
Al centro, privacy per impostazione predefinita, come previsto dal GDPR, è un principio architetturale: i sistemi devono essere configurati per proteggere il più possibile i dati personali fin dal primo utilizzo, senza richiedere azioni da parte dell’utente. Ciò significa che vengono trattati solo i dati personali necessari, la raccolta è rigorosamente minimizzata e l’accesso è limitato fin dall’inizio.
Il problema: la privacy come ripensamento per la conformità
Per molti responsabili tecnici, l’Articolo 25 del GDPR — che impone la privacy per impostazione predefinita del GDPR — arriva spesso sulla loro scrivania come un altro vincolo legale, un altro elemento di una lunga checklist di conformità.
Questa prospettiva è un percorso diretto verso il debito tecnico.
Trattare la privacy come una funzionalità da aggiungere in seguito porta a sistemi fragili, evidenti vulnerabilità di sicurezza e frenetici, costosi progetti di refactoring quando un regolatore inevitabilmente indaga. Il problema centrale è una mentalità reattiva che vede la protezione dei dati come un ostacolo legale piuttosto che come un componente fondamentale della progettazione del sistema.
L’approccio ingenuo è raccogliere dati in modo liberale “per ogni eventualità” e concedere ampie autorizzazioni di accesso per la “flessibilità”. Questo crea un’impronta di dati estesa difficile da mettere in sicurezza, costosa da mantenere e quasi impossibile da rendere conforme retroattivamente.
La soluzione: la privacy come scelta architetturale
La soluzione è ripensare la privacy per impostazione predefinita come principio architetturale centrale. Non è una casella legale da spuntare; plasma il modo in cui progetti i modelli di dati, costruisci le API e realizzi le interfacce utente fin dalla prima riga di codice.
Quando operi questo cambiamento, l’obbligo legale diventa un vantaggio competitivo. Costruire sistemi intrinsecamente protettivi per la privacy crea piattaforme più resilienti, manutenibili e affidabili. Questo approccio costringe i team di ingegneria a essere deliberati su ogni dato che processano.
Ecco le considerazioni di implementazione:
- Giustificazione dei dati: invece della raccolta permissiva, gli ingegneri devono giustificare ogni punto dati. Qual è il suo scopo specifico? Qual è il periodo minimo di conservazione? Chi necessita dell’accesso e perché?
- Semplificazione del sistema: un’impronta di dati minima riduce la complessità. Meno punti dati significano una superficie di attacco più piccola, rendendo i sistemi più facili da gestire, debugare e mettere in sicurezza.
- Costruire fiducia: in un contesto B2B, la protezione dei dati dimostrabile è uno strumento di vendita potente. L’architettura del sistema diventa una prova concreta del vostro impegno a proteggere i dati dei clienti.
L’impatto reale delle impostazioni predefinite
Il mandato per la privacy per impostazione predefinita ai sensi dell’Articolo 25 del GDPR è entrato in vigore il 25 maggio 2018. Ha richiesto che i sistemi trattassero solo i dati personali necessari con uno stoccaggio minimo e accessi ristetti. L’impatto operativo è stato significativo.
Uno studio del MIT ha rilevato che entro due anni le aziende IT dell’UE avevano ridotto lo stoccaggio dei dati del 26% e il calcolo del 15% rispetto ai loro omologhi statunitensi. Questo è stato il risultato diretto della ristrutturazione dei sistemi per minimizzare il trattamento dei dati e mantenere la conformità.
Abbracciare la privacy per impostazione predefinita impone chiarezza e disciplina. Se non puoi giustificare il trattamento di un dato per uno scopo specifico e legittimo, il tuo sistema non dovrebbe raccoglierlo. Questa semplice regola previene una cascata di problemi futuri, dalle violazioni dei dati alle onerose richieste degli interessati.
In ultima analisi, questo principio è profondamente interconnesso con il concetto più ampio di Protezione dei dati fin dalla progettazione, che incorpora la protezione dei dati nell’intero ciclo di sviluppo. Quando adotti privacy per impostazione predefinita, prendi una decisione strategica per costruire software migliore e più sicuro.
