
A lot of CTOs already know their application estate is complex. What often gets missed is that risk is no longer limited to the code your team ships. It sits in the payment processor your product depends on, the observability platform your engineers trust during incidents, the LLM API inside a customer-facing workflow, the analytics tool embedded by marketing, and the subcontractors behind those services.
That is why third party risk management has moved out of procurement and into architecture, engineering, and operational resilience. If a vendor can affect your data, uptime, deployment path, customer trust, or regulatory posture, that vendor is part of your system. Treating it as an external administrative concern is how teams end up with impressive policies and weak control over real failure modes.
For software companies, this changes the shape of the work. Vendor reviews cannot live only in legal checklists or annual audits. They need to influence design decisions, access patterns, fallback logic, CI/CD controls, incident response, and service decomposition. Privacy is an architectural choice, not a feature. The same is true of vendor risk.
The Unseen Risk in Your Digital Supply Chain
A common scenario looks harmless until the day it is not.
A SaaS company uses a small analytics vendor to track product adoption, route campaign events, and enrich customer records. The integration was added quickly because the product team needed insight, the marketing team needed attribution, and the engineering team wanted to avoid building another internal service. The vendor did not look strategic. It was not the cloud host, identity provider, or payment gateway. It was “just” a tool.
Then the vendor has a breach.
No production database was hacked directly. No engineer introduced a critical flaw. Yet customers still ask why their information was exposed, why the company allowed the integration, and whether other suppliers can reach the same data. The company now has a security issue, a contractual issue, a product issue, and possibly a regulatory one. The root cause sits outside its own codebase, but the consequences land squarely inside its business.
This is the operating reality of modern software delivery. Every API, SaaS platform, cloud service, support tool, and embedded model provider extends your attack surface. If you rely on outsourced engineering or managed services, the chain grows again. That is one reason IT outsourcing decisions need architectural scrutiny, not only cost analysis.
The scale of the problem is already visible. In 2024, 30% of data breaches involved a third-party vendor, and Recorded Future notes that this figure doubled from the previous year in environments dependent on SaaS, cloud platforms, and supply chain partners critical to software and AI delivery (Recorded Future third-party risk statistics).
Vendors are part of your architecture
For a CTO, the practical shift is simple.
A vendor, not only a supplier, may be:
- A data processor handling customer records, logs, prompts, or attachments
- An execution dependency inside a request path or background job
- A control-plane dependency used for deployment, identity, support, or observability
- A resilience dependency whose outage changes your own recovery options
- A compliance dependency whose practices affect your obligations under GDPR, NIS2, or DORA
