
Molti programmi di gestione flotte funzionano ancora su fogli di calcolo, telefonate e una manciata di dashboard di fornitori scollegate tra loro. Le operations sentono per prime il peso del problema. La spesa per il carburante aumenta gradualmente. Le revisioni degli incidenti arrivano in ritardo. I dispatcher aggirano a memoria piani di percorso sbagliati. I team di compliance inseguono i documenti a posteriori invece di modellare il processo a monte.
Da un punto di vista sistemico, non è solo un problema di strumenti. È un problema di controllo. L’organizzazione non dispone di un modo affidabile per trasformare i dati dei veicoli, l’attività dei conducenti, i segnali di manutenzione e le regole di policy in decisioni ripetibili.
Un programa di gestione flotte va considerato soprattutto come un sistema operativo per le operazioni di trasporto, non come una singola applicazione. Combina hardware di bordo, feed telematici, software di workflow, livelli di reporting, controlli di sicurezza e i processi umani che li circondano. Se anche solo uno di questi livelli è debole, l’intero programma diventa rumoroso, costoso e difficile da fidare.
Questo è uno dei motivi per cui la categoria continua a espandersi. Il mercato statunitense della fleet management è stato valutato 19,47 miliardi di dollari nel 2020 e si prevede che raggiungerà 52,5 miliardi di dollari entro il 2030, con un CAGR del 10,6%, a conferma di una più ampia adozione di software di flotte e telematica secondo le statistiche sulla gestione flotte di IntelliShift.
Per CTO e responsabili operations, la domanda importante non è se il software debba far parte delle operazioni di flotta. Lo è già. La domanda è se il programma sottostante sia progettato per scalare in sicurezza, integrarsi in modo pulito e sopravvivere alla complessità del mondo reale.
Questo conta ancora di più nei settori in cui i dati di mobilità, la logica dei percorsi e l’intelligence operativa stanno diventando asset strategici. Il lavoro su sistemi di smart mobility e prodotti di trasporto connessi continua a rafforzare la stessa lezione. Il vantaggio duraturo raramente deriva da una dashboard accattivante. Deriva da architettura, governance e rilascio disciplinato.
Introduzione oltre i punti su una mappa
Una mappa piena di icone di veicoli in movimento fa colpo in demo. In produzione, è solo una piccola parte del lavoro.
Un vero programma di gestione flotte deve rispondere a domande più difficili. Quali veicoli sono sottoutilizzati. Quali percorsi generano inutili tempi di inattività. Quali conducenti necessitano di coaching prima che un assicuratore o un ente regolatore imponga misure correttive. Quali attività di manutenzione possono attendere e quali stanno diventando un rischio di fermo. Quali dati possono essere conservati e quali espongono a rischi per la privacy.
Il problema operativo è il coordinamento
La maggior parte dei problemi di flotta non è isolata. Si sommano.
Un intervento di servizio in ritardo influisce sull’esecuzione del percorso. Un piano di percorso scadente aumenta i tempi di inattività. Dati diagnostici mancanti rendono la manutenzione reattiva. Controlli deboli sull’identità espongono i dati dei conducenti. Il reporting manuale rompe l’auditabilità. I team acquistano quindi un altro strumento per l’ultimo punto dolente e creano un’ulteriore lacuna di integrazione.
Un programma di gestione flotte funziona quando operations, compliance e engineering si fidano tutti dello stesso modello dati sottostante.
Questo cambia il modo in cui si progetta il programma. Si smette di chiedere un elenco di funzionalità e si iniziano a porre domande di sistema:
- Acquisizione dati: Quali segnali provengono da dispositivi, app mobili e terze parti?
- Logica decisionale: Dove risiedono avvisi, soglie ed eccezioni?
- Percorsi d’azione: Chi riceve un problema di manutenzione, una deviazione di percorso o una violazione di compliance?
- Governance: Quali record devono essere conservati, minimizzati, revisionati o eliminati?
- Resilienza: Cosa succede quando un dispositivo va offline, un feed arriva in ritardo o un’integrazione fallisce?
Cos’è davvero un programma moderno
A livello dirigenziale, la definizione utile è semplice. Un programma di gestione flotte è un insieme coordinato di regole di business, servizi software, endpoint hardware e workflow operativi che aiuta l’organizzazione a gestire asset, conducenti, sicurezza, manutenzione, compliance e costi nel tempo.
La differenza conta perché acquistare software senza progettazione del programma di solito produce tre esiti:
- Visibilità senza controllo: i team vedono la flotta ma non riescono ad agire in modo coerente su ciò che vedono.
- Automazione senza governance: gli avvisi scattano, ma nessuno è responsabile del workflow o della traccia di audit.
- Dati senza contesto: arrivano telemetrie grezze, ma finanza, compliance e operations continuano a lavorare in sistemi separati.
L’approccio migliore è architetturale. Progettare per valore di lungo periodo, non per le slide del vendor.
