
Un Privacy Impact Assessment (PIA) non è una casella da spuntare per la conformità. È un test di stress architetturale per i processi di gestione dei dati—un metodo sistematico per identificare, valutare e mitigare i rischi per la privacy prima che diventino parte integrante di un nuovo progetto, sistema o funzionalità software.
Che cos’è un Privacy Impact Assessment e perché è importante
Alla base, una PIA è uno strumento di gestione del rischio. Costringe i team a prendere decisioni consapevoli e documentate sul trattamento dei dati personali, costringendo a confrontarsi con potenziali fallimenti in materia di privacy prima che vengano vincolati nell’architettura software.
Questo è fondamentalmente diverso da un audit di sicurezza. Un audit di sicurezza si concentra sulla protezione dei sistemi da minacce esterne e accessi non autorizzati. Una PIA, al contrario, esamina l’impatto del trattamento legittimo dei dati sulle persone. Pone un insieme diverso di domande: non solo “possiamo proteggere questi dati?” ma “dovremmo raccogliere questi dati?” e “quali sono le potenziali conseguenze negative per le persone a cui appartengono questi dati?”
Un approccio proattivo al rischio
Considerate come gli ingegneri progettano un ponte. Non lo costruiscono semplicemente e sperano che regga il traffico. Eseguono test di resistenza rigorosi, analizzando le capacità di carico e la resilienza dei materiali per individuare i punti deboli strutturali prima dell’apertura del ponte.
Una PIA applica la stessa disciplina ai flussi di dati. Testa in modo proattivo il design di un sistema contro potenziali fallimenti in termini di privacy, spostando l’organizzazione da una posizione reattiva di “indagine e riparazione” a una metodologia proattiva di “progettare e prevenire”. Questa è l’essenza di Protezione della privacy fin dalla progettazione—trattare la privacy come un requisito architetturale non negoziabile, non come un ripensamento.
Il debito tecnico derivante dalla trascuratezza delle PIA
Per i CTO e i responsabili di prodotto, omettere una PIA o condurre una valutazione superficiale genera un significativo debito tecnico e commerciale. Integrare retroattivamente controlli per la privacy in un sistema in produzione è esponenzialmente più complesso e costoso che progettarli fin dall’inizio.
Un processo di gestione dati mal progettato può portare a gravi problemi operativi:
- Rifacimenti costosi: i team di ingegneria potrebbero essere costretti a riprogettare intere pipeline di dati per soddisfare requisiti legali scoperti dopo il lancio.
- Danno reputazionale: un fallimento in termini di privacy erode la fiducia degli utenti più rapidamente e profondamente di un bug funzionale, influenzando direttamente adozione e fidelizzazione.
- Sanzioni normative: la non conformità a regolamenti come il GDPR può comportare multe misurate in milioni di euro.
Una PIA richiede la giustificazione per ogni dato personale raccolto, per ogni attività di trattamento e per ogni integrazione con terze parti. Questo approccio disciplinato non solo mitiga il rischio di conformità, ma spesso porta a sistemi più snelli, efficienti e manutenibili.
In definitiva, una PIA ben eseguita è un investimento strategico per costruire software resilienti e affidabili che rispettano gli utenti—un differenziatore critico nell’economia digitale moderna.
Driver normativi per le Privacy Impact Assessment
Una Privacy Impact Assessment non è semplicemente una best practice; in molte giurisdizioni è un requisito legale. Per qualsiasi organizzazione che sviluppi software che tratta dati personali, comprendere questi regolamenti è fondamentale per l’accesso al mercato, il design del prodotto e la gestione del rischio. Questi quadri legali traducono principi astratti di privacy in obblighi concreti per ingegneria e conformità.
GDPR e il criterio di trattamento “ad alto rischio”
Il Regolamento generale sulla protezione dei dati (GDPR) dell’UE è una forza dominante in questo ambito. Esso obbliga esplicitamente a una Data Protection Impact Assessment (DPIA)—il termine GDPR per una PIA—in circostanze specifiche.
