
Il disaster recovery nel cloud non riguarda i backup; è una disciplina strategica per garantire la continuità operativa. Consiste nella replica dell’intero ambiente operativo—applicazioni, dati e configurazioni—su un’infrastruttura cloud remota. Questo approccio assicura un rapido ripristino del servizio dopo una interruzione, minimizzando l’impatto operativo e finanziario. Rappresenta una significativa evoluzione architetturale rispetto ai modelli tradizionali on-premise, offrendo superiore flessibilità, scalabilità ed efficienza dei costi.
Il problema: il downtime è un’inevitabile realtà operativa
Il downtime dei sistemi non è più un rischio ipotetico—è una certezza operativa. Per qualsiasi azienda moderna guidata dal software, in particolare i fornitori SaaS e i team di prodotto digitale, un’interruzione è una questione di “quando”, non di “se”.
Questa prospettiva è cruciale. Le conseguenze del downtime vanno ben oltre una temporanea interruzione del servizio. Si traducono direttamente in danni aziendali tangibili: entrate perse, fiducia dei clienti erosa e danni alla reputazione.
I dati empirici confermano la gravità del problema. Le statistiche recenti sul disaster recovery mostrano che le organizzazioni hanno registrato in media 86 interruzioni lo scorso anno, con ogni incidente che è durato oltre tre ore. Con un impatto finanziario stimato in $33.333 al minuto, anche brevi interruzioni diventano eccezionalmente costose. Non si tratta di un problema di nicchia: il 100% delle aziende tecnologiche ha riportato perdite di entrate dovute a interruzioni, confermando che il downtime è un costo inevitabile per fare business.
Perché i modelli tradizionali di recovery falliscono con le architetture moderne
Il disaster recovery tradizionale è stato progettato per un’era monolitica e statica. Le soluzioni on-premise—che richiedono data center secondari, hardware fisico e processi di failover manuali—sono fondamentalmente incompatibili con la natura dinamica e distribuita dei sistemi cloud-native.
Questi modelli legacy sono difettosi per progettazione:
- Costosi: Mantenere un’infrastruttura fisica duplicata rappresenta una spesa in conto capitale significativa, giustificabile solo per le imprese più grandi.
- Lenti e inflessibili: I processi di recovery manuali sono intrinsecamente lenti, soggetti a errori e non possono tenere il passo con i cicli di deployment continui dei team di ingegneria moderni.
- Incompatibili dal punto di vista architetturale: Non sono in grado di proteggere applicazioni containerizzate, funzioni serverless e i microservizi distribuiti che costituiscono i prodotti digitali moderni.
La transizione verso una necessità architetturale
Una strategia di disaster recovery nel cloud non è quindi un elemento della checklist IT, ma un requisito architetturale fondamentale. Riformula la continuità del business da un’attività reattiva post-incidente a un principio di design proattivo. Quando il ripristino è considerato fin dall’inizio, i sistemi sono progettati per la resilienza, non solo per la funzionalità.
Per un CTO o un responsabile di prodotto, un piano di disaster recovery nel cloud è tanto fondamentale quanto una policy di sicurezza o una pipeline CI/CD. È un investimento diretto nella sostenibilità a lungo termine e nell’affidabilità del tuo prodotto.
Questa guida va oltre la teoria per fornire indicazioni pratiche e attuabili. Esploreremo i pattern architetturali, i compromessi strategici e le discipline operative necessarie per costruire un piano di disaster recovery robusto e pragmatico per sistemi software del mondo reale.
Definire gli obiettivi di recovery: RTO e RPO
Prima di progettare un’architettura o scegliere un fornitore cloud, qualsiasi piano di disaster recovery efficace deve poggiare su due metriche chiave: Recovery Time Objective (RTO) e Recovery Point Objective (RPO).
Queste non sono semplici gerghi tecnici; sono l’interfaccia contrattuale tra requisiti di business e implementazione tecnica. Definirle correttamente garantisce che la tua strategia di DR offra valore aziendale tangibile. Interpretarle male porta o a spese eccessive per protezioni non necessarie o a pericolose esposizioni di sistemi critici.
