
La scelta tra infrastruttura cloud e on-premise non è una preferenza tecnologica; è una decisione architetturale fondamentale che determina il modello operativo della tua organizzazione, il livello di sicurezza e la capacità di innovare. Il compromesso principale è tra agilità operativa e controllo assoluto. Le piattaforme cloud offrono infrastruttura gestita e scalabile come spesa operativa, mentre le soluzioni on-premise garantiscono piena proprietà e autorità su hardware e dati come spesa in conto capitale.
Questa decisione ha conseguenze dirette sul tuo modello finanziario (CapEx vs. OpEx), sulla strategia di conformità e sulla stessa architettura del software che sviluppi. Una scelta superficiale può portare a costi incontrollati, vulnerabilità di sicurezza o incapacità di scalare—mettendo in crisi l’azienda in un momento critico.
Definire la tua infrastruttura di base
Scegliere un modello infrastrutturale è una delle decisioni più importanti che un leader tecnico debba prendere. Non si tratta di trovare un’opzione universalmente “migliore”, ma di un’analisi pragmatica del contesto di business, delle caratteristiche del carico di lavoro e dei vincoli normativi. Per una startup che costruisce una piattaforma SaaS con crescita imprevedibile degli utenti, l’elasticità del cloud è un abilitatore fondamentale. Viceversa, un istituto finanziario con rigidi requisiti di sovranità dei dati e necessità di latenza estremamente bassa per algoritmi di trading potrebbe considerare l’infrastruttura on-premise non negoziabile.
Il problema sorge quando questa decisione viene trattata come una semplice scelta di acquisto. I rischi di un approccio ingenuo—come una migrazione “lift-and-shift” senza modifiche architetturali—possono annullare i benefici promessi dal cloud, causando scarse prestazioni e costi superiori rispetto all’impostazione on-premise originale. Un approccio strategico, invece, trasforma l’infrastruttura da centro di costo a vantaggio competitivo.
Differenze architetturali fondamentali
La distinzione tra cloud e on-premise va ben oltre la collocazione fisica. Rappresentano modelli operativi fondamentalmente diversi, ciascuno con responsabilità e profili di rischio distinti. Comprenderli è il primo passo per prendere una decisione architetturale difendibile.
| Attributo | Cloud Computing | Infrastruttura On-Premise |
|---|---|---|
| Modello di proprietà | Abbonamento al servizio (OpEx); noleggi capacità da un provider. | Piena proprietà dell’hardware (CapEx); acquisti e manutieni i server. |
| Livello di controllo | Responsabilità condivisa; il provider gestisce la sicurezza fisica e l’infrastruttura di base. | Controllo assoluto su hardware, software e accesso fisico. |
| Scalabilità | Alta elasticità; aumenta o riduce le risorse su richiesta, spesso automaticamente. | Limitata e lenta; la scalabilità richiede l’approvvigionamento e il provisioning di nuovo hardware. |
| Manutenzione | Gestita dal provider cloud, riducendo il carico operativo del tuo team. | Gestita interamente dal team IT interno, con necessità di competenze specialistiche. |
Il dibattito non è più cloud contro on-premise. Per la maggior parte delle imprese moderne, la sfida è progettare una realtà ibrida in cui i singoli carichi di lavoro vengano collocati nell’ambiente che meglio risponde ai loro vincoli tecnici e di business unici.
Questa scelta plasma direttamente la capacità dell’azienda di adattarsi. Determina se i team spendono il loro tempo a gestire hardware o a costruire funzionalità, e se i sistemi possono gestire un improvviso picco di domanda o crollare sotto la pressione.
Un confronto dettagliato degli attributi architetturali fondamentali
Per prendere una decisione informata, dobbiamo andare oltre le affermazioni di marketing e analizzare i compromessi architetturali che incidono su budget, prestazioni e rischio. Esaminiamo le sei caratteristiche che definiscono il panorama cloud vs. on-premise.
Costo totale di proprietà
I modelli finanziari sono diametralmente opposti. L’on-premise si basa sulle Spese in conto capitale (CapEx), richiedendo un investimento iniziale significativo in hardware, licenze software e strutture fisiche del data center. Questo modello offre prevedibilità di budget, ma spesso costringe a sovraprovisionare per gestire i picchi di capacità, lasciando costosi asset sottoutilizzati.
L’infrastruttura cloud opera con un modello di Spese operative (OpEx). I grandi investimenti di capitale vengono sostituiti da canoni ricorrenti di abbonamento, consentendoti di pagare solo per le risorse consumate. Ciò offre enorme flessibilità, soprattutto per sistemi con carichi di lavoro variabili. Il rischio principale è la gestione dei costi; senza una governance rigorosa e pratiche FinOps, le spese per trasferimento dati, chiamate API e storage possono aumentare inaspettatamente.