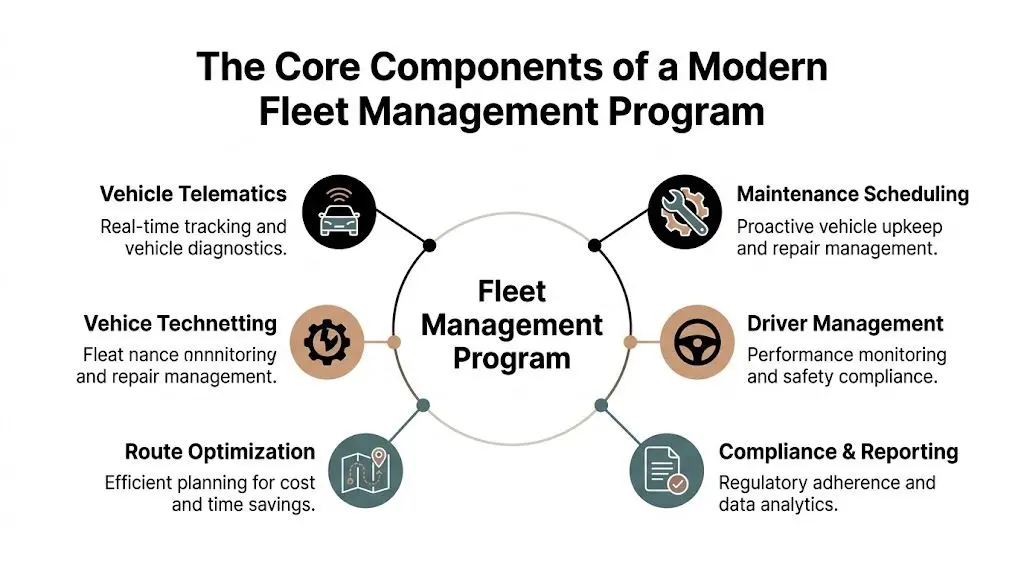
I componenti fondamentali di un programma moderno di gestione flotte
Un programma di gestione flotte robusto di solito si articola attorno a un numero ristretto di capacità core. I nomi cambiano in base al vendor. Le responsabilità no.
Telematica veicolare come livello dati
La telematica è il sistema nervoso operativo. Senza di essa, la maggior parte delle analisi a valle è una congettura.
Inoltre non è più una nicchia. L’83% delle flotte statunitensi intervistate utilizza strumenti telematici, e il 42% delle flotte ha riportato incidenti di sicurezza significativamente inferiori dopo l’implementazione, mentre il monitoraggio del comportamento dei conducenti ha ridotto i costi delle richieste di risarcimento per incidenti del 50% secondo le statistiche sulla gestione flotte di Expert Market.
Quel livello di adozione dice qualcosa di importante. La telematica non è più il fattore distintivo. Lo è l’uso efficace dei dati telematici.
Una buona progettazione telematica si concentra su:
- Qualità del segnale: GPS, contachilometri, codici guasto, ore motore e timestamp degli eventi devono essere abbastanza coerenti per l’uso operativo.
- Ciclo di vita del dispositivo: provisioning, gestione firmware, sostituzione e supporto contano tanto quanto la dashboard.
- Contratti dati: se i campi cambiano senza notifica, tutto ciò che sta a valle si rompe. Reporting, avvisi e funzionalità di machine learning dipendono tutti da schemi stabili.
Ciò che non funziona è trattare la telematica come un feed isolato usato solo dal team trasporti.
Asset tracking a supporto delle decisioni
I dati di localizzazione hanno usi evidenti, ma il loro pieno valore emerge dal contesto. La posizione di un veicolo conta quando può essere collegata all’aderenza al percorso, alle regole di geofencing, agli aggiornamenti ETA, all’uso non autorizzato e al workflow rivolto al cliente.
In pratica, questo significa che l’asset tracking dovrebbe rispondere a domande come:
- Il veicolo è dove dice il piano che dovrebbe essere?
- È entrato o uscito da una zona controllata?
- L’asset è fermo perché il lavoro è in corso o perché il processo è fallito?
- La deviazione dal percorso giustifica un intervento?
Di solito questo richiede logica geospaziale, elaborazione degli eventi e interfacce mappa ben progettate, non solo il tracciamento di coordinate. I team che sviluppano software ricco di localizzazione spesso prendono in prestito pattern dall’architettura dei sistemi informativi geospaziali perché l’intelligence su percorsi e asset supera rapidamente i semplici widget di mappe.
Manutenzione e monitoraggio dello stato
La manutenzione è il punto in cui molti programmi rivelano se sono davvero maturi operativamente o ancora reattivi.
Un sistema utile non si limita a registrare le riparazioni completate. Correlaziona piani di manutenzione, codici guasto, risultati delle ispezioni, utilizzo dei ricambi e storico dei fermi. È così che la manutenzione diventa una funzione di pianificazione invece di un’interruzione costante.