Considerale come i due vincoli fondamentali che devono essere definiti prima di scrivere una sola riga di codice o di provisioning di un singolo server:
- Recovery Time Objective (RTO): Quanto rapidamente il sistema deve essere pienamente operativo dopo un guasto? Questa metrica definisce la durata massima accettabile di un’interruzione.
- Recovery Point Objective (RPO): Qual è la quantità massima accettabile di perdita di dati, misurata in termini temporali? Questa metrica definisce la tolleranza per i dati persi tra l’ultimo backup e il momento del guasto.
Questi due obiettivi esistono in uno stato di tensione costante con costi e complessità. Un RTO e un RPO prossimi allo zero sono tecnicamente raggiungibili ma richiedono un’architettura active-active altamente complessa e costosa. Viceversa, un RTO più lungo e un RPO maggiore consentono soluzioni più semplici ed economiche.
Tradurre le esigenze di business in specifiche tecniche
Definire RTO e RPO non è un compito isolato dell’IT. Richiede una discussione pragmatica tra stakeholder di business e leader dell’ingegneria, informata da un’analisi dell’impatto sul business (BIA). L’obiettivo è classificare le applicazioni in base alla loro criticità per il business.
Considera due scenari architetturali distinti:
- Piattaforma FinTech mission-critical: Per una piattaforma SaaS che elabora transazioni finanziarie, la tolleranza per downtime o perdita di dati è quasi nulla. Requisiti normativi come DORA e SLA stringenti con i clienti potrebbero imporre un RTO inferiore a 15 minuti e un RPO di pochi secondi. Perdere anche un minuto di cronologia delle transazioni potrebbe comportare pesanti sanzioni finanziarie e danni irreparabili alla fiducia dei clienti.
- Dashboard di analytics interna: Uno strumento interno utilizzato per report settimanali è un inconveniente se non funziona, ma la sua assenza non blocca le operazioni aziendali. Un RTO di 24 ore e un RPO di 12 ore sarebbero probabilmente accettabili. Il basso impatto sul business giustifica una strategia semplice di backup-and-restore a basso costo.
Definire RTO e RPO è un esercizio di gestione del rischio. Costringe a una valutazione quantitativa del costo del downtime rispetto al costo della prevenzione, garantendo che l’investimento in DR sia economicamente razionale.
Il rischio di un approccio “taglia unica”
Un anti-pattern comune è applicare uno standard unico di RTO/RPO a tutti i servizi. Questo approccio ingenuo porta inesorabilmente a uno dei due esiti negativi: o si sotto-proteggono pericolosamente i sistemi più critici, o si sprecano capitali significativi proteggendo eccessivamente quelli non essenziali.
Una valutazione granulare, servizio per servizio, è l’unico metodo per costruire una strategia di disaster recovery nel cloud che sia efficace e finanziariamente sostenibile.
RTO e RPO non sono statici. Devono essere rivisti e adeguati periodicamente man mano che il business evolve, le architetture cambiano e emergono nuovi obblighi di compliance. Queste metriche sono il progetto per tutte le decisioni successive, dai pattern architetturali alle procedure di test operative.
Confronto tra le principali architetture di disaster recovery nel cloud
Una volta definiti gli obiettivi RTO e RPO, il passo successivo è mapparli su una specifica architettura di disaster recovery. Qui la strategia tecnica deve allinearsi con gli obiettivi di business. La scelta comporta un compromesso critico tra costo, complessità e velocità di ripristino.
Non esiste una singola soluzione “migliore”. L’architettura ottimale dipende interamente dalla criticità dell’applicazione da proteggere. Esaminiamo le quattro strategie principali, dalla più semplice e conveniente alla più complessa e resistente.
Questa guida decisionale illustra come le metriche di recovery guidino la selezione architetturale.
