
A Privacy Impact Assessment (PIA) is not a compliance checkbox. It is an architectural stress test for data handling processes—a systematic method for identifying, evaluating, and mitigating privacy risks before they become embedded in a new project, system, or software feature.
What Is a Privacy Impact Assessment and Why It Matters
At its core, a PIA is a risk management tool. It compels teams to make conscious, documented decisions about personal data processing, forcing a confrontation with potential privacy failures before they are locked into the software architecture.
This is fundamentally different from a security audit. A security audit focuses on protecting systems from external threats and unauthorized access. A PIA, in contrast, scrutinizes the impact of legitimate data processing on individuals. It asks a different set of questions: not just “can we protect this data?” but “should we collect this data?” and “what are the potential negative consequences for the individuals whose data this is?”
A Proactive Approach to Risk
Consider how engineers design a bridge. They don’t simply build it and hope it withstands traffic. They conduct rigorous stress tests, analyzing load capacities and material resilience to identify structural weaknesses before the bridge opens.
A PIA applies the same discipline to data flows. It proactively tests a system’s design against potential privacy failures, shifting the organization from a reactive “breach and fix” posture to a proactive “design and prevent” methodology. This is the essence of Privacy by Design—treating privacy as a non-negotiable architectural requirement, not an afterthought.
The Technical Debt of Neglecting PIAs
For CTOs and product leaders, omitting a PIA or conducting a superficial one generates significant technical and business debt. Retrofitting privacy controls into a live system is exponentially more complex and costly than designing them from the outset.
A poorly architected data process can lead to severe operational problems:
- Costly Rework: Engineering teams may be forced to re-architect entire data pipelines to satisfy legal requirements discovered post-launch.
- Reputational Damage: A privacy failure erodes user trust more rapidly and deeply than a functional bug, directly impacting adoption and retention.
- Regulatory Fines: Non-compliance with regulations like GDPR can result in fines measured in millions of euros.
A PIA mandates justification for every piece of personal data collected, every processing activity, and every third-party integration. This disciplined approach not only mitigates compliance risk but often results in leaner, more efficient, and more maintainable systems.
Ultimately, a well-executed PIA is a strategic investment in building resilient, trustworthy software that respects users—a critical differentiator in the modern digital economy.
Regulatory Drivers for Privacy Impact Assessments
A Privacy Impact Assessment is not merely a best practice; in many jurisdictions, it is a legal requirement. For any organization building software that processes personal data, understanding these regulations is fundamental to market access, product design, and risk management. These legal frameworks translate abstract privacy principles into concrete engineering and compliance obligations.
GDPR and the “High-Risk” Processing Trigger
The EU’s General Data Protection Regulation (GDPR) is a dominant force in this domain. It explicitly mandates a Data Protection Impact Assessment (DPIA)—the GDPR’s term for a PIA—under specific circumstances.
GDPR does not require a DPIA for all data processing. Instead, it targets activities deemed “high-risk” to the rights and freedoms of individuals, focusing scrutiny where the potential for harm is greatest.
When Does GDPR Mandate a DPIA?
Article 35 of the GDPR requires a DPIA whenever processing is “likely to result in a high risk.” Regulatory guidance has clarified what this means in practice. A DPIA is generally required when a system involves:
- Systematic and extensive evaluation of personal aspects: This includes profiling and automated decision-making with legal or similarly significant effects. A common example is an AI model used for credit scoring or automated resume screening.
- Large-scale processing of special categories of data: This covers sensitive information such as health records, genetic data, biometrics for unique identification, or data revealing racial origin, political opinions, or religious beliefs.
- Systematic monitoring of a publicly accessible area on a large scale: For instance, using AI-powered video analytics in a public space to track crowd behavior.
The penalties for non-compliance are severe. Failure to conduct a required DPIA can lead to fines of up to €10 million or 2% of global annual turnover, whichever is higher. For guidance on navigating these requirements, learn more about the role of a Data Protection Officer in our dedicated article.
The Evolving Landscape of US Privacy Laws
The United States lacks a single federal privacy law equivalent to GDPR. Instead, a growing patchwork of state-level legislation is creating a complex compliance map where PIAs are becoming standard practice.
