
Per founder, CTO e responsabili prodotto, la scelta tra opt-in e opt-out è una decisione architetturale fondamentale, non una modifica dell’interfaccia utente. Definisce come il tuo software gestisce i dati, la fiducia e il debito tecnico fin dal primo giorno. Un approccio superficiale crea un futuro di complesse rimediature sui dati, rischio crescente di non conformità e una lotta persistente per mantenere la fiducia degli utenti.
Questa decisione riguarda se il tuo sistema opera su una base “permission-first” (priorità al permesso) o “permission-assumed” (permesso presunto). Sbagliare è come installare a posteriori un impianto antincendio in un grattacielo già completato: costoso, dirompente e soggetto a guasti.
Il problema centrale: Permission-First vs. Permission-Assumed
Nel suo nucleo, la distinzione è di ingegneria.
- Opt-in è un modello “permission-first”. Il sistema deve ricevere un consenso esplicito e affermativo dall’utente prima di processare i suoi dati per uno scopo specifico. Per impostazione predefinita, il trattamento dei dati è disabilitato. Questa è l’imposizione prevista da regolamenti come il GDPR.
- Opt-out è un modello “permission-assumed”. Il sistema presume di avere il permesso di trattare i dati fino a quando l’utente non compie un’azione esplicita per revocarlo. Questo approccio è ancora utilizzato in alcune giurisdizioni, ad esempio in parte sotto il California Consumer Privacy Act (CCPA).
Una decisione architetturale, non una funzione dell’interfaccia
Trattare il consenso come un componente dell’interfaccia di ultima ora è un errore comune e critico. Ignora la natura sistemica del flusso dei dati.
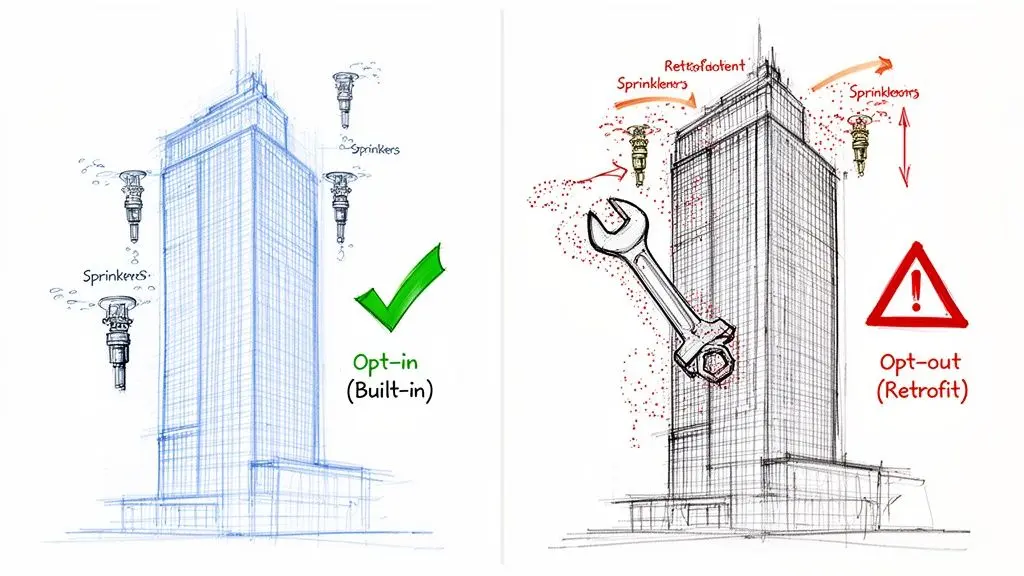
L’approccio opt-in è progettare l’impianto antincendio nei piani dell’edificio. Tubazioni e sensori sono integrati in modo pulito sin dall’inizio. Il sistema è efficiente, affidabile e strutturalmente solido.
L’approccio opt-out è il retrofit. Stai forando pareti finite, disturbando gli inquilini e assemblando componenti a pezzi. È costoso, dirompente e non sei mai certo di aver coperto ogni angolo.
Quando un utente sceglie di rinunciare (opt-out), quel segnale deve propagarsi in modo affidabile a ogni microservizio, strumento di analytics di terze parti e replica del database. Un sistema non progettato per gestire questo crea “silosi del consenso”, dove una parte dello stack rispetta la scelta mentre un’altra la ignora. Questo non è un bug; è un fallimento di conformità in attesa di accadere.
Per chiarire i compromessi, ecco un confronto tra i due modelli.
