
Cloud disaster recovery is not about backups; it is a strategic discipline for ensuring business continuity. It involves replicating your entire operational environment—applications, data, and configurations—to a remote cloud infrastructure. This approach ensures rapid restoration of service after a disruption, minimising operational and financial impact. It represents a significant architectural evolution from traditional, on-premise models, offering superior flexibility, scalability, and cost-efficiency.
The Problem: Downtime is an Operational Inevitability
System downtime is no longer a hypothetical risk—it is an operational certainty. For any modern software-driven business, particularly SaaS providers and digital product teams, an outage is a matter of “when,” not “if.”
This perspective is critical. The consequences of downtime extend far beyond a temporary service interruption. They translate directly into tangible business harm: lost revenue, eroded customer trust, and reputational damage.
Empirical data confirms the severity of the problem. Recent disaster recovery statistics show that organisations averaged 86 outages last year, with each incident lasting over three hours. With a financial impact estimated at $33,333 per minute, even brief interruptions become exceptionally expensive. This is not a niche issue: 100% of technology companies reported lost revenue from outages, confirming that downtime is an unavoidable cost of doing business.
Why Traditional Recovery Models Fail Modern Architectures
Traditional disaster recovery was designed for a monolithic, static era. On-premise solutions—requiring secondary data centres, physical hardware, and manual failover processes—are fundamentally incompatible with the dynamic, distributed nature of cloud-native systems.
These legacy models are flawed by design:
- Cost-Prohibitive: Maintaining a duplicate physical infrastructure represents a significant capital expenditure, justifiable only by the largest enterprises.
- Slow and Inflexible: Manual recovery processes are inherently slow, error-prone, and cannot keep pace with the continuous deployment cycles of modern software engineering teams.
- Architecturally Incompatible: They are incapable of protecting containerised applications, serverless functions, and the distributed microservices that constitute modern digital products.
The Shift to Architectural Necessity
A disaster recovery cloud strategy is therefore not an IT checklist item, but a core architectural requirement. It reframes business continuity from a reactive, post-incident activity to a proactive design principle. When recovery is considered from the outset, systems are engineered for resilience, not just functionality.
For a CTO or product leader, a cloud disaster recovery plan is as fundamental as a security policy or a CI/CD pipeline. It is a direct investment in the long-term viability and trustworthiness of your product.
This guide moves beyond theory to provide practical, actionable implementation guidance. We will explore the architectural patterns, strategic trade-offs, and operational disciplines required to build a robust and pragmatic disaster recovery plan for real-world software systems.
Defining Recovery Objectives: RTO and RPO
Before designing an architecture or selecting a cloud provider, any effective disaster recovery plan must be grounded in two key metrics: Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
These are not mere technical jargon; they are the contractual interface between business requirements and technical implementation. Defining them correctly ensures your DR strategy delivers tangible business value. Misinterpreting them leads to either excessive expenditure on unnecessary protection or dangerous exposure of critical systems.
Consider them the two fundamental constraints that must be defined before writing a single line of code or provisioning a single server:
- Recovery Time Objective (RTO): How quickly must the system be fully operational after a failure? This metric defines the maximum acceptable duration of an outage.
- Recovery Point Objective (RPO): What is the maximum acceptable amount of data loss, measured in time? This metric defines the tolerance for data lost between the last backup and the moment of failure.
These two objectives exist in a constant state of tension with cost and complexity. A near-zero RTO and RPO is technically achievable but demands a highly complex and expensive active-active architecture. Conversely, a longer RTO and a larger RPO allow for simpler, more cost-effective solutions.
Translating Business Needs into Technical Specifications
Defining RTO and RPO is not a siloed IT task. It requires a pragmatic discussion between business stakeholders and engineering leaders, informed by a thorough business impact analysis (BIA). The objective is to classify applications based on their criticality to the business.
Consider two distinct architectural scenarios:
- Mission-Critical FinTech Platform: For a SaaS platform processing financial transactions, the tolerance for downtime or data loss is near-zero. Regulatory requirements like DORA and stringent customer SLAs might mandate an RTO of less than 15 minutes and an RPO of mere seconds. Losing even a minute of transaction history could result in severe financial penalties and irreparable damage to customer trust.
