
A modern document management system (DMS) is not a digital filing cabinet. It is the foundational architecture for an organization’s security, operational resilience, and automation capabilities. A properly engineered DMS provides immutable version control, granular access management, and auditable workflows—transforming static files into strategic assets.
For technical and business leaders, the distinction is critical. Treating a DMS as a simple IT expense ignores its role in mitigating risk and enabling future innovation.
The Operational Risk of Unstructured Data
Reliance on shared drives, spreadsheets, and email chains for critical information introduces significant business risk. This legacy approach creates data silos, versioning chaos, and security vulnerabilities that are incompatible with modern operational requirements.
The consequences impact both technical and business functions. CTOs cannot integrate fragmented data into coherent applications. Compliance managers face audit failures due to the absence of verifiable access logs. Product leaders are unable to leverage disorganized, low-quality documents to train reliable AI models, stifling innovation.
The Problem: Lack of Control and Verifiability
The core issue is a fundamental lack of control and visibility over critical information assets. Consider a scenario where a master services agreement exists in three different locations: an engineer’s local machine, a shared project folder, and a project manager’s email archive. The absence of a single source of truth creates significant operational friction.
This is a symptom of systemic architectural deficiencies, leading to a cascade of problems:
- Version Control Failure: Teams waste engineering cycles resolving discrepancies between document versions, leading to costly errors and rework.
- Security Vulnerabilities: Sensitive data stored in general-purpose drives often lacks the granular access controls required, exposing it to unauthorized internal or external access.
- Compliance and Audit Deficiencies: Proving compliance with regulations like GDPR or NIS2 is nearly impossible without immutable audit logs that track data access and modification.
- Inefficient Workflows: Manual document routing for approvals creates bottlenecks that delay projects and impede operational velocity.
A Strategic Shift in Perspective
A well-architected document management system addresses these issues by enforcing structure, security, and process automation at an architectural level. This is not about adding overhead; it is about enabling modern digital operations. Market data reflects this understanding. North America, for instance, dominated the global DMS market with a 40.8% share in 2024, representing USD 3.5 billion in revenue.
For organizations building custom software, the trend is clear. The U.S. market is projected to grow at a 14.9% CAGR from 2025 to 2030, driven by regulated industries demanding secure and compliant data infrastructure. The technical imperative is undeniable; you can explore more about these market dynamics for a deeper analysis.
A robust DMS transforms documents from static, passive files into active, intelligent assets. It provides the architectural foundation needed to build reliable, secure, and scalable B2B applications, turning information into a competitive advantage.
The Architectural Blueprint of a Modern DMS
A modern document management system is a complex assembly of interconnected engineering components, not a monolithic application. For technical leaders, understanding this architecture is essential to evaluate trade-offs and move beyond marketing claims to assess underlying capabilities. This blueprint deconstructs the core patterns of a robust DMS.
The system’s lifecycle begins with ingestion—the process of securely incorporating a document into the system via a flexible, auditable pipeline.
Ingestion and Metadata Extraction
Documents originate from diverse sources: user uploads, automated system outputs, and scanned physical records. A well-designed ingestion layer must accommodate these varied workflows programmatically.
- APIs: For system-to-system integration, RESTful or GraphQL APIs are mandatory. They serve as the programmatic backbone for automated workflows, allowing other applications to push documents into the DMS without manual intervention.
- Scanning and OCR: For physical documents, Optical Character Recognition (OCR) is required. Modern OCR engines leverage computer vision to convert scanned images into machine-readable, searchable text.
- Direct Connectors: Integrations with email servers or cloud storage providers (e.g., Google Drive, Dropbox) enable automated document capture, eliminating manual and error-prone processes.
Once ingested, the document must be understood. Metadata extraction is the process where the DMS automatically parses the file to identify key attributes: author, creation date, document type, and even domain-specific data points like contract values or invoice numbers. This metadata is the foundation for precise search, retrieval, and governance.
Without a coherent architectural approach, the result is data chaos. The following risk map illustrates the common failure modes of a disorganized system.
