
A familiar product request usually starts like this. The team wants better onboarding, sharper retention signals, or a smarter dashboard, and the fastest path seems obvious: use the customer data flowing through the platform.
That is where many companies make a poor legal and architectural decision. They assume legitimate interest means “we do not need consent, so we can proceed”. In practice, a legitimate interest assessment is not a shortcut. It is a structured test of whether the processing is justified, necessary, and proportionate for the people affected by it.
For software teams, that distinction matters. If you treat lawful basis as paperwork added after release, you usually end up defending weak purpose statements, over-collecting telemetry, and retrofitting controls that should have been designed into the system. If you treat it as an engineering decision, the assessment becomes useful. It forces clear scope, tighter data flows, and better boundaries around analytics, profiling, and AI features.
The Hidden Risks of Processing Data Without Consent
A common failure starts after a feature request is approved, not during legal review. The data pipeline already exists. Product wants better recommendations or churn signals. An engineer adds support data, usage events, and account metadata to the model input because it is faster than defining a narrower dataset first.
The legal problem is rarely the first query. It is the quiet expansion that follows. A dashboard analytics stream becomes behavioural profiling. A support classification workflow starts informing account scoring. An LLM feature built to summarise tickets begins ingesting free-text fields that contain personal details no one expected to reuse. By the time anyone asks whether legitimate interest applies, the architecture already assumes broad reuse.
That sequence creates weak LIAs. Teams write them after the design is fixed, so the assessment documents the existing system instead of testing whether the system should work that way at all.
GDPR enforcement, beginning May 25, 2018, requires the three-part test of purpose, necessity, and balancing. In practice, that means teams need more than a short statement that the processing helps the business. They need a clear purpose, evidence that the chosen data is required, and a documented view of the impact on the people behind the records.
For SaaS and AI products, the hidden risk is scope creep inside normal engineering decisions. Event retention gets extended because storage is cheap. Identifiers stay in the warehouse because they might help with debugging later. Model prompts include raw customer text because redaction was left for a later sprint. Each choice looks minor on its own. Together they create processing that is harder to justify, harder to explain to users, and harder to scale safely across regions and product lines.
What goes wrong in practice
The recurring issue is poor scope control.
- Purposes drift. “Service improvement” becomes a catch-all label for segmentation, ranking, fraud review, feature targeting, or sales prioritisation.
- Necessity is never tested. Teams keep raw logs, persistent identifiers, and detailed event histories without checking whether aggregated metrics, shorter retention, or pseudonymous IDs would achieve the same result.
- Balancing is treated as a formality. The assessment omits the effect on users, especially where the processing changes recommendations, visibility, eligibility, or internal risk scores.
- Consent mechanics get mixed in too late. A team builds around legitimate interest, then discovers that part of the feature would have been cleaner with user choice and clearer opt-in and opt-out patterns.
A useful LIA changes architecture. It reduces data collected, narrows access, shortens retention, or separates high-risk processing from routine analytics. If the document leaves the system untouched, it usually has not examined the trade-offs.
Choosing Your Lawful Basis Legitimate Interest vs Consent
Before drafting an LIA, decide whether legitimate interest is the right lawful basis at all. Teams often rush this decision because consent feels expensive and legitimate interest feels flexible.
That instinct is understandable, but it is not reliable.
The six lawful bases in operational terms
Under GDPR, processing personal data requires a lawful basis. In software delivery, the six bases are best treated as design constraints.
-
Consent Use this when the person has a real choice and can refuse without detriment.
-
Contract Use this when processing is required to deliver the service the user asked for.
-
Legal obligation Use this when another law requires the processing.
-
Vital interests Relevant in narrow cases involving protection of life.
-
Public task Mostly relevant to public authorities.
-
Legitimate interests Use this when the processing supports a real and lawful business or third-party interest, is necessary for that purpose, and does not override the person’s rights and freedoms.
For most SaaS companies, the common decision is usually between consent, contract, and legitimate interests.
When consent is the better answer
Consent is not just a banner or a checkbox. It creates a reversible permission model. That is useful when the processing is optional, especially if the user would not reasonably expect it without a specific prompt.
Examples where teams should examine consent very carefully include:
- Optional personalisation features that are not required to operate the service
- Marketing and tracking choices that sit outside core service delivery
- Processing involving sensitive or high-risk contexts, where a broad legitimate interest argument is unlikely to be defensible
If your team is still unclear on the mechanics of opt-in and opt-out design, this guide on opt-in and opt-out choices is a useful operational reference.
