
The choice between cloud and on-premise infrastructure is not a technology preference; it’s a fundamental architectural decision that dictates your organization’s operational model, security posture, and capacity for innovation. The core trade-off is between operational agility and absolute control. Cloud platforms offer managed, scalable infrastructure as an operational expense, while on-premise solutions provide complete ownership and authority over hardware and data as a capital expense.
This decision has direct consequences for your financial model (CapEx vs. OpEx), compliance strategy, and the very architecture of the software you build. A superficial choice can lead to uncontrolled costs, security vulnerabilities, or an inability to scale—crippling the business at a critical moment.
Defining Your Foundational Infrastructure
Choosing an infrastructure model is one of the most consequential decisions a technical leader will make. It’s not about finding a universally “better” option but about a pragmatic analysis of business context, workload characteristics, and regulatory constraints. For a startup building a SaaS platform with unpredictable user growth, the cloud’s elasticity is a core enabler. Conversely, a financial institution with strict data sovereignty mandates and ultra-low latency requirements for trading algorithms may find on-premise infrastructure non-negotiable.
The problem arises when this decision is treated as a simple procurement choice. The risks of a naive approach—such as a “lift-and-shift” migration without architectural modification—can negate the promised benefits of the cloud, resulting in poor performance and higher costs than the original on-premise setup. A strategic approach, however, transforms infrastructure from a cost center into a competitive advantage.
Core Architectural Differences
The distinction between cloud and on-premise extends far beyond physical location. They represent fundamentally different operating models, each with distinct responsibilities and risk profiles. Understanding these is the first step toward making a defensible architectural decision.
| Attribute | Cloud Computing | On-Premise Infrastructure |
|---|---|---|
| Ownership Model | Service subscription (OpEx); you rent capacity from a provider. | Full hardware ownership (CapEx); you buy and maintain servers. |
| Control Level | Shared responsibility; the provider manages physical security and base infrastructure. | Absolute control over hardware, software, and physical access. |
| Scalability | High elasticity; scale resources up or down on demand, often automatically. | Limited and slow; scaling requires procuring and provisioning new hardware. |
| Maintenance | Managed by the cloud provider, reducing your team’s operational burden. | Managed entirely by your in-house IT team, demanding specialised skills. |
The debate is no longer cloud versus on-premise. For most modern enterprises, the challenge is architecting a hybrid reality where specific workloads are placed in the environment that best serves their unique technical and business constraints.
This choice directly shapes your company’s ability to adapt. It dictates whether your teams spend their time managing hardware or building features, and whether your systems can handle a sudden surge in demand or buckle under the pressure.
A Detailed Comparison of Core Architectural Attributes
To make an informed decision, we must move beyond marketing claims and analyze the architectural trade-offs that impact budget, performance, and risk. Let’s dissect the six attributes that define the cloud vs. on-premise landscape.
Total Cost of Ownership
The financial models are diametrically opposed. On-premise is rooted in Capital Expenditure (CapEx), requiring significant upfront investment in hardware, software licenses, and physical data center facilities. This model offers budget predictability but often forces over-provisioning to handle peak capacity, leaving expensive assets underutilized.
Cloud infrastructure operates on an Operational Expenditure (OpEx) model. Large capital investments are replaced with recurring subscription fees, allowing you to pay only for the resources consumed. This offers tremendous flexibility, particularly for systems with variable workloads. The primary risk is cost management; without rigorous governance and FinOps practices, expenses for data transfer, API calls, and storage can escalate unexpectedly.
This financial dichotomy is reflected in market trends. While 48% of enterprises report using cloud services (read the full research about these cloud adoption trends), many maintain on-premise systems for specific workloads, creating a hybrid reality. In fact, a multi-cloud strategy is now the norm, providing resilience and avoiding vendor lock-in for critical systems.
This chart summarizes the key trade-offs across growth, security, and innovation.
