
Disaster recovery in the cloud is not merely about backing up data. It is the architectural discipline of ensuring an entire digital operation—applications, infrastructure, and data—can be restored predictably and reliably following a catastrophic failure. This responsibility is shared: your cloud provider guarantees their infrastructure, but you are accountable for recovering the applications and data built upon it.
This guide provides a pragmatic framework for CTOs, architects, and engineering leaders to design, implement, and validate a robust disaster recovery strategy that aligns with business objectives and technical realities.
Rethinking Disaster Recovery as an Architectural Mandate
A common and dangerous misconception is that cloud providers handle disaster recovery end-to-end. This assumption stems from a misunderstanding of the shared responsibility model. While providers like AWS or Azure ensure the resilience of their global infrastructure—data centers, networking, physical hardware—your organization is responsible for everything built on that foundation. This includes your applications, data, configurations, and access policies.
If a cloud region fails or a faulty deployment script corrupts a critical database, the provider’s obligation is to restore its own services. They are not responsible for restoring your specific application or recovering your lost data. That accountability lies entirely with your engineering and operations teams.
From IT Checklist to Business Imperative
Viewing disaster recovery as a compliance checkbox is a significant strategic blind spot. For technical and product leadership, a failure to implement a robust DR plan translates directly to severe business risks:
- Reputational Damage: Every minute of downtime erodes customer trust, which is difficult and expensive to regain.
- Irreversible Data Loss: Without a sound recovery strategy, critical business and user data can be permanently lost.
- Regulatory Penalties: Emerging frameworks like DORA (Digital Operational Resilience Act) in the financial sector and the NIS2 Directive for critical infrastructure impose stringent resilience requirements, with substantial fines for non-compliance.
The operational reality is that recovery is often incomplete. Recent disaster recovery statistics show that a significant percentage of organizations fail to achieve full data recovery after an incident, revealing a critical gap between planning and execution. This problem is particularly acute for SaaS data, where recovery times often fall far short of business expectations.
Defining Recovery Objectives as Business Decisions
At the core of any effective disaster recovery strategy are two key metrics. These are not merely technical parameters; they are fundamental business decisions with direct architectural implications.
Recovery Time Objective (RTO): What is the maximum acceptable duration of service unavailability before the business impact becomes unacceptable?
Recovery Point Objective (RPO): What is the maximum volume of data loss the business can tolerate, measured in time from the moment of failure?
An RTO of minutes necessitates a highly automated, pre-provisioned architecture, which is significantly more expensive than a solution supporting an RTO of 24 hours. Similarly, a near-zero RPO requires synchronous data replication, a non-trivial engineering challenge with considerable performance and cost overhead. These objectives are not toggles to be flipped but direct reflections of the business’s tolerance for downtime and data loss.
This guide will detail the architectural patterns and implementation considerations for building resilient systems that are both effective and cost-efficient. For additional context, our comparison of cloud vs. on-premise infrastructure provides a foundational overview.
Translating Business Needs into Engineering Metrics
Before designing a disaster recovery architecture, you must translate business requirements into quantifiable engineering targets. Recovery Time Objective (RTO) and Recovery Point Objective (RPO) are the core metrics that dictate the complexity, architecture, and cost of your DR strategy.
RTO defines the maximum acceptable downtime. RPO defines the maximum acceptable data loss. The answers to these two questions—“How long can we be offline?” and “How much data can we lose?”—drive all subsequent technical decisions.
Recovery Time Objective (RTO) Explained
RTO is the target time within which a business process must be restored after a disaster to avoid unacceptable consequences associated with a break in business continuity. The clock starts at the moment of failure and stops when the service is fully operational for users.
RTO directly reflects business impact. A customer-facing payments API may require an RTO of minutes, as each second of downtime translates to lost revenue and eroded trust. In contrast, an internal batch-processing system might tolerate an RTO of several hours without causing significant business disruption.