When legitimate interest is often the stronger basis
Legitimate interest can be more appropriate where the processing is closely tied to secure, reliable, and expected service operations.
Examples include:
- Fraud prevention
- Network and application security
- Certain forms of product analytics
- Service quality monitoring
- Customer experience improvements within an existing relationship
The distinction is expectation. An existing customer usually expects some level of monitoring to keep the service secure and usable. That does not mean every analytics feature is covered. It means the starting point is more defensible than with a prospect who has never used the product.
In Italy’s IT sector, LIA reliance accounted for 62% of GDPR-based processing by software development firms in 2024, compared with 28% for consent, according to the cited source discussing the Garante’s annual reporting (Ipsos page referencing the balancing test data). That tells you how common this basis has become in software companies. It does not make it automatically safe.
A practical decision filter
Ask four questions before choosing legitimate interest:
- Is the purpose specific enough to explain to a regulator and to a user?
- Would the user reasonably expect this processing in the product context where the data was collected?
- Can the same outcome be achieved with less data or a less intrusive method?
- If the user objected, would your justification still sound proportionate?
If any answer is weak, stop and reassess the basis.
Consent is not weaker because it is stricter. In many systems, consent is cleaner because it aligns the product boundary with the user’s expectation boundary.
A bad pattern is choosing legitimate interest because consent management is inconvenient. A sound pattern is choosing legitimate interest because the processing is operationally necessary, narrow in scope, and supported by clear safeguards.
Executing the Three-Part LIA Test
A product team ships a useful feature. Login anomaly detection, in-app usage analytics, prompt logging for an LLM assistant, or support transcript review for model tuning. The feature works. The LIA fails because nobody defined the purpose tightly, nobody proved the data was necessary, and nobody documented why users would reasonably expect the processing.
That is the three-part test in practice. It is not a legal formality. It is a design review for data use.
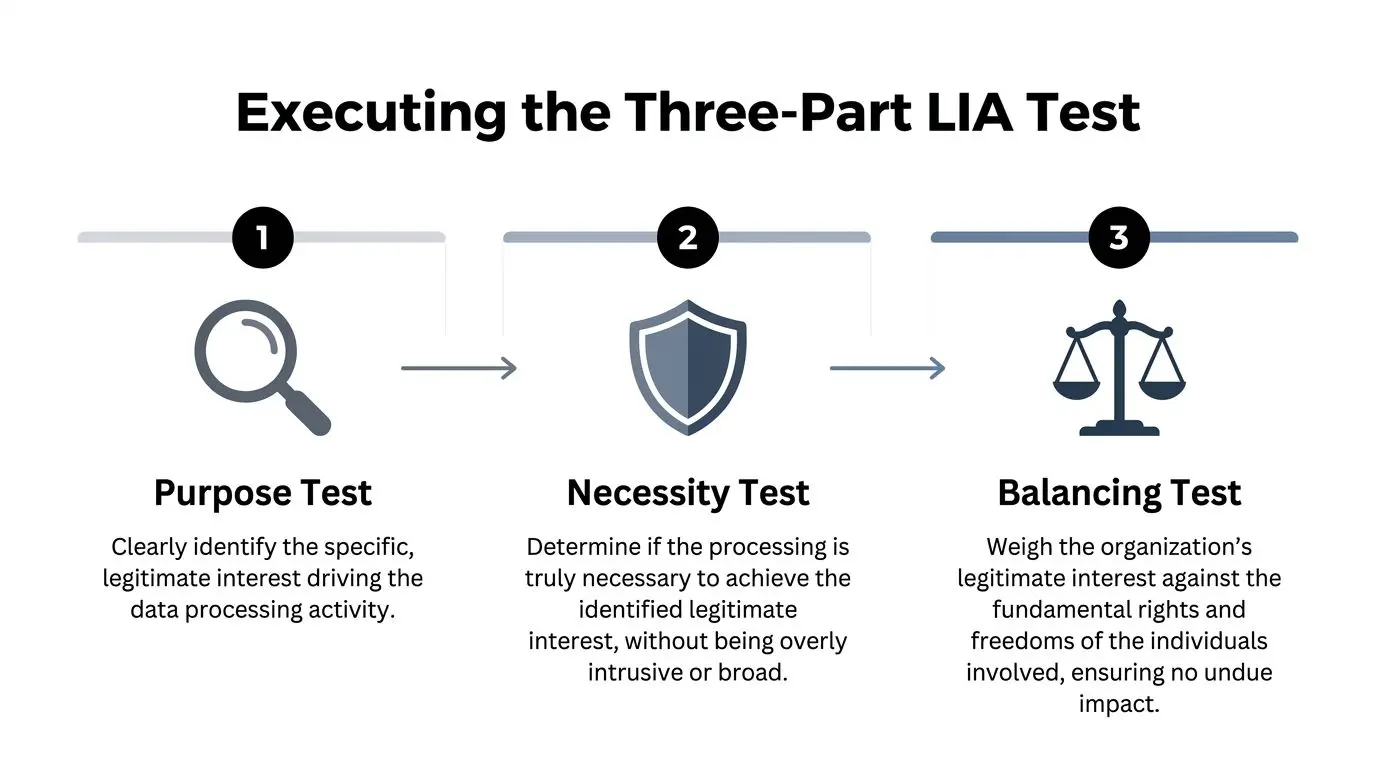
For SaaS and AI teams, the test works best when it is tied to system design decisions. Run it when a team proposes a new processing activity, changes retention, adds a vendor, expands analytics scope, or reuses existing data for a new model or feature. If the LIA starts after launch, it usually turns into a justification exercise instead of an honest review.