Da un obbligo legale a una roadmap di ingegneria
Colmare il divario tra il gergo legale denso del GDPR e compiti ingegneristici concreti è dove la maggior parte delle iniziative di privacy si arenano. Per un product leader o un CTO, i mandati legali astratti devono tradursi direttamente in user story, impostazioni predefinite e compromessi architetturali. La chiave è incorporare la conformità nella disciplina di sviluppo del prodotto.
Questo processo deve iniziare molto prima che venga scritto codice, partendo da una domanda fondamentale: quali dati personali sono strettamente necessari perché questa nuova funzionalità funzioni?
Mappa i tuoi dati prima di costruire
Per prima cosa, crea un inventario preciso di tutti i dati personali che la nuova funzionalità tratterà. Non è una mera formalità di conformità; è uno strumento critico di pianificazione del prodotto che richiede chiarezza assoluta sui flussi di dati. Per ogni punto dati, devi definire il suo scopo esatto e la base giuridica per il trattamento.
Scenario: una piattaforma SaaS B2B che aggiunge una nuova funzionalità di collaborazione. Un approccio ingenuo potrebbe rendere pubblici per impostazione predefinita tutti i profili utente all’interno di uno spazio di lavoro per “aumentare il coinvolgimento”. Una mentalità di privacy per impostazione predefinita del GDPR mette in discussione questa ipotesi.
L’esercizio di mappatura dei dati sarebbe così:
- Punto dati: Nome completo dell’utente. Scopo: Visualizzare l’identità nello spazio collaborativo.
- Punto dati: Foto del profilo dell’utente. Scopo: Abilitare un rapido riconoscimento visivo.
- Punto dati: Mansione dell’utente. Scopo: Fornire contesto organizzativo ai membri del team.
Questa semplice mappa evidenzia immediatamente una decisione critica di prodotto. È necessario che la mansione di ogni utente sia visibile a tutti gli altri per impostazione predefinita? La risposta probabilmente è no. Questa intuizione porta direttamente a un’architettura più centrata sulla privacy: rendere i dettagli del profilo privati per impostazione predefinita e fornire agli utenti un’opzione chiara e granulare per condividere di più.
Esegui una DPIA leggera durante la pianificazione
Il termine Data Protection Impact Assessment (DPIA) può intimidire, ma una versione pragmatica dovrebbe essere integrata nella pianificazione della funzionalità o nello sprint zero. L’obiettivo non è la burocrazia; si tratta di ridurre i rischi nello sviluppo identificando i vincoli di privacy in anticipo.
Prima di impegnarsi in una funzionalità, il team deve rispondere a:
- Necessità: Il trattamento di questi dati personali è strettamente necessario perché la funzionalità funzioni?
- Proporzionalità: Stiamo raccogliendo il minimo assoluto di dati richiesti?
- Rischi: Quali sono i potenziali impatti sull’interessato se questi dati fossero violati o usati in modo improprio?
- Mitigazioni: Quali misure tecniche e organizzative (es. pseudonimizzazione, controlli di accesso) implementeremo per gestire tali rischi?
Una DPIA leggera non serve a produrre documenti legali esaustivi. Serve a instillare una “coscienza della privacy” nel team di prodotto, assicurando che ogni funzionalità sia esaminata attraverso la lente della protezione dei dati prima di entrare nel backlog.
Questo controllo proattivo previene costose correzioni successive. Ad esempio, un team potrebbe proporre di raccogliere vaste informazioni sull’attività degli utenti per una “futura funzionalità AI”. Una DPIA segnalerebbe immediatamente questa pratica come una violazione del principio di limitazione della finalità. Raccogliere dati per una funzionalità inesistente è un chiaro segnale d’allarme GDPR. Questo costringe il team a progettare un modello di consenso appropriato in cui le analisi opzionali siano disattivate per impostazione predefinita.
Incorporando queste pratiche, trasformi privacy per impostazione predefinita del GDPR da onere legale a framework di sviluppo prodotto. Tenere registri chiari di queste decisioni è vitale per dimostrare responsabilità, un argomento trattato nella nostra guida alla conformità all’Articolo 30 del GDPR.
