
Per troppo tempo, protezione dei dati e privacy sono state trattate come semplici caselle da spuntare per la conformità. Questa visione è un errore tecnico e strategico. Per i leader B2B, si tratta di scelte ingegneristiche deliberate che definiscono sistemi software moderni e resilienti.
Fare le cose nel modo giusto non serve principalmente a evitare multe; serve a salvaguardare la fiducia dei clienti, ridurre il debito architetturale e costruire un vantaggio competitivo duraturo.
Perché la protezione dei dati è una preoccupazione architetturale fondamentale
La conversazione sulla protezione dei dati è maturata. Non è più un compito dell’ultimo minuto per il reparto legale o una funzionalità aggiunta poco prima del lancio. Oggi è un principio centrale di una solida ingegneria del software e un pilastro della strategia aziendale.
Per founder, CTO e product leader, osservare la privacy da una prospettiva esclusivamente orientata alla conformità è un errore strategico. Normative come il GDPR non sono solo ostacoli burocratici; codificano diritti fondamentali degli utenti che si traducono direttamente in requisiti architetturali. Un sistema non progettato tenendo conto della privacy è, per definizione, un sistema difettoso. Porta con sé rischi latenti che prima o poi emergono sotto forma di multe devastanti, danni reputazionali e refactoring costosi e dolorosi.
Il mandato architetturale
Trattare la privacy come una scelta architetturale significa che essa influenza le decisioni fin dal primo giorno del ciclo di sviluppo. Questa filosofia riguarda la costruzione di sistemi sicuri e conformi by design, non per caso.
Privacy by design è un approccio proattivo e preventivo che inizia prima ancora che venga scritta una sola riga di codice. Significa prendere decisioni architetturali fondamentali che riducono al minimo l’esposizione dei dati per impostazione predefinita. La sicurezza si chiede: “I dati sono protetti?” La privacy by design si chiede: “Abbiamo davvero bisogno di questi dati in primo luogo?”
Questa guida offre un approccio pragmatico, orientato all’ingegneria, alla protezione dei dati. Elimineremo il gergo legale e forniremo a CTO e product manager indicazioni operative su:
- Principi fondamentali: tradurre i requisiti legali in vincoli ingegneristici concreti.
- Pattern architetturali: implementare minimizzazione dei dati, pseudonimizzazione e controlli di accesso robusti.
- Minacce moderne: mettere in sicurezza il vostro stack tecnologico contro i rischi contemporanei di cybersecurity.
- Sfide specifiche dell’AI: affrontare le particolari complessità di privacy dei sistemi AI e LLM.
Questo approccio proattivo non riguarda solo la gestione del rischio. Un framework robusto di protezione dei dati è un potente elemento di differenziazione sul mercato. Segnala un profondo rispetto per i dati dei clienti, costruendo fiducia e fedeltà nel lungo periodo. Comprendere il ruolo di un data protection manager può anche offrire spunti chiave su come rendere operativi questi principi.
Orientarsi nel panorama globale della protezione dei dati
Per i leader dell’ingegneria e del prodotto, la rete globale di normative sulla protezione dei dati—GDPR, CCPA, NIS2, DORA—può sembrare un groviglio intimidatorio di acronimi.
La chiave non è memorizzare ogni singolo articolo, ma comprendere i principi ingegneristici fondamentali che li collegano. Queste leggi non sono solo documenti legali; sono specifiche tecniche che stabiliscono come deve essere costruito il software moderno. Traduccono idee giuridiche astratte come base giuridica, minimizzazione dei dati e diritti fondamentali degli utenti in vincoli ingegneristici concreti. Affinché un sistema sia conforme, la sua architettura deve basarsi su questi pilastri. Un approccio basato solo sulle policy non è sufficiente.
Dai principi legali ai vincoli ingegneristici
Una base giuridica significa che per ogni dato personale che trattate dovete avere una ragione chiara e documentata. Non si tratta di un esercizio di spunta di caselle; richiede un collegamento diretto e dimostrabile tra i dati raccolti e il servizio fornito. Se raccogliete la posizione di un utente, il vostro sistema deve avere una funzionalità, come il tracciamento delle consegne locali, che ne richieda l’uso.
