a new user is automatically afforded the highest level of privacy; they must make an explicit, affirmative choice to reduce their privacy settings, such as opting in to data sharing, rather than being forced to opt out.
The following table clarifies the distinction in a practical product context.
Privacy by Design vs Privacy by Default in Practice
| Aspect | Privacy by Design (PbD) | Privacy by Default (PbbD) |
|---|---|---|
| Core Focus | The system’s underlying architecture and data flows. | The user-facing settings and default configurations. |
| Timing | Implemented from the project’s very beginning (Day 0). | Configured at the point of user onboarding or feature activation. |
| Software Example | Using database-level encryption and data minimization by design. | An analytics opt-in checkbox is unchecked by default. |
One is the foundation; the other is the factory setting. Both are required for compliance, but they address different aspects of the privacy challenge.
The 7 Foundational Principles of PbD
The Privacy by Design framework is built on seven core principles. For engineering leaders, these serve as a practical checklist for building systems that are both compliant and trustworthy.
- Proactive not Reactive; Preventative not Remedial: Design systems to anticipate and prevent privacy failures before they occur, rather than relying solely on incident response.
- Privacy as the Default Setting: This is the direct link to PbbD. Ensure that if a user takes no action, their personal data is fully protected by default.
- Privacy Embedded into Design: Data protection must be a fundamental component of the core architecture, influencing database schemas, API contracts, and service interactions.
- Full Functionality—Positive-Sum, not Zero-Sum: Reject the false trade-off between privacy and user experience. The design challenge is to deliver both without compromise.
- End-to-End Security—Full Lifecycle Protection: Implement robust security measures to protect data throughout its entire lifecycle—from collection to processing, storage, and secure deletion.
- Visibility and Transparency—Keep it Open: Provide clear, accessible information about what data is collected, the purpose of its collection, and how it is processed. Avoid opaque processes.
- Respect for User Privacy—Keep it User-Centric: The system’s design must empower users by giving them control over their personal data. Provide clear choices and honor them consistently.
Failure to adhere to these principles introduces significant business risks.
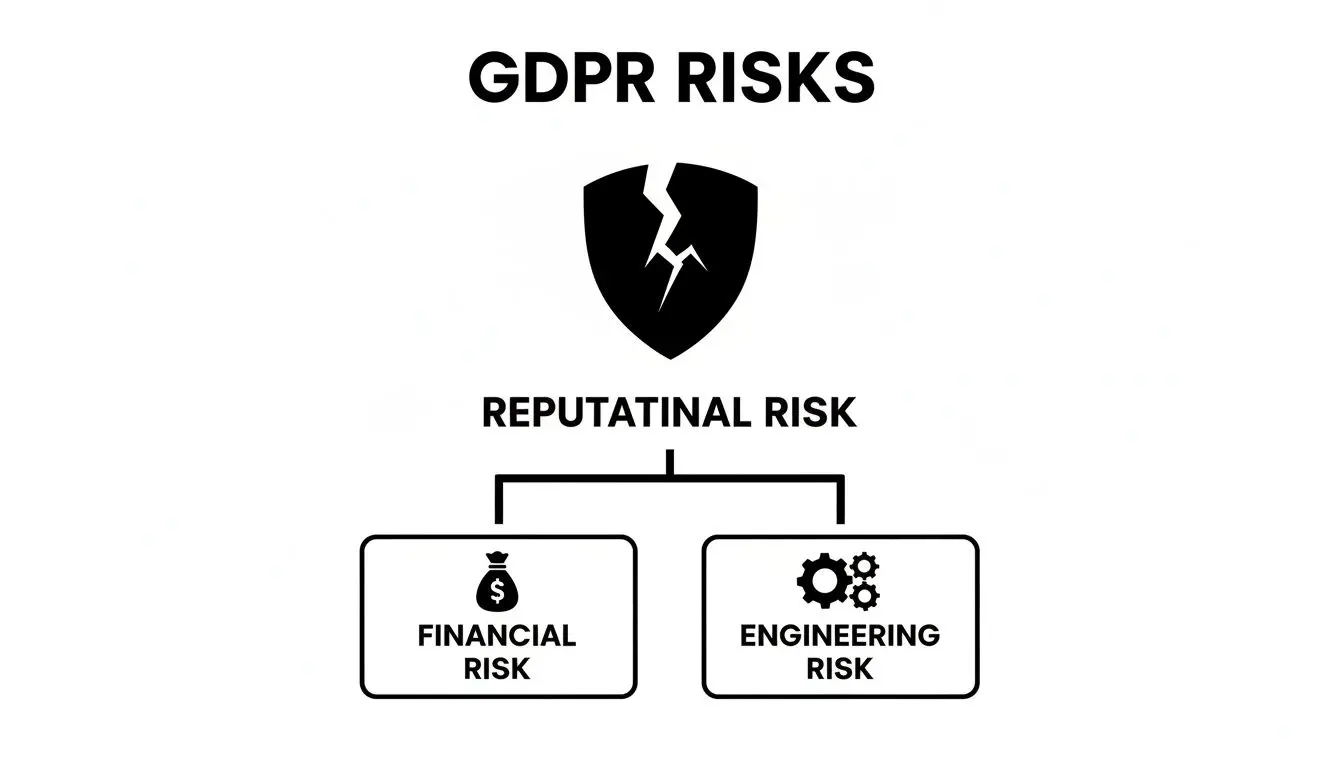
As this diagram illustrates, privacy failures result in direct financial and engineering costs, but the overarching reputational risk is often the most damaging and difficult to repair.
A common pitfall is to confuse a well-designed consent UI with genuine GDPR Privacy by Design. If the underlying architecture aggressively collects and retains data by default, no amount of front-end polish can fix the fundamental compliance failure. The system itself must be built on these principles.
