
Il disaster recovery nel cloud non riguarda semplicemente il backup dei dati. È la disciplina architetturale che garantisce che un’intera operazione digitale—applicazioni, infrastruttura e dati—possa essere ripristinata in modo prevedibile e affidabile a seguito di un guasto catastrofico. Questa responsabilità è condivisa: il tuo provider cloud garantisce la propria infrastruttura, ma sei tu a essere responsabile del recupero delle applicazioni e dei dati costruiti sopra di essa.
Questa guida fornisce un framework pragmatico per CTO, architetti e responsabili ingegneristici per progettare, implementare e validare una strategia di disaster recovery solida, allineata agli obiettivi di business e alle realtà tecniche.
Ripensare il Disaster Recovery come un Imperativo Architetturale
Un malinteso comune e pericoloso è che i provider cloud gestiscano il disaster recovery end-to-end. Questa supposizione deriva da una incomprensione del modello di responsabilità condivisa. Sebbene provider come AWS o Azure garantiscano la resilienza della loro infrastruttura globale—data center, networking, hardware fisico—la tua organizzazione è responsabile di tutto ciò che viene costruito su quella base. Questo include le tue applicazioni, i dati, le configurazioni e le policy di accesso.
Se una regione cloud va in fault o uno script di deployment difettoso corrompe un database critico, l’obbligo del provider è ripristinare i propri servizi. Non è responsabile del ripristino della tua specifica applicazione o del recupero dei tuoi dati persi. Quella responsabilità ricade interamente sui tuoi team di engineering e operations.
Da checklist IT a imperativo di business
Considerare il disaster recovery come una semplice casella di conformità è una grave lacuna strategica. Per la leadership tecnica e di prodotto, il mancato implementazione di un piano DR solido si traduce direttamente in seri rischi di business:
- Danno reputazionale: Ogni minuto di inattività erode la fiducia dei clienti, che è difficile e costosa da riconquistare.
- Perdita irreversibile di dati: Senza una strategia di recupero adeguata, i dati critici aziendali e degli utenti possono andare persi in modo permanente.
- Sanzioni regolatorie: Framework emergenti come DORA (Digital Operational Resilience Act) nel settore finanziario e la Direttiva NIS2 per le infrastrutture critiche impongono requisiti stringenti di resilienza, con multe significative in caso di mancata conformità.
La realtà operativa è che il recupero è spesso incompleto. Le recenti statistiche sul disaster recovery mostrano che una percentuale significativa di organizzazioni non riesce a ottenere un recupero completo dei dati dopo un incidente, evidenziando un divario critico tra pianificazione ed esecuzione. Questo problema è particolarmente acuto per i dati SaaS, dove i tempi di recupero spesso risultano ben al di sotto delle aspettative del business.
Definire gli obiettivi di recupero come decisioni di business
Al centro di qualsiasi strategia efficace di disaster recovery ci sono due metriche chiave. Non si tratta semplicemente di parametri tecnici; sono decisioni di business fondamentali con implicazioni architetturali dirette.
Recovery Time Objective (RTO): Qual è la massima durata accettabile di indisponibilità del servizio prima che l’impatto sul business diventi inaccettabile?
Recovery Point Objective (RPO): Qual è il massimo volume di perdita di dati che il business può tollerare, misurato nel tempo a partire dal momento del guasto?
Un RTO di minuti richiede un’architettura altamente automatizzata e pre-provisioned, significativamente più costosa di una soluzione che supporti un RTO di 24 ore. Allo stesso modo, un RPO quasi pari a zero richiede una replica sincrona dei dati, una sfida ingegneristica non banale con un notevole impatto su prestazioni e costi. Questi obiettivi non sono interruttori da attivare, ma riflessi diretti della tolleranza del business ai downtime e alla perdita di dati.
Questa guida illustrerà in dettaglio i pattern architetturali e le considerazioni di implementazione per costruire sistemi resilienti che siano al tempo stesso efficaci ed efficienti in termini di costi. Per ulteriore contesto, il nostro confronto tra cloud e infrastruttura on-premise fornisce una panoramica di base.