Opt-In vs. Opt-Out: un confronto ingegneristico
| Aspect | Opt-In (Explicit Consent) | Opt-Out (Implied Consent) |
|---|---|---|
| Default State | Nessun trattamento fino al consenso dell’utente. Il sistema “fail closed”. | Il trattamento avviene fino a obiezione dell’utente. Il sistema “fail open”. |
| User Action | L’utente deve compiere un’azione positiva (es., selezionare una casella). | L’utente deve trovare ed eseguire un’azione per ritirare il consenso. |
| Compliance Posture | Lo standard richiesto per GDPR e la direttiva ePrivacy. | Accettabile per casi d’uso specifici sotto CCPA/CPRA ma comporta un rischio maggiore. |
| User Trust | Alto. Dimostra rispetto per la scelta dell’utente per default. | Basso. Può essere percepito come ostile all’utente presumendo il permesso. |
| Initial Data Volume | Inferiore. | Maggiore. |
| Technical Debt | Minore. Il consenso è un vincolo architetturale integrato, semplificando la gestione. | Maggiore. Aggiungere la logica opt-out a posteriori è complesso e soggetto a errori. |
Progettare attorno a una strategia di consenso chiara rende la conformità verificabile e gestibile. Più importante, dimostra che rispetti i dati degli utenti per progettazione, non per caso — una base di fiducia difficile da replicare per i concorrenti.
Come le normative sulla privacy definiscono il design del sistema
Le normative sulla privacy non sono documenti legali astratti; sono vincoli di ingegneria concreti che dettano il comportamento del sistema. La decisione tra un modello opt-in opt out è una conseguenza diretta delle normative che si applicano ai tuoi utenti. Scegliere in modo errato crea un rischio di conformità immediato e significativo, poiché le regole definiscono lo stato predefinito del consenso e quindi la logica fondamentale della tua architettura dati.
GDPR: il rigido obbligo di opt-in
Il Regolamento Generale sulla Protezione dei Dati (GDPR), che disciplina i dati delle persone nell’Unione Europea, opera su un principio rigoroso di opt-in. Non puoi trattare dati personali senza un consenso esplicito, affermativo e liberamente prestato per uno scopo specifico.
Da una prospettiva ingegneristica, questo obbliga i tuoi sistemi a “fail closed”.
- Default State: Per impostazione predefinita non è permesso alcun trattamento dei dati. L’inazione dell’utente non può essere interpretata come consenso.
- User Action: L’utente deve compiere un’azione chiara e positiva, come selezionare una casella non selezionata. Le caselle pre-selezionate sono una chiara violazione.
- Granularity: Il consenso deve essere granulare. Non puoi raggruppare il consenso per email di marketing, analytics e personalizzazione in un’unica richiesta; ciascuno richiede un opt-in affermativo separato.
Questo significa che i tuoi servizi backend devono essere costruiti per verificare la presenza di un flag di permesso esplicito prima di generare qualsiasi evento di tracciamento, inviare comunicazioni di marketing o usare i dati per la personalizzazione. L’assenza di un flag “consenso concesso” per uno scopo specifico implica che l’azione è bloccata. Copriamo gli aspetti tecnici specifici per costruire sistemi conformi al GDPR nel nostro articolo dettagliato.
CCPA e il diritto di opt-out
Al contrario, il California Consumer Privacy Act (CCPA), così come emendato dal CPRA, utilizza generalmente un modello opt-out. Pur riconoscendo agli utenti diritti significativi, il meccanismo primario per molti usi dei dati — in particolare relativi alla pubblicità — è il diritto dell’utente di ritirare il consenso in qualsiasi momento.
Questo quadro sposta la sfida architetturale dal bloccare la raccolta dati iniziale a eseguire perfettamente le richieste di opt-out degli utenti.
Sotto CCPA/CPRA, la sfida tecnica principale non è impedire la raccolta dei dati in anticipo. È garantire di avere un processo affidabile e verificabile per onorare la richiesta di un utente di interrompere la “vendita” o la “condivisione” delle sue informazioni personali attraverso ogni sistema.
Le implicazioni tecniche sono significative. Una richiesta di opt-out deve generare un segnale che si propaghi in modo affidabile a tutti i microservizi, data warehouse e strumenti di terze parti. Se la tua piattaforma di marketing automation non riceve il segnale dal tuo database centrale del consenso, non sei conforme. Il tuo sistema deve essere progettato per gestire e registrare questi ritiri con 100% di accuratezza.
