
Molti CTO sanno già che il loro parco applicativo è complesso. Quello che spesso sfugge è che il rischio non è più limitato al codice che il team rilascia. Si annida nel payment processor da cui dipende il vostro prodotto, nella piattaforma di osservabilità di cui gli ingegneri si fidano durante gli incidenti, nell’API LLM all’interno di un flusso rivolto ai clienti, nello strumento di analytics integrato dal marketing e nei subappaltatori che stanno dietro a quei servizi.
Ecco perché il third party risk management è uscito dagli acquisti ed è entrato nell’architettura, nell’ingegneria e nella resilienza operativa. Se un fornitore può influenzare i vostri dati, l’uptime, il percorso di deployment, la fiducia dei clienti o il vostro posizionamento normativo, quel fornitore fa parte del vostro sistema. Trattarlo come una questione amministrativa esterna è il modo in cui i team finiscono con policy impressionanti e un controllo debole sui veri modi di guasto.
Per le software company, questo cambia la forma del lavoro. Le valutazioni dei fornitori non possono vivere solo in checklist legali o audit annuali. Devono influenzare le decisioni di design, i pattern di accesso, la logica di fallback, i controlli CI/CD, la risposta agli incidenti e la scomposizione dei servizi. La privacy è una scelta architetturale, non una funzionalità. Lo stesso vale per il vendor risk.
Il rischio invisibile nella tua supply chain digitale
Uno scenario comune sembra innocuo fino al giorno in cui non lo è più.
Una società SaaS utilizza un piccolo fornitore di analytics per monitorare l’adozione del prodotto, instradare gli eventi delle campagne e arricchire i record dei clienti. L’integrazione è stata aggiunta rapidamente perché il team prodotto aveva bisogno di insight, il team marketing aveva bisogno di attribuzione e il team engineering voleva evitare di costruire un altro servizio interno. Il fornitore non sembrava strategico. Non era l’host cloud, l’identity provider o il gateway di pagamento. Era “solo” uno strumento.
Poi il fornitore subisce una violazione.
Nessun database di produzione è stato violato direttamente. Nessun ingegnere ha introdotto una falla critica. Eppure i clienti chiedono comunque perché le loro informazioni siano state esposte, perché l’azienda abbia consentito l’integrazione e se altri fornitori possano accedere agli stessi dati. L’azienda ora ha un problema di sicurezza, un problema contrattuale, un problema di prodotto e forse anche uno normativo. La causa primaria si trova fuori dal proprio codebase, ma le conseguenze ricadono direttamente sul suo business.
Questa è la realtà operativa della moderna delivery software. Ogni API, piattaforma SaaS, servizio cloud, strumento di supporto e provider di modelli embedded estende la vostra attack surface. Se vi affidate a engineering in outsourcing o a managed services, la catena si allunga ancora. Questo è uno dei motivi per cui le decisioni di IT outsourcing richiedono un esame architetturale, non solo un’analisi dei costi.
La scala del problema è già visibile. Nel 2024, il 30% delle violazioni dei dati ha coinvolto un fornitore terzo, e Recorded Future osserva che questa cifra è raddoppiata rispetto all’anno precedente in ambienti dipendenti da SaaS, piattaforme cloud e partner della supply chain critici per la delivery di software e AI (Recorded Future third-party risk statistics).
I fornitori fanno parte della tua architettura
Per un CTO, il cambiamento pratico è semplice.
Un fornitore, e non solo un supplier, può essere:
- Un data processor che gestisce record dei clienti, log, prompt o allegati
- Una dipendenza di esecuzione dentro un percorso di richiesta o un job in background
- Una dipendenza del control plane usata per deployment, identità, supporto o osservabilità
- Una dipendenza di resilienza la cui indisponibilità cambia le vostre opzioni di ripristino
- Una dipendenza di compliance le cui pratiche influenzano gli obblighi derivanti da GDPR, NIS2 o DORA
Se una terza parte può interrompere il vostro servizio, accedere a dati sensibili o influenzare i risultati per i clienti, trattatela come parte del vostro sistema di produzione.
Il third party risk management, in questo contesto, è la disciplina che identifica quelle dipendenze, ne comprende il blast radius e applica controlli tecnici, contrattuali e operativi attorno a esse prima che falliscano.
Il ciclo completo del Third Party Risk Management
Un programma efficace non è un questionario una tantum. È un ciclo che inizia prima degli acquisti e termina dopo l’offboarding.