La minimizzazione dei dati è la disciplina ingegneristica che consiste nel raccogliere solo ciò che è assolutamente essenziale e, cosa altrettanto importante, cancellarlo quando non serve più. Un approccio ingenuo è creare un’unica tabella monolitica “users” con decine di colonne nullable, “per ogni evenienza”. Un’architettura privacy-first, invece, suddividerebbe i dati in servizi distinti, orientati allo scopo. Questo garantisce che un sistema di analisi comportamentale, ad esempio, non abbia alcun accesso ai dettagli di pagamento di un utente.
Infine, i diritti dell’utente come accesso, rettifica e cancellazione non sono funzionalità che potete aggiungere in seguito. Richiedono scelte architetturali specifiche fin dal primo giorno.
Una richiesta di accesso dell’interessato (DSAR), o “diritto di sapere”, non è un ticket di supporto; è un test di stress architetturale. Richiede ai vostri sistemi di individuare, aggregare ed esportare ogni singolo dato di un utente in tutti i vostri microservizi, database e log di terze parti. Senza una mappa dei dati robusta e flussi di lavoro automatizzati, questo diventa un compito frenetico, manuale e quasi impossibile.
Questa realtà costringe i team di ingegneria a progettare sistemi con funzionalità di recupero e cancellazione dei dati fin dall’inizio.
Le conseguenze reali della non conformità
La motivazione per implementare correttamente questi principi è sempre più finanziaria. Il panorama della conformità è maturato e i regolatori stanno esercitando una pressione senza precedenti. In base a framework come il GDPR, le aziende rischiano multe fino a 20 milioni di euro o il 4% del fatturato annuo globale per violazioni significative.
Gli Stati Uniti seguono una traiettoria simile. Entro il 2026, 20 stati applicheranno proprie leggi sulla privacy dei consumatori, creando un mosaico complesso per qualsiasi azienda che operi su scala nazionale. Potete approfondire questi dati in evoluzione e capire cosa significano per i leader aziendali.
Questo cambiamento dimostra che i regolatori non si limitano più a leggere i documenti di policy; stanno esaminando il codice e l’infrastruttura. Un algoritmo di hashing debole, un’API insicura o l’impossibilità di rispettare una richiesta di cancellazione sono tutti fallimenti tecnici con conseguenze finanziarie molto reali.
Le principali normative sulla protezione dei dati in sintesi
Osservare queste normative attraverso una lente ingegneristica le rende molto meno intimidatorie. Invece di perderci nel testo legale, possiamo concentrarci su ciò che significano per la nostra architettura e per le funzionalità del prodotto. La tabella seguente traduce le principali normative dal legalese in attività ingegneristiche.
| Normativa | Ambito geografico | Principio chiave per gli ingegneri | Esempio di implementazione |
|---|---|---|---|
| GDPR (Regolamento generale sulla protezione dei dati) | Unione Europea | Consenso e base giuridica | Costruire una piattaforma granulare di gestione del consenso in cui gli utenti possano aderire a usi specifici dei dati (ad es. analisi vs. marketing) e revocare facilmente tale consenso. |
| CCPA/CPRA (leggi californiane sulla privacy) | California, USA | Diritto di opt-out e trasparenza | Implementare un link “Do Not Sell or Share My Personal Information” e progettare il backend in modo che rispetti questo flag in tutte le integrazioni pubblicitarie e di condivisione dei dati. |
| Direttiva NIS2 | Unione Europea | Cybersecurity e segnalazione degli incidenti | Creare sistemi di logging centralizzati e robusti e sistemi di alert automatici in grado di rilevare una violazione e raccogliere i dati necessari per la segnalazione entro la rigorosa finestra di notifica di 24 ore. |
| DORA (Digital Operational Resilience Act) | Settore finanziario dell’UE | Rischio di terze parti e resilienza | Progettare sistemi con chiari meccanismi di failover ed eseguire test di penetration obbligatori sulle dipendenze software critiche di terze parti. |
In definitiva, orientarsi nel panorama globale della protezione dei dati è una sfida ingegneristica. Traducendo i principi in architettura, i leader tecnici possono costruire sistemi non solo conformi, ma anche più robusti, affidabili e resilienti by design.