Tradurre le esigenze di business in metriche ingegneristiche
Prima di progettare un’architettura di disaster recovery, devi tradurre i requisiti di business in obiettivi ingegneristici quantificabili. Recovery Time Objective (RTO) e Recovery Point Objective (RPO) sono le metriche fondamentali che determinano la complessità, l’architettura e il costo della tua strategia DR.
L’RTO definisce il downtime massimo accettabile. L’RPO definisce la massima perdita di dati accettabile. Le risposte a queste due domande—“Per quanto tempo possiamo essere offline?” e “Quanti dati possiamo perdere?”—guidano tutte le decisioni tecniche successive.
Recovery Time Objective (RTO) spiegato
RTO è il tempo obiettivo entro il quale un processo di business deve essere ripristinato dopo un disastro per evitare conseguenze inaccettabili associate a una interruzione della continuità operativa. Il cronometro parte nel momento del guasto e si ferma quando il servizio è pienamente operativo per gli utenti.
L’RTO riflette direttamente l’impatto sul business. Un’API di pagamenti rivolta ai clienti può richiedere un RTO di pochi minuti, poiché ogni secondo di downtime si traduce in perdita di ricavi ed erosione della fiducia. Al contrario, un sistema interno di batch processing potrebbe tollerare un RTO di diverse ore senza causare significative interruzioni operative.
Un RTO basso (minuti) richiede un’automazione estesa e un’infrastruttura preallestita per il failover. Un RTO più alto (ore) può consentire un processo di ripristino manuale ben documentato.
Recovery Point Objective (RPO) spiegato
RPO definisce il periodo massimo tollerabile in cui i dati potrebbero andare persi da un servizio IT a causa di un incidente grave. È il delta tra l’ultima copia consistente dei dati e il momento del guasto.
Un RPO di un’ora implica una potenziale perdita fino a un’ora di dati. Un RPO quasi pari a zero, che significa che non è accettabile alcuna perdita di dati, richiede una replica sincrona dei dati—una soluzione tecnicamente complessa e costosa che influisce sulla latenza di scrittura.
Applicare RTO e RPO nella pratica
Non tutti i sistemi hanno la stessa importanza. Applicare obiettivi DR aggressivi in modo uniforme a tutte le applicazioni è un’allocazione inefficiente delle risorse. Un approccio più pragmatico consiste nel classificare i servizi in base alla loro criticità, definita in collaborazione con gli stakeholder di business.
Considera questi due sistemi contrastanti:
- Database transazionale e-commerce: In quanto sistema di riferimento per ordini e pagamenti, questo è un servizio di primo livello. Il business richiederà un RTO e un RPO quasi pari a zero. La perdita di dati non è accettabile e il servizio deve essere ripristinato quasi istantaneamente per evitare perdite di ricavi. Questo requisito giustifica un’architettura active-active o warm standby.
- Dashboard di analytics: Questo sistema interno elabora i dati durante la notte. Può tollerare un RPO di 24 ore, poiché i dati vengono aggiornati quotidianamente. L’RTO potrebbe essere di diverse ore; la sua indisponibilità sarebbe un disagio ma non bloccherebbe le operazioni core del business. Una semplice strategia di backup e ripristino è sufficiente ed economicamente vantaggiosa.
Definire RTO e RPO è un esercizio di gestione dei trade-off. Sebbene downtime e perdita di dati quasi pari a zero siano tecnicamente raggiungibili, il costo è spesso proibitivo. Chiarire questi obiettivi fin dall’inizio garantisce che gli sforzi di engineering siano concentrati sulla protezione di ciò che è più prezioso per il business, dando vita a una strategia DR efficace e sostenibile.