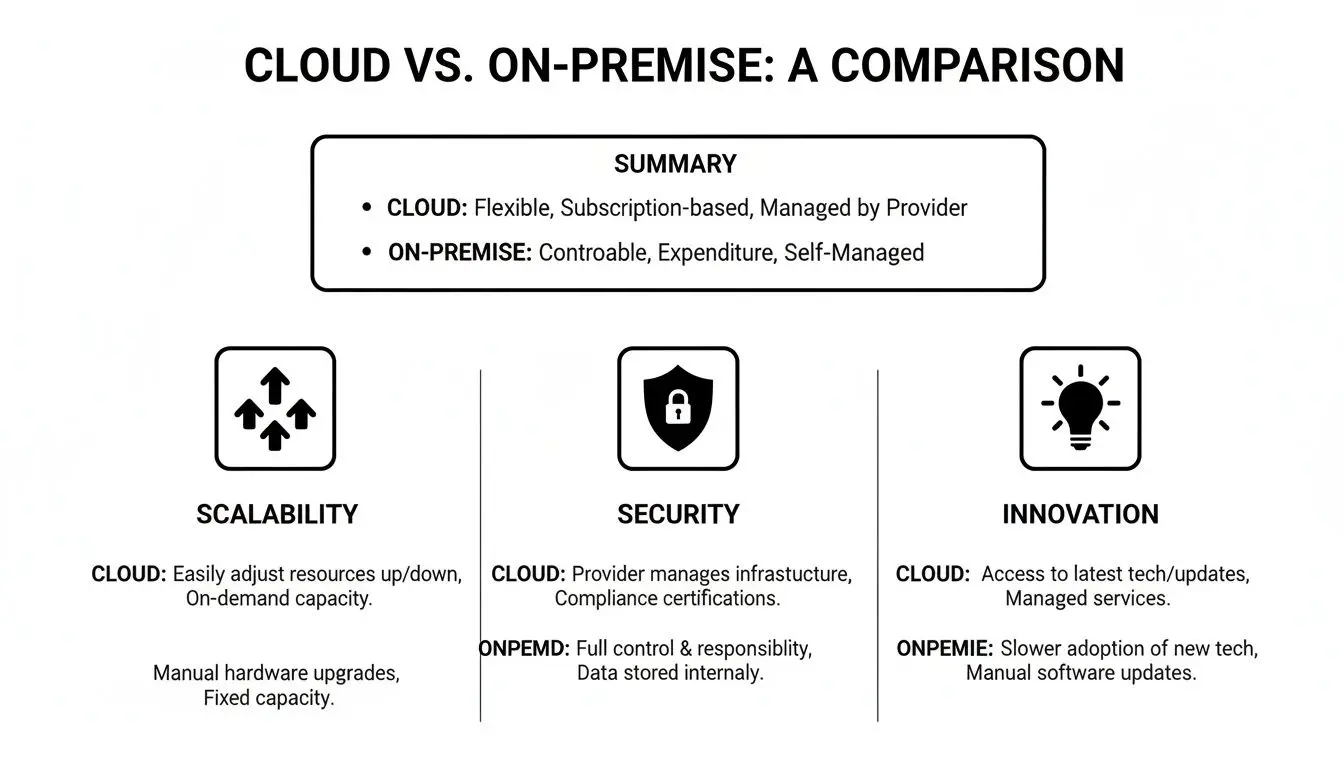
While the cloud is engineered for elastic scale, on-premise provides undeniable, direct control over the security stack. The optimal choice depends on which attribute is a primary business driver.
Performance and Latency
For most distributed web applications, the performance of major cloud providers is more than sufficient. Their global networks and content delivery networks (CDNs) are designed to minimize latency for a geographically dispersed user base.
However, for certain workloads, latency is a hard architectural constraint, not a preference.
- Industrial IoT: In a manufacturing environment, a sensor triggering an emergency shutdown cannot tolerate the round-trip time to a cloud data center. An on-premise edge server provides the necessary real-time response.
- High-Frequency Trading: In financial markets, algorithms must be physically co-located with exchange servers to minimize network delay. Here, on-premise is the default architecture.
- Real-Time AI Inference: A live chatbot powered by a large language model (LLM) must provide instant responses. While cloud GPUs offer immense power, a smaller, specialized model deployed on-premise can deliver lower latency for a specific, well-defined task.
Scalability and Elasticity
This is the cloud’s native advantage. Scalability is the ability to handle increased load, while elasticity is the ability to automatically provision and de-provision resources to match demand precisely.
