
Una richiesta di prodotto familiare di solito inizia così. Il team vuole un onboarding migliore, segnali di retention più nitidi o una dashboard più intelligente, e la strada più rapida sembra ovvia: usare i dati dei clienti che scorrono attraverso la piattaforma.
È qui che molte aziende prendono una decisione legale e architetturale sbagliata. Presumono che l’interesse legittimo significhi “non abbiamo bisogno del consenso, quindi possiamo procedere”. In pratica, una valutazione dell’interesse legittimo non è una scorciatoia. È un test strutturato per stabilire se il trattamento sia giustificato, necessario e proporzionato per le persone che ne sono interessate.
Per i team software, questa distinzione conta. Se tratti la base giuridica come burocrazia aggiunta dopo il rilascio, di solito finisci per dover difendere dichiarazioni di finalità deboli, raccogliere telemetria in eccesso e adattare a posteriori controlli che avrebbero dovuto essere progettati nel sistema fin dall’inizio. Se la tratti come una decisione di ingegneria, la valutazione diventa utile. Impone un ambito chiaro, flussi di dati più rigorosi e confini migliori attorno ad analytics, profiling e funzionalità di AI.
I rischi nascosti del trattamento dei dati senza consenso
Un errore comune inizia dopo che una richiesta di funzionalità viene approvata, non durante la revisione legale. La pipeline dei dati esiste già. Il prodotto vuole raccomandazioni migliori o segnali di abbandono. Un ingegnere aggiunge dati di supporto, eventi di utilizzo e metadati dell’account all’input del modello perché è più veloce che definire prima un dataset più ristretto.
Il problema legale raramente è la prima query. È l’espansione silenziosa che segue. Un flusso di analytics della dashboard diventa profiling comportamentale. Un workflow di classificazione del supporto inizia a influire sul punteggio dell’account. Una funzionalità LLM costruita per riassumere i ticket inizia a ingerire campi di testo libero che contengono dettagli personali che nessuno si aspettava di riutilizzare. Nel momento in cui qualcuno chiede se si applichi l’interesse legittimo, l’architettura presume già un riutilizzo ampio.
Questa sequenza genera LIA deboli. I team le scrivono dopo che il design è stato fissato, quindi la valutazione documenta il sistema esistente invece di verificare se il sistema dovrebbe funzionare in quel modo.
L’applicazione del GDPR, a partire dal 25 maggio 2018, richiede il test in tre parti di finalità, necessità e bilanciamento. In pratica, ciò significa che i team hanno bisogno di più di una breve affermazione che il trattamento aiuti il business. Hanno bisogno di una finalità chiara, di prove che i dati scelti siano necessari e di una valutazione documentata dell’impatto sulle persone dietro i record.
Per i prodotti SaaS e AI, il rischio nascosto è il progressivo ampliamento dell’ambito all’interno delle normali decisioni di ingegneria. La conservazione degli eventi viene estesa perché lo storage è economico. Gli identificativi restano nel data warehouse perché potrebbero essere utili per il debug in futuro. I prompt del modello includono testo grezzo dei clienti perché la redazione è stata rimandata a uno sprint successivo. Ogni scelta, presa singolarmente, sembra minima. Insieme, creano un trattamento più difficile da giustificare, più difficile da spiegare agli utenti e più difficile da scalare in sicurezza tra regioni e linee di prodotto.
Cosa va storto nella pratica
Il problema ricorrente è uno scarso controllo dell’ambito.
- Le finalità si spostano. “Miglioramento del servizio” diventa un’etichetta generica per segmentazione, ranking, revisione antifrode, targeting delle funzionalità o prioritizzazione commerciale.
- La necessità non viene mai verificata. I team conservano log grezzi, identificativi persistenti e cronologie dettagliate degli eventi senza controllare se metriche aggregate, una retention più breve o ID pseudonimi potrebbero raggiungere lo stesso risultato.
- Il bilanciamento viene trattato come una formalità. La valutazione omette l’effetto sugli utenti, soprattutto quando il trattamento modifica raccomandazioni, visibilità, idoneità o punteggi di rischio interni.
- I meccanismi di consenso vengono inseriti troppo tardi. Un team costruisce tutto attorno all’interesse legittimo, poi scopre che una parte della funzionalità sarebbe stata più pulita con la scelta dell’utente e con modelli più chiari di opt-in e opt-out.
Una LIA utile cambia l’architettura. Riduce i dati raccolti, restringe gli accessi, accorcia la conservazione o separa i trattamenti ad alto rischio dall’analisi ordinaria. Se il documento lascia il sistema invariato, di solito non ha esaminato i compromessi.
Scegliere la tua base giuridica: interesse legittimo vs consenso
Prima di redigere una LIA, decidi se l’interesse legittimo sia davvero la base giuridica corretta. I team spesso affrettano questa decisione perché il consenso sembra costoso e l’interesse legittimo sembra flessibile.
Questo istinto è comprensibile, ma non è affidabile.