A low RTO (minutes) mandates extensive automation and pre-staged infrastructure for failover. A higher RTO (hours) may permit a well-documented manual recovery process.
Recovery Point Objective (RPO) Explained
RPO defines the maximum tolerable period in which data might be lost from an IT service due to a major incident. It is the delta between the last consistent data copy and the moment of failure.
An RPO of one hour implies a potential loss of up to one hour of data. A near-zero RPO, which means no data loss is acceptable, necessitates synchronous data replication—a technically complex and costly solution that impacts write latency.
Applying RTO and RPO in Practice
Not all systems are of equal importance. Applying aggressive DR goals uniformly across all applications is an inefficient allocation of resources. A more pragmatic approach is to tier services based on their criticality, defined in collaboration with business stakeholders.
Consider these two contrasting systems:
- E-commerce Transaction Database: As the system of record for orders and payments, this is a tier-one service. The business will require a near-zero RTO and RPO. Data loss is unacceptable, and the service must be restored almost instantaneously to prevent revenue loss. This requirement justifies an active-active or warm standby architecture.
- Analytics Dashboard: This internal system processes data overnight. It can tolerate an RPO of 24 hours, as data is refreshed daily. The RTO could be several hours; its unavailability would be an inconvenience but would not halt core business operations. A simple backup-and-restore strategy is sufficient and cost-effective.
Setting RTO and RPO is an exercise in managing trade-offs. While near-zero downtime and data loss are technically achievable, the cost is often prohibitive. Clarifying these objectives upfront ensures that engineering efforts are focused on protecting what is most valuable to the business, resulting in a DR strategy that is both effective and sustainable.
Exploring Core Cloud Disaster Recovery Architectures
With RTO and RPO defined, the next step is to select an appropriate architectural pattern. Choosing the right strategy for disaster recovery in the cloud requires balancing recovery speed, data loss tolerance, and implementation complexity against budgetary constraints.
Each approach exists on a spectrum of cost and performance. The optimal choice depends on the criticality of the application. This decision tree illustrates how business tolerance for downtime and data loss maps to specific architectural choices.
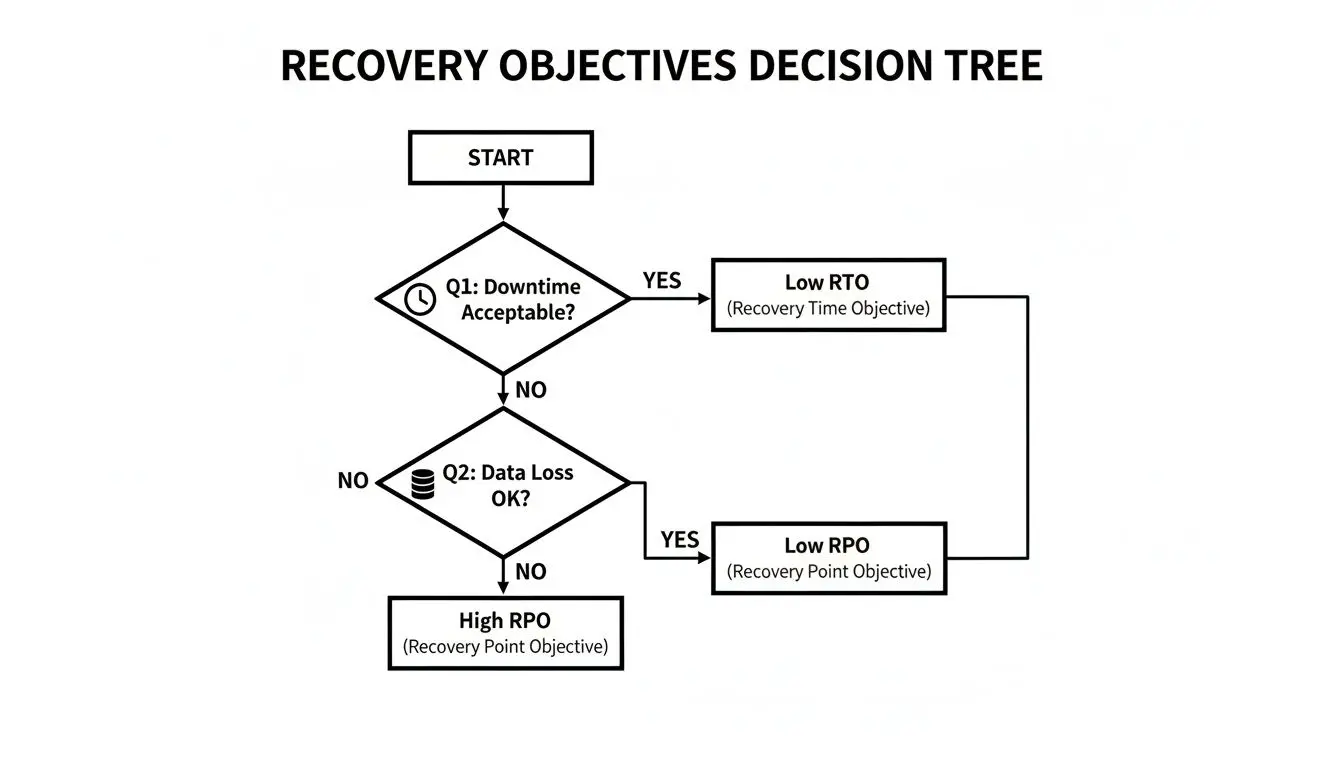
As the diagram indicates, a high tolerance for downtime allows for simpler, lower-cost strategies. Conversely, mission-critical systems with low tolerance for disruption demand more complex and expensive architectures that provide near-instantaneous recovery.