With the cloud, an architect can design a system to grow from a handful of users to millions without manual intervention. On-premise scaling is a slow, capital-intensive cycle of procurement, installation, and configuration.
Consider a SaaS startup launching a new product. An on-premise approach forces a difficult decision: over-provision hardware and waste capital, or under-provision and risk system failure at launch. A cloud-native design using auto-scaling groups and serverless functions adapts dynamically, optimizing both cost and performance in real time.
Security and Control
The security discussion centers on control versus responsibility. On-premise provides absolute physical and logical control over your hardware, network, and software stack. This also means you bear 100% of the responsibility for securing every layer, from data center access control to OS patching.
The cloud operates on a shared responsibility model. The provider is responsible for securing the underlying infrastructure—the physical data centers, hardware, and core network. The customer is responsible for securing what they run on the cloud—their data, access policies, application code, and configurations. While this model offloads significant operational burden, it introduces new risks. A misconfigured cloud storage bucket can expose sensitive data far more rapidly and broadly than a traditional server vulnerability.
Compliance and Data Sovereignty
For organizations subject to regulations like GDPR, NIS2, or DORA, the physical location of data is a critical compliance issue. Data sovereignty—the principle that data is subject to the laws of the country in which it is located—has historically made on-premise the default choice for conservative legal and compliance teams.
However, major cloud providers have invested heavily in addressing these concerns. They now offer specific cloud regions (e.g., in Frankfurt or Paris for EU data) with contractual guarantees to meet local regulatory requirements. The decision is no longer about whether data can reside in-country, but whether your specific legal framework or risk posture permits a third-party to manage the underlying infrastructure, even if the data itself never crosses a border.
Maintenance and Operations
Operating an on-premise data center requires a dedicated team with expertise in networking, hardware management, storage, and virtualization. This represents a significant and continuous investment in specialized personnel responsible for everything from replacing failed hardware to managing backups and patching systems.
Cloud services abstract away most of this infrastructure management. This allows engineering teams to focus on application development and business logic rather than hardware maintenance. However, it requires a new skill set focused on cloud architecture, infrastructure-as-code, and cost optimization (FinOps). A robust disaster recovery plan, for example, remains critical in the cloud; the principles are identical, but the implementation and tooling are different.
To consolidate these points, let’s look at a direct comparison.
Cloud vs On-Premise Attribute Comparison
This table summarizes the core differences, offering a quick reference for technical leaders evaluating their infrastructure strategy.
| Attribute | Cloud Computing (PaaS/IaaS) | On-Premise Infrastructure |
|---|---|---|
| Cost Model | OpEx: Pay-as-you-go, subscription-based. Avoids large upfront costs but requires cost management. | CapEx: High initial investment in hardware and software, followed by ongoing maintenance costs. |
| Scalability | High & Elastic: Resources scale up or down automatically based on real-time demand. | Limited & Manual: Scaling requires purchasing and provisioning new hardware, a slow process. |
| Performance | Excellent for distributed workloads. Latency can be a factor for highly sensitive applications. | Unmatched for low-latency tasks where physical proximity to the source is critical. |
| Security | Shared Responsibility: Provider secures the infrastructure; you secure your data and applications. | Full Control: You have complete physical and logical control over the entire security stack. |
| Maintenance | Minimal hardware maintenance. Focus shifts to cloud architecture, automation, and governance. | Requires a dedicated IT team for hardware, patching, and physical infrastructure management. |
| Compliance | Providers offer region-specific data centres and tools to meet regulations like GDPR. | Provides clear-cut data sovereignty, as you control the exact physical location of data. |
The table reinforces that there is no single “best” option. The ideal choice is contextual, driven by your specific business requirements, risk tolerance, and long-term architectural vision.
A Decision Framework for Choosing Your Path
Choosing between cloud and on-premise infrastructure must be a structured, analytical process. The right decision depends on your workloads, regulatory environment, and strategic goals. A superficial choice can lead to significant technical debt, budget overruns, or critical compliance failures.
This framework guides technical leaders and compliance managers through the critical questions that should inform your infrastructure strategy, focusing on operational realities and architectural trade-offs.