Le sei basi giuridiche in termini operativi
Ai sensi del GDPR, il trattamento dei dati personali richiede una base giuridica. Nella delivery del software, le sei basi sono meglio considerate come vincoli di progettazione.
-
Consenso Usalo quando la persona ha una scelta reale e può rifiutare senza subire svantaggi.
-
Contratto Usalo quando il trattamento è richiesto per fornire il servizio richiesto dall’utente.
-
Obbligo legale Usalo quando un’altra legge richiede il trattamento.
-
Interessi vitali Rilevante in casi limitati che riguardano la protezione della vita.
-
Compito di interesse pubblico Rilevante soprattutto per le autorità pubbliche.
-
Interessi legittimi Usalo quando il trattamento supporta un interesse reale e lecito dell’azienda o di terzi, è necessario per tale finalità e non prevale sui diritti e le libertà della persona.
Per la maggior parte delle aziende SaaS, la decisione più comune è di solito tra consenso, contratto e interessi legittimi.
Quando il consenso è la risposta migliore
Il consenso non è solo un banner o una checkbox. Crea un modello di autorizzazione revocabile. È utile quando il trattamento è facoltativo, soprattutto se l’utente non se lo aspetterebbe ragionevolmente senza un prompt specifico.
Esempi in cui i team dovrebbero esaminare il consenso con molta attenzione includono:
- Funzionalità opzionali di personalizzazione che non sono necessarie per far funzionare il servizio
- Scelte di marketing e tracking che si collocano al di fuori della fornitura del servizio principale
- Trattamenti che coinvolgono contesti sensibili o ad alto rischio, in cui un’argomentazione ampia basata sull’interesse legittimo difficilmente sarebbe difendibile
Se il tuo team non ha ancora chiaro il funzionamento dei modelli di opt-in e opt-out, questa guida sulle scelte di opt-in e opt-out è un utile riferimento operativo.
Quando l’interesse legittimo è spesso la base più forte
L’interesse legittimo può essere più appropriato quando il trattamento è strettamente legato a operazioni di servizio sicure, affidabili e attese.
Esempi includono:
- Prevenzione delle frodi
- Sicurezza della rete e delle applicazioni
- Alcune forme di analytics di prodotto
- Monitoraggio della qualità del servizio
- Miglioramenti dell’esperienza cliente all’interno di una relazione esistente
La distinzione è l’aspettativa. Un cliente esistente di solito si aspetta un certo livello di monitoraggio per mantenere il servizio sicuro e utilizzabile. Questo non significa che ogni funzionalità di analytics sia coperta. Significa che il punto di partenza è più difendibile rispetto a quello di un prospect che non ha mai usato il prodotto.
Nel settore IT italiano, il ricorso alla LIA ha rappresentato il 62% dei trattamenti basati sul GDPR nelle aziende di sviluppo software nel 2024, rispetto al 28% per il consenso, secondo la fonte citata che discute il reporting annuale del Garante (pagina Ipsos che fa riferimento ai dati del test di bilanciamento). Questo ti dice quanto questa base sia diventata comune nelle aziende software. Non la rende automaticamente sicura.
Un filtro decisionale pratico
Poniti quattro domande prima di scegliere l’interesse legittimo:
- La finalità è abbastanza specifica da poter essere spiegata a un’autorità di controllo e a un utente?
- L’utente si aspetterebbe ragionevolmente questo trattamento nel contesto del prodotto in cui i dati sono stati raccolti?
- Lo stesso risultato può essere ottenuto con meno dati o con un metodo meno invasivo?
- Se l’utente si opponesse, la tua giustificazione suonerebbe comunque proporzionata?
Se una risposta è debole, fermati e rivaluta la base giuridica.
Il consenso non è più debole perché è più rigoroso. In molti sistemi, il consenso è più pulito perché allinea il confine del prodotto con il confine delle aspettative dell’utente.
Un cattivo approccio è scegliere l’interesse legittimo perché la gestione del consenso è scomoda. Un approccio corretto è scegliere l’interesse legittimo perché il trattamento è necessario dal punto di vista operativo, limitato nell’ambito e supportato da chiare misure di salvaguardia.
Eseguire il test LIA in tre parti
Un team di prodotto rilascia una funzionalità utile. Rilevamento di anomalie nell’accesso, analytics di utilizzo in-app, logging dei prompt per un assistente LLM o revisione dei transcript del supporto per il tuning del modello. La funzionalità funziona. La LIA fallisce perché nessuno ha definito con precisione la finalità, nessuno ha dimostrato che i dati fossero necessari e nessuno ha documentato perché gli utenti avrebbero ragionevolmente previsto il trattamento.
Questo è il test in tre parti nella pratica. Non è una formalità legale. È una revisione di design per l’uso dei dati.