Let’s examine the four primary patterns, from the most basic to the most resilient.
Backup and Restore
This is the most fundamental and cost-effective DR architecture. The principle is simple: regularly back up data and application configurations to a secure, geographically separate location (typically another cloud region). In a disaster, a new environment is provisioned from scratch, and data is restored from these backups.
- How it Works: Automated snapshots of databases, virtual machines, and object storage are created at defined intervals. During a failover, engineers or automated scripts provision new infrastructure and initiate a data restore from the most recent backup.
- Typical RTO/RPO: The RTO is measured in hours or days, as it involves provisioning new resources and restoring large data volumes. The RPO is determined by the backup frequency; daily backups result in a potential RPO of up to 24 hours.
- Best Suited For: Non-critical systems, development/test environments, and internal applications where extended downtime is acceptable.
The primary trade-off is time. While inexpensive to operate, the recovery process is slow and carries the highest risk of data loss among these patterns.
Pilot Light
The Pilot Light strategy offers a balance between the slowness of Backup and Restore and the higher costs of more advanced approaches. It involves maintaining a minimal, scaled-down version of the core infrastructure in the recovery region. This “pilot light” is always running but does not handle production traffic.
The analogy is a gas furnace: the pilot light is always on, ready to ignite the main burners when needed. In this architecture, essential components like a small database replica and a single application server run idle. During a disaster, the infrastructure is scaled out to full production capacity.
This approach significantly reduces RTO compared to Backup and Restore because the core infrastructure is already provisioned. Failover becomes a process of scaling and traffic redirection, not building from zero.
- How it Works: A minimal footprint of infrastructure, including a replicated database, runs continuously in the DR region. Data is asynchronously replicated from the primary region.
- Typical RTO/RPO: RTO is typically minutes to a few hours. RPO can be seconds or minutes, depending on data replication latency.
- Best Suited For: Business-critical applications where an RTO of several hours is unacceptable, but the cost of a fully duplicated environment is not justified.
Warm Standby
A Warm Standby architecture extends the Pilot Light concept. Instead of a minimal core, a fully scaled—but idle—version of the production environment is maintained in the recovery region. The system is ready to take over traffic almost immediately.
