
At its core, privacy by default, as mandated by GDPR, is an architectural principle: systems must be configured to be as protective of personal data as possible out of the box, requiring no user action. This means that only necessary personal data is processed, collection is strictly minimized, and access is locked down from the start.
The Problem: Privacy as a Compliance Afterthought
For many engineering leaders, GDPR Article 25—which mandates privacy by default GDPR—often lands on their desk as just another legal constraint, another item on a long compliance checklist.
This perspective is a direct path to technical debt.
Treating privacy as a feature to be bolted on later leads to brittle systems, glaring security vulnerabilities, and frantic, costly refactoring projects when a regulator inevitably investigates. The core problem is a reactive mindset that sees data protection as a legal hurdle rather than a foundational component of system design.
The naive approach is to collect data liberally “just in case” and grant broad access permissions for “flexibility.” This creates a sprawling data footprint that is difficult to secure, expensive to maintain, and nearly impossible to bring into compliance retroactively.
The Solution: Privacy as an Architectural Choice
The solution is to reframe privacy by default as a core architectural principle. It’s not a legal box to tick; it shapes how you design data models, build APIs, and craft user interfaces from the first line of code.
When you make this shift, the legal obligation becomes a competitive advantage. Building inherently privacy-protective systems creates more resilient, maintainable, and trustworthy platforms. This approach forces engineering teams to be deliberate about every piece of data they process.
Here are the implementation considerations:
- Data Justification: Instead of permissive collection, engineers must justify every data point. What is its specific purpose? What is the minimum retention period? Who requires access, and why?
- System Simplification: A minimal data footprint reduces complexity. Fewer data points mean a smaller attack surface, making systems easier to manage, debug, and secure.
- Building Trust: In a B2B context, demonstrable data protection is a powerful sales tool. Your system architecture becomes concrete proof of your commitment to protecting client data.
The Real-World Impact of Default Settings
The mandate for privacy by default under GDPR Article 25 took effect on May 25, 2018. It required systems to process only necessary personal data with minimal storage and restricted access. The operational impact was significant.
One MIT study found that within two years, EU IT firms had reduced their data storage by 26% and computation by 15% compared to their US counterparts. This was a direct result of re-architecting systems to minimize data processing to maintain compliance.
Embracing privacy by default forces clarity and discipline. If you cannot justify processing a piece of data for a specific, legitimate purpose, your system should not collect it. This simple rule prevents a cascade of future problems, from data breaches to burdensome data subject requests.
Ultimately, this principle is deeply intertwined with the broader concept of Privacy by Design, which embeds data protection into the entire development lifecycle. When you adopt privacy by default, you make a strategic decision to build better, more secure software.
From Legal Mandate to Engineering Roadmap
Bridging the gap between dense GDPR legalese and actionable engineering tasks is where most privacy initiatives stall. For a product leader or CTO, abstract legal mandates must translate directly into user stories, default settings, and architectural trade-offs. The key is to embed compliance into your product development discipline.
This process must begin long before any code is written, starting with a fundamental question: what personal data is strictly necessary for this new feature to function?
Map Your Data Before You Build
First, create a precise inventory of all personal data the new feature will process. This is not a mere compliance formality; it’s a critical product planning tool that demands absolute clarity on data flows. For every data point, you must define its exact purpose and legal basis for processing.
Scenario: A B2B SaaS platform adding a new collaboration feature. A naive approach might make all user profiles within a workspace public by default to “drive engagement.” A privacy by default GDPR mindset challenges this assumption.
The data mapping exercise would look like this:
- Data Point: User’s full name. Purpose: Display identity in the collaborative space.
- Data Point: User’s profile picture. Purpose: Enable quick visual identification.
- Data Point: User’s job title. Purpose: Provide organizational context to team members.
This simple map immediately flags a critical product decision. Is it necessary for every user’s job title to be visible to everyone else by default? The answer is likely no. This insight leads directly to a more privacy-centric architecture: make profile details private by default and provide users with a clear, granular option to share more.
Run a Lightweight DPIA During Planning
The term Data Protection Impact Assessment (DPIA) can be intimidating, but a pragmatic version should be integrated into your feature planning or sprint zero. The goal is not bureaucracy; it’s about de-risking development by identifying privacy constraints early.