Tre scelte di progettazione sono importanti:
| Componente | Cosa funziona | Cosa fallisce |
|---|---|---|
| Trigger di servizio | Combinare regole di calendario, chilometraggio, ore motore ed eventi di guasto | Affidarsi solo ai promemoria del calendario |
| Workflow dell’officina | Usare lavori strutturati, ricambi, stati e approvazioni | Tracciare le riparazioni in thread di email |
| Storico del veicolo | Mantenere una timeline unificata dell’asset | Suddividere i record tra vendor e fogli di calcolo |
Ottimizzazione di routing e dispatch
Il routing è il punto in cui il software ha un effetto operativo diretto. Un piano di percorso non è solo un esercizio di mappa. Determina tempo, carburante, qualità del servizio e spesso affaticamento del conducente.
I sistemi di routing solidi tengono conto dei vincoli reali. Tipo di veicolo. Carico. finestre temporali del cliente. restrizioni urbane. esposizione alle condizioni meteo. pattern di congestione noti. logica di hand-off tra dispatch e conducente.
Regola pratica: se i dispatcher aggirano regolarmente l’ottimizzatore per abitudine, al modello manca il contesto di business.
La logica dei percorsi dovrebbe essere ispezionabile. L’ottimizzazione black-box spesso sembra brillante finché i team non devono spiegare perché un percorso è cambiato, perché una fermata è stata riprioritizzata o perché un conducente presenta un sovraccarico persistente.
Compliance e reporting
Le funzionalità di compliance tendono a essere sottofinanziate all’inizio e sovrafinanziate alla fine, dopo un problema di audit o un incidente.
È l’opposto di ciò che serve. In un programma di gestione flotte ben progettato, la compliance è incorporata nel workflow. I limiti delle ore di servizio, i report di ispezione veicolo del conducente, le verifiche delle licenze, i registri degli incidenti e le tracce di audit dovrebbero essere acquisiti nel punto in cui il lavoro avviene.
La chiave è evitare il “reporting per ricostruzione”. Se gli utenti completano il lavoro in un sistema e le evidenze di compliance vengono assemblate successivamente da screenshot, PDF e caselle di posta, il programma è fragile.
Il livello di reporting dovrebbe produrre:
- Evidenza operativa: chi ha fatto cosa, quando e su quale asset
- Evidenza regolatoria: record allineati ai requisiti di conservazione e audit
- Viste manageriali: report di eccezione, indicatori di trend e code di rischio non risolte
Si tratta di output diversi derivanti dallo stesso storico degli eventi sottostante. Costruire correttamente lo storico rende il reporting semplice. Costruirlo male lo trasforma in un progetto permanente di pulizia dati.
Architettura di sistema per operazioni di flotta scalabili
Le decisioni di architettura emergono in seguito sotto forma di costi operativi, problemi di integrazione e frequenza degli incidenti. Ecco perché i sistemi di flotta meritano lo stesso rigore di qualsiasi altra piattaforma critica per il business.
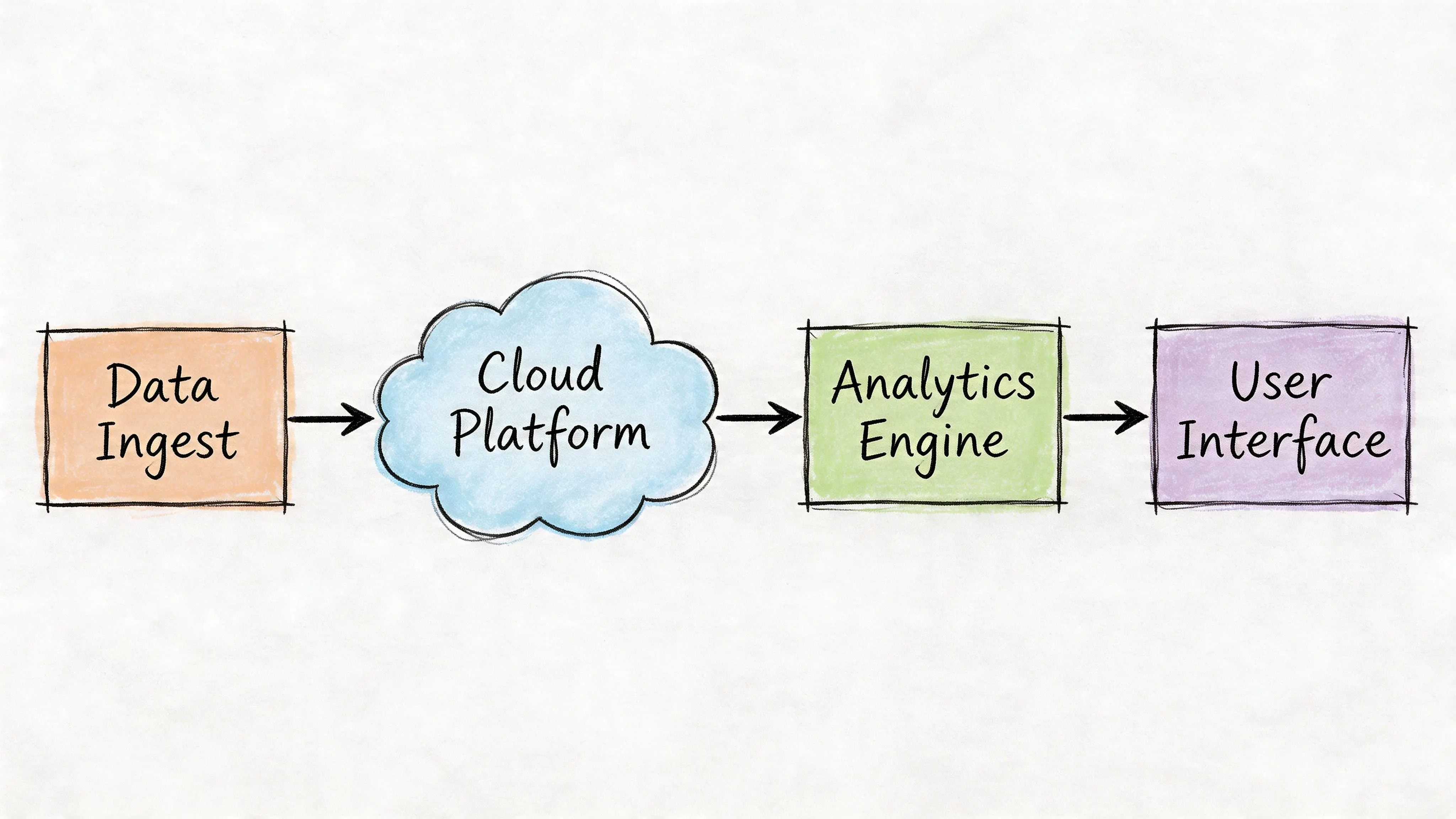
Parti dal flusso dei dati, non dal numero di servizi