All servers, databases, and services are running and synchronized with the production environment but do not serve user requests. The key distinction from Pilot Light is that no scaling is required during failover; the infrastructure is only activated. The primary technical challenge is maintaining data consistency through continuous replication. Failover is often as simple as a DNS change.
- How it Works: A full-scale, idle copy of the production environment runs in a separate region with continuous data replication.
- Typical RTO/RPO: RTO is reduced to minutes. RPO is extremely low, often seconds.
- Best Suited For: Mission-critical services, such as e-commerce platforms or core SaaS applications, where downtime has a direct and significant financial impact.
Multi-Region Active-Active
This is the most resilient—and most complex—disaster recovery architecture, offering near-zero downtime and data loss. In an Active-Active configuration, the application runs simultaneously in two or more geographic regions, with traffic load-balanced between them. Both environments are live and actively serving users.
If one region fails, traffic is automatically rerouted to the remaining healthy region(s) without manual intervention. This architecture eliminates the concept of a “failover event”; a regional outage is treated as a routine operational event. However, this level of resilience introduces significant engineering complexity and cost.
- Challenges: Managing data replication and consistency across geographically distributed databases is a major engineering hurdle. Complex networking and traffic routing are required to direct users to the nearest healthy region while maintaining data locality and consistency.
- Typical RTO/RPO: Both RTO and RPO are near-zero.
- Best Suited For: Global applications with the strictest uptime requirements, such as financial trading platforms or large-scale consumer services, where any amount of downtime is unacceptable.
Comparing Cloud Disaster Recovery Architectures
This table provides a side-by-side comparison to clarify the trade-offs between the four main strategies.
| Architecture | Typical RTO | Typical RPO | Relative Cost | Implementation Complexity | Best Suited For |
|---|---|---|---|---|---|
| Backup and Restore | Hours to Days | Minutes to 24 Hours | Low | Low | Non-critical apps, dev/test environments |
| Pilot Light | Minutes to Hours | Seconds to Minutes | Medium | Medium | Business-critical apps with moderate downtime tolerance |
| Warm Standby | Minutes | Seconds | High | High | Mission-critical services with high financial impact |
| Multi-Region Active-Active | Near-Zero | Near-Zero | Very High | Very High | Global apps where any downtime is unacceptable |
As shown, there is a direct correlation between cost, complexity, and recovery performance. The key is to align the architectural choice with the business value of the application it protects.
Leveraging Automation for Reliable Recovery
A manual disaster recovery plan is a plan destined to fail. During a real incident, stress levels are high, engineers are under immense pressure, and the probability of human error increases dramatically. Relying on static documentation and manual checklists is a recipe for extended downtime and failed recovery attempts.
The only path to predictable, rapid, and reliable recovery is through automation and orchestration. By treating recovery processes as code, you transform them from abstract plans into testable, repeatable systems.
From Static Runbooks to Executable Code
The traditional DR runbook—a document stored in a wiki—is often obsolete upon creation. Modern systems evolve too quickly for manual documentation to remain accurate. The solution is to codify the entire recovery process.
This begins with Infrastructure as Code (IaC). Tools like Terraform or AWS CloudFormation allow you to define your entire cloud environment—servers, networks, security groups, load balancers—in version-controlled files. This enables you to provision a consistent, identical environment in a recovery region with a single command, eliminating configuration drift and manual setup errors.
An automated recovery process provides not just speed but also consistency. Code executes identically every time, removing the guesswork and panic that derail manual efforts during a high-stakes outage.
This approach effectively turns your runbook into a set of executable scripts, integrating DR into your CI/CD strategy. You can learn more about this integration in our guide to building a robust CI/CD pipeline.
Automating Failover and Health Checks
Beyond infrastructure provisioning, automation is critical for the failover process itself. Every manual step introduces a potential point of failure. These actions should be scripted and, where feasible, automated.
Key areas for automation include:
- DNS Failover: Services like AWS Route 53 or Azure Traffic Manager can automatically reroute traffic to a healthy recovery region based on configurable health checks. This is the primary mechanism for redirecting production traffic with minimal downtime.