Before committing to a feature, the team must answer:
- Necessity: Is processing this personal data strictly required for the feature to function?
- Proportionality: Are we collecting the absolute minimum data required?
- Risks: What are the potential impacts on the individual if this data were breached or misused?
- Mitigations: What technical and organizational measures (e.g., pseudonymization, access controls) will we implement to manage those risks?
A lightweight DPIA isn’t about producing exhaustive legal documents. It’s about instilling a ‘privacy conscience’ in the product team, ensuring every feature is scrutinized through a data protection lens before it enters the backlog.
This proactive check prevents expensive downstream course corrections. For instance, a team might propose collecting extensive user activity data for a “future AI feature.” A DPIA would immediately flag this as a violation of the purpose limitation principle. Collecting data for a non-existent feature is a clear GDPR red flag. This forces the team to design a proper consent model where optional analytics are disabled by default.
By embedding these practices, you transform privacy by default GDPR from a legal burden into a product development framework. Keeping clear records of these decisions is vital for demonstrating accountability, a topic covered in our guide to GDPR Article 30 compliance.
Implementing Privacy by Default in Your Architecture
Turning principles into system architecture is how privacy by default GDPR becomes an engineering reality. It requires specific, deliberate technical controls at the code and infrastructure levels. Getting this right avoids painful refactoring and builds a defensible privacy posture.
The implementation rests on three interconnected pillars: enforcing strict access, minimizing data at every stage, and automating the data lifecycle. These are not bolt-on features; they are mutually reinforcing architectural decisions.
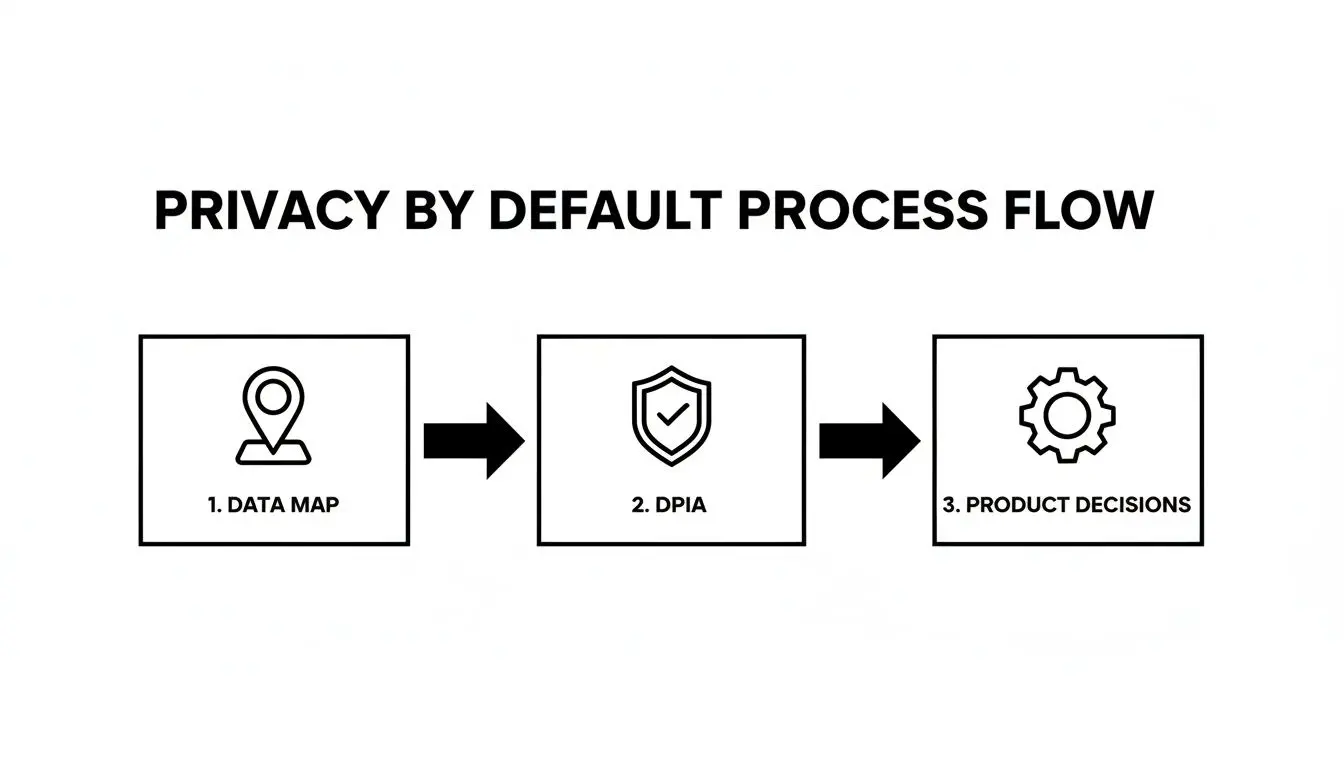
This flow shows how early diligence—data mapping and DPIAs—directly shapes the product decisions that engineers implement. Your technical controls cannot be generic; they must be a direct response to the specific data and its associated risks.
