
The usual smart mobility conversation starts in the boardroom. Someone has seen the market forecasts, a city tender, or a competitor launching a new mobility service. The opportunity looks obvious. The engineering reality doesn’t.
Your team then opens the hood and finds a different picture. Vehicle telematics arrives in inconsistent formats. Public transport APIs change without notice. Parking, charging, routing, identity, and payments all live in separate systems. Legal asks about GDPR. Security asks about NIS2 exposure. Product asks for AI features. Operations asks for uptime. Everyone is right, and none of these concerns fit neatly into a slide about innovation.
That is the entry point into the smart mobility world. It isn’t a single market or a single platform problem. It’s a systems integration problem with strict operational consequences.
For a CTO, the core decision isn’t whether mobility is interesting. It’s whether the organisation can build something that remains reliable when data is late, third parties drift, field devices fail, and regulators ask hard questions. The companies that do well here usually avoid two mistakes. They don’t treat mobility as a polished front-end problem, and they don’t bolt privacy and governance on after launch.
Entering the Smart Mobility World Beyond the Hype
A typical first move is to chase the most visible use case. A MaaS app. A fleet dashboard. A charging integration. A city operations console. Each can be viable. Each can also become a costly integration trap if the architecture assumes clean data, stable suppliers, or uniform standards.
That’s why the first useful question isn’t “What should we build?” It’s “Which part of the stack can we control well enough to operate safely?”
The opportunity is real, but the terrain is uneven
The commercial pull is strong. North America held a 35.1% share of the global smart mobility market in 2025, from a market valued at USD 51.77 billion, driven by advanced infrastructure and supportive regulation, according to Fortune Business Insights’ smart mobility market analysis.
That matters less as a headline than as a signal. Mature regions tend to reward vendors that can handle integrations, observability, and governance. The product surface may look consumer-friendly. The underlying stack is enterprise infrastructure.
What catches teams out
Most failed mobility products don’t fail because routing is hard or maps are unavailable. They fail because of a stack of ordinary mistakes:
- Over-scoped first releases that try to unify too many operators, data sources, or payment rails at once.
- Naive event models where location, booking, ticketing, and billing events have no stable contract.
- Weak operational design with poor audit trails, limited replay capability, and no isolation between critical and non-critical services.
- Compliance delayed until procurement when design choices have already made data minimisation difficult.
Practical rule: if your first architecture diagram has more partner systems than your team can simulate locally, your MVP is probably too broad.
The smart mobility world rewards restraint. Start with one operational problem, one class of users, and one hard metric that matters to the operator. Then build the integration and governance model around that.
Mapping the Smart Mobility Ecosystem
Smart mobility isn’t one market. It’s a layered ecosystem where vehicles, infrastructure, operators, software vendors, and public authorities depend on one another, often with conflicting incentives.
