
Ai sensi del GDPR, la privacy by design è un requisito legale, non una raccomandazione di best practice. Per CTO, architetti e responsabili di prodotto, questo obbligo trasforma la privacy da una verifica di conformità dell’ultimo minuto in un principio ingegneristico fondamentale. Stabilisce che la protezione dei dati deve essere integrata nell’architettura dei sistemi software fin dall’inizio del ciclo di vita dello sviluppo.
Perché la Privacy by Design è una sfida ingegneristica centrale
L’articolo 25 del GDPR attribuisce la responsabilità della protezione dei dati direttamente ai team che costruiscono il software. Il problema che molte organizzazioni affrontano è trattare la privacy come un ripensamento secondario—una funzionalità da “aggiungere” poco prima del lancio. Questo approccio reattivo è una strategia ad alto rischio che porta costantemente a sistemi fragili, vulnerabilità di sicurezza e un significativo accumulo di debito tecnico e di conformità.
Quando la privacy non è progettata nel sistema, le conseguenze sono tangibili. I team di ingegneria devono ricorrere a processi manuali inefficienti o a costosi rifacimenti del sistema per gestire diritti fondamentali degli interessati, come il diritto alla cancellazione. Questo non solo distoglie risorse dall’innovazione di prodotto, ma crea anche colli di bottiglia operativi ed erode la fiducia dei clienti. Il mancato inserimento della privacy nel design di base è la causa principale di molte violazioni dei dati e di molti fallimenti di conformità prevenibili.
Il costo reale della non conformità
Ignorare la privacy by design del GDPR espone un’azienda a significative sanzioni finanziarie e danni reputazionali. Dalla sua applicazione nel 2018, le autorità per la protezione dei dati (DPA) hanno dimostrato la volontà di far rispettare il regolamento con multe sostanziose. Un’analisi del Future of Privacy Forum (FPF) ha rilevato oltre 630 azioni di enforcement che hanno portato a 283 milioni di euro di multe nei primi anni. Casi di alto profilo, come la sanzione di 57 milioni di euro a Google, evidenziano i rischi finanziari. Puoi saperne di più sulle tendenze di enforcement delle DPA e sul loro impatto sull’IT.
Tuttavia, le sanzioni normative sono solo una parte del costo. Una violazione dei dati legata alla progettazione innesca una cascata di conseguenze costose:
- Sprint di ingegneria di emergenza: Distogliere ingegneri senior dallo sviluppo strategico del prodotto per rispondere con urgenza e in modo reattivo a un incidente.
- Danno reputazionale: La perdita della fiducia dei clienti incide direttamente sull’acquisizione e sulla retention degli utenti, causando un danno commerciale di lungo periodo.
- Interruzione operativa: Bloccare lo sviluppo del prodotto o le operazioni di core business per affrontare un fallimento di conformità.
Per un CTO, l’argomento a favore della privacy by design è una forma pragmatica di gestione del rischio. È un investimento nella costruzione di un prodotto resiliente, mantenibile e affidabile—più adatto alla crescita a lungo termine e meno soggetto a interruzioni normative.
Da obbligo legale a vantaggio competitivo
Considerare la privacy by design del GDPR esclusivamente attraverso la lente della conformità è un’occasione mancata. Un prodotto costruito su una solida base di privacy è intrinsecamente più sicuro, affidabile e meglio allineato alle aspettative moderne degli utenti.
I team che integrano i principi di privacy fin dall’inizio realizzano sistemi più facili da scalare, verificare e adattare alle normative future. Non si limitano a essere conformi; stanno costruendo un vantaggio competitivo. Dimostrare un impegno tangibile per la protezione dei dati attraverso un’accurata ingegneria crea una fiducia profonda e duratura che distingue i leader di mercato dai concorrenti. Questo posiziona la privacy come funzionalità centrale del prodotto, non solo come onere operativo.
Dai principi legali alla realtà ingegneristica
Per implementare efficacemente la Privacy by Design del GDPR, i responsabili tecnici devono tradurre il linguaggio legale in requisiti tecnici concreti. L’articolo 25 riguarda fondamentalmente due concetti distinti ma correlati: Privacy by Design e Privacy by Default. Confondere i due è un errore di implementazione comune e costoso.