Mastering these concepts is the first step toward building privacy-first software systems that are not just compliant, but architecturally sound.
Building Privacy into Your Software Architecture
Translating legal principles into robust software requires deliberate architectural decisions, not just the adoption of specific tools. Effective GDPR privacy by design is reflected in database schemas, API contracts, and inter-service communication patterns. The objective is to implement technical controls that make privacy an inherent, non-negotiable property of the system.
These controls are not mere compliance obligations; they contribute to more resilient, maintainable, and secure products. A system architected for privacy can handle data subject requests efficiently, minimizes its attack surface, and can adapt to new regulations without requiring a complete redesign.
Engineering True Data Minimisation
The most common failure in data minimisation is treating it as a front-end issue. A minimal UI form is ineffective if the backend architecture indiscriminately collects and stores data “just in case.” To be effective, minimisation must be enforced at the data model and persistence layers.
Consider a user profile service in a typical SaaS application. A naive implementation might use a single, wide users table with numerous nullable columns. A privacy-by-design approach would segregate data based on necessity and purpose.
- Authentication Table: Contains only the data essential for authentication (e.g.,
user_id,hashed_password,email). - Profile Table: Stores optional, user-provided data (e.g.,
display_name,bio), linked byuser_id. - Activity Logs: Are stored in a separate system, such as a time-series database, with strict, automated retention policies.
This architectural separation makes it structurally difficult to over-collect data and simplifies the implementation of data subject rights. For example, an erasure request can be fulfilled with a targeted DELETE on the Profile table without affecting core authentication records.
Choosing Between Pseudonymisation and Anonymisation
Engineers often use these terms interchangeably, but their distinction is critical under GDPR. Pseudonymisation involves replacing direct identifiers with a persistent but artificial identifier (e.g., a UUID). Crucially, the original identity can be restored using a separate, securely stored key. In contrast, anonymisation is an irreversible process that permanently severs the link to an individual.
The choice between these techniques depends entirely on the use case.
- Use Pseudonymisation for: Internal analytics, where you need to track user journeys without exposing personal identities to the analytics service. The link to the individual exists but is protected by strong access controls.
- Use Anonymisation for: Public data releases or training machine learning models where re-identification must be impossible. This often requires advanced techniques like k-anonymity or differential privacy.