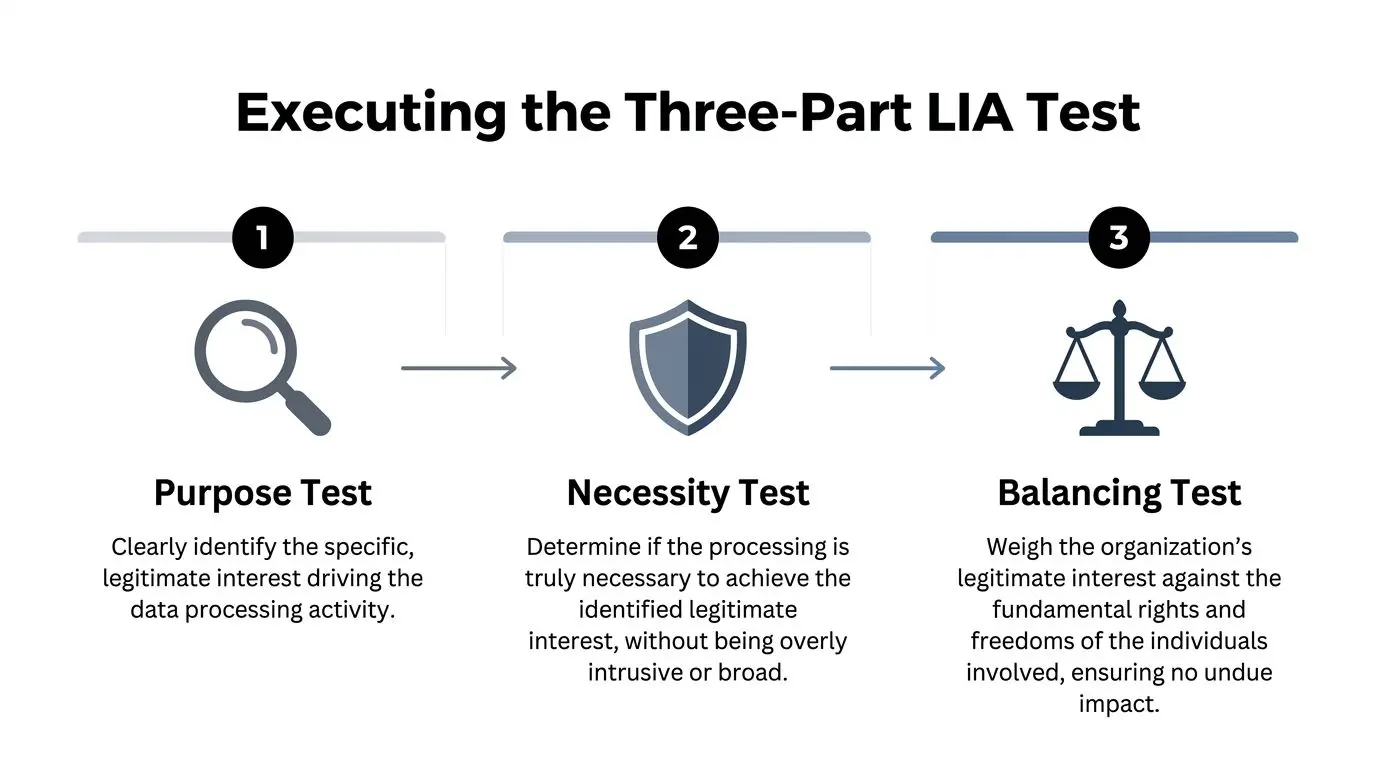
Per i team SaaS e AI, il test funziona meglio quando è collegato alle decisioni di progettazione del sistema. Eseguilo quando un team propone una nuova attività di trattamento, modifica la retention, aggiunge un fornitore, amplia l’ambito delle analytics o riutilizza dati esistenti per un nuovo modello o una nuova funzionalità. Se la LIA inizia dopo il lancio, di solito si trasforma in un esercizio di giustificazione invece che in una revisione onesta.
Test di finalità
Inizia con una domanda. Quale interesse sta perseguendo l’azienda?
Le LIA deboli descrivono un’aspirazione. Le buone LIA descrivono un obiettivo operativo che un altro team potrebbe contestare, implementare e verificare. “Migliorare la piattaforma” è troppo vago per essere difendibile. Non identifica il workflow, gli utenti interessati o i dati necessari.
Una dichiarazione di finalità difendibile di solito include quattro elementi:
-
L’obiettivo operativo Esempio: rilevare accessi fraudolenti agli account in un portale amministrativo enterprise.
-
Il beneficio per il business o per l’utente Esempio: ridurre la compromissione degli account e preservare l’integrità del servizio.
-
L’attività di trattamento Esempio: analizzare i metadati di login, gli eventi di cambio dispositivo e i ripetuti tentativi di autenticazione falliti.
-
Il perimetro di ambito Esempio: escludere l’uso per marketing, pubblicità o profiling non correlato.
Confronta queste due affermazioni:
-
Debole Trattiamo il comportamento degli utenti per migliorare la piattaforma.
-
Più forte Trattiamo i dati di interazione degli utenti autenticati del modulo di reporting per identificare i problemi di navigazione e ridurre gli incidenti di supporto ripetuti per i clienti esistenti.