Il GDPR non richiede una DPIA per tutti i trattamenti dei dati. Piuttosto, prende di mira attività considerate “ad alto rischio” per i diritti e le libertà delle persone, indirizzando il controllo dove il potenziale di danno è maggiore.
Quando il GDPR impone una DPIA?
L’articolo 35 del GDPR richiede una DPIA ogni volta che il trattamento è “probabilmente destinato a comportare un alto rischio”. Le linee guida regolamentari hanno chiarito cosa significhi questo nella pratica. Generalmente una DPIA è richiesta quando un sistema comporta:
- Valutazione sistematica ed estesa di aspetti personali: questo include il profiling e le decisioni automatizzate con effetti legali o simili di rilievo. Un esempio comune è un modello di IA utilizzato per il punteggio creditizio o per il screening automatico dei curricula.
- Trattamento su larga scala di categorie particolari di dati: questo riguarda informazioni sensibili come cartelle cliniche, dati genetici, dati biometrici per identificazione univoca o dati che rivelano origine razziale, opinioni politiche o convinzioni religiose.
- Monitoraggio sistematico di un’area accessibile al pubblico su larga scala: per esempio, l’uso di analisi video alimentate dall’IA in uno spazio pubblico per tracciare il comportamento delle folle.
Le sanzioni per la non conformità sono severe. La mancata esecuzione di una DPIA richiesta può comportare multe fino a 10 milioni di euro o il 2% del fatturato annuo mondiale, a seconda di quale importo sia maggiore. Per indicazioni su come districarsi tra questi requisiti, scoprite di più sul ruolo di un Responsabile della protezione dei dati nel nostro articolo dedicato.
Il panorama normativo in evoluzione delle leggi sulla privacy negli Stati Uniti
Gli Stati Uniti non hanno una singola legge federale sulla privacy equivalente al GDPR. Al suo posto, un mosaico crescente di normative a livello statale sta creando una mappa di conformità complessa in cui le PIA stanno diventando prassi standard.
Le Privacy Impact Assessment sono diventate uno strumento critico di conformità negli Stati Uniti, spinte da un’ondata di leggi statali sulla privacy che le impongono per attività di trattamento ad alto rischio.
La California Privacy Rights Act (CPRA) è un driver chiave. Le normative CPRA obbligano valutazioni formali del rischio per i trattamenti che presentano un “rischio significativo” per la privacy dei consumatori. Questo è particolarmente rilevante per lo sviluppo di tecnologie di IA, poiché la legge richiama specificamente l’uso di Automated Decision-Making Technology (ADMT). Queste valutazioni devono analizzare i rischi relativi a equità e bias, non solo la protezione dei dati.
Dall’UE alla California, la tendenza normativa è chiara: ci si aspetta che le organizzazioni identifichino e mitigino proattivamente i rischi per la privacy prima che causino danni. La PIA è lo strumento essenziale per soddisfare questa aspettativa.
Integrare la PIA nel ciclo di vita dello sviluppo software
Considerare una PIA come una casella finale da spuntare prima del deployment ne annulla il valore. La sua vera utilità si realizza quando è integrata nel ciclo di vita dello sviluppo software (SDLC) fin dall’inizio, attivata da eventi specifici e prevedibili. Implementata in questo modo, una PIA si trasforma da un ostacolo di conformità in uno strumento strategico per costruire sistemi più robusti e affidabili. Questa è l’applicazione pratica della Protezione della privacy fin dalla progettazione.
Consigli vaghi come “iniziare presto” sono insufficienti. I team di ingegneria e di prodotto necessitano di trigger chiari e operativi che definiscano esattamente quando una PIA è necessaria. Incorporare questi trigger nei flussi di lavoro esistenti, come la pianificazione degli sprint o le review architetturali, previene l’accumulo di debito tecnico legato alla privacy.