- Internal Analytics Dashboard: An internal tool used for weekly reporting is an inconvenience if it fails, but its absence does not halt business operations. An RTO of 24 hours and an RPO of 12 hours would likely be acceptable. The low business impact justifies a simple, low-cost backup-and-restore strategy.
Defining RTO and RPO is an exercise in risk management. It forces a quantitative assessment of the cost of downtime versus the cost of prevention, ensuring the DR investment is economically rational.
The Risk of a “One-Size-Fits-All” Approach
A common anti-pattern is applying a single RTO/RPO standard across all services. This naive approach invariably leads to one of two negative outcomes: you either dangerously under-protect your most critical systems, or you waste significant capital over-protecting non-essential ones.
A granular, service-by-service assessment is the only method for building a disaster recovery cloud strategy that is both effective and financially sustainable.
RTO and RPO are not static. They must be periodically reviewed and adjusted as the business evolves, architectures change, and new compliance obligations arise. These metrics are the blueprint for all subsequent decisions, from architectural patterns to operational testing procedures.
Comparing Core Disaster Recovery Cloud Architectures
Once RTO and RPO targets are defined, the next step is to map them to a specific disaster recovery architecture. This is where technical strategy must align with business objectives. The choice involves a critical trade-off between cost, complexity, and recovery speed.
There is no single “best” solution. The optimal architecture depends entirely on the criticality of the application being protected. Let’s examine the four primary strategies, from the simplest and most cost-effective to the most complex and resilient.
This decision guide illustrates how recovery metrics guide architectural selection.
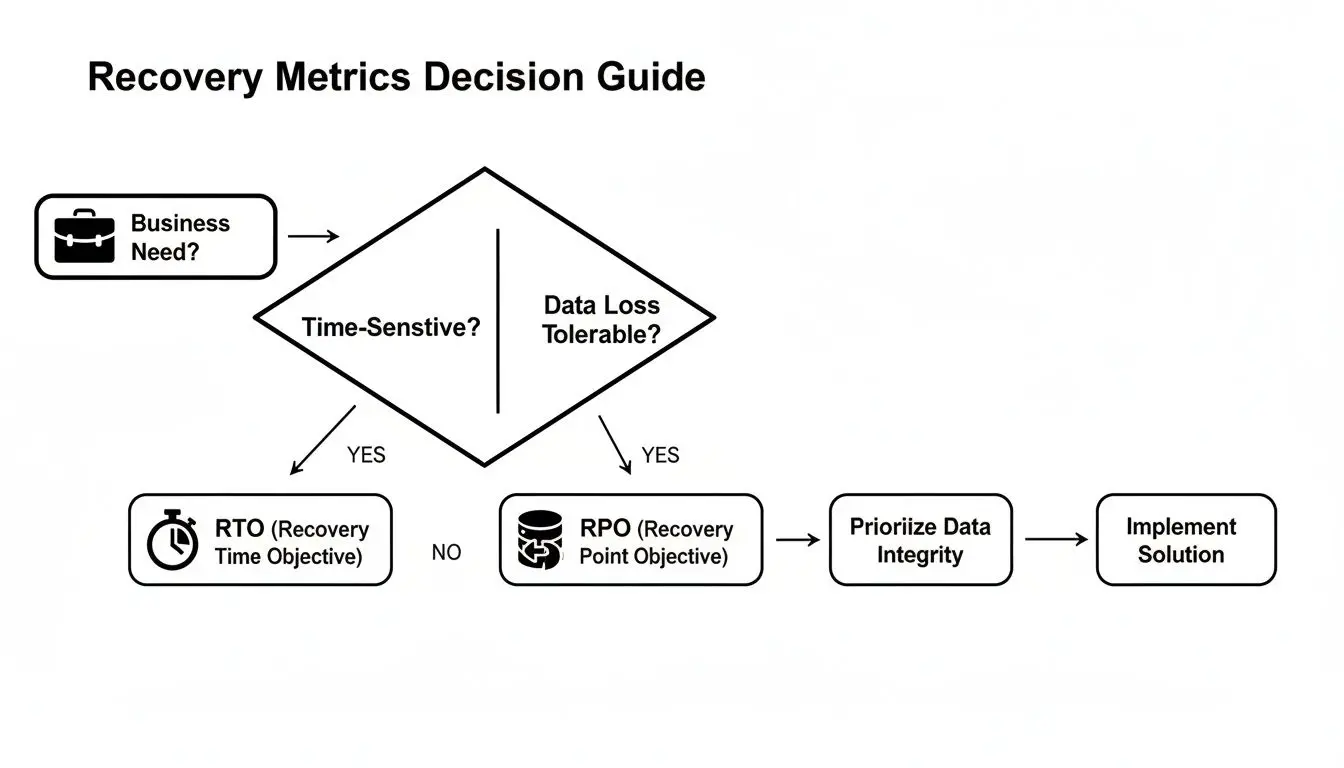
The relationship is direct and unambiguous: the lower the tolerance for downtime (RTO) and data loss (RPO), the more complex and costly the required solution.