If a third party can interrupt your service, access sensitive data, or influence customer outcomes, treat it as part of your production system.
Third party risk management, in this context, is the discipline of identifying those dependencies, understanding their blast radius, and placing technical, contractual, and operational controls around them before they fail.
The Complete Third Party Risk Management Lifecycle
A workable programme is not a one-off questionnaire. It is a loop that starts before procurement and ends after offboarding.
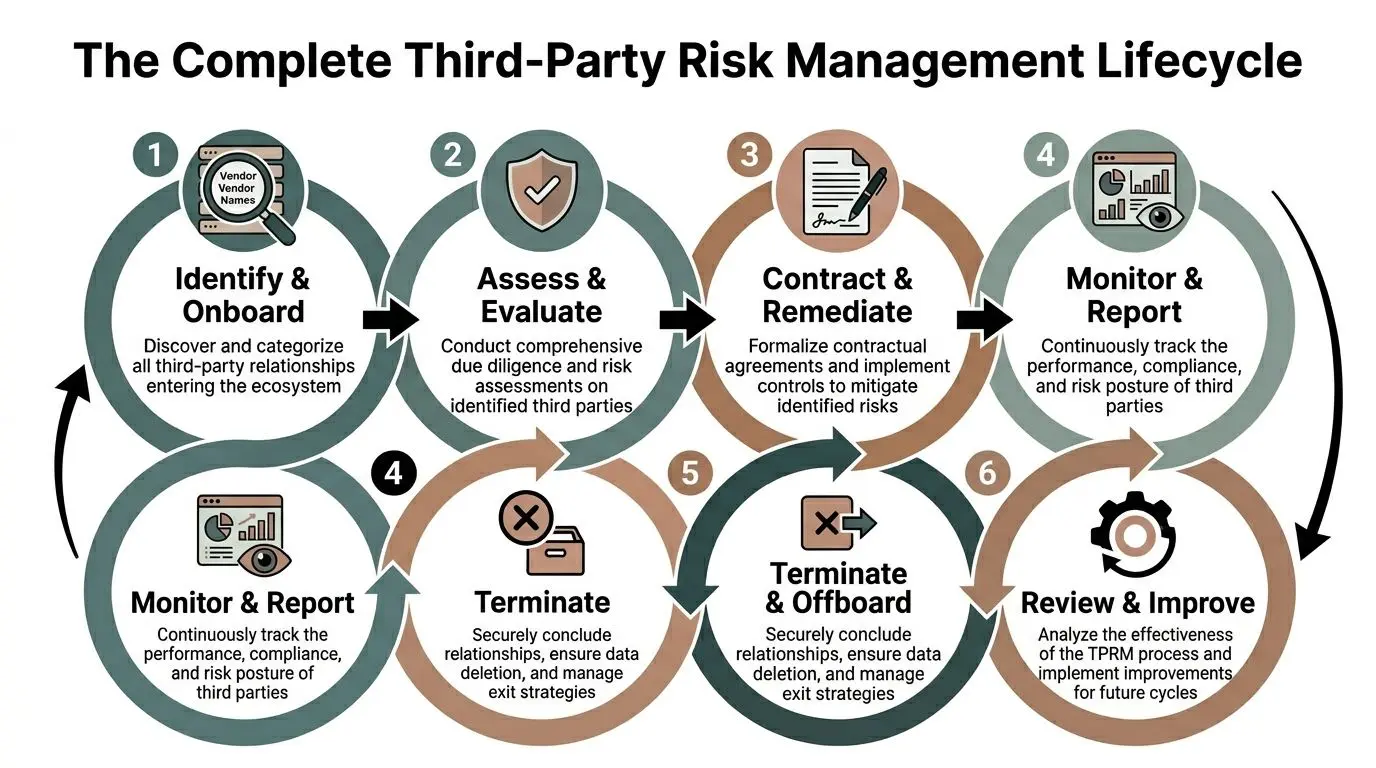
Identify and categorise vendors
Start with inventory. Most organisations underestimate how many third parties are already inside the stack.
This inventory must include more than signed contracts. It should cover browser scripts, support tools, CI/CD services, AI APIs, SDKs, embedded payment components, managed databases, outsourced support access, and any service with system or data access.
Then classify each vendor by business criticality and risk exposure. BlueVoyant describes a practical three-tier model: Tier 1 for high criticality and high risk, Tier 2 for medium, and Tier 3 for low, with Tier 1 vendors consuming the most assessment effort. A vendor handling customer data should be treated as Tier 1 and subjected to layered safeguards and deeper technical review (BlueVoyant guide to TPRM).
Use tiering that reflects software reality
A useful software-focused tiering model usually looks like this:
-
Tier 1 vendors Payment processors, cloud hosts, identity providers, customer support platforms with account access, data processors, model providers used in customer-facing AI features.
-
Tier 2 vendors Internal productivity tools, non-core analytics platforms, CRM systems with limited sensitive data, managed services with constrained scope.
-
Tier 3 vendors Low-access tools with no meaningful system integration and no customer data exposure.
The mistake is to tier by annual spend or vendor brand recognition alone. Technical access matters more than size.
Assess and perform due diligence
This stage is where many programmes become shallow. Teams send the same security questionnaire to every supplier, collect documents, and move on. That creates paperwork, not assurance.
A Tier 1 assessment should match the dependency type.
What to check for an AI provider
If the vendor provides LLM, embedding, vision, or speech capabilities, assess questions such as:
- Data handling. Are prompts, outputs, files, or metadata retained? Under what terms?
- Model routing. Does traffic stay within the expected service boundary, or can it be routed through sub-processors?
- Isolation. Can customer data be segregated by tenant, workspace, or API key?
- Abuse controls. Are there rate limits, misuse monitoring, and clear incident notification terms?
- Fallback design. What happens if the provider rate-limits, degrades, or changes behaviour?
What to check for a cloud or infrastructure provider
The emphasis shifts:
- Identity and access controls
- Encryption standards
- Patch and vulnerability management cadence
- Availability and resilience commitments
- Backup, restore, RTO, and RPO alignment
- Audit artefacts such as SOC 2 Type II where applicable
A cloud storage vendor and an LLM provider can both be Tier 1, but the risk mechanics are different. Your diligence should reflect that.