Trigger chiave per l’avvio di una PIA
Certi cambiamenti tecnici e commerciali introducono inevitabilmente nuove considerazioni in termini di privacy che richiedono una valutazione formale. Riconoscere questi trigger è il primo passo verso una governance della privacy sistematica. La tabella seguente delinea gli eventi comuni che dovrebbero attivare una PIA.
Trigger comuni per una Privacy Impact Assessment
| Trigger Event | Description | Example Scenario |
|---|---|---|
| Lancio di un nuovo prodotto o sistema | Qualsiasi nuovo sistema che raccoglie, tratta o memorizza dati personali richiede una PIA fondamentale. | Un’azienda sviluppa una nuova app mobile che richiede la registrazione degli utenti e tratta dati di posizione. |
| Integrazione di un nuovo modello di IA | Introdurre l’IA per profiling o decisioni automatizzate crea rischi unici legati a bias, equità e utilizzo dei dati. | Una piattaforma di e-commerce distribuisce un modello di machine learning per personalizzare le raccomandazioni di prodotto in base alla cronologia di navigazione. |
| Cambio dello scopo del trattamento dei dati | Riutilizzare dati personali esistenti per un nuovo caso d’uso richiede una nuova valutazione per garantire legittimità e correttezza. | I log delle chat del supporto clienti, raccolti originariamente per assicurare la qualità, vengono usati per addestrare un nuovo modello linguistico di grandi dimensioni (LLM) orientato alle vendite. |
| Adozione di nuove tecnologie o fornitori | Integrare un servizio di terze parti che gestirà dati personali richiede una revisione delle sue implicazioni sulla privacy. | Un team di sviluppo decide di migrare i dati di autenticazione degli utenti da un database on-premise a una nuova piattaforma cloud Identity-as-a-Service (IDaaS). |
| Espansione in una nuova giurisdizione | Entrare in un mercato con leggi sulla privacy diverse (es. GDPR, CPRA) spesso impone requisiti specifici per le PIA. | Una società SaaS statunitense inizia a commercializzare i suoi servizi a clienti nell’Unione Europea. |
Un framework decisionale pratico
Non ogni modifica di una funzionalità richiede una PIA completa. Sovraccaricare i team con processi inutili porta a elusioni. È necessario un framework decisionale leggero per distinguere tra cambiamenti rilevanti che richiedono un’analisi approfondita e modifiche minori che non lo fanno.
L’obiettivo è dimensionare correttamente la valutazione rispetto al rischio. Un cambiamento architetturale rilevante che coinvolge dati sensibili richiede una PIA completa, mentre un aggiornamento minore dell’interfaccia utente che non modifica la gestione dei dati potrebbe richiedere solo un rapido controllo rispetto ai principi di privacy stabiliti.
Per implementare questo, integrate un semplice questionario di screening nella pianificazione degli sprint o nella definizione delle funzionalità:
- Questa modifica comporta la raccolta di nuove categorie di dati personali?
- I dati esistenti saranno usati per un nuovo scopo non precedentemente comunicato agli utenti?
- Condivideremo i dati con una nuova terza parte o un sistema esterno?
- Questa funzionalità implica decisioni automatizzate con un potenziale impatto significativo su una persona?
Una risposta affermativa a una qualsiasi di queste domande indica che è necessaria una PIA formale. Questa semplice checklist integra le considerazioni sulla privacy direttamente negli sprint di sviluppo, rendendola una componente naturale dell’ingegneria del software.
I componenti principali di una PIA efficace
Una corretta Privacy Impact Assessment non è un esercizio di compilazione di moduli. È un’indagine strutturata sull’architettura dei dati di un sistema. Per i team di ingegneria e prodotto, è essenziale avere una roadmap chiara per condurre una PIA significativa.
Pensatela come un’ispezione architettonica. Non si approverebbe un nuovo edificio con uno sguardo frettoloso; si ispezionerebbero le fondamenta, l’integrità strutturale, gli impianti elettrici e le misure antincendio. Una PIA applica la stessa rigore sistematico al trattamento dei dati. Una PIA efficace si basa su quattro pilastri: mappatura del flusso dei dati, identificazione dei rischi, strategia di mitigazione e documentazione completa.