Esplorare le principali architetture di disaster recovery nel cloud
Definiti RTO e RPO, il passo successivo è selezionare un pattern architetturale appropriato. Scegliere la strategia giusta per il disaster recovery nel cloud richiede di bilanciare velocità di recupero, tolleranza alla perdita di dati e complessità di implementazione rispetto ai vincoli di budget.
Ogni approccio esiste lungo uno spettro di costi e prestazioni. La scelta ottimale dipende dalla criticità dell’applicazione. Questo albero decisionale illustra come la tolleranza aziendale per downtime e perdita di dati si traduca in scelte architetturali specifiche.
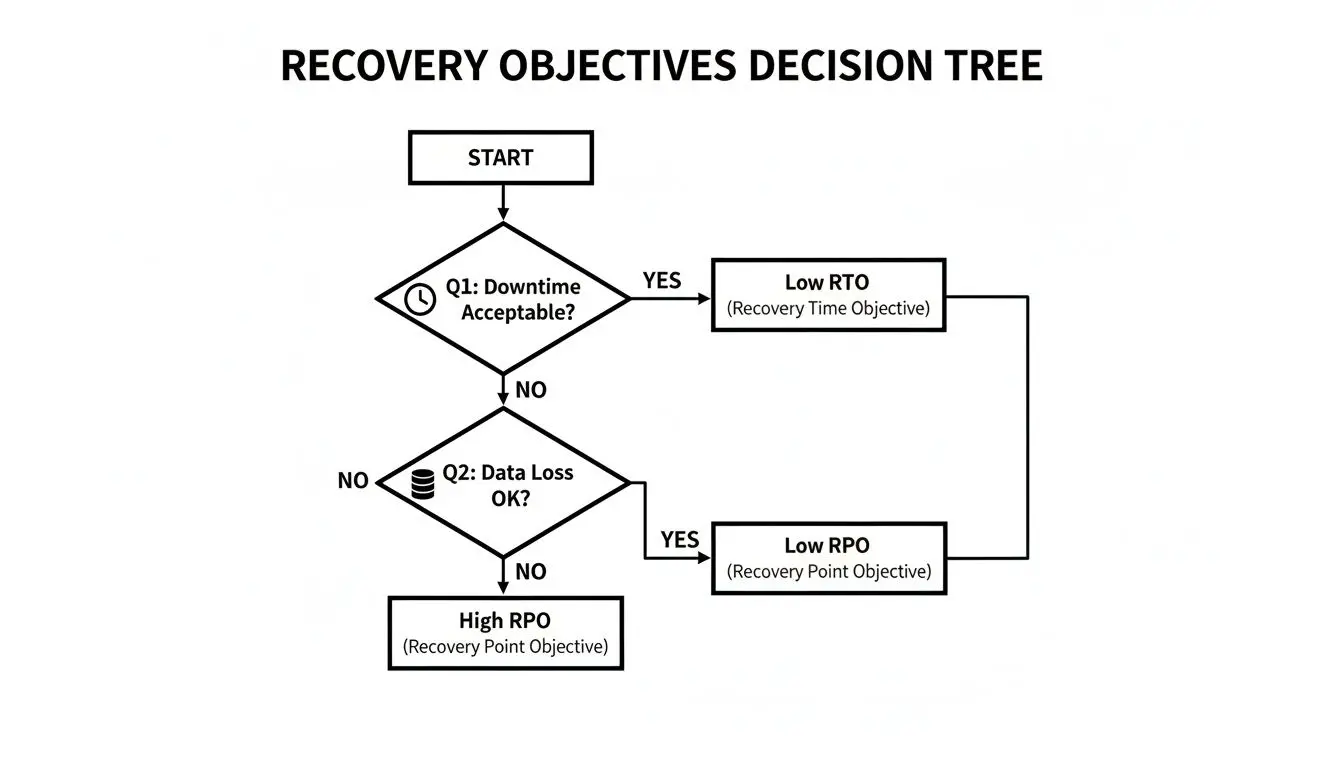
Come indica il diagramma, un’elevata tolleranza al downtime consente strategie più semplici e meno costose. Al contrario, i sistemi mission-critical con bassa tolleranza alle interruzioni richiedono architetture più complesse e costose che offrano un recupero quasi istantaneo.