Privacy Impact Assessments have become a critical compliance tool in the United States, driven by a wave of state-level privacy laws mandating them for high-risk processing activities.
The California Privacy Rights Act (CPRA) is a key driver. CPRA regulations mandate formal risk assessments for processing that presents a “significant risk” to consumer privacy. This is particularly relevant for AI development, as it specifically calls out the use of Automated Decision-Making Technology (ADMT). These assessments must evaluate risks related to fairness and bias, not just data protection.
From the EU to California, the regulatory trend is clear: organizations are expected to proactively identify and mitigate privacy risks before they cause harm. The PIA is the essential instrument for meeting this expectation.
Integrating the PIA into the Software Development Lifecycle
Treating a PIA as a final, pre-deployment checkbox negates its value. Its true utility is realized when integrated into the software development lifecycle (SDLC) from the start, triggered by specific, predictable events. When implemented this way, a PIA transforms from a compliance hurdle into a strategic tool for building more robust and trustworthy systems. This is the practical application of Privacy by Design.
Vague advice like “start early” is insufficient. Engineering and product teams require clear, actionable triggers that define precisely when a PIA is necessary. Embedding these triggers into existing workflows, such as sprint planning or architectural reviews, prevents the accumulation of privacy-related technical debt.
Key Triggers for Initiating a PIA
Certain technical and business changes invariably introduce new privacy considerations that warrant a formal assessment. Recognizing these triggers is the first step toward systematic privacy governance. The following table outlines common events that should trigger a PIA.
Common Triggers for a Privacy Impact Assessment
| Trigger Event | Description | Example Scenario |
|---|---|---|
| New Product or System Launch | Any new system that collects, processes, or stores personal data requires a foundational PIA. | A company builds a new mobile app that requires user registration and processes location data. |
| Integration of a New AI Model | Introducing AI for profiling or automated decisions creates unique risks related to bias, fairness, and data usage. | An e-commerce platform deploys a machine learning model to personalize product recommendations based on browsing history. |
| Change in Data Processing Purpose | Repurposing existing personal data for a new use case requires a fresh assessment to ensure legitimacy and fairness. | Customer support chat logs, originally collected for quality assurance, are used to train a new sales-focused large language model (LLM). |
| Adoption of New Technology or Vendors | Integrating a third-party service that will handle personal data requires a review of its privacy implications. | A development team decides to migrate user authentication data from an on-premise database to a new cloud-based Identity-as-a-Service (IDaaS) platform. |
| Expansion into a New Jurisdiction | Entering a market with different privacy laws (e.g., GDPR, CPRA) often mandates specific PIA requirements. | A US-based SaaS company begins marketing its services to customers in the European Union. |
A Practical Decision Framework
Not every feature change requires a full-scale PIA. Overburdening teams with unnecessary process leads to circumvention. A lightweight decision-making framework is needed to distinguish between major changes requiring a deep dive and minor ones that do not.
The objective is to right-size the assessment to the risk. A major architectural change involving sensitive data warrants a comprehensive PIA, whereas a minor UI update that does not alter data handling might only require a quick check against established privacy principles.
To implement this, integrate a simple screening questionnaire into sprint planning or feature scoping:
- Does this change involve collecting new categories of personal data?
- Will existing data be used for a new purpose not previously disclosed to users?
- Are we sharing data with a new third party or external system?
- Does this feature involve automated decision-making with a potentially significant impact on an individual?
An affirmative answer to any of these questions indicates that a formal PIA is warranted. This simple checklist embeds privacy considerations directly into development sprints, making it a natural component of software engineering.
The Core Components of an Effective PIA
A proper Privacy Impact Assessment is not a form-filling exercise. It is a structured investigation into a system’s data architecture. For engineering and product teams, a clear blueprint is essential for conducting a meaningful PIA.