Implementare la privacy by design nella vostra architettura software
La teoria legale è chiara. Ma come tradurre protezione dei dati e privacy da una checklist di conformità in software reale e funzionante? È qui che la Privacy by Design smette di essere una parola d’ordine e diventa un insieme di principi ingegneristici.
L’obiettivo è rendere la privacy lo stato predefinito, non un’aggiunta opzionale. Significa costruire sistemi in cui l’esposizione dei dati è strutturalmente ridotta al minimo fin dal primo giorno. Non si tratta di compiacere gli avvocati; si tratta di creare un’architettura duratura e manutenibile. Un espediente comune ma pericoloso è creare archivi monolitici dei dati degli utenti, accumulando informazioni “per ogni evenienza”. Questo approccio crea una responsabilità enorme. Una sola violazione di quel database centrale potrebbe esporre ogni dato utente in vostro possesso.
Un’architettura privacy-first rifiuta questo modello. Al contrario, trattiamo la raccolta dei dati con precisione chirurgica. Ogni componente del sistema dovrebbe accedere solo al minimo assoluto di informazioni necessarie per svolgere la propria funzione. Questa è la base di un software affidabile e manutenibile.
Pattern architetturali fondamentali per la privacy
Per mettere in pratica la Privacy by Design, gli ingegneri possono fare affidamento su diversi pattern collaudati. Sono i mattoni fondamentali per sistemi sia conformi sia resilienti.
-
Minimizzazione dei dati: questo è il principio più critico. Prima di raccogliere qualsiasi dato, chiedetevi: è assolutamente essenziale perché la funzionalità possa operare? Ad esempio, invece di memorizzare la data di nascita esatta di un utente per verificarne l’età, potete salvare un semplice valore booleano:
is_over_18. Il requisito viene soddisfatto senza conservare informazioni personali identificabili (PII) sensibili. -
Segregazione dei dati: separate i diversi tipi di dati, sia logicamente sia fisicamente. Le informazioni del profilo di un utente (nome, email) non dovrebbero trovarsi nello stesso database — o addirittura nello stesso schema — dei dati di analisi comportamentale (click, visualizzazioni di pagina). Questo contenimento garantisce che un compromesso in un sistema non si propaghi automaticamente ad altri. Il vostro servizio di analytics dovrebbe interrogare un registro eventi con ID anonimi, non il database principale dei clienti.
-
Pseudonimizzazione: sostituite gli identificatori diretti con token reversibili e non identificativi. Un utente con ID
123nel database principale potrebbe diventareE7A8B9nel sistema di analytics. Questo vi consente di tracciare i percorsi utente e aggregare i comportamenti senza trattare direttamente i loro dati personali, riducendo drasticamente il vostro profilo di rischio.
Questi pattern non sono idee astratte; hanno un impatto diretto su come progettate servizi e database.
Dall’archiviazione dei dati al controllo degli accessi
Una volta che i dati sono archiviati in modo sicuro, il livello successivo critico della protezione dei dati e della privacy è controllare chi può accedervi. Un modello di controllo degli accessi robusto non è negoziabile.
Il Role-Based Access Control (RBAC) è un pattern standard estremamente efficace per applicare il principio del privilegio minimo. Il ruolo di un ingegnere non dovrebbe concedergli accesso senza restrizioni ai database di produzione. Il ruolo di un operatore del customer support, ad esempio, potrebbe consentire solo l’accesso in sola lettura ai dati non sensibili di uno specifico cliente, e solo quando un ticket di assistenza attivo lo giustifica.