Assessing Your Workload and Growth Strategy
First, perform a rigorous analysis of the systems you are building. The unique characteristics of each workload are the primary drivers in the cloud vs. on-premise decision.
Ask your team these key questions:
- Is demand predictable or spiky? Systems with steady, predictable traffic, such as internal back-office applications, can be cost-effective on-premise. For workloads with volatile demand—like a new B2C product launch or a viral marketing campaign—the cloud’s elasticity is a mission-critical feature.
- What is our long-term growth plan? If rapid global expansion is part of your strategy, a cloud-native architecture is almost always the correct path. It enables entry into new geographic markets without the capital expenditure of building physical data centers. A business with a stable, regional focus may not require this capability.
- What are the hard latency requirements? For use cases like industrial control systems, high-frequency trading platforms, or real-time robotics, sub-millisecond latency is non-negotiable. For these systems, on-premise or edge computing is a technical necessity.
Evaluating Regulatory and Compliance Constraints
For many organizations, particularly in sectors like finance and healthcare in Europe, compliance is a foundational architectural requirement. Regulations such as GDPR, NIS2, and DORA impose strict rules on data handling, residency, and security that cannot be retrofitted.
The critical compliance question is not whether the cloud can be compliant, but whether your organization has the governance, expertise, and processes to make it compliant. On-premise offers a false sense of security if your internal security practices are weak.
Your evaluation must include:
- Data Sovereignty: Are you legally obligated to store certain data within specific national borders? While major cloud providers offer EU-based regions, some government contracts or highly sensitive data may mandate that it never resides in a third-party facility.
- Auditability and Control: Do your auditors require physical inspection of servers? While rare, this is a firm requirement in some highly regulated industries, making on-premise a simpler path to demonstrating control.
- Security Posture: On-premise provides total control but also total responsibility. Recent exploits targeting on-premises Microsoft Exchange servers demonstrate that without a dedicated security team for continuous patching and monitoring, self-managed systems can represent a significant vulnerability.
Analysing In-House Expertise and Financial Models
Finally, your decision must align with your team’s skills and your company’s financial model. Adopting cloud technologies without the requisite expertise in cloud architecture and FinOps can be as risky as operating a data center with an understaffed IT team.
Assess your operational readiness:
- Technical Skillsets: Does your team have deep expertise in network engineering, hardware maintenance, and virtualization (for on-premise)? Or are they skilled in cloud architecture, infrastructure-as-code, and cost management (for cloud)? The answer dictates your path of least resistance.
- Financial Preference: Does your finance department prefer predictable capital expenditures (CapEx) or flexible operational expenditures (OpEx)? Startups often rely on the cloud’s OpEx model to conserve cash, while established enterprises may prefer the budget predictability of CapEx.
This structured analysis clarifies the real-world trade-offs. The industry trend is clear: projections show that by 2026, public cloud spending will account for 60% of key enterprise IT markets (discover more insights about cloud computing’s growth on Codegnan.com). Answering these questions ensures your decision is tailored to your context, not just a reaction to market trends.
Navigating Hybrid and Multi-Cloud Architectures
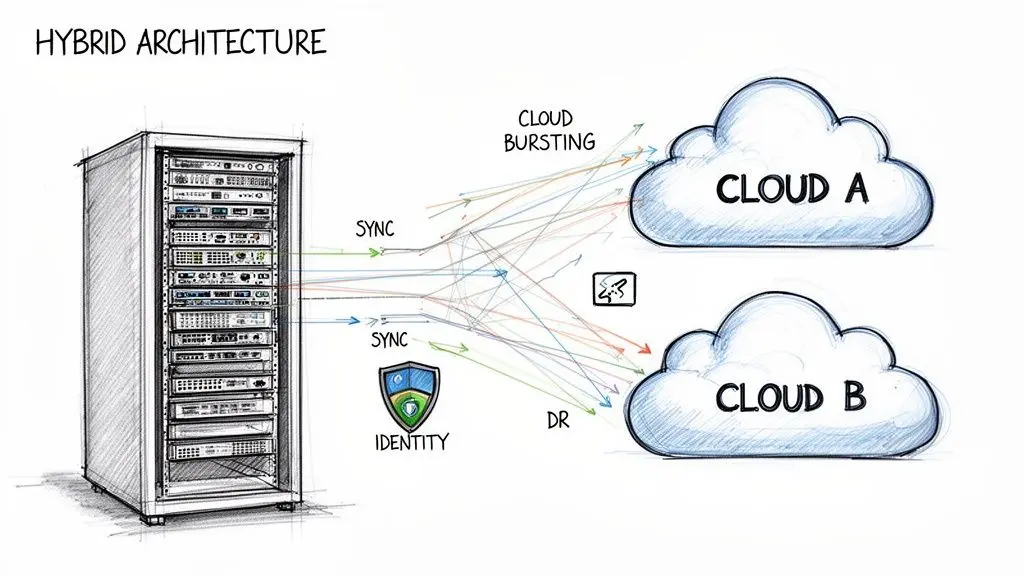
The debate between cloud and on-premise rarely concludes with a binary choice. The most resilient and effective modern architectures often blend both into a hybrid model, matching each workload to the most appropriate environment. This pragmatic approach leverages the strengths of private infrastructure (control, latency) and public clouds (scale, managed services) to optimize for performance, cost, and compliance simultaneously.