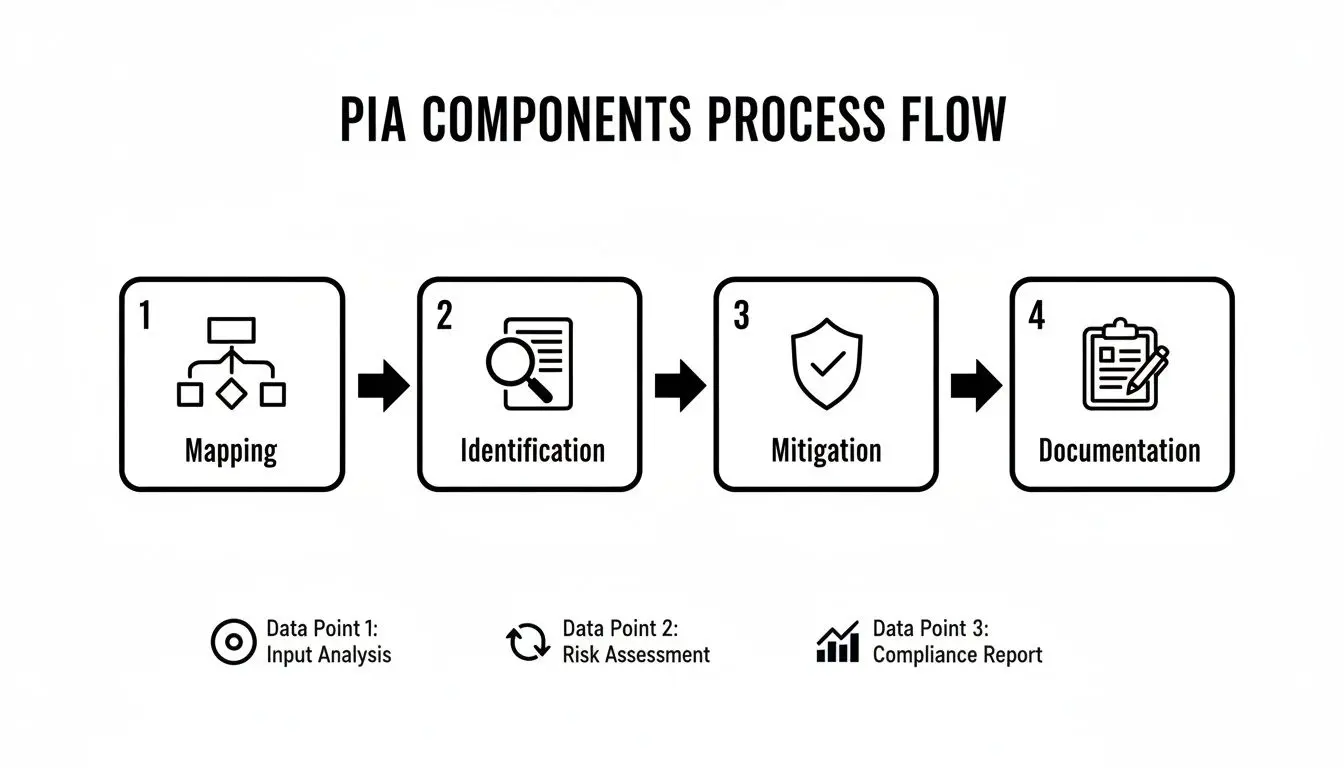
Think of it as an architectural inspection. One would not approve a new building with a cursory glance; one would inspect the foundations, structural integrity, electrical systems, and fire safety measures. A PIA applies the same systematic rigor to data processing. An effective PIA is built on four pillars: data flow mapping, risk identification, mitigation strategy, and comprehensive documentation.
Stage 1: Data Flow Mapping
Before analyzing risks, you must have a precise understanding of how personal data moves through your system. This is the foundation; a superficial mapping will weaken the entire assessment. Data flow mapping is the process of documenting every data touchpoint.
The goal is to answer fundamental questions with high precision:
- Collection: What specific personal data is being collected? From what sources?
- Processing: How is this data being used? Is it an input for an AI model, used for automated decisions, or simply transformed?
- Storage: Where is the data stored (e.g., which cloud provider, geographic region)? What are the security and retention policies?
- Sharing: Is data shared with third-party services, APIs, or vendors? If so, what data is transferred, and for what purpose?