Backup and Restore
This is the most fundamental and cost-effective disaster recovery strategy. The methodology is straightforward: data and application states are regularly backed up to a durable, low-cost object storage service in a separate geographic region.
In a disaster scenario, a new environment is provisioned from scratch, and the system is restored from these backups.
- RTO/RPO Profile: This model yields the longest recovery times and highest potential for data loss. RTO can be hours or even days, while RPO is determined by the frequency of the last successful backup.
- Ideal Use Case: Non-critical applications, development environments, and internal tools where significant downtime and several hours of data loss are acceptable trade-offs for minimal cost.
Pilot Light
The Pilot Light strategy significantly improves recovery speed. In this model, a minimal version of the core infrastructure—the “pilot light”—is kept running in the recovery region. This typically includes a database server with continuous data replication, but core application servers remain offline.
During a failover, the rest of the application environment is rapidly provisioned around this pre-existing, data-current core.
The “Pilot Light” metaphor is precise. A small, essential flame is always burning, ready to ignite the full infrastructure on demand. This approach dramatically reduces the time required to achieve a fully operational state.
This model provides a balanced trade-off between cost and readiness. It is more expensive than a simple backup strategy but far more economical than maintaining a full-scale duplicate environment.
Warm Standby
A Warm Standby architecture expands on the Pilot Light concept. Instead of a minimal core, a scaled-down but fully functional version of the entire application stack runs continuously in the recovery region.
This standby environment might operate on smaller instance types or handle a fraction of production traffic. During a failover, the primary actions are to scale up the infrastructure to production capacity and redirect all user traffic to the standby site.
- RTO/RPO Profile: This architecture reduces the RTO to minutes. With continuous data synchronisation, the RPO is also extremely low, often measured in seconds.
- Key Consideration: The primary operational challenge is preventing “configuration drift” between the production and standby environments. Rigorous automation and continuous testing are required to ensure the two stacks remain perfectly synchronised.
Hot Standby (Multi-Region Active-Active)
This is the most advanced and resilient disaster recovery architecture. A Hot Standby (or active-active) configuration involves running full-scale production environments in two or more geographically distinct regions simultaneously.
Live user traffic is distributed across all active regions via a global load balancer. If one region fails, traffic is automatically and seamlessly redirected to the remaining healthy regions with no manual intervention. This is a complex architectural decision that goes far beyond a simple comparison of cloud computing vs. on-premise solutions.
- RTO/RPO Profile: This model delivers near-zero RTO and RPO, representing the highest standard of availability for mission-critical systems.
- Trade-Offs: The cost and engineering complexity are substantial. This architecture requires sophisticated solutions for data replication consistency, global traffic routing, and state management. It is reserved for systems where the financial cost of downtime is exceptionally high.
Comparison of Disaster Recovery Cloud Strategies
This table provides a high-level comparison of the four strategies to aid in decision-making.
| Strategy | Typical RTO | Typical RPO | Relative Cost | Key Use Case |
|---|---|---|---|---|
| Backup and Restore | Hours to Days | Hours | $ | Non-critical apps, archives, dev/test |
| Pilot Light | 10s of Minutes to Hours | Minutes | $$ | Important but not mission-critical systems |
| Warm Standby | Minutes | Seconds to Minutes | $$$ | Business-critical applications |
| Hot Standby | Seconds to Near-Zero | Near-Zero | $$$$ | Mission-critical systems with zero downtime tolerance |
The optimal strategy is the one where the cost of implementation is justified by the business value of the system it protects. For most organisations, this balance is often found between the Pilot Light and Warm Standby models.