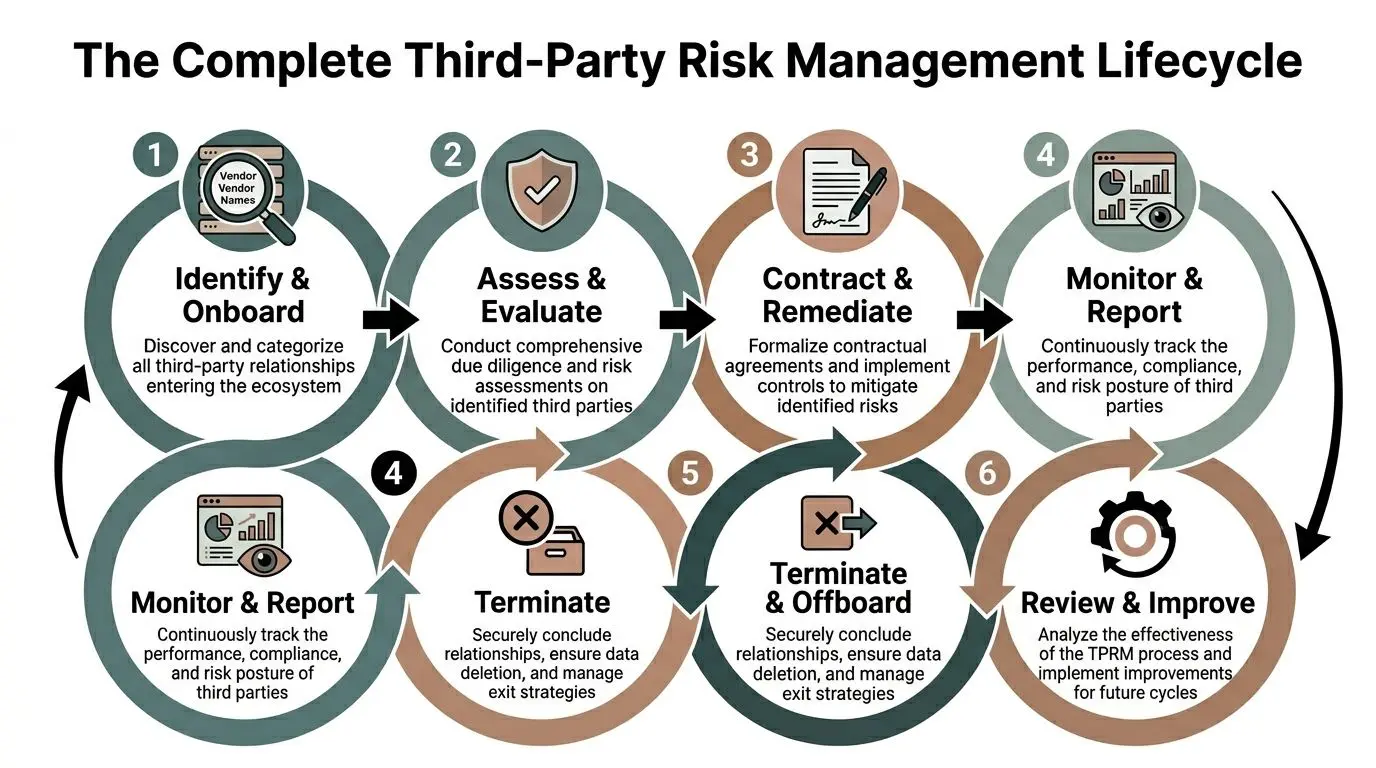
Identificare e categorizzare i fornitori
Inizia dall’inventario. La maggior parte delle organizzazioni sottostima quanti terzi siano già dentro lo stack.
Questo inventario deve includere più dei contratti firmati. Dovrebbe coprire script browser, strumenti di supporto, servizi CI/CD, API AI, SDK, componenti di pagamento embedded, database gestiti, accessi di supporto in outsourcing e qualsiasi servizio con accesso al sistema o ai dati.
Poi classifica ogni fornitore in base a criticità per il business ed esposizione al rischio. BlueVoyant descrive un modello pratico a tre livelli: Tier 1 per alta criticità e alto rischio, Tier 2 per livello medio e Tier 3 per livello basso, con i fornitori Tier 1 che richiedono il maggiore sforzo di valutazione. Un fornitore che gestisce dati dei clienti dovrebbe essere trattato come Tier 1 e sottoposto a garanzie stratificate e a una revisione tecnica più approfondita (BlueVoyant guide to TPRM).
Usare una classificazione a livelli che rispecchi la realtà software
Un modello di tiering utile e focalizzato sul software appare di solito così:
-
Fornitori Tier 1 Payment processor, host cloud, identity provider, piattaforme di customer support con accesso agli account, data processor, provider di modelli usati in funzionalità AI rivolte ai clienti.