Implementare correttamente l’RBAC significa che nessuna singola persona o sistema detiene le chiavi dell’intero regno. L’accesso dovrebbe essere temporaneo, verificato tramite audit e strettamente limitato a un compito specifico e giustificabile. Questo riduce drasticamente il rischio sia delle minacce interne sia dei danni causati da un account compromesso.
Adottare questi pattern richiede una mentalità di lungo periodo. L’investimento ingegneristico iniziale è maggiore rispetto all’adozione di scorciatoie, ma il ROI è significativo. Costruite un sistema più facile da auditare, più semplice da mantenere e molto meno rischioso. La conformità a normative come il GDPR diventa un effetto collaterale naturale di una buona architettura, non una corsa frenetica dell’ultimo minuto.
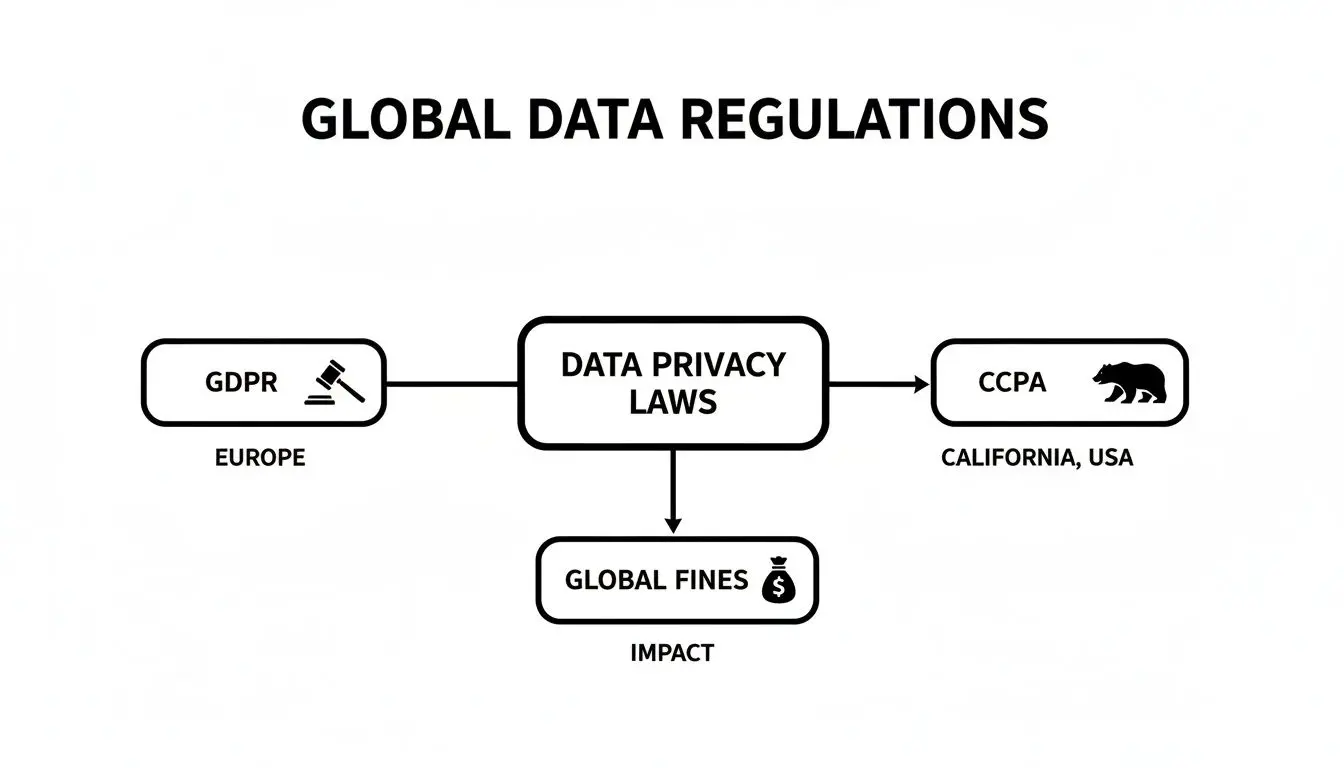
Questo diagramma di flusso rende chiaro un concetto: leggi regionali come GDPR e CCPA hanno ora un impatto finanziario diretto e globale. Una solida architettura della privacy non è solo una best practice: è una necessità aziendale, indipendentemente da dove operi.
