
A lot of fleet programmes still run on spreadsheets, phone calls, and a handful of disconnected vendor dashboards. Operations feels the pain first. Fuel spend drifts upward. Incident reviews arrive late. Dispatchers work around bad route plans by memory. Compliance teams chase documents after the fact instead of shaping the process upstream.
From a systems perspective, that isn’t a tooling problem alone. It’s a control problem. The organisation lacks a reliable way to turn vehicle data, driver activity, maintenance signals, and policy rules into repeatable decisions.
A fleet management program is best treated as an operating system for transport operations, not as a single application. It combines in-vehicle hardware, telematics feeds, workflow software, reporting layers, security controls, and the human processes around them. If any one layer is weak, the whole programme becomes noisy, expensive, and hard to trust.
That’s one reason the category keeps expanding. The U.S. fleet management market was valued at $19.47 billion in 2020 and is projected to reach $52.5 billion by 2030, with a 10.6% CAGR, reflecting broader adoption of fleet software and telematics according to IntelliShift fleet management statistics.
For CTOs and operations leaders, the important question isn’t whether software belongs in fleet operations. It already does. The question is whether the underlying programme is designed to scale safely, integrate cleanly, and survive real-world complexity.
That matters even more in sectors where mobility data, route logic, and operational intelligence are becoming strategic assets. Work in smart mobility systems and connected transport products keeps reinforcing the same lesson. The durable advantage rarely comes from a glossy dashboard. It comes from architecture, governance, and disciplined rollout.
Introduction Beyond Dots on a Map
A map full of moving vehicle icons looks impressive in a demo. In production, it’s one small part of the job.
A real fleet management program has to answer harder questions. Which vehicles are underused. Which routes create avoidable idling. Which drivers need coaching before an insurer or regulator forces the issue. Which maintenance tasks can wait, and which ones are turning into downtime risk. Which data can be retained, and which data creates privacy exposure.
The operational problem is coordination
Most fleet problems aren’t isolated. They compound.
A late service event affects route execution. A poor route plan increases idle time. Missing diagnostic data makes maintenance reactive. Weak identity controls expose driver data. Manual reporting breaks auditability. Teams then buy another tool for the latest pain point and create one more integration gap.
A fleet management program works when operations, compliance, and engineering all trust the same underlying data model.
That changes how you design the programme. You stop asking for a feature list and start asking system questions:
- Data capture: Which signals come from devices, mobile apps, and third parties?
- Decision logic: Where do alerts, thresholds, and exceptions live?
- Action paths: Who receives a maintenance issue, route deviation, or compliance breach?
- Governance: Which records must be retained, minimised, reviewed, or deleted?
- Resilience: What happens when a device goes offline, a feed arrives late, or an integration fails?
What a modern programme actually is
At senior level, the useful definition is simple. A fleet management program is a coordinated set of business rules, software services, hardware endpoints, and operating workflows that helps the organisation manage assets, drivers, safety, maintenance, compliance, and cost over time.
The difference matters because buying software without programme design usually produces three outcomes:
- Visibility without control: Teams can see the fleet but can’t consistently act on what they see.
- Automation without governance: Alerts fire, but no one owns the workflow or the audit trail.
- Data without context: Raw telemetry arrives, but finance, compliance, and operations still work in separate systems.
The better approach is architectural. Build for long-term value, not vendor slideware.
The Core Components of a Modern Fleet Management Program
A robust fleet management program usually settles around a small number of core capabilities. The names differ by vendor. The responsibilities don’t.
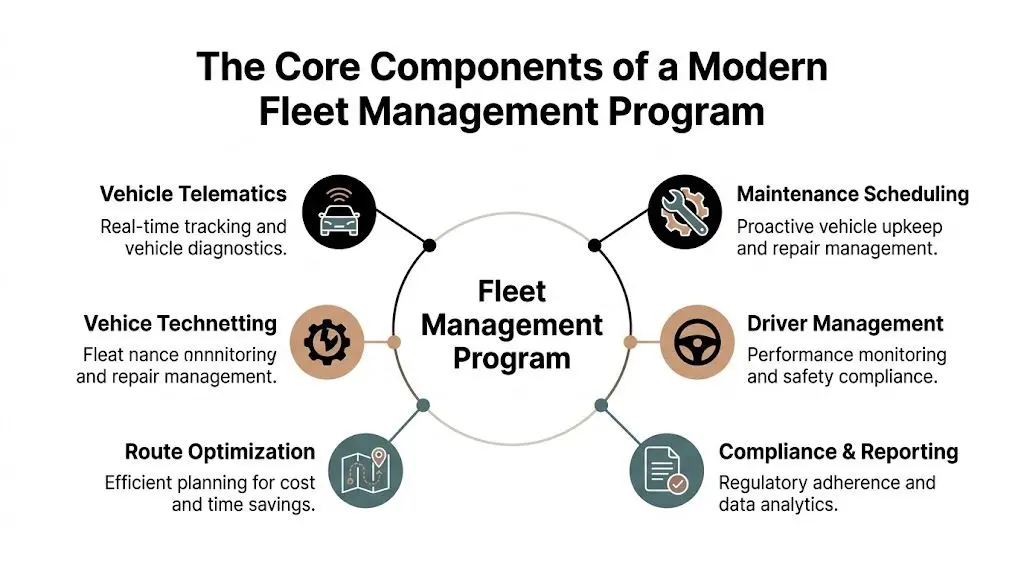
Vehicle telematics as the data layer
Telematics is the operational nervous system. Without it, most downstream analytics are guesswork.