La seconda versione è migliore perché l’ingegneria può costruirsi sopra e la governance può testarla. Questo è importante nei moderni sistemi SaaS, dove lo stesso flusso di eventi viene spesso riutilizzato tra analytics, sperimentazione, sicurezza e funzionalità AI. Se la finalità è ampia, ogni riutilizzo successivo sembra “abbastanza vicino”, e la LIA smette di fissare un confine reale.
Test di necessità
Il test di necessità pone una domanda più difficile. Questo trattamento è richiesto per la finalità dichiarata, oppure è disponibile solo perché la piattaforma già raccoglie quei dati?
L’architettura è importante qui. I team spesso superano il test di finalità, ma poi falliscono quello di necessità perché ingeriscono troppi dati, li conservano troppo a lungo o utilizzano record identificabili quando sarebbero bastati dati pseudonimi o aggregati.
Affronta la revisione in termini tecnici:
- Abbiamo bisogno di dati personali?
- Se sì, abbiamo bisogno di identificativi diretti, o funzionano ID pseudonimi?
- Le telemetrie aggregate possono raggiungere lo stesso risultato?
- I campi possono essere rimossi prima dell’ingestione?
- La retention può essere accorciata senza compromettere il caso d’uso?
- L’accesso può essere limitato a un gruppo operativo più piccolo?
Le LIA più solide rimandano a scelte di progettazione concrete, non a intenzioni.
I pattern utili includono:
-
Filtraggio edge Rimuovere i campi non necessari prima che entrino nelle pipeline di analytics o training.
-
Identificativi di eventi pseudonimi Mantenere l’analisi comportamentale separata dalla risoluzione dell’identità, salvo che un flusso di lavoro approvato richieda una nuova associazione.
-
Conservazione a livelli Conservare i log grezzi per poco tempo, quindi convertirli in record aggregati o riassunti.
-
Dataset specifici per funzionalità Evitare che un data lake generico diventi la fonte predefinita per ogni nuova iniziativa.
Questo conta ancora di più per i sistemi di AI. Se un team vuole usare ticket di supporto, log di chat o cronologie dei prompt per migliorare il modello, la necessità dovrebbe essere verificata a livello di campo. Trascrizioni complete, identificativi degli account, allegati e contenuti in testo libero creano un profilo di rischio molto diverso da estratti redatti o metadati etichettati. Se l’obiettivo è la classificazione dell’intento, il contenuto grezzo può essere eccessivo. Se l’obiettivo è il rilevamento degli abusi, dati di eventi a breve conservazione potrebbero essere sufficienti.
Se la telemetria aggregata può soddisfare lo scopo, l’uso di contenuti grezzi degli utenti è di solito difficile da giustificare.
Test di bilanciamento
Il test di bilanciamento chiede se l’interesse dell’organizzazione è superato dai diritti e dalle libertà della persona. I team spesso lo trattano come un’affermazione generale sul basso rischio. Non basta.
L’analisi di bilanciamento dovrebbe concentrarsi su come il trattamento viene percepito dal lato dell’utente e su cosa fa il sistema con i dati. Una funzionalità interna può comunque essere invasiva. Una funzionalità utile può comunque essere inattesa. Un danno a bassa probabilità può comunque contare se la conseguenza è grave o difficile da rilevare per l’utente.
Il rischio di solito aumenta quando il trattamento coinvolge:
- Profilazione che modifica il trattamento dell’utente
- Riutilizzo inatteso dei dati esistenti
- Lunga conservazione dei record comportamentali
- Dati di categorie particolari o utenti vulnerabili
- Funzionalità AI che inferiscono preferenze, rischio o intento
- Logica decisionale opaca che gli utenti non possono comprendere o contestare
Le aspettative ragionevoli hanno molto peso in questo contesto. I clienti esistenti possono aspettarsi monitoraggio della sicurezza, analisi del servizio e attività limitate di miglioramento del prodotto. È meno probabile che si aspettino profilazione estesa, conservazione indefinita o uso secondario delle conversazioni di supporto per addestrare sistemi AI interni. Il contesto conta. Conta anche il design del prodotto. Se gli utenti scoprono il trattamento solo in un’informativa sulla privacy, le aspettative sono probabilmente deboli.
Le evidenze rendono difendibile la fase di bilanciamento:
| Area delle evidenze | Cosa acquisire |
|---|---|
| Relazione con l’utente | Cliente esistente, utente di prova, dipendente, prospect |
| Categoria di dati | Eventi di utilizzo, contenuti di supporto, metadati dell’account, testo libero |
| Analisi delle aspettative | Perché l’utente si aspetterebbe o non si aspetterebbe questo trattamento |
| Misure di controllo | Opt-out, controlli di accesso, limiti di conservazione, revisione umana |
| Rischio residuo | Cosa resta rischioso anche dopo le salvaguardie |
Ad esempio, se un modello di qualità del supporto usa trascrizioni interne, documentare i controlli in termini operativi. Indicare se le trascrizioni vengono controllate per identificativi non necessari, se il testo libero viene redatto prima dell’addestramento o della valutazione, chi può accedere ai record grezzi, per quanto tempo vengono conservati e se l’output influenza il trattamento dell’utente. Questo è il livello di dettaglio che i regolatori si aspettano e il livello di cui i team di ingegneria hanno bisogno se vogliono che la valutazione contribuisca a modellare il sistema.