Le piattaforme fleet ingeriscono dati rapidi, irregolari e spesso inaffidabili. I dispositivi inviano aggiornamenti di posizione, segnali motore ed eventi di stato. Le app mobili aggiungono report di ispezione e foto. I sistemi esterni contribuiscono con record di carburante, HR, payroll ed ERP. Nessuna di queste fonti arriva con tempistiche perfette.
Questa realtà rende il flusso degli eventi più importante dell’ideologia sui monoliti o sui microservizi.
Un monolite modulare è spesso il punto di partenza giusto quando l’organizzazione ha bisogno di velocità, ownership chiara e meno componenti in movimento. È più semplice da debuggare, più facile da distribuire e di solito sufficiente finché i workflow stanno ancora stabilizzandosi.
I microservizi guadagnano il loro posto più avanti, quando una o più di queste condizioni diventano vere:
- L’ingestione scala in modo diverso dal resto del sistema
- I carichi di routing o analytics richiedono caratteristiche runtime separate
- I domini regolamentati richiedono un isolamento più rigoroso
- Team diversi possono governare i confini dei servizi con disciplina
API aperte e supporto ai protocolli contano fin dall’inizio
Il tracciamento GPS quasi in tempo reale tramite integrazioni telematiche e API aperte può ridurre i costi del carburante fino al 16% grazie alla riduzione dei tempi al minimo e a un routing migliore, e le piattaforme scalabili devono supportare i dati motore OBD-II e J1939 secondo ABI Research sulle funzionalità dei sistemi di fleet management.
La lezione architetturale non riguarda solo il risparmio. Riguarda l’interoperabilità.
Se la tua piattaforma non è in grado di ingerire i dati dei dispositivi in modo pulito, normalizzarli ed esporli tramite API documentate, ogni futura integrazione diventa una soluzione ad hoc. I collegamenti con ERP, la riconciliazione delle fuel card, i vendor di manutenzione, gli adeguamenti payroll e i portali clienti diventano tutti più difficili.
Un pattern di riferimento pratico
Un’architettura fleet affidabile spesso appare così:
- Livello di ingestione: gateway dei dispositivi, API mobile, importazioni batch ed endpoint webhook
- Backbone degli eventi: code o stream durevoli per telemetria, avvisi, ispezioni e cambiamenti di stato
- Servizi operativi: registro asset, logica di dispatch, flusso di lavoro di manutenzione, motore di conformità, gestione utenti
- Archivio analitico: dati temporali e adatti al reporting strutturati per dashboard e analisi dei trend
- Livello di esperienza: dashboard web, app per conducenti, console operative e consumatori di API esterne
Questo modello supporta uno dei comportamenti più preziosi nei sistemi di flotte. Un singolo evento può attivare più azioni controllate.
Per esempio, una violazione di geofence può creare un avviso operativo, aggiornare lo stato di un percorso, registrare un record di audit e aprire una coda di revisione delle eccezioni. L’evento accade una volta. Il sistema reagisce in diversi modi circoscritti.