-
Fornitori Tier 2 Strumenti di produttività interni, piattaforme di analytics non core, sistemi CRM con dati sensibili limitati, managed services con ambito ristretto.
-
Fornitori Tier 3 Strumenti con accesso ridotto, senza integrazione significativa con il sistema e senza esposizione ai dati dei clienti.
L’errore è classificare i fornitori solo in base alla spesa annua o al riconoscimento del brand. L’accesso tecnico conta più delle dimensioni.
Valutare ed eseguire la due diligence
È in questa fase che molti programmi diventano superficiali. I team inviano lo stesso questionario di sicurezza a ogni fornitore, raccolgono documenti e vanno avanti. Questo crea burocrazia, non assurance.
Una valutazione Tier 1 dovrebbe corrispondere al tipo di dipendenza.
Cosa verificare per un provider AI
Se il fornitore offre funzionalità LLM, embedding, vision o speech, valuta domande come:
- Gestione dei dati. Prompt, output, file o metadati vengono conservati? A quali condizioni?
- Instradamento del modello. Il traffico rimane nel perimetro del servizio previsto o può essere instradato attraverso sub-processor?
- Isolamento. I dati dei clienti possono essere segregati per tenant, workspace o API key?
- Controlli contro l’abuso. Esistono rate limit, monitoraggio degli abusi e termini chiari di notifica degli incidenti?
- Progettazione del fallback. Cosa accade se il provider applica rate limit, degrada o cambia comportamento?
Cosa verificare per un provider cloud o di infrastruttura
L’attenzione si sposta su:
- Controlli di identità e accesso
- Standard di cifratura
- Cadenza di patch e vulnerability management
- Impegni di availability e resilienza
- Allineamento di backup, restore, RTO e RPO
- Evidenze di audit come SOC 2 Type II, dove applicabile
Un fornitore di storage cloud e un provider LLM possono entrambi essere Tier 1, ma la meccanica del rischio è diversa. La vostra due diligence dovrebbe rifletterlo.
Una buona due diligence chiede: “Come può fallire questo fornitore dentro il nostro sistema?” Una cattiva due diligence chiede: “Ha compilato il modulo?”
Contrattualizzare e onboarding con controlli applicabili
L’onboarding è il punto in cui il linguaggio legale deve collegarsi alla realtà tecnica.
Per i fornitori ad alto impatto, i contratti dovrebbero supportare controlli come:
- Obblighi definiti di notifica delle violazioni
- Trasparenza sui sub-processor
- Termini di cancellazione e restituzione dei dati
- Diritti di audit o di evidenza
- Impegni sui controlli di sicurezza
- Aspettative di business continuity
- Restrizioni sull’uso non autorizzato dei dati
Anche la parte engineering è altrettanto importante. Non concedere ampi accessi in produzione solo perché il contratto è stato firmato.
Usa checklist di onboarding che includano:
- Accesso circoscritto con il principio del privilegio minimo
- Separazione degli ambienti tra test e produzione
- Gestione delle API key con rotazione e ownership
- Logging e tracciabilità delle azioni del fornitore
- Kill switch o feature flag per integrazioni ad alto impatto
Monitorare continuamente, non una volta l’anno
La valutazione puntuale fallisce quando un fornitore cambia dopo l’onboarding. I certificati scadono. La postura di sicurezza peggiora. Viene aggiunto un sub-processor. Un’acquisizione cambia dove vengono gestiti i dati. Un’API inizia a fallire in un modo che il vostro product team nota solo dopo i reclami dei clienti.
Il monitoraggio continuo colma quel divario. In termini pratici, il monitoraggio dovrebbe includere segnali di sicurezza esterni, checkpoint al rinnovo dei contratti, osservabilità a livello di integrazione, review dei referenti interni e una rivalutazione dopo cambiamenti materiali.
Concentrati su eventi come:
- Nuove richieste di accesso in produzione
- Cambiamenti architetturali materiali
- Nuovi sub-processor
- Ripetuti fallimenti SLA
- Incidenti di sicurezza o disclosure pubbliche
- Cambiamenti significativi del prodotto che coinvolgono dati personali o regolamentati
Offboarding pulito
L’offboarding è di solito la parte più debole del ciclo.
Una relazione con un fornitore non finisce quando gli acquisti chiudono il contratto. Finisce quando l’organizzazione ha:
- Revocato credenziali e token
- Rimosso percorsi di rete e integrazioni
- Cancellato o recuperato i dati
- Aggiornato record e ownership
- Confermato gli obblighi contrattuali di uscita
- Documentato il rischio residuo
Rivedere e migliorare il programma
Ogni incidente, ritardo nella valutazione o eccezione di procurement urgente dovrebbe rientrare nel sistema.