Esaminiamo i quattro pattern principali, dal più basilare al più resiliente.
Backup e ripristino
Questa è l’architettura DR più fondamentale ed economica. Il principio è semplice: eseguire regolarmente il backup dei dati e delle configurazioni applicative in una posizione sicura e geograficamente separata (tipicamente un’altra regione cloud). In caso di disastro, un nuovo ambiente viene provisionato da zero e i dati vengono ripristinati da questi backup.
- Come funziona: Snapshot automatizzati di database, macchine virtuali e object storage vengono creati a intervalli definiti. Durante un failover, gli ingegneri o script automatizzati provisionano nuova infrastruttura e avviano un ripristino dei dati dal backup più recente.
- RTO/RPO tipici: L’RTO si misura in ore o giorni, poiché comporta il provisioning di nuove risorse e il ripristino di grandi volumi di dati. L’RPO è determinato dalla frequenza dei backup; backup giornalieri comportano un potenziale RPO fino a 24 ore.
- Più adatto per: Sistemi non critici, ambienti di sviluppo/test e applicazioni interne in cui è accettabile un downtime prolungato.
Il principale compromesso è il tempo. Pur essendo economico da gestire, il processo di recupero è lento e presenta il rischio più elevato di perdita di dati tra questi pattern.
Pilot Light
La strategia Pilot Light offre un equilibrio tra la lentezza del Backup e ripristino e i costi più elevati di approcci più avanzati. Consiste nel mantenere una versione minimale e ridotta dell’infrastruttura core nella regione di recovery. Questa “pilot light” è sempre attiva, ma non gestisce il traffico di produzione.
L’analogia è quella di una stufa a gas: la fiamma pilota è sempre accesa, pronta ad accendere i bruciatori principali quando necessario. In questa architettura, componenti essenziali come una piccola replica del database e un singolo application server rimangono inattivi. Durante un disastro, l’infrastruttura viene scalata fino alla piena capacità di produzione.
Questo approccio riduce significativamente l’RTO rispetto al Backup e ripristino perché l’infrastruttura core è già provisionata. Il failover diventa un processo di scaling e di reindirizzamento del traffico, non di costruzione da zero.
- Come funziona: Un footprint minimo di infrastruttura, inclusa una replica del database, gira continuamente nella regione DR. I dati vengono replicati in modo asincrono dalla regione primaria.
- RTO/RPO tipici: L’RTO è in genere da minuti a poche ore. L’RPO può essere di secondi o minuti, a seconda della latenza di replica dei dati.
- Più adatto per: Applicazioni business-critical in cui un RTO di diverse ore non è accettabile, ma il costo di un ambiente completamente duplicato non è giustificato.
Warm Standby
Un’architettura Warm Standby estende il concetto di Pilot Light. Invece di un core minimale, nella regione di recovery viene mantenuta una versione completamente scalata—ma inattiva—dell’ambiente di produzione. Il sistema è pronto a prendere in carico il traffico quasi immediatamente.
Tutti i server, database e servizi sono in esecuzione e sincronizzati con l’ambiente di produzione, ma non servono richieste degli utenti. La differenza chiave rispetto al Pilot Light è che durante il failover non è necessario alcuno scaling; l’infrastruttura viene solo attivata. La sfida tecnica principale è mantenere la consistenza dei dati tramite replica continua. Il failover è spesso semplice come una modifica DNS.
- Come funziona: una copia completa e inattiva dell’ambiente di produzione viene eseguita in una regione separata con replica continua dei dati.
- RTO/RPO tipici: l’RTO si riduce a minuti. L’RPO è estremamente basso, spesso di secondi.
- Ideale per: servizi mission-critical, come piattaforme di e-commerce o applicazioni SaaS core, in cui il downtime ha un impatto finanziario diretto e significativo.