Enforcing Least Privilege with Robust Access Control
The foundation of data access is the principle of least privilege. By default, no user or system should be able to access data unless it is essential for their function. The classic anti-pattern is to grant broad permissions initially and attempt to restrict them later.
Instead, build your system using Role-Based Access Control (RBAC) patterns from day one.
- Define Granular Roles: Avoid generic roles like “admin.” Define roles tied to specific job functions, such as “BillingManager,” “SupportTier1,” or “SystemAuditor.” Each role should have the absolute minimum permissions required.
- Default to No Access: A new user account should have zero permissions by default. Roles must be explicitly and intentionally assigned.
- Separate Service Account Permissions: Machine-to-machine communication requires the same discipline. A service account for an analytics pipeline should have read-only access to specific, pseudonymized datasets, not broad database permissions.
A common risk is hardcoding access logic directly into the application. A cleaner architectural pattern is to manage roles and permissions in a centralized identity provider (IdP) or a dedicated authorization service. This decouples policy from code, making the system easier to audit and update.
Applying Pseudonymization and Anonymization
Data minimization isn’t just about collecting less data; it’s about reducing the identifiability of the data you process. Pseudonymization and anonymization are critical tools with different technical and legal implications.
Pseudonymization replaces direct identifiers (e.g., email) with a reversible token. The data remains personal data under GDPR because re-identification is possible. It is ideal for internal processing where you need to link user activities without exposing raw personal details in logs or analytics systems.
- Architectural Pattern: An analytics system tracks user behavior. Instead of logging
user_email: 'jane.doe@example.com', it logsuser_id: 'a1b2-c3d4-e5f6'. The mapping linking the ID to the email is stored separately in a highly secured, access-controlled database.
Anonymization involves irreversibly removing or altering data so an individual can no longer be identified. Once data is truly anonymized, it is no longer considered personal data under GDPR. This is the required approach for public data releases or training machine learning models where individual identities are irrelevant.
- Architectural Pattern: To train a churn prediction model, use a dataset where all personal identifiers have been stripped and data is aggregated to a point where re-identification is computationally infeasible.
The choice of technique depends on the use case and risk tolerance. Pseudonymization reduces risk; true anonymization eliminates it for a given dataset.
Automating Data Lifecycle Management
Finally, privacy by default GDPR means data cannot be retained indefinitely “just in case.” Data retention and deletion must be automated, programmatic processes, not manual cleanup tasks.
Consider these architectural patterns:
- Time-to-Live (TTL) Policies: Many modern datastores (like DynamoDB or Redis) support TTL attributes on records. Set a default expiration on data at creation. For example, user activity logs can have a default TTL of 90 days.
- Scheduled Deletion Jobs: For more complex rules, a cron job or scheduled serverless function can periodically purge data that has passed its retention period. This job must be idempotent and produce detailed logs for auditing.
- Event-Driven Deletion: In an event-driven architecture, an event like “UserAccountClosed” can trigger a cascade of deletion tasks across multiple microservices, ensuring all associated user data is systematically removed.
Building these technical controls into the fabric of your systems moves beyond compliance checklists. It creates a more secure, maintainable, and trustworthy platform where data protection is an inherent property of the architecture.
Designing a User Experience That Builds Trust
True privacy by default must be reflected in the user experience. A compliant backend is insufficient if the user interface is confusing or deceptive. The objective is to design a journey where privacy is an intuitive, transparent feature.