Questa dicotomia finanziaria si riflette nelle tendenze di mercato. Mentre il 48% delle imprese dichiara di utilizzare servizi cloud (leggi la ricerca completa su queste tendenze di adozione del cloud), molte mantengono sistemi on-premise per carichi di lavoro specifici, creando una realtà ibrida. In effetti, una strategia multi-cloud è ormai la norma, offrendo resilienza ed evitando il vendor lock-in per i sistemi critici.
Questo grafico riassume i principali compromessi tra crescita, sicurezza e innovazione.
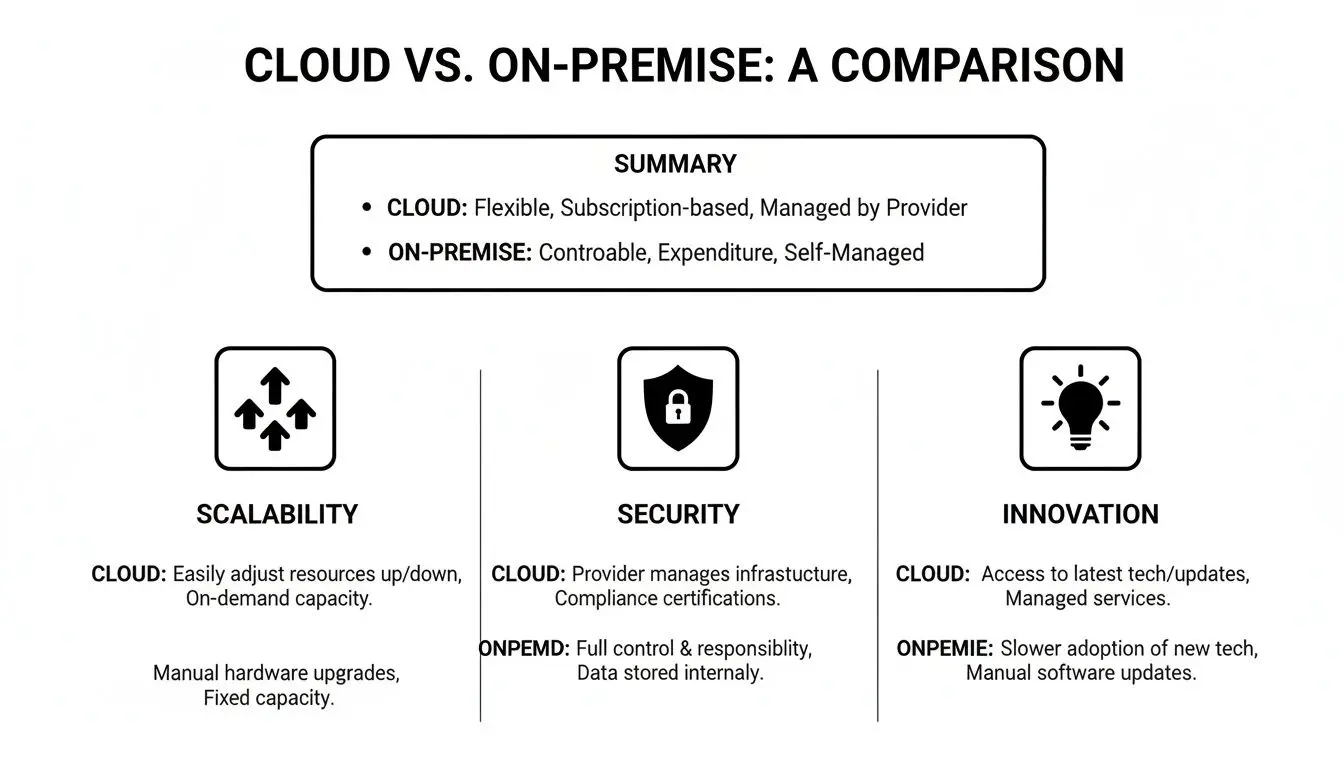
Sebbene il cloud sia progettato per una scala elastica, l’on-premise offre un controllo diretto e innegabile sullo stack di sicurezza. La scelta ottimale dipende da quale attributo è il principale motore di business.
Prestazioni e latenza
Per la maggior parte delle applicazioni web distribuite, le prestazioni dei principali provider cloud sono più che sufficienti. Le loro reti globali e le content delivery network (CDN) sono progettate per ridurre al minimo la latenza per una base utenti geograficamente distribuita.
Tuttavia, per alcuni carichi di lavoro, la latenza è un vincolo architetturale rigido, non una preferenza.
- IoT industriale: In un ambiente di produzione, un sensore che attiva uno spegnimento di emergenza non può tollerare il tempo di andata e ritorno verso un data center cloud. Un server edge on-premise fornisce la risposta in tempo reale necessaria.
