
For founders, CTOs, and product leaders, the choice between opt-in and opt-out is a foundational architectural decision, not a UI tweak. It defines how your software handles data, trust, and technical debt from day one. A superficial approach creates a future of complex data remediation, mounting compliance risk, and a persistent struggle to maintain user trust.
This decision is about whether your system operates on a “permission-first” or “permission-assumed” basis. Getting it wrong is like retrofitting a fire suppression system into a completed skyscraper—expensive, disruptive, and prone to failure.
The Core Problem: Permission-First vs. Permission-Assumed
At its core, the distinction is an engineering one.
- Opt-in is a “permission-first” model. The system must receive explicit, affirmative user consent before processing their data for a specific purpose. By default, data processing is disabled. This is the mandate under regulations like GDPR.
- Opt-out is a “permission-assumed” model. The system assumes it has permission to process data until the user takes an explicit action to revoke it. This approach is still used in certain jurisdictions, such as under parts of the California Consumer Privacy Act (CCPA).
An Architectural Decision, Not a UI Feature
Treating consent as a last-minute UI component is a common and critical error. It ignores the systemic nature of data flow.
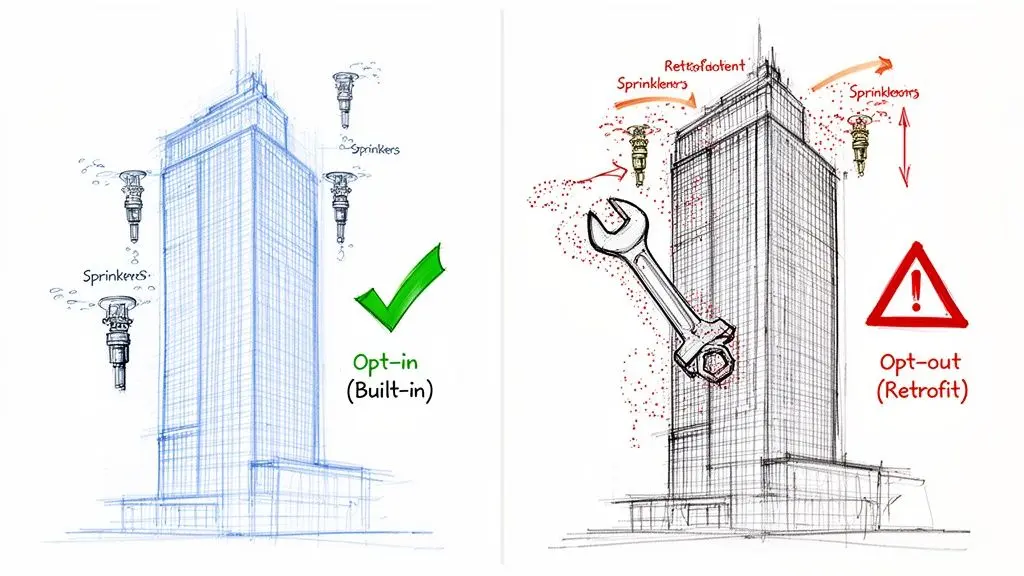
The opt-in approach is designing the sprinkler system into the building’s blueprints. Pipes and sensors are integrated cleanly from the start. The system is efficient, reliable, and structurally sound.
The opt-out approach is the retrofit. You’re drilling through finished walls, disrupting tenants, and patching components together. It’s expensive, disruptive, and you’re never certain you’ve covered every corner.
When a user opts out, that signal must propagate reliably to every microservice, third-party analytics tool, and database replica. A system not built to handle this creates “consent silos,” where one part of the stack respects the choice while another ignores it. This isn’t a bug; it’s a compliance failure waiting to happen.
To clarify the trade-offs, here is a comparison of the two models.