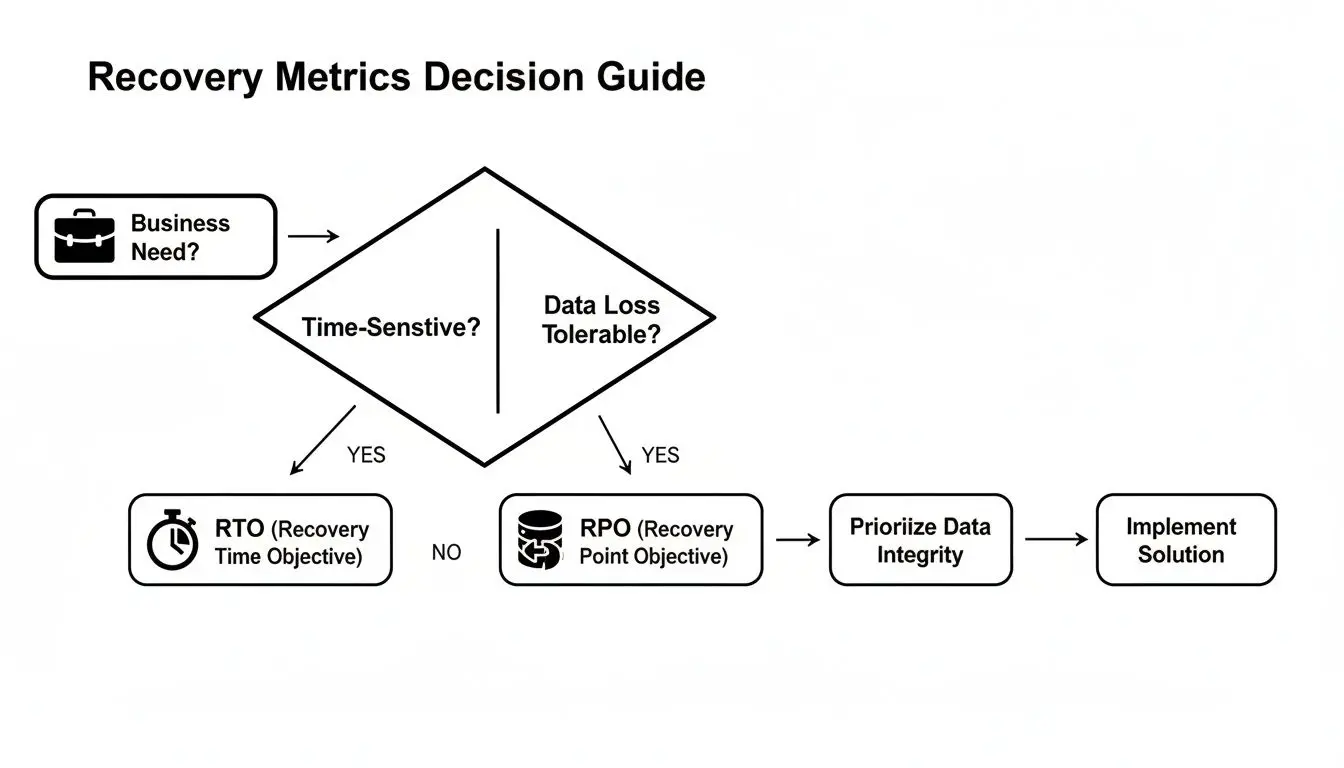
La relazione è diretta e inequivocabile: minore è la tolleranza per il downtime (RTO) e la perdita di dati (RPO), più complessa e costosa deve essere la soluzione richiesta.
Backup e restore
Questa è la strategia di disaster recovery più fondamentale ed economica. La metodologia è semplice: dati e stati delle applicazioni vengono regolarmente salvati su un servizio di object storage durevole e a basso costo in una regione geografica separata.
In uno scenario di disastro, viene provisioningato un nuovo ambiente da zero e il sistema viene ripristinato da questi backup.
- Profilo RTO/RPO: Questo modello comporta i tempi di ripristino più lunghi e il potenziale maggiore di perdita di dati. L’RTO può essere di ore o anche giorni, mentre l’RPO è determinato dalla frequenza dell’ultimo backup riuscito.
- Caso d’uso ideale: Applicazioni non critiche, ambienti di sviluppo e strumenti interni dove un downtime significativo e alcune ore di perdita di dati sono trade-off accettabili per costi minimi.
Pilot Light
La strategia Pilot Light migliora notevolmente la velocità di ripristino. In questo modello, una versione minimale dell’infrastruttura core—la “pilot light”—viene mantenuta attiva nella regione di recovery. Questo include tipicamente un server database con replica continua dei dati, mentre i server applicativi principali restano offline.