Fase 1: Mappatura del flusso dei dati
Prima di analizzare i rischi, bisogna avere una comprensione precisa di come i dati personali si muovono attraverso il sistema. Questa è la base; una mappatura superficiale indebolirà l’intera valutazione. La mappatura del flusso dei dati è il processo di documentare ogni punto di contatto dei dati.
L’obiettivo è rispondere a domande fondamentali con alta precisione:
-
Raccolta: Quali dati personali specifici vengono raccolti? Da quali fonti?
-
Trattamento: Come vengono utilizzati questi dati? Sono un input per un modello di IA, usati per decisioni automatizzate o semplicemente trasformati?
-
Archiviazione: Dove sono memorizzati i dati (es. quale provider cloud, regione geografica)? Quali sono le politiche di sicurezza e di conservazione?
-
Condivisione: I dati sono condivisi con servizi di terze parti, API o fornitori? In tal caso, quali dati vengono trasferiti e per quale scopo?
Un diagramma di flusso dei dati (DFD) è spesso lo strumento più efficace per questa fase. Fornisce una comprensione chiara e condivisa sia per gli stakeholder tecnici sia per quelli non tecnici e mette frequentemente in luce percorsi dei dati non documentati o assunzioni errate.
Fase 2: Identificazione e Analisi del Rischio
Con una mappa dei dati chiara, il passo successivo è identificare le potenziali minacce alla privacy. Questo richiede di pensare oltre gli attacchi esterni e considerare come un trattamento legittimo potrebbe danneggiare le persone.
Una categorizzazione pratica delle minacce alla privacy include:
- Accesso non autorizzato: Il rischio che i dati siano accessibili da sistemi o personale non autorizzati, sia interni che esterni.
- Perdita di dati: L’esposizione accidentale dei dati a causa di infrastrutture mal configurate, vulnerabilità dell’applicazione o protocolli di trasferimento non sicuri.
- Ri-identificazione: Il rischio che dati anonimizzati o pseudonimizzati possano essere combinati con altri dataset per identificare individui specifici.
- Pregiudizio algoritmico: Un rischio critico nei sistemi di IA in cui i modelli producono risultati ingiusti o discriminatori per certi gruppi demografici, spesso a causa di dati di addestramento distorti.
L’aspetto più critico di questa fase non è solo elencare le minacce ma analizzarne la probabilità e il potenziale impatto. Una piccola esposizione di dati su un sistema di test ha un profilo di rischio molto diverso rispetto a un bias sistemico in un algoritmo di valutazione del credito.
Fase 3: Strategie di Mitigazione del Rischio
Una volta che i rischi sono stati identificati e prioritizzati, l’attenzione si sposta sulla progettazione e l’implementazione di controlli per ridurli a un livello accettabile. Qui i principi della Privacy by Design passano dalla teoria a scelte architetturali concrete. Scopri di più su come integrare questi principi nella nostra guida su implementare Privacy by Design.
I controlli di mitigazione ricadono tipicamente in queste categorie:
- Controlli tecnici: Implementati direttamente nel software e nell’infrastruttura. Esempi includono crittografia end-to-end, pseudonimizzazione dei dati, controllo degli accessi basato sui ruoli (RBAC) basato sul principio del minimo privilegio e tecniche di minimizzazione dei dati.
- Controlli procedurali: Politiche e processi che regolano l’interazione umana con i dati. Esempi includono politiche interne di accesso rigorose, formazione obbligatoria sulla privacy per gli sviluppatori e piani di risposta agli incidenti robusti.
- Soluzioni architetturali: Decisioni di design fondamentali che riducono intrinsecamente il rischio. Esempi includono l’adozione di un’architettura dati decentralizzata o l’uso di tecnologie che migliorano la privacy (PETs) come il federated learning.