Purpose test
Start with one question. What interest is the company pursuing?
Weak LIAs describe an aspiration. Good LIAs describe an operational objective that another team could challenge, implement, and audit. “Improve the platform” is too vague to defend. It does not identify the workflow, the affected users, or the data needed.
A defensible purpose statement usually includes four elements:
-
The operational goal Example: detect fraudulent account access in an enterprise admin portal.
-
The business or user benefit Example: reduce account compromise and preserve service integrity.
-
The processing activity Example: analyse login metadata, device change events, and repeated failed authentication attempts.
-
The scope boundary Example: exclude use for marketing, advertising, or unrelated profiling.
Compare these two statements:
-
Weak We process user behaviour to improve the platform.
-
Stronger We process authenticated user interaction data from the reporting module to identify navigation failures and reduce repeated support incidents for existing customers.
The second version is better because engineering can build to it and governance can test it. That matters in modern SaaS systems, where the same event stream is often reused across analytics, experimentation, security, and AI features. If the purpose is broad, every later reuse looks “close enough,” and the LIA stops setting a real boundary.
Necessity test
The necessity test forces a harder question. Is this processing required for the stated purpose, or is it available because the platform already collects the data?
Architecture matters here. Teams often pass the purpose test, then fail necessity because they ingest too much, keep it too long, or use identifiable records where pseudonymous or aggregated data would have done the job.
Ask the review in technical terms:
- Do we need personal data at all?
- If yes, do we need direct identifiers, or will pseudonymous IDs work?
- Can aggregate telemetry achieve the same outcome?
- Can fields be removed before ingestion?
- Can retention be shortened without breaking the use case?
- Can access be limited to a smaller operational group?
The strongest LIAs point to concrete design choices, not intentions.
Useful patterns include:
-
Edge filtering Remove unneeded fields before they enter analytics or training pipelines.
-
Pseudonymous event identifiers Keep behavioural analysis separate from identity resolution unless an approved workflow requires re-linking.
-
Tiered retention Keep raw logs briefly, then convert them into aggregated or summarised records.
-
Feature-specific datasets Prevent a general-purpose data lake from becoming the default source for every new initiative.
This matters even more for AI systems. If a team wants to use support tickets, chat logs, or prompt histories for model improvement, necessity should be tested at field level. Full transcripts, account identifiers, attachments, and free-text content create a very different risk profile from redacted excerpts or labelled metadata. If the goal is intent classification, raw content may be excessive. If the goal is abuse detection, short-lived event data may be enough.
If aggregated telemetry can meet the purpose, using raw user content is usually difficult to justify.
Balancing test
The balancing test asks whether the organisation’s interest is overridden by the person’s rights and freedoms. Teams often treat this as a general statement about low risk. That is not enough.
The balancing analysis should focus on how the processing feels from the user side and what the system does with the data. An internal feature can still be intrusive. A useful feature can still be unexpected. A low-probability harm can still matter if the consequence is serious or hard for the user to detect.
Risk usually increases when the processing involves:
- Profiling that changes user treatment
- Unexpected reuse of existing data
- Long retention of behavioural records
- Special category data or vulnerable users
- AI features that infer preferences, risk, or intent
- Opaque decision logic that users cannot understand or challenge
Reasonable expectations carry a lot of weight here. Existing customers may expect security monitoring, service analytics, and limited product improvement work. They are less likely to expect broad profiling, indefinite retention, or secondary use of support conversations to train internal AI systems. Context matters. So does product design. If users only discover the processing in a privacy notice, expectations are probably weak.