Direttiva ePrivacy: la “Cookie Law”
Spesso operante insieme al GDPR, la direttiva ePrivacy regola specificamente i cookie e altre tecnologie di tracciamento. Essa impone il consenso preventivo e informato (opt-in) prima di collocare qualsiasi cookie non essenziale sul dispositivo di un utente.
Questo crea una distinzione critica. Anche se hai un “interesse legittimo” a trattare i dati ai sensi del GDPR, l’uso di un cookie per raccogliere quei dati richiede un proprio opt-in esplicito. Questo invalida un approccio “one-size-fits-all”. La tua architettura deve essere in grado di distinguere tra il consenso per il trattamento dei dati e il consenso per la tecnologia di tracciamento in sé. Spesso questo richiede l’uso del rilevamento geo-IP per mostrare l’interfaccia corretta — un banner di opt-in rigoroso per gli utenti UE e una notifica di opt-out più semplice per altri.
Pattern architetturali per la gestione moderna del consenso
Conoscere la differenza tra opt-in e opt-out è una cosa. Costruire un sistema che effettivamente applichi quelle scelte attraverso un’architettura distribuita è una sfida completamente diversa. Un approccio superficiale — trattare il consenso come un semplice flag booleano in una tabella utenti — è una ricetta per mal di testa di conformità e debito tecnico.
Per costruire un sistema resiliente e verificabile, devi trattare il consenso come una risorsa di prima classe nella tua architettura. Non può essere un ripensamento; deve essere un servizio centrale che fornisce una singola fonte di verità che tutti gli altri componenti del sistema interrogano prima di agire. Qui, delineiamo quattro pattern architetturali critici per costruire un sistema compliant by design.
Il diagramma sottostante mette in evidenza come diverse leggi sulla privacy impongano requisiti differenti, che a loro volta modellano le tue scelte architetturali.
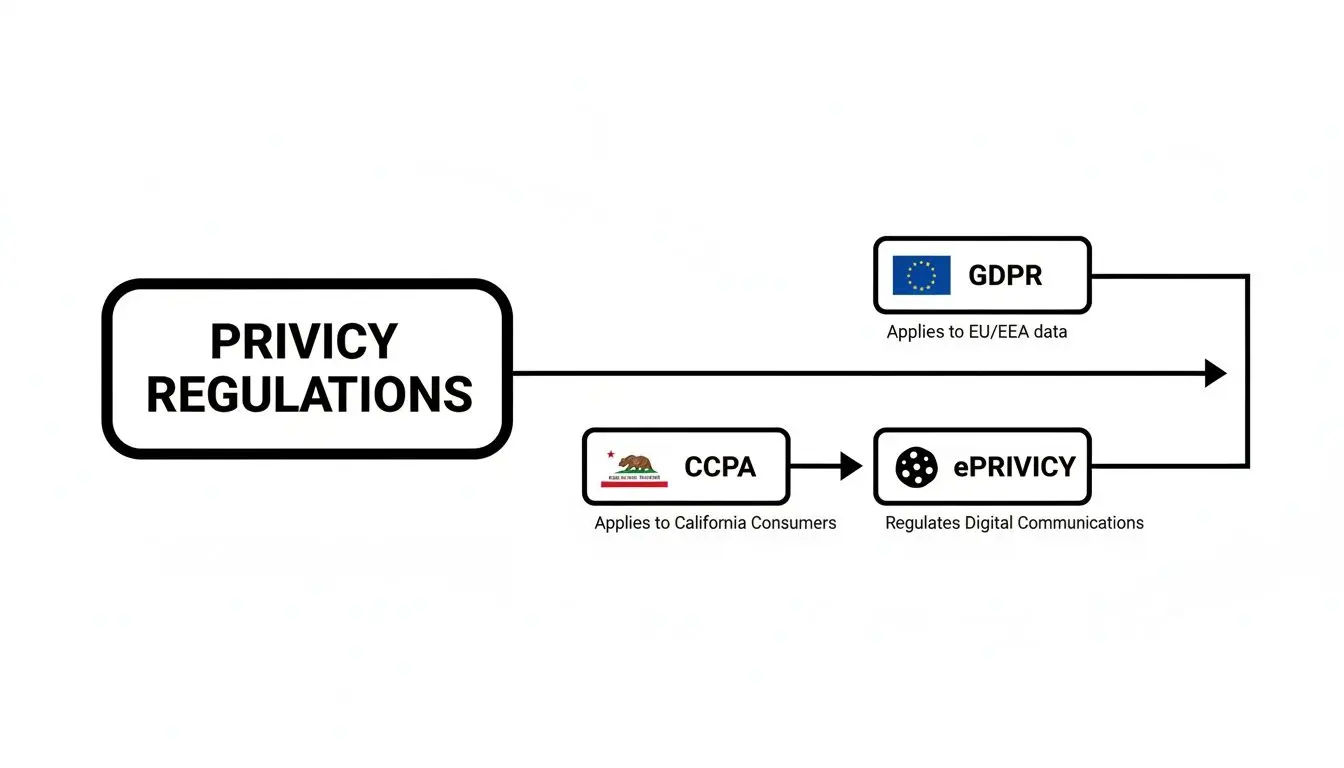
Questa visualizzazione rende chiaro: hai bisogno di un’architettura flessibile che possa gestire sia regole rigorose di opt-in (come il GDPR) sia meccanismi opt-out (come il CCPA), spesso all’interno dello stesso prodotto.