Active-Active multi-regione
Questa è l’architettura di disaster recovery più resiliente — e più complessa —, che offre quasi zero downtime e perdita di dati. In una configurazione Active-Active, l’applicazione viene eseguita contemporaneamente in due o più regioni geografiche, con il traffico distribuito tramite load balancing tra di esse. Entrambi gli ambienti sono online e servono attivamente gli utenti.
Se una regione fallisce, il traffico viene automaticamente reindirizzato alla/le regione/i sana/e rimanente/i senza intervento manuale. Questa architettura elimina il concetto di un “evento di failover”; un’interruzione regionale viene trattata come un normale evento operativo. Tuttavia, questo livello di resilienza introduce una significativa complessità ingegneristica e un costo elevato.
- Sfide: gestire la replica e la coerenza dei dati tra database distribuiti geograficamente è un importante ostacolo ingegneristico. Sono necessari networking e routing del traffico complessi per indirizzare gli utenti verso la regione sana più vicina, mantenendo al contempo la località e la coerenza dei dati.
- RTO/RPO tipici: sia l’RTO che l’RPO sono quasi zero.
- Ideale per: applicazioni globali con i requisiti di uptime più stringenti, come piattaforme di trading finanziario o servizi consumer su larga scala, in cui qualsiasi downtime è inaccettabile.
Confronto tra le architetture di disaster recovery nel cloud
Questa tabella fornisce un confronto affiancato per chiarire i compromessi tra le quattro strategie principali.
| Architettura | RTO tipico | RPO tipico | Costo relativo | Complessità di implementazione | Ideale per |
|---|---|---|---|---|---|
| Backup e Ripristino | Da ore a giorni | Da minuti a 24 ore | Basso | Bassa | App non critiche, ambienti di sviluppo/test |
| Pilot Light | Da minuti a ore | Da secondi a minuti | Medio | Media | App business-critical con tolleranza moderata al downtime |
| Warm Standby | Minuti | Secondi | Alto | Alta | Servizi mission-critical con forte impatto finanziario |
| Active-Active multi-regione | Quasi zero | Quasi zero | Molto alto | Molto alta | App globali in cui qualsiasi downtime è inaccettabile |
Come mostrato, esiste una correlazione diretta tra costo, complessità e prestazioni di ripristino. La chiave è allineare la scelta architetturale al valore di business dell’applicazione che protegge.
Sfruttare l’automazione per un ripristino affidabile
Un piano di disaster recovery manuale è un piano destinato a fallire. Durante un incidente reale, i livelli di stress sono alti, gli ingegneri sono sotto un’enorme pressione e la probabilità di errore umano aumenta drasticamente. Affidarsi a documentazione statica e checklist manuali è la ricetta per downtime prolungati e tentativi di ripristino falliti.
L’unica strada verso un ripristino prevedibile, rapido e affidabile è tramite automazione e orchestrazione. Trattando i processi di ripristino come codice, li trasformi da piani astratti in sistemi testabili e ripetibili.
Da runbook statici a codice eseguibile
Il tradizionale runbook di DR — un documento archiviato in una wiki — è spesso obsoleto già al momento della creazione. I sistemi moderni evolvono troppo rapidamente perché la documentazione manuale rimanga accurata. La soluzione è codificare l’intero processo di ripristino.
Questo inizia con l’Infrastructure as Code (IaC). Strumenti come Terraform o AWS CloudFormation ti permettono di definire l’intero ambiente cloud — server, reti, gruppi di sicurezza, load balancer — in file versionati. Questo consente di provisionare un ambiente coerente e identico in una regione di recovery con un solo comando, eliminando il drift di configurazione e gli errori di setup manuale.
Un processo di ripristino automatizzato offre non solo velocità, ma anche coerenza. Il codice viene eseguito allo stesso modo ogni volta, eliminando le supposizioni e il panico che fanno deragliare gli sforzi manuali durante un’interruzione ad alto rischio.