It’s also no longer niche. 83% of surveyed U.S. fleets employ telematics tools, and 42% of fleets reported considerably fewer safety incidents after implementation, while tracking driver behaviour reduced accident claim costs by 50% according to Expert Market’s fleet management statistics.
That level of adoption tells you something important. Telematics isn’t the differentiator anymore. Using telematics data well is.
Good telematics design focuses on:
- Signal quality: GPS, odometer, fault codes, engine hours, and event timestamps have to be consistent enough for operational use.
- Device lifecycle: Provisioning, firmware handling, replacement, and support matter as much as the dashboard.
- Data contracts: If fields change without notification, everything downstream breaks. Reporting, alerts, and machine-learning features all depend on stable schemas.
What doesn’t work is treating telematics as an isolated feed that only the transport team uses.
Asset tracking that supports decisions
Location data has obvious uses, but its full value comes from context. A vehicle’s position matters when it can be tied to route adherence, geofence rules, ETA updates, unauthorised usage, and customer-facing workflow.
In practice, this means asset tracking should answer questions like:
- Is the vehicle where the plan says it should be?
- Has it entered or left a controlled zone?
- Is the asset stationary because the job is in progress, or because the process failed?
- Does the route deviation justify intervention?
That usually requires geospatial logic, event processing, and well-designed map interfaces rather than just plotting coordinates. Teams building location-heavy software often borrow patterns from geospatial information systems architecture because route and asset intelligence quickly outgrow simple map widgets.
Maintenance and health monitoring
Maintenance is where many programmes reveal whether they’re operationally mature or still reactive.
A useful system doesn’t just log completed repairs. It correlates service schedules, fault codes, inspection findings, parts usage, and downtime history. That’s how maintenance becomes a planning function instead of a constant interruption.
Three design choices matter:
| Component | What works | What fails |
|---|---|---|
| Service triggers | Combine calendar rules, mileage, engine hours, and fault events | Rely on calendar reminders alone |
| Workshop workflow | Use structured jobs, parts, statuses, and approvals | Track repairs in email threads |
| Vehicle history | Keep a single asset timeline | Split records across vendors and spreadsheets |
Routing and dispatch optimisation
Routing is where software has a direct operational effect. A route plan isn’t just a map exercise. It determines time, fuel, service quality, and often driver fatigue.
Strong routing systems account for actual constraints. Vehicle type. Load. customer time windows. urban restrictions. weather exposure. known congestion patterns. hand-off logic between dispatch and driver.
Practical rule: If dispatchers routinely override the optimiser by habit, the model is missing business context.
Route logic should be inspectable. Black-box optimisation often looks clever until teams need to explain why a route changed, why a stop was reprioritised, or why one driver carries persistent over-allocation.
Compliance and reporting
Compliance features tend to be underfunded early and overfunded late, after an audit issue or incident.
That’s backwards. In a sound fleet management program, compliance is embedded into the workflow. Hours-of-service constraints, driver vehicle inspection reporting, licensing checks, incident logs, and audit trails should be captured where the work happens.
The key is to avoid “reporting by reconstruction”. If users complete the work in one system and compliance evidence gets assembled later from screenshots, PDFs, and inboxes, the programme is fragile.
The reporting layer should produce:
- Operational evidence: who did what, when, and on which asset
- Regulatory evidence: records aligned to retention and audit needs
- Management views: exception reports, trend indicators, and unresolved risk queues
Those are different outputs from the same underlying event history. Build the history correctly and reporting becomes straightforward. Build it badly and reporting becomes a permanent clean-up project.