For example, a product analytics pipeline could pseudonymise a user_id by hashing it with a secret salt before sending event data to a third-party service. This allows for user behavior analysis while restricting access to the user’s actual identity.
The primary risk is “pseudonymisation theatre”—using easily reversible masking techniques. A valid pseudonymisation strategy requires that the key linking the pseudonym to the individual is stored separately and protected by its own strict access controls. Without this segregation, the technique is merely obfuscation, not a compliant GDPR control.
Implementing Granular Access Controls
The Principle of Least Privilege is a foundational security concept that is central to privacy engineering. It dictates that any system component—a user or a microservice—should have access only to the minimum data required to perform its function.
Role-Based Access Control (RBAC) is a common starting point. You define roles (e.g., ‘SupportAgent’, ‘BillingAdmin’) and assign specific permissions to each. A SupportAgent might have read-only access to support tickets, while a BillingAdmin can modify subscription details.
In a microservices architecture, this principle extends to service-to-service communication. If an OrderProcessing service needs to verify a shipping address, it should request only the address fields from the UserProfile service, not the entire user profile. This is enforced at the API gateway or service mesh layer, limiting the “blast radius” of a compromised service and creating a clear, auditable trail of data access.
Navigating the Business Realities of Privacy by Design
While the architectural advantages are clear, implementing GDPR privacy by design involves practical trade-offs that impact project timelines, budgets, and feature roadmaps. Acknowledging these challenges allows leadership to frame compliance not as a constraint, but as a strategic investment in product quality and resilience.
One of the first impacts is on initial development velocity. Engineering teams must now incorporate privacy considerations at every stage, from data modeling to UI implementation. For example, building a granular consent management system is significantly more complex than a simple “accept all” banner, requiring more backend logic and front-end development, which extends initial timelines.
Similarly, effective data minimisation is not about removing a few form fields; it is about establishing an architectural discipline where every data element has a defined purpose and lifecycle. This upfront effort slows initial development but yields substantial long-term benefits by simplifying compliance and reducing the system’s attack surface.
The Financial and Operational Impact
Beyond development hours, there are direct costs associated with implementing privacy by design. These can include investments in privacy-enhancing technologies (PETs), more complex cloud infrastructure for data segregation, or dedicated engineering time for compliance activities like conducting a Privacy Impact Assessment (PIA). Our guide on the Privacy Impact Assessment process covers this in detail. These costs must be factored into project budgets.
The operational impact of GDPR is well-documented. A George Mason Law Review study on the impact of Europe’s privacy regulation on digital markets found that its rollout correlated with a one-third decrease in the number of available apps and a halving of the entry rate for new apps.
The same study noted that post-2018, EU firms experienced an 8% drop in profits and a 2% decrease in sales. Furthermore, analysis of cloud data showed that companies subject to GDPR reduced their data storage by 26% and processing by 15% compared to US counterparts. These statistics illustrate the tangible financial and operational adjustments required to comply with modern privacy regulations.
A naive approach views these costs as a burden. A strategic approach sees them as an investment in product quality and market resilience. A system architected for privacy is fundamentally more secure, more transparent, and better positioned to earn long-term user trust.
Balancing Innovation with Compliance
This creates a necessary tension between rapid innovation and compliant development. Product teams accustomed to data-driven iteration—collecting extensive data to analyze user behavior—must now operate with greater precision. The “move fast and break things” mantra is incompatible with a regulatory environment where every new feature processing personal data requires a privacy review.
This shift imposes constraints but also fosters more thoughtful and intentional product development. The guiding question changes from “What data can we collect?” to “What is the minimum data required for this feature to function effectively?” This constraint often stimulates more creative and efficient engineering solutions.
Consider these trade-offs from a strategic perspective:
- Slower Initial Launch vs. Reduced Technical Debt: Investing time in privacy architecture upfront prevents expensive, high-risk retrofitting projects later.
- Limited Data Collection vs. Higher-Quality Insights: Data collected with clear purpose and consent is often more meaningful and actionable than vast, uncurated datasets.
- Increased Upfront Cost vs. Lower Long-Term Risk: The cost of implementing robust encryption, anonymisation, and access controls is negligible compared to the potential fines and reputational damage of a data breach.