Durante un failover, il resto dell’ambiente applicativo viene rapidamente provisioningato attorno a questo core preesistente e aggiornato con dati correnti.
La metafora della “Pilot Light” è precisa. Una piccola fiamma essenziale è sempre accesa, pronta a incendiare l’infrastruttura completa su richiesta. Questo approccio riduce drasticamente il tempo necessario per raggiungere uno stato pienamente operativo.
Questo modello offre un compromesso bilanciato tra costo e prontezza. È più costoso di una semplice strategia di backup, ma molto più economico rispetto al mantenimento di un ambiente duplicato a piena scala.
Warm Standby
Un’architettura Warm Standby amplia il concetto di Pilot Light. Invece di un core minimale, una versione ridotta ma completamente funzionante dell’intero stack applicativo viene eseguita continuamente nella regione di recovery.
Questo ambiente di standby potrebbe operare su tipi di istanze più piccoli o gestire una frazione del traffico di produzione. Durante un failover, le azioni principali sono scalare l’infrastruttura alla capacità di produzione e reindirizzare tutto il traffico utente verso il sito di standby.
- Profilo RTO/RPO: Questa architettura riduce l’RTO a pochi minuti. Con sincronizzazione continua dei dati, l’RPO è anche estremamente basso, spesso misurato in secondi.
- Considerazione chiave: La sfida operativa primaria è prevenire la “deriva di configurazione” tra gli ambienti di produzione e standby. È necessaria un’automazione rigorosa e test continui per garantire che i due stack rimangano perfettamente sincronizzati.
Hot Standby (Active-Active multi-regione)
Questa è l’architettura di disaster recovery più avanzata e resiliente. Una configurazione Hot Standby (o active-active) prevede l’esecuzione di ambienti di produzione a piena scala in due o più regioni geografiche distinte simultaneamente.
Il traffico utente live viene distribuito tra tutte le regioni attive tramite un bilanciatore di carico globale. Se una regione fallisce, il traffico viene reindirizzato automaticamente e senza soluzione di continuità alle regioni rimanenti sane senza intervento manuale. Questa è una decisione architetturale complessa che va ben oltre un semplice confronto tra cloud computing vs. on-premise.
- Profilo RTO/RPO: Questo modello offre RTO e RPO prossimi allo zero, rappresentando il massimo standard di disponibilità per sistemi mission-critical.
- Compromessi: Il costo e la complessità ingegneristica sono sostanziali. Questa architettura richiede soluzioni sofisticate per la coerenza della replica dei dati, il routing globale del traffico e la gestione dello stato. È riservata ai sistemi in cui il costo finanziario del downtime è eccezionalmente alto.
Confronto delle strategie di disaster recovery nel cloud
Questa tabella fornisce un confronto ad alto livello delle quattro strategie per agevolare il processo decisionale.
| Strategia | RTO tipico | RPO tipico | Costo relativo | Caso d’uso principale |
|---|---|---|---|---|
| Backup and Restore | Ore a giorni | Ore | $ | Applicazioni non critiche, archivi, sviluppo/test |
| Pilot Light | Decine di minuti a ore | Minuti | $$ | Sistemi importanti ma non critici per la missione |
| Warm Standby | Minuti | Secondi a minuti | $$$ | Applicazioni critiche per il business |
| Hot Standby | Secondi a quasi zero | Quasi zero | $$$$ | Sistemi critici per la missione con tolleranza zero ai tempi di inattività |
La strategia ottimale è quella in cui il costo di implementazione è giustificato dal valore aziendale del sistema che protegge. Per la maggior parte delle organizzazioni, questo equilibrio si trova spesso tra i modelli Pilot Light e Warm Standby.
Il modello di responsabilità condivisa: una distinzione fondamentale
Uno dei fraintendimenti più pericolosi nell’adozione del cloud è l’assunzione che il provider gestisca tutti gli aspetti della resilienza. Questo è un errore di giudizio critico. Pur garantendo la resilienza della loro infrastruttura globale—data center, reti, hardware fisico—provider come AWS, Google Cloud, e Microsoft Azure non garantiscono esplicitamente la sicurezza delle tue applicazioni, dati o configurazioni in esecuzione su quell’infrastruttura.