Opt-In vs. Opt-Out: An Engineering Comparison
| Aspect | Opt-In (Explicit Consent) | Opt-Out (Implied Consent) |
|---|---|---|
| Default State | No processing until user agrees. System “fails closed.” | Processing occurs until user objects. System “fails open.” |
| User Action | User must take a positive action (e.g., check a box). | User must find and execute an action to withdraw consent. |
| Compliance Posture | The required standard for GDPR and the ePrivacy Directive. | Acceptable for specific use cases under CCPA/CPRA but carries higher risk. |
| User Trust | High. Demonstrates respect for user choice by default. | Low. Can be perceived as user-hostile by assuming permission. |
| Initial Data Volume | Lower. | Higher. |
| Technical Debt | Lower. Consent is a built-in architectural constraint, simplifying management. | Higher. Retrofitting opt-out logic is complex and error-prone. |
Architecting around a clear consent strategy makes compliance auditable and manageable. More importantly, it demonstrates that you respect user data by design, not by accident—a foundation of trust that is difficult for competitors to replicate.
How Privacy Regulations Define System Design
Privacy regulations are not abstract legal documents; they are concrete engineering constraints that dictate system behavior. The decision between an opt-in opt out model is a direct consequence of which regulations apply to your users. Choosing incorrectly creates immediate and significant compliance risk, as the rules define the default state of consent and thus the fundamental logic of your data architecture.
GDPR: The Strict Opt-In Mandate
The General Data Protection Regulation (GDPR), which governs data for individuals in the European Union, operates on a strict opt-in principle. You cannot process personal data without explicit, affirmative, and freely given consent for a specific purpose.
From an engineering perspective, this forces your systems to “fail closed.”
- Default State: No data processing is permitted by default. User inaction cannot be interpreted as consent.
- User Action: The user must perform a clear, positive action, such as ticking an unchecked box. Pre-checked boxes are a clear violation.
- Granularity: Consent must be granular. You cannot bundle consent for marketing emails, analytics, and personalization into a single request; each requires a separate, affirmative opt-in.
This means your backend services must be built to check for an explicit permission flag before firing any tracking event, sending marketing communications, or using data for personalization. The absence of a “consent granted” flag for a specific purpose means the action is blocked. We cover the technical specifics of building GDPR-compliant systems in our detailed article.
CCPA and the Right to Opt Out
In contrast, the California Consumer Privacy Act (CCPA), as amended by the CPRA, generally utilizes an opt-out model. While it grants users significant rights, the primary mechanism for many data uses—particularly related to advertising—is the user’s right to withdraw consent at any time.
This framework shifts the architectural challenge from gating initial data collection to flawlessly executing user opt-out requests.
Under CCPA/CPRA, the primary technical challenge is not preventing data collection upfront. It is ensuring you have a reliable, auditable process to honor a user’s request to stop the “sale” or “sharing” of their personal information across every system.
The technical implications are significant. An opt-out request must trigger a signal that reliably propagates through all microservices, data warehouses, and third-party tools. If your marketing automation platform does not receive the signal from your central consent database, you are non-compliant. Your system must be designed to handle and log these withdrawals with 100% accuracy.
The ePrivacy Directive: The “Cookie Law”
Often operating alongside GDPR, the ePrivacy Directive specifically governs cookies and other tracking technologies. It mandates prior, informed opt-in consent before placing any non-essential cookies on a user’s device.
This creates a critical distinction. Even if you have a “legitimate interest” to process data under GDPR, the act of using a cookie to gather that data requires its own explicit opt-in. This invalidates a one-size-fits-all approach. Your architecture must be capable of distinguishing between consent for data processing and consent for the tracking technology itself. This often requires using geo-IP detection to serve the correct interface—a strict opt-in banner for EU users and a simpler opt-out notice for others.
Architectural Patterns for Modern Consent Management
Knowing the difference between opt-in and opt-out is one thing. Building a system that actually enforces those choices across a distributed architecture is a completely different challenge. A superficial approach—treating consent as just another boolean flag in a user table—is a recipe for compliance headaches and technical debt.