System Architecture for Scalable Fleet Operations
Architecture decisions show up later as operating cost, integration pain, and incident frequency. That’s why fleet systems deserve the same rigour as any other business-critical platform.
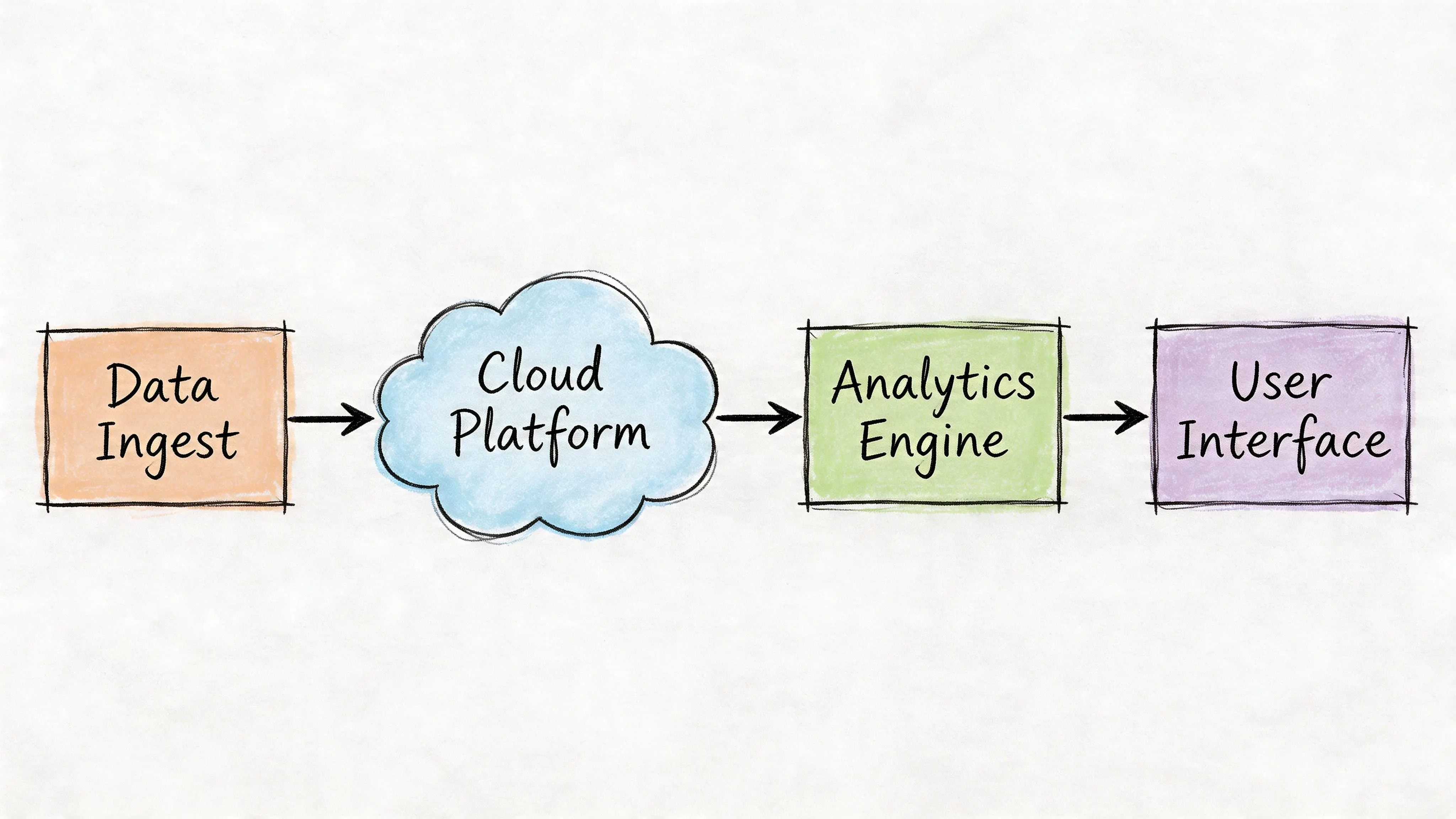
Start with data flow, not service count
Fleet platforms ingest fast, uneven, and often unreliable data. Devices send location updates, engine signals, and status events. Mobile apps add inspection reports and photos. External systems contribute fuel, HR, payroll, and ERP records. None of these sources arrive with perfect timing.
That reality makes event flow more important than ideology about monoliths or microservices.