Implementare la privacy per impostazione predefinita nella tua architettura
Trasformare i principi in architettura di sistema è il modo in cui privacy per impostazione predefinita del GDPR diventa una realtà ingegneristica. Richiede controlli tecnici specifici e deliberati a livello di codice e infrastruttura. Farlo bene evita dolorosi refactoring e costruisce una postura di privacy difendibile.
L’implementazione si basa su tre pilastri interconnessi: applicare accessi rigorosi, minimizzare i dati in ogni fase e automatizzare il ciclo di vita dei dati. Questi non sono feature da aggiungere dopo; sono decisioni architetturali che si rafforzano a vicenda.
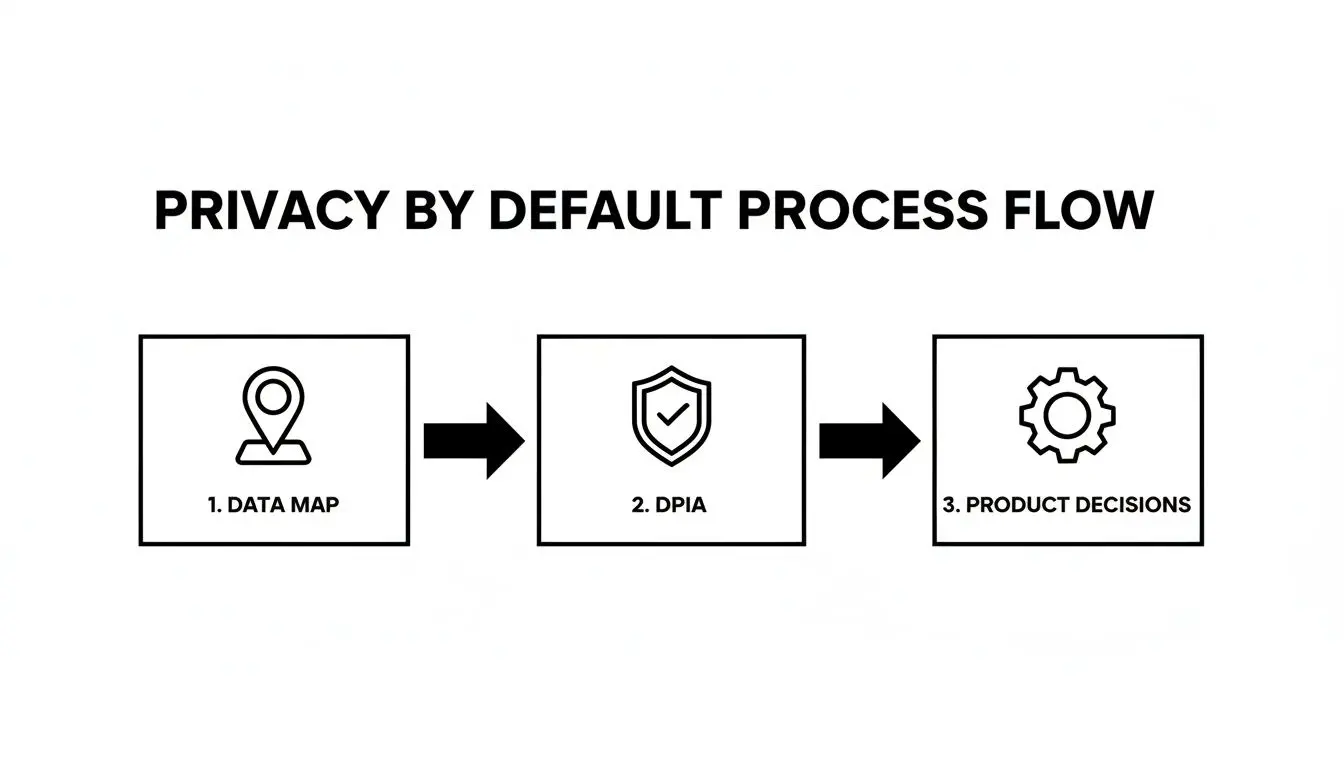
Questo flusso mostra come la diligenza precoce — mappatura dei dati e DPIA — plasmi direttamente le decisioni di prodotto che gli ingegneri devono implementare. I tuoi controlli tecnici non possono essere generici; devono rispondere direttamente ai dati specifici e ai rischi associati.