To build a resilient and auditable system, you must treat consent as a first-class citizen in your architecture. It cannot be an afterthought; it must be a core service providing a single source of truth that all other system components query before acting. Here, we outline four critical architectural patterns for building a system that is compliant by design.
The diagram below highlights how different privacy laws impose different requirements, which in turn shapes your architectural choices.
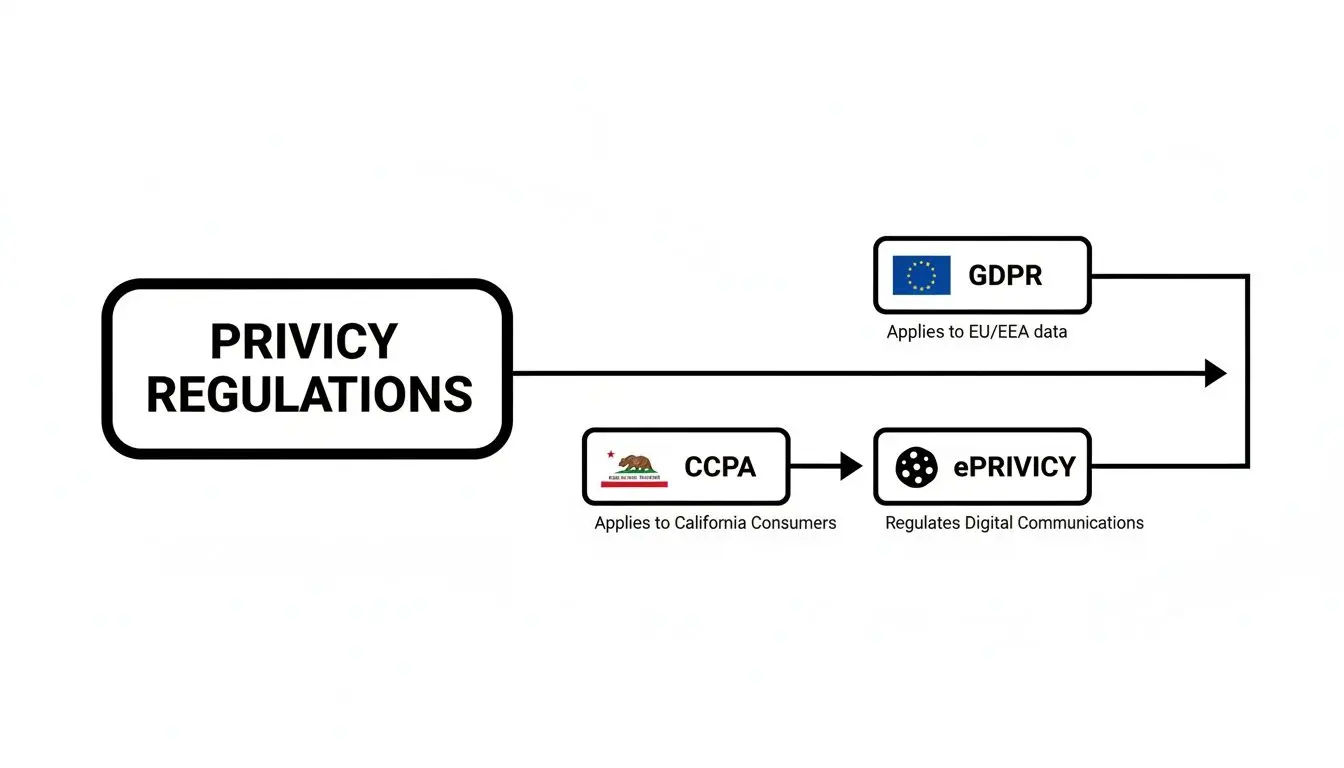
This visual makes it clear: you need a flexible architecture that can manage both strict opt-in rules (like GDPR) and opt-out mechanisms (like CCPA), often within the same product.