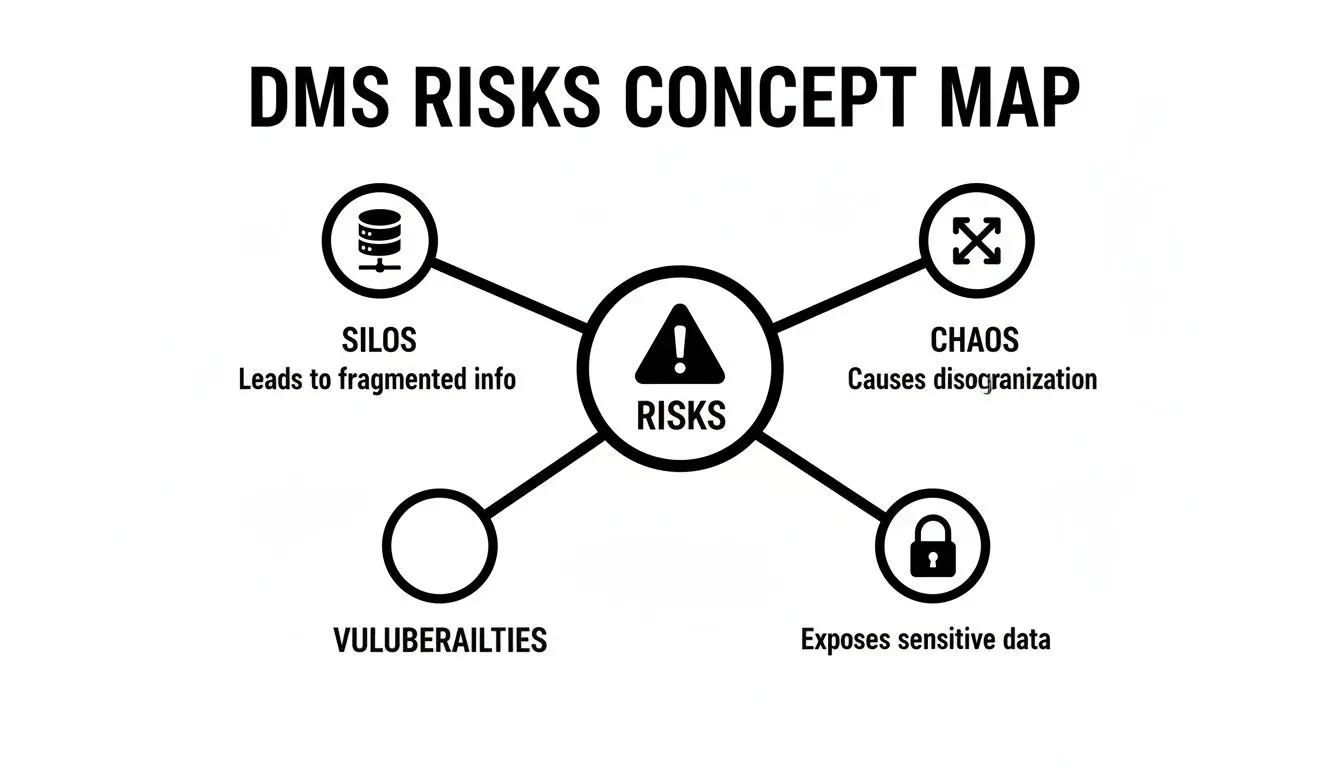
This visualization highlights a direct causal link: unstructured data leads to information silos, workflow breakdowns, and critical security vulnerabilities. A robust DMS architecture is engineered specifically to mitigate these risks.
Indexing and Storage Layers
With content and metadata prepared, the next architectural challenge is enabling efficient retrieval. A naive approach using standard database queries will not scale. This requires dedicated, high-performance indexing engines like Elasticsearch or Apache Solr.
These engines create an inverted index, which maps content to its location within documents, enabling near-instantaneous, full-text search across millions of files. The primary trade-off is between indexing granularity and resource consumption; deeper indexing provides superior search capabilities but requires more processing and storage overhead.
The choice of storage layer is equally critical, with significant implications for cost, durability, and security.
The core architectural principle is to decouple metadata and the search index from the binary files themselves. This separation of concerns allows each component to be optimized for its specific function—fast queries for the index, and durable, cost-effective storage for the files.