Applicare il principio del privilegio minimo con controlli di accesso robusti
La base dell’accesso ai dati è il principio del privilegio minimo. Per impostazione predefinita, nessun utente o sistema dovrebbe poter accedere ai dati a meno che non sia essenziale per la loro funzione. L’antipattern classico è concedere ampi permessi inizialmente e cercare di restinguerli in seguito.
Invece, costruisci il tuo sistema usando pattern di Controllo degli Accessi Basato sui Ruoli (RBAC) fin dal primo giorno.
- Definire ruoli granulari: Evita ruoli generici come “admin”. Definisci ruoli legati a specifiche funzioni lavorative, come “BillingManager”, “SupportTier1” o “SystemAuditor”. Ogni ruolo dovrebbe avere i permessi minimi assoluti necessari.
- Impostare il default su Nessun Accesso: Un nuovo account utente dovrebbe avere zero permessi per impostazione predefinita. I ruoli devono essere assegnati in modo esplicito e intenzionale.
- Separare i permessi degli account di servizio: La comunicazione macchina-a-macchina richiede la stessa disciplina. Un account di servizio per una pipeline di analytics dovrebbe avere accesso in sola lettura a dataset specifici e pseudonimizzati, non ampi permessi sul database.
Un rischio comune è hardcodare la logica di accesso direttamente nell’applicazione. Un pattern architetturale più pulito è gestire ruoli e permessi in un identity provider (IdP) centralizzato o in un servizio di autorizzazione dedicato. Questo disaccoppia la policy dal codice, rendendo il sistema più facile da verificare e aggiornare.
Applicare pseudonimizzazione e anonimizzazione
La minimizzazione dei dati non riguarda solo la raccolta ridotta; riguarda la riduzione dell’identificabilità dei dati che processi. Pseudonimizzazione e anonimizzazione sono strumenti critici con implicazioni tecniche e legali differenti.
La pseudonimizzazione sostituisce identificatori direttI (es. email) con un token reversibile. I dati rimangono dati personali ai sensi del GDPR perché la ri-identificazione è possibile. È ideale per l’elaborazione interna quando è necessario collegare le attività degli utenti senza esporre i dettagli personali grezzi nei log o nei sistemi di analytics.
- Pattern architetturale: Un sistema di analytics traccia il comportamento degli utenti. Invece di registrare
user_email: 'jane.doe@example.com', registrauser_id: 'a1b2-c3d4-e5f6'. La mappatura che collega l’ID all’email è memorizzata separatamente in un database altamente protetto e con controllo di accesso.
L’anonimizzazione comporta la rimozione o l’alterazione irreversibile dei dati in modo tale che un individuo non possa più essere identificato. Una volta che i dati sono veramente anonimizzati, non sono più considerati dati personali ai sensi del GDPR. Questo è l’approccio richiesto per rilasci pubblici di dati o per l’addestramento di modelli di machine learning dove le identità individuali sono irrilevanti.
- Pattern architetturale: Per addestrare un modello di previsione dell’abbandono, usa un dataset in cui tutti gli identificatori personali sono stati rimossi e i dati sono aggregati fino a un livello tale che la ri-identificazione sia computazionalmente infeasible.
La scelta della tecnica dipende dal caso d’uso e dalla tolleranza al rischio. La pseudonimizzazione riduce il rischio; la vera anonimizzazione lo elimina per un determinato dataset.
Automatizzare la gestione del ciclo di vita dei dati
Infine, privacy per impostazione predefinita del GDPR significa che i dati non possono essere conservati indefinitamente “per ogni evenienza”. La conservazione e la cancellazione dei dati devono essere processi automatizzati e programmati, non attività di pulizia manuale.
Considera questi pattern architetturali:
- Politiche Time-to-Live (TTL): Molti datastore moderni (come DynamoDB o Redis) supportano attributi TTL sui record. Imposta una scadenza predefinita sui dati al momento della creazione. Ad esempio, i log di attività degli utenti possono avere un TTL predefinito di 90 giorni.
- Job di Eliminazione Pianificati: Per regole più complesse, un cron job o una funzione serverless programmata può periodicamente eliminare i dati che hanno superato il periodo di conservazione. Questo job deve essere idempotente e generare log dettagliati per la verifica.