Cerca attriti ricorrenti:
- Review Tier 1 che iniziano troppo tardi nel delivery
- Contratti firmati prima della revisione architetturale
- Fornitori aggiunti da dipartimenti fuori dall’ingegneria
- Pattern di fallback mancanti per servizi esterni core
Quel ciclo di feedback è ciò che trasforma il third party risk management da obbligo di compliance in disciplina di delivery.
Stabilire la governance e definire i ruoli
I programmi falliscono quando l’ownership è vaga. La sicurezza presume che gli acquisti stiano tracciando i fornitori. Gli acquisti presumono che l’ingegneria abbia valutato il rischio tecnico. L’ingegneria presume che il legale abbia coperto le parti difficili nel contratto. Nessuno è del tutto in errore, ma nessuno è chiaramente responsabile.
Il third party risk management funziona meglio come modello operativo cross-funzionale. Non dovrebbe stare in un silo, perché le decisioni non sono in un silo. Una singola scelta di fornitore può alterare i flussi di dati, la delivery del prodotto, i termini contrattuali, le procedure di supporto e la risposta agli incidenti.
Chi dovrebbe occuparsi di cosa
Un modello pratico per una software company di solito coinvolge questi attori:
- Engineering o platform leadership: valutazione tecnica di architettura, accessi, profondità di integrazione, logging e pattern di resilienza.
- Security o compliance: framework di controllo, criteri di revisione, eccezioni e percorsi di escalation.
- Legal: protezioni contrattuali, termini da processor, clausole di responsabilità e obblighi di notifica.
- Procurement o finance: approvazione commerciale e record dei fornitori.
- Product leadership: motivazione di business e accettazione dei compromessi funzionali quando un fornitore viene rifiutato o vincolato.
- Responsabili operativi: gestione della relazione in esercizio una volta che il servizio è in uso.
Questo non richiede un grande comitato per ogni strumento. Richiede un percorso chiaro su chi decide, chi rivede e chi approva quando il rischio è materiale.
Costruire una policy che gli ingegneri possano usare
La maggior parte delle policy TPRM fallisce perché sono scritte per gli auditor, non per gli operatori.
Una policy utile dovrebbe definire:
- Quando è obbligatoria la revisione di un fornitore
- Come vengono classificati i fornitori
- Quale evidenza è richiesta per ciascun livello
- Quali controlli tecnici sono essenziali
- Come vengono approvate le eccezioni
- Come vengono attivate le rivalutazioni
- Cosa deve includere l’offboarding Mantieni la policy abbastanza breve da poter essere usata durante la delivery, quindi allega standard e template di supporto.
Un modello efficace è collegare la policy ai ruoli di governance già esistenti. Se la tua organizzazione ha già un responsabile privacy o sicurezza, allinea le decisioni TPRM a quella funzione invece di inventare un’autorità parallela. Per molte aziende, il ruolo si sovrappone a responsabilità simili a quelle di un data protection manager, soprattutto quando terze parti trattano dati personali o influenzano una gestione conforme alla legge.
Usa un RACI semplice, non un labirinto
Una matrice di responsabilità leggera è spesso sufficiente.
| Attività | Responsabile | Accountable | Consultato | Informato |
|---|---|---|---|---|
| Invio richiesta fornitore | Product owner o responsabile di business | Responsabile di dipartimento | Engineering, security | Procurement |
| Revisione del rischio tecnico | Engineering o security | CTO o responsabile security | Product, operations | Legal |
| Revisione contrattuale | Legal | Responsabile legal | Security, procurement | Responsabile fornitore |
| Approvazione accessi | Platform o amministratore IT | Responsabile engineering | Security | Responsabile fornitore |
| Coordinamento incidenti | Security e operations | Responsabile esecutivo dell’incidente | Legal, product, responsabile fornitore | Leadership |
| Offboarding | Team IT o platform | Responsabile fornitore | Security, legal, procurement | Finance |
Se un fornitore in produzione non ha un responsabile interno nominato, non hai governance. Hai una dipendenza non gestita.
Mantieni la governance vicina alla delivery
I team più efficaci inseriscono la revisione dei fornitori all’inizio del discovery e del lavoro di architettura, non alla fine del procurement. È lì che i compromessi sono ancora economici da modificare.
Se un provider di modelli non può soddisfare i tuoi requisiti di gestione dei dati, è meglio saperlo prima che prompt, workflow e aspettative degli utenti vengano costruiti attorno ad esso. Se uno strumento di customer support richiede un ampio accesso alla produzione, questo dovrebbe influenzare la progettazione delle operazioni di supporto prima del rilascio.
La governance dovrebbe accelerare buone decisioni, non rallentarle con sorprese arrivate troppo tardi.