Proteggere il tuo stack tecnologico dalle minacce moderne
Una robusta architettura della privacy è solo metà della storia. Senza controlli di sicurezza altrettanto solidi, è una casa con pareti di vetro. La vera protezione dei dati e della privacy dipende dalla capacità di difendere i tuoi sistemi da un panorama di minacce più complesso e in rapido cambiamento che mai.
Fare affidamento su modelli legacy come la difesa perimetrale è pericolosamente obsoleto. Oggi, una singola debolezza—una API configurata male, una vulnerabilità nella tua supply chain software, o un solo attacco di social engineering andato a buon fine—può sfociare in una violazione catastrofica dei dati. Per i leader tecnici, la sfida è passare da un atteggiamento reattivo all’integrazione della sicurezza lungo l’intero ciclo di vita dello sviluppo software (SDLC). Questo significa costruire una strategia di defense-in-depth in cui più controlli sovrapposti lavorano in sinergia. Se un livello fallisce, gli altri sono pronti a rilevare, contenere e neutralizzare la minaccia.
Comprendere l’evoluzione del panorama delle minacce
Gli aggressori di oggi non si limitano a lanciare attacchi brute-force; sono strategici, efficienti e sfruttano le debolezze comuni con una velocità allarmante. I numeri dipingono un quadro netto: puoi consultare le principali statistiche sulla privacy dei dati per vedere l’intera portata della sfida.
Il punto chiave è che gli aggressori prendono di mira senza sosta gli anelli più deboli della tua infrastruttura e della tua supply chain software, con un’attenzione maniacale al furto di dati a fini di estorsione. Un modello di sicurezza reattivo, basato sul perimetro, non è più una difesa valida.
Strategie di mitigazione pratiche per i leader dell’ingegneria
Mettere in sicurezza il tuo stack tecnologico significa passare da principi astratti a controlli tecnici concreti. Un approccio pragmatico si concentra sulle aree a maggior impatto che riducono direttamente la superficie di attacco e migliorano i tempi di risposta.
-
Progettazione sicura delle API: Molte violazioni hanno origine da API protette in modo inadeguato. Devi imporre un rate limiting rigoroso, usare un’autenticazione robusta come OAuth 2.0 e implementare un’autorizzazione granulare. Ogni singolo endpoint API che gestisce dati sensibili deve convalidare i permessi dell’utente a ogni richiesta—non fidarti mai di un controllo effettuato lato client.
-
Scansione automatizzata delle dipendenze: La sicurezza della tua applicazione è tanto forte quanto la sua dipendenza più debole. Integra strumenti automatizzati come Dependabot o Snyk direttamente nella tua pipeline CI/CD. Questi strumenti eseguono scansioni continue alla ricerca di vulnerabilità note nelle tue librerie open source. Una vulnerabilità critica in un pacchetto di terze parti è una vulnerabilità critica nel tuo prodotto.
-
Logging robusto e rilevamento delle anomalie: Non puoi fermare un attacco che non puoi vedere. Implementa logging centralizzato e strutturato in tutti i tuoi servizi e nella tua infrastruttura. Questi log non servono solo per il debug; sono uno strumento di sicurezza fondamentale per individuare attività insolite, come un improvviso aumento dei tentativi di accesso falliti o modelli di accesso ai dati inattesi da parte di un account di servizio.
Un piano efficace di risposta agli incidenti non è un documento che prende polvere. È un playbook collaudato sul campo che il tuo team esercita regolarmente. Deve definire ruoli chiari, canali di comunicazione e passaggi tecnici per isolare i sistemi, preservare le prove e ripristinare i servizi. Quando si verifica una violazione, la confusione è il tuo nemico.