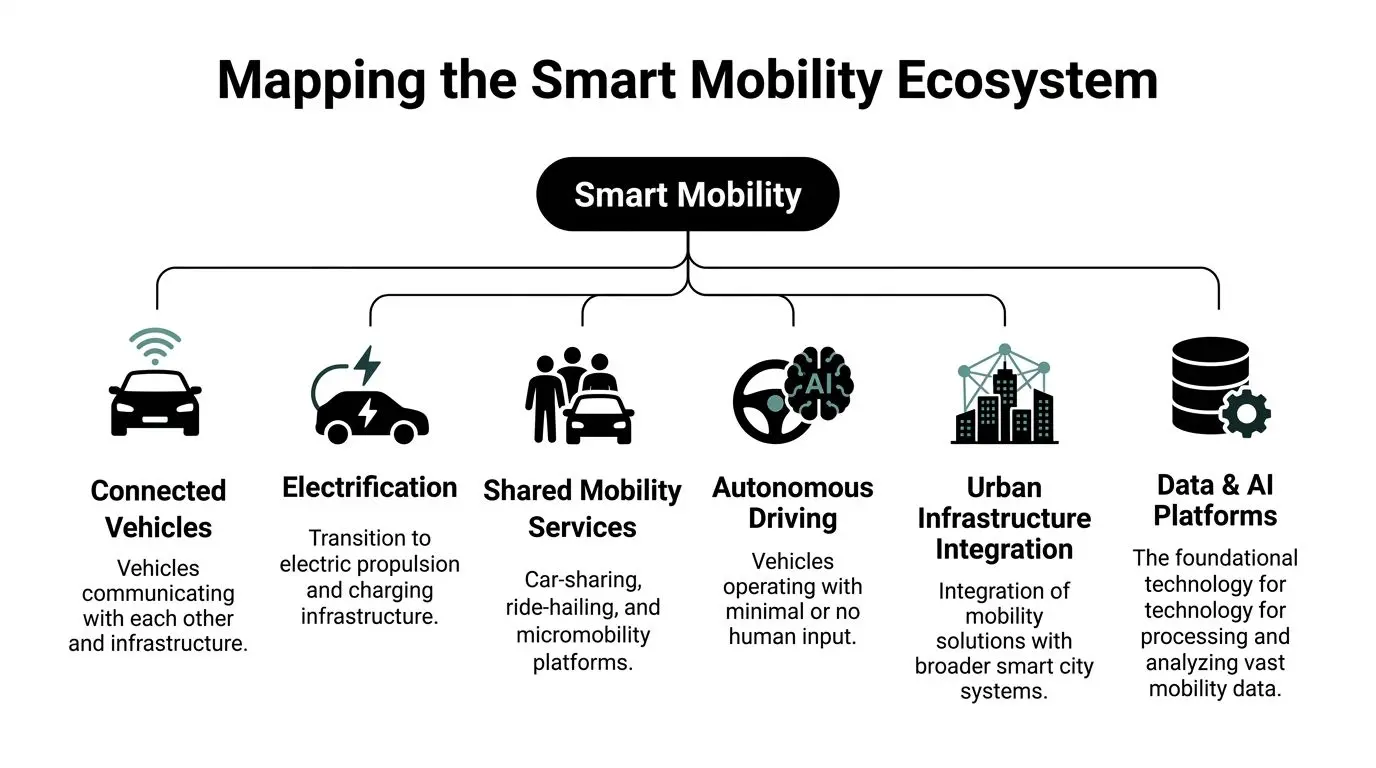
The mobility modes that shape product scope
Some CTOs enter through public transport integration. Others start with ride-hailing, fleet management, micro-mobility, or logistics orchestration. These aren’t just customer segments. They produce different architectural demands.
A MaaS platform needs identity, booking, payment reconciliation, and policy logic across operators. A micro-mobility platform puts more pressure on real-time asset state, geofencing, and field operations. Logistics systems care more about route optimisation, telemetry ingestion, proof-of-delivery, and driver workflows than consumer trip planning.
The mistake is assuming these can share the same domain model from day one. They usually can’t.
The stakeholders who control your constraints
A good map of the smart mobility world starts with power, not technology.
| Stakeholder | What they usually control | What they often constrain |
|---|---|---|
| Cities and public authorities | Data access, permits, policy, procurement | Retention rules, service obligations, reporting |
| Operators | Vehicles, schedules, service quality, incident response | API access, data quality, operational variation |
| OEMs and hardware vendors | Device capabilities, telematics, firmware | Proprietary protocols, slow release cycles |
| Platform providers | Cloud, analytics, AI tooling, identity | Cost model, portability, lock-in risk |
| End users | Demand patterns, support volume, consent decisions | Fragmented journeys, unreliable inputs |
A city can open data and still require strict controls around location histories. An operator may want route optimisation while resisting changes to dispatch workflows. Hardware suppliers may provide data, but only through proprietary payloads that don’t fit your event model.