A data flow diagram (DFD) is often the most effective tool for this stage. It provides a clear, shared understanding for both technical and non-technical stakeholders and frequently exposes undocumented data pathways or incorrect assumptions.
Stage 2: Risk Identification and Analysis
With a clear data map, the next step is to identify potential privacy threats. This requires thinking beyond external attacks to consider how legitimate processing could harm individuals.
A practical categorization of privacy threats includes:
- Unauthorized Access: The risk of data being accessed by unauthorized systems or personnel, both internal and external.
- Data Leakage: The accidental exposure of data due to misconfigured infrastructure, application vulnerabilities, or insecure transfer protocols.
- Re-identification: The risk that anonymized or pseudonymized data could be combined with other datasets to identify specific individuals.
- Algorithmic Bias: A critical risk in AI systems where models produce unfair or discriminatory outcomes for certain demographic groups, often due to biased training data.
The most critical aspect of this stage is not just listing threats but analyzing their likelihood and potential impact. A minor data exposure on a test system has a vastly different risk profile than systemic bias in a credit-scoring algorithm.
Stage 3: Risk Mitigation Strategies
Once risks are identified and prioritized, the focus shifts to designing and implementing controls to reduce them to an acceptable level. This is where the principles of Privacy by Design transition from theory to concrete architectural choices. Learn more about embedding these principles in our guide on implementing Privacy by Design.
Mitigation controls typically fall into these categories:
- Technical Controls: Implemented directly in software and infrastructure. Examples include end-to-end encryption, data pseudonymization, role-based access control (RBAC) based on the principle of least privilege, and data minimization techniques.
- Procedural Controls: Policies and processes that govern human interaction with data. Examples include strict internal access policies, mandatory privacy training for developers, and robust incident response plans.
- Architectural Solutions: Fundamental design decisions that inherently reduce risk. Examples include adopting a decentralized data architecture or using privacy-enhancing technologies (PETs) like federated learning.
Stage 4: Documentation and Reporting
The final component is creating a clear, auditable record of the entire process. The PIA report is not merely a summary; it is the evidence that demonstrates due diligence. This document serves as a defense against regulatory scrutiny and as a living reference for the team.
Comprehensive documentation must capture:
- A description of the data flows and processing activities.
- The privacy risks identified and their severity ratings.
- The mitigation measures implemented and the rationale for their selection.
- Any residual risks that were formally accepted, along with the business justification.
- Sign-offs from key stakeholders, such as the DPO, legal counsel, and the lead engineer.
This documented output transforms the PIA from a one-time project into a valuable asset for ongoing governance, ensuring privacy remains a core consideration as the system evolves.
A Step-by-Step Workflow for Your PIA Process
A structured, repeatable workflow is essential for translating PIA theory into practice. A Privacy Impact Assessment is not a singular task but a process that convenes technical, product, and legal expertise to make defensible decisions about data. Its real value is realized when this workflow is integrated into existing development cycles, such as Agile or DevOps. This integration makes privacy a core component of building reliable software, not a compliance burden.
This workflow deconstructs the PIA into discrete stages, from initial analysis and data gathering to risk mitigation and continuous oversight.
The sequence is critical: data mapping must precede risk identification, which in turn must precede the design of mitigation measures and final documentation.
Stage 1: Threshold Analysis
This initial step functions as a gatekeeper. Not every minor code change or feature update requires a full-scale PIA. The objective is to quickly determine if a formal assessment is necessary.
This screening is typically performed by the Product Manager during feature ideation or sprint planning, using a concise checklist:
- Are we collecting a new type of personal data?
- Are we using existing data for a new purpose?
- Will we share data with a new third-party vendor?
- Does this feature involve automated decision-making with a significant impact on individuals?
An affirmative answer to any of these questions triggers a full PIA. This approach avoids unnecessary administrative overhead and concentrates effort where the risk is highest.
Stage 2: Collaborative Information Gathering
Once a PIA is triggered, the focus shifts to detailed information collection. This is a collaborative effort.