Questa divisione dei compiti è nota come modello di responsabilità condivisa, un concetto fondamentale per qualsiasi team che costruisca sistemi in cloud.
Il modello è semplice: il provider è responsabile per la sicurezza DEL cloud. Tu, il cliente, sei responsabile della sicurezza e della resilienza NEL cloud. Questo include la protezione dei dati, la gestione delle identità e degli accessi, la configurazione dei servizi e, in modo critico, il tuo piano di disaster recovery.
La mancata comprensione di questa distinzione può portare a perdite di dati catastrofiche e irreversibili. Migrare al cloud non rende intrinsecamente la tua azienda resiliente.
Il ruolo del provider e i suoi limiti
I provider cloud offrono una base eccezionalmente resiliente, con più zone di disponibilità, ridondanza hardware e protezione contro eventi fisici su larga scala. Gestiscono l’infrastruttura complessa e ad alta intensità di capitale in modo che i loro clienti non debbano farlo.
Tuttavia, la loro responsabilità termina all’API del servizio. Garantiscano che il loro servizio S3 o Blob Storage sia disponibile, ma non sono responsabili se un ingegnere elimina accidentalmente un bucket di dati critico o se un attacco ransomware cifra i tuoi file. Quella responsabilità ricade su di te.
Il tuo provider cloud ti fornisce gli strumenti per costruire un sistema resiliente, ma non lo costruisce assolutamente per te. Credere il contrario è una strada diretta verso un recupero fallito.
Questo non è un dettaglio nascosto nei termini legali; è un principio fondamentale del cloud computing. I provider sono chiari che la protezione e il recupero dei dati sono responsabilità del cliente. Gli accordi di servizio di Microsoft, per esempio, raccomandano esplicitamente l’uso di soluzioni di backup di terze parti, riconoscendo che gli strumenti nativi della piattaforma non sono un sostituto per una strategia completa di DR.
Il divario critico nel recupero
Questo modello di responsabilità condivisa crea un divario significativo tra la sicurezza percepita e la reale prontezza operativa. Molte organizzazioni soffrono di uno scollegamento pericoloso tra le loro politiche di backup e la loro capacità di recupero. Sebbene la maggior parte delle aziende abbia sistemi di backup, un sorprendente 35% non riesce a raggiungere un recupero completo di tutti i dati dopo un incidente.
La ragione è chiara: il recupero è responsabilità dell’organizzazione, non del provider cloud. Il problema della perdita diffusa di dati evidenzia le conseguenze di questo fraintendimento.
Una strategia cloud di ripristino di emergenza proattiva e ben progettata è l’unico modo per colmare questo divario. Ciò significa assumersi la piena responsabilità di:
- Resilienza a livello di applicazione: Implementare backup non solo per i database, ma anche per le configurazioni delle applicazioni, le dipendenze e le variabili d’ambiente.
- Sovranità e residenza dei dati: Controllare la posizione fisica dei dati di backup per conformarsi a regolamenti come il GDPR, che impongono stringenti requisiti di residenza dei dati.
- Verifica indipendente: Gestire il processo di test e convalida regolari dei backup per garantire che siano completi, non corrotti e, cosa più importante, ripristinabili.
Fare affidamento esclusivamente sulla resilienza sottostante dell’infrastruttura di un provider cloud è una strategia ingenua e ad alto rischio. Per qualsiasi fondatore, CTO o responsabile IT, il modello di responsabilità condivisa pone la responsabilità finale per la continuità del business saldamente sulle tue spalle. La sopravvivenza dei tuoi dati dipende dai sistemi che progetti, non solo dalla piattaforma che usi.
Operazionalizzare il piano di ripristino di emergenza
Un piano di disaster recovery documentato in una wiki è inutile. Durante una crisi, conta solo un’esecuzione precisa e testata. Il processo di trasformare un piano teorico in una capacità operativa affidabile è fondamentale.