- Database Promotion: Scripts must handle the promotion of a read-replica database in the recovery region to become the new primary master. This is a critical procedure that must be orchestrated precisely to prevent data corruption.
- Post-Failover Validation: Once the failover is complete, automated health checks should run immediately to confirm that all services are operational, connected, and serving traffic correctly before the recovery is declared successful.
The Hidden Risks of Manual Steps
Even with a strong automation strategy, the greatest threats often lie in undocumented manual interventions performed by engineers under pressure. These “heroic” fixes during an outage are rarely documented and almost never repeatable, creating a false sense of security for subsequent incidents.
Many organizations remain unprepared. A high percentage of businesses using cloud services protect fewer than half of their applications with a viable DR plan. The primary challenges cited are system complexity, IT personnel constraints, and skill shortages.
These statistics underscore the necessity of automation. By building automation and testability into your disaster recovery in the cloud strategy from the outset, you transition from a reactive, hope-based approach to a proactive, engineering-driven discipline that delivers proven resilience.
Validating Your Recovery Plan Through Rigorous Testing
A disaster recovery plan that exists only on paper is a liability, not an asset. It is an untested hypothesis about your system’s resilience. The only way to convert that hypothesis into a reliable capability is through regular, rigorous testing.
Without validation, you have no assurance that automated scripts will execute correctly, that data backups are viable, or that your team understands their roles and responsibilities during a crisis. For compliance and product leaders, an untested plan is a direct threat to regulatory standing and customer trust. Functionally, it is no better than having no plan at all.
The financial stakes are immense. Downtime costs can range from thousands to millions of dollars per hour. More critically, a significant number of companies that experience a major data disaster without a tested recovery plan fail to remain in business. As detailed in an analysis of disaster recovery at Penncomp.com, untested bespoke systems often lead to slow restores and corrupted backups.
Moving Beyond DR Theatre
A common failure mode is “DR theatre”—superficial tests that create a false sense of security. These exercises, such as restarting a single service or performing a basic data integrity check, may satisfy a compliance requirement but do not simulate the cascading failures of a genuine disaster.
Effective validation requires pushing systems and teams to their operational limits. It means simulating failures without warning, testing obscure dependencies, and verifying that every step in the recovery process functions as designed. The objective is not to pass a test but to actively identify and remediate weaknesses before a real incident exploits them.
Practical Methodologies for Effective Testing
A mature approach to disaster recovery in the cloud employs a layered testing strategy. Instead of a single, large-scale annual drill, different types of tests should be integrated into your operational cadence.
-
Tabletop Exercises: These are structured, discussion-based sessions where the response team walks through a simulated disaster scenario. The goal is to validate the clarity of the runbook, identify communication gaps, and ensure all participants understand their roles. This is a low-risk method for testing the human elements of the plan.
-
Partial Failover Drills: In these drills, you simulate the failure of a specific service or component in a non-production environment. For example, failing over a single database replica or an application tier validates specific automation scripts and technical dependencies without risking production availability.
-
Full-Scale Simulations: This is the most comprehensive test, involving a complete failover of the entire production environment to the recovery region. While disruptive and resource-intensive, it is the only way to validate the end-to-end recovery process under realistic conditions. These simulations are essential for mission-critical systems and must be meticulously planned.
A successful test is one from which you learn. The post-mortem is the most valuable part of the exercise. Document every finding, update automation scripts and runbooks, and create tickets to address the identified weaknesses.
A culture of continuous validation is what distinguishes resilient organizations from vulnerable ones. Testing should not be a feared annual event but a routine practice that builds genuine confidence in your ability to recover.
Moving from Resilience Planning to Operational Reality
Disaster recovery in the cloud is not a project to be completed but a core architectural quality that must be continuously maintained and aligned with business objectives. A plan on paper is meaningless during a real outage; only a proven, operational capability can safeguard your organization.