The foundational stack under the product
At the bottom of most mobility systems are the same ingredients:
- Connectivity such as telematics feeds, mobile apps, roadside systems, and vehicle links
- Cloud infrastructure for ingestion, storage, identity, analytics, and orchestration
- Operational systems like ticketing, fleet tools, payment gateways, maintenance platforms, and support desks
- Decision layers for routing, optimisation, ETA logic, anomaly detection, and policy enforcement
The stack only works if the contracts between these layers are explicit. “Integration” is too vague. You need to know who owns truth for a vehicle’s state, a trip’s lifecycle, a user’s entitlement, and a payment’s final status.
Why region matters
Regional maturity changes what’s feasible. In North America, the market’s scale and infrastructure maturity have helped establish a strong environment for connected vehicle software and operational platforms, as noted in the Fortune Business Insights analysis cited earlier. In practical terms, that means more benchmark patterns for dashboards, integrations, and enterprise-grade mobility systems.
In smart mobility, the ecosystem is the product. Your interface is only as reliable as the contracts beneath it.
A useful entry strategy starts by choosing a narrow place in this ecosystem where your team can own data quality, supportability, and compliance boundaries.
Key Trends and Their Engineering Implications
Mobility trends matter only when they change architecture decisions. Most do.

Electrification changes integration, not just propulsion
Electrification adds software complexity long before it adds strategic advantage. Teams usually discover this when they try to unify charger availability, session state, tariffs, user identity, and billing across multiple providers.
The hard part isn’t showing charging points on a map. It’s keeping session state accurate when provider APIs differ in latency, error handling, and event semantics.
Three design choices matter early:
- Normalise external charger events into your own canonical model instead of leaking provider-specific states into product logic.
- Separate operational truth from customer display so intermittent provider delays don’t break user journeys.
- Design billing as a reconciliation workflow, not a synchronous transaction chain.
Connected and autonomous systems produce a data firehose
In the US, AI and IoT integrated with cloud platforms are already delivering 15 to 25% reductions in urban congestion through real-time vehicle-to-infrastructure communication, while AI processing of IoT sensor data is cutting autonomous vehicle downtime by 30%, according to IMARC Group’s smart mobility market report.
That’s the business outcome. The engineering implication is straightforward. Once telemetry and infrastructure data start arriving continuously, your architecture has to handle high-volume ingestion, filtering, prioritisation, and secure event exchange without turning every downstream service into a bottleneck.
A common anti-pattern is sending all raw telemetry to the central platform and hoping analytics will sort it out later. That creates storage waste, noisy alerts, and weak incident response.
For teams working on vehicle intelligence, ADAS integration, or roadside coordination, safety and software architecture meet. The interface between perception, decision support, and user-facing systems needs disciplined contracts. The design concerns in advanced driver assistance system engineering are closely related to the broader mobility stack, especially around latency, fallback behaviour, and traceability.
MaaS fails when orchestration is treated as aggregation
Many MaaS products start as simple aggregators. They combine routes, fares, and availability. That’s useful, but it isn’t enough. The moment users expect one journey across multiple providers, the platform becomes an orchestrator.
That introduces harder problems:
- one identity may need to map to several operator systems
- one disruption may require rebooking, refund logic, and customer support context
- one itinerary may have different policy constraints depending on operator, city, or entitlement rules
In other words, MaaS isn’t mainly a UI problem. It’s a workflow reliability problem.
Micro-mobility depends on operational discipline
Scooters and bikes look lightweight from a product point of view. They aren’t lightweight operationally. The platform has to know where assets are, whether they’re rideable, whether they’re in a permitted zone, and whether field teams can service them quickly.
What works:
- event-driven updates for asset state
- explicit geofence policy engines
- support tooling that exposes operational context, not just customer status
- replayable audit logs for disputes and enforcement
What doesn’t work:
- pushing all decisions into a mobile app
- hiding state conflicts behind eventual consistency without operator tooling
- assuming pricing logic can be updated without testing knock-on effects in support, billing, and compliance
If a trend creates more states, more counterparties, and more exceptions, it’s an architecture problem before it’s a market opportunity.