Evidence makes the balancing stage defensible:
| Evidence area | What to capture |
|---|---|
| User relationship | Existing customer, trial user, employee, prospect |
| Data category | Usage events, support content, account metadata, free text |
| Expectation analysis | Why the user would or would not expect this processing |
| Control measures | Opt-out, access controls, retention limits, human review |
| Residual risk | What remains risky even after safeguards |
For example, if a support quality model uses internal transcripts, document the controls in operational terms. State whether transcripts are screened for unnecessary identifiers, whether free text is redacted before training or evaluation, who can access raw records, how long they are kept, and whether the output affects user treatment. That is the level of detail regulators expect and the level engineering teams need if they want the assessment to shape the system.
A valid LIA is a record of decisions the product and data architecture implement.
A Pragmatic Scoring Model for the Balancing Test
A balancing test usually fails in a familiar product review scenario. The team wants to ship a useful feature, legal accepts that legitimate interest might apply, and the ticket closes with a vague conclusion that user impact is “low.” That is not enough for a SaaS platform with event pipelines, support data, feature flags, and LLM components touching the same records in different ways.
Engineering teams need a method that survives design changes and audit questions. A scoring model gives the balancing test that structure. It does not replace judgment. It forces the team to show which architectural choices reduce risk and which ones make the justification harder to defend.
How to score the balance
Use a -10 to +10 range for each factor, then require written reasoning beside every score.
- Negative values reflect impact on the individual.
- Positive values reflect business need, service integrity, or clear user benefit.
- Evidence should outweigh assumptions.
- A safeguard only earns points if the system enforces it.
The point is consistency. If one product squad gives a +5 for pseudonymisation and another gives it +1, the discrepancy should trigger review. Over time, the scoring rubric becomes a practical standard for privacy engineering decisions, much like severity ratings in security review.
Sample Balancing Test Scoring Matrix
| Factor | Impact/Benefit Score (-10 to +10) | Justification |
|---|---|---|
| Fraud reduction in account activity monitoring | +8 | Strong operational need tied to service security and customer protection |
| Existing customer relationship | +4 | Users are already using the service and can expect some security monitoring |
| Use of pseudonymous identifiers in analytics layer | +3 | Reduces direct exposure of identities during routine analysis |
| Behavioural profiling at individual level | -6 | Can affect how users are assessed or treated inside the service |
| Limited transparency in feature explanation | -4 | Users may not fully understand that behavioural signals drive outcomes |
| Retention of raw event history beyond immediate need | -5 | Increases intrusion and future misuse risk |
| Human review before significant action | +3 | Reduces unfair automated outcomes |
| Processing of free-text support content | -4 | Free text may contain unexpected personal details |
A matrix like this works best when scores are tied to implementation details. “Human review” means a defined approval step, named reviewers, and logs that show the review happened. “Pseudonymous analytics” means identifiers are separated, access paths are restricted, and downstream tools do not rejoin the data.
Worked example for a B2B SaaS personalisation feature
Consider a team building workspace personalisation from click paths, time spent in modules, and support history. The stated purpose is reasonable. Help existing customers find the next task faster and reduce product friction. The balancing result depends less on that purpose than on how the data flow is designed.
Version one of the design
The first design includes:
- raw event streams tied to named users
- support tickets ingested with full free text
- long retention for model tuning
- ranking logic that changes what each user sees without a clear explanation
This version creates avoidable negatives. It combines behavioural data with support context, keeps raw records too long, and makes the feature harder to explain to users and internal reviewers. If an LLM is added later for summarisation or recommendation generation, the risk increases again because free text often carries unexpected personal data and sensitive context.
Version two of the design
The revised design includes:
- pseudonymous workspace-level event analysis
- support categories instead of full ticket text
- short raw-log retention followed by aggregation
- human review for recommendations that could materially affect user workflows
- an in-product explanation of why recommendations appear
The purpose did not change. The score did. The team reduced identifiability, narrowed the data categories, and added controls that product and engineering can prove in practice.
That is the useful outcome of a balancing test. It gives teams a reason to redesign pipelines, feature logic, and retention rules before launch, not after a complaint.
A useful threshold
Set a launch threshold that fits the organisation, but make it operational. A common approach is to require a clearly positive net score, escalate any unresolved high-impact negative factor, and open a broader review if profiling, monitoring, or model behaviour creates uncertainty. Teams that already run privacy reviews can connect that escalation point to a privacy impact assessment workflow, so escalation is based on defined criteria rather than last-minute judgement calls.