L’implementazione di questi controlli richiede un cambiamento fondamentale di mentalità. La sicurezza non è una fase separata aggiunta alla fine dello sviluppo; è una parte integrante della scrittura di codice di alta qualità e affidabile. Se hai bisogno di una guida esperta, affidarti a specializzate società di consulenza cybersecurity può fornire le competenze necessarie per valutare i rischi e implementare i controlli giusti. Uno stack tecnologico sicuro è il fondamento su cui si costruiscono una vera protezione dei dati e della privacy.
Protezione pratica dei dati per sistemi AI e LLM
Integrare l’AI e i modelli linguistici di grandi dimensioni (LLM) nei tuoi prodotti introduce sfide del tutto nuove in termini di protezione dei dati e della privacy. Non si tratta semplicemente di versioni più grandi di vecchi problemi; sono rischi fondamentalmente diversi che richiedono un nuovo approccio architetturale.
Trattare un LLM come una semplice chiamata API è un errore critico. È una scorciatoia che può—e spesso lo fa—portare a gravi fughe di dati e problemi normativi. A differenza del software tradizionale, i modelli AI hanno comportamenti complessi, spesso imprevedibili. I loro output sono probabilistici, non deterministici. Ciò significa che possono divulgare accidentalmente informazioni sensibili assorbite durante l’addestramento o dal prompt di un utente. Questo crea modalità di guasto uniche che le tue misure di sicurezza standard non sono progettate per gestire.
Per i leader dell’ingegneria e del prodotto, questo significa progettare sistemi con una visione chiara di come i dati fluiscono verso, attraverso e dal modello. Ogni prompt che contiene dati dei clienti è un potenziale incidente di privacy in attesa di accadere.
Rischi unici nell’integrazione di AI e LLM
I rischi qui vanno ben oltre il semplice archiviazione dei dati. La natura stessa di come questi modelli elaborano le informazioni apre nuove superfici di attacco e la possibilità di esposizione involontaria dei dati.
-
Contaminazione dei dati di training: Se dati personali entrano nel set di addestramento di un modello, il modello può “memorizzare” e successivamente ripetere quei dati nelle sue risposte. Questo non è un bug; è una fuga di dati persistente, difficile da correggere, che viola i principi fondamentali della privacy.
-
Prompt injection e fuga di dati: Un attore malevolo può costruire un prompt per ingannare il modello e fargli ignorare le istruzioni di sicurezza, così da rivelare informazioni sensibili di sistema o dati provenienti dalle sessioni di altri utenti. Si tratta di una nuova classe di attacco injection specifica per gli LLM.
-
Esposizione involontaria di PII: Un modello incaricato di sintetizzare un ticket di assistenza clienti potrebbe includere il nome del cliente, l’email o altri dati personali nel riepilogo, anche se istruito a non farlo. Questo comportamento probabilistico rende il semplice filtraggio dell’output una difesa inaffidabile.
Questi rischi non sono teorici. Sono problemi pratici di ingegneria che richiedono soluzioni specifiche e architetturali.
Pattern architetturali per sistemi AI più sicuri
Per mitigare queste sfide, devi progettare il tuo sistema partendo dall’assunzione fondamentale che il modello sia un potenziale punto di guasto e progettare attorno ad esso salvaguardie esplicite. Ciò significa creare livelli di controllo per proteggere i dati prima che raggiungano il modello e per sanificare gli output prima che vengano mostrati a un utente.
Un errore architetturale critico è consentire una comunicazione diretta tra i database della tua applicazione principale e un LLM di terze parti. L’approccio corretto consiste nel progettare un servizio di ‘buffer’ o ‘proxy’ che intercetti tutte le richieste, sanifichi i dati e gestisca l’interazione con il modello.
Questo servizio intermedio diventa il tuo punto di controllo cruciale per implementare pattern che migliorano la privacy.
Implementare strategie di mitigazione pratiche
Costruire una solida postura di privacy per l’AI implica un mix di controlli orientati ai dati e ai modelli. Queste strategie lavorano insieme per formare una difesa a più livelli.