The AI and Data Architecture for Mobility Platforms
Mobility platforms rarely fail because they lack data. They fail because they ingest data without deciding what must be trusted, what can be inferred, and what must be discarded.
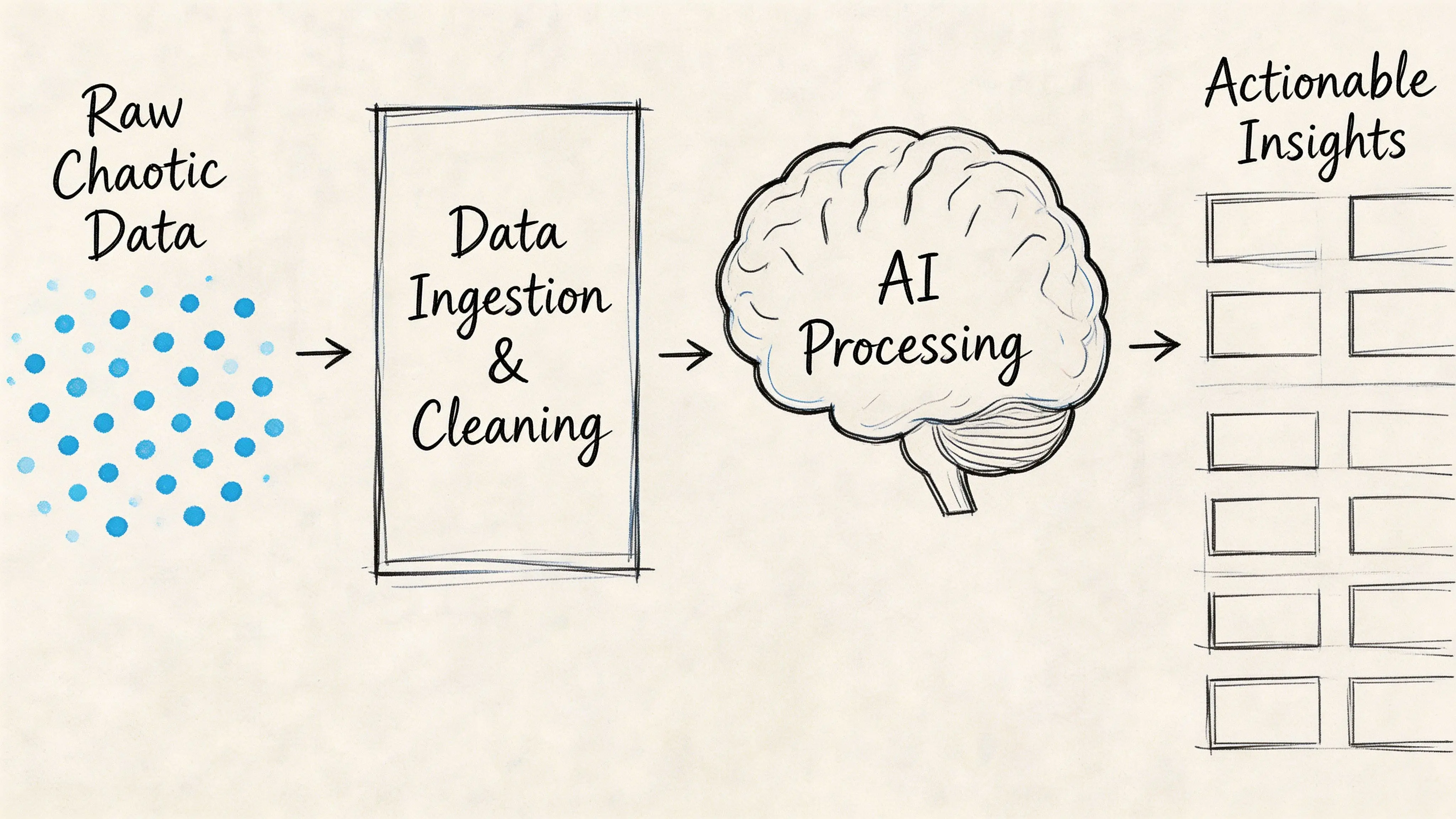
Start with an ingestion model that assumes noise
Vehicle telemetry, app events, transit feeds, support tickets, and partner APIs all arrive with different timing and quality characteristics. A practical architecture uses a streaming backbone such as Kafka or Redpanda for event ingestion, then applies validation and enrichment before data reaches product logic.