The Shared Responsibility Model: A Critical Distinction
One of the most dangerous misconceptions in cloud adoption is the assumption that the provider manages all aspects of resilience. This is a critical error in judgment. While providers like AWS, Google Cloud, and Microsoft Azure guarantee the resilience of their global infrastructure—data centres, networks, physical hardware—they explicitly do not guarantee the safety of your applications, data, or configurations running on that infrastructure.
This division of duties is known as the shared responsibility model, a foundational concept for any team building systems in the cloud.
The model is simple: the provider is responsible for the security OF the cloud. You, the customer, are responsible for security and resilience IN the cloud. This includes data protection, identity and access management, service configuration, and, critically, your own disaster recovery plan.
Failure to understand this distinction can lead to catastrophic, unrecoverable data loss. Migrating to the cloud does not inherently make your business resilient.
The Provider’s Role and Its Limits
Cloud providers offer an exceptionally resilient foundation, with multiple availability zones, hardware redundancy, and protection against large-scale physical events. They manage the complex, capital-intensive infrastructure so their customers do not have to.
However, their responsibility ends at the service API. They ensure their S3 or Blob Storage service is available, but they are not responsible if an engineer accidentally deletes a critical data bucket or if a ransomware attack encrypts your files. That accountability lies with you.
Your cloud provider gives you the tools to build a resilient system, but they absolutely do not build it for you. Believing otherwise is a direct path to a failed recovery.
This is not a detail hidden in legal fine print; it is a core principle of cloud computing. Providers are transparent that data protection and recovery are the customer’s responsibility. Microsoft’s service agreements, for instance, explicitly recommend using third-party backup solutions, acknowledging that native platform tools are not a substitute for a comprehensive DR strategy.
The Critical Recovery Gap
This shared responsibility creates a significant gap between perceived safety and actual operational readiness. Many organisations suffer from a dangerous disconnect between their backup policies and their ability to recover. While most companies have backup systems, a startling 35% fail to achieve full recovery of all data after an incident.
The reason is clear: recovery is the organization’s responsibility, not the cloud provider’s. The widespread data loss issue highlights the consequences of this misunderstanding.
A proactive, well-architected disaster recovery cloud strategy is the only way to bridge this gap. This means taking full ownership of:
- Application-Level Resiliency: Implementing backups not just for databases, but also for application configurations, dependencies, and environment variables.
- Data Sovereignty and Compliance: Controlling the physical location of backup data to comply with regulations like GDPR, which impose strict data residency requirements.
- Independent Verification: Owning the process of regularly testing and validating backups to ensure they are complete, uncorrupted, and, most importantly, restorable.
Relying solely on the underlying resilience of a cloud provider’s infrastructure is a naive and high-risk strategy. For any founder, CTO, or IT manager, the shared responsibility model places the final accountability for business continuity squarely on your shoulders. The survival of your data depends on the systems you design, not just the platform you use.
Operationalising the Disaster Recovery Plan
A disaster recovery strategy documented in a wiki is useless. During a crisis, only precise, tested execution matters. The process of turning a theoretical plan into a reliable, operational capability is paramount.
The cornerstone of any practical recovery process is a detailed runbook. This is not a high-level summary but a prescriptive, step-by-step guide documenting every action, command, dependency, and contact person required for a failover.
A well-architected runbook eliminates ambiguity and improvisation during a high-stress outage. It must be clear enough for an engineer with no prior context to execute it flawlessly under pressure.
From Manual Checklists to Automated Recovery
Relying on a manual checklist is a recipe for failure. Human error is magnified under duress, and manual processes are far too slow to meet the aggressive RTOs required by modern businesses. Automation is therefore non-negotiable.
Infrastructure as Code (IaC) tools like Terraform or OpenTofu are foundational to modern DR automation. By defining the recovery environment in declarative code, the entire process is transformed from a frantic, manual effort into a repeatable, version-controlled, and auditable workflow.