- High-Frequency Trading: Nei mercati finanziari, gli algoritmi devono essere fisicamente collocati vicino ai server di scambio per minimizzare il ritardo di rete. Qui, l’on-premise è l’architettura predefinita.
- Inferenza AI in tempo reale: Un chatbot live alimentato da un grande modello linguistico (LLM) deve fornire risposte istantanee. Sebbene le GPU cloud offrano una potenza enorme, un modello più piccolo e specializzato distribuito on-premise può garantire latenza inferiore per un compito specifico e ben definito.
Scalabilità ed elasticità
Questo è il vantaggio nativo del cloud. La scalabilità è la capacità di gestire un carico crescente, mentre l’elasticità è la capacità di approvvigionare e deprovisionare automaticamente le risorse per allinearsi con precisione alla domanda.
Con il cloud, un architetto può progettare un sistema che cresca da pochi utenti a milioni senza intervento manuale. La scalabilità on-premise è un ciclo lento e ad alta intensità di capitale di approvvigionamento, installazione e configurazione.
Si consideri una startup SaaS che lancia un nuovo prodotto. Un approccio on-premise impone una decisione difficile: sovraprovisionare l’hardware e sprecare capitale, oppure sottoprovisionare e rischiare il guasto del sistema al lancio. Un design cloud-native che utilizza gruppi di auto-scaling e funzioni serverless si adatta dinamicamente, ottimizzando in tempo reale sia costi sia prestazioni.
Sicurezza e controllo
La discussione sulla sicurezza ruota attorno a controllo versus responsabilità. L’on-premise fornisce controllo fisico e logico assoluto su hardware, rete e stack software. Questo significa anche che assumi il 100% della responsabilità per la protezione di ogni livello, dal controllo degli accessi al data center al patching del sistema operativo.
Il cloud opera con un modello di responsabilità condivisa. Il provider è responsabile della protezione dell’infrastruttura sottostante—i data center fisici, l’hardware e la rete core. Il cliente è responsabile della sicurezza di ciò che esegue nel cloud—i dati, le policy di accesso, il codice applicativo e le configurazioni. Sebbene questo modello scarichi un notevole carico operativo, introduce nuovi rischi. Un bucket di storage cloud configurato in modo errato può esporre dati sensibili molto più rapidamente e diffusamente rispetto a una vulnerabilità tradizionale di un server.
Conformità e sovranità dei dati
Per le organizzazioni soggette a normative come GDPR, NIS2 o DORA, la posizione fisica dei dati è un tema di conformità critico. La sovranità dei dati—il principio secondo cui i dati sono soggetti alle leggi del paese in cui si trovano—ha storicamente reso l’on-premise la scelta predefinita per i team legali e di compliance più prudenti.
Tuttavia, i principali provider cloud hanno investito molto per affrontare queste preoccupazioni. Oggi offrono regioni cloud specifiche (ad esempio a Francoforte o Parigi per i dati UE) con garanzie contrattuali per soddisfare i requisiti normativi locali. La decisione non riguarda più se i dati possano risiedere nel paese, ma se il tuo specifico quadro giuridico o profilo di rischio consenta a terzi di gestire l’infrastruttura sottostante, anche se i dati stessi non attraversano mai un confine.
Manutenzione e operazioni
Gestire un data center on-premise richiede un team dedicato con competenze in networking, gestione hardware, storage e virtualizzazione. Ciò rappresenta un investimento significativo e continuo in personale specializzato, responsabile di tutto, dalla sostituzione dell’hardware guasto alla gestione dei backup e al patching dei sistemi.
I servizi cloud astraono gran parte di questa gestione infrastrutturale. Ciò consente ai team di engineering di concentrarsi sullo sviluppo applicativo e sulla logica di business anziché sulla manutenzione hardware. Tuttavia, richiede un nuovo set di competenze incentrato su architettura cloud, infrastructure-as-code e ottimizzazione dei costi (FinOps). Un piano di disaster recovery robusto, ad esempio, rimane fondamentale nel cloud; i principi sono identici, ma implementazione e strumenti sono diversi.
Per consolidare questi punti, vediamo un confronto diretto.