This requires moving beyond legacy consent models like massive, one-time pop-ups during onboarding. The focus must be on creating contextual interactions that build trust. Every UI element, from a simple toggle to a detailed preference center, must have the most privacy-protective option pre-selected.
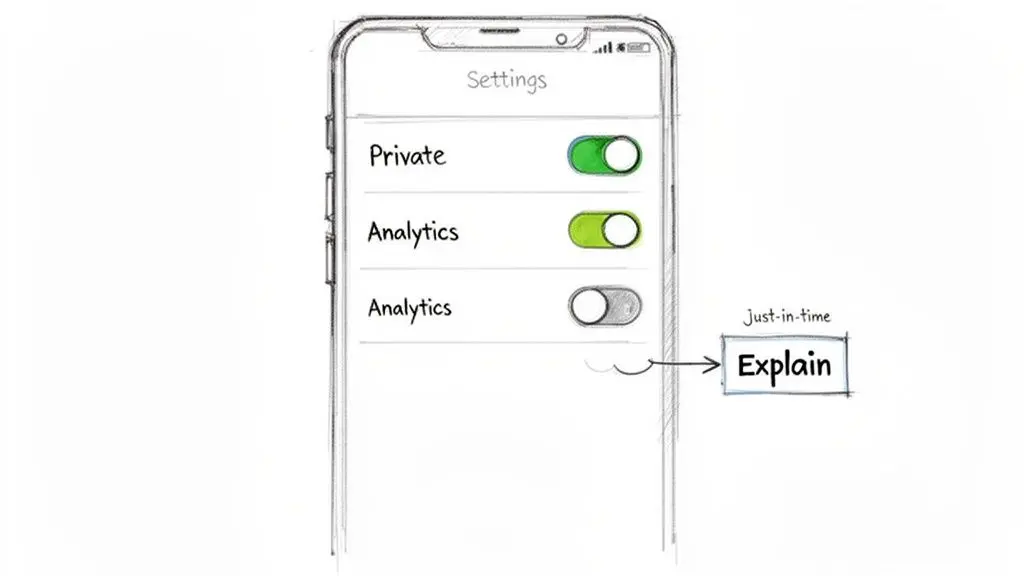
Positive Patterns for Privacy UX
An effective privacy UX makes defaults obvious and empowers users to make informed choices without coercion. This is achieved through clarity and context.
- Granular Toggles, Off by Default: Replace a single “Accept All” button with separate, clearly labeled toggles for “Performance Analytics” or “Personalized Marketing.” Both must be off by default. Opting in must be a clear, affirmative action.
- Just-in-Time (JIT) Notices: Do not request microphone access on app launch. Instead, trigger the permission request only when the user interacts with a feature that requires it, like a voice memo button. This system prompt should be paired with a clear explanation of why access is needed at that moment.
- Layered Information: Provide information at different levels of detail. In a settings panel, use concise labels for quick scanning (e.g., “Share usage data to help us improve”). A “Learn More” link next to it can expand to provide a more detailed but still plain-language explanation of what data is collected and for what purpose.
Avoiding Deceptive Dark Patterns
Dark patterns are UI manipulations designed to nudge users into sharing more data than they intend. These practices not only violate the spirit of GDPR but also erode user trust. A classic example is a pre-ticked box for marketing consent, but modern dark patterns can be far more subtle.
Identifying and eliminating dark patterns is a core engineering and design responsibility. If an interface makes it significantly harder to opt out than to opt in, it is almost certainly a dark pattern. This includes using confusing language, hiding privacy settings, or using visual tricks like a greyed-out “Decline” button.
Common dark patterns to avoid:
- Misdirection: Using vague phrases like “Enable Enhanced Experience” to describe optional data tracking. Language must be specific and neutral.
- Forced Action: Requiring consent to non-essential data processing to access a core feature. Consent must be freely given.
- Aesthetic Manipulation: Designing the “Accept” button to be large and colorful while the “Decline” option is small and grey. Both choices must have equal visual weight.
A trustworthy UX treats the user with respect. It assumes users will grant consent for valuable features if the value is explained clearly and honestly. By making the most private setting the default, you demonstrate respect for user autonomy from the first interaction.