The key is to classify streams by operational importance.
| Data class | Typical examples | Design priority |
|---|---|---|
| Safety or operationally critical | incident alerts, vehicle status, route disruptions | low latency, replay, strict access control |
| Commercially important | bookings, fares, subscriptions, charging sessions | consistency, auditability, reconciliation |
| Analytical | demand patterns, service quality trends, heatmaps | cost efficiency, retention policy, governed access |
When teams skip this classification, everything becomes “real-time” and costs rise without improving outcomes.
Pick storage patterns by workflow, not fashion
A mobility stack usually needs more than one storage model. A data lake is useful for raw and historical event retention, model training, and replay. A warehouse helps with reporting, finance, and product analytics. A transactional store handles bookings, identities, and current operational state.
Don’t force one system to do all three jobs.
In Italy, 3G and 4G networks remain the backbone of smart mobility and are considered cost-effective for 95% of current V2X use cases. AI-powered traffic systems using these mature networks have improved traffic flow efficiency by 20 to 30% in congested cities, according to Coherent Market Insights on the smart mobility market. That’s a useful reminder that dependable mobility systems often depend more on reliable data contracts and practical network assumptions than on the newest connectivity layer.
Apply AI where the workflow is already clear
The best AI use cases in mobility usually sit on top of a well-understood operational process.
Some examples:
- Predictive maintenance built from telematics and service history
- Demand forecasting for fleet allocation or staffing
- Routing optimisation that balances ETA, service quality, and operational constraints
- Support automation for refunds, disruptions, and itinerary changes
The riskiest pattern is adding an LLM before clarifying the workflow it supports. If support teams can’t explain their escalation logic, an agent won’t fix it. It will just make the ambiguity faster.
Teams exploring the intersection of connected devices and machine intelligence can borrow useful implementation patterns from AI and IoT system design, especially around event handling, model placement, and operational monitoring.
LLMs and agent workflows need guardrails
LLMs can help with itinerary support, operator tooling, internal knowledge retrieval, and anomaly triage. They should not become an unbounded decision-maker in high-impact workflows.
A workable pattern looks like this:
- Constrain the task to a narrow operational domain, such as refund eligibility or disruption messaging.
- Ground responses in trusted internal data, not open-ended generation.
- Use tool calling for deterministic actions like booking lookups or policy checks.
- Keep a human in the loop where exceptions, compliance, or financial impact are involved.
- Log prompts, tools, outputs, and overrides for audit and tuning.
That’s how you get practical automation without creating a governance problem.
Here’s a useful visual explanation of how AI workflows mature from raw input to operational insight:
Privacy and resilience are architectural decisions
Location data, movement patterns, payment context, and accessibility needs are sensitive by nature. Privacy-by-design in mobility means making structural choices early:
- Minimise personal data in event payloads
- Use pseudonymisation where full identity isn’t operationally required
- Partition access by role and workflow
- Set retention rules per data class, not per database
- Audit administrative access as carefully as customer-facing activity
NIS2 and DORA pressure organisations to prove resilience, accountability, and supply-chain awareness. In mobility, that means clear dependency mapping, incident response playbooks, tested fallback modes, and observable third-party integrations.