-
Sanificazione e anonimizzazione degli input: Prima che qualsiasi dato venga inviato a un LLM, un servizio dedicato dovrebbe ripulirlo da PII. Usa tecniche come il Named Entity Recognition (NER) per individuare e sostituire nomi, email e numeri di telefono con segnaposto generici (ad es.,
[CUSTOMER_NAME]). -
Implementazione dei guardrail: Un “guardrail” è un processo separato o persino un altro modello che convalida sia il prompt dell’utente (input guardrail) sia la risposta del modello (output guardrail). Agisce come un checkpoint di sicurezza, bloccando prompt dannosi, verificando la presenza di PII nelle risposte e assicurando che l’output sia coerente con le tue policy.
-
Workflow human-in-the-loop (HITL): Per decisioni ad alto impatto, come quelle in ambito sanitario o finanziario, gli output dell’AI non dovrebbero essere completamente automatizzati. Devi progettare un flusso di lavoro in cui un esperto umano esamina e approva il suggerimento del modello prima che venga intrapresa qualsiasi azione. Questo è il tuo controllo finale e critico contro errori e bias del modello.
-
Logging robusto per l’auditabilità: Ogni prompt inviato al modello e ogni risposta ricevuta devono essere registrati con i relativi metadati (ad es. ID utente, ID sessione). Questa traccia di audit non è negoziabile per il debug, il monitoraggio degli abusi e la dimostrazione della conformità agli enti regolatori.
Adottando questi pattern, i team possono costruire potenti funzionalità basate sull’AI senza compromettere il loro impegno verso la protezione dei dati e della privacy. È un investimento necessario per gestire i rischi complessi che accompagnano questa potente tecnologia.
Costruire una cultura di protezione dei dati duratura
La vera protezione dei dati e della privacy non è fatta di progetti una tantum o sprint per spuntare una casella di conformità. È un impegno strategico e continuo. Un approccio di successo va oltre le soluzioni tecniche; richiede un cambiamento culturale in cui ogni ingegnere, product manager e leader consideri la privacy come una propria responsabilità.
Questo cambiamento inizia rifiutando la stanca idea che la privacy sia un ostacolo all’innovazione. Al contrario, devi presentarla come un ingrediente fondamentale dell’eccellenza del prodotto. Un approccio pragmatico, orientato all’ingegneria, è l’unico modo sostenibile per costruire software sicuro, conforme e affidabile by design.
Dall’architettura al DNA organizzativo
Integrare la privacy nel DNA della tua azienda la rende una priorità condivisa. Questo significa formazione continua, processi trasparenti e i giusti incentivi. Quando la privacy viene considerata fin dall’inizio come una scelta architetturale, cresce naturalmente fino a diventare anche una scelta culturale.
Per favorire questo ambiente, la leadership deve sostenere la privacy come pilastro del successo aziendale. Ciò richiede investimenti in formazione, strumenti e nel dare ai team il tempo necessario per costruire le cose nel modo giusto.
Una protezione dei dati duratura è il risultato di uno sforzo deliberato e costante. Si ottiene quando le decisioni attente alla privacy diventano la norma per tutti coloro che partecipano alla costruzione e alla gestione del tuo software, dall’architetto di sistema allo sviluppatore junior.
Questa base culturale è ciò che trasforma le buone intenzioni in sistemi affidabili e manutenibili di cui i clienti possono fidarsi.
Una checklist pratica per i leader
Ecco una checklist operativa per aiutarti a valutare la tua situazione attuale e identificare le priorità:
- Rivedi la tua mappa dei dati: Hai un documento vivo che traccia tutti i dati personali, il loro scopo, la loro posizione e il loro periodo di conservazione? In caso contrario, questo è il tuo primo e più importante compito.
- Valuta i controlli di accesso: Le tue policy RBAC stanno davvero applicando il principio del privilegio minimo? Esegui audit regolari per assicurarti che nessuno abbia più accesso di quanto sia assolutamente necessario.