La pietra angolare di qualsiasi processo di recupero pratico è un dettagliato runbook. Questo non è un riassunto ad alto livello, ma una guida prescrittiva passo-passo che documenta ogni azione, comando, dipendenza e persona di contatto necessaria per un failover.
Un runbook ben progettato elimina ambiguità e improvvisazione durante un’interruzione ad alto stress. Deve essere sufficientemente chiaro perché un ingegnere senza conoscenze pregresse possa eseguirlo alla perfezione sotto pressione.
Dalle checklist manuali al ripristino automatizzato
Affidarsi a una checklist manuale è una ricetta per il fallimento. L’errore umano si amplifica sotto tensione, e i processi manuali sono troppo lenti per soddisfare gli aggressivi RTO richiesti dalle moderne aziende. Pertanto, l’automazione è non negoziabile.
Strumenti di Infrastructure as Code (IaC) come Terraform o OpenTofu sono fondamentali per l’automazione del DR moderno. Definendo l’ambiente di recupero in codice dichiarativo, l’intero processo si trasforma da uno sforzo frenetico e manuale in un flusso di lavoro ripetibile, versionato e verificabile.
Con l’IaC, puoi:
- Garantire un provisioning coerente: Provisionare in modo affidabile reti, server, bilanciatori di carico e gruppi di sicurezza in un ordine predeterminato, eliminando la deriva delle configurazioni.
- Raggiungere RTO aggressivi: L’automazione riduce drasticamente il tempo necessario per attivare un ambiente di recupero, migliorando direttamente il tuo RTO.
- Eliminare l’errore umano: Processi scriptati e deterministici rimuovono l’incertezza e il potenziale di errori costosi insiti nella configurazione manuale.
Un piano di disaster recovery non testato non è un piano; è un’ipotesi. L’unico modo per costruire fiducia nella tua capacità di recuperare è attraverso test regolari, rigorosi e automatizzati.
Questa metodologia si integra perfettamente con le moderne pratiche di delivery del software. Per contesto su come questo si inserisce nel ciclo di vita di sviluppo più ampio, vedi la nostra guida sulla creazione di una pipeline CI/CD.
Validare il piano con esercitazioni DR
Il testing è il meccanismo che trasforma una strategia DR ipotetica in una capacità operativa comprovata. Scoprire difetti nei runbook o negli script IaC durante un disastro reale è un rischio aziendale inaccettabile. Esercitazioni regolari sono essenziali per convalidare il piano e assicurare che il team sia pronto a eseguirlo.
Diversi tipi di test servono scopi distinti, da semplici revisioni procedurali a simulazioni su larga scala.
Tipi di esercitazioni per il ripristino di emergenza
- Esercitazioni a tavolino: Sessioni basate sulla discussione in cui il team tecnico percorre verbalmente il runbook passo dopo passo. Questo esercizio a basso costo è altamente efficace per identificare lacune logiche, assunzioni errate e dipendenze mancanti nel piano.
- Test a livello di componente: Coinvolge il ripristino di un singolo componente architetturale—come un database da backup o un microservizio specifico—in un ambiente isolato. Questo valida l’integrità dei backup e le procedure di recupero individuali senza influenzare i sistemi di produzione.
- Test in ambiente parallelo: Utilizza script IaC per provisioningare un ambiente di recupero completo e parallelo. Questo test convalida l’intero processo di provisioning e consente test funzionali di smoke sull’applicazione ripristinata senza reindirizzare traffico live.
- Simulazione di failover completo: Il test più comprensivo. Viene eseguito un failover completo, reindirizzando un piccolo sottoinsieme di traffico non critico o interno al sito di recupero. Questa esercitazione convalida l’intero processo end-to-end, dal provisioning dell’infrastruttura alla propagazione DNS e alla funzionalità dell’applicazione.
Eseguire queste esercitazioni secondo un calendario definito—ad esempio, esercitazioni a tavolino e test paralleli trimestrali, con un failover completo annuale—costruisce memoria muscolare operativa ed espone le debolezze prima che diventino passività critiche. Ogni esercitazione deve concludersi con un post-mortem per documentare i riscontri e iterare sui runbook e sugli script di automazione. Questo processo disciplinato e iterativo è ciò che garantisce che una strategia di ripristino di emergenza funzioni come progettato quando è più importante.