The Lead Engineer maps the technical implementation—data flows, storage locations, and security controls. The Product Manager provides the business context—the purpose of the processing and the value it delivers. The Data Protection Officer (DPO) or legal counsel provides the regulatory framework, ensuring the processing has a valid legal basis under applicable laws like GDPR. This collaborative phase ensures the PIA is grounded in both technical reality and legal obligations.
Stage 3: Risk Analysis and Evaluation
With all information gathered, the team identifies potential privacy threats. This analysis extends beyond security vulnerabilities to include risks to individuals, such as re-identification of anonymized data or the introduction of algorithmic bias.
Each identified risk is then scored against two factors:
- Likelihood: The probability of the risk materializing.
- Impact: The severity of harm to individuals if the risk materializes.
This analysis, often led by the DPO with input from engineering, produces a prioritized list of concerns. A risk of systemic bias in an AI-driven hiring tool will correctly score much higher than a minor data exposure in a sandboxed test environment.
Stage 4: Mitigation Planning and Implementation
This stage involves designing and implementing controls to reduce high-priority risks to an acceptable level. This is the Lead Engineer’s domain, translating privacy requirements into concrete technical solutions.
A common failure is treating mitigation as a post-development addition. True Privacy by Design embeds controls into the system’s architecture—choosing pseudonymization over plaintext by default, implementing granular access controls, and building data minimization into the core logic.
Mitigation can be technical (e.g., end-to-end encryption), procedural (e.g., a new access policy), or architectural (e.g., using federated learning to avoid data centralization).
Stage 5: Reporting and Sign-Off
The entire process is documented in a formal PIA report. This document is an auditable record of due diligence, detailing the data flows, identified risks, implemented mitigations, and any residual risks that the business has formally accepted.
The DPO, Product Manager, and Lead Engineer must review and sign off on the report, establishing clear accountability and providing critical evidence of compliance for regulators.
Stage 6: Continuous Monitoring and Review
A PIA is a snapshot in time, not a static document. As the product evolves, so do its privacy implications.
The PIA must be treated as a living document, reviewed and updated periodically—at least annually, or whenever a significant change is made to data processing activities. This ongoing monitoring ensures the organization’s privacy posture remains robust and the PIA remains an accurate, useful governance tool.
Adapting the PIA for AI and Machine Learning Systems
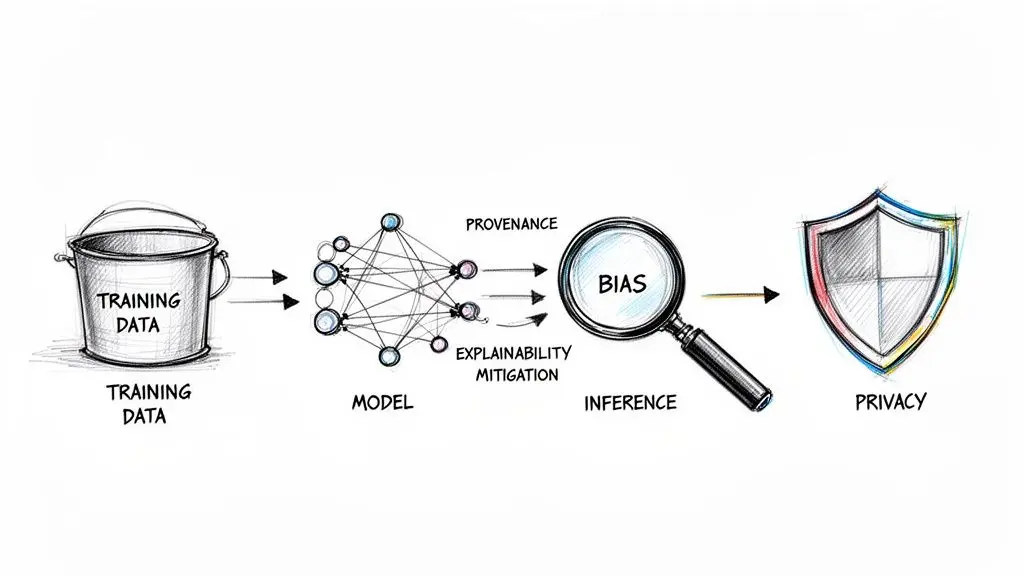
Conducting a Privacy Impact Assessment for an AI or machine learning system introduces unique complexities that a traditional PIA is ill-equipped to handle. Standard assessments focus on data flows and storage policies, but AI models introduce a distinct layer of risk rooted in algorithmic behavior, model opacity, and the potential for discriminatory outcomes.