Confronto degli attributi Cloud vs On-Premise
Questa tabella riassume le differenze fondamentali, offrendo un riferimento rapido ai leader tecnici che valutano la propria strategia infrastrutturale.
| Attributo | Cloud Computing (PaaS/IaaS) | Infrastruttura On-Premise |
|---|---|---|
| Modello di costo | OpEx: pagamento a consumo, basato su abbonamento. Evita grandi costi iniziali ma richiede gestione dei costi. | CapEx: investimento iniziale elevato in hardware e software, seguito da costi di manutenzione continui. |
| Scalabilità | Alta ed elastica: le risorse scalano automaticamente verso l’alto o il basso in base alla domanda in tempo reale. | Limitata e manuale: la scalabilità richiede l’acquisto e il provisioning di nuovo hardware, un processo lento. |
| Prestazioni | Eccellenti per carichi di lavoro distribuiti. La latenza può essere un fattore per applicazioni molto sensibili. | Ineguagliabili per attività a bassa latenza in cui la prossimità fisica alla sorgente è critica. |
| Sicurezza | Responsabilità condivisa: il provider protegge l’infrastruttura; tu proteggi i tuoi dati e le tue applicazioni. | Controllo totale: hai pieno controllo fisico e logico sull’intero stack di sicurezza. |
| Manutenzione | Manutenzione hardware minima. L’attenzione si sposta su architettura cloud, automazione e governance. | Richiede un team IT dedicato per hardware, patching e gestione dell’infrastruttura fisica. |
| Conformità | I provider offrono data center regionali e strumenti per soddisfare normative come il GDPR. | Offre una sovranità dei dati chiara e netta, poiché controlli l’esatta ubicazione fisica dei dati. |
La tabella rafforza il fatto che non esista un’unica opzione “migliore”. La scelta ideale è contestuale, guidata dai requisiti specifici di business, dalla tolleranza al rischio e dalla visione architetturale di lungo periodo.
Un framework decisionale per scegliere il tuo percorso
La scelta tra infrastruttura cloud e on-premise deve essere un processo strutturato e analitico. La decisione giusta dipende dai tuoi carichi di lavoro, dal contesto normativo e dagli obiettivi strategici. Una scelta superficiale può portare a un debito tecnico significativo, sforamenti di budget o gravi fallimenti di conformità.
Questo framework guida i responsabili tecnici e i manager della compliance attraverso le domande critiche che dovrebbero informare la strategia infrastrutturale, concentrandosi sulle realtà operative e sui compromessi architetturali.
Valutare il tuo carico di lavoro e la strategia di crescita
Per prima cosa, esegui un’analisi rigorosa dei sistemi che stai costruendo. Le caratteristiche uniche di ogni carico di lavoro sono i principali fattori che guidano la decisione tra cloud e on-premise.
Poni al tuo team queste domande chiave:
- La domanda è prevedibile o a picchi? Sistemi con traffico stabile e prevedibile, come le applicazioni interne di back-office, possono essere convenienti on-premise. Per carichi di lavoro con domanda volatile—come il lancio di un nuovo prodotto B2C o una campagna di marketing virale—l’elasticità del cloud è una funzionalità mission-critical.
- Qual è il nostro piano di crescita a lungo termine? Se l’espansione globale rapida fa parte della tua strategia, un’architettura cloud-native è quasi sempre la scelta corretta. Consente di entrare in nuovi mercati geografici senza l’investimento di capitale necessario per costruire data center fisici. Un’azienda con un focus regionale stabile potrebbe non avere bisogno di questa capacità.
- Quali sono i requisiti di latenza rigidi? Per casi d’uso come sistemi di controllo industriale, piattaforme di trading ad alta frequenza o robotica in tempo reale, una latenza inferiore al millisecondo non è negoziabile. Per questi sistemi, l’on-premise o l’edge computing sono una necessità tecnica.
Valutare i vincoli normativi e di conformità
Per molte organizzazioni, in particolare in settori come la finanza e la sanità in Europa, la conformità è un requisito architettonico fondamentale. Regolamenti come GDPR, NIS2 e DORA impongono regole rigorose sulla gestione dei dati, sulla residenza dei dati e sulla sicurezza che non possono essere aggiustate a posteriori.
La domanda critica sulla conformità non è se il cloud può essere conforme, ma se la tua organizzazione dispone della governance, dell’expertise e dei processi per renderlo conforme. L’on-premise offre un falso senso di sicurezza se le pratiche di sicurezza interne sono deboli.
La tua valutazione deve includere:
- Sovranità dei dati: Sei legalmente obbligato a conservare determinati dati entro specifici confini nazionali? Sebbene i principali provider cloud offrano regioni basate nell’UE, alcuni contratti governativi o dati altamente sensibili possono richiedere che non risiedano mai in una struttura di terze parti.
- Auditabilità e controllo: I tuoi revisori richiedono l’ispezione fisica dei server? Sebbene raro, questo è un requisito fermo in alcuni settori altamente regolamentati, rendendo l’on-premise un percorso più semplice per dimostrare il controllo.
- Postura di sicurezza: L’on-premise offre controllo totale ma anche responsabilità totale. Recenti exploit contro server Microsoft Exchange on-premises dimostrano che, senza un team di sicurezza dedicato per patching e monitoraggio continui, i sistemi autogestiti possono rappresentare una vulnerabilità significativa.