Progetta un servizio centralizzato per il consenso
L’errore architetturale più significativo è permettere a ogni microservizio o applicazione di gestire il consenso localmente. Questo crea “silosi del consenso”, dove un utente potrebbe disiscriversi dalle email di marketing sull’app web, ma continuare a riceverle perché il backend mobile o una pipeline di analytics separata non ha mai ricevuto la preferenza aggiornata.
La soluzione è un Centralised Consent Service. Si tratta di un microservizio dedicato che funge da fonte unica e immutabile di verità per tutte le preferenze degli utenti in tutta l’organizzazione.
- Single Responsibility: La sua unica funzione è memorizzare, gestire e servire gli stati di consenso degli utenti.
- Isolates Logic: Centralizzare questa funzione evita che le regole di consenso vengano duplicate o divergano tra codebase differenti.
- Auditability by Design: Un singolo servizio fornisce una traccia di audit pulita e unificata per i regolatori. Puoi dimostrare esattamente quando e come un utente ha dato o revocato il consenso.
Questo modello si allinea perfettamente con il design dei sistemi moderni. Per un approfondimento su come strutturare tali sistemi, la nostra guida su service-oriented architecture and its benefits fornisce pattern rilevanti.
Implementa uno schema dati pragmatico per il consenso
Il tuo Centralised Consent Service richiede uno schema dati ben progettato. Un semplice flag booleano è insufficiente. Per dimostrare la conformità e risolvere problemi, hai bisogno di metadati ricchi e di un registro immutabile — vengono aggiunti nuovi record, ma quelli vecchi non vengono mai modificati, creando un log storico perfetto.
Uno schema pratico deve includere:
- UserID: Un identificatore unico che collega il record a un utente.
- ConsentType: Un nome versionato e leggibile dalla macchina (es.,
marketing_emails_v1.2,analytics_tracking_v2.0). Questo è critico per aggiornare le policy senza invalidare consensi esistenti. - Status: Lo stato corrente, come
granted,denied, orevoked. - Timestamp: Un timestamp ISO 8601 per quando lo stato è stato registrato.
- Audit Metadata: Il contesto necessario per un audit, come la sorgente della modifica (
'web_preferences_page'), l’indirizzo IP e la stringa user agent.
Versionare i tipi di consenso è cruciale. Quando i tuoi termini di servizio cambiano, puoi introdurre una nuova versione (es., analytics_tracking_v2.1) e chiedere agli utenti il nuovo consenso, mantenendo allo stesso tempo un registro chiaro dei loro accordi precedenti.
Progetta API sicure per le operazioni sul consenso
Con un servizio centrale e uno schema solido, hai bisogno di endpoint sicuri con cui gli altri servizi possano interagire. L’API dovrebbe essere semplice, sicura e veloce.
Gli endpoint chiave includerebbero:
POST /consent: Crea un nuovo record di consenso quando un utente compie una scelta. Il body della richiesta contiene l’ID utente, il tipo di consenso e lo stato.GET /consent/{userId}: Recupera tutti gli stati di consenso correnti per un dato utente. Altri servizi lo chiamano per verificare il permesso prima di agire sui dati dell’utente.GET /consent/{userId}/{consentType}: Un controllo più mirato per un permesso specifico, che restituisce un semplice booleano per mantenere pulita la logica dell’applicazione.
Queste chiamate API fungono da guardiani per l’elaborazione dei dati. Prima che il tuo servizio email invii una campagna o che un servizio di analytics registri un evento, deve effettuare una chiamata bloccante al servizio di consenso per verificare il permesso.