Privacy by Design (PbD) è una filosofia architetturale. Richiede che le misure di protezione dei dati siano integrate nel design centrale del sistema fin dalle fasi più iniziali. Così come le caratteristiche di sicurezza strutturale di un grattacielo fanno parte del progetto iniziale, e non vengono aggiunte successivamente, i controlli di privacy devono essere parte integrante dell’architettura software.
Privacy by Default (PbbD) riguarda la configurazione. Impone che le impostazioni più protettive per la privacy siano abilitate per impostazione predefinita, senza alcun intervento dell’utente. Ciò significa che a un nuovo utente viene automaticamente garantito il massimo livello di privacy; per ridurre le impostazioni di privacy, ad esempio acconsentendo alla condivisione dei dati, deve compiere una scelta esplicita e affermativa, invece di essere costretto a rinunciare attivamente.
La tabella seguente chiarisce la distinzione in un contesto pratico di prodotto.
Privacy by Design vs Privacy by Default in pratica
| Aspetto | Privacy by Design (PbD) | Privacy by Default (PbbD) |
|---|---|---|
| Focus principale | L’architettura sottostante del sistema e i flussi di dati. | Le impostazioni rivolte all’utente e le configurazioni predefinite. |
| Tempistica | Implementata fin dall’inizio del progetto (Giorno 0). | Configurata al momento dell’onboarding dell’utente o dell’attivazione di una funzionalità. |
| Esempio software | Uso della crittografia a livello di database e della minimizzazione dei dati per progettazione. | Una casella di opt-in per l’analisi dati è deselezionata per impostazione predefinita. |
Uno è il fondamento; l’altro è l’impostazione di fabbrica. Entrambi sono necessari per la conformità, ma affrontano aspetti diversi della sfida della privacy.
I 7 principi fondamentali della PbD
Il framework Privacy by Design si basa su sette principi fondamentali. Per i responsabili tecnici, questi fungono da checklist pratica per costruire sistemi che siano sia conformi sia affidabili.
- Proattivo, non reattivo; preventivo, non correttivo: Progettare sistemi che anticipino e prevengano i fallimenti di privacy prima che si verifichino, anziché fare affidamento solo sulla risposta agli incidenti.
- La privacy come impostazione predefinita: Questo è il collegamento diretto con la PbbD. Assicurarsi che, se un utente non compie alcuna azione, i suoi dati personali siano completamente protetti di default.
- Privacy integrata nel design: La protezione dei dati deve essere una componente fondamentale dell’architettura centrale, influenzando schemi di database, contratti API e interazioni tra servizi.
- Funzionalità completa—somma positiva, non somma zero: Rifiutare il falso compromesso tra privacy e user experience. La sfida progettuale è offrire entrambe senza compromessi.
- Sicurezza end-to-end—protezione dell’intero ciclo di vita: Implementare misure di sicurezza robuste per proteggere i dati durante tutto il loro ciclo di vita—dalla raccolta all’elaborazione, all’archiviazione e alla cancellazione sicura.
- Visibilità e trasparenza—mantenere apertura: Fornire informazioni chiare e accessibili su quali dati vengono raccolti, sullo scopo della raccolta e su come vengono elaborati. Evitare processi opachi.
- Rispetto della privacy dell’utente—mantenere l’utente al centro: Il design del sistema deve dare potere agli utenti offrendo loro il controllo sui propri dati personali. Fornire scelte chiare e rispettarle in modo coerente.
Il mancato rispetto di questi principi introduce significativi rischi di business.