Design a Centralised Consent Service
The most significant architectural error is allowing each microservice or application to manage consent locally. This creates “consent silos,” where a user might opt out of marketing emails on the web application, but still receive them because the mobile backend or a separate analytics pipeline never received the updated preference.
The solution is a Centralised Consent Service. This is a dedicated microservice that acts as the single, immutable source of truth for all user preferences across the entire organization.
- Single Responsibility: Its sole function is to store, manage, and serve user consent states.
- Isolates Logic: Centralizing this function prevents consent rules from being duplicated or diverging across different codebases.
- Auditability by Design: A single service provides a clean, unified audit trail for regulators. You can prove exactly when and how a user gave or withdrew consent.
This model aligns perfectly with modern system design. For a deeper dive into structuring such systems, our guide on service-oriented architecture and its benefits provides relevant patterns.
Implement a Pragmatic Data Schema for Consent
Your Centralised Consent Service requires a well-designed data schema. A simple boolean flag is insufficient. To prove compliance and debug issues, you need rich metadata and an immutable ledger—new records are added, but old ones are never modified, creating a perfect historical log.
A practical schema must include:
- UserID: A unique identifier linking the record to a user.
- ConsentType: A versioned, machine-readable name (e.g.,
marketing_emails_v1.2,analytics_tracking_v2.0). This is critical for updating policies without invalidating existing consents. - Status: The current state, such as
granted,denied, orrevoked. - Timestamp: An ISO 8601 timestamp for when the status was recorded.
- Audit Metadata: The context required for an audit, such as the source of the change (
'web_preferences_page'), IP address, and user agent string.
Versioning consent types is crucial. When your terms of service change, you can introduce a new version (e.g., analytics_tracking_v2.1) and prompt users for re-consent, while maintaining a clear record of their previous agreements.
Secure API Design for Consent Operations
With a central service and a solid schema, you need secure endpoints for other services to interact with it. The API should be simple, secure, and fast.
Key endpoints would include:
POST /consent: Creates a new consent record when a user makes a choice. The request body carries the user ID, consent type, and status.GET /consent/{userId}: Retrieves all current consent statuses for a given user. Other services call this to check for permission before acting on user data.GET /consent/{userId}/{consentType}: A more focused check for a specific permission, returning a simple boolean to keep application logic clean.
These API calls act as gatekeepers for data processing. Before your email service sends a campaign or an analytics service logs an event, it must make a blocking call to the consent service to verify permission.
Use Event-Driven Propagation for Real-Time Updates
When a user revokes consent, that change must propagate across all systems in near real-time. A user who opts out of marketing emails at 10:00 AM cannot receive a promotional email at 10:05 AM. Waiting for a nightly batch job is not a viable option.
This is where an event-driven architecture is essential.
- When the Consent Service records a status change (e.g., from
grantedtorevoked), it publishes an event to a message queue such as Apache Kafka or RabbitMQ. - Downstream systems—the email platform, the personalization engine, the data warehouse jobs—are subscribed to these events.
- Upon receiving the event, each service acts immediately. The email service can instantly add the user to a suppression list, ensuring no further emails are sent.
This pattern decouples your services while ensuring near real-time consistency. It shifts your architecture from a passive “pull” model (where services periodically check for updates) to an active “push” model where consent changes are broadcast immediately. In a complex, distributed environment, this is how you reliably honor an opt-out choice.
Great backend architecture is worthless if it doesn’t translate into a clear and trustworthy user experience. The bridge between your backend consent logic and the frontend interface is where your commitment to privacy becomes real to your users.
A seamless connection ensures that when a user makes an opt-in or opt-out choice, it’s instantly and accurately respected everywhere. This means moving far beyond a simple cookie banner.
A modern, compliant frontend requires a granular preference center. This is not a single “accept all” button but a clean dashboard where users can manage different data processing activities with individual toggles. The language must be direct and transparent, avoiding manipulative dark patterns designed to coerce users into giving consent.