Usa la propagazione basata su eventi per aggiornamenti in tempo reale
Quando un utente revoca il consenso, quel cambiamento deve propagarsi attraverso tutti i sistemi quasi in tempo reale. Un utente che rinuncia alle email di marketing alle 10:00 non può ricevere una email promozionale alle 10:05. Aspettare un job notturno non è un’opzione praticabile.
Qui è dove un’architettura basata su eventi diventa essenziale.
- Quando il Servizio di Consenso registra un cambiamento di stato (ad esempio da
grantedarevoked), pubblica un evento su una coda di messaggi come Apache Kafka o RabbitMQ. - I sistemi a valle — la piattaforma email, il motore di personalizzazione, i job del data warehouse — sono sottoscritti a questi eventi.
- Al ricevimento dell’evento, ogni servizio agisce immediatamente. Il servizio email può aggiungere istantaneamente l’utente a una lista di soppressione, garantendo che non vengano inviate ulteriori email.
Questo schema disaccoppia i tuoi servizi assicurando al contempo una consistenza quasi in tempo reale. Trasforma la tua architettura da un modello passivo di “pull” (dove i servizi verificano periodicamente gli aggiornamenti) a un modello attivo di “push” dove i cambiamenti di consenso vengono trasmessi immediatamente. In un ambiente complesso e distribuito, è così che onori in modo affidabile una scelta di rinuncia.
Una grande architettura backend non ha valore se non si traduce in un’esperienza utente chiara e affidabile. Il ponte tra la logica di consenso del backend e l’interfaccia frontend è dove il tuo impegno per la privacy diventa reale per gli utenti.
Una connessione senza soluzione di continuità assicura che quando un utente compie una scelta di adesione o rinuncia, questa venga rispettata istantaneamente e con precisione ovunque. Questo significa andare ben oltre un semplice banner di cookie.
Un frontend moderno e conforme richiede un centro preferenze granulare. Non si tratta di un singolo pulsante “accetta tutto” ma di una dashboard pulita dove gli utenti possono gestire le diverse attività di trattamento dei dati con interruttori separati. Il linguaggio deve essere diretto e trasparente, evitando pratiche manipolative progettate per coartare gli utenti nel dare il consenso.
La privacy by design significa che l’interfaccia utente è un riflesso onesto dell’architettura backend. Se il tuo sistema può distinguere tra dati di analytics e dati di marketing, il tuo centro preferenze deve offrire controlli separati per ciascuno.
Questa trasparenza costruisce fiducia nell’utente. Quando un utente vede scelte specifiche e comprensibili, dimostra rispetto per la sua autonomia. Un’interfaccia confusa, al contrario, implica che il sistema sottostante sia altrettanto confuso e probabilmente non conforme.
Dall’interruttore del frontend al guardiano del backend
Quando un utente attiva o disattiva un interruttore sul frontend, un servizio backend corrispondente deve agire come un rigido guardiano. Questo non è un suggerimento: è una regola ferrea applicata nel tuo codice prima che qualsiasi dato venga elaborato. Il Servizio di Consenso Centralizzato discusso in precedenza diventa la fonte unica di verità che ogni altro servizio deve consultare.
Ad esempio, prima che la tua applicazione tracci un’interazione utente, il codice deve eseguire un controllo esplicito. Questo passaggio semplice ma non negoziabile è il nucleo di un efficace sistema di adesione e rinuncia.
Ecco un esempio in pseudocodice che illustra il pattern del guardiano:
# A user performs an action in the app, like viewing a product page
def on_product_view(user_id, event_details):
# CRITICAL CHECK: Before tracking, query the consent service.
# This is a blocking call. The function waits for a clear 'yes' or 'no'.
has_permission = consent_service.check_consent(
user_id=user_id,
consent_type='ANALYTICS_TRACKING_V2'
)
# Only if consent is explicitly 'granted' does the event fire.
# If the check returns false or null, nothing happens. The system fails closed.
if has_permission:
analytics.track('product_viewed', event_details)
# ... continue with other application logicQuesto frammento illustra il principio fondamentale: il consenso è un prerequisito, non un pensiero successivo. Il servizio analytics non stabilisce regole autonome; segue la decisione trasmessa dal servizio di consenso.
Gestire scenari di consenso complessi
Gli scenari reali introducono complessità, in particolare con gli utenti non autenticati. Un visitatore che non ha creato un account ha comunque diritti sulla privacy e le sue scelte di consenso devono essere gestite con la stessa cura.
- Utenti non autenticati: Per i visitatori anonimi, il consenso viene tipicamente memorizzato in un cookie di prima parte sicuro o in local storage, collegato a un identificatore temporaneo.