Metriche essenziali per misurare l’efficacia del TPRM
Molti programmi riportano attività, non rischio. Contano i questionari completati, i contratti firmati o i fornitori revisionati in questo trimestre. Queste misure hanno un certo valore, ma non rispondono alla domanda che interessa a un CTO. Stiamo riducendo l’esposizione in un modo che migliori affidabilità e controllo?
Il dashboard giusto combina KPI, che mostrano quanto efficientemente opera il programma, e KRI, che mostrano quanto rischio resta nel sistema.
Censinet cita un sondaggio KPMG su 1.263 professionisti in cui il 73% aveva affrontato almeno una significativa interruzione causata da terze parti tra il 2019 e il 2022, un forte promemoria del fatto che l’affidabilità dei fornitori e l’esposizione agli incidenti devono essere misurate direttamente, non dedotte dalla documentazione di onboarding (articolo KPI di Censinet).
I KPI ti dicono come funziona il processo
Queste sono metriche operative. Rivelano backlog, attriti e throughput del programma.
Esempi:
- Tempo per completare la revisione iniziale del fornitore
- Tempo per onboardare un fornitore Tier 1
- Percentuale di fornitori con un responsabile interno assegnato
- Percentuale di revisioni completate prima della firma del procurement
- Copertura delle valutazioni tra i fornitori attivi
- Tempo di ciclo della remediation per i problemi identificati
Sono utili perché i ritardi qui di solito creano workaround. I team sotto pressione di delivery aggirano i controlli lenti.
I KRI ti dicono dove si trova la tua esposizione
Queste metriche contano di più per le decisioni della leadership.
Cerca indicatori come:
- Percentuale di fornitori Tier 1 con finding ad alto rischio non risolti
- Fornitori con accesso alla produzione ma revisione incompleta
- Fornitori critici senza accordi di uscita o fallback testati
- Incidenti aperti collegati al degrado di servizi di terze parti
- Fornitori che trattano dati sensibili senza termini di cancellazione confermati
- Dipendenze da fourth party che restano opache
Metriche chiave del TPRM
| Categoria metrica | Esempio di metrica | Cosa misura |
|---|---|---|
| KPI | Tempo del ciclo di revisione | Quanto rapidamente l’organizzazione può valutare un fornitore |
| KPI | Tempo di remediation | Quanto efficientemente i problemi passano dal finding alla chiusura |
| KPI | Copertura per tier | Se il programma sta raggiungendo i fornitori giusti |
| KPI | Tasso di revisione pre-contratto | Se i controlli avvengono abbastanza presto da avere impatto |
| KRI | Fornitori ad alto rischio non risolti | La quantità di esposizione grave del fornitore ancora attiva |
| KRI | Fornitori critici senza fallback | Lacune di resilienza nei servizi business-critical |
| KRI | Numero di incidenti di terze parti | Impatto operativo reale da guasti legati ai fornitori |
| KRI | Fornitori con accesso ampio | Concentrazione del rischio tecnico in parti esterne |
Cosa dovrebbe guardare la leadership
Un dashboard esecutivo utile è piccolo. Se servono dieci minuti per spiegarlo, è troppo denso.
Per la maggior parte delle organizzazioni, una vista mensile dovrebbe includere:
- Distribuzione dei tier di rischio
- Fornitori in attesa di remediation
- Dipendenze critiche senza contingenza
- Nuovi cambiamenti materiali dei fornitori
- Trend degli incidenti collegati a terze parti
Misura ciò che cambia le decisioni. Se una metrica non porta mai a escalation, redesign o remediation, eliminala.
L’errore principale è premiare il completamento del processo invece della riduzione del blast radius. Un dashboard ordinato con colori a basso rischio può comunque nascondere uno stack di produzione tenuto insieme da servizi esterni fragili.
Sfruttare tooling e automazione per un TPRM scalabile
Il TPRM manuale non scala bene negli ambienti software. I fogli di calcolo si deteriorano. I questionari diventano obsoleti. La responsabilità si perde nelle catene di email. Quando la revisione è completata, il fornitore potrebbe essere già integrato in produzione.
Il tooling aiuta in queste situazioni, ma solo se lo usi come parte del sistema di engineering e non come piattaforma di compliance isolata.
Mitratech osserva che le organizzazioni che usano valutazioni automatizzate del rischio e monitoraggio continuo possono identificare il degrado della sicurezza dei fornitori, come vulnerabilità non patchate o mancate conformità, entro poche ore invece di aspettare le revisioni trimestrali, migliorando il mean time to detection e response (Mitratech sul third-party risk management).