Modern architectures predominantly utilize object storage solutions like Amazon S3 or Google Cloud Storage. They offer near-infinite scalability, built-in redundancy, and a cost-effective, consumption-based pricing model. Attempting to store large volumes of files on a traditional server file system introduces single points of failure and significant scaling challenges.
Version Control Models
Finally, a DMS must provide robust version control. Two primary architectural patterns address this requirement:
- Database Snapshots: This model saves a complete copy of the document for each revision and tracks the version history in a database table. While simple to implement, it can lead to significant storage consumption if not managed with care through lifecycle policies.
- Git-based Models: Inspired by software development, some systems use a Git-like model to store only the differences (diffs) between versions. This approach is highly efficient for text-based documents but introduces greater architectural complexity.
The optimal choice depends on the specific document types being managed and the required granularity of the version history.
Each architectural decision—from ingestion to versioning—involves critical trade-offs that dictate the system’s performance, security, and scalability. To understand how these components can be composed as independent services, explore our Service-Oriented Architecture in our comprehensive guide.
Navigating The Build Vs Buy Decision
The implementation of a document management system presents a fundamental strategic decision: acquire an off-the-shelf product or invest in a custom-built solution. This choice extends beyond a simple cost-benefit analysis; it determines an organization’s control over its architecture, risk exposure, and long-term operational agility.
A pragmatic decision requires a rigorous assessment of internal technical capabilities, unique workflow requirements, and strategic objectives. A miscalculation can result in vendor lock-in with a tool that constrains business processes, or worse, a costly and unmaintainable custom build that becomes a persistent drain on engineering resources.
The Case For Buying An Off-the-Shelf DMS
Procuring a commercial DMS is typically the fastest path to deployment. These platforms provide immediate access to a feature set that has been validated across a large customer base.
The primary advantages are:
- Rapid Deployment: A commercial system can be operational within days or weeks, compared to the months or years required for a custom build. This accelerates time-to-value.
- Built-in Compliance and Security: Reputable vendors invest heavily in meeting regulatory standards such as GDPR, HIPAA, and NIS2. Core features like audit trails, retention policies, and access controls are pre-built, reducing the internal compliance burden.
- Predictable Costs: Subscription models provide a clear operating expense (OpEx) rather than a large, uncertain capital expenditure (CapEx). The vendor is responsible for all maintenance, updates, and security patching.
However, this convenience comes with significant trade-offs. Control over the system’s architecture and roadmap is relinquished to a third party. Vendor lock-in presents a substantial risk, making future migration to another platform technically difficult and financially prohibitive. Furthermore, the system’s functionality is constrained by the vendor’s design, which may not align perfectly with specific business processes.
The Strategic Rationale For Building A Custom DMS
Building a custom document management system is a significant engineering investment that offers the ultimate benefit: complete control. This approach is justifiable for organizations with highly specialized workflows, complex integration requirements, or stringent security postures that cannot be met by off-the-shelf products.
A custom build enables an organization to:
- Achieve Perfect Workflow Alignment: The system can be designed to precisely model existing business processes, avoiding the need for teams to adapt their workflows to a generic tool. This can result in significant long-term efficiency gains.
- Maintain Full Architectural Control: The internal team dictates the technology stack, security implementation, and all integration points. This is essential when the DMS must be deeply embedded within a proprietary software ecosystem.
- Own The Intellectual Property: The resulting system is a strategic asset owned by the company, free from recurring licensing fees and dependency on a vendor’s viability.
The risks, however, are substantial. The upfront investment in development is significant. Critically, the organization assumes total responsibility for ongoing maintenance, security patching, and scalability. A naive approach to security in a custom build could expose sensitive data, leading to catastrophic compliance failures and reputational damage.
The decision to build is not merely technical; it is a long-term commitment to owning, maintaining, and securing a mission-critical infrastructure component. This requires dedicated engineering resources and deep security expertise.
The following table provides a direct comparison of these trade-offs. The choice of data residency also has its own set of implications, which you can explore in our guide on Cloud Computing Vs On-Premise solutions.