Fase 4: Documentazione e Reporting
L’ultimo componente è creare una traccia chiara e verificabile dell’intero processo. Il rapporto PIA non è semplicemente un riepilogo; è la prova che dimostra la diligenza. Questo documento funge da difesa contro il controllo normativo e da riferimento vivo per il team.
La documentazione completa deve includere:
- Una descrizione dei flussi di dati e delle attività di trattamento.
- I rischi per la privacy identificati e le relative valutazioni di gravità.
- Le misure di mitigazione implementate e la razionale per la loro selezione.
- Qualsiasi rischio residuo formalmente accettato, insieme alla giustificazione aziendale.
- Approvazioni dai principali stakeholder, come il DPO, il consulente legale e il lead engineer.
Questo output documentato trasforma il PIA da un progetto una tantum in un asset prezioso per la governance continua, garantendo che la privacy rimanga un elemento centrale man mano che il sistema evolve.
Flusso di lavoro passo-passo per il tuo processo PIA
Un flusso di lavoro strutturato e ripetibile è essenziale per tradurre la teoria del PIA in pratica. Una Privacy Impact Assessment non è un’attività singola ma un processo che riunisce competenze tecniche, di prodotto e legali per prendere decisioni difendibili sui dati. Il suo valore reale si realizza quando questo flusso di lavoro è integrato nei cicli di sviluppo esistenti, come Agile o DevOps. Questa integrazione rende la privacy una componente centrale della costruzione di software affidabile, non un onere di conformità.
Questo flusso di lavoro scompone il PIA in fasi discrete, dall’analisi iniziale e raccolta dei dati fino alla mitigazione dei rischi e alla supervisione continua.
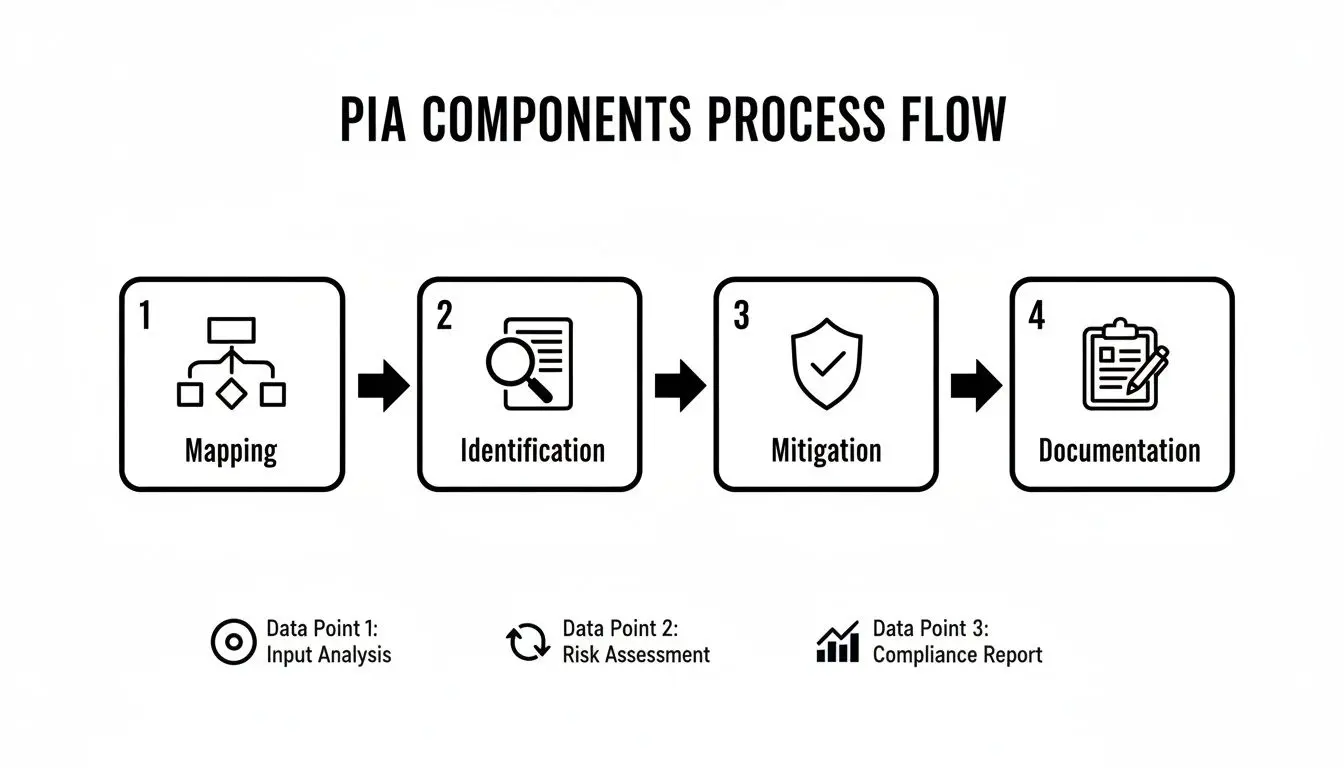
La sequenza è critica: la mappatura dei dati deve precedere l’identificazione dei rischi, che a sua volta deve precedere la progettazione delle misure di mitigazione e la documentazione finale.
Fase 1: Analisi di Soglia
Questo passo iniziale funziona da guardiano. Non ogni modifica minore al codice o aggiornamento di funzionalità richiede un PIA su larga scala. L’obiettivo è determinare rapidamente se è necessaria una valutazione formale.