Una LIA valida è una registrazione delle decisioni che il prodotto e l’architettura dei dati implementano.
Un modello di scoring pragmatico per il test di bilanciamento
Un test di bilanciamento di solito fallisce in uno scenario familiare di revisione del prodotto. Il team vuole rilasciare una funzionalità utile, il legale accetta che possa applicarsi un interesse legittimo, e il ticket si chiude con una conclusione vaga che l’impatto sugli utenti è “basso”. Non basta per una piattaforma SaaS con pipeline di eventi, dati di supporto, feature flag e componenti LLM che toccano gli stessi record in modi diversi.
I team di ingegneria hanno bisogno di un metodo che resista ai cambiamenti di design e alle domande di audit. Un modello di scoring dà a questo test di bilanciamento una struttura. Non sostituisce il giudizio. Costringe il team a mostrare quali scelte architetturali riducono il rischio e quali rendono la giustificazione più difficile da difendere.
Come valutare il bilanciamento
Usare un intervallo da -10 a +10 per ciascun fattore, quindi richiedere una motivazione scritta accanto a ogni punteggio.
- I valori negativi riflettono l’impatto sull’individuo.
- I valori positivi riflettono la necessità aziendale, l’integrità del servizio o un chiaro beneficio per l’utente.
- Le evidenze devono avere più peso delle supposizioni.
- Una salvaguardia ottiene punti solo se il sistema la applica.
Il punto è la coerenza. Se uno squad di prodotto assegna +5 alla pseudonimizzazione e un altro assegna +1, la discrepanza dovrebbe attivare una revisione. Col tempo, la griglia di scoring diventa uno standard pratico per le decisioni di privacy engineering, un po’ come le valutazioni di gravità nella revisione della sicurezza.
Esempio di matrice di scoring del test di bilanciamento
| Fattore | Punteggio impatto/beneficio (-10 a +10) | Giustificazione |
|---|---|---|
| Riduzione delle frodi nel monitoraggio dell’attività dell’account | +8 | Forte necessità operativa legata alla sicurezza del servizio e alla protezione del cliente |
| Relazione con il cliente esistente | +4 | Gli utenti stanno già usando il servizio e possono aspettarsi un certo monitoraggio della sicurezza |
| Uso di identificativi pseudonimi nel livello di analisi | +3 | Riduce l’esposizione diretta delle identità durante l’analisi di routine |
| Profilazione comportamentale a livello individuale | -6 | Può influire su come gli utenti vengono valutati o trattati all’interno del servizio |
| Trasparenza limitata nella spiegazione della funzionalità | -4 | Gli utenti potrebbero non comprendere appieno che i segnali comportamentali influenzano i risultati |
| Conservazione della cronologia grezza degli eventi oltre la necessità immediata | -5 | Aumenta l’intrusività e il rischio di uso improprio futuro |
| Revisione umana prima di un’azione significativa | +3 | Riduce i risultati automatizzati ingiusti |
| Trattamento del contenuto di supporto in testo libero | -4 | Il testo libero può contenere dettagli personali inattesi |
Una matrice come questa funziona meglio quando i punteggi sono legati ai dettagli di implementazione. “Revisione umana” significa un passaggio di approvazione definito, revisori nominati e log che dimostrano che la revisione è avvenuta. “Analisi pseudonima” significa che gli identificativi sono separati, i percorsi di accesso sono limitati e gli strumenti a valle non riassociano i dati.
Esempio pratico per una funzionalità di personalizzazione B2B SaaS
Considerare un team che costruisce la personalizzazione dell’area di lavoro partendo dai percorsi di clic, dal tempo trascorso nei moduli e dalla cronologia di supporto. Lo scopo dichiarato è ragionevole. Aiutare i clienti esistenti a trovare più rapidamente l’attività successiva e ridurre l’attrito del prodotto. L’esito del bilanciamento dipende meno da quello scopo che da come è progettato il flusso dei dati.
Versione uno del design
Il primo design include:
- flussi di eventi grezzi collegati a utenti nominativi
- ticket di supporto acquisiti con testo libero completo
- lunga conservazione per la messa a punto del modello
- logica di ranking che modifica ciò che ogni utente vede senza una spiegazione chiara
Questa versione crea negativi evitabili. Combina dati comportamentali con il contesto del supporto, conserva i record grezzi troppo a lungo e rende la funzionalità più difficile da spiegare agli utenti e ai revisori interni. Se in seguito si aggiunge un LLM per la sintesi o la generazione di raccomandazioni, il rischio aumenta di nuovo perché il testo libero spesso contiene dati personali inattesi e contesto sensibile.