Common Hybrid Architectural Patterns
A hybrid architecture is not a single solution but a collection of patterns designed to solve specific business problems. Each pattern uses the cloud for its unique capabilities while retaining on-premise infrastructure for tasks requiring absolute control or low-latency processing.
Three common patterns offer clear strategic advantages:
- Cloud Bursting: Baseline, predictable workloads run on-premise. During a sudden traffic spike, the system “bursts” into the public cloud to handle the excess load. For an e-commerce platform, day-to-day operations run on cost-effective private servers, but during a Black Friday sale, the system automatically scales into the cloud to prevent downtime.
- Cloud-Based Disaster Recovery (DR): Maintaining a fully redundant on-premise DR site is prohibitively expensive. A hybrid model uses the cloud as a failover target, replicating critical on-premise data and applications to a cloud provider. This dramatically reduces the cost of resilience while ensuring business continuity.
- Leveraging Specialized Cloud Services: An organization might keep its core transactional database and sensitive customer data on-premise to comply with strict GDPR requirements. Simultaneously, it can securely send anonymized data to a public cloud to access powerful AI and machine learning platforms for analytics, without exposing protected information.
The goal of a hybrid model is to treat infrastructure as a portfolio. Each component is placed where it delivers the most value—whether in a public cloud for elastic scale or on-premise for absolute control.
Designing for this flexibility requires careful planning. Principles from architectures like Service-Oriented Architecture (SOA) are valuable for building the modular, interoperable systems needed for a successful hybrid implementation.
The Rise of Multi-Cloud Strategies
Beyond a single hybrid model, many organizations are adopting a multi-cloud strategy, using services from more than one public cloud provider (e.g., a combination of AWS and Azure). This approach is primarily driven by two strategic goals: avoiding vendor lock-in and enhancing resilience. By architecting applications that are not tightly coupled to one provider’s proprietary services, an organization maintains negotiating leverage and architectural freedom. A multi-cloud setup also provides an additional layer of disaster recovery; a major regional outage at one provider can be mitigated by failing over services to another.
Practical Implementation Challenges
Adopting a hybrid or multi-cloud architecture introduces significant complexity that must be managed deliberately. A poorly planned implementation can result in a fragmented system that is less secure and more difficult to manage than a pure on-premise or single-cloud environment.
Key implementation challenges include:
- Network Connectivity: A secure, low-latency, and reliable link between your data center and the cloud is essential, often requiring dedicated connections that add cost and complexity.
- Data Synchronization: Maintaining data consistency across distributed environments is a major architectural challenge, requiring robust mechanisms for replication and conflict resolution.
- Unified Identity Management: Managing user access across multiple platforms demands a centralized identity and access management (IAM) solution to prevent security gaps and operational overhead.
- Unified Observability: Monitoring performance, aggregating logs, and managing security across disparate systems is notoriously difficult. Achieving a “single pane of glass” for observability is critical for effective troubleshooting and control.