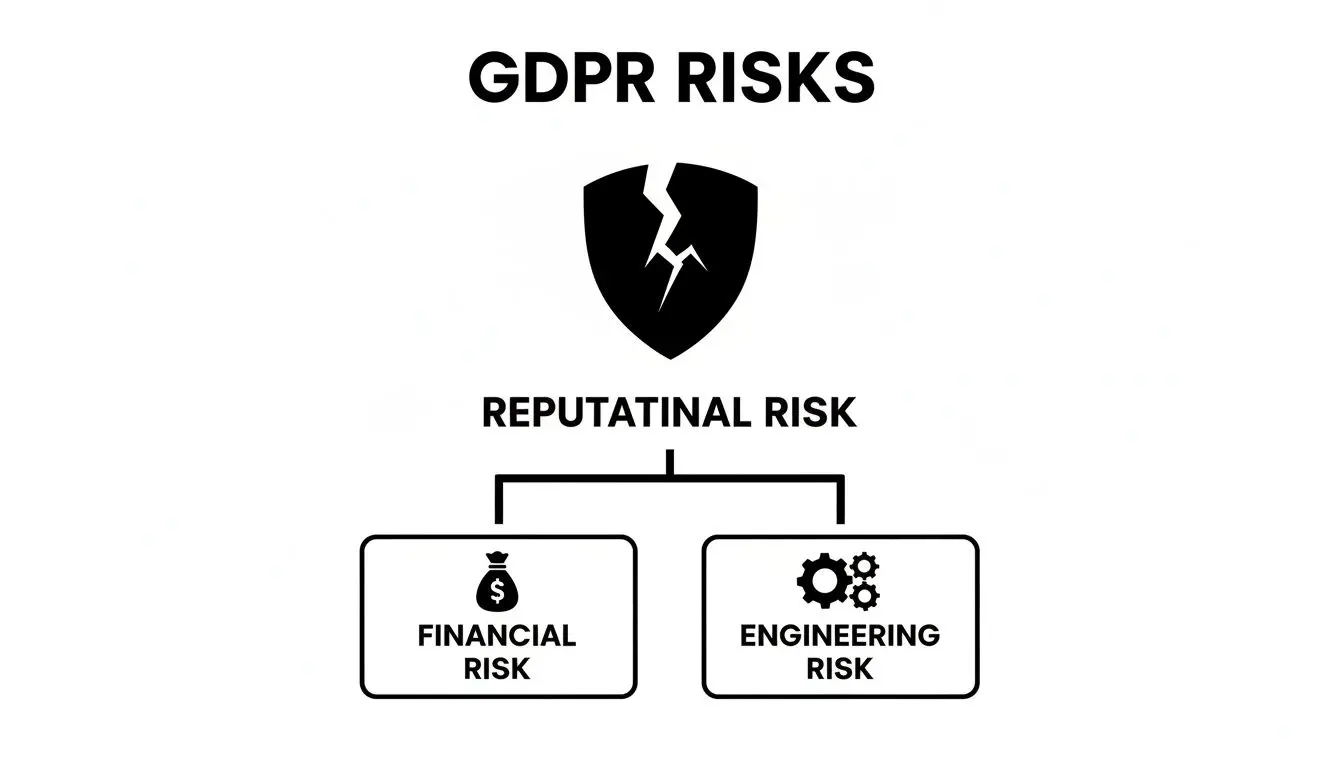
Come illustra questo diagramma, i fallimenti della privacy comportano costi finanziari e di ingegneria diretti, ma il rischio reputazionale complessivo è spesso il più dannoso e difficile da riparare.
Un errore comune è confondere una UI di consenso ben progettata con la vera Privacy by Design del GDPR. Se l’architettura sottostante raccoglie e conserva i dati in modo aggressivo per impostazione predefinita, nessun livello di rifinitura del front-end può correggere il fallimento fondamentale di conformità. Il sistema stesso deve essere costruito su questi principi.
Padroneggiare questi concetti è il primo passo verso la costruzione di sistemi software privacy-first che non siano solo conformi, ma anche architettonicamente solidi.
Integrare la privacy nella tua architettura software
Tradurre i principi legali in software robusto richiede decisioni architetturali deliberate, non solo l’adozione di strumenti specifici. Una privacy by design del GDPR efficace si riflette negli schemi di database, nei contratti API e nei pattern di comunicazione tra servizi. L’obiettivo è implementare controlli tecnici che rendano la privacy una proprietà intrinseca e non negoziabile del sistema.
Questi controlli non sono semplici obblighi di conformità; contribuiscono a prodotti più resilienti, mantenibili e sicuri. Un sistema progettato per la privacy può gestire in modo efficiente le richieste degli interessati, minimizza la sua superficie d’attacco e può adattarsi alle nuove normative senza richiedere una riprogettazione completa.