Good due diligence asks, “How can this vendor fail inside our system?” Poor due diligence asks, “Did they complete the form?”
Contract and onboard with enforceable controls
Onboarding is where legal language must connect to technical reality.
For high-impact vendors, contracts should support controls such as:
- Defined breach notification obligations
- Sub-processor transparency
- Data deletion and return terms
- Audit or evidence rights
- Security control commitments
- Business continuity expectations
- Restrictions on unauthorised data use
The engineering side matters just as much. Do not grant broad production access because the contract is signed.
Use onboarding checklists that include:
- Scoped access using least privilege
- Environment separation between test and production
- API key management with rotation and ownership
- Logging and traceability for vendor actions
- Kill switches or feature flags for high-impact integrations
Monitor continuously, not annually
Point-in-time assessment fails when a vendor changes after onboarding. Certificates expire. Security posture degrades. A sub-processor is added. An acquisition changes where data is handled. An API starts failing in a way your product team only notices after customer complaints.
Continuous monitoring closes that gap. In practical terms, monitoring should include external security signals, contract renewal checkpoints, integration-level observability, internal owner reviews, and reassessment after material changes.
Focus on events such as:
- New production access requests
- Material architecture changes
- New sub-processors
- Repeated SLA failures
- Security incidents or public disclosures
- Significant product changes affecting personal or regulated data
Offboard cleanly
Offboarding is usually the weakest part of the lifecycle.
A vendor relationship is not finished when procurement closes the contract. It is finished when the organisation has:
- Revoked credentials and tokens
- Removed network paths and integrations
- Deleted or recovered data
- Updated records and ownership
- Confirmed contractual exit obligations
- Documented the residual risk
Review and improve the programme
Every incident, delayed assessment, or emergency procurement exception should feed back into the system.
Look for recurring friction:
- Tier 1 reviews starting too late in delivery
- Contracts signed before architecture review
- Vendors added by departments outside engineering
- Missing fallback patterns for core external services
That feedback loop is what turns third party risk management from a compliance obligation into a delivery discipline.
Establishing Governance and Defining Roles
Programmes fail when ownership is vague. Security assumes procurement is tracking vendors. Procurement assumes engineering has assessed technical risk. Engineering assumes legal has covered the hard parts in contract language. Nobody is fully wrong, but nobody is clearly accountable.
Third party risk management works best as a cross-functional operating model. It should not sit in a silo, because the decisions are not siloed. A single vendor choice can alter data flows, product delivery, contractual terms, support procedures, and incident response.
Who should own what
A practical model for a software company usually involves these actors:
- Engineering or platform leadership owns technical assessment of architecture, access, integration depth, logging, and resilience patterns.
- Security or compliance owns the control framework, review criteria, exceptions, and escalation paths.
- Legal owns contractual protections, processor terms, liability language, and notification obligations.
- Procurement or finance owns commercial approval and supplier records.
- Product leadership owns the business rationale and accepts feature trade-offs when a vendor is rejected or constrained.
- Operational owners manage the live relationship once the service is in use.
This does not require a large committee for every tool. It requires a clear route for who decides, who reviews, and who signs off when risk is material.
Build a policy that engineers can use
Most TPRM policies fail because they are written for auditors, not operators.
A useful policy should define:
- When a vendor review is mandatory
- How vendors are tiered
- What evidence is required by tier
- What technical controls are essential
- How exceptions are approved
- How reassessments are triggered
- What offboarding must include
Keep the policy short enough to be used during delivery, then attach supporting standards and templates.
A strong pattern is to connect the policy to existing governance roles. If your organisation already has a privacy or security lead, align TPRM decisions with that function rather than inventing parallel authority. For many businesses, the role overlaps with responsibilities similar to a data protection manager, especially where third parties process personal data or influence lawful handling.
Use a simple RACI, not a maze
A lightweight responsibility matrix is often enough.
| Activity | Responsible | Accountable | Consulted | Informed |
|---|---|---|---|---|
| Vendor request submission | Product or business owner | Department lead | Engineering, security | Procurement |
| Technical risk review | Engineering or security | CTO or security lead | Product, operations | Legal |
| Contract review | Legal | Legal lead | Security, procurement | Vendor owner |
| Access approval | Platform or IT admin | Engineering lead | Security | Vendor owner |
| Incident coordination | Security and operations | Executive incident owner | Legal, product, vendor owner | Leadership |
| Offboarding | IT or platform team | Vendor owner | Security, legal, procurement | Finance |
If a production vendor has no named internal owner, you do not have governance. You have an unmanaged dependency.