Proven Strategies for Cloud Migration
Migrating applications from on-premise infrastructure to the cloud is a complex engineering initiative, not a simple IT project. A naive approach can introduce unacceptable risks, including performance degradation, security vulnerabilities, and budget overruns that negate the intended benefits. A successful migration requires a methodical strategy that balances speed, cost, and long-term architectural health.
The process should begin with a thorough discovery phase to map application dependencies and identify potential failure points before they become production incidents. It is about choosing the right migration path for each specific workload, not a one-size-fits-all mandate.
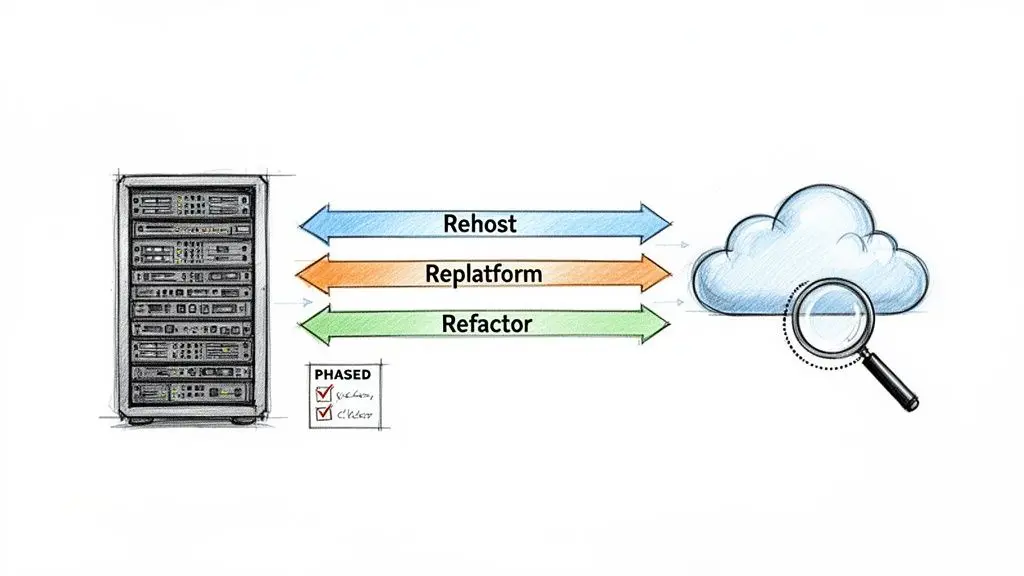
Rehosting: The “Lift-and-Shift” Model
Rehosting, commonly known as “lift-and-shift”, is the most direct migration path. It involves moving applications from on-premise servers to cloud-based virtual machines with minimal or no changes to the application’s architecture.
This approach is suitable for:
- Legacy applications where modifying the source code is impossible or too risky.
- Rapid data center exits driven by lease expirations or hardware end-of-life.
- Initial migration phases where the primary goal is to quickly establish a cloud footprint before optimizing workloads.
The primary advantage of rehosting is speed. However, its significant disadvantage is that it often fails to leverage cloud-native benefits like auto-scaling or serverless computing. This can result in higher operational costs in the cloud than the original on-premise setup.
Replatforming: The “Lift-and-Reshape” Model
Replatforming, or “lift-and-reshape,” represents a practical middle ground. This strategy involves making targeted modifications to an application to take advantage of cloud-managed services, but without a complete architectural overhaul.
A classic example is migrating an on-premise database to a managed cloud database service like Amazon RDS or Azure SQL Database. This offloads the operational burden of patching, backups, and scaling from the engineering team. While more involved than rehosting, replatforming delivers tangible benefits by reducing maintenance overhead and improving resilience.
Refactoring: The Rearchitecting Model
Refactoring is the most intensive migration strategy. It involves completely redesigning an application to be fully cloud-native. This often means decomposing a monolithic application into microservices, adopting serverless functions, and deeply integrating with cloud-managed services.
This path is chosen when the goal is to achieve maximum scalability, performance, and cost-efficiency. A refactored application can scale individual components independently, optimizing resource utilization and improving fault isolation. While it requires a significant upfront investment in engineering, refactoring is the only way to fully exploit the capabilities of the cloud. A robust CI/CD pipeline is non-negotiable for this approach. The choice between rehosting, replatforming, and refactoring must be made on a per-application basis, considering business value, technical debt, and risk tolerance.