A modular monolith is often the right starting point when the organisation needs speed, clear ownership, and fewer moving parts. It’s easier to debug, easier to deploy, and usually sufficient while workflows are still stabilising.
Microservices earn their keep later, when one or more of these become true:
- Ingestion scales differently from the rest of the system
- Routing or analytics workloads need separate runtime characteristics
- Regulated domains require tighter isolation
- Different teams can own service boundaries with discipline
Open APIs and protocol support matter early
Near real-time GPS tracking through telematics integrations and open APIs can reduce fuel costs by up to 16% through reduced idling and better routing, and scalable platforms need support for OBD-II and J1939 engine data according to ABI Research on fleet management system features.
The architectural lesson isn’t just about savings. It’s about interoperability.
If your platform can’t ingest device data cleanly, normalise it, and expose it through documented APIs, every future integration becomes custom glue. ERP links, fuel card reconciliation, maintenance vendors, payroll adjustments, and customer portals all get harder.
A practical reference pattern
A dependable fleet architecture often looks like this:
- Ingestion layer: Device gateways, mobile APIs, batch imports, and webhook endpoints
- Event backbone: Durable queues or streams for telemetry, alerts, inspections, and state changes
- Operational services: Asset registry, dispatch logic, maintenance workflow, compliance engine, user management
- Analytical store: Time-series and reporting-friendly data shaped for dashboards and trend analysis
- Experience layer: Web dashboards, driver apps, operations consoles, and external API consumers
This pattern supports one of the most valuable behaviours in fleet systems. A single event can trigger multiple controlled actions.
For example, a geofence breach can create an operations alert, update a route status, log an audit record, and open an exception review queue. The event occurs once. The system reacts in several bounded ways.
Keep the canonical event immutable. Downstream interpretations can change. Historical facts shouldn’t.
Integration strategy decides maintainability
Most fleet programmes fail at the edges, not at the centre.
The core product may look fine, but integrations become brittle because teams skip versioning, build point-to-point dependencies, or overload one vendor API for everything. Over time, small failures accumulate. Duplicated identities. mismatched asset IDs. missing fuel records. inconsistent timestamps. orphaned maintenance tasks.
A better pattern uses:
- Canonical identifiers for vehicles, drivers, depots, and jobs
- Adapter layers around external providers
- Explicit retries and dead-letter handling
- Schema versioning for message and API evolution
- Observability around delayed, dropped, or malformed events
That’s less glamorous than front-end dashboards, but it’s where a scalable fleet management program becomes cheaper to operate and safer to extend.
Defining Success with KPIs and ROI Analysis
Most fleet dashboards look busy and answer very little.
They show map activity, trip counts, and long lists of events. They rarely help leadership decide whether the programme is reducing cost, lowering risk, or improving service quality in a sustained way. A fleet management program needs measurement that supports action, not theatre.
Vanity metrics create false confidence
A common mistake is overvaluing metrics because they’re easy to collect.
Total trips, total alerts, average speed, and raw log-in counts might be operationally interesting. On their own, they don’t tell you whether the system is working. In some cases they mask deterioration. More alerts can mean better detection, worse behaviour, or broken thresholds. You need context.
Useful KPI design starts with business outcomes and works backwards. If finance cares about cost control, then idle time, route adherence, maintenance timing, and vehicle utilisation should connect to cost categories the finance team already recognises.
Idling is a good example. Fuel management modules that track cost per mile and detect idling matter because idling can cause up to 20% of fuel waste, and digitising preventive maintenance can reduce repair expenses by 25% through telematics fault code alerts according to Simply Fleet’s fleet management requirements guide.
Use leading and lagging indicators together
Lagging indicators tell you what happened. Leading indicators show where the next problem is forming.
A practical dashboard usually needs both.
| KPI type | Example | Why it matters |
|---|---|---|
| Lagging | Total fuel spend by business unit | Good for financial review, poor for daily intervention |
| Leading | Vehicles with repeated high-idle sessions this week | Points to action before the monthly bill lands |
| Lagging | Breakdown-related downtime | Useful for trend analysis and asset decisions |
| Leading | Fault code exceptions awaiting review | Shows whether teams are acting early enough |
| Lagging | Completed compliance incidents | Good for audit and retrospective review |
| Leading | Overdue inspection submissions | Highlights process risk before escalation |
Build dashboards for decisions, not observation
Dashboards should reflect who needs to act.
Operations managers need exception queues, route deviations, and depot-level utilisation. Maintenance leads need fault alerts, overdue services, and repeat repair patterns. Executives need trend views tied to margin, risk, and asset planning.