Build Vs Buy: A Strategic Comparison For DMS Implementation
Choosing between building a custom DMS and buying an off-the-shelf solution involves a series of critical trade-offs. This table breaks down the key considerations to help guide your decision-making process.
| Consideration | Off-the-Shelf (Buy) | Custom Solution (Build) |
|---|---|---|
| Time to Value | Fast (days to weeks) | Slow (months to years) |
| Initial Cost | Low (subscription fees) | High (development resources) |
| Long-Term Cost | Predictable but ongoing OpEx | Variable; includes maintenance, hosting, and personnel |
| Workflow Fit | General; may require process adaptation | Bespoke; tailored to exact needs |
| Control & Flexibility | Limited to vendor’s offerings | Complete architectural and feature control |
| Security Responsibility | Shared with vendor | Entirely internal |
| Vendor Lock-in | High risk | No risk |
| Maintenance Burden | Handled by vendor | Internal responsibility |
There is no universally correct answer. The optimal path depends on an organization’s specific context, resources, and strategic priorities. Buying offers speed and predictability, whereas building provides unparalleled control and a perfect process fit, but at a significantly higher cost and risk.
Integrating AI for Intelligent Document Processing
A traditional document management system stores files but lacks any understanding of their content. Integrating Artificial Intelligence (AI) transforms the DMS from a passive repository into an active knowledge base, enabling the system to interpret and act on the information contained within the documents.
This is not a superficial feature enhancement. It is a fundamental architectural shift that unlocks the value embedded in contracts, reports, and invoices at scale.
The primary problem AI solves is human limitation. No team can manually read, classify, and extract insights from millions of documents. Intelligent document processing (IDP) automates these tasks, turning the DMS into a dynamic information asset. The IDP market is projected to grow from $1.8 billion in 2023 to $2.9 billion by 2032, reflecting this shift.
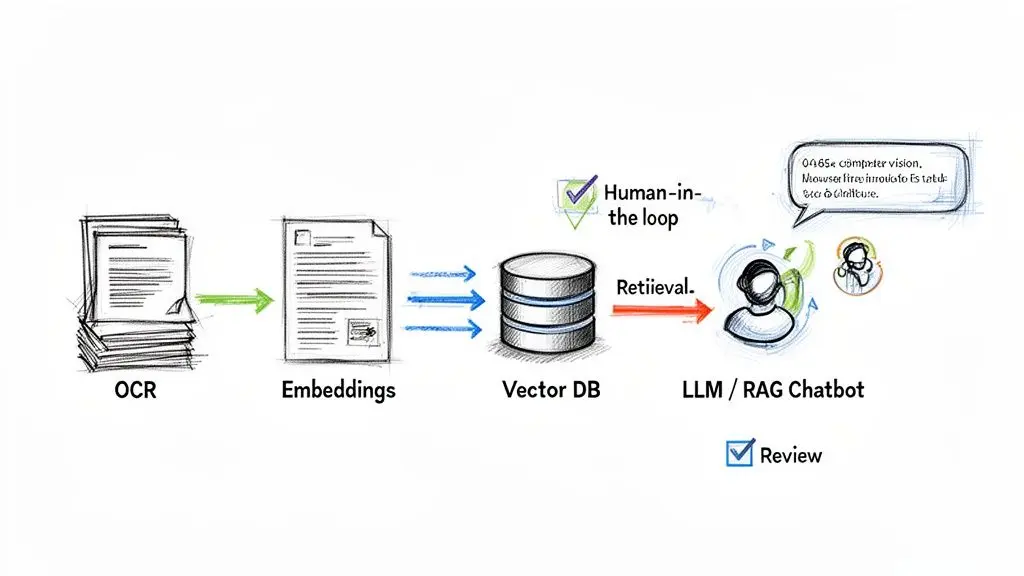
This workflow illustrates how static files can be transformed into an interactive source of verifiable information. Successful implementation depends on specific architectural components and a pragmatic approach to managing AI risks.
Beyond Keywords With Semantic Search
Standard keyword search is brittle; it fails if the user does not know the precise terminology within a document. The user receives no results and incorrectly concludes the information is unavailable.
Semantic search resolves this by understanding conceptual meaning, not just lexical matches.