Mantieni immutabile l’evento canonico. Le interpretazioni downstream possono cambiare. I fatti storici non dovrebbero.
La strategia di integrazione determina la manutenibilità
La maggior parte dei programmi di gestione flotte fallisce ai margini, non al centro.
Il prodotto core può sembrare valido, ma le integrazioni diventano fragili perché i team saltano il versioning, costruiscono dipendenze point-to-point o sovraccaricano un’unica API del vendor per tutto. Col tempo, i piccoli guasti si accumulano. Identità duplicate. ID asset non corrispondenti. registri carburante mancanti. timestamp incoerenti. attività di manutenzione orfane.
Un modello migliore prevede:
- Identificatori canonici per veicoli, conducenti, depositi e incarichi
- Livelli di adattamento attorno ai provider esterni
- Retry espliciti e gestione dei dead-letter
- Versioning dello schema per l’evoluzione dei messaggi e delle API
- Osservabilità sugli eventi ritardati, scartati o malformati
È meno glamour delle dashboard front-end, ma è il punto in cui un programma scalabile di gestione flotte diventa meno costoso da gestire e più sicuro da estendere.
Definire il successo con KPI e analisi del ROI
La maggior parte delle dashboard per flotte sembra piena di attività e risponde a pochissimo.
Mostrano attività sulla mappa, conteggi dei viaggi e lunghe liste di eventi. Raramente aiutano la leadership a decidere se il programma sta riducendo i costi, abbassando il rischio o migliorando la qualità del servizio in modo duraturo. Un programma di fleet management necessita di metriche che supportino l’azione, non la scenografia.
Le vanity metric creano falsa fiducia
Un errore comune è sopravvalutare le metriche perché sono facili da raccogliere.
Viaggi totali, avvisi totali, velocità media e conteggi grezzi dei login possono essere operativamente interessanti. Da soli, non dicono se il sistema sta funzionando. In alcuni casi mascherano il deterioramento. Più avvisi possono significare migliore rilevamento, comportamento peggiore o soglie rotte. Serve contesto.
Una progettazione efficace dei KPI parte dagli obiettivi di business e procede a ritroso. Se la finanza si preoccupa del controllo dei costi, allora tempo di inattività, aderenza al percorso, tempistiche di manutenzione e utilizzo del veicolo dovrebbero collegarsi alle categorie di costo già riconosciute dal team finance.
L’idling è un buon esempio. I moduli di gestione carburante che tracciano il costo per miglio e rilevano i tempi di inattività sono importanti perché l’idling può causare fino al 20% di spreco di carburante, e la digitalizzazione della manutenzione preventiva può ridurre le spese di riparazione del 25% tramite avvisi sui codici guasto telematici, secondo la guida ai requisiti di fleet management di Simply Fleet.
Usa insieme indicatori leading e lagging
Gli indicatori lagging ti dicono cosa è successo. Gli indicatori leading mostrano dove si sta formando il prossimo problema.
Una dashboard pratica ne ha normalmente bisogno di entrambi.
| Tipo di KPI | Esempio | Perché conta |
|---|---|---|
| Lagging | Spesa totale carburante per unità aziendale | Utile per la revisione finanziaria, scarsa per l’intervento quotidiano |
| Leading | Veicoli con sessioni ripetute di alto idling questa settimana | Indica un’azione prima che arrivi la bolletta mensile |
| Lagging | Downtime legato a guasti | Utile per analisi dei trend e decisioni sugli asset |
| Leading | Eccezioni dei codici guasto in attesa di revisione | Mostra se i team stanno agendo abbastanza presto |
| Lagging | Incidenti di conformità completati | Buono per audit e revisione retrospettiva |
| Leading | Invii di ispezioni in ritardo | Evidenzia il rischio di processo prima dell’escalation |
Costruisci dashboard per le decisioni, non per l’osservazione
Le dashboard dovrebbero rispecchiare chi deve agire.
I responsabili operativi hanno bisogno di code di eccezioni, deviazioni di percorso e utilizzo a livello di deposito. I responsabili della manutenzione hanno bisogno di avvisi sui guasti, servizi scaduti e schemi di riparazione ricorrenti. I dirigenti hanno bisogno di viste di trend collegate a margine, rischio e pianificazione degli asset.
Ecco perché una singola grande dashboard raramente funziona bene. Utenti diversi hanno bisogno di diverse porzioni degli stessi dati governati.
Usa poche regole di progettazione:
- Mostra chiaramente le soglie: Una metrica senza intervallo atteso non è utile.
- Mostra la responsabilità: Ogni eccezione dovrebbe avere un team o un ruolo responsabile.
- Supporta il drill-down: Le viste di sintesi dovrebbero collegarsi al record di asset, viaggio, conducente o incarico.
- Separa il rumore dalla priorità: Non ogni evento merita lo stesso peso visivo.
Se un KPI non cambia il comportamento di qualcuno, è un costo di reporting.