Progettare una vera minimizzazione dei dati
Il fallimento più comune nella minimizzazione dei dati è considerarla un problema di front-end. Un modulo UI minimale è inefficace se l’architettura backend raccoglie e memorizza indiscriminatamente i dati “per ogni evenienza”. Per essere efficace, la minimizzazione deve essere applicata ai livelli del modello dati e della persistenza.
Prendiamo in considerazione un servizio di profilo utente in una tipica applicazione SaaS. Un’implementazione ingenua potrebbe utilizzare un’unica tabella users molto ampia con numerose colonne nullable. Un approccio privacy by design segmenterebbe i dati in base alla necessità e alla finalità.
- Tabella di autenticazione: Contiene solo i dati essenziali per l’autenticazione (ad esempio,
user_id,hashed_password,email). - Tabella del profilo: Memorizza dati opzionali forniti dall’utente (ad esempio,
display_name,bio), collegati tramiteuser_id. - Log delle attività: Sono archiviati in un sistema separato, come un database time-series, con policy di retention rigorose e automatizzate.
Questa separazione architetturale rende strutturalmente difficile sovraccaricare la raccolta dei dati e semplifica l’implementazione dei diritti degli interessati. Per esempio, una richiesta di cancellazione può essere soddisfatta con un DELETE mirato sulla tabella Profile senza influire sui record di autenticazione principali.
Scegliere tra pseudonimizzazione e anonimizzazione
Gli ingegneri spesso usano questi termini in modo intercambiabile, ma la loro distinzione è cruciale ai sensi del GDPR. La pseudonimizzazione consiste nel sostituire gli identificatori diretti con un identificatore persistente ma artificiale (ad esempio, un UUID). Fondamentalmente, l’identità originale può essere ripristinata usando una chiave separata e conservata in modo sicuro. Al contrario, l’anonimizzazione è un processo irreversibile che interrompe in modo permanente il collegamento con una persona.
La scelta tra queste tecniche dipende interamente dal caso d’uso.
- Usare la pseudonimizzazione per: Analytics interni, quando è necessario tracciare i percorsi degli utenti senza esporre le identità personali al servizio di analytics. Il collegamento con la persona esiste, ma è protetto da forti controlli di accesso.
- Usare l’anonimizzazione per: Rilasci pubblici di dati o addestramento di modelli di machine learning in cui la re-identificazione deve essere impossibile. Spesso ciò richiede tecniche avanzate come k-anonymity o differential privacy.
Per esempio, una pipeline di product analytics potrebbe pseudonimizzare un user_id facendone l’hash con un salt segreto prima di inviare i dati degli eventi a un servizio di terze parti. Ciò consente l’analisi del comportamento degli utenti limitando l’accesso alla loro identità reale.
Il rischio principale è il “teatro della pseudonimizzazione”—l’uso di tecniche di mascheramento facilmente reversibili. Una strategia di pseudonimizzazione valida richiede che la chiave che collega lo pseudonimo alla persona sia archiviata separatamente e protetta da controlli di accesso rigorosi propri. Senza questa segregazione, la tecnica è solo offuscamento, non un controllo GDPR conforme.
Implementare controlli di accesso granulari
Il principio del privilegio minimo è un concetto di sicurezza fondamentale, centrale nell’ingegneria della privacy. Stabilisce che qualsiasi componente del sistema — un utente o un microservizio — debba avere accesso solo alla quantità minima di dati necessaria per svolgere la propria funzione.
Controllo degli accessi basato sui ruoli (RBAC) è un punto di partenza comune. Si definiscono ruoli (ad es. ‘SupportAgent’, ‘BillingAdmin’) e si assegnano a ciascuno permessi specifici. Un SupportAgent potrebbe avere accesso in sola lettura ai ticket di supporto, mentre un BillingAdmin può modificare i dettagli dell’abbonamento.