Navigating Privacy Challenges in AI and ML Systems
Artificial Intelligence and Machine Learning systems introduce a new class of privacy challenges. Applying privacy by default GDPR principles here requires scrutinizing the entire lifecycle—from training data to live inference endpoints—through a different lens.
The core problem is that these systems learn from data, creating complex artifacts that can unintentionally leak personal information. The common but high-risk practice of feeding raw production data directly into a model must be avoided. The only safe default is aggressive data minimization before any model interacts with the data.
Minimizing Data in Model Inputs
The most effective strategy is prevention: stop personal data from reaching the model in the first place. This requires a layered approach covering both training and real-time inference.
For model training:
- Anonymize Datasets: Before training, datasets must be processed to remove or irreversibly transform direct identifiers. This goes beyond pseudonymization, employing techniques like aggregation, noise injection (as in differential privacy), or k-anonymity to make re-identification computationally infeasible.
- Use Synthetic Data: Where possible, generate synthetic data that mirrors the statistical properties of the real dataset but contains no actual personal information. This is an excellent default for initial model development and testing.
For inference endpoints, the focus is on real-time filtering. Implement strict input validation guardrails that actively scan for and either reject or sanitize inputs containing personal data like email addresses or phone numbers, unless that data is explicitly required for the feature’s function.
The Hidden Risks of Embeddings and Logs
Embeddings—numerical vectors models use to represent data—are a significant risk. While not human-readable, they are not anonymous. Research has shown it is possible to reconstruct parts of original input data from its embedding.
By default, treat embeddings derived from personal data with the same security controls as the raw data itself. They are not ‘anonymized’ simply because they are vectors.
System logging is another major blind spot. Developers are often tempted to log full user inputs and model outputs for debugging, a practice that directly violates privacy by default GDPR.
A robust logging strategy for AI systems includes:
- Sanitize Logs by Default: All logs should be stripped of personal data before being written to disk. Log only metadata, trace IDs, and sanitized snippets necessary for debugging.
- Separate Audit Trails: If logging sensitive data is unavoidable for security or audit purposes, it must go into a separate, highly secured system with a short retention period and strict access controls.
Human-in-the-Loop as a Default Control
Finally, consider Article 22 of the GDPR, which grants individuals the right not to be subject to solely automated decisions that have a legal or similarly significant effect on them.
For any high-risk AI system (e.g., credit scoring, recruitment), a human-in-the-loop (HITL) review process should be the default architecture. An automated decision should not be final until a qualified person reviews and approves it. Building this safeguard into your system from day one is a critical expression of privacy by default, ensuring fairness, accountability, and a clear path for user recourse.
To better assess specific risks in your AI systems, use our free AI Risk & Privacy Checklist to identify and mitigate these issues early.
Conclusion: Key Takeaways for Technical Leaders
Implementing privacy by default is not a one-off project but a continuous discipline. It requires a fundamental shift from reactive compliance to proactive, privacy-led engineering.
Here are the key takeaways:
- Treat Privacy as an Architectural Principle: Embed data protection into your system design from the start. A reactive approach creates technical debt and increases risk.
- Minimize Data Aggressively: The default action should always be to not collect or process data. Every data point must have a clear, documented justification.
- Automate Data Lifecycle Management: Use technical controls like TTL policies and automated deletion jobs to enforce retention policies programmatically. Manual processes are prone to failure.
- Design for Transparency: Your user interface must make privacy-protective settings the default and give users clear, granular control without resorting to dark patterns.
- Validate and Document: Continuously test your privacy controls and document their implementation. This provides auditable evidence that your system operates as designed, transforming privacy by default GDPR from a legal obligation into a tangible engineering asset. You can read more about these post-GDPR findings from MIT Sloan.
Ultimately, your documentation and architecture should tell a simple story: every product decision was made with the intent to protect user data by default. This proactive stance simplifies audits, streamlines processes like data subject access requests, and builds a foundation of trust with your users.
At Devisia, we believe privacy is an architectural choice, not a feature. We build reliable, maintainable software and AI systems with data protection designed in from the start. If you are building a robust digital product, let’s connect. Learn more at https://www.devisia.pro.