Bilanciare gli obblighi normativi con i vincoli di budget
Progettare una strategia cloud di ripristino di emergenza non è puramente un esercizio tecnico. È un equilibrio tra obblighi normativi e vincoli finanziari. Per qualsiasi azienda che opera in o serve l’Europa, regolamenti come il GDPR, NIS2 e DORA influenzano direttamente i piani di recupero, elevando la conformità da un requisito legale a un driver architetturale centrale.
Questi regolamenti non sono suggerimenti; sono mandati con sanzioni finanziarie e legali significative per la non conformità. Introducono requisiti specifici che un piano di DR deve affrontare per progettazione.
Tradurre la normativa in architettura
I mandati di conformità influenzano direttamente gli obiettivi di RTO e RPO e dettano scelte architetturali. Il compito è tradurre il testo legale in decisioni tecniche concrete. Per esempio:
- Residenza e sovranità dei dati: Regolamenti come il GDPR impongono regole rigorose sulla posizione geografica del trattamento e dello stoccaggio dei dati personali. Un piano di DR deve rispettare questi vincoli. Le regioni di failover e le posizioni di storage dei backup devono essere scelte per conformarsi a questi confini legali. La nostra analisi di Articolo 30 del GDPR fornisce ulteriore contesto sulla documentazione richiesta.
- Disponibilità e resilienza: Per entità finanziarie soggette a DORA o fornitori di infrastrutture critiche sotto NIS2, l’alta disponibilità è un requisito legale. Questi regolamenti obbligano di fatto a RTO bassi, spingendo le architetture verso modelli Warm o Hot Standby più sofisticati per garantire la continuità dei servizi critici.
- Segnalazione degli incidenti: NIS2 richiede la segnalazione tempestiva di incidenti di sicurezza significativi. Una segnalazione accurata e puntuale è impossibile senza un piano DR ben testato e runbook chiari per identificare, contenere e recuperare da un evento.
Tentare di retrofitare la conformità su un’architettura esistente è un errore comune e costoso. È sempre più complesso e costoso che incorporare questi requisiti nella progettazione iniziale.
Allineare il budget al rischio
Sebbene la conformità stabilisca il livello minimo di resilienza, il budget determina ciò che è praticamente realizzabile. Un’architettura multi-regione con Hot Standby può soddisfare ogni requisito normativo, ma il suo costo è proibitivo per la maggior parte delle organizzazioni. L’obiettivo non è la spesa illimitata ma l’allocazione strategica delle risorse, allineando il costo al rischio e al dovere legale.
Un’efficace disaster recovery riguarda il fare scelte consapevoli. Devi investire quanto basta per soddisfare gli obblighi legali e proteggere le funzioni aziendali critiche, ma non così tanto da compromettere il budget sovraingegnerizzando la protezione di servizi non essenziali.
Questo vincolo finanziario è uno dei principali driver dell’adozione della DR basata sul cloud. Si prevede che il mercato raggiungerà $631 milioni entro il 2032, in gran parte perché le soluzioni cloud offrono risparmi sui costi del 40-60% rispetto ai modelli tradizionali on-premise. Eliminando la spesa in conto capitale per l’hardware e riducendo i costi dovuti ai tempi di inattività, le piattaforme cloud permettono alle aziende più piccole di ottenere una resilienza di livello enterprise. Puoi consultare la analisi di mercato e i dati sui risparmi per maggiori dettagli su queste tendenze.
Per ottimizzare il budget per la DR, considera queste scelte architetturali pragmatiche:
- Usa regioni a costo inferiore: Provisiona ambienti di standby in regioni cloud meno costose per ridurre i costi di calcolo e storage.
- Sfrutta lo scaling on-demand: Progetta architetture Pilot Light o Warm Standby per funzionare su istanze più piccole e on-demand, scalando alla piena capacità di produzione solo durante un effettivo evento di failover.
- Classifica lo storage dei dati: Clasifica i dati in base alla criticità e alla frequenza di accesso. Usa tier di storage archivistico più economici come Amazon S3 Glacier o Azure Archive Storage per backup a lungo termine di dati non critici con una maggiore tolleranza di RTO.