In un’architettura a microservizi, questo principio si estende alla comunicazione da servizio a servizio. Se un servizio OrderProcessing deve verificare un indirizzo di spedizione, dovrebbe richiedere solo i campi dell’indirizzo al servizio UserProfile, non l’intero profilo utente. Ciò viene applicato a livello di API gateway o di service mesh, limitando il “blast radius” di un servizio compromesso e creando una traccia chiara e verificabile dell’accesso ai dati.
Navigare le realtà aziendali della privacy by design
Sebbene i vantaggi architetturali siano chiari, implementare la privacy by design conforme al GDPR comporta compromessi pratici che incidono su tempistiche di progetto, budget e roadmap delle funzionalità. Riconoscere queste sfide consente alla leadership di inquadrare la conformità non come un vincolo, ma come un investimento strategico nella qualità e nella resilienza del prodotto.
Uno dei primi impatti riguarda la velocità di sviluppo iniziale. I team di ingegneria devono ora integrare le considerazioni sulla privacy in ogni fase, dalla modellazione dei dati all’implementazione dell’interfaccia utente. Ad esempio, costruire un sistema granulare di gestione del consenso è significativamente più complesso di un semplice banner “accetta tutto”, richiedendo più logica backend e sviluppo frontend, con conseguente allungamento delle tempistiche iniziali.
Allo stesso modo, un’efficace minimizzazione dei dati non consiste nel rimuovere alcuni campi da un modulo; significa stabilire una disciplina architetturale in cui ogni elemento dati abbia uno scopo e un ciclo di vita definiti. Questo sforzo iniziale rallenta lo sviluppo ma produce notevoli benefici a lungo termine, semplificando la conformità e riducendo la superficie d’attacco del sistema.
L’impatto finanziario e operativo
Oltre alle ore di sviluppo, esistono costi diretti associati all’implementazione della privacy by design. Questi possono includere investimenti in tecnologie che migliorano la privacy (PETs), infrastrutture cloud più complesse per la segregazione dei dati o tempo di ingegneria dedicato ad attività di conformità come la conduzione di una Valutazione d’Impatto sulla Protezione dei Dati (DPIA). La nostra guida sul processo di valutazione d’impatto sulla protezione dei dati tratta questo tema in dettaglio. Questi costi devono essere considerati nei budget di progetto.
L’impatto operativo del GDPR è ben documentato. Uno studio della George Mason Law Review sull’impatto della normativa europea sulla privacy nei mercati digitali ha rilevato che la sua introduzione è stata associata a una diminuzione di un terzo nel numero di app disponibili e a un dimezzamento del tasso di ingresso di nuove app.
Lo stesso studio ha osservato che, dopo il 2018, le aziende dell’UE hanno registrato un calo dell’8% dei profitti e una diminuzione del 2% delle vendite. Inoltre, l’analisi dei dati cloud ha mostrato che le aziende soggette al GDPR hanno ridotto l’archiviazione dei dati del 26% e l’elaborazione del 15% rispetto alle controparti statunitensi. Queste statistiche illustrano gli adeguamenti finanziari e operativi tangibili richiesti per conformarsi alle moderne normative sulla privacy.
Un approccio ingenuo considera questi costi un peso. Un approccio strategico li vede come un investimento nella qualità del prodotto e nella resilienza sul mercato. Un sistema progettato per la privacy è intrinsecamente più sicuro, più trasparente e meglio posizionato per guadagnare la fiducia degli utenti nel lungo periodo.
Bilanciare innovazione e conformità
Questo crea una tensione necessaria tra innovazione rapida e sviluppo conforme. I team di prodotto abituati a iterazioni basate sui dati — raccogliendo grandi quantità di informazioni per analizzare il comportamento degli utenti — devono ora operare con maggiore precisione. Il mantra “muoviti velocemente e rompi le cose” è incompatibile con un contesto normativo in cui ogni nuova funzionalità che tratta dati personali richiede una revisione sulla privacy.
Questo cambiamento impone vincoli ma favorisce anche uno sviluppo di prodotto più ponderato e intenzionale. La domanda guida passa da “Quali dati possiamo raccogliere?” a “Qual è la quantità minima di dati necessaria affinché questa funzionalità funzioni efficacemente?”. Questo vincolo spesso stimola soluzioni ingegneristiche più creative ed efficienti.