Versione due del design
Il design rivisto include:
- analisi di eventi pseudonimi a livello di workspace
- categorie di supporto invece del testo completo dei ticket
- breve conservazione dei log grezzi seguita da aggregazione
- revisione umana per le raccomandazioni che potrebbero influire materialmente sui flussi di lavoro dell’utente
- una spiegazione in prodotto del perché compaiono le raccomandazioni
Lo scopo non è cambiato. Il punteggio sì. Il team ha ridotto l’identificabilità, ristretto le categorie di dati e aggiunto controlli che prodotto e ingegneria possono dimostrare nella pratica.
Questo è l’esito utile di un test di bilanciamento. Dà ai team un motivo per riprogettare pipeline, logica delle funzionalità e regole di conservazione prima del rilascio, non dopo un reclamo.
Una soglia utile
Impostare una soglia di rilascio che si adatti all’organizzazione, ma renderla operativa. Un approccio comune è richiedere un punteggio netto chiaramente positivo, far salire di livello qualsiasi fattore negativo ad alto impatto non risolto e aprire una revisione più ampia se la profilazione, il monitoraggio o il comportamento del modello creano incertezza. I team che già eseguono revisioni privacy possono collegare quel punto di escalation a un flusso di lavoro di valutazione d’impatto sulla privacy, così l’escalation si basa su criteri definiti anziché su decisioni dell’ultimo minuto.
Le categorie dovrebbero restare stabili tra i prodotti così i risultati sono confrontabili:
- Aspettativa e trasparenza
- Sensibilità dei dati
- Possibilità di opposizione
- Rischio di profilazione ingiusta
- Ambito e conservazione
- Salvaguardie e supervisione umana
Per i CTO, questo produce qualcosa di più utile di un’approvazione legale di una sola riga. Crea un registro decisionale che si mappa direttamente su schemi, job di conservazione, controlli di accesso e confini dei modelli. Questo è ciò che rende una LIA difendibile nei moderni sistemi SaaS e AI.
Integrare le LIA nel vostro framework di governance
Un team SaaS rilascia una funzionalità dietro un flag, poi sei settimane dopo instrada lo stesso flusso di eventi verso un motore di raccomandazione, una dashboard di supporto e un livello di prompt per LLM. Il codice è cambiato più velocemente del registro di governance. È così che una LIA difendibile si trasforma in un documento obsoleto che non corrisponde più al sistema in produzione.
La soluzione è operativa. Trattare la LIA come parte del processo di delivery, con collegamenti alle decisioni architetturali, ai release gate e all’approvazione delle modifiche, così il ragionamento resta allineato ai flussi di dati.
Dove inserire la LIA nel ciclo di vita
Il posto giusto per una LIA è accanto alle decisioni di prodotto e ingegneria, non dopo l’implementazione. In pratica, contano tre checkpoint.
-
Discovery Registrare lo scopo, il beneficio atteso per l’utente e la base giuridica prima che il team si impegni su una soluzione. Se lo scopo è vago in questa fase, il resto della valutazione deriverà.
-
Revisione del design Confermare quali campi dati entrano nel servizio, dove sono archiviati, se gli identificativi possono essere ridotti e quali controlli sono realisticamente applicabili dal punto di vista tecnico. Di solito è il punto in cui gli ingegneri possono ancora modificare schemi, finestre di conservazione o costruzione dei prompt senza rifare tutto a caro prezzo.
-
Revisione delle modifiche Rivalutare quando una funzionalità inizia a usare nuove categorie di dati, aggiunge logica di profilazione, si estende a un nuovo segmento di clienti o introduce inferenze basate sul modello. Per i prodotti abilitati all’AI, questo spesso accade attraverso modifiche incrementali che sembrano innocue se considerate singolarmente.
Gli esiti più rischiosi derivanti dalla LIA dovrebbero attivare un percorso di revisione più ampio. I team che formalizzano questo passaggio di consegne di solito lo collegano a un flusso di lavoro di valutazione d’impatto sulla privacy, così l’escalation si basa su criteri definiti anziché su decisioni dell’ultimo minuto.
Documentazione che aiuta
Un record LIA utile consente a un revisore di comprendere il trattamento senza dover ricostruire ticket Jira, codice sorgente e impostazioni dei vendor. Il solo linguaggio giuridico non basta. Il record dovrebbe mostrare come la valutazione si mappa al sistema che è in esecuzione.
Includere:
- Nome del sistema e owner responsabile
- Scopo del trattamento in linguaggio semplice
- Base giuridica scelta e alternative scartate
- Categorie di dati, identificativi e fonti
- Utenti o gruppi di clienti interessati
- Analisi di bilanciamento e salvaguardie implementate
- Regole di conservazione, cancellazione e accesso
- Data di revisione, cronologia delle versioni e trigger di modifica
- Collegamenti a note architetturali, voci del ROPA e approvazioni di rilascio Le LIA più solidi allegano anche prove. Un diagramma del flusso dei dati, una configurazione di conservazione, l’ambito di un feature flag o una specifica degli input del modello fanno molto di più per sostenere il ragionamento di un paragrafo rifinito e pieno di astrazioni.