Privacy by design means the user interface is an honest reflection of the backend architecture. If your system can distinguish between analytics and marketing data, your preference centre must offer separate controls for each.
This transparency builds user trust. When a user sees specific, understandable choices, it demonstrates respect for their autonomy. A confusing interface, by contrast, implies that the system behind it is equally convoluted and likely non-compliant.
From Frontend Toggle to Backend Gatekeeper
When a user flips a toggle on the frontend, a corresponding backend service must act as a strict gatekeeper. This is not a suggestion—it’s a hard rule enforced in your code before any data is processed. The Centralised Consent Service discussed earlier becomes the single source of truth that every other service must check.
For instance, before your application tracks a user interaction, the code must perform an explicit check. This simple but non-negotiable step is the core of an effective opt-in opt-out system.
Here’s a pseudocode example illustrating the gatekeeper pattern:
# A user performs an action in the app, like viewing a product page
def on_product_view(user_id, event_details):
# CRITICAL CHECK: Before tracking, query the consent service.
# This is a blocking call. The function waits for a clear 'yes' or 'no'.
has_permission = consent_service.check_consent(
user_id=user_id,
consent_type='ANALYTICS_TRACKING_V2'
)
# Only if consent is explicitly 'granted' does the event fire.
# If the check returns false or null, nothing happens. The system fails closed.
if has_permission:
analytics.track('product_viewed', event_details)
# ... continue with other application logicThis snippet illustrates the fundamental principle: consent is a prerequisite, not an afterthought. The analytics service does not make its own rules; it follows the decision passed down from the consent service.
Managing Complex Consent Scenarios
Real-world scenarios introduce complexity, particularly with unauthenticated users. A visitor who has not created an account still has privacy rights, and their consent choices must be managed just as carefully.
- Unauthenticated Users: For anonymous visitors, consent is typically stored in a secure, first-party cookie or local storage, linked to a temporary identifier.
- Authenticated Transition: When that user logs in or signs up, your system must merge their anonymous consent preferences with their new user profile. This creates a seamless, compliant experience without forcing them to repeat their choices.
Handling these edge cases correctly is a sign of a mature architecture. It ensures your opt-in and opt-out mechanisms apply consistently to everyone interacting with your product, not just authenticated users. This builds a foundation of trust from the very first click, proving your system was built to respect user choice in all situations.
The Unique Challenges of Consent in AI Systems
When we talk about consent management, the old playbook for databases and simple applications just doesn’t work for AI. Artificial intelligence, and especially Large Language Models (LLMs), introduces a whole new level of complexity for opt-in and opt-out. For any engineering leader building AI products, thinking of training data as just another record in a database is a critical, and potentially very expensive, mistake.
The heart of the problem lies in how models are trained. Once a user’s data is fed into a training process, it gets mathematically woven into the fabric of the model—its weights and parameters. You can’t just delete a user’s contribution from a trained model like you would delete a row from a table. This process, known as ‘machine unlearning’, is incredibly difficult and often computationally impossible.