Analizzare l’expertise interna e i modelli finanziari
Infine, la tua decisione deve essere allineata alle competenze del tuo team e al modello finanziario della tua azienda. Adottare tecnologie cloud senza la necessaria expertise in cloud architecture e FinOps può essere rischioso quanto gestire un data center con un team IT sottodimensionato.
Valuta la tua prontezza operativa:
- Competenze tecniche: Il tuo team ha una profonda esperienza in network engineering, manutenzione hardware e virtualizzazione (per l’on-premise)? Oppure è esperto in cloud architecture, infrastructure-as-code e gestione dei costi (per il cloud)? La risposta determina il tuo percorso di minor resistenza.
- Preferenza finanziaria: Il tuo reparto finanziario preferisce spese in conto capitale prevedibili (CapEx) o spese operative flessibili (OpEx)? Le startup spesso si affidano al modello OpEx del cloud per preservare la liquidità, mentre le aziende consolidate possono preferire la prevedibilità di budget del CapEx.
Questa analisi strutturata chiarisce i compromessi del mondo reale. La tendenza del settore è chiara: le proiezioni mostrano che entro il 2026, la spesa per il public cloud rappresenterà il 60% dei principali mercati IT enterprise (scopri maggiori approfondimenti sulla crescita del cloud computing su Codegnan.com). Rispondere a queste domande garantisce che la tua decisione sia adattata al tuo contesto, e non solo una reazione alle tendenze di mercato.
Orientarsi tra architetture ibride e multi-cloud
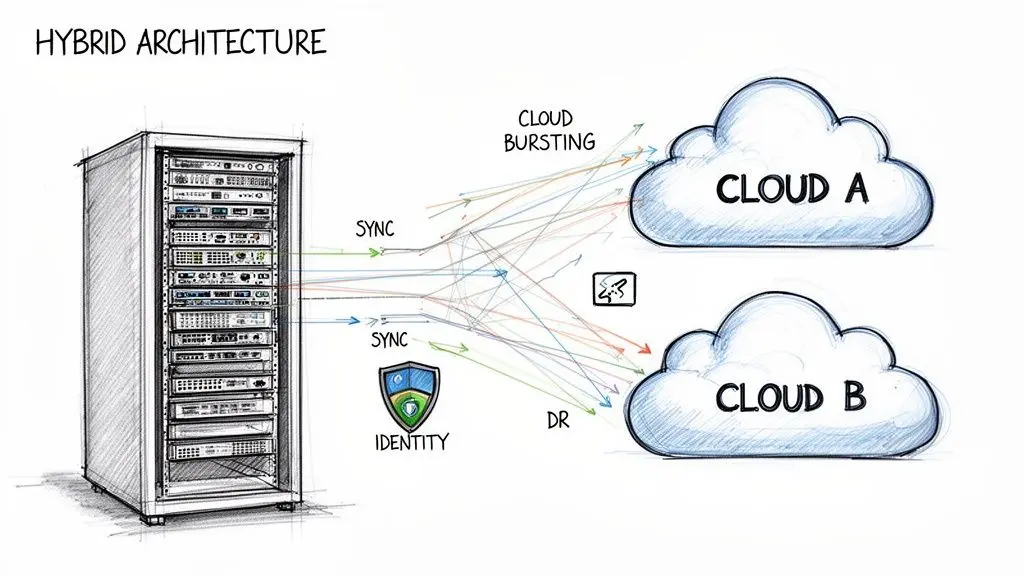
Il dibattito tra cloud e on-premise raramente si conclude con una scelta binaria. Le architetture moderne più resilienti ed efficaci spesso combinano entrambi in un modello ibrido, abbinando ogni carico di lavoro all’ambiente più appropriato. Questo approccio pragmatico sfrutta i punti di forza dell’infrastruttura privata (controllo, latenza) e dei cloud pubblici (scalabilità, servizi gestiti) per ottimizzare contemporaneamente prestazioni, costi e conformità.
Pattern architetturali ibridi comuni
Un’architettura ibrida non è una singola soluzione, ma una raccolta di pattern progettati per risolvere specifici problemi aziendali. Ogni pattern usa il cloud per le sue capacità uniche, mantenendo al contempo l’infrastruttura on-premise per attività che richiedono controllo assoluto o elaborazione a bassa latenza.
Tre pattern comuni offrono chiari vantaggi strategici:
- Cloud bursting: I carichi di lavoro di base e prevedibili vengono eseguiti on-premise. Durante un improvviso picco di traffico, il sistema si “espande” nel public cloud per gestire il carico in eccesso. Per una piattaforma di e-commerce, le operazioni quotidiane vengono eseguite su server privati convenienti, ma durante una vendita del Black Friday il sistema scala automaticamente nel cloud per prevenire tempi di inattività.