Keep governance close to delivery
The most effective teams place vendor review early in discovery and architecture work, not at the end of procurement. That is where trade-offs are still cheap to change.
If a model provider cannot meet your data handling requirements, it is better to know before prompts, workflows, and user expectations are built around it. If a customer support tool requires broad production access, that should shape the design of support operations before rollout.
Governance should accelerate good decisions, not slow them down with late-stage surprises.
Essential Metrics for Measuring TPRM Effectiveness
Many programmes report activity, not risk. They count completed questionnaires, signed contracts, or vendors reviewed this quarter. Those measures have some value, but they do not answer the question a CTO cares about. Are we reducing exposure in a way that improves reliability and control?
The right dashboard combines KPIs, which show how efficiently the programme operates, and KRIs, which show how much risk remains in the system.
Censinet cites a KPMG survey of 1,263 professionals in which 73% had faced at least one significant third-party disruption between 2019 and 2022, which is a strong reminder that vendor reliability and incident exposure must be measured directly, not inferred from onboarding paperwork (Censinet KPI article).
KPIs tell you how the process runs
These are operational metrics. They reveal backlog, friction, and programme throughput.
Examples include:
- Time to complete initial vendor review
- Time to onboard a Tier 1 vendor
- Percentage of vendors with an assigned internal owner
- Percentage of reviews completed before procurement signature
- Assessment coverage across active vendors
- Remediation cycle time for identified issues
These are useful because delays here usually create workarounds. Teams under delivery pressure will bypass slow controls.
KRIs tell you where your exposure sits
These metrics matter more for leadership decisions.
Look for indicators such as:
- Percentage of Tier 1 vendors with unresolved high-risk findings
- Vendors with production access but incomplete review
- Critical vendors without tested exit or fallback arrangements
- Open incidents linked to third-party service degradation
- Vendors processing sensitive data without confirmed deletion terms
- Dependencies on fourth parties that remain opaque
Key TPRM Metrics
| Metric Category | Metric Example | What It Measures |
|---|---|---|
| KPI | Review cycle time | How quickly the organisation can assess a vendor |
| KPI | Remediation turnaround | How efficiently issues move from finding to closure |
| KPI | Coverage by tier | Whether the programme is reaching the right vendors |
| KPI | Pre-contract review rate | Whether controls happen early enough to matter |
| KRI | Unresolved high-risk vendors | The amount of serious vendor exposure still active |
| KRI | Critical vendors without fallback | Resilience gaps in business-critical services |
| KRI | Third-party incident count | Real operational impact from vendor-related failures |
| KRI | Vendors with broad access | Concentration of technical risk in external parties |
What leadership should look at
A useful executive dashboard is small. If it takes ten minutes to explain, it is too dense.
For most organisations, a monthly view should include:
- Risk tier distribution
- Vendors awaiting remediation
- Critical dependencies without contingency
- New material vendor changes
- Incident trends linked to third parties
Measure what changes decisions. If a metric never leads to escalation, redesign, or remediation, remove it.
The main mistake is rewarding process completion instead of reduced blast radius. A neat dashboard with low-risk colouring can still hide a production stack held together by fragile external services.
Leveraging Tooling and Automation for Scalable TPRM
Manual TPRM does not scale well in software environments. Spreadsheets drift. Questionnaires go stale. Ownership gets lost in email chains. By the time a review is complete, the vendor may already be integrated into production.
Tooling helps in these situations, but only if you use it as part of the engineering system rather than as an isolated compliance platform.
Mitratech notes that organisations using automated risk assessment and continuous monitoring can identify vendor security degradation, such as unpatched vulnerabilities or compliance lapses, within hours rather than waiting for quarterly reviews, improving mean time to detection and response (Mitratech on third-party risk management).
What to automate first
The first automation layer should remove repetitive work, not hide judgement.
Start with:
- Central vendor inventory tied to owners, systems, and data classes
- Tier-based assessment workflows so low-risk tools do not consume Tier 1 effort
- Evidence collection for standard artefacts and review history
- Renewal and reassessment triggers when contracts or integrations change
- Issue tracking integration so findings create visible work items
If your engineers live in Jira, create Jira tickets for remediation. If your security team works in a SIEM or alerting platform, route meaningful vendor risk signals there. If your platform team uses service catalogues, map vendors to the services they affect.