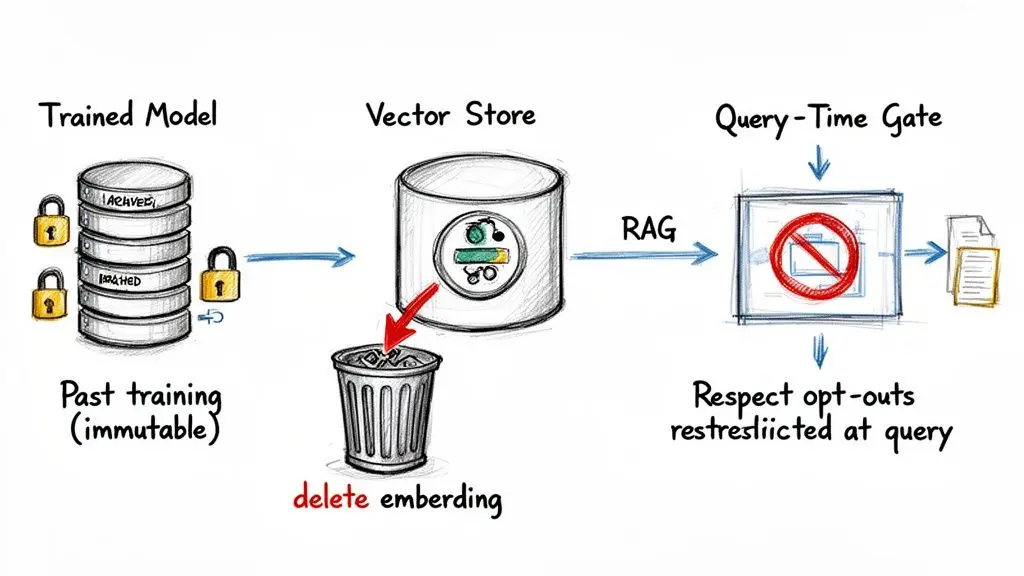
Because of this, a user’s opt-out request for model training can’t be applied retroactively. Instead, it’s an architectural problem: you have to design your systems to enforce that opt-out for all future training runs.
Respecting Permissions At Query Time With RAG
This is where Retrieval-Augmented Generation (RAG) architectures become an essential tool for privacy. In a RAG system, the LLM doesn’t just rely on its static, pre-trained knowledge. It pulls in relevant information from an external source—like a vector database—right at the moment a user asks a question.
This “just-in-time” data retrieval gives you a powerful control point for enforcing user permissions.
An LLM’s static training makes removing data nearly impossible. A RAG system, on the other hand, lets you enforce permissions at query time, stopping the model from ever seeing or using data a user has restricted.
When you’re designing a RAG system with privacy in mind, your architecture has to link the retrieval mechanism directly to your consent management service. Before your system fetches any documents to help the LLM form a response, it must first check if the current user is even allowed to access that information. This simple check prevents the LLM from accidentally leaking sensitive or restricted data.
Deleting Vector Embeddings On Erasure Requests
While you can’t practically un-train a model, you absolutely can—and must—handle data erasure requests (like GDPR’s “right to be forgotten”) within your RAG system’s knowledge base. When a user opts out or asks for their data to be deleted, you need a solid process for finding and removing all the vector embeddings connected to their content.
This is a real engineering challenge that requires careful planning.
- Metadata Is Crucial: Every vector embedding needs to be stored with rich metadata, especially the original data source ID and the user ID of the owner. Without that link, finding the right vectors to delete is like searching for a needle in a haystack.
- Architect for Deletion: Your vector database and the architecture around it must be built to handle efficient deletions based on metadata filters. Just adding vectors without a clear deletion strategy is a ticking compliance bomb.
- Auditable Processes: The entire deletion process has to be logged and auditable. You need to be able to prove that when you received a valid request, you successfully removed all the associated vector embeddings from your RAG knowledge base.
Tackling these issues demands a change in mindset. You have to architect your AI systems assuming that data will need to be filtered and deleted. Building these controls in from day one is fundamental to responsible AI development. For a structured way to think through these issues, our free AI Risk & Privacy Checklist offers a useful framework for evaluating your systems without storing any of your sensitive data. Proactive governance like this is the only way to manage the complex opt-out landscape in modern AI.
Conclusion: Privacy as an Architectural Choice
For years, many B2B companies have treated consent management as just another compliance headache—a box to be ticked. This is a profound mistake. Your approach to opt-in and opt-out is a foundational architectural choice that signals your company’s values and engineering maturity.
Treating consent with the same architectural gravity as security or scalability is the new standard for building trustworthy software. Architecting for an opt-in by default model, even where not legally mandated, creates a more resilient and future-proof system by reducing long-term compliance debt and building durable user trust. This is not a cost center; it’s a competitive advantage.