Collegare il LIA ai flussi di lavoro ROPA e DPIA
Il ROPA dovrebbe riflettere lo stesso scopo, le stesse categorie, gli stessi destinatari e la stessa logica di conservazione descritti nel LIA. Se l’ingegneria ha ristretto un dataset per il test di bilanciamento, tale restrizione dovrebbe comparire anche nel ROPA. Descrizioni generiche come “miglioramento del servizio” creano rischi evitabili quando il caso d’uso implementato è molto più specifico.
Trigger per la DPIA
Alcuni LIA mostrano che il trattamento può procedere con adeguate garanzie. Altri mostrano che il team ha bisogno di una revisione più completa dei rischi prima del lancio. I trigger comuni includono:
- Profilazione ampliata o scoring comportamentale
- Uso di modelli di AI su contenuti generati dagli utenti
- Ranking automatizzato che influenza visibilità o accesso
- Trattamenti che modificano in modo sostanziale l’esperienza dell’utente
- Riutilizzo dei dati al di fuori del contesto di raccolta originale
Un programma privacy disciplinato usa il LIA per individuare questi casi in anticipo, mentre le modifiche architetturali sono ancora poco costose.
Versionamento e responsabilità
Versiona il LIA come qualsiasi altro artefatto di progettazione. Collega gli aggiornamenti alle milestone di rilascio, alle modifiche dello schema, ai cambiamenti dei vendor e alle principali revisioni del modello.
Una chiara attribuzione delle responsabilità è importante perché ogni funzione detiene prove diverse. Product definisce l’obiettivo di business e il beneficio atteso. Engineering documenta i flussi di dati, i controlli e i confini del sistema. Privacy verifica la base giuridica e controlla la coerenza con informative e registri. Il DPO rivede il ragionamento, i punti di contestazione e la traccia documentale.
Questa suddivisione evita un modo di fallire comune nei team SaaS moderni. Qualcuno completa il modello una volta, la funzionalità evolve tramite eventi di analytics, integrazioni API e prompt del modello, e il LIA approvato non descrive più il sistema in esercizio.
Applicare i LIA ai sistemi AI e al SaaS moderno
Le linee guida generiche sul LIA spesso non reggono quando vengono applicate alle funzionalità AI. I prodotti SaaS moderni mescolano telemetria, testo libero, contenuti di supporto, embedding, tracce di agenti e output dei modelli. Questo rende estremamente facile il purpose creep.
In Italia, il controllo sta aumentando. Una fonte citata osserva che nel 2025 le sanzioni per profilazione AI non documentata hanno raggiunto 12,5 milioni di euro e che un 68% stimato delle verifiche in quest’area fallisce sui test di bilanciamento specifici per l’AI (Shoosmiths su quando usare una valutazione del legittimo interesse). È proprio per questo che i casi d’uso AI richiedono una disciplina LIA più rigorosa.
I team che affrontano questi aspetti hanno anche bisogno di una visione ingegneristica più ampia di protezione dei dati e privacy nei sistemi software, perché il LIA funziona solo quando i controlli circostanti sono reali.
Scenario uno uso delle chat di supporto per migliorare un assistente LLM interno
Un’azienda vuole usare le chat storiche di supporto per migliorare un assistente interno per gli operatori di supporto. L’idea è sensata. Un migliore retrieval e risposte suggerite possono ridurre i tempi di gestione e migliorare la coerenza.
Lo scopo può essere legittimo. La questione della necessità è la parte difficile.
Se il team inserisce trascrizioni complete, identificativi dell’account e narrazioni del cliente in testo libero in una pipeline di fine-tuning o retrieval, il trattamento diventa difficile da difendere. Le chat di supporto contengono spesso dettagli personali inattesi. Contengono anche contesto che gli utenti possono aspettarsi rimanga all’interno dell’interazione di supporto, non diventi materiale di training.
Un design più sicuro di solito appare così:
- Ambito dello scopo limitato alla qualità del supporto interno
- Filtraggio degli identificativi non necessari prima dell’ingestione
- Uso di snippet di conoscenza curati anziché trascrizioni complete senza restrizioni
- Regole chiare di conservazione per i log di prompt e retrieval
- Revisione umana dei suggerimenti prima che influenzino una risposta al cliente
La questione del bilanciamento dipende dalla sorpresa e dall’uso a valle. Il supporto interno per il personale di assistenza è più facile da giustificare rispetto al training ampio del modello per funzionalità di prodotto non correlate.