- Disaster Recovery (DR) basato su cloud: Mantenere un sito DR on-premise completamente ridondante è proibitivamente costoso. Un modello ibrido utilizza il cloud come target di failover, replicando dati e applicazioni critici on-premise verso un provider cloud. Ciò riduce drasticamente il costo della resilienza garantendo al contempo la continuità operativa.
- Sfruttare servizi cloud specializzati: Un’organizzazione potrebbe mantenere il proprio database transazionale core e i dati sensibili dei clienti on-premise per rispettare i rigorosi requisiti GDPR. Allo stesso tempo, può inviare in modo sicuro dati anonimizzati a un public cloud per accedere a potenti piattaforme AI e machine learning per l’analisi, senza esporre informazioni protette.
L’obiettivo di un modello ibrido è trattare l’infrastruttura come un portafoglio. Ogni componente viene collocato dove offre il massimo valore—sia in un public cloud per una scalabilità elastica, sia on-premise per un controllo assoluto.
Progettare per questa flessibilità richiede un’attenta pianificazione. I principi di architetture come Service-Oriented Architecture (SOA) sono preziosi per costruire i sistemi modulari e interoperabili necessari per una corretta implementazione ibrida.
L’ascesa delle strategie multi-cloud
Oltre a un singolo modello ibrido, molte organizzazioni stanno adottando una strategia multi-cloud, utilizzando servizi di più di un provider di public cloud (ad es. una combinazione di AWS e Azure). Questo approccio è guidato principalmente da due obiettivi strategici: evitare il vendor lock-in e migliorare la resilienza. Progettando applicazioni non strettamente legate ai servizi proprietari di un solo provider, un’organizzazione mantiene leva negoziale e libertà architetturale. Una configurazione multi-cloud offre anche un ulteriore livello di disaster recovery; un grave outage regionale presso un provider può essere mitigato effettuando il failover dei servizi verso un altro.
Sfide pratiche di implementazione
Adottare un’architettura ibrida o multi-cloud introduce una complessità significativa che deve essere gestita deliberatamente. Un’implementazione pianificata male può produrre un sistema frammentato, meno sicuro e più difficile da gestire rispetto a un ambiente puramente on-premise o a cloud singolo.
Le principali sfide di implementazione includono:
- Connettività di rete: Un collegamento sicuro, a bassa latenza e affidabile tra il tuo data center e il cloud è essenziale, richiedendo spesso connessioni dedicate che aggiungono costi e complessità.
- Sincronizzazione dei dati: Mantenere la coerenza dei dati in ambienti distribuiti è una sfida architettonica importante, che richiede meccanismi robusti per la replica e la risoluzione dei conflitti.
- Gestione unificata delle identità: Gestire l’accesso degli utenti su più piattaforme richiede una soluzione centralizzata di identity and access management (IAM) per prevenire lacune di sicurezza e oneri operativi.
- Osservabilità unificata: Monitorare le prestazioni, aggregare i log e gestire la sicurezza su sistemi eterogenei è notoriamente difficile. Ottenere una “single pane of glass” per l’osservabilità è fondamentale per un troubleshooting e un controllo efficaci.
Strategie comprovate per la migrazione al cloud
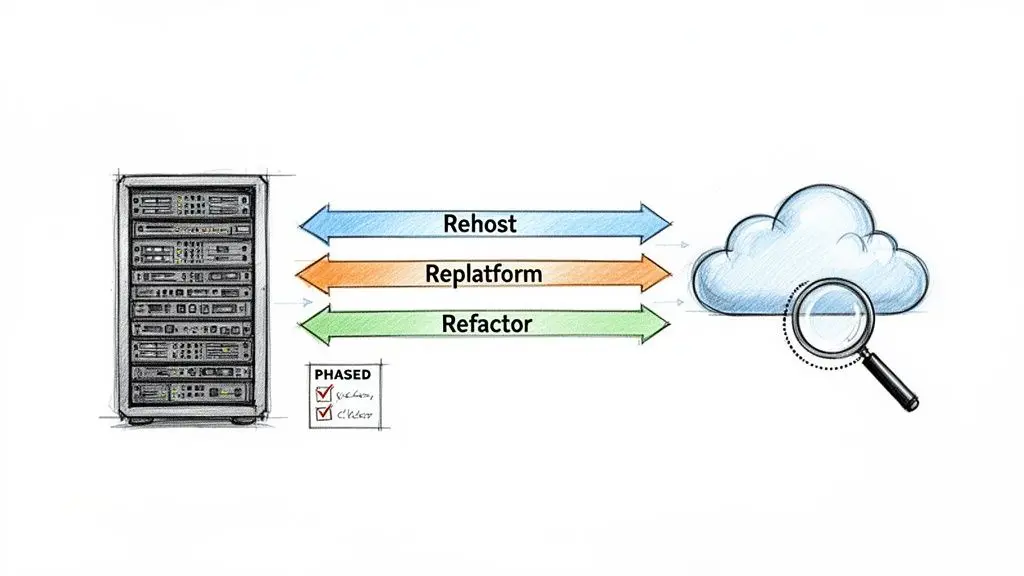
Migrare applicazioni da un’infrastruttura on-premise al cloud è un’iniziativa di ingegneria complessa, non un semplice progetto IT. Un approccio ingenuo può introdurre rischi inaccettabili, inclusi degrado delle prestazioni, vulnerabilità di sicurezza e sforamenti di budget che annullano i benefici previsti. Una migrazione di successo richiede una strategia metodica che bilanci velocità, costi e salute architetturale a lungo termine.