That’s why one large dashboard rarely works well. Different users need different slices of the same governed data.
Use a few design rules:
- Show thresholds clearly: A metric without an expected range isn’t useful.
- Display ownership: Each exception should have a responsible team or role.
- Support drill-down: Summary views should link to the asset, trip, driver, or job record.
- Separate noise from priority: Not every event deserves equal visual weight.
If a KPI doesn’t change someone’s behaviour, it’s reporting overhead.
A mature ROI discussion also avoids the trap of promising a single universal payback number. Fleet operations differ too much for that. The practical way to evaluate ROI is to connect measurable operational changes to cost categories, risk reduction, and avoided disruption over time. That yields a more credible business case and a more honest roadmap.
Leveraging AI and Automation for Predictive Fleet Management
Many organisations already have data from telematics, inspections, and maintenance logs. What they don’t have is a safe path from data collection to predictive action.
That gap matters more than the model choice.
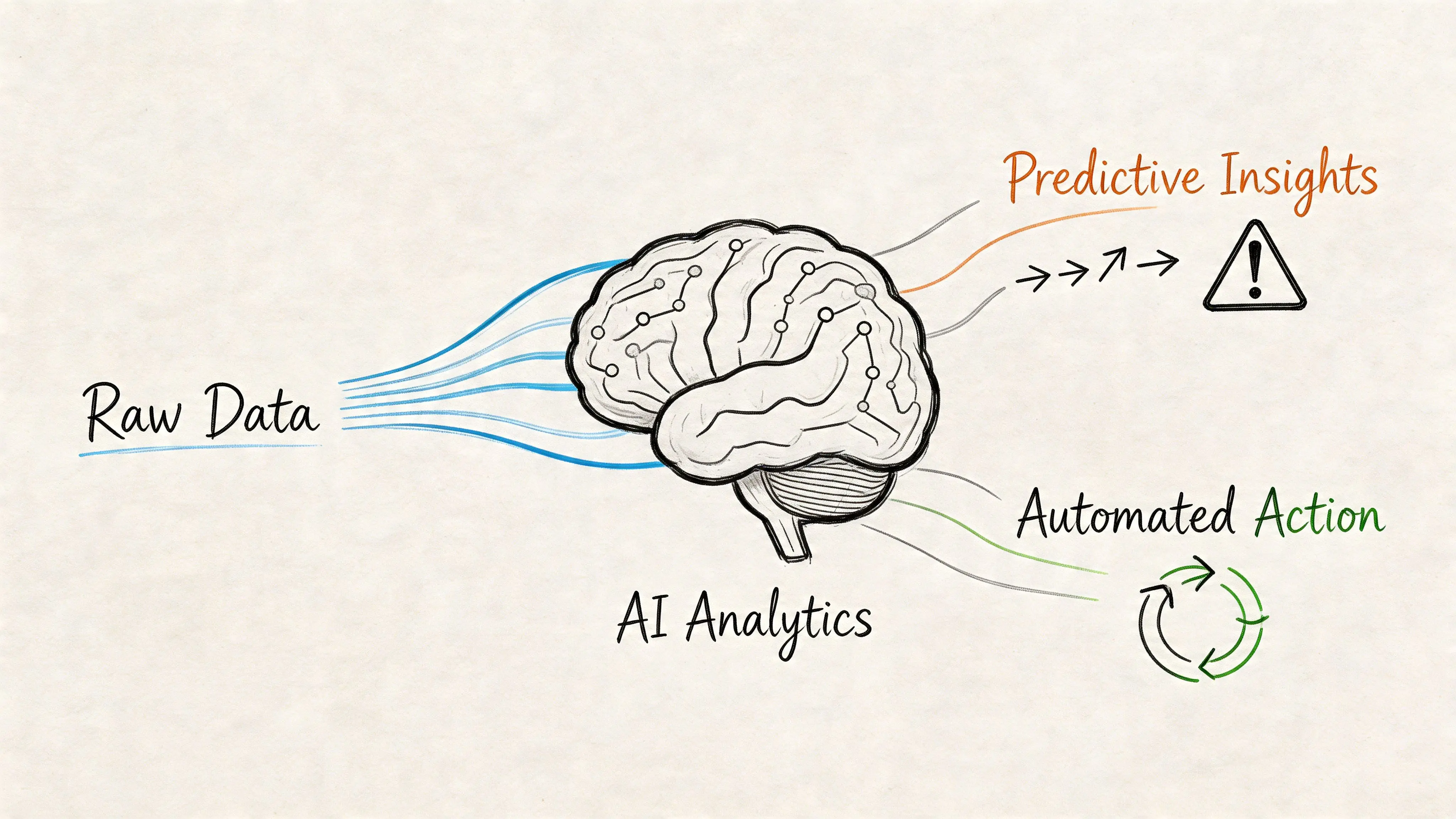
The wrong question is whether to add AI
The better question is where AI can improve a real workflow without creating opaque decisions, fragile dependencies, or governance problems.