This is achieved using embedding models. When a document is ingested, a model converts its text into a high-dimensional vector—an “embedding”—that numerically represents its semantic meaning. These embeddings are stored and indexed in a specialized vector database.
During a search query:
- The user’s query is also converted into an embedding.
- The system performs a nearest-neighbor search in the vector database to find document embeddings that are semantically “closest” to the query embedding.
- The most relevant documents are returned, even if they lack the exact keywords used in the query.
A user searching for “liability limitations in our supplier agreements” can thus retrieve a contract that only uses the legal phrase “caps on indemnity”—a connection a keyword search would miss.
Building Knowledge Bases With RAG
A powerful application of AI in a DMS is the creation of an internal question-answering system using a Retrieval-Augmented Generation (RAG) architecture. RAG mitigates the risk of Large Language Model (LLM) “hallucinations” by grounding their responses in the factual content of an organization’s own documents.
The process is straightforward in concept but requires careful engineering:
- A user submits a natural language question (e.g., “What is our data breach notification policy?”).
- The system uses semantic search to retrieve the most relevant text chunks from the document corpus.
- These retrieved chunks are then passed to an LLM along with the original question and a prompt instructing it to “Answer the user’s question using only the provided information.”
This architecture transforms the document library into a verifiable knowledge base that can be queried using natural language.
Architectural Prerequisites and Risks
Integrating an LLM is not a plug-and-play exercise. It requires a specific technology stack and a pragmatic understanding of the system’s limitations.
A naive approach that connects an LLM directly to a document store is a recipe for inaccurate answers and data leaks. The architecture must be designed for control, verification, and safety.
Key technical components include:
- Vector Database: A system for storing and querying embeddings is required. Options include dedicated solutions like Pinecone or Weaviate, or extensions like pgvector for PostgreSQL.
- Orchestration Frameworks: Tools like LangChain or LlamaIndex provide the necessary abstractions to manage the complex sequence of prompts, retrievals, and model interactions in a RAG pipeline.
- Advanced OCR: For unstructured or scanned documents, modern computer vision models are necessary to accurately extract structured text and data before it can be processed by an LLM.
Crucially, no AI system is infallible. A human-in-the-loop (HITL) process is non-negotiable for high-stakes applications like contract analysis or compliance verification. This involves building interfaces for domain experts to review, correct, and approve AI-generated outputs, creating a feedback loop that improves system accuracy over time.
Embedding Security and Compliance by Design
In any serious document management system, security is not an add-on feature; it is an architectural prerequisite. Treating security and privacy as afterthoughts is a naive strategy that leads to data breaches and regulatory penalties.
A defensible system embeds these protections into its core architecture from the initial design phase. Every component, from API endpoints to storage buckets, must be engineered with a security-first principle. This is the distinction between a system that is secure by design and one that is merely secure by chance.
Foundational Security Layers
A secure DMS architecture is built upon several non-negotiable layers. These are not best practices but the baseline requirements for handling sensitive B2B data.
-
Robust Access Control: Granular control over user permissions is fundamental. Role-Based Access Control (RBAC) provides a starting point by defining permissions for groups (e.g., ‘administrators’, ‘users’). However, for complex environments, Attribute-Based Access Control (ABAC) is a superior model. ABAC enables dynamic, context-aware rules such as, “Allow access only if the user is in the Finance department, the request occurs during business hours, and the document is tagged ‘Q3-Financials’.”
-
End-to-End Encryption: Data must be protected both in transit and at rest. This requires using strong transport protocols like TLS 1.3 for data moving between clients and servers, and robust encryption standards like AES-256 for data stored on disk.
-
Immutable Audit Logs: To meet compliance requirements, a verifiable and tamper-proof record of all system activity is essential. An immutable audit log records every action—view, edit, download, delete—in a way that cannot be altered or deleted. This provides the complete traceability required for regulatory audits.
These layers work in concert to create a hardened system where security is an intrinsic property, not a configuration option. This philosophy is central to implementing Privacy by Design.
Mapping Architecture to Regulatory Mandates
Compliance with regulations such as GDPR, NIS2, DORA, or HIPAA is not a checklist exercise; it is the direct outcome of specific architectural choices and system capabilities. A well-designed DMS provides the technical controls necessary to enforce these complex legal frameworks.