Key Takeaways for Technical Leaders
To put this philosophy into practice, engineering and product teams should internalize these core principles to build systems that are compliant today and prepared for future regulations.
- Centralise Consent Logic: Build a dedicated microservice as the single source of truth for user preferences. This eliminates consent silos and ensures consistency.
- Version Your Consents: Use versioned consent types in your data schema (e.g.,
analytics_v2.1) to manage policy updates and re-consent flows without corrupting historical records. - Implement Gatekeeper APIs: Design secure, blocking APIs that other services must call before processing data. The system should “fail closed” by default.
- Propagate Changes via Events: Use message queues to broadcast consent changes instantly, ensuring that an opt-out request is honored everywhere in real-time.
Ultimately, architecting for privacy forces clarity, discipline, and a user-centric focus—qualities that build better products and stronger customer loyalty.
Frequently Asked Questions
When it comes to privacy, the gap between legal theory and engineering reality can be huge. Technical leaders often run into the same practical roadblocks when building out consent systems. Here are some of the most common questions we see—and how to handle them correctly.
Can I Use One Banner For Both GDPR And CCPA?
Trying to create a single, hybrid cookie banner for both GDPR and CCPA is a common and dangerous mistake. The regulations are built on fundamentally different philosophies of consent, which makes a one-size-fits-all approach almost guaranteed to fail. GDPR demands a strict opt-in before you collect data; CCPA works on an opt-out model.
A banner trying to do both usually satisfies neither. For example, a banner that tracks by default but includes an opt-out link is a direct violation of GDPR’s pre-consent rule. On the other hand, forcing a strict opt-in on users in regions where it isn’t legally required just adds unnecessary friction.
A much safer and more effective approach is to use geo-IP detection on your backend.
- For EU Users: Serve a clear, granular opt-in interface where no non-essential trackers are active by default.
- For California Users: Present a clear notice with an easy-to-find “Do Not Sell or Share My Personal Information” link to meet opt-out requirements.
This ensures you’re applying the right legal standard for the right user, minimising both compliance risk and business disruption.
How Do I Handle A Right To Be Forgotten Request?
Handling a “right to be forgotten” request is far more than just flagging an account as ‘deleted’ in a database. It’s a complex distributed systems problem. True erasure means you have to permanently remove a user’s personal data from every single corner of your infrastructure—and be able to prove you did it.
The entire process must be automated, auditable, and comprehensive. Once a request is validated, it must trigger a workflow that spreads across your entire tech stack.
An erasure request isn’t a single database query; it’s a cascade of deletion commands that must be executed across every microservice, database, cache, log file, and third-party vendor integration. The entire process must be logged to provide an audit trail proving the data is gone.
If you miss even one downstream system—like a marketing automation tool or an analytics warehouse—it’s a compliance failure. Your architecture has to be designed from the ground up to trace and purge data by user ID, everywhere it lives.
What Is The Biggest Engineering Mistake With Opt-In and Opt-Out?
The single most critical mistake engineers make is treating consent like a local, frontend-only problem. This is how you end up with ‘consent silos’—a severe architectural flaw. One part of your system, like the website, might honour a user’s opt-out, but another part, like your mobile app or a backend data pipeline, is completely unaware and continues processing their data illegally.
This happens when consent choices are stored locally within each application instead of being managed by a single, authoritative service. The user’s preference gets trapped in one part of the system, making your compliance fragmented and unreliable.
The only way to avoid this is to treat consent as a distributed systems challenge from day one. A user’s choice to opt-in or opt-out is a global state that must be respected universally across your entire architecture. This requires a centralised consent service that acts as the single source of truth, forcing every service to ask for permission before it acts on user data.
At Devisia, we believe that privacy is an architectural choice, not just a feature. We build reliable, maintainable software systems that bake in compliance and trust from day one. If you’re ready to build a digital product on a foundation of engineering excellence, explore how we can help at https://www.devisia.pro.