The categories should stay stable across products so results are comparable:
- Expectation and transparency
- Data sensitivity
- Ability to object
- Risk of unfair profiling
- Scope and retention
- Safeguards and human oversight
For CTOs, this produces something more useful than a one-line legal sign-off. It creates a decision record that maps directly to schemas, retention jobs, access controls, and model boundaries. That is what makes an LIA defensible in modern SaaS and AI systems.
Integrating LIAs into Your Governance Framework
A SaaS team ships a feature behind a flag, then six weeks later routes the same event stream into a recommendation engine, a support dashboard, and an LLM prompt layer. The code changed faster than the governance record. That is how a defensible LIA turns into a stale document that no longer matches the system in production.
The fix is operational. Treat the LIA as part of the delivery process, with links to architecture decisions, release gates, and change approval, so the reasoning stays aligned with the data flows.
Where the LIA belongs in the lifecycle
The right place for an LIA is alongside product and engineering decisions, not after implementation. In practice, three checkpoints matter.
-
Discovery Record the purpose, the expected user benefit, and the lawful basis before the team commits to a solution. If the purpose is vague at this stage, the rest of the assessment will drift.
-
Design review Confirm which data fields enter the service, where they are stored, whether identifiers can be reduced, and what controls are technically realistic. This is usually the point where engineers can still change schemas, retention windows, or prompt construction without expensive rework.
-
Change review Reassess when a feature starts using new data categories, adds profiling logic, expands to a new customer segment, or introduces model-based inferences. For AI-enabled products, this often happens through incremental changes that look harmless in isolation.
Higher-risk outcomes from the LIA should trigger a broader review path. Teams that formalise that handoff usually connect it to a privacy impact assessment workflow, so escalation is based on defined criteria rather than last-minute judgement calls.
Documentation that helps
A useful LIA record lets a reviewer understand the processing without reverse-engineering Jira tickets, source code, and vendor settings. Legal wording alone is not enough. The record should show how the assessment maps to the system that runs.
Include:
- System name and accountable owner
- Processing purpose in plain language
- Chosen lawful basis and rejected alternatives
- Data categories, identifiers, and sources
- Affected users or customer groups
- Balancing analysis and implemented safeguards
- Retention, deletion, and access rules
- Review date, version history, and change triggers
- Links to architecture notes, ROPA entries, and release approvals
The strongest LIAs also attach evidence. A data flow diagram, retention config, feature flag scope, or model input specification does more to support the reasoning than a polished paragraph full of abstractions.
Linking the LIA to ROPA and DPIA workflows
The ROPA should reflect the same purpose, categories, recipients, and retention logic described in the LIA. If engineering narrowed a dataset for the balancing test, that narrowing should appear in the ROPA as well. Broad descriptions such as “service improvement” create avoidable risk when the implemented use case is much more specific.
DPIA triggers
Some LIAs show that the processing can proceed with safeguards. Others show that the team needs a fuller risk review before launch. Common triggers include:
- Expanded profiling or behavioural scoring
- Use of AI models on user-generated content
- Automated ranking that shapes visibility or access
- Processing that materially changes the user experience
- Reuse of data outside the original collection context
A disciplined privacy programme uses the LIA to detect those cases early, while architectural changes are still cheap.
Versioning and ownership
Version the LIA like any other design artefact. Tie updates to release milestones, schema changes, vendor changes, and major model revisions.
Clear ownership matters because each function holds different evidence. Product defines the business objective and expected benefit. Engineering documents data flows, controls, and system boundaries. Privacy tests the lawful basis and checks consistency with notices and records. The DPO reviews the reasoning, challenge points, and documentation trail.
That split avoids a common failure mode in modern SaaS teams. Someone completes the template once, the feature evolves through analytics events, API integrations, and model prompts, and the approved LIA no longer describes the live system.
Applying LIAs to AI Systems and Modern SaaS
Generic LIA guidance often breaks down when applied to AI features. Modern SaaS products mix telemetry, free text, support content, embeddings, agent traces, and model outputs. That makes purpose creep very easy.
In Italy, scrutiny is increasing. A cited source notes that 2025 fines for undocumented AI profiling reached €12.5 million, and that an estimated 68% of audits in this area fail on AI-specific balancing tests (Shoosmiths on when to use a legitimate interest assessment). That is exactly why AI use cases need tighter LIA discipline.