Questo approccio trasforma di fatto il tuo runbook in un insieme di script eseguibili, integrando il DR nella tua strategia CI/CD. Puoi saperne di più su questa integrazione nella nostra guida su come costruire una pipeline CI/CD robusta.
Automatizzare il failover e i controlli di salute
Oltre al provisioning dell’infrastruttura, l’automazione è fondamentale per il processo di failover stesso. Ogni passaggio manuale introduce un potenziale punto di guasto. Queste azioni dovrebbero essere scriptate e, dove possibile, automatizzate.
Le aree chiave da automatizzare includono:
- Failover DNS: servizi come AWS Route 53 o Azure Traffic Manager possono reindirizzare automaticamente il traffico verso una regione di recovery sana in base a controlli di salute configurabili. Questo è il meccanismo principale per reindirizzare il traffico di produzione con downtime minimo.
- Promozione del database: gli script devono gestire la promozione di un database read-replica nella regione di recovery affinché diventi il nuovo master primario. Si tratta di una procedura critica che deve essere orchestrata con precisione per evitare la corruzione dei dati.
- Validazione post-failover: una volta completato il failover, i controlli di salute automatici dovrebbero essere eseguiti immediatamente per confermare che tutti i servizi siano operativi, connessi e in grado di servire correttamente il traffico prima che il ripristino venga dichiarato riuscito.
I rischi nascosti dei passaggi manuali
Anche con una forte strategia di automazione, le minacce maggiori spesso risiedono in interventi manuali non documentati eseguiti da ingegneri sotto pressione. Questi fix “eroici” durante un’interruzione sono raramente documentati e quasi mai ripetibili, creando un falso senso di sicurezza per gli incidenti successivi.
Molte organizzazioni restano impreparate. Un’alta percentuale di aziende che utilizzano servizi cloud protegge con un piano DR valido meno della metà delle proprie applicazioni. Le principali sfide citate sono la complessità dei sistemi, i vincoli di personale IT e la carenza di competenze.
Queste statistiche sottolineano la necessità dell’automazione. Integrando automazione e testabilità nella tua strategia di disaster recovery nel cloud fin dall’inizio, passi da un approccio reattivo, basato sulla speranza, a una disciplina proattiva guidata dall’ingegneria che offre resilienza comprovata.
Validare il tuo piano di recovery attraverso test rigorosi
Un piano di disaster recovery che esiste solo sulla carta è una passività, non un asset. È un’ipotesi non testata sulla resilienza del tuo sistema. L’unico modo per trasformare quell’ipotesi in una capacità affidabile è attraverso test regolari e rigorosi.
Senza validazione, non hai alcuna garanzia che gli script automatici verranno eseguiti correttamente, che i backup dei dati siano utilizzabili o che il tuo team comprenda ruoli e responsabilità durante una crisi. Per i responsabili di compliance e prodotto, un piano non testato è una minaccia diretta alla conformità normativa e alla fiducia dei clienti. Dal punto di vista funzionale, non è meglio che non avere alcun piano.
Le implicazioni finanziarie sono enormi. I costi del downtime possono variare da migliaia a milioni di dollari all’ora. Ancora più criticamente, un numero significativo di aziende che subiscono un grave disastro dei dati senza un piano di recovery testato non riesce a rimanere in attività. Come dettagliato in un’analisi del disaster recovery su Penncomp.com, i sistemi proprietari non testati spesso portano a ripristini lenti e backup corrotti.
Oltre il DR theatre
Una modalità di fallimento comune è il “DR theatre” — test superficiali che creano un falso senso di sicurezza. Questi esercizi, come il riavvio di un singolo servizio o l’esecuzione di un controllo di integrità dei dati di base, possono soddisfare un requisito di compliance ma non simulano i guasti a cascata di un vero disastro.
Una validazione efficace richiede di spingere sistemi e team ai loro limiti operativi. Significa simulare guasti senza preavviso, testare dipendenze poco evidenti e verificare che ogni fase del processo di recovery funzioni come progettato. L’obiettivo non è superare un test, ma identificare e risolvere attivamente le debolezze prima che un incidente reale le sfrutti.