Considera questi compromessi da una prospettiva strategica:
- Rilascio iniziale più lento vs. riduzione del debito tecnico: investire tempo nell’architettura della privacy fin dall’inizio evita costosi e rischiosi interventi di retrofit in seguito.
- Raccolta dati limitata vs. insight di qualità superiore: i dati raccolti con uno scopo chiaro e con consenso sono spesso più significativi e più utili di enormi dataset non curati.
- Costi iniziali maggiori vs. minore rischio a lungo termine: il costo di implementare crittografia robusta, anonimizzazione e controlli degli accessi è trascurabile rispetto alle potenziali multe e ai danni reputazionali di una violazione dei dati.
In definitiva, integrare la privacy by design conforme al GDPR è una scelta strategica. Riconosce che, in un mercato di consumatori attenti alla privacy, la fiducia è una caratteristica fondamentale. Costruire tale fiducia non è un compito una tantum; è un impegno continuo incorporato nell’architettura del prodotto.
Applicare la privacy by design nei sistemi AI e LLM
L’integrazione di Intelligenza Artificiale (AI) e Large Language Model (LLM) introduce una nuova classe di sfide per la privacy. La natura ad alta intensità di dati di questi modelli spesso entra in conflitto con i principi fondamentali della privacy by design conforme al GDPR, come la minimizzazione dei dati e la limitazione delle finalità.
Un’implementazione ingenua può portare a un modello che memorizza e divulga involontariamente dati sensibili degli utenti. Un’AI addestrata su trascrizioni grezze del supporto clienti potrebbe, ad esempio, rivelare i dettagli personali di un utente in risposta a una richiesta non correlata di un altro utente. Non si tratta di un rischio ipotetico; è uno scenario grave di violazione dei dati causato dal mancato inserimento di controlli sulla privacy nel ciclo di vita dell’AI.
Mitigare l’esposizione dei dati nell’addestramento del modello
La prima linea di difesa è un controllo rigoroso sui dati di addestramento. Usare dati di produzione grezzi per l’addestramento del modello è un’attività ad alto rischio. I team di ingegneria dovrebbero invece implementare una strategia a più livelli per ridurre il rischio di questa fase.
Le soluzioni tecniche pratiche includono:
- Generazione di dati sintetici: invece di usare dati reali degli utenti, generare dataset strutturalmente identici ma completamente artificiali. Ciò consente al modello di apprendere schemi statistici senza esposizione a informazioni personali identificabili (PII).
- Anonimizzazione e pseudonimizzazione robuste: prima che qualsiasi dato entri nella pipeline di addestramento, deve essere ripulito dagli identificatori usando tecniche difficili o impossibili da invertire. Questo va oltre la semplice redazione.
- Minimizzazione dei dati by design: valutare criticamente la necessità di ogni punto dati. Il modello richiede il nome di un utente, o è sufficiente un ID pseudonimizzato? Progettare pipeline di dati che alimentino il modello solo con la quantità minima assoluta di dati necessaria per il suo compito.
Salvaguardie ingegneristiche per i sistemi in produzione
Una volta distribuito un modello, il profilo di rischio si sposta dai dati di addestramento agli input e output in tempo reale. In questa fase, i controlli di ingegneria sono imprescindibili per mantenere la privacy by design conforme al GDPR.
Un componente critico è l’implementazione di guardrail per prompt e output. Si tratta di livelli software che ispezionano i dati prima che raggiungano l’LLM e prima che vengano restituiti all’utente. I guardrail in input rilevano e rimuovono i PII dai prompt degli utenti, impedendo che dati sensibili vengano elaborati o registrati nei log. I guardrail in output analizzano le risposte del modello per garantire che non contengano informazioni sensibili rigurgitate.
Per esempio, un chatbot per il servizio clienti dovrebbe essere progettato per filtrare automaticamente i numeri delle carte di credito dalle richieste degli utenti prima che vengano inviate all’LLM. Anche la risposta del modello dovrebbe essere sottoposta a scansione per impedire la divulgazione dei dati di altri utenti.