Questo screening è tipicamente svolto dal Product Manager durante l’ideazione della funzionalità o la pianificazione dello sprint, usando una checklist concisa:
- Stiamo raccogliendo un nuovo tipo di dati personali?
- Stiamo usando dati esistenti per uno scopo nuovo?
- Condivideremo dati con un nuovo fornitore terzo?
- Questa funzionalità comporta decisioni automatizzate con un impatto significativo sugli individui?
Una risposta affermativa a una qualsiasi di queste domande attiva un PIA completo. Questo approccio evita sovraccarichi amministrativi inutili e concentra lo sforzo dove il rischio è più alto.
Fase 2: Raccolta Collaborativa delle Informazioni
Una volta attivato un PIA, l’attenzione si sposta sulla raccolta dettagliata delle informazioni. Questo è uno sforzo collaborativo.
Il Lead Engineer mappa l’implementazione tecnica—flussi di dati, posizioni di archiviazione e controlli di sicurezza. Il Product Manager fornisce il contesto aziendale—lo scopo del trattamento e il valore che apporta. Il Data Protection Officer (DPO) o il consulente legale fornisce il quadro normativo, assicurando che il trattamento abbia una base legale valida secondo le norme applicabili come il GDPR. Questa fase collaborativa garantisce che il PIA sia radicato sia nella realtà tecnica sia negli obblighi legali.
Fase 3: Analisi e Valutazione del Rischio
Con tutte le informazioni raccolte, il team identifica le potenziali minacce alla privacy. Questa analisi va oltre le vulnerabilità di sicurezza per includere i rischi per gli individui, come la ri-identificazione di dati anonimizzati o l’introduzione di bias algoritmico.
Ogni rischio identificato viene quindi valutato su due fattori:
- Probabilità: La probabilità che il rischio si materializzi.
- Impatto: La gravità del danno per gli individui se il rischio si materializza.
Questa analisi, spesso guidata dal DPO con il contributo dell’ingegneria, produce un elenco prioritario di preoccupazioni. Un rischio di bias sistemico in uno strumento di assunzione guidato dall’IA verrà correttamente valutato molto più in alto rispetto a una piccola esposizione di dati in un ambiente di test isolato.