Scenario due personalizzazione guidata dall’AI basata sui dati comportamentali
Una piattaforma SaaS vuole adattare la dashboard in base ai clic, al tempo di permanenza, ai flussi di lavoro abbandonati e all’uso precedente delle funzionalità. Questa è una richiesta di prodotto comune perché si colloca all’intersezione tra UX, analytics e machine learning.
Lo scopo può essere presentato come miglioramento dell’esperienza cliente. Questo da solo non basta.
Le domande più difficili sono queste:
- L’utente si aspetta una profilazione comportamentale individuale?
- Il modello si limita a riordinare contenuti utili, oppure condiziona in modo sostanziale le opzioni che l’utente vede?
- Lo stesso beneficio può essere ottenuto con raccomandazioni basate su coorti anziché con previsioni a livello di singola persona?
- Esiste un modo semplice per opporsi o disattivare la funzionalità?
Se la risposta richiede il tracciamento a livello personale su una lunga cronologia, il caso di bilanciamento si indebolisce. Se invece il sistema utilizza segnali di interazione recenti e di ambito limitato all’interno di una relazione cliente già esistente, e la raccomandazione può essere spiegata in linguaggio semplice, il bilanciamento è più facile da sostenere.
Scenario tre log di osservabilità dagli agenti AI
Gli agenti AI creano un nuovo problema LIA perché l’osservabilità può trasformarsi accidentalmente in sorveglianza. Per eseguire il debug delle modalità di errore, i team spesso registrano prompt, chiamate agli strumenti, passaggi intermedi, output e feedback degli utenti.
Questo è utile operativamente. Crea anche un record denso del comportamento dell’utente, delle intenzioni e del testo libero.
Un’implementazione debole memorizza tutto indefinitamente in un unico sink di debug. Un’implementazione più solida separa le finalità:
- Telemetria operativa per latenza, tassi di errore e guasti degli strumenti
- Logging dei contenuti solo dove necessario per la diagnosi
- Redazione o filtraggio prima della memorizzazione
- Accesso ristretto per i team di debugging
- Conservazione breve con percorsi di escalation espliciti per i casi di incidente
Il logging dell’AI dovrebbe impostare di default il minimo necessario per l’affidabilità. Se ogni prompt diventa storia permanente, il tuo argomento sulla necessità è già in difficoltà.
Cosa fallisce di solito nei LIA per l’AI
L’errore ricorrente non è l’uso dell’AI in sé. È l’unione di troppi scopi in un unico pipeline.
Per esempio:
- i dati di supporto diventano input di analytics di prodotto
- gli analytics di prodotto diventano dati di training per la personalizzazione
- i log di osservabilità diventano dati riutilizzabili per il miglioramento del modello
Ogni passaggio può sembrare efficiente. Insieme, creano un uso secondario inatteso.
Ecco perché i LIA per l’AI dovrebbero essere esaminati insieme a model card, progettazione del logging, calendari di conservazione e logica di fallback. La base giuridica non può essere difesa in isolamento dall’architettura.
Conclusione Una scelta difendibile e architetturale
Una valutazione del legittimo interesse è utile solo quando cambia le decisioni. Se chiarisce lo scopo, riduce i dati raccolti, restringe la conservazione e porta le funzionalità più rischiose a una revisione più approfondita, allora sta facendo il suo lavoro.
Questo è il valore principale per CTO e product leader. Un buon LIA non è un memo legale allegato alla consegna a posteriori. È un vincolo di progettazione che migliora il sistema. Costringe il team a giustificare perché il trattamento esiste, perché il metodo scelto è necessario e perché l’impatto sulle persone è proporzionato.
Il modello pratico è coerente:
- Scegliere deliberatamente la base giuridica
- Definire lo scopo con una precisione sufficiente a essere contestato
- Testare la necessità tramite minimizzazione e alternative architetturali
- Eseguire il test di bilanciamento con prove, non con intuizioni
- Collegare l’esito a DPIA, voci ROPA e gestione del cambiamento
- Rivedere la valutazione quando il sistema si espande in nuovi usi dei dati
Una semplice checklist finale aiuta prima del lancio:
- Controllo dello scopo. Il team può descrivere il trattamento in una frase precisa?
- Controllo della necessità. Il team ha escluso alternative meno invasive per ragioni esplicitate?
- Controllo del bilanciamento. Aspettative degli utenti, obiezioni e garanzie sono documentate?
- Controllo della governance. Il LIA è collegato a registri, revisioni e responsabili?
- Controllo del cambiamento. Esistono trigger per la rivalutazione quando la funzionalità evolve?
- Controllo AI. Se sono coinvolti modelli, embedding o log di agenti, gli usi secondari sono stati separati e controllati?
La privacy è più forte quando è integrata nell’architettura. Il legittimo interesse non fa eccezione.
Se il tuo team sta costruendo piattaforme SaaS, workflow AI o funzionalità di prodotto ad alta intensità di dati e ha bisogno di aiuto per trasformare i requisiti privacy in un’architettura realmente utilizzabile, Devisia può aiutare a progettare sistemi manutenibili, conformi e radicati in trade-off ingegneristici concreti.