L’idea che innovazione AI e privacy siano mutuamente esclusive è un falso dilemma. Quadri di privacy ben implementati creano i confini necessari per uno sviluppo AI sicuro e affidabile. In questo contesto, la conformità diventa un fattore abilitante dell’innovazione responsabile, non un ostacolo.
Garantire trasparenza e supervisione umana
Ai sensi del GDPR, le persone hanno diritti riguardo al processo decisionale automatizzato. Se un sistema AI prende decisioni con effetti significativi sugli utenti (ad es. credit scoring, assunzioni), sono richieste trasparenza e la possibilità di revisione umana.
Ciò significa che l’architettura del sistema deve supportare:
- Spiegabilità: la capacità di spiegare, in termini comprensibili, la base di una decisione del modello. Ciò richiede la registrazione degli input chiave e della logica per creare una traccia verificabile.
- Workflow Human-in-the-Loop (HITL): per decisioni ad alto impatto, il sistema deve essere progettato per segnalare casi limite o output con bassa confidenza affinché siano esaminati da una persona. Questo è sia un requisito di conformità sia una misura critica di controllo qualità.
Uno studio del Parlamento europeo del 2020 sui risultati relativi a GDPR e innovazione AI641530_EN.pdf) ha concluso che i principi del GDPR, come la minimizzazione dei dati e la mitigazione del rischio, sono compatibili con e possono persino incoraggiare uno sviluppo responsabile dell’AI. Trattando la privacy come un pilastro architettonico, i team possono costruire potenti sistemi AI che conquistano la fiducia degli utenti e resistono all’esame normativo.
Una checklist operativa per il tuo ciclo di sviluppo
Integrare la privacy by design conforme al GDPR nella pratica richiede un approccio sistematico integrato in tutto il ciclo di vita dello sviluppo software (SDLC). Non si tratta di un audit una tantum, ma di una disciplina continua.
Questa checklist fornisce un quadro per incorporare la protezione dei dati in ogni fase, rendendo la privacy un pilastro architettonico e non una correzione tardiva.
Fase di scoperta e progettazione
Prima che venga scritto qualsiasi codice, è qui che vengono stabiliti lo scopo e la base giuridica del trattamento dei dati. Gli errori in questa fase generano debito di conformità, molto più costoso da sanare del debito tecnico.
- Effettuare una Valutazione d’Impatto sulla Protezione dei Dati (DPIA): per qualsiasi nuova funzionalità che tratti dati personali su larga scala o coinvolga informazioni sensibili, una DPIA è una valutazione del rischio obbligatoria per identificare e mitigare proattivamente i rischi per la privacy.
- Mappare tutti i flussi di dati: creare e mantenere diagrammi dei flussi di dati che fungano da unica fonte di verità, dettagliando quali dati personali vengono raccolti, dove sono archiviati, quali servizi li elaborano e la loro destinazione finale.
- Definire una base giuridica per il trattamento: documentare la base giuridica ai sensi del GDPR (ad es. consenso, legittimo interesse) per ogni elemento di dati trattato. Se la raccolta non può essere giustificata, non raccoglierla.
Fase di sviluppo e implementazione
È qui che i principi architetturali vengono tradotti in codice. L’attenzione è sull’implementazione di controlli tecnici che applicano automaticamente le policy sulla privacy.
- Applicare la minimizzazione dei dati: assicurarsi che gli schemi del database e i contratti API includano solo i campi strettamente necessari per la funzionalità della caratteristica.
- Implementare una crittografia forte: utilizzare standard di crittografia attuali e robusti per tutti i dati personali, sia in transito (ad es. TLS 1.3) sia a riposo (ad es. AES-256).
- Costruire controlli di accesso robusti: Implementare il Controllo degli Accessi Basato sui Ruoli (RBAC) e controlli basati sugli attributi per applicare il principio del privilegio minimo sia per gli utenti interni sia per i microservizi.
- Creare registri di audit: Implementare una registrazione immutabile di tutti gli accessi o delle modifiche ai dati personali per garantire una traccia chiara e verificabile per le revisioni di sicurezza e conformità.