- Valuta il rischio dei fornitori: Hai verificato a fondo le pratiche di privacy e sicurezza di tutti i tuoi servizi di terze parti? Presta particolare attenzione alle piattaforme di AI e di analytics.
- Testa il tuo piano di risposta agli incidenti: Quando è stata l’ultima volta che hai condotto una simulazione tabletop o un drill? Un piano che esiste solo sulla carta è inutile sotto pressione.
- Dai priorità alla privacy nelle roadmap: State allocando tempo di engineering per il lavoro sulla privacy? Questo include il refactoring del codice per ridurre al minimo la raccolta dei dati o l’implementazione di nuove Privacy-Enhancing Technologies (PETs).
In definitiva, costruire una cultura della protezione dei dati trasforma la privacy da centro di costo in ciò che dovrebbe essere: un vantaggio competitivo che rafforza la fiducia dei clienti e favorisce la crescita a lungo termine.
Domande frequenti
Quando si parla di protezione dei dati e privacy, i leader B2B si trovano spesso ad affrontare le stesse domande pratiche. Ecco risposte dirette ai problemi più comuni.
Da dove dovrebbe iniziare una startup con la protezione dei dati e la privacy?
Inizia con una mappa dei dati. Prima di scrivere codice per una nuova funzionalità, documenta esattamente quali dati personali ti servono, perché ti servono e per quanto tempo prevedi di conservarli. Questo semplice esercizio è il cuore del principio di minimizzazione dei dati e la base di regolamenti moderni come il GDPR. Impone chiarezza fin dal primo giorno.
Da lì, integra la privacy nella tua architettura. Inserisci meccanismi di consenso nella tua UI, esegui correttamente l’hash delle password e implementa controlli di accesso di base. Soprattutto, non raccogliere dati sensibili a meno che non siano assolutamente critici per il funzionamento del prodotto. Una semplice informativa sulla privacy e una mappa interna dei dati sono i tuoi primi asset più preziosi.
In che cosa la Privacy by Design differisce da una normale revisione della sicurezza?
Una normale revisione della sicurezza avviene in genere verso la fine del ciclo di sviluppo. Il suo scopo è individuare e correggere vulnerabilità, come il rischio di SQL injection. È un processo reattivo.
La Privacy by Design è una disciplina proattiva che inizia prima dell’avvio dello sviluppo, modellando l’architettura per ridurre al minimo l’esposizione dei dati per impostazione predefinita.
Ad esempio, invece di memorizzare la data di nascita di un utente, potresti memorizzare solo un flag booleano che indichi se ha più di 18 anni. La sicurezza chiede: ‘I dati che conserviamo sono protetti?’ La privacy by design chiede: ‘Abbiamo davvero bisogno di conservare questi dati in primo luogo?‘
Qual è il singolo errore più grande che le aziende commettono con l’IA e la privacy?
L’errore più grande è trattare un modello di IA di terze parti come una semplice chiamata API in più, senza progettare il flusso dei dati.
Troppo spesso le aziende inviano direttamente nei prompt dati sensibili dei clienti, senza rendersi conto che questi dati potrebbero essere registrati dal fornitore o persino utilizzati per il futuro addestramento del modello. Questo crea un significativo rischio per la privacy e un potenziale incubo di conformità.
L’approccio corretto è progettare uno strato di “buffer”. Si tratta di un servizio intermedio che anonimizza o pseudonimizza i dati prima che raggiungano il modello esterno. Per casi d’uso altamente sensibili, eseguire i propri modelli on-premise o in cloud privato offre un grado molto più elevato di controllo e sicurezza.
Costruire prodotti digitali affidabili con un chiaro focus sulla privacy richiede fin dall’inizio una mentalità architetturale. Devisia aiuta le aziende a trasformare la loro visione in software manutenibile, integrando sicurezza e conformità nel cuore di ogni sistema. Scopri di più sul nostro approccio pragmatico allo sviluppo di software custom e di soluzioni IA su https://www.devisia.pro.