Cosa automatizzare per primo
Il primo livello di automazione dovrebbe eliminare il lavoro ripetitivo, non nascondere il giudizio.
Inizia con:
- Inventario centralizzato dei fornitori collegato a owner, sistemi e classi di dati
- Workflow di assessment basati sul tier in modo che gli strumenti a basso rischio non consumino effort da Tier 1
- Raccolta evidenze per artefatti standard e cronologia delle revisioni
- Trigger di rinnovo e rivalutazione quando contratti o integrazioni cambiano
- Integrazione del tracciamento dei problemi in modo che i finding generino item di lavoro visibili
Se i tuoi engineer vivono in Jira, crea ticket Jira per la remediation. Se il team security lavora in un SIEM o in una piattaforma di alerting, instrada lì i segnali rilevanti di vendor risk. Se il team platform usa service catalogue, mappa i fornitori ai servizi che influenzano.
Questa breve spiegazione copre bene la logica operativa:
Integra il TPRM nei workflow di engineering
Il modello più forte è rendere visibile il rischio dei fornitori dove avvengono le decisioni di delivery.
Esempi:
- Gate CI/CD per dipendenze che si affidano a servizi esterni ad alto rischio
- Template di architecture review che richiedono la divulgazione dei nuovi flussi di dati di terze parti
- Automazione dei ticket quando viene mancato un termine di rivalutazione o remediation
- Runbook che includono contatti del fornitore, azioni di fallback e procedure di kill-switch
- Hook di change management per nuovi provider AI, sub-processor o percorsi di accesso alla produzione
Questo è particolarmente importante per i sistemi AI. Un provider LLM può influenzare privacy, affidabilità dell’output, latenza, retention dei prompt ed esecuzione degli strumenti downstream. Prima di tutto sono preoccupazioni di engineering, poi di compliance.
Dove l’AI aiuta
L’AI nel TPRM è utile quando riduce lo sforzo ripetitivo di assessment e fa emergere pattern che gli umani potrebbero altrimenti non notare.
Usi pratici includono:
- Riassumere le evidenze del fornitore
- Estrarre clausole contrattuali per la revisione
- Confrontare le risposte tra rivalutazioni
- Segnalare deviazioni dai controlli baseline
- Classificare i fornitori per la revisione umana in base ai segnali di rischio
Ciò che non funziona bene è trattare l’output dell’AI come un decisore. L’accettazione del rischio richiede ancora responsabilità umana.
Evita la trappola del tooling
Acquistare una piattaforma non equivale a gestire un programma.
I failure mode comuni includono:
- Nessun owner per il tooling
- Alert automatizzati senza workflow di risposta
- Questionari inviati senza tiering
- Punteggi dei fornitori scollegati dall’architettura reale
- Monitoraggio che non attiva azioni di engineering
Il miglior tooling TPRM si comporta come osservabilità per il tuo parco fornitori. Dovrebbe rivelare i cambiamenti in anticipo, indirizzare il lavoro in modo chiaro e supportare le decisioni con contesto.
L’obiettivo non è l’automazione totale. È l’automazione selettiva intorno a inventario, evidenze, monitoraggio e workflow, con la revisione umana concentrata sui fornitori che possono danneggiare il business.
Orientarsi tra i principali requisiti normativi e di compliance
La regolamentazione è una delle ragioni per formalizzare il third party risk management, ma non dovrebbe essere l’unica. Se costruisci sistemi software che trattano dati personali, supportano servizi essenziali o operano in settori regolamentati, la supervisione di terze parti diventa un requisito legale oltre che una necessità operativa.
La sfida è che i testi legali parlano di obblighi, mentre i team di engineering lavorano con sistemi, interfacce e controlli. Il compito è tradurre gli obblighi in scelte di implementazione.
GDPR in termini pratici
Ai sensi del GDPR, se un fornitore tratta dati personali per tuo conto, non stai delegando la responsabilità delegando il trattamento.
In pratica, significa che dovresti avere:
- Una base giuridica e una finalità chiare per il trattamento
- Un Data Processing Agreement
- Istruzioni che definiscono cosa può fare il processor
- Garanzie sulle misure di sicurezza
- Controllo sui sub-processor
- Un percorso per cancellazione, restituzione e notifica degli incidenti
Per i team software, questo significa mappare dove i dati personali fluiscono attraverso sistemi esterni, in particolare strumenti di supporto, piattaforme di analytics, servizi AI e provider di infrastruttura.
DORA e NIS2 in termini operativi
DORA è più rilevante dove il rischio di terze parti ICT è regolato direttamente in contesti finanziari. NIS2 amplia più in generale la pressione sulla sicurezza della supply chain per entità importanti ed essenziali.