- Transizione a utente autenticato: Quando quell’utente effettua l’accesso o si registra, il sistema deve unire le sue preferenze anonime di consenso con il nuovo profilo utente. Questo crea un’esperienza fluida e conforme senza costringerlo a ripetere le scelte.
Gestire correttamente questi casi limite è segno di un’architettura matura. Assicura che i tuoi meccanismi di adesione e rinuncia si applichino in modo coerente a tutti coloro che interagiscono con il tuo prodotto, non solo agli utenti autenticati. Questo costruisce una base di fiducia fin dal primo clic, dimostrando che il tuo sistema è stato progettato per rispettare la scelta dell’utente in tutte le situazioni.
Le sfide uniche del consenso nei sistemi di IA
Quando si parla di gestione del consenso, il vecchio manuale per database e applicazioni semplici semplicemente non funziona per l’IA. L’intelligenza artificiale, e in particolare i Large Language Model (LLM), introduce un livello completamente nuovo di complessità per adesione e rinuncia. Per qualsiasi responsabile tecnico che costruisce prodotti IA, pensare ai dati di addestramento come se fossero soltanto un record in un database è un errore critico e potenzialmente molto costoso.
Il cuore del problema risiede nel modo in cui i modelli vengono addestrati. Una volta che i dati di un utente vengono inseriti in un processo di addestramento, vengono matematicamente intrecciati nella struttura del modello — nei suoi pesi e parametri. Non puoi semplicemente eliminare il contributo di un utente da un modello addestrato come faresti eliminando una riga da una tabella. Questo processo, noto come “machine unlearning”, è incredibilmente difficile e spesso computazionalmente impossibile.
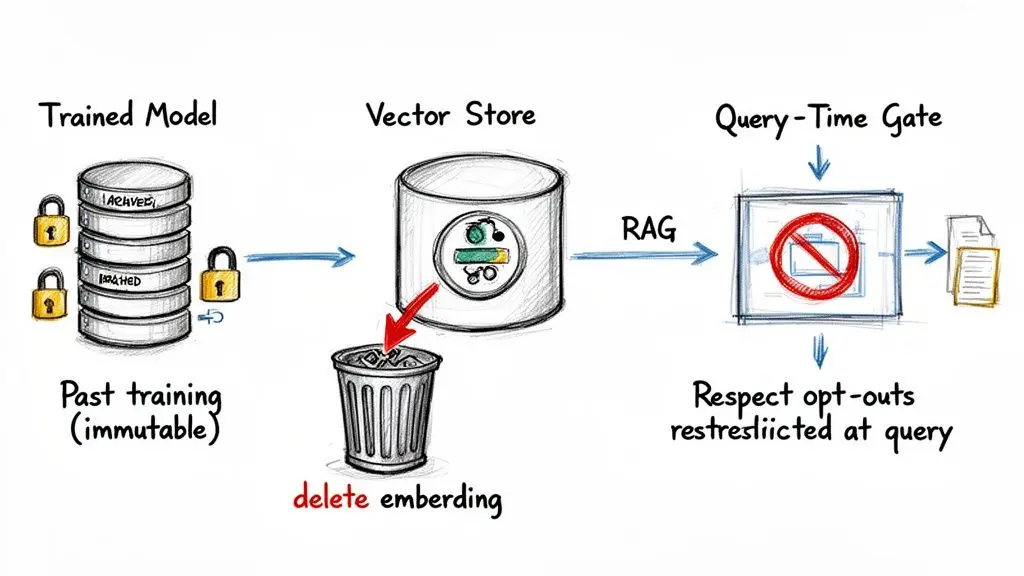
Per questo motivo, una richiesta di rinuncia dell’utente rispetto all’addestramento del modello non può essere applicata retroattivamente. Si tratta invece di un problema architetturale: devi progettare i tuoi sistemi in modo da far rispettare tale rinuncia per tutte le future esecuzioni di addestramento.
Rispettare i permessi in fase di interrogazione con RAG
Qui le architetture Retrieval-Augmented Generation (RAG) diventano uno strumento essenziale per la privacy. In un sistema RAG, l’LLM non si basa solo sulla sua conoscenza statica pre-addestrata. Recupera informazioni rilevanti da una fonte esterna — come un database vettoriale — proprio nel momento in cui un utente pone una domanda.
Questo recupero “just-in-time” dei dati ti offre un potente punto di controllo per far rispettare i permessi degli utenti.