For an AI system, a PIA must extend beyond simple data inventories to scrutinize the entire model lifecycle, from the provenance and quality of training data to the internal logic of the model and the downstream impact of its predictions.
Beyond Standard Data Privacy Checks
A traditional PIA answers questions like, “Is this data encrypted?” or “Do we have consent?” With AI, the necessary questions are fundamentally different and probe algorithmic risk:
- Algorithmic Bias: Does the training data contain historical biases that the model will learn and amplify, leading to unfair outcomes?
- Model Explainability: If the model denies an individual a service, can we explain why? An opaque “black box” model represents a significant privacy and ethical liability.
- Data Provenance: Is there a clear, auditable trail for the training data? Using poorly sourced or low-quality data can introduce deep-seated flaws that are difficult to remediate.
- Inference Risks: What new, potentially sensitive information can the model infer about individuals, even from non-sensitive input data?
An effective AI-focused PIA merges data protection principles with AI ethics and fairness reviews. It is less a compliance exercise and more a governance framework for building responsible technology.
Unifying Governance Models
The need for a broader, integrated assessment is increasingly recognized. Research indicates that while 92% of organizations understand the need to build customer trust in AI, their processes often lag. For example, while 60% conduct AI impact assessments in parallel with privacy reviews, only 49% have integrated them into a single, cohesive process.
This gap between awareness and implementation is a primary source of risk. To close it, engineering and product leaders need a unified governance framework. The PIA should not be a separate workstream from an AI ethics review; they should be components of a single, holistic assessment that evaluates risk from all angles.
This unified approach ensures privacy is not an afterthought but a core consideration in how you design, build, and operate intelligent systems—ensuring your AI is compliant, fair, transparent, and trustworthy.
Frequently Asked Questions About PIAs
This section addresses common, practical questions from technical and product leaders tasked with implementing a Privacy Impact Assessment.
How do PIAs fit into an Agile development environment?
A PIA should not be a monolithic, waterfall-style report. In an Agile context, it must be an iterative, living process. You begin with a foundational PIA during initial product design to map core data flows and identify high-level risks. Subsequently, you integrate smaller, focused PIAs or privacy checks into sprint planning. Any new feature that alters data processing undergoes a targeted review. This approach allows the PIA to evolve with the product, keeping privacy a central concern without impeding development velocity.
What is the difference between a PIA and a security audit?
While related, they address distinct problems. A security audit is focused on defense. It asks, “Can we protect our systems and data from unauthorized access, breaches, and external threats?” Its primary concern is system integrity and confidentiality.
A Privacy Impact Assessment deals with the risks arising from your legitimate, authorized use of personal data. It asks a more fundamental question: “What harm could our intended data processing cause to individuals, even if our security is perfect?” A system can be perfectly secure yet still pose a significant privacy risk due to its design or purpose.
What level of technical detail is required?
A PIA must balance technical depth with accessibility. It must be detailed enough for a technical reviewer to validate the data architecture but clear enough for a non-technical stakeholder, such as a legal advisor or DPO, to understand the privacy implications.
The following technical details are non-negotiable:
- The specific data points being collected.
- Data storage locations, including cloud providers and geographic regions.
- Encryption methods used, both in transit and at rest.
- A complete list of third-party services or APIs that receive personal data.
The objective is not mere inventory but providing sufficient evidence to justify your risk assessment. Vague statements like “user data is stored in the cloud” are inadequate for a meaningful privacy impact assessment.
A robust Privacy Impact Assessment is a cornerstone of building trustworthy, compliant software. At Devisia, we embed privacy into every stage of the development lifecycle, from pragmatic architecture to long-term maintenance. Discover how we build reliable digital products at https://www.devisia.pro.