Fase 4: Pianificazione e Implementazione della Mitigazione
Questa fase riguarda la progettazione e l’implementazione di controlli per ridurre i rischi prioritari a un livello accettabile. Questo è il dominio del Lead Engineer, che traduce i requisiti di privacy in soluzioni tecniche concrete.
Un fallimento comune è trattare la mitigazione come un’aggiunta post-sviluppo. La vera Privacy by Design incorpora i controlli nell’architettura del sistema—scegliendo la pseudonimizzazione invece del testo in chiaro per impostazione predefinita, implementando controlli di accesso granulare e integrando la minimizzazione dei dati nella logica principale.
La mitigazione può essere tecnica (es. crittografia end-to-end), procedurale (es. una nuova politica di accesso) o architetturale (es. usare il federated learning per evitare la centralizzazione dei dati).
Fase 5: Reporting e Approvazione
L’intero processo viene documentato in un rapporto formale PIA. Questo documento è una traccia verificabile della diligenza, che dettaglia i flussi di dati, i rischi identificati, le mitigazioni implementate e eventuali rischi residui che l’azienda ha formalmente accettato.
Il DPO, il Product Manager e il Lead Engineer devono rivedere e approvare il rapporto, stabilendo una chiara responsabilità e fornendo prove critiche di conformità per i regolatori.
Fase 6: Monitoraggio e Revisione Continui
Un PIA è una fotografia nel tempo, non un documento statico. Man mano che il prodotto evolve, evolvono anche le sue implicazioni sulla privacy.
Il PIA deve essere trattato come un documento vivo, rivisto e aggiornato periodicamente—almeno annualmente, o ogni volta che viene effettuata una modifica significativa alle attività di trattamento dei dati. Questo monitoraggio continuo assicura che la postura di privacy dell’organizzazione rimanga robusta e che il PIA resti uno strumento di governance accurato e utile.
Adattare il PIA per sistemi di IA e Machine Learning
Condurre una Privacy Impact Assessment per un sistema di intelligenza artificiale o machine learning introduce complessità uniche che un PIA tradizionale non è attrezzato a gestire. Le valutazioni standard si concentrano sui flussi di dati e sulle politiche di archiviazione, ma i modelli di IA introducono uno strato distinto di rischio radicato nel comportamento algoritmico, nell’opacità del modello e nella potenziale produzione di risultati discriminatori.
Per un sistema di IA, un PIA deve estendersi oltre semplici inventari dei dati per scrutinare l’intero ciclo di vita del modello, dalla provenienza e qualità dei dati di addestramento alla logica interna del modello e all’impatto a valle delle sue predizioni.
Oltre i controlli standard sulla privacy dei dati
Un PIA tradizionale risponde a domande come, “I dati sono crittografati?” o “Abbiamo il consenso?” Con l’IA, le domande necessarie sono fondamentalmente diverse e sondano il rischio algoritmico:
- Pregiudizio algoritmico: I dati di addestramento contengono bias storici che il modello apprenderà e amplificherà, portando a risultati ingiusti?
- Spiegabilità del modello: Se il modello nega a un individuo un servizio, possiamo spiegare perché? Un modello opaco “black box” rappresenta una responsabilità significativa per la privacy e l’etica.
- Provenienza dei dati: Esiste una traccia chiara e verificabile per i dati di addestramento? L’uso di dati di scarsa qualità o di fonte discutibile può introdurre difetti profondi difficili da correggere.
- Rischi di inferenza: Quali nuove informazioni potenzialmente sensibili il modello può inferire sugli individui, anche a partire da dati di input non sensibili?
Un PIA efficace focalizzato sull’IA fonde i principi di protezione dei dati con revisioni di etica e equità dell’IA. È meno un esercizio di conformità e più un quadro di governance per costruire tecnologia responsabile.
Unificare i modelli di governance
La necessità di una valutazione più ampia e integrata è sempre più riconosciuta. La ricerca indica che mentre il 92% delle organizzazioni comprende la necessità di costruire fiducia dei clienti nell’IA, i loro processi spesso restano indietro. Ad esempio, mentre il 60% esegue valutazioni dell’impatto dell’IA in parallelo con le revisioni sulla privacy, solo il 49% le ha integrate in un processo unico e coerente.