This short explainer covers the operational logic well:
Integrate TPRM into engineering workflows
The strongest pattern is to make vendor risk visible where delivery decisions happen.
Examples:
- CI/CD gates for dependencies that rely on high-risk external services
- Architecture review templates that require disclosure of new third-party data flows
- Ticket automation when a reassessment or remediation deadline is missed
- Runbooks that include vendor contacts, fallback actions, and kill-switch procedures
- Change management hooks for new AI providers, sub-processors, or production access paths
This is especially important for AI systems. An LLM provider may affect privacy, output reliability, latency, prompt retention, and downstream tool execution. Those are engineering concerns first, compliance concerns second.
Where AI helps
AI in TPRM is useful when it reduces repetitive assessment effort and surfaces patterns humans would otherwise miss.
Practical uses include:
- Summarising vendor evidence
- Extracting contract clauses for review
- Comparing responses across reassessments
- Flagging deviations from baseline controls
- Ranking vendors for human review based on risk signals
What does not work well is treating AI output as a decision-maker. Risk acceptance still needs human accountability.
Avoid the tooling trap
Buying a platform is not the same as running a programme.
Common failure modes include:
- No owner for the tooling
- Automated alerts with no response workflow
- Questionnaires sent without tiering
- Vendor scores disconnected from actual architecture
- Monitoring that does not trigger engineering action
The best TPRM tooling behaves like observability for your vendor estate. It should reveal changes early, route work clearly, and support decisions with context.
The target is not total automation. It is selective automation around inventory, evidence, monitoring, and workflow, with human review concentrated on the vendors that can hurt the business.
Navigating Key Regulatory and Compliance Demands
Regulation is one reason to formalise third party risk management, but it should not be the only one. If you build software systems that process personal data, support essential services, or operate in regulated sectors, third-party oversight becomes a legal expectation as well as an operational necessity.
The challenge is that legal texts speak in duties, while engineering teams work in systems, interfaces, and controls. The job is to translate obligations into implementation choices.
GDPR in practical terms
Under GDPR, if a vendor processes personal data on your behalf, you do not outsource responsibility by outsourcing processing.
In practice, that means you should have:
- A clear lawful basis and purpose for the processing
- A Data Processing Agreement
- Instructions that define what the processor may do
- Assurance around security measures
- Control over sub-processors
- A route for deletion, return, and incident notification
For software teams, this means mapping where personal data flows through external systems, especially support tools, analytics platforms, AI services, and infrastructure providers.
DORA and NIS2 in operational terms
DORA matters most where ICT third-party risk is directly regulated in financial contexts. NIS2 expands pressure on supply chain security more broadly for important and essential entities.
Both push organisations toward the same operational disciplines:
- Inventory critical third-party dependencies
- Assess concentration risk
- Document controls and responsibilities
- Test resilience and incident processes
- Maintain visibility into provider changes
- Ensure leadership can evidence oversight
That is why broad compliance claims are not enough. A vendor saying “we take security seriously” does not satisfy a resilience requirement.
Turn legal requirements into control points
A workable approach is to align each regulation with a control in your delivery process.
Examples:
| Regulatory area | Practical control |
|---|---|
| Personal data processing | DPA, data flow mapping, sub-processor review |
| Incident reporting obligations | Contract terms and internal escalation runbooks |
| Resilience requirements | Exit planning, fallback architecture, service dependency mapping |
| Access governance | Least privilege, role review, token rotation, logging |
| Auditability | Retained evidence, review history, ownership records |
A useful way to think about this is through the organisation’s overall means of compliance. Third party risk management is one component of that system, not a separate administrative island.
Regulators rarely care that a vendor caused the issue. They care whether you selected, governed, and monitored that vendor with appropriate diligence.
The companies that struggle most are usually not ignoring compliance. They are treating it as documentation after the fact, instead of shaping system design before launch.
Common TPRM Pitfalls and How to Avoid Them
Most weak programmes do not fail because nobody cares. They fail because the organisation chooses convenience in small decisions, then discovers those decisions have compounded into unmanaged exposure.
Tick-box reviews
The classic anti-pattern is the completed questionnaire that nobody challenged.
A vendor answers security questions, uploads a few documents, and receives approval. No one checks whether the controls match the actual integration. No one asks whether the product team is about to send sensitive data into a feature that was never approved for that use.