Un dettaglio di implementazione critico è rendere i controlli sulla privacy difficili da disattivare involontariamente. L’architettura del sistema dovrebbe rendere il percorso sicuro e conforme il percorso più semplice per gli sviluppatori.
Fase di testing e QA
I test devono andare oltre la correttezza funzionale e includere il controllo attivo di eventuali vulnerabilità della privacy. La protezione dei dati dovrebbe essere considerata una metrica di qualità fondamentale.
- Sviluppare casi di test specifici per la privacy: Scrivere test automatizzati per verificare che i controlli di accesso siano applicati correttamente e che le richieste di cancellazione dei dati rimuovano completamente ogni traccia dei dati di un utente da tutti i sistemi pertinenti.
- Usare dati anonimizzati o sintetici: Applicare una politica rigorosa contro l’uso di dati reali dei clienti negli ambienti di staging o di test.
Fase di distribuzione e manutenzione
Gli obblighi relativi alla privacy sono continui. Il monitoraggio continuo e le revisioni regolari sono necessari per gestire nuovi rischi e adattarsi alle modifiche del prodotto.
- Stabilire un piano di risposta alle violazioni dei dati: Mantenere e provare regolarmente un piano chiaro e attuabile per rilevare, segnalare e mitigare una violazione dei dati.
- Programmare revisioni periodiche della privacy: Rivalutare le mappe dei dati e le DPIA almeno una volta all’anno o ogni volta che vengono apportate modifiche significative al sistema. Per un’analisi più approfondita dell’altro lato di questo mandato, consulta la nostra guida su implementare la Privacy by Default ai sensi del GDPR.
Domande frequenti
Qual è la differenza tra Privacy by Design e una DPIA?
Privacy by Design e una Valutazione d’Impatto sulla Protezione dei Dati (DPIA) sono concetti correlati ma distinti. Privacy by Design è l’approccio strategico complessivo: la filosofia di integrare la protezione dei dati nell’intero ciclo di vita di un sistema.
Una DPIA è uno strumento specifico e formale di valutazione del rischio utilizzato per applicare tale filosofia a una particolare attività di trattamento ad alto rischio. Ad esempio, se stai lanciando una nuova funzionalità basata sull’AI che analizza il comportamento degli utenti, dovresti condurre una DPIA per quel progetto specifico.
In un’analogia, Privacy by Design è il codice antincendio completo dell’edificio. La DPIA è l’ispezione obbligatoria effettuata dal responsabile dei vigili del fuoco prima dell’apertura di una nuova area ad alto rischio come un laboratorio di chimica. L’ispezione è un’esecuzione tattica della strategia complessiva di sicurezza.
L’implementazione della Privacy by Design rallenta lo sviluppo?
Sì, può aggiungere tempo alle fasi iniziali dello sviluppo. Richiede più pianificazione preventiva, progettazione architetturale e documentazione, il che può sembrare una riduzione della velocità durante gli sprint iniziali.
Tuttavia, questo investimento iniziale previene ritardi e costi significativi in seguito. Un approccio proattivo riduce drasticamente il debito tecnico e di conformità a lungo termine, evita gli ultimi minuti di “interventi d’emergenza” per correggere i problemi di conformità ed elimina la necessità di costosi progetti ad alto rischio per adattare la privacy in un sistema già in produzione. Nel lungo periodo, ciò porta a prodotti più resilienti e manutenibili, consentendo in definitiva una crescita più rapida e sostenibile.
Una piccola startup può realisticamente implementare la Privacy by Design?
Sì, e in effetti è l’approccio più efficiente e conveniente per una startup. Implementare la Privacy by Design fin dall’inizio è molto meno costoso e complesso che ristrutturare un sistema difettoso dopo aver raggiunto il product-market fit e accumulato una quantità significativa di dati degli utenti.
Per una startup, ciò significa prendere decisioni fondamentali solide: raccogliere solo i dati assolutamente necessari per la proposta di valore principale, implementare una crittografia forte fin dal primo giorno, applicare controlli di accesso rigorosi e valutare attentamente i fornitori terzi per le loro pratiche di sicurezza e privacy. Queste scelte architetturali iniziali stabiliscono una base conforme e scalabile che mitiga i rischi e i costi futuri.