This is reflected in global DMS market trends. The North American IT sector, holding a 43.70% market share, is driven by technology firms requiring airtight data controls to mitigate cyber threats. With cloud deployments now comprising over 67.2% of the market, organizations are leveraging DMS features to automate compliance with regulations like HIPAA, which can reduce manual document processing errors by up to 40%. You can discover more insights about these market trends on Fortune Business Insights.
Compliance isn’t a separate workflow; it’s an output of a well-designed system. Your DMS architecture should make compliance the path of least resistance.
Specific DMS features map directly to regulatory requirements:
-
Data Residency Controls: GDPR requires control over the physical storage location of personal data. A DMS architecture must allow for policy enforcement, ensuring that documents related to EU citizens are stored exclusively in data centers within the EU.
-
Automated Retention Policies: Regulations mandate specific data retention and deletion schedules. A DMS automates this by enabling rules such as, “Automatically delete all invoices after seven years,” ensuring consistent policy enforcement without manual intervention.
-
Legal Holds: In the event of litigation or an investigation, a legal hold requirement may override standard retention policies. A legal hold feature allows compliance teams to place a lock on specific documents, preventing alteration or deletion until the hold is lifted.
-
Data Classification: Tagging documents based on sensitivity (e.g., ‘Public’, ‘Internal’, ‘Confidential’) allows for the automation of security policies. These tags can drive rules that restrict access to ‘Confidential’ documents to specific user groups or prevent them from being downloaded.
A Phased Implementation and Migration Roadmap
Deploying a document management system via a “big bang” launch is a high-risk strategy that often leads to operational disruption and poor user adoption. A pragmatic, phased roadmap is essential to de-risk the project, manage scope, and deliver measurable value at each stage.
The implementation should follow a structured, three-phase process: from strategic definition to a controlled pilot and, finally, a full-scale rollout. This methodical approach mitigates risk and ensures alignment with business objectives.
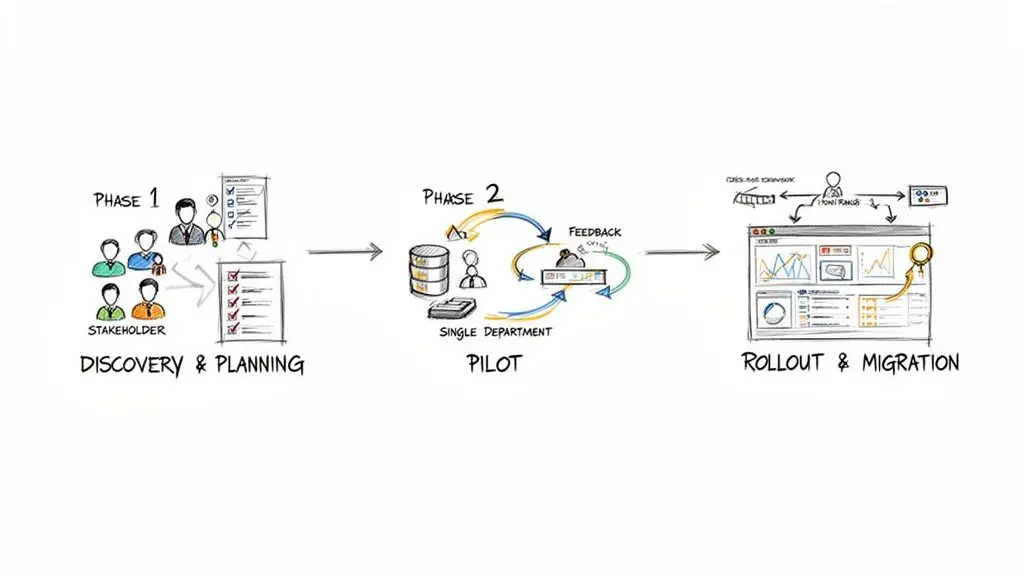
Phase 1: Discovery and Planning
This foundational phase defines the problem to be solved and the metrics for success. It focuses exclusively on requirements and governance before any code is written or licenses are procured. Errors made here will be amplified in subsequent phases.