With IaC, you can:
- Ensure Consistent Provisioning: Reliably provision networks, servers, load balancers, and security groups in a predetermined order, eliminating configuration drift.
- Achieve Aggressive RTOs: Automation drastically reduces the time required to stand up a recovery environment, directly improving your RTO.
- Eliminate Human Error: Scripted, deterministic processes remove the guesswork and potential for costly mistakes inherent in manual configuration.
An untested disaster recovery plan is not a plan; it is a hypothesis. The only way to build confidence in your ability to recover is through regular, rigorous, automated testing.
This methodology integrates seamlessly with modern software delivery practices. For context on how this fits into the broader development lifecycle, see our guide on building a CI/CD pipeline.
Validating the Plan with DR Drills
Testing is the mechanism that converts a hypothetical DR strategy into a proven operational capability. Discovering flaws in runbooks or IaC scripts during a real disaster is an unacceptable business risk. Regular drills are essential to validate the plan and ensure the team is prepared to execute it.
Different types of tests serve distinct purposes, from simple procedural reviews to full-scale simulations.
Types of Disaster Recovery Drills
- Tabletop Exercises: Discussion-based sessions where the technical team verbally walks through the runbook step-by-step. This low-cost exercise is highly effective at identifying logical gaps, incorrect assumptions, and missing dependencies in the plan.
- Component-Level Tests: Involves restoring a single architectural component—such as a database from a backup or a specific microservice—in an isolated environment. This validates backup integrity and individual recovery procedures without affecting production systems.
- Parallel Environment Tests: Uses IaC scripts to provision a complete, parallel recovery environment. This test validates the entire provisioning process and allows for functional smoke tests against the restored application without redirecting any live traffic.
- Full Failover Simulation: The most comprehensive test. A complete failover is executed, redirecting a small subset of non-critical or internal traffic to the recovery site. This drill validates the entire process end-to-end, from infrastructure provisioning to DNS propagation and application functionality.
Conducting these drills on a defined schedule—for example, quarterly tabletop and parallel tests, with an annual full failover—builds operational muscle memory and exposes weaknesses before they become critical liabilities. Each drill must conclude with a post-mortem to document findings and iterate on the runbooks and automation scripts. This disciplined, iterative process is what ensures a disaster recovery strategy will function as designed when it matters most.
Balancing Compliance Mandates with Budget Realities
Architecting a cloud disaster recovery strategy is not purely a technical exercise. It is a balancing act between regulatory obligations and financial constraints. For any company operating in or serving Europe, regulations like GDPR, NIS2, and DORA directly influence recovery plans, elevating compliance from a legal requirement to a core architectural driver.
These regulations are not suggestions; they are mandates with significant financial and legal penalties for non-compliance. They introduce specific requirements that a DR plan must address by design.
Translating Regulation into Architecture
Compliance mandates directly impact RTO and RPO targets and dictate architectural choices. The task is to translate legal text into concrete technical decisions. For instance:
- Data Residency and Sovereignty: Regulations like GDPR impose strict rules on the geographic location of personal data processing and storage. A DR plan must respect these constraints. Failover regions and backup storage locations must be chosen to comply with these legal boundaries. Our analysis of Article 30 of the GDPR provides further context on required documentation.
- Availability and Resilience: For financial entities under DORA or critical infrastructure providers under NIS2, high availability is a legal requirement. These regulations effectively mandate low RTOs, pushing architectures toward more sophisticated Warm or Hot Standby models to ensure continuity of critical services.
- Incident Reporting: NIS2 requires prompt reporting of significant security incidents. Accurate and timely reporting is impossible without a well-tested DR plan and clear runbooks to first identify, contain, and recover from an event.
Attempting to retrofit compliance onto an existing architecture is a common and costly mistake. It is always more complex and expensive than incorporating these requirements into the initial design.
Aligning Budget with Risk
While compliance sets the minimum resilience baseline, budget determines what is practically achievable. A multi-region, Hot Standby architecture may satisfy every regulatory requirement, but its cost is prohibitive for most organisations. The objective is not unlimited spending but the strategic allocation of resources, aligning cost with risk and legal duty.