Making a Maintainable and Future-Proof Choice
The debate over cloud vs on-premise is not about selecting a permanent winner. It is a strategic exercise in aligning your technical foundation with your business objectives, workload characteristics, and long-term vision. The right decision is the one that provides the most leverage today while offering a clear path for evolution.
A future-proof choice looks beyond the immediate project to consider long-term maintainability and agility. Your infrastructure dictates how quickly you can respond to market changes, how you manage operational overhead, and how resilient your systems are. A decision based solely on upfront cost can create significant technical debt, hindering growth and innovation.
Key Architectural Trade-offs Revisited
At its core, the decision comes down to a few critical trade-offs. You must prioritize what matters most to your organization.
- Cost vs Flexibility: On-premise offers predictable CapEx but locks you into fixed capacity. The cloud provides OpEx flexibility but requires strict governance to prevent cost overruns.
- Control vs Responsibility: On-premise provides total control over the entire stack, but also total responsibility for securing and maintaining it. The cloud’s shared responsibility model offloads much of that burden but demands new skills in configuration management and security automation.
- Scalability vs Latency: For handling unpredictable growth, the cloud’s elastic scale is unparalleled. For specific industrial or high-frequency trading workloads, on-premise delivers the non-negotiable ultra-low latency.
- Compliance vs Agility: While on-premise once made proving data sovereignty straightforward, modern cloud regions now offer robust, in-country solutions that satisfy stringent regulations like GDPR, making compliance achievable in both models.
Your infrastructure is an architectural choice with lasting consequences for maintainability and business agility. It demands deliberate, informed decision-making that views technology not as a cost center, but as a direct enabler of your strategic goals. Whether cloud, on-premise, or a hybrid model, the best architecture is the one that is deliberately chosen.
Common Questions from the Trenches
Here are concise, pragmatic answers to the questions we frequently hear from CTOs and IT leaders evaluating the cloud versus on-premise decision.
What’s the Biggest Hidden Cost in the Cloud?
The most common and significant hidden cost is data egress fees—the cost of moving data out of a cloud provider’s network. Ingress (moving data in) is almost always free, but egress for backups, multi-cloud replication, or feeding on-premise analytics systems can lead to unexpectedly large bills. This is particularly true for data-intensive applications like video streaming or large-scale AI training. Other easily overlooked costs include uncontrolled logging, excessive API calls, and over-provisioned resources. Effective cost control requires designing for efficiency from day one, not as an afterthought.
How Does Data Sovereignty Actually Impact This Decision?
Data sovereignty is a non-negotiable legal requirement for many organizations, mandating that data remains within a specific jurisdiction (e.g., GDPR in the EU). Historically, this was a clear advantage for on-premise, providing absolute physical control and certainty over data location. Today, the major cloud providers have dedicated regions (e.g., AWS in Frankfurt, Azure in Germany) designed to meet these requirements. The decision now hinges on a more nuanced interpretation of your compliance framework: does it simply require data to reside within a national border (which the cloud can handle), or does it mandate direct, physical control over the hardware itself, precluding third-party infrastructure?
Is On-Premise Ever Genuinely More Secure?
Yes, but only in specific, niche scenarios. For highly sensitive government or industrial systems that must be “air-gapped”—completely disconnected from external networks—on-premise is the only architecture that can provide absolute control over every physical and network layer. However, this control comes with absolute responsibility. Cloud providers invest billions in security, employing elite teams and AI-driven threat detection that most individual companies cannot match. For the vast majority of businesses, a well-configured cloud environment is far more secure than a self-managed on-premise setup that relies on a small team to keep pace with constant patching and monitoring.
Consider the recent waves of attacks exploiting on-premise Exchange or SharePoint vulnerabilities. These incidents demonstrate that without relentless vigilance, self-managed systems can easily become a greater liability than a properly secured cloud environment.
Ready to build a robust, maintainable, and future-proof digital product? Devisia specialises in turning your vision into reliable software, whether on-premise, in the cloud, or a hybrid of both. We provide end-to-end delivery with a product mindset, ensuring your architecture aligns with your long-term business goals.