Entrambe spingono le organizzazioni verso le stesse discipline operative:
- Inventariare le dipendenze critiche di terze parti
- Valutare il rischio di concentrazione
- Documentare controlli e responsabilità
- Testare resilienza e processi di incidente
- Mantenere visibilità sui cambiamenti dei provider
- Garantire che la leadership possa dimostrare la supervisione
Ecco perché le dichiarazioni generiche di compliance non sono sufficienti. Un fornitore che dice “prendiamo la sicurezza sul serio” non soddisfa un requisito di resilienza.
Trasforma i requisiti legali in punti di controllo
Un approccio praticabile è allineare ogni regolamento a un controllo nel tuo processo di delivery.
Esempi:
| Area normativa | Controllo pratico |
|---|---|
| Trattamento di dati personali | DPA, mappatura dei flussi di dati, revisione dei sub-processor |
| Obblighi di notifica degli incidenti | Clausole contrattuali e runbook interni di escalation |
| Requisiti di resilienza | Pianificazione dell’uscita, architettura di fallback, mappatura delle dipendenze del servizio |
| Governance degli accessi | Least privilege, revisione dei ruoli, rotazione dei token, logging |
| Auditabilità | Evidenze conservate, cronologia delle revisioni, record di ownership |
| Un modo utile di pensarci è attraverso i mezzi di conformità complessivi dell’organizzazione. La gestione del rischio di terze parti è una componente di quel sistema, non un’isola amministrativa separata. |
I regolatori si preoccupano raramente del fatto che un fornitore abbia causato il problema. Si preoccupano se avete selezionato, governato e monitorato quel fornitore con la dovuta diligenza.
Le aziende che hanno più difficoltà di solito non stanno ignorando la conformità. La stanno trattando come documentazione a posteriori, invece di modellare la progettazione del sistema prima del lancio.
Insidie comuni della TPRM e come evitarle
La maggior parte dei programmi deboli non fallisce perché a nessuno importa. Falliscono perché l’organizzazione sceglie la comodità in piccole decisioni, poi scopre che quelle decisioni si sono sommate in un’esposizione non gestita.
Revisioni a caselle di spunta
L’antimodello classico è il questionario compilato che nessuno ha contestato.
Un fornitore risponde alle domande di sicurezza, carica alcuni documenti e riceve l’approvazione. Nessuno verifica se i controlli corrispondono alla reale integrazione. Nessuno chiede se il team di prodotto stia per inviare dati sensibili in una funzionalità che non era mai stata approvata per quell’uso.
Ciò che funziona invece: collegare le revisioni all’architettura concreta. Valutare il percorso dei dati, l’ambito di accesso e l’impatto in caso di guasto.
Prioritizzazione difettosa
I fornitori grandi e ben noti spesso ricevono la maggiore attenzione perché sembrano importanti. I piccoli strumenti SaaS vengono fatti passare perché sembrano periferici.
In molti stack moderni questo è il contrario. SAFE Security osserva che i fornitori SaaS piccoli e medi ad alto rischio rappresentano una quota significativa delle violazioni dei dati, eppure i modelli TPRM tradizionali spesso li trascurano concentrandosi su grandi fornitori consolidati (SAFE Security sulle sfide della TPRM).
Ciò che funziona invece: dare priorità all’esposizione tecnica, non al prestigio del fornitore. Un plugin di supporto di nicchia con accesso ai dati dei clienti può essere più rischioso di un grande provider cloud con controlli maturi.
Onboarding “imposta e dimentica”
L’onboarding viene spesso trattato come il traguardo. È solo l’inizio della relazione.
I fornitori cambiano proprietà, sub-responsabili del trattamento, termini, architetture e postura di sicurezza. Anche il vostro uso del fornitore cambia. Uno strumento a basso rischio può diventare ad alto rischio quando un team inizia a inviarci esportazioni di clienti.
Ciò che funziona invece: attivare una rivalutazione in caso di cambiamento materiale, non solo al rinnovo.
Ignorare il rischio di quarta parte
Anche le revisioni solide dei fornitori possono fermarsi troppo presto. Il vostro provider può dipendere da piattaforme di hosting, subappaltatori, modelli incorporati o partner di supporto che non vedete direttamente.
Ciò che funziona invece: richiedere la divulgazione dei principali sub-responsabili del trattamento, definire aspettative di approvazione per le modifiche sensibili e incorporare assunzioni di fallback nell’architettura dove la visibilità è limitata.
Lasciare che la velocità scavalchi il controllo
I team che si muovono rapidamente spesso aggiungono strumenti durante incidenti, spinte di crescita o esperimenti di prodotto. Mesi dopo, quegli strumenti restano in uso con accesso alla produzione e senza un proprietario adeguato.