That’s especially important in fleets with legacy systems. Guidance on this transition is still thin. The practical gap is integrating predictive capabilities into existing operations without replacing everything at once. Vehicles on preventive maintenance schedules cost 25% to 35% less in annual repairs, yet many teams still lack a staged migration path for legacy environments, as noted by Intangles on the shift from visibility to foresight.
The lesson is straightforward. Don’t begin with “AI platform transformation”. Begin with one bounded, high-value decision loop.
Good early use cases
Predictive maintenance is usually the strongest starting point. The inputs already exist in many fleets. Fault codes, service history, inspection notes, usage patterns, and downtime records can support prioritisation without handing full control to a model.
A sensible first version might do this:
- Ingest signals: Pull fault events, service intervals, and inspection anomalies into one review queue
- Rank risk: Score assets for human review based on pattern combinations
- Trigger action: Open maintenance recommendations with evidence attached
- Capture outcomes: Record whether technicians confirmed, dismissed, or rescheduled the issue
That keeps the model inside a governed workflow.
Driver behaviour analysis is another useful area, but it needs restraint. Scoring drivers without context creates resentment and poor decisions. Road conditions, vehicle type, route mix, and job pressure all affect event patterns. Use AI to support coaching and review. Don’t let it become an unchallengeable personnel signal.
Route optimisation is attractive too, but dynamic rerouting can create operational instability if the optimiser ignores local business reality. Good systems preserve human override, explain route changes, and limit automated adjustments to agreed constraints.
LLMs help best at the workflow edge
Large language models are often more useful around fleet operations than at the centre of optimisation itself.
For example, an LLM can:
- Summarise driver vehicle inspection reports for supervisors
- Classify free-text maintenance notes
- Draft exception narratives from structured event histories
- Help operators search across policies, inspections, and incident records
- Support fraud review workflows around OCR’d receipts and supporting evidence
Those are high-friction tasks with human review already built in.
For a useful technical overview of these patterns in connected systems, work on AI and IoT integration in operational products is a better reference point than generic AI marketing.
A short visual example helps here:
A safer adoption pattern
The most reliable path is incremental:
- Stabilise source data
- Choose one decision workflow
- Keep a human in the approval loop
- Log prompts, outputs, and actions for audit
- Measure whether the new workflow outperforms the old one
- Expand only after exception handling is trustworthy
AI should narrow uncertainty in an existing process. It shouldn’t become a substitute for process design.
That approach is slower than the typical “deploy AI everywhere” pitch. It’s also much more likely to survive first contact with real operations.
Embedding Security and Governance into Your Program
Fleet systems handle more sensitive data than many teams initially realise. Vehicle location can reveal employee patterns. Driver records can become HR data. Inspection photos may contain personal information. Integration with payroll, fuel cards, and customer schedules expands the exposure surface again.
That means security and governance can’t sit on top of the programme as later add-ons. They have to be built into the architecture and operating model.