Privacy isn’t a feature you add to a route planner. It’s a property of the data model, the access model, and the retention model.
Navigating Business Opportunities and Implementation Risks
The best mobility opportunities are usually boring on first inspection. They sit where operations are expensive, fragmented, or opaque. That’s where software can create durable value.
Where new entrants can win
The strongest entry points often come from fixing one stubborn operational problem:
- Operator dashboards that unify fleet, service, and incident status
- Middleware platforms that standardise messy third-party feeds
- Workflow tools for support, dispatch, compliance, or maintenance teams
- Accessibility-focused services that existing platforms overlook
- Decision support layers for routing, charging, or disruption handling
The macro signal is encouraging. Asia Pacific is projected to be the fastest-growing smart mobility market, with a CAGR of 23.60% through 2035, fuelled by urbanisation, smart city investment, and demand for scalable AI and IoT-enabled platforms, according to Spherical Insights on the global smart mobility market. For CTOs, the useful conclusion isn’t “expand everywhere”. It’s that software layers which scale across operators and cities will matter more than narrow one-off builds.
Four risks that derail otherwise good products
Technical debt from premature consolidation
Mobility products often begin with a monolith that mixes booking logic, pricing, partner adapters, support workflows, and reporting. That can be acceptable at the start. It becomes dangerous when every new operator requires editing core logic.
A safer pattern is modular decomposition around business capabilities, not technology teams.
Vendor lock-in hidden inside convenience
Managed AI, mapping, telematics, and messaging services can speed delivery. They also create brittle dependencies if your data model and workflow semantics are coupled to one provider.
Keep your internal contracts stable. Swap providers behind adapters where possible.
Compliance and security blind spots
Mobility systems often touch location history, user identity, financial events, and public infrastructure. The cost of weak governance is high. Not just legally, but operationally.
Here, supplier review matters. Third-party APIs, cloud tools, and AI services all expand your exposure. A disciplined approach to third-party risk management is part of the platform architecture, not just procurement hygiene.
Scalability failures under uneven load
Mobility demand is bursty. Weather, strikes, events, school runs, and service disruptions produce concentrated spikes. Systems that perform well in average conditions can collapse when one dependency slows down and retries multiply.
Practical mitigations
Build for degraded operation. In mobility, partial service is often better than elegant failure.
A pragmatic mitigation plan usually includes:
- Incremental delivery with a narrow MVP and explicit non-goals
- Contract testing for external integrations and event schemas
- Queue-based buffering around unstable dependencies
- Observability with traces, business metrics, and replay capability
- Fallback modes for maps, routing, notifications, and payment flows
- Security reviews embedded in design and release cycles
The commercial upside in the smart mobility world is real. So is the implementation risk. The winners usually aren’t the teams with the boldest deck. They’re the teams that remove avoidable failure modes before scale exposes them.
How Devisia Builds Maintainable Smart Mobility Systems
A maintainable mobility product starts with a narrow promise. Not a broad platform claim.
The right first release usually solves one operational bottleneck for one user group with a delivery model the team can support. That could mean a real-time operations dashboard for a fleet team, a booking and support workflow for an accessibility service, or an orchestration layer between operators and a customer-facing app.
Start with the workflow, not the feature list
The most reliable delivery pattern begins with a focused discovery phase. That work should identify:
- the event sources you must trust
- the workflows that break most often
- the decisions that require deterministic logic
- the places where AI can help without creating uncontrolled risk
- the retention and access rules that must exist before launch
This usually narrows the MVP dramatically. That’s a good result.
A mobility team may begin by asking for route planning, support automation, city reporting, dynamic pricing, and partner reconciliation in one release. After proper discovery, the first build often becomes a smaller operational core with cleaner contracts.