L’addestramento statico di un LLM rende quasi impossibile rimuovere dati. Un sistema RAG, invece, ti permette di far rispettare i permessi in fase di interrogazione, impedendo al modello di vedere o usare dati che un utente ha limitato.
Quando progetti un sistema RAG con la privacy in mente, la tua architettura deve collegare il meccanismo di recupero direttamente al servizio di gestione del consenso. Prima che il sistema recuperi qualsiasi documento per aiutare l’LLM a formulare una risposta, deve prima verificare se l’utente corrente è autorizzato ad accedere a quelle informazioni. Questo semplice controllo impedisce che l’LLM filtri accidentalmente dati sensibili o riservati.
Cancellare gli embedding vettoriali su richieste di cancellazione
Anche se non puoi praticabilemente “disaddestrare” un modello, puoi — e devi — gestire le richieste di cancellazione dei dati (come il diritto all’oblio del GDPR) all’interno della base di conoscenza del tuo sistema RAG. Quando un utente rinuncia o richiede la cancellazione dei propri dati, hai bisogno di un processo solido per trovare e rimuovere tutti gli embedding vettoriali collegati ai loro contenuti.
Questa è una sfida ingegneristica reale che richiede una pianificazione accurata.
- I metadata sono cruciali: Ogni embedding vettoriale deve essere memorizzato con metadata ricchi, in particolare l’ID della fonte originale dei dati e l’ID utente del proprietario. Senza quel collegamento, trovare i vettori giusti da eliminare è come cercare un ago in un pagliaio.
- Progetta per la cancellazione: Il tuo database vettoriale e l’architettura attorno ad esso devono essere costruiti per gestire cancellazioni efficienti basate su filtri di metadata. Aggiungere vettori senza una strategia chiara di cancellazione è una bomba a orologeria in termini di conformità.
- Processi verificabili: L’intero processo di cancellazione deve essere loggato e verificabile. Devi essere in grado di dimostrare che quando hai ricevuto una richiesta valida, hai rimosso con successo tutti gli embedding vettoriali associati dalla base di conoscenza RAG.
Affrontare queste questioni richiede un cambiamento di mentalità. Devi progettare i tuoi sistemi IA assumendo che i dati dovranno essere filtrati e cancellati. Integrare questi controlli sin dal primo giorno è fondamentale per uno sviluppo dell’IA responsabile. Per un modo strutturato di affrontare queste tematiche, la nostra gratuita Checklist sui rischi e la privacy dell’AI offre un quadro utile per valutare i tuoi sistemi senza memorizzare nessuno dei tuoi dati sensibili. Una governance proattiva di questo tipo è l’unico modo per gestire il complesso panorama della rinuncia nell’IA moderna.
Conclusione: la privacy come scelta architetturale
Per anni molte aziende B2B hanno trattato la gestione del consenso come una semplice seccatura di conformità — una casella da spuntare. Questo è un errore profondo. Il tuo approccio a adesione e rinuncia è una scelta architetturale fondamentale che segnala i valori della tua azienda e la maturità ingegneristica.
Trattare il consenso con la stessa importanza architetturale della sicurezza o della scalabilità è il nuovo standard per costruire software affidabile. Progettare per un modello di adesione di default, anche quando non è legalmente obbligatorio, crea un sistema più resiliente e a prova di futuro riducendo il debito di conformità a lungo termine e costruendo una fiducia duratura negli utenti. Questo non è un centro di costo; è un vantaggio competitivo.
Punti chiave per i leader tecnici
Per mettere in pratica questa filosofia, i team di ingegneria e prodotto dovrebbero interiorizzare questi principi fondamentali per costruire sistemi conformi oggi e pronti per le future normative.
- Centralizza la logica del consenso: Costruisci un microservizio dedicato come fonte unica di verità per le preferenze degli utenti. Questo elimina i silos di consenso e garantisce coerenza.
- Versiona i consensi: Usa tipi di consenso versionati nello schema dei dati (ad es.,
analytics_v2.1) per gestire aggiornamenti di policy e flussi di nuovo consenso senza corrompere i record storici. - Implementa API guardiane: Progetta API bloccanti e sicure che gli altri servizi devono chiamare prima di elaborare i dati. Il sistema dovrebbe “fallire chiuso” per impostazione predefinita.
- Propaga i cambiamenti tramite eventi: Usa code di messaggi per trasmettere istantaneamente i cambiamenti di consenso, garantendo che una richiesta di rinuncia sia rispettata ovunque in tempo reale.