Una discussione matura sul ROI evita anche la trappola di promettere un unico numero universale di payback. Le operazioni di flotta variano troppo per questo. Il modo pratico per valutare il ROI è collegare cambiamenti operativi misurabili alle categorie di costo, alla riduzione del rischio e ai disservizi evitati nel tempo. Questo produce un business case più credibile e una roadmap più onesta.
Sfruttare AI e automazione per la gestione predittiva della flotta
Molte organizzazioni hanno già dati da telematica, ispezioni e log di manutenzione. Ciò che non hanno è un percorso sicuro dalla raccolta dati all’azione predittiva.
Quel divario conta più della scelta del modello.
La domanda sbagliata è se aggiungere l’AI
La domanda migliore è dove l’AI può migliorare un flusso di lavoro reale senza creare decisioni opache, dipendenze fragili o problemi di governance.
Questo è particolarmente importante nelle flotte con sistemi legacy. La guida a questa transizione è ancora scarsa. Il divario pratico consiste nell’integrare capacità predittive nelle operazioni esistenti senza sostituire tutto in una volta. I veicoli con programmi di manutenzione preventiva costano dal 25% al 35% in meno in riparazioni annuali, eppure molti team non hanno ancora un percorso di migrazione graduale per gli ambienti legacy, come osservato da Intangles sul passaggio dalla visibilità alla previsione.
La lezione è semplice. Non iniziare con una “trasformazione della piattaforma AI”. Inizia con un solo ciclo decisionale circoscritto e ad alto valore.
Buoni casi d’uso iniziali
La manutenzione predittiva è di solito il punto di partenza più forte. Gli input esistono già in molte flotte. Codici guasto, storico dei servizi, note di ispezione, modelli di utilizzo e registri di downtime possono supportare la prioritizzazione senza affidare il controllo completo a un modello.
Una prima versione sensata potrebbe fare questo:
- Ingerire i segnali: Prelevare eventi di guasto, intervalli di servizio e anomalie di ispezione in un’unica coda di revisione
- Valutare il rischio: Assegnare un punteggio agli asset per la revisione umana in base a combinazioni di pattern
- Attivare l’azione: Aprire raccomandazioni di manutenzione con evidenze allegate
- Raccogliere gli esiti: Registrare se i tecnici hanno confermato, scartato o riprogrammato il problema
Questo mantiene il modello all’interno di un workflow governato.
L’analisi del comportamento dei conducenti è un’altra area utile, ma richiede moderazione. Valutare i conducenti senza contesto crea risentimento e cattive decisioni. Condizioni stradali, tipo di veicolo, mix di percorso e pressione lavorativa influenzano tutti i pattern degli eventi. Usa l’AI per supportare coaching e revisione. Non lasciarla diventare un segnale del personale incontestabile.
L’ottimizzazione dei percorsi è allettante anch’essa, ma il rerouting dinamico può creare instabilità operativa se l’ottimizzatore ignora la realtà aziendale locale. I sistemi buoni preservano l’override umano, spiegano i cambi di percorso e limitano gli aggiustamenti automatici ai vincoli concordati.
Gli LLM aiutano di più sul bordo del workflow
I large language model sono spesso più utili attorno alle operazioni di flotta che non al centro dell’ottimizzazione stessa.
Per esempio, un LLM può:
- Riassumere i report di ispezione del veicolo del conducente per i supervisori
- Classificare le note di manutenzione in testo libero
- Redigere narrative delle eccezioni da storici di eventi strutturati
- Aiutare gli operatori a cercare tra policy, ispezioni e record degli incidenti
- Supportare i workflow di revisione delle frodi attorno a ricevute OCR e prove a supporto
Si tratta di attività ad alta frizione con revisione umana già integrata.
Per una panoramica tecnica utile di questi pattern nei sistemi connessi, il lavoro su AI e integrazione IoT nei prodotti operativi è un punto di riferimento migliore del marketing generico sull’AI.
Un breve esempio visivo aiuta qui:
Un modello di adozione più sicuro
Il percorso più affidabile è incrementale:
- Stabilizza i dati di origine
- Scegli un solo workflow decisionale
- Mantieni un umano nel ciclo di approvazione
- Registra prompt, output e azioni per l’audit
- Misura se il nuovo workflow supera quello vecchio
- Espandi solo dopo che la gestione delle eccezioni è affidabile
L’AI dovrebbe ridurre l’incertezza in un processo esistente. Non dovrebbe diventare un sostituto della progettazione del processo.
Questo approccio è più lento del tipico slogan “deploy AI ovunque”. È anche molto più probabile che sopravviva al primo contatto con le operazioni reali.
Integrare sicurezza e governance nel tuo programma
I sistemi di flotta gestiscono dati più sensibili di quanto molti team inizialmente realizzino. La posizione del veicolo può rivelare i pattern dei dipendenti. I record dei conducenti possono diventare dati HR. Le foto di ispezione possono contenere informazioni personali. L’integrazione con payroll, carte carburante e schedulazioni dei clienti amplia di nuovo la superficie di esposizione.