Ciò che funziona invece: rendere veloce il percorso sicuro. Un intake leggero per gli strumenti a basso rischio, una revisione rigorosa per quelli ad alto impatto e un’escalation chiara quando l’urgenza di business è reale.
Un buon programma non blocca la velocità. Impedisce ai team di prendere in prestito velocità oggi e pagarla più tardi durante un incidente.
Domande frequenti sulla TPRM
La gestione del rischio di terze parti include le dipendenze open source
Sì, in pratica dovrebbe.
I componenti open source non sono fornitori in senso contrattuale, ma sono dipendenze esterne che possono influire su sicurezza, licenze, resilienza e manutenzione. Trattateli con un processo parallelo: mantenete un inventario, comprendete la criticità, monitorate i cambiamenti e definite regole di aggiornamento o sostituzione.
Per i team di ingegneria, l’analisi della composizione del software, la revisione delle dipendenze e i controlli di provenienza spesso affiancano la TPRM anziché farne parte. La logica di governance è simile anche se il flusso di lavoro è diverso.
Qual è il primo passo migliore per una startup con budget limitato
Create un inventario semplice e classificate i fornitori per livello.
Non iniziate con un framework pesante. Partite da un foglio di calcolo o da un sistema leggero che registri:
- nome del fornitore
- responsabile
- servizio fornito
- accesso ai dati
- accesso alla produzione
- criticità per il business
- stato di fallback
Poi esaminate prima solo i fornitori a maggiore impatto. Una piccola startup trae più beneficio dal valutare correttamente cinque dipendenze critiche che dall’inviare moduli generici a ogni strumento nello stack.
Cosa fare se un fornitore critico per il business non supera la valutazione
Non forzate un falso binario tra approvazione completa e rifiuto totale.
Usate opzioni strutturate:
- Rinviare l’onboarding finché i controlli chiave non vengono corretti.
- Limitare l’ambito tramite il principio del minimo privilegio, la condivisione ridotta dei dati o l’isolamento dell’ambiente.
- Aggiungere controlli compensativi come crittografia, logging, revisione umana o restrizioni delle funzionalità.
- Creare un piano di rimedio a tempo con responsabilità esplicita.
- Escalare l’accettazione del rischio se l’azienda insiste nel procedere.
Se nessuna di queste strade porta il rischio a un livello accettabile, scegliete un altro fornitore. Ripiattaformare presto è doloroso. Ripiattaformare durante una violazione è peggio.
In che modo la TPRM per un provider di IA è diversa da quella per un fornitore SaaS tradizionale
I provider di IA aggiungono una classe diversa di incertezza.
Una revisione SaaS tradizionale si concentra su accesso, hosting, controlli di sicurezza e protezioni contrattuali. Una revisione dell’IA dovrebbe considerare anche la gestione dei prompt, l’affidabilità delle risposte, la gestione delle modifiche del modello, i controlli di sicurezza, la supervisione umana e la possibilità che i contenuti dei clienti vengano usati oltre la transazione prevista.
La progettazione tecnica dovrebbe riflettere queste incognite. Usate la redazione dove possibile, isolate i prompt ad alto rischio, definite un comportamento di fallback ed evitate di dare a flussi di lavoro autonomi ampia autorità senza punti di revisione.
Con quale frequenza i fornitori dovrebbero essere rivalutati
Non esiste un intervallo universale adatto a ogni fornitore.
Usate una combinazione di trigger basati sul tempo e sugli eventi. Rivedete i fornitori critici con maggiore attenzione, ma rivalutateli anche ogni volta che c’è un cambiamento materiale nell’accesso, nell’uso dei dati, nell’architettura, nello storico degli incidenti o nei termini legali. I cicli annuali statici da soli sono troppo grossolani per ambienti software in rapido movimento.
Chi dovrebbe approvare le eccezioni al rischio dei fornitori
Qualcuno con l’autorità di accettare il rischio di business, non solo qualcuno incaricato di completare un processo.
Per gli strumenti a basso impatto, potrebbe essere un responsabile di dipartimento. Per i fornitori critici che incidono sulla produzione, sui dati dei clienti o sulle operazioni regolamentate, l’approvazione delle eccezioni dovrebbe essere affidata a leadership senior di engineering, sicurezza o direzione esecutiva, con il coinvolgimento del legale quando necessario.
Se il vostro team sta costruendo prodotti SaaS, piattaforme interne o flussi di lavoro abilitati dall’IA e ha bisogno di un approccio più pratico al rischio dei fornitori, Devisia aiuta le aziende a progettare sistemi affidabili in cui privacy, resilienza e conformità sono integrate nell’architettura fin dall’inizio.