The process begins by translating business needs into engineering constraints through well-defined RTO and RPO metrics. These objectives drive the selection of an appropriate architecture—from a cost-effective Backup and Restore model to a fully resilient Active-Active configuration—forcing explicit trade-offs between cost, complexity, and recovery speed.
Embracing Continuous Improvement
However, a sound design is only the starting point. Without robust automation and rigorous, regular testing, even the best-laid plans degrade into unreliable theories. Automation transforms static runbooks into executable, repeatable code. Testing validates that both your systems and your teams can perform under pressure. This approach shifts DR from a one-time setup to a cycle of continuous improvement.
True resilience is not achieved by writing a plan; it is built by consistently validating your ability to recover. Each test, whether a tabletop exercise or a full simulation, is an opportunity to find and fix weaknesses before a real disaster does it for you.
The ultimate goal is to move beyond mere planning and into a state of constant operational readiness. This disciplined, engineering-driven approach ensures your digital products remain available and trustworthy, protecting both your customers and your business. For technical leaders, fostering this culture is a critical component of system health and long-term maintainability, echoing the principles of continuous improvement seen in how Kaizen projects maintain existing systems.
Frequently Asked Questions
Pragmatic answers to common questions from technical and business leaders regarding architectural trade-offs, hidden costs, and realistic testing cadences.
How Do I Choose the Right Disaster Recovery Architecture?
There is no single “best” architecture; the choice is always a trade-off between cost, complexity, and your RTO/RPO goals. A tiered approach based on application criticality is the most effective and financially sound strategy.
Categorize your services:
- Mission-Critical Systems: These include services like payment gateways or core user authentication, where any downtime directly impacts revenue and trust. These systems justify the expense of a Warm Standby or Multi-Region Active-Active architecture to achieve a near-zero RTO.
- Business-Critical Applications: These services are essential for operations but can tolerate brief interruptions. A Pilot Light architecture provides a sensible balance between recovery speed and operational cost for this tier.
- Non-Essential Systems: Internal tools, analytics dashboards, and development environments rarely require immediate recovery. A simple and low-cost Backup and Restore strategy is sufficient.
By aligning resilience investment with business impact, you can develop a DR plan that is both effective and sustainable.
What Are the Biggest Hidden Costs?
The most significant and often overlooked costs in cloud DR are operational, not infrastructural. While the monthly bill for idle resources is predictable, other expenses can be substantial.
Be mindful of these three areas:
- Engineering Overhead: The engineering hours required to build, maintain, and test IaC scripts, manage data replication, and keep runbooks current represent a significant and ongoing cost. This workload grows as your systems evolve.
- Data Egress Fees: Failing over to another region involves transferring large volumes of data across the cloud provider’s network. These egress fees can be substantial and are frequently omitted from initial cost models.
- Complexity Tax: Highly resilient architectures, particularly Active-Active, introduce significant complexity. Managing state and ensuring data consistency across geographically distributed regions creates long-term engineering and maintenance costs associated with diagnosing and fixing subtle, distributed-systems bugs.
How Often Should We Test Our Disaster Recovery Plan?
Your testing frequency should align with your rate of system change. A static internal application has different testing requirements than a customer-facing SaaS platform with weekly deployments.
For mission-critical systems, a reasonable cadence is to conduct partial failover drills quarterly and a full-scale simulation annually. This rhythm builds operational confidence without causing excessive disruption.
A more advanced approach integrates DR validation into the development lifecycle. Any major architectural change—such as replacing a database or introducing a new microservice—should trigger a targeted recovery test for the affected component. This transforms testing from an annual event into a continuous engineering practice, ensuring your DR plan remains synchronized with your system’s reality.
A robust disaster recovery strategy is a cornerstone of any reliable digital product. At Devisia, we help organisations design and build resilient, maintainable systems grounded in pragmatic architectural choices and clear business objectives. Learn more about how we turn vision into dependable software at https://www.devisia.pro.