Ciò significa che sicurezza e governance non possono stare sopra il programma come aggiunte successive. Devono essere integrate nell’architettura e nel modello operativo.
Privacy by design nelle operazioni di flotta
Il giusto punto di partenza è la minimizzazione dei dati.
Raccogli ciò che il programma necessita per routing, sicurezza, manutenzione e conformità. Non raccogliere tutto solo perché il dispositivo può emetterlo. Un errore di progettazione comune è conservare per troppo tempo la cronologia di localizzazione ad alta granularità senza uno scopo chiaro, una policy di retention o un modello di accesso.
Per gli ambienti sensibili al GDPR, i team dovrebbero definire:
- Confini di finalità: Perché esiste ogni categoria di dato
- Regole di retention: Per quanto tempo i dati restano disponibili e perché
- Condizioni di accesso: Quali ruoli possono visualizzare dati personali, di percorso o diagnostici
- Gestione dei diritti degli interessati: Come vengono gestite, ove applicabile, le richieste di accesso, correzione o cancellazione
Privacy by design non è burocrazia. Influisce sulla progettazione dello schema, sul logging di audit, sui permessi dell’interfaccia e sull’automazione della retention.
Le minacce sono operative, non teoriche
Le piattaforme di flotta affrontano un profilo di minaccia misto. Alcuni attacchi prendono di mira la piattaforma software. Altri prendono di mira il bordo fisico e di rete.
Gli esempi includono:
- Accesso non autorizzato alla dashboard
- Dispositivi mobili compromessi
- Input telematici manomessi
- Spoofing o jamming del GPS
- Account interni con privilegi eccessivi
- Esfiltrazione da integrazioni di terze parti
La risposta pratica inizia con le basi fatte bene:
| Area di controllo | Cosa implementare |
|---|---|
| Identità | Autenticazione forte, controllo degli accessi basato sui ruoli, privilegio minimo |
| Protezione dei dati | Crittografia in transito e a riposo, gestione delle chiavi, registri di audit |
| Fiducia all’edge | Provisioning sicuro dei dispositivi, identità hardware, governance del firmware |
| Sicurezza delle applicazioni | Convalida degli input, gestione dei segreti, igiene delle dipendenze |
| Resilienza | Backup, pianificazione del failover, runbook di risposta agli incidenti |
Governance per ambienti regolamentati
Per i team che operano in Europa o servono settori regolamentati, la governance dovrebbe essere progettata tenendo conto di framework come GDPR, NIS2 e DORA.
Le implicazioni pratiche variano da organizzazione a organizzazione, ma alcuni schemi sono ampiamente utili:
- Tracciabilità: è necessaria una catena chiara dall’evento all’azione dell’utente fino al record conservato.
- Resilienza operativa: i flussi di lavoro principali dovrebbero degradare in modo sicuro quando un provider, un’API o una classe di dispositivo si guasta.
- Supervisione di terze parti: le integrazioni dei fornitori richiedono revisione del rischio, chiarezza contrattuale e confini tecnici.
- Prontezza agli incidenti: i team dovrebbero sapere come contenere, indagare e comunicare un incidente di telemetria o di accesso.
Le revisioni di sicurezza dovrebbero includere l’edge della flotta, la piattaforma cloud e le persone che operano i flussi di lavoro. Escludere anche solo uno di questi elementi dà una falsa sensazione di copertura.
Scelte progettuali che riducono il rischio a lungo termine
Alcune scelte si ripagano più volte.
Usa viste basate sui ruoli in modo che addetti alla pianificazione, tecnici, responsabili della conformità ed executive non vedano tutti gli stessi dati per impostazione predefinita. Separa la telemetria grezza dalle viste operative rivolte all’utente. Registra le azioni amministrative. Rendi eseguibili le regole di conservazione dei dati invece di limitarle a una semplice policy. Considera le integrazioni come confini di fiducia, non come innocue funzionalità di comodità.
Le implementazioni ingenue spesso falliscono perché centralizzano i dati ma decentralizzano la responsabilità. Tutti possono vedere tutto. Nessuno si occupa della conservazione. Le eccezioni possono essere modificate senza traccia. I diritti di accesso si accumulano e non vengono mai rimossi.
Non si tratta solo di cattive pratiche. Nel momento sbagliato, diventa un problema legale, operativo e reputazionale.
Una roadmap pragmatica per l’implementazione
Il modo più rischioso di lanciare un programma di fleet management è quello che molte organizzazioni scelgono ancora. Acquistare una grande piattaforma, distribuirla ovunque, imporre a ogni team un nuovo processo e sperare che il reporting migliori entro un trimestre.
Di solito non accade.
Un approccio più solido è graduale, guidato dalle evidenze e deliberatamente noioso. L’obiettivo è il controllo iniziale, non la complessità iniziale.
Fase uno attraverso scoperta e validazione
Inizia mappando il modello operativo attuale così come funziona davvero, non come dice la policy che funzioni.