Metodologie pratiche per un testing efficace
Un approccio maturo al disaster recovery nel cloud utilizza una strategia di testing a più livelli. Invece di un unico grande esercizio annuale, diversi tipi di test dovrebbero essere integrati nella cadenza operativa.
-
Tabletop exercise: si tratta di sessioni strutturate basate sulla discussione in cui il team di risposta ripercorre uno scenario di disastro simulato. L’obiettivo è validare la chiarezza del runbook, individuare lacune nella comunicazione e assicurarsi che tutti i partecipanti comprendano i propri ruoli. È un metodo a basso rischio per testare gli elementi umani del piano.
-
Drill di failover parziale: in questi test, simuli il guasto di un servizio o componente specifico in un ambiente non di produzione. Ad esempio, effettuare il failover di una singola replica del database o di un livello applicativo convalida script di automazione specifici e dipendenze tecniche senza rischiare la disponibilità della produzione.
-
Simulazioni su larga scala: è il test più completo, che coinvolge un failover completo dell’intero ambiente di produzione verso la regione di recovery. Sebbene sia dirompente e richieda molte risorse, è l’unico modo per convalidare il processo di recovery end-to-end in condizioni realistiche. Queste simulazioni sono essenziali per i sistemi mission-critical e devono essere pianificate con estrema cura.
Un test riuscito è quello da cui impari. Il post-mortem è la parte più preziosa dell’esercizio. Documenta ogni scoperta, aggiorna gli script di automazione e i runbook, e crea ticket per affrontare le debolezze identificate.
Una cultura della validazione continua è ciò che distingue le organizzazioni resilienti da quelle vulnerabili. Il testing non dovrebbe essere un temuto evento annuale, ma una pratica routinaria che costruisce una fiducia reale nella tua capacità di recupero.
Passare dalla pianificazione della resilienza alla realtà operativa
Il disaster recovery nel cloud non è un progetto da completare, ma una qualità architetturale fondamentale che deve essere mantenuta continuamente e allineata agli obiettivi di business. Un piano su carta è privo di significato durante una vera interruzione; solo una capacità operativa comprovata può mettere al sicuro la tua organizzazione.
Il processo inizia traducendo le esigenze di business in vincoli ingegneristici tramite metriche RTO e RPO ben definite. Questi obiettivi guidano la selezione di un’architettura adeguata — da un modello Backup and Restore conveniente a una configurazione Active-Active completamente resiliente — imponendo trade-off espliciti tra costo, complessità e velocità di ripristino.
Abbracciare il miglioramento continuo
Tuttavia, un buon design è solo il punto di partenza. Senza automazione robusta e test rigorosi e regolari, anche i piani migliori si degradano in teorie inaffidabili. L’automazione trasforma i runbook statici in codice eseguibile e ripetibile. Il testing convalida che sia i sistemi sia i team possano operare sotto pressione. Questo approccio sposta il DR da una configurazione una tantum a un ciclo di miglioramento continuo.
La vera resilienza non si ottiene scrivendo un piano; si costruisce validando costantemente la propria capacità di recupero. Ogni test, che sia un tabletop exercise o una simulazione completa, è un’opportunità per individuare e correggere le debolezze prima che lo faccia un vero disastro.”} L’obiettivo finale è andare oltre la semplice pianificazione e raggiungere uno stato di costante prontezza operativa. Questo approccio disciplinato, guidato dall’ingegneria, garantisce che i vostri prodotti digitali rimangano disponibili e affidabili, proteggendo sia i vostri clienti sia la vostra attività. Per i leader tecnici, promuovere questa cultura è una componente critica della salute del sistema e della manutenibilità a lungo termine, riecheggiando i principi del miglioramento continuo visibili nel modo in cui i progetti Kaizen mantengono i sistemi esistenti.