Teams working through these issues also need a broader engineering view of data protection and privacy in software systems, because the LIA only works when the surrounding controls are real.
Scenario one using support chats to improve an internal LLM assistant
A company wants to use historic support chats to improve an internal assistant for support agents. The idea is sensible. Better retrieval and suggested answers can reduce handling time and improve consistency.
The purpose may be legitimate. The necessity question is the difficult part.
If the team pushes full transcripts, account identifiers, and open-text customer narratives into a fine-tuning or retrieval pipeline, the processing becomes hard to defend. Support chats often contain unexpected personal details. They also contain context that users may expect to remain inside the support interaction, not become training material.
A safer design usually looks like this:
- Purpose scope limited to internal support quality
- Filtering of unnecessary identifiers before ingestion
- Use of curated knowledge snippets rather than unrestricted full transcripts
- Clear retention rules for prompt and retrieval logs
- Human review of suggestions before they affect a customer response
The balancing question hinges on surprise and downstream use. Internal assistance for support staff is easier to justify than broad model training for unrelated product features.
Scenario two AI-driven personalisation from behaviour data
A SaaS platform wants to adjust the dashboard based on clicks, dwell time, abandoned workflows, and prior feature usage. This is a common product request because it sits at the intersection of UX, analytics, and machine learning.
The purpose may be framed as customer experience enhancement. That is not enough on its own.
The harder questions are these:
- Does the user expect individual behavioural profiling?
- Does the model merely reorder helpful content, or does it materially shape what options the user sees?
- Can the same benefit be delivered through cohort-based recommendations rather than person-level prediction?
- Is there an easy way to object or disable the feature?
If the answer requires person-level tracking across a long history, the balancing case weakens. If the system instead uses recent, limited-scope interaction signals inside an existing customer relationship, and the recommendation can be explained in plain language, the balance is easier to support.
Scenario three observability logs from AI agents
AI agents create a new LIA problem because observability can become surveillance by accident. To debug failure modes, teams often log prompts, tool calls, intermediate steps, outputs, and user feedback.
That is operationally useful. It also creates a dense record of user behaviour, intent, and free text.
A weak implementation stores everything indefinitely in one debugging sink. A stronger implementation separates concerns:
- Operational telemetry for latency, error rates, and tool failures
- Content logging only where necessary for diagnosis
- Redaction or filtering before storage
- Restricted access for debugging teams
- Short retention with explicit escalation paths for incident cases
AI logging should default to the minimum needed for reliability. If every prompt becomes permanent history, your necessity argument is already in trouble.
What usually fails in AI LIAs
The recurring mistake is not the use of AI itself. It is combining too many purposes into one pipeline.
For example:
- support data becomes product analytics input
- product analytics becomes personalisation training data
- observability logs become reusable model improvement data
Each step may look efficient. Together, they create unexpected secondary use.
That is why AI LIAs should be reviewed alongside model cards, logging design, retention schedules, and fallback logic. The legal basis cannot be defended in isolation from the architecture.
Conclusion A Defensible and Architectural Choice
A legitimate interest assessment is useful only when it changes decisions. If it sharpens the purpose, reduces the data collected, tightens retention, and pushes riskier features into deeper review, it is doing its job.
That is the primary value for CTOs and product leaders. A good LIA is not a legal memo attached to delivery after the fact. It is a design constraint that improves the system. It forces the team to justify why the processing exists, why the chosen method is necessary, and why the impact on people is proportionate.
The practical pattern is consistent:
- Choose the lawful basis deliberately
- Define the purpose with enough precision to be challenged
- Test necessity through minimisation and architectural alternatives
- Run the balancing test with evidence, not intuition
- Connect the outcome to DPIAs, ROPA entries, and change management
- Revisit the assessment when the system expands into new data uses
A simple final checklist helps before launch:
- Purpose check. Can the team describe the processing in one precise sentence?
- Necessity check. Has the team rejected less intrusive alternatives for stated reasons?
- Balancing check. Are user expectations, objections, and safeguards documented?
- Governance check. Is the LIA linked to records, reviews, and owners?
- Change check. Are there triggers for reassessment when the feature evolves?
- AI check. If models, embeddings, or agent logs are involved, have secondary uses been separated and controlled?
Privacy is strongest when it is built into architecture. Legitimate interest is no exception.
If your team is building SaaS platforms, AI workflows, or data-heavy product features and needs help turning privacy requirements into workable architecture, Devisia can help design systems that are maintainable, compliant, and grounded in real engineering trade-offs.