A reference architecture that stays operable
For most smart mobility systems, the maintainable shape looks something like this:
| Layer | Purpose | Design principle |
|---|---|---|
| Integration layer | partner APIs, telematics, public feeds, payments | isolate variability behind adapters |
| Event backbone | state changes, alerts, workflow triggers | replayable, observable, schema-governed |
| Domain services | trips, bookings, fleet, billing, support | bounded contexts, explicit ownership |
| Decision layer | routing, anomaly detection, eligibility, AI workflows | deterministic where impact is high |
| Control plane | audit, permissions, policy, monitoring | central governance, local execution |
That structure isn’t about chasing microservices. It’s about making change safer. When a partner breaks an API contract, you want the damage contained. When legal changes a retention rule, you want one policy surface. When support asks why a refund happened, you want a traceable decision path.
Two patterns that work in practice
The first is a real-time fleet and operations dashboard.
This works when the platform combines telematics, maintenance events, and dispatch status into one operator-facing view. The value comes from shared operational truth. Not just visualisation. The dashboard should expose stale feeds, failed commands, exception queues, and audit history so operations teams can act without asking engineering to interpret system behaviour.
The second is an AI support assistant with strict boundaries.
This works when the assistant is grounded in policy documents, trip status, and account context, then limited to narrow tasks such as disruption explanations, refund preparation, or case triage. It should call tools for deterministic checks and escalate anything ambiguous. That keeps cost and risk under control while reducing repetitive support work.
Good AI in mobility behaves like a supervised operator. It doesn’t pretend to be an autonomous business process.
Accessibility is a serious product opportunity
There’s a recurring gap in the smart mobility world around users with accessibility and affordability constraints. That gap is commercially relevant and socially important.
In Tel Aviv, 28% of low-income residents face mobility barriers, and AI route prediction pilots for disabled users have reduced no-show rates by 22%, according to this Smart Cities Dive accessibility discussion. The engineering lesson is clear. Accessibility shouldn’t be treated as a settings page. It often requires dedicated workflow logic, better real-time orchestration, and operator tools for intervention.
That kind of product needs more than a consumer app. It needs:
- policy-aware routing that accounts for assistance needs
- agent-assisted support flows for exceptions and rebooking
- human review paths for sensitive changes
- clear governance around the personal data involved
What maintainability looks like
In mobility, maintainability means the team can answer five questions quickly:
- What happened?
- Why did it happen?
- Who or what was affected?
- Can we replay or correct it safely?
- Will the same issue recur tomorrow?
If the system can’t answer those questions, it isn’t mature enough for serious operational use.
That’s why the engineering posture matters so much. Favour explicit schemas over informal payloads. Favour adapter layers over direct coupling. Favour auditable workflows over hidden automation. Favour incremental delivery over platform grandiosity.
Your Next Steps in the Smart Mobility World
The smart mobility world rewards engineering discipline far more than trend chasing. Strong products in this space usually share the same foundations. They define a narrow operational problem, isolate third-party complexity, treat data quality as a first-order concern, and design privacy and resilience into the system from the start.
If you’re evaluating an entry point, keep the next steps simple.
A practical starting checklist
- Choose one painful workflow rather than a broad category like MaaS or fleet intelligence.
- Map every dependency across operators, APIs, devices, and internal teams before you scope the MVP.
- Define the system of record for bookings, vehicle state, user entitlement, and payments.
- Set governance early for retention, access control, auditability, and incident handling.
- Use AI selectively where the workflow is stable enough to supervise and measure.
What to avoid first
Don’t start by promising a unified platform for every mobility mode. Don’t centralise every feed before you know which events matter. Don’t let a third-party API define your internal business model. And don’t assume compliance can be solved in procurement review.
A strong mobility roadmap is usually smaller than the strategy deck and more rigorous than the prototype. That’s a healthy sign.
If you’re planning a mobility product, modernising an existing platform, or assessing AI, privacy, and integration risks before launch, Devisia can help you shape a practical path from discovery to maintainable delivery. The team works on custom software, dashboards, integrations, and governed AI systems with a product mindset that prioritises reliability, incremental progress, and long-term operability.