What works instead: tie reviews to the concrete architecture. Assess the data path, access scope, and failure impact.
Flawed prioritisation
Large, well-known suppliers often get the most attention because they feel important. Smaller SaaS tools are waved through because they look peripheral.
That is backwards in many modern stacks. SAFE Security notes that high-risk small-to-mid-sized SaaS vendors account for a significant portion of data breaches, yet traditional TPRM models often overlook them by focusing on large established suppliers (SAFE Security on TPRM challenges).
What works instead: prioritise by technical exposure, not vendor prestige. A niche support plugin with customer data access can be riskier than a major cloud provider with mature controls.
Set and forget onboarding
Onboarding is often treated as the finish line. It is only the start of the relationship.
Vendors change ownership, sub-processors, terms, architectures, and security posture. Your own use of the vendor also changes. A low-risk tool can become high-risk when a team starts feeding customer exports into it.
What works instead: trigger reassessment on material change, not only at renewal.
Ignoring fourth-party risk
Even strong vendor reviews can stop too early. Your provider may depend on hosting platforms, subcontractors, embedded models, or support partners that you never see directly.
What works instead: require disclosure of material sub-processors, define approval expectations for sensitive changes, and build fallback assumptions into architecture where visibility is limited.
Letting speed bypass control
Fast-moving teams often add tools during incidents, growth pushes, or product experiments. Months later, those tools remain in place with production access and no proper owner.
What works instead: make the safe path fast. Lightweight intake for low-risk tools, strong review for high-impact ones, and clear escalation when business urgency is real.
A good programme does not block speed. It prevents teams from borrowing speed now and paying for it later during an incident.
Frequently Asked Questions about TPRM
Does third party risk management include open-source dependencies
Yes, in practice it should.
Open-source components are not vendors in the contractual sense, but they are external dependencies that can affect security, licensing, resilience, and maintenance. Treat them with a parallel process: maintain an inventory, understand criticality, monitor changes, and define upgrade or replacement rules.
For engineering teams, software composition analysis, dependency review, and provenance checks often sit next to TPRM rather than inside it. The governance logic is similar even if the workflow differs.
What is the best first step for a startup with limited budget
Build a simple inventory and tier your vendors.
Do not start with a heavyweight framework. Start with a spreadsheet or lightweight system that records:
- vendor name
- owner
- service provided
- data access
- production access
- business criticality
- fallback status
Then review only the highest-impact vendors first. A small startup gains more from reviewing five critical dependencies properly than from sending generic forms to every tool in the stack.
What should you do if a business-critical vendor fails assessment
Do not force a false binary between full approval and total rejection.
Use structured options:
- Delay onboarding until key controls are fixed.
- Limit scope through least privilege, reduced data sharing, or environment isolation.
- Add compensating controls such as encryption, logging, human review, or feature restrictions.
- Create a time-bound remediation plan with explicit ownership.
- Escalate risk acceptance if the business insists on proceeding.
If none of these routes bring the risk into an acceptable range, choose another vendor. Replatforming early is painful. Replatforming during a breach is worse.
How is TPRM for an AI provider different from a traditional SaaS vendor
AI providers add a different class of uncertainty.
A traditional SaaS review focuses on access, hosting, security controls, and contractual protections. An AI review should also consider prompt handling, output reliability, model change management, safety controls, human oversight, and whether customer content could be used beyond the intended transaction.
The technical design should reflect those unknowns. Use redaction where possible, isolate high-risk prompts, define fallback behaviour, and avoid giving autonomous workflows broad authority without review points.
How often should vendors be reassessed
There is no universal interval that fits every vendor.
Use a mix of time-based and event-based triggers. Review critical vendors more closely, but also reassess whenever there is a material change in access, data use, architecture, incident history, or legal terms. Static annual cycles alone are too blunt for fast-moving software environments.
Who should approve vendor risk exceptions
Someone with authority to accept business risk, not only someone tasked with completing a process.
For low-impact tools, that may be a department lead. For critical vendors affecting production, customer data, or regulated operations, exception approval should sit with senior engineering, security, or executive leadership, with legal consulted where needed.
If your team is building SaaS products, internal platforms, or AI-enabled workflows and needs a more practical approach to vendor risk, Devisia helps companies design reliable systems where privacy, resilience, and compliance are built into the architecture from the start.