Parla con pianificazione, manutenzione, compliance, finanza e autisti. Esamina da dove origina il dato, dove vengono prese le decisioni e dove il lavoro esce dal sistema per poi rientrare più tardi tramite email, carta o fogli di calcolo. Quelle interruzioni mostrano dove il programma è debole.
Raccogli in anticipo un piccolo insieme di decisioni:
- Risultati principali: controllo dei costi, sicurezza, manutenzione, conformità, qualità del servizio
- Asset inclusi: classi di veicoli, depositi, unità aziendali
- Integrazioni critiche: fornitore di telematica, ERP, carte carburante, HR, fornitori di manutenzione
- Elenco dei vincoli: budget, obblighi contrattuali, limitazioni dei dispositivi, residenza dei dati, regole sulla privacy
L’output dovrebbe essere una problem statement prioritizzata, non un enorme catalogo dei requisiti.
Fase due attraverso un pilot controllato
Un pilot dovrebbe essere abbastanza circoscritto da consentire un apprendimento rapido e abbastanza ampio da far emergere la complessità reale.
Scegli un sottoinsieme definito di veicoli, utenti e flussi di lavoro. Strumenta correttamente il pilot. Questo include processi di supporto, controlli sulla qualità dei dati e registrazione dei problemi, non solo test dell’interfaccia utente.
Buone domande per il pilot includono:
- I segnali in ingresso sono abbastanza affidabili per l’uso operativo?
- Quali avvisi generano azione e quali generano rumore?
- Autisti e addetti alla pianificazione si fidano del flusso di lavoro?
- I registri di manutenzione e conformità sono completi senza ricostruzione manuale?
- Quali ipotesi di integrazione hanno fallito per prime?
Un pilot non serve solo a dimostrare la tecnologia. Serve a mettere in luce il debito di processo nascosto.
Fase tre attraverso un rollout graduale
Distribuisci per confine operativo, non per entusiasmo organizzativo.
Questo può significare un deposito alla volta, un tipo di veicolo alla volta o un flusso di lavoro alla volta. Mantieni visibili sia i processi vecchi sia quelli nuovi durante la transizione, ma evita un funzionamento in doppio regime indefinito. Se i sistemi paralleli durano troppo a lungo, il programma non si stabilizza mai.
Una checklist pratica per il rollout:
- Conferma la mappatura dei dati per veicoli, utenti e sistemi esterni
- Forma per ruolo invece di inviare guide generiche della piattaforma
- Definisci la responsabilità del supporto per problemi di hardware, software e processo
- Monitora le eccezioni ogni giorno durante le prime ondate di rollout
- Rivedi i permessi prima che ogni nuovo team vada live
- Ritira gli artefatti obsoleti come fogli di calcolo duplicati e log manuali
Fase quattro attraverso il miglioramento continuo
Una volta che il sistema è live, inizia il vero lavoro.
Le operazioni di flotta cambiano. Le rotte si modificano. i depositi si fondono. le normative evolvono. i fornitori cambiano API. l’hardware invecchia. Se il programma non riesce ad assorbire questi cambiamenti, si degraderà.
Usa un ciclo di revisione regolare con un piccolo gruppo interfunzionale. Esamina la qualità dei dati, i trend delle eccezioni, i workaround degli utenti e i problemi di integrazione irrisolti. Poi apporta modifiche misurate.
I programmi di fleet più duraturi migliorano attraverso molte piccole correzioni, non attraverso reinvenzioni periodiche.
Questa è anche la fase in cui AI e automazione più profonda diventano più sicure da introdurre. A quel punto, i flussi di lavoro principali, le tracce di audit e il modello di responsabilità dovrebbero già essere abbastanza stabili da supportarle.
Conclusione Costruire un Programma Fleet a Prova di Futuro
Un solido programma di fleet management non è l’acquisto di una dashboard. È un sistema operativo di lunga durata.
I programmi che resistono nel tempo condividono alcuni tratti. Considerano la telematica come una fonte di dati all’interno di un’architettura più ampia. Progettano i flussi di lavoro attorno alle decisioni e alla responsabilità. Misurano i risultati con KPI che supportano l’azione. Introducono l’AI con cautela, all’interno di processi governati. E trattano privacy, sicurezza e resilienza come requisiti di progettazione fin dal primo giorno.
Questa è la differenza tra un software che sembra moderno e un programma che migliora le operazioni.
Per CTO, product leader e team operativi, l’obiettivo pratico è semplice. Costruire un sistema di cui le persone possano fidarsi quando i dati sono disordinati, le integrazioni falliscono, arrivano gli audit e il business cambia. Se l’architettura può gestire queste condizioni, il programma di fleet management diventa una risorsa anziché un altro peso di manutenzione.
Se stai pianificando una piattaforma per la flotta, un dashboard operativo o un workflow abilitato dall’AI e vuoi un partner tecnico che dia priorità a manutenibilità, privacy e delivery pragmatico, Devisia può aiutarti a trasformare l’idea in software affidabile.