In ultima analisi, progettare per la privacy impone chiarezza, disciplina e un focus centrato sull’utente — qualità che costruiscono prodotti migliori e una fedeltà del cliente più solida.
Domande frequenti
Quando si parla di privacy, il divario tra teoria legale e realtà ingegneristica può essere enorme. I leader tecnici spesso incontrano gli stessi ostacoli pratici quando costruiscono sistemi di consenso. Ecco alcune delle domande più comuni che vediamo — e come gestirle correttamente.
Posso usare un unico banner sia per GDPR che per CCPA?
Tentare di creare un unico banner per i cookie ibrido valido sia per il GDPR che per il CCPA è un errore comune e pericoloso. Le normative si basano su filosofie del consenso fondamentalmente diverse, il che rende quasi garantito il fallimento di un approccio valido per tutti. Il GDPR richiede un rigoroso consenso esplicito prima di raccogliere dati; il CCPA funziona con un modello di rinuncia.
Un banner che traccia per impostazione predefinita ma include un link per la rinuncia rappresenta una violazione diretta della regola del pre-consenso del GDPR. D’altra parte, imporre un consenso esplicito rigoroso agli utenti in regioni dove non è legalmente richiesto aggiunge solo attrito inutile.
Un approccio molto più sicuro ed efficace è utilizzare il rilevamento geo-IP sul tuo lato server.
- Per gli utenti dell’UE: Fornisci un’interfaccia chiara e granulare di consenso esplicito in cui nessun tracker non essenziale sia attivo per impostazione predefinita.
- Per gli utenti della California: Presenta un avviso chiaro con un link facile da trovare “Non vendere o condividere le mie informazioni personali” per soddisfare i requisiti di rinuncia.
Questo garantisce che tu applichi lo standard legale corretto agli utenti giusti, minimizzando sia il rischio di non conformità sia le interruzioni per il business.
Come gestisco una richiesta del diritto all’oblio?
Gestire una richiesta del “diritto all’oblio” è molto più che contrassegnare un account come ‘eliminato’ in un database. È un problema complesso di sistemi distribuiti. La vera cancellazione significa che devi rimuovere permanentemente i dati personali di un utente da ogni singolo angolo della tua infrastruttura—e poter dimostrare di averlo fatto.
L’intero processo deve essere automatizzato, verificabile e comprensivo. Una volta che una richiesta è convalidata, deve attivare un flusso di lavoro che si propaga in tutto il tuo stack tecnologico.
Una richiesta di cancellazione non è una singola query al database; è una cascata di comandi di eliminazione che devono essere eseguiti su ogni microservizio, database, cache, file di log e integrazione con fornitori terzi. L’intero processo deve essere registrato per fornire una traccia di controllo che dimostri che i dati sono stati rimossi.
Se trascuri anche un solo sistema a valle—come uno strumento di automazione marketing o un data warehouse per l’analisi—si tratta di una violazione della conformità. La tua architettura deve essere progettata fin dall’inizio per tracciare e purgare i dati per ID utente, ovunque risiedano.
Qual è il più grande errore di ingegneria con consenso esplicito e rinuncia?
L’errore più critico che gli ingegneri commettono è trattare il consenso come un problema locale, limitato al frontend. È così che nascono i “silos di consenso”—un grave difetto architetturale. Una parte del sistema, come il sito web, potrebbe rispettare la rinuncia di un utente, ma un’altra parte, come la tua app mobile o una pipeline di backend, è completamente ignara e continua a processare i loro dati illegalmente.
Questo accade quando le scelte di consenso sono memorizzate localmente all’interno di ciascuna applicazione invece di essere gestite da un servizio autorevole unico. La preferenza dell’utente resta intrappolata in una parte del sistema, rendendo la tua conformità frammentata e inaffidabile.
L’unico modo per evitare questo è considerare il consenso come una sfida dei sistemi distribuiti fin dal primo giorno. La scelta di un utente di dare consenso o di rinunciare è uno stato globale che deve essere rispettato universalmente in tutta la tua architettura. Questo richiede un servizio centralizzato per il consenso che agisca come unica fonte di verità, obbligando ogni servizio a chiedere il permesso prima di agire sui dati dell’utente.
In Devisia, crediamo che la privacy sia una scelta architettonica, non solo una funzionalità. Costruiamo sistemi software affidabili e manutenibili che integrano conformità e fiducia fin dal primo giorno. Se sei pronto a costruire un prodotto digitale su una base di eccellenza ingegneristica, scopri come possiamo aiutarti su https://www.devisia.pro.