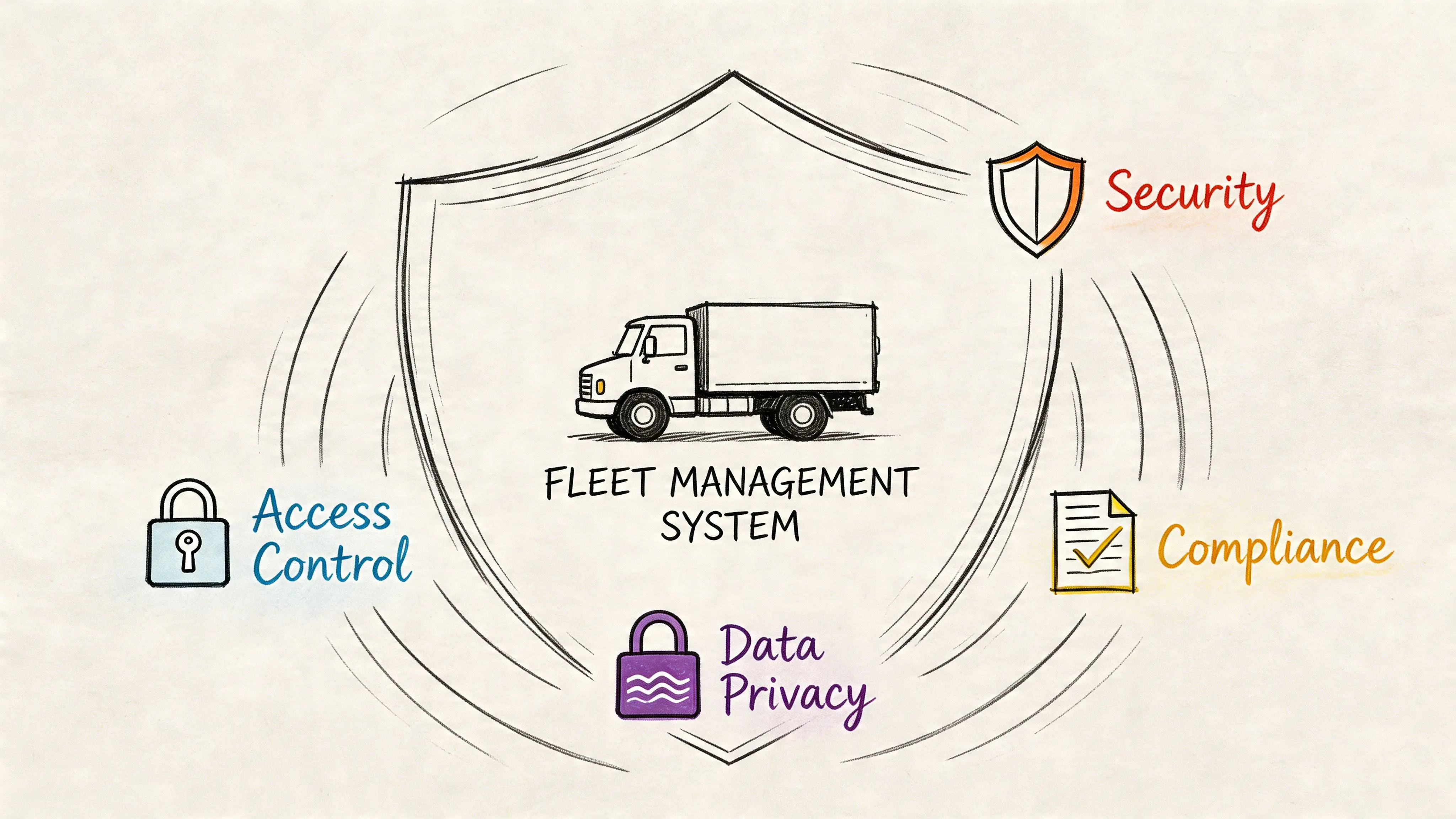
Privacy by design in fleet operations
The right starting point is data minimisation.
Collect what the programme needs for routing, safety, maintenance, and compliance. Don’t collect everything just because the device can emit it. A common design failure is storing high-granularity location history for too long without a clear purpose, retention policy, or access model.
For GDPR-sensitive environments, teams should define:
- Purpose boundaries: Why each data category exists
- Retention rules: How long data remains available and why
- Access conditions: Which roles can view personal, route, or diagnostic data
- Subject rights handling: How requests for access, correction, or deletion are processed where applicable
Privacy by design isn’t paperwork. It affects schema design, audit logging, interface permissions, and retention automation.
Threats are operational, not theoretical
Fleet platforms face a mixed threat profile. Some attacks target the software platform. Others target the physical and network edge.
Examples include:
- Unauthorised dashboard access
- Compromised mobile devices
- Tampered telemetry inputs
- GPS spoofing or jamming
- Over-privileged internal accounts
- Third-party integration leakage
The practical response starts with basics done well:
| Control area | What to implement |
|---|---|
| Identity | Strong authentication, role-based access control, least privilege |
| Data protection | Encryption in transit and at rest, key management, audit logs |
| Edge trust | Secure device provisioning, hardware identity, firmware governance |
| Application security | Input validation, secret management, dependency hygiene |
| Resilience | Backups, failover planning, incident response runbooks |
Governance for regulated environments
For teams operating in Europe or serving regulated sectors, governance should be designed with frameworks such as GDPR, NIS2, and DORA in mind.
The practical implications differ by organisation, but several patterns are broadly useful:
- Traceability: You need a clear chain from event to user action to retained record.
- Operational resilience: Core workflows should degrade safely when a provider, API, or device class fails.
- Third-party oversight: Vendor integrations need risk review, contractual clarity, and technical boundaries.