Questo divario tra consapevolezza e attuazione è una fonte primaria di rischio. Per colmarlo, i responsabili dell’ingegneria e del prodotto hanno bisogno di un quadro di governance unificato. Il PIA non dovrebbe essere un flusso di lavoro separato dalla revisione etica dell’IA; dovrebbero essere componenti di una singola valutazione olistica che valuta il rischio da tutti i punti di vista.
Questo approccio unificato garantisce che la privacy non sia un ripensamento ma una considerazione centrale nel modo in cui progetti, costruisci e gestisci i sistemi intelligenti—assicurando che la tua IA sia conforme, equa, trasparente e affidabile.
Domande frequenti sui PIA
Questa sezione affronta domande comuni e pratiche da parte di leader tecnici e di prodotto incaricati di implementare una Privacy Impact Assessment.
Come si inseriscono i PIA in un ambiente di sviluppo Agile?
Una PIA non dovrebbe essere un rapporto monolitico in stile waterfall. In un contesto Agile, deve essere un processo iterativo e vivente. Si inizia con una PIA fondamentale durante la progettazione iniziale del prodotto per mappare i flussi di dati principali e identificare i rischi di alto livello. Successivamente, si integrano PIAs più piccoli e mirati o controlli sulla privacy nella pianificazione degli sprint. Qualsiasi nuova funzionalità che modifica il trattamento dei dati viene sottoposta a una revisione mirata. Questo approccio permette alla PIA di evolvere con il prodotto, mantenendo la privacy una preoccupazione centrale senza ostacolare la velocità di sviluppo.
Qual è la differenza tra una PIA e un audit di sicurezza?
Sebbene correlati, si occupano di problemi distinti. Un audit di sicurezza è incentrato sulla difesa. Si chiede, “Possiamo proteggere i nostri sistemi e i nostri dati da accessi non autorizzati, violazioni e minacce esterne?” La sua principale preoccupazione è l’integrità e la riservatezza del sistema.
Una Valutazione d’impatto sulla privacy si occupa dei rischi derivanti dal vostro uso legittimo, autorizzato dei dati personali. Pone una domanda più fondamentale: “Quali danni potrebbe causare il nostro trattamento previsto dei dati alle persone, anche se la nostra sicurezza è perfetta?” Un sistema può essere perfettamente sicuro e tuttavia rappresentare un rischio significativo per la privacy a causa del suo design o del suo scopo.
Quale livello di dettaglio tecnico è richiesto?
Una PIA deve bilanciare profondità tecnica e accessibilità. Deve essere sufficientemente dettagliata per consentire a un revisore tecnico di convalidare l’architettura dei dati, ma abbastanza chiara perché uno stakeholder non tecnico, come un consulente legale o il DPO, comprenda le implicazioni per la privacy.
I seguenti dettagli tecnici sono non negoziabili:
- I punti dati specifici che vengono raccolti.
- Le posizioni di archiviazione dei dati, inclusi i provider cloud e le regioni geografiche.
- I metodi di crittografia utilizzati, sia in transito che a riposo.
- Un elenco completo dei servizi di terze parti o delle API che ricevono dati personali.
L’obiettivo non è il mero inventario, ma fornire prove sufficienti a giustificare la vostra valutazione del rischio. Affermazioni vaghe come “i dati degli utenti sono archiviati nel cloud” sono inadeguate per una valutazione d’impatto sulla privacy significativa.
Una solida valutazione d’impatto sulla privacy è un pilastro per costruire software affidabile e conforme. Presso Devisia, integriamo la privacy in ogni fase del ciclo di sviluppo, dall’architettura pragmatica alla manutenzione a lungo termine. Scoprite come costruiamo prodotti digitali affidabili su https://www.devisia.pro.