Key activities include:
- Stakeholder Identification: Involve representatives from legal, finance, operations, and other departments that rely on document-centric workflows. Their input is non-negotiable for designing a system that aligns with actual business processes.
- Workflow Mapping: Analyze and document critical document processes as they currently exist. Identify bottlenecks, security gaps, and sources of manual effort. This analysis forms the business case for the project.
- Data Governance Policy: Before migrating any data, establish clear rules. Define a data classification scheme (Public, Internal, Confidential), set retention schedules, and formalize access control policies. This document serves as the blueprint for the DMS configuration.
Phase 2: Pilot Implementation
The pilot phase tests the plan’s assumptions in a controlled, real-world environment. The objective is to validate the chosen technology, gather user feedback, and achieve an early success to build project momentum. A pilot contains the blast radius of any unforeseen issues, unlike a high-risk, full-scale initial launch.
Select a single, well-defined use case, such as contract management for the legal department or invoice processing for finance. This controlled test allows you to:
- Validate the Architecture: Confirm that the DMS integrates correctly with existing infrastructure, such as identity providers and cloud storage.
- Gather User Feedback: Collect feedback from a small group of end-users on the interface, search functionality, and workflow design. This input is critical for fine-tuning the system before a broader rollout.
- Demonstrate Early Wins: A successful pilot serves as an internal proof-of-concept, demonstrating the system’s value and securing buy-in from other departments for the full implementation.
Phase 3: Full Rollout and Data Migration
The final phase involves scaling the solution across the organization and executing the data migration strategy. This stage is as much about change management as it is about technology. Clear communication and user training are critical for a successful launch.
Legacy data migration requires a methodical approach, not a naive “lift-and-shift,” which risks creating a digital landfill.
- Cleanse and Classify: Before migration, audit existing file shares to identify and archive or delete redundant, obsolete, and trivial (ROT) data.
- Phased Migration: Migrate data on a department-by-department or workflow-by-workflow basis. This minimizes operational disruption and allows for iterative improvements to the process.
- Monitor and Iterate: Post-launch, continuously monitor system performance, user adoption metrics, and adherence to governance policies. Use this data to inform ongoing system improvements and training efforts. The launch is the beginning of the system’s lifecycle, not the end.
Key Implementation Questions Answered
For CTOs, product leaders, and IT managers evaluating a DMS implementation, several practical questions consistently arise. Here are concise, pragmatic answers.
What Are The Biggest Hidden Costs In A Custom DMS Project?
The most significant unforeseen costs are rarely in the initial development. They are found in ongoing maintenance, security patching, and infrastructure scaling. Data migration from legacy systems is also a common source of budget overruns due to its complexity.
A proactive approach requires a detailed maintenance plan and a phased migration strategy from the outset. This allows for better control over the total cost of ownership (TCO) and mitigates project risk.
How Do We Choose Between On-Premise And Cloud Deployment?
The decision is driven by specific requirements for security, compliance, and operations. For most organizations, a cloud deployment (SaaS or IaaS) is the pragmatic choice, offering superior scalability, lower upfront capital expenditure, and simplified remote access.
An on-premise solution provides absolute control over data and security architecture. This is often a non-negotiable requirement for organizations in highly regulated sectors like government or finance. However, it carries a substantially higher burden for internal infrastructure management and maintenance.
How Can We Measure The ROI Of A New Document Management System?
Measuring return on investment requires analyzing both quantitative and qualitative metrics.
- Quantitative Metrics: Track direct cost reductions in physical storage, printing, and shipping. More importantly, measure productivity gains by quantifying the reduction in time employees spend searching for information.
- Qualitative Metrics: Assess improvements in compliance posture, data security, and the velocity of decision-making. While harder to assign a precise monetary value, these often represent the most significant strategic benefits.
A pilot program is the most effective method for establishing a credible ROI forecast. It provides real-world data on efficiency gains and cost savings, allowing for a data-driven projection rather than speculation.
Building a reliable, secure, and scalable document management system requires more than just code; it requires a partner with deep technical expertise and a pragmatic, business-first approach. At Devisia, we specialise in creating custom software that delivers measurable value. Learn more about our approach.