- Eliminazione Event-Driven: In un’architettura event-driven, un evento come ‘UserAccountClosed’ può attivare una cascata di attività di eliminazione attraverso più microservizi, garantendo che tutti i dati associati all’utente siano rimossi in modo sistematico.
Integrare questi controlli tecnici nell’architettura dei tuoi sistemi va oltre le liste di controllo per la conformità. Crea una piattaforma più sicura, manutenibile e affidabile, dove la protezione dei dati è una proprietà intrinseca dell’architettura.
Progettare un’esperienza utente che costruisca fiducia
La vera privacy per impostazione predefinita (GDPR) deve riflettersi nell’esperienza utente. Un backend conforme non è sufficiente se l’interfaccia utente è confusa o ingannevole. L’obiettivo è progettare un percorso in cui la privacy sia una caratteristica intuitiva e trasparente.
Ciò richiede di andare oltre i vecchi modelli di consenso come pop-up massivi e monofase durante l’onboarding. Il focus deve essere sulla creazione di interazioni contestuali che costruiscano fiducia. Ogni elemento dell’interfaccia, da un semplice interruttore a un centro preferenze dettagliato, deve avere l’opzione più protettiva per la privacy pre-selezionata.
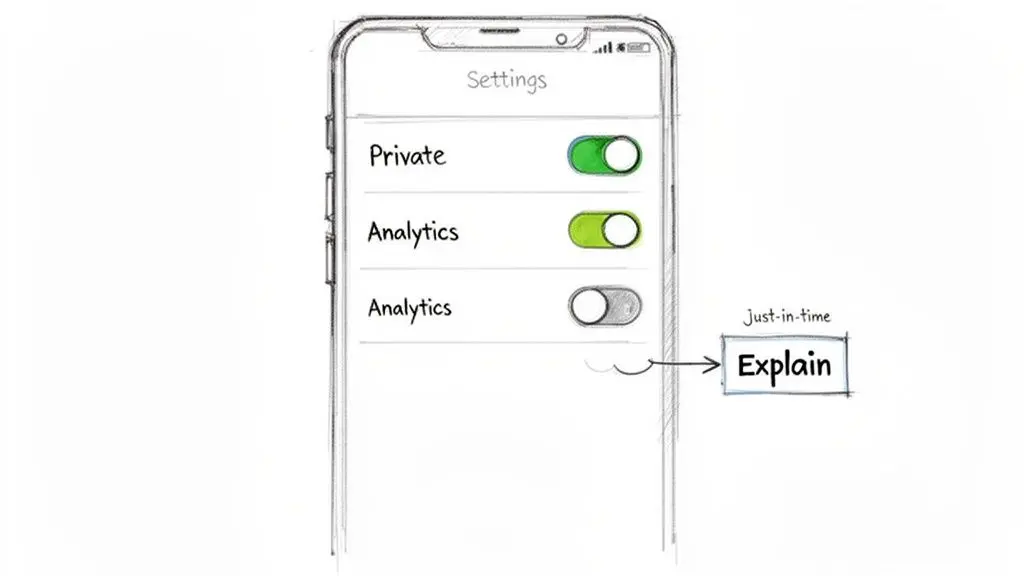
Pattern positivi per la UX della privacy
Una UX per la privacy efficace rende i valori predefiniti ovvi e mette gli utenti in condizione di fare scelte informate senza coercizione. Questo si ottiene attraverso chiarezza e contesto.
- Interruttori granulari, disattivati per impostazione predefinita: Sostituisci un singolo pulsante ‘Accetta tutto’ con interruttori separati e chiaramente etichettati per ‘Performance Analytics’ o ‘Marketing Personalizzato’. Entrambi devono essere disattivati per impostazione predefinita. L’opt-in deve essere un’azione chiara e affermativa.
- Avvisi Just-in-Time (JIT): Non richiedere accesso al microfono all’avvio dell’app. Invece, attiva la richiesta di permesso solo quando l’utente interagisce con una funzionalità che lo richiede, come un pulsante per memo vocali. Questa richiesta di sistema dovrebbe essere accompagnata da una chiara spiegazione sul perché l’accesso è necessario in quel momento.