Il processo dovrebbe iniziare con una fase di discovery approfondita per mappare le dipendenze delle applicazioni e identificare i potenziali punti di guasto prima che diventino incidenti di produzione. Si tratta di scegliere il percorso di migrazione giusto per ogni specifico carico di lavoro, non di un mandato valido per tutti.
Rehosting: il modello “lift-and-shift”
Rehosting, comunemente noto come “lift-and-shift”, è il percorso di migrazione più diretto. Consiste nello spostare le applicazioni da server on-premise a macchine virtuali basate su cloud con modifiche minime o nulle all’architettura dell’applicazione.
Questo approccio è adatto a:
- Applicazioni legacy in cui modificare il codice sorgente è impossibile o troppo rischioso.
- Uscite rapide dal data center guidate dalla scadenza dei contratti di locazione o dal fine vita dell’hardware.
- Fasi iniziali di migrazione in cui l’obiettivo principale è stabilire rapidamente una presenza nel cloud prima di ottimizzare i carichi di lavoro.
Il principale vantaggio del rehosting è la velocità. Tuttavia, il suo svantaggio significativo è che spesso non sfrutta i benefici cloud-native come l’auto-scaling o il serverless computing. Ciò può tradursi in costi operativi più elevati nel cloud rispetto alla configurazione on-premise originale.
Replatforming: il modello “lift-and-reshape”
Replatforming, o “lift-and-reshape,” rappresenta un compromesso pratico. Questa strategia consiste nel fare modifiche mirate a un’applicazione per sfruttare i servizi cloud gestiti, ma senza una completa revisione architetturale.
Un esempio classico è la migrazione di un database on-premise a un servizio di database cloud gestito come Amazon RDS o Azure SQL Database. Questo scarica sul provider l’onere operativo di patching, backup e scalabilità dal team di engineering. Pur essendo più impegnativo del rehosting, il replatforming offre benefici tangibili riducendo l’overhead di manutenzione e migliorando la resilienza.
Refactoring: il modello di rielaborazione architetturale
Refactoring è la strategia di migrazione più intensiva. Implica la riprogettazione completa di un’applicazione affinché sia totalmente cloud-native. Spesso ciò significa scomporre un’applicazione monolitica in microservizi, adottare funzioni serverless e integrarsi profondamente con servizi gestiti dal cloud.
Questo percorso viene scelto quando l’obiettivo è raggiungere la massima scalabilità, prestazioni ed efficienza dei costi. Un’applicazione refactorizzata può scalare i singoli componenti in modo indipendente, ottimizzando l’utilizzo delle risorse e migliorando l’isolamento dei guasti. Sebbene richieda un investimento iniziale significativo in termini di ingegneria, il refactoring è l’unico modo per sfruttare pienamente le capacità del cloud. Una solida pipeline CI/CD è imprescindibile per questo approccio. La scelta tra rehosting, replatforming e refactoring deve essere fatta per singola applicazione, considerando il valore di business, il debito tecnico e la tolleranza al rischio.
Fare una Scelta Manutenibile e a Prova di Futuro
Il dibattito su cloud vs on-premise non riguarda la scelta di un vincitore definitivo. È un esercizio strategico di allineamento tra la tua base tecnica e gli obiettivi di business, le caratteristiche dei carichi di lavoro e la visione di lungo periodo. La decisione giusta è quella che oggi offre il massimo vantaggio, pur fornendo un percorso chiaro di evoluzione.
Una scelta a prova di futuro guarda oltre il progetto immediato, considerando la manutenibilità e l’agilità a lungo termine. La tua infrastruttura determina quanto rapidamente puoi rispondere ai cambiamenti del mercato, come gestisci il sovraccarico operativo e quanto sono resilienti i tuoi sistemi. Una decisione basata esclusivamente sul costo iniziale può creare un debito tecnico significativo, ostacolando crescita e innovazione.
Rivalutare i Principali Trade-off Architetturali
Nella sua essenza, la decisione si riduce a pochi trade-off critici. Devi dare priorità a ciò che conta di più per la tua organizzazione.