Effective disaster recovery is about making informed trade-offs. You must invest enough to meet legal obligations and protect critical business functions, but not so much that you cripple your budget by over-engineering protection for non-essential services.
This financial constraint is a primary driver behind the adoption of cloud-based DR. The market is projected to reach $631 million by 2032, largely because cloud solutions offer 40-60% cost savings over traditional on-premise models. By eliminating hardware capital expenditure and reducing downtime costs, cloud platforms enable smaller companies to achieve enterprise-grade resilience. You can explore the full market analysis and cost-saving data for more detail on these trends.
To optimise your DR budget, consider these pragmatic architectural choices:
- Use Lower-Cost Regions: Provision standby environments in less expensive cloud regions to reduce compute and storage costs.
- Leverage On-Demand Scaling: Design Pilot Light or Warm Standby architectures to run on smaller, on-demand instances, scaling up to full production capacity only during an actual failover event.
- Tier Data Storage: Classify data based on criticality and access frequency. Use cheaper archival storage tiers like Amazon S3 Glacier or Azure Archive Storage for long-term backups of non-critical data with a higher RTO tolerance.
Balancing compliance and budget is an exercise in prioritisation. By mapping regulatory requirements to specific applications and selecting the appropriate architectural pattern for each, you can build a resilient, compliant, and financially sustainable DR strategy.
Conclusion: Building Resilient Systems by Design
Achieving genuine resilience in the cloud is not the outcome of a one-time project. It is a fundamental architectural commitment, integrated into the entire lifecycle of building and operating digital products. It requires a strategic shift from reactive incident response to proactive design, where recovery is a primary consideration from inception.
The objective is to engineer products that are not only functional but also robust, maintainable, and trustworthy. This demands moving beyond technical checklists to a deep understanding of business priorities, resulting in a recovery plan that is both technically effective and economically rational.
Core Principles for an Actionable Strategy
To translate theory into reliable practice, technical leaders must anchor their DR strategy in a few core principles. These pillars ensure that the plan remains grounded in business value and operational reality.
- Align RTO/RPO with Business Impact: Before any technical implementation, quantify the acceptable downtime (RTO) and data loss (RPO) for each individual service. This business-driven approach prevents over-investment in non-critical systems and under-protection of mission-critical ones.
- Embrace the Shared Responsibility Model: Your cloud provider is responsible for the cloud’s infrastructure, but you are responsible for everything you build in the cloud. Your data, applications, and configurations are your responsibility to protect and recover.
- Mandate Regular, Automated Testing: An untested recovery plan is a liability. Implement automated drills using Infrastructure as Code to validate runbooks, eliminate human error, and build quantifiable confidence in your ability to recover.
A Pragmatic Checklist for Technical Leaders
Effective disaster recovery is the result of deliberate, informed trade-offs. It is an ongoing process of balancing risk, cost, and compliance—not a search for a theoretical, perfect system.
A mature disaster recovery strategy is a key competitive differentiator. It signals to customers, regulators, and partners that your organisation is committed to operational excellence and is a reliable steward of their interests.
Use this concise checklist to guide your implementation:
- Map Business Criticality: Have you identified mission-critical applications and defined specific RTO/RPO targets for each one?
- Select the Right Architecture: Have you chosen a DR pattern (e.g., Pilot Light, Warm Standby) that aligns with your RTO/RPO needs without exceeding budget constraints?
- Automate Recovery Processes: Are you using Infrastructure as Code to automate the provisioning of your recovery environment for speed and consistency?
- Validate with Drills: Do you have a defined schedule for regular DR testing, including both tabletop exercises and full failover simulations?
- Integrate Compliance by Design: Does your plan meet regulatory requirements like GDPR or NIS2 regarding data residency and availability?
- Maintain Comprehensive Documentation: Is your recovery runbook detailed, current, and accessible to the entire engineering organisation?
By focusing on these pragmatic steps, you can develop a disaster recovery capability that is robust, maintainable, and aligned with the long-term strategic success of your digital products.
At Devisia, we build reliable digital products with a product mindset, turning business vision into scalable and maintainable software. If you need a partner to help design and implement a pragmatic, resilient architecture, learn more about our approach.