- Informazione stratificata: Fornisci informazioni a diversi livelli di dettaglio. In un pannello delle impostazioni, usa etichette concise per una rapida scansione (es., ‘Condividi i dati di utilizzo per aiutarci a migliorare’). Un link ‘Per saperne di più’ accanto può espandere per fornire una spiegazione più dettagliata ma comunque in linguaggio semplice su quali dati vengono raccolti e per quale scopo.
Evitare pattern oscuri ingannevoli
I dark pattern sono manipolazioni dell’interfaccia progettate per indurre gli utenti a condividere più dati di quanto intendano. Queste pratiche non solo violano lo spirito del GDPR, ma erodono anche la fiducia degli utenti. Un esempio classico è una casella pre-selezionata per il consenso al marketing, ma i moderni dark pattern possono essere molto più sottili.
Identificare ed eliminare i dark pattern è una responsabilità centrale di ingegneria e design. Se un’interfaccia rende significativamente più difficile rinunciare rispetto all’iscriversi, è quasi certamente un dark pattern. Questo include l’uso di linguaggio confuso, la nascosta delle impostazioni sulla privacy o trucchi visivi come un pulsante ‘Rifiuta’ oscurato.
Pattern oscuri comuni da evitare:
- Misdirezione: Usare frasi vaghe come ‘Abilita Esperienza Avanzata’ per descrivere il tracciamento dati opzionale. Il linguaggio deve essere specifico e neutro.
- Azione forzata: Richiedere il consenso a trattamenti di dati non essenziali per accedere a una funzionalità core. Il consenso deve essere libero.
- Manipolazione estetica: Progettare il pulsante ‘Accetta’ grande e colorato mentre l’opzione ‘Rifiuta’ è piccola e grigia. Entrambe le scelte devono avere lo stesso peso visivo.
Una UX affidabile tratta l’utente con rispetto. Presuppone che gli utenti concederanno il consenso per funzionalità di valore se il valore viene spiegato in modo chiaro e onesto. Rendendo la configurazione più privata l’impostazione predefinita, dimostri rispetto per l’autonomia dell’utente fin dalla prima interazione.
Affrontare le sfide della privacy nei sistemi di AI e ML
I sistemi di Intelligenza Artificiale e Machine Learning introducono una nuova categoria di sfide per la privacy. Applicare i principi di privacy per impostazione predefinita (GDPR) qui richiede di esaminare l’intero ciclo di vita — dai dati di addestramento agli endpoint di inferenza live — sotto una lente diversa.
Il problema centrale è che questi sistemi apprendono dai dati, creando artefatti complessi che possono involontariamente divulgare informazioni personali. La pratica comune ma ad alto rischio di alimentare modelli con dati di produzione grezzi deve essere evitata. L’unico comportamento predefinito sicuro è una forte minimizzazione dei dati prima che qualsiasi modello interagisca con essi.
Minimizzare i dati negli input del modello
La strategia più efficace è la prevenzione: impedire che i dati personali raggiungano il modello. Questo richiede un approccio stratificato che copra sia l’addestramento sia l’inferenza in tempo reale.
Per l’addestramento del modello:
- Anonimizzare i dataset: Prima dell’addestramento, i dataset devono essere trattati per rimuovere o trasformare in modo irreversibile gli identificatori diretti. Questo va oltre la pseudonimizzazione, impiegando tecniche come aggregazione, iniezione di rumore (come nella privacy differenziale) o k-anonimato per rendere la re-identificazione computazionalmente impraticabile.
- Usare dati sintetici: Quando possibile, genera dati sintetici che rispecchino le proprietà statistiche del dataset reale ma non contengano informazioni personali effettive. Questo è un ottimo default per lo sviluppo iniziale del modello e per i test.
Per gli endpoint di inferenza, il focus è sul filtraggio in tempo reale. Implementa rigide validazioni degli input che scansionino attivamente e rifiutino o sanifichino gli input contenenti dati personali come indirizzi email o numeri di telefono, a meno che tali dati non siano esplicitamente necessari per la funzione.
I rischi nascosti di embeddings e log
Gli embeddings — vettori numerici che i modelli usano per rappresentare i dati — rappresentano un rischio significativo. Pur non essendo leggibili dall’uomo, non sono anonimi. La ricerca ha dimostrato che è possibile ricostruire parti dell’input originale dall’embedding.