- Costo vs Flessibilità: L’on-premise offre un CapEx prevedibile ma ti vincola a una capacità fissa. Il cloud offre flessibilità OpEx ma richiede una governance rigorosa per evitare sforamenti di costo.
- Controllo vs Responsabilità: L’on-premise offre il controllo totale sull’intero stack, ma anche la responsabilità totale di garantirne la sicurezza e la manutenzione. Il modello di responsabilità condivisa del cloud scarica gran parte di questo peso, ma richiede nuove competenze nella gestione della configurazione e nell’automazione della sicurezza.
- Scalabilità vs Latenza: Per gestire una crescita imprevedibile, la scalabilità elastica del cloud è impareggiabile. Per specifici carichi di lavoro industriali o di high-frequency trading, l’on-premise offre una latenza bassissima non negoziabile.
- Conformità vs Agilità: Sebbene in passato l’on-premise rendesse semplice dimostrare la sovranità dei dati, oggi le region cloud moderne offrono soluzioni robuste, localizzate nel paese, che soddisfano normative stringenti come il GDPR, rendendo la conformità realizzabile in entrambi i modelli.
La tua infrastruttura è una scelta architetturale con conseguenze durature per la manutenibilità e l’agilità del business. Richiede decisioni deliberate e informate che vedano la tecnologia non come un centro di costo, ma come un abilitatore diretto dei tuoi obiettivi strategici. Che si tratti di cloud, on-premise o di un modello ibrido, la migliore architettura è quella scelta in modo consapevole.
Domande Frequenti dal Campo
Ecco risposte concise e pratiche alle domande che sentiamo spesso da CTO e responsabili IT che valutano la scelta tra cloud e on-premise.
Qual è il Maggior Costo Nascosto nel Cloud?
Il costo nascosto più comune e significativo sono le tariffe di data egress—il costo di trasferire i dati fuori dalla rete di un provider cloud. L’ingress (il trasferimento dei dati in ingresso) è quasi sempre gratuito, ma l’egress per backup, replica multi-cloud o per alimentare sistemi di analisi on-premise può portare a fatture inaspettatamente elevate. Questo è particolarmente vero per applicazioni ad alta intensità di dati come lo streaming video o l’addestramento AI su larga scala. Altri costi facilmente trascurati includono logging incontrollato, chiamate API eccessive e risorse sovradimensionate. Un controllo efficace dei costi richiede di progettare per l’efficienza fin dal primo giorno, non come ripensamento.
In Che Modo la Sovranità dei Dati Influisce Davvero su Questa Decisione?
La sovranità dei dati è un requisito legale non negoziabile per molte organizzazioni, che impone che i dati rimangano entro una specifica giurisdizione (ad esempio, il GDPR nell’UE). Storicamente, questo era un chiaro vantaggio dell’on-premise, poiché forniva controllo fisico assoluto e certezza sulla posizione dei dati. Oggi i principali provider cloud dispongono di region dedicate (ad esempio, AWS a Francoforte, Azure in Germania) progettate per soddisfare questi requisiti. La decisione dipende ora da un’interpretazione più sfumata del tuo framework di conformità: richiede semplicemente che i dati risiedano entro un confine nazionale (cosa che il cloud può gestire), oppure impone il controllo diretto e fisico dell’hardware stesso, escludendo l’infrastruttura di terze parti?
L’On-Premise È Davvero Mai Più Sicuro?
Sì, ma solo in scenari specifici e di nicchia. Per sistemi governativi o industriali altamente sensibili che devono essere “air-gapped”—completamente disconnessi da reti esterne—l’on-premise è l’unica architettura in grado di fornire un controllo assoluto su ogni livello fisico e di rete. Tuttavia, questo controllo comporta responsabilità assoluta. I provider cloud investono miliardi nella sicurezza, impiegando team d’élite e rilevamento delle minacce basato sull’IA che la maggior parte delle singole aziende non può eguagliare. Per la grande maggioranza delle imprese, un ambiente cloud ben configurato è molto più sicuro di una configurazione on-premise autogestita che si affida a un piccolo team per stare al passo con patch e monitoraggio continui.
Considera le recenti ondate di attacchi che hanno sfruttato vulnerabilità di Exchange o SharePoint on-premise. Questi incidenti dimostrano che, senza una vigilanza incessante, i sistemi autogestiti possono facilmente diventare una responsabilità maggiore di un ambiente cloud adeguatamente protetto.
Pronto a costruire un prodotto digitale robusto, manutenibile e a prova di futuro? Devisia è specializzata nel trasformare la tua visione in software affidabile, sia on-premise, nel cloud o in una combinazione ibrida di entrambi. Offriamo una delivery end-to-end con mentalità di prodotto, garantendo che la tua architettura sia allineata ai tuoi obiettivi di business a lungo termine.