- Incident readiness: Teams should know how to contain, investigate, and communicate a telemetry or access incident.
Security reviews should include the fleet edge, the cloud platform, and the people operating the workflows. Leaving out any one of those gives a false sense of coverage.
Design choices that reduce long-term risk
Some choices pay for themselves repeatedly.
Use role-based views so dispatchers, technicians, compliance leads, and executives don’t all see the same data by default. Separate raw telemetry from user-facing operational views. Log administrative actions. Make retention rules executable rather than policy-only. Treat integrations as trust boundaries, not as harmless convenience features.
Naive implementations often fail because they centralise data but decentralise accountability. Everyone can see everything. No one owns retention. Exceptions can be edited without trace. Access rights accumulate and are never removed.
That isn’t just poor hygiene. In the wrong moment, it becomes a legal, operational, and reputational problem.
A Pragmatic Roadmap for Implementation
The highest-risk way to launch a fleet management program is the one many organisations still choose. Buy a large platform, roll it out everywhere, force every team into a new process, and hope reporting improves within a quarter.
It usually doesn’t.
A stronger approach is phased, evidence-led, and deliberately boring. The goal is early control, not early complexity.
Phase one through discovery and validation
Start by mapping the current operating model as it functions, not as policy says it functions.
Talk to dispatch, maintenance, compliance, finance, and drivers. Review where data originates, where decisions are made, and where work leaves the system and returns later through email, paper, or spreadsheets. Those breaks show you where the programme is weak.
Capture a small set of decisions up front:
- Primary outcomes: cost control, safety, maintenance, compliance, service quality
- In-scope assets: vehicle classes, depots, business units
- Critical integrations: telematics provider, ERP, fuel cards, HR, maintenance vendors
- Constraint list: budget, contractual obligations, device limitations, data residency, privacy rules
The output should be a prioritised problem statement, not a giant requirements catalogue.
Phase two through a controlled pilot
A pilot should be narrow enough to learn quickly and broad enough to expose real complexity.
Pick a defined subset of vehicles, users, and workflows. Instrument the pilot properly. That includes support processes, data quality checks, and issue logging, not just UI testing.
Good pilot questions include:
- Are incoming signals reliable enough for operational use?
- Which alerts create action, and which create noise?
- Do drivers and dispatchers trust the workflow?
- Are maintenance and compliance records complete without manual reconstruction?
- Which integration assumptions failed first?
A pilot isn’t just for proving technology. It’s for exposing hidden process debt.
Phase three through phased rollout
Roll out by operational boundary, not by organisational enthusiasm.
That might mean one depot at a time, one vehicle type at a time, or one workflow at a time. Keep old and new processes visible during transition, but avoid indefinite dual running. If parallel systems persist too long, the programme never stabilises.
A practical rollout checklist:
- Confirm data mapping for vehicles, users, and external systems
- Train by role rather than sending generic platform guides
- Define support ownership for hardware, software, and process issues
- Monitor exceptions daily during early rollout waves
- Review permissions before each new team goes live
- Retire obsolete artefacts such as duplicate spreadsheets and manual logs
Phase four through continuous improvement
Once the system is live, the true work begins.
Fleet operations change. Routes shift. depots merge. regulations evolve. providers change APIs. hardware ages. If the programme can’t absorb those changes, it will decay.
Use a regular review cycle with a small cross-functional group. Look at data quality, exception trends, user workarounds, and unresolved integration pain. Then make measured changes.
The most durable fleet programmes improve through many small corrections, not periodic reinventions.
This is also the stage where AI and deeper automation become safer to introduce. By then, your core workflows, audit trails, and ownership model should already be stable enough to support them.
Conclusion Building a Future-Proof Fleet Program
A strong fleet management program isn’t a dashboard purchase. It’s a long-lived operational system.
The programmes that hold up over time share a few traits. They treat telematics as one data source within a broader architecture. They design workflows around decisions and accountability. They measure outcomes with KPIs that support action. They introduce AI carefully, inside governed processes. And they treat privacy, security, and resilience as design requirements from day one.
That’s the difference between software that looks modern and a programme that improves operations.
For CTOs, product leaders, and operations teams, the practical aim is simple. Build a system that people can trust when data is messy, integrations fail, audits happen, and the business changes. If the architecture can handle those conditions, the fleet management program becomes an asset rather than another maintenance burden.
If you’re planning a fleet platform, operational dashboard, or AI-enabled workflow and want a technical partner that prioritises maintainability, privacy, and pragmatic delivery, Devisia can help you turn the idea into reliable software.