Domande frequenti
Risposte pragmatiche alle domande più comuni di leader tecnici e aziendali riguardo ai compromessi architetturali, ai costi nascosti e a cadenze di test realistiche.
Come scelgo la giusta architettura di disaster recovery?
Non esiste un’unica architettura “migliore”; la scelta è sempre un compromesso tra costi, complessità e i vostri obiettivi di RTO/RPO. Un approccio a livelli basato sulla criticità dell’applicazione è la strategia più efficace e finanziariamente solida.
Classificate i vostri servizi:
- Sistemi mission-critical: includono servizi come i gateway di pagamento o l’autenticazione principale degli utenti, dove qualsiasi downtime ha un impatto diretto su ricavi e fiducia. Questi sistemi giustificano la spesa per un’architettura Warm Standby o Multi-Region Active-Active per raggiungere un RTO quasi nullo.
- Applicazioni business-critical: questi servizi sono essenziali per le operazioni ma possono tollerare brevi interruzioni. Un’architettura Pilot Light offre un equilibrio sensato tra velocità di ripristino e costo operativo per questo livello.
- Sistemi non essenziali: strumenti interni, dashboard di analisi e ambienti di sviluppo raramente richiedono un ripristino immediato. È sufficiente una strategia semplice e a basso costo di Backup and Restore.
Allineando l’investimento in resilienza all’impatto sul business, potete sviluppare un piano DR che sia al tempo stesso efficace e sostenibile.
Quali sono i maggiori costi nascosti?
I costi più significativi e spesso trascurati nel DR cloud sono operativi, non infrastrutturali. Sebbene la fattura mensile per le risorse inattive sia prevedibile, altre spese possono essere considerevoli.
Tenete presenti queste tre aree:
- Overhead ingegneristico: le ore di ingegneria necessarie per costruire, mantenere e testare gli script IaC, gestire la replica dei dati e mantenere aggiornati i runbook rappresentano un costo significativo e continuo. Questo carico di lavoro cresce man mano che i vostri sistemi evolvono.
- Costi di data egress: l’attivazione del failover verso un’altra regione comporta il trasferimento di grandi volumi di dati attraverso la rete del provider cloud. Questi costi di egress possono essere consistenti e spesso vengono omessi dai modelli di costo iniziali.
- Tassa di complessità: architetture altamente resilienti, in particolare Active-Active, introducono una complessità significativa. Gestire lo stato e garantire la coerenza dei dati tra regioni distribuite geograficamente genera costi di ingegneria e manutenzione a lungo termine legati alla diagnosi e alla correzione di bug sottili dei sistemi distribuiti.
Quanto spesso dovremmo testare il nostro piano di disaster recovery?
La frequenza dei test dovrebbe essere allineata al ritmo di cambiamento del sistema. Un’applicazione interna statica ha esigenze di test diverse rispetto a una piattaforma SaaS rivolta ai clienti con deploy settimanali.
Per i sistemi mission-critical, una cadenza ragionevole è eseguire trimestralmente esercitazioni parziali di failover e annualmente una simulazione su larga scala. Questo ritmo costruisce fiducia operativa senza causare interruzioni eccessive.
Un approccio più avanzato integra la validazione del DR nel ciclo di vita dello sviluppo. Qualsiasi cambiamento architetturale importante — come sostituire un database o introdurre un nuovo microservizio — dovrebbe attivare un test di ripristino mirato per il componente interessato. Questo trasforma il testing da evento annuale a pratica ingegneristica continua, garantendo che il vostro piano DR rimanga sincronizzato con la realtà del sistema.
Una strategia di disaster recovery robusta è una pietra angolare di qualsiasi prodotto digitale affidabile. In Devisia, aiutiamo le organizzazioni a progettare e costruire sistemi resilienti e manutenibili, fondati su scelte architetturali pragmatiche e obiettivi di business chiari. Scoprite di più su come trasformiamo la visione in software affidabile su https://www.devisia.pro.