Per impostazione predefinita, tratta gli embeddings derivati da dati personali con le stesse misure di sicurezza applicate ai dati grezzi. Non sono ‘anonimizzati’ solo perché sono vettori.
Il logging di sistema è un altro grande punto cieco. Gli sviluppatori sono spesso tentati di registrare gli input completi degli utenti e le uscite del modello per il debug, una pratica che viola direttamente la privacy per impostazione predefinita (GDPR).
Una solida strategia di logging per i sistemi AI include:
- Sanificare i log per impostazione predefinita: Tutti i log dovrebbero essere privati di dati personali prima di essere scritti su disco. Registra solo metadati, ID di tracciamento e frammenti sanificati necessari per il debug.
- Tracce di audit separate: Se il logging di dati sensibili è inevitabile per motivi di sicurezza o audit, deve andare in un sistema separato e altamente protetto con un periodo di conservazione breve e rigidi controlli di accesso.
Human-in-the-Loop come controllo predefinito
Infine, considera l’Articolo 22 del GDPR, che garantisce agli individui il diritto a non essere soggetti a decisioni basate esclusivamente su processi automatizzati che abbiano effetti legali o significativamente simili su di loro.
Per qualsiasi sistema AI ad alto rischio (es., valutazione del credito, reclutamento), un processo di revisione human-in-the-loop (HITL) dovrebbe essere l’architettura predefinita. Una decisione automatizzata non dovrebbe essere finale finché una persona qualificata non la revisiona e approva. Integrare questa salvaguardia nel sistema fin dal primo giorno è un’espressione critica della privacy per impostazione predefinita, garantendo equità, responsabilità e una chiara via di ricorso per l’utente.
Per valutare meglio i rischi specifici nei tuoi sistemi AI, usa la nostra checklist gratuita sui rischi e sulla privacy per l’IA: Checklist sui rischi e sulla privacy per l’IA per identificare e mitigare questi problemi precocemente.
Conclusione: punti chiave per i leader tecnici
Implementare la privacy per impostazione predefinita non è un progetto una tantum ma una disciplina continua. Richiede un cambiamento fondamentale dal rispetto reattivo alla conformità verso un’ingegneria proattiva guidata dalla privacy.
Ecco i punti chiave:
- Tratta la privacy come principio architetturale: Incorpora la protezione dei dati nel design del sistema fin dall’inizio. Un approccio reattivo genera debito tecnico e aumenta il rischio.
- Minimizza i dati in modo aggressivo: L’azione predefinita dovrebbe sempre essere di non raccogliere o trattare dati. Ogni punto dati deve avere una giustificazione chiara e documentata.
- Automatizza la gestione del ciclo di vita dei dati: Usa controlli tecnici come politiche TTL e job di eliminazione automatizzati per far rispettare programmaticamente le politiche di conservazione. I processi manuali sono soggetti a fallimento.
- Progetta per la trasparenza: L’interfaccia utente deve rendere le impostazioni più protettive per la privacy l’impostazione predefinita e dare agli utenti un controllo chiaro e granulare senza ricorrere ai dark pattern.
- Valida e documenta: Testa continuamente i tuoi controlli per la privacy e documentane l’implementazione. Questo fornisce prove verificabili che il sistema opera come progettato, trasformando la privacy per impostazione predefinita (GDPR) da obbligo legale a risorsa ingegneristica tangibile. Puoi leggere di più su questi risultati post-GDPR del MIT Sloan.
In ultima analisi, la tua documentazione e la tua architettura dovrebbero raccontare una storia semplice: ogni decisione di prodotto è stata presa con l’intento di proteggere i dati degli utenti per impostazione predefinita. Questa posizione proattiva semplifica le verifiche, snellisce processi come le richieste di accesso dei soggetti interessati e costruisce una base di fiducia con i tuoi utenti.
Presso Devisia, crediamo che la privacy sia una scelta architetturale, non una feature. Costruiamo software e sistemi AI affidabili e manutenibili con la protezione dei dati progettata fin dall’inizio. Se stai costruendo un prodotto digitale solido, mettiamoci in contatto. Scopri di più su https://www.devisia.pro.