Ultimately, integrating GDPR privacy by design is a strategic decision. It acknowledges that in a market of privacy-aware consumers, trust is a critical feature. Building that trust is not a one-time task; it is a continuous commitment embedded in the product’s architecture.
Applying Privacy by Design in AI and LLM Systems
The integration of Artificial Intelligence (AI) and Large Language Models (LLMs) introduces a new class of privacy challenges. The data-intensive nature of these models often conflicts with core GDPR privacy by design principles like data minimisation and purpose limitation.
A naive implementation can result in a model that memorises and inadvertently discloses sensitive user data. An AI trained on raw customer support transcripts could, for example, reveal a user’s personal details in response to an unrelated query from another user. This is not a hypothetical risk; it is a severe data breach scenario caused by a failure to embed privacy controls into the AI lifecycle.
Mitigating Data Exposure in Model Training
The first line of defense is rigorous control over training data. Using raw production data for model training is a high-risk activity. Instead, engineering teams should implement a layered strategy to de-risk this phase.
Practical technical solutions include:
- Synthetic Data Generation: Instead of using real user data, generate structurally identical but entirely artificial datasets. This allows the model to learn statistical patterns without exposure to personally identifiable information (PII).
- Robust Anonymisation and Pseudonymisation: Before any data enters the training pipeline, it must be scrubbed of identifiers using techniques that are difficult or impossible to reverse. This goes beyond simple redaction.
- Data Minimisation by Design: Critically evaluate the necessity of every data point. Does the model require a user’s name, or is a pseudonymised ID sufficient? Architect data pipelines to feed the model only the absolute minimum data required for its task.
Engineering Safeguards for Live Systems
Once a model is deployed, the risk profile shifts from training data to real-time inputs and outputs. At this stage, engineering controls are non-negotiable for maintaining GDPR privacy by design.
A critical component is the implementation of prompt and output guardrails. These are software layers that inspect data before it reaches the LLM and before it is returned to the user. Input guardrails detect and strip PII from user prompts, preventing sensitive data from being processed or logged. Output guardrails scan the model’s responses to ensure they do not contain regurgitated sensitive information.
For instance, a customer service chatbot should be engineered to automatically filter credit card numbers from user queries before they are sent to the LLM. The model’s response should be similarly scanned to prevent the disclosure of other users’ data.
The notion that AI innovation and privacy are mutually exclusive is a false dichotomy. Well-implemented privacy frameworks create the necessary boundaries for safe and trustworthy AI development. In this context, compliance becomes an enabler of responsible innovation, not a blocker.
Ensuring Transparency and Human Oversight
Under GDPR, individuals have rights regarding automated decision-making. If an AI system makes decisions with significant effects on users (e.g., credit scoring, hiring), transparency and the potential for human review are required.
This means the system architecture must support:
- Explainability: The ability to explain, in understandable terms, the basis for a model’s decision. This requires logging key inputs and logic to create an auditable trail.
- Human-in-the-Loop (HITL) Workflows: For high-stakes decisions, the system must be designed to flag edge cases or low-confidence outputs for review by a human. This is both a compliance requirement and a critical quality control measure.
A 2020 European Parliament study on the findings on GDPR and AI innovation641530_EN.pdf) concluded that GDPR’s principles, such as data minimisation and risk mitigation, are compatible with and can even encourage responsible AI development. By treating privacy as an architectural pillar, teams can build powerful AI systems that earn user trust and withstand regulatory scrutiny.
An Actionable Checklist for Your Development Lifecycle
Integrating GDPR privacy by design into practice requires a systematic approach embedded throughout the software development lifecycle (SDLC). This is not a one-time audit but a continuous discipline.
This checklist provides a framework for embedding data protection at each stage, making privacy an architectural pillar rather than a late-stage patch.
Discovery and Design Phase
Before any code is written, this is where the purpose and legal basis for data processing are established. Errors at this stage create compliance debt, which is far more costly to remedy than technical debt.
- Conduct a Data Protection Impact Assessment (DPIA): For any new feature that processes personal data at scale or involves sensitive information, a DPIA is a mandatory risk assessment to identify and mitigate privacy risks proactively.
- Map All Data Flows: Create and maintain data flow diagrams that serve as a single source of truth, detailing what personal data is collected, where it is stored, which services process it, and its final disposition.
- Define a Lawful Basis for Processing: Document the lawful basis under GDPR (e.g., consent, legitimate interest) for every data element processed. If collection cannot be justified, do not collect it.
Development and Implementation Phase
This is where architectural principles are translated into code. The focus is on implementing technical controls that automatically enforce privacy policies.
- Enforce Data Minimisation: Ensure database schemas and API contracts include only fields that are strictly necessary for the feature’s functionality.
- Implement Strong Encryption: Use current, robust encryption standards for all personal data, both in transit (e.g., TLS 1.3) and at rest (e.g., AES-256).
- Build Robust Access Controls: Implement Role-Based Access Control (RBAC) and attribute-based controls to enforce the principle of least privilege for both internal users and microservices.
- Create Audit Logs: Implement immutable logging for all access to or modification of personal data to ensure a clear, auditable trail for security and compliance reviews.
A critical implementation detail is making privacy controls difficult to disable inadvertently. The system architecture should make the secure and compliant path the easiest path for developers.
Testing and QA Phase
Testing must extend beyond functional correctness to include actively probing for privacy vulnerabilities. Data protection should be treated as a core quality metric.
- Develop Privacy-Specific Test Cases: Write automated tests to verify that access controls are correctly enforced and that data erasure requests completely remove all traces of a user’s data from all relevant systems.
- Use Anonymised or Synthetic Data: Enforce a strict policy against using real customer data in staging or testing environments.
Deployment and Maintenance Phase
Privacy obligations are ongoing. Continuous monitoring and regular reviews are necessary to manage new risks and adapt to product changes.
- Establish a Data Breach Response Plan: Maintain and regularly rehearse a clear, actionable plan for detecting, reporting, and mitigating a data breach.
- Schedule Periodic Privacy Reviews: Re-evaluate data maps and DPIAs at least annually or whenever significant system changes are made. For a deeper look at the other side of this mandate, review our guide on implementing Privacy by Default under GDPR.
Frequently Asked Questions
What’s the Difference Between Privacy by Design and a DPIA?
Privacy by Design and a Data Protection Impact Assessment (DPIA) are related but distinct concepts. Privacy by Design is the overarching strategic approach—the philosophy of embedding data protection into the entire lifecycle of a system.
A DPIA is a specific, formal risk assessment tool used to implement that philosophy for a particular high-risk processing activity. For example, if you are launching a new AI-powered feature that analyzes user behavior, you would conduct a DPIA for that specific project.
In an analogy, Privacy by Design is the building’s comprehensive fire safety code. The DPIA is the mandatory inspection conducted by the fire marshal before opening a new, high-risk area like a chemistry lab. The inspection is a tactical execution of the overall safety strategy.
Does Implementing Privacy by Design Slow Down Development?
Yes, it can add time to the initial stages of development. It requires more upfront planning, architectural design, and documentation, which may feel like a reduction in velocity during early sprints.
However, this initial investment prevents significant delays and costs later. A proactive approach dramatically reduces long-term technical and compliance debt, averts last-minute “fire drills” to fix compliance issues, and eliminates the need for expensive, high-risk projects to retrofit privacy into a live system. Over the long term, this leads to more resilient and maintainable products, ultimately enabling faster, more sustainable growth.
Can a Small Startup Realistically Implement Privacy by Design?
Yes, and in fact, it is the most efficient and cost-effective approach for a startup. Implementing Privacy by Design from the outset is far less expensive and complex than re-architecting a flawed system after achieving product-market fit and accumulating significant user data.
For a startup, this means making sound foundational decisions: collect only the data you absolutely need for your core value proposition, implement strong encryption from day one, enforce strict access controls, and carefully vet third-party vendors for their security and privacy practices. These early architectural choices establish a compliant and scalable foundation that mitigates future risk and cost.