Bilanciare conformità e budget è un esercizio di prioritarizzazione. Mappando i requisiti normativi alle specifiche applicazioni e selezionando il pattern architetturale appropriato per ciascuna, puoi costruire una strategia di DR resiliente, conforme e finanziariamente sostenibile.
Conclusione: Progettare Sistemi Resilienti fin dall’Inizio
Raggiungere una vera resilienza nel cloud non è il risultato di un progetto una tantum. È un impegno architetturale fondamentale, integrato nell’intero ciclo di vita di costruzione e gestione dei prodotti digitali. Richiede uno spostamento strategico dalla risposta reattiva agli incidenti a una progettazione proattiva, dove il recupero è una considerazione primaria fin dall’inizio.
L’obiettivo è ingegnerizzare prodotti che non siano solo funzionali ma anche robusti, manutenibili e affidabili. Questo richiede di andare oltre le checklist tecniche verso una profonda comprensione delle priorità di business, risultando in un piano di recovery sia tecnicamente efficace sia economicamente razionale.
Principi fondamentali per una strategia attuabile
Per tradurre la teoria in pratica affidabile, i leader tecnici devono ancorare la loro strategia di DR a pochi principi fondamentali. Questi pilastri assicurano che il piano rimanga radicato nel valore di business e nella realtà operativa.
- Allinea RTO/RPO all’impatto di business: Prima di qualsiasi implementazione tecnica, quantifica il tempo di fermo accettabile (RTO) e la perdita di dati accettabile (RPO) per ciascun servizio. Questo approccio guidato dal business previene sovrainvestimenti in sistemi non critici e sottoprotezione di quelli mission-critical.
- Abbraccia il modello di responsabilità condivisa: Il tuo provider cloud è responsabile dell’infrastruttura del cloud, ma tu sei responsabile di tutto ciò che costruisci nel cloud. I tuoi dati, le tue applicazioni e le tue configurazioni sono tua responsabilità da proteggere e recuperare.
- Imponi test regolari e automatizzati: Un piano di recovery non testato è una passività. Implementa esercitazioni automatizzate usando Infrastructure as Code per convalidare i runbook, eliminare l’errore umano e costruire fiducia quantificabile nella tua capacità di recupero.
Una checklist pragmatica per i leader tecnici
Un’efficace disaster recovery è il risultato di scelte deliberate e informate. È un processo continuo di bilanciamento tra rischio, costo e conformità — non la ricerca di un sistema teoricamente perfetto.
Una strategia di disaster recovery matura è un importante elemento distintivo competitivo. Comunica a clienti, regolatori e partner che la tua organizzazione è impegnata nell’eccellenza operativa ed è una custode affidabile dei loro interessi.
Usa questa checklist concisa per guidare la tua implementazione:
- Mappa la criticità di business: Hai identificato le applicazioni mission-critical e definito target RTO/RPO specifici per ciascuna?
- Seleziona l’architettura giusta: Hai scelto un pattern di DR (es. Pilot Light, Warm Standby) che si allinea ai tuoi requisiti RTO/RPO senza superare i vincoli di budget?
- Automatizza i processi di recovery: Stai usando Infrastructure as Code per automatizzare il provisioning del tuo ambiente di recovery per velocità e coerenza?
- Convalida con esercitazioni: Hai un calendario definito per test regolari di DR, includendo sia esercitazioni tabletop sia simulazioni di failover complete?
- Integra la conformità by design: Il tuo piano soddisfa requisiti normativi come GDPR o NIS2 riguardo alla residenza e disponibilità dei dati?
- Mantieni documentazione completa: Il tuo runbook di recovery è dettagliato, aggiornato e accessibile a tutta l’organizzazione di ingegneria?
Concentrandoti su questi passaggi pragmatici, puoi sviluppare una capacità di disaster recovery che sia robusta, manutenibile e allineata al successo strategico a lungo termine dei tuoi prodotti digitali.
Presso Devisia, costruiamo prodotti digitali affidabili con una mentalità di prodotto, trasformando la visione di business in software scalabile e manutenibile. Se hai bisogno di un partner per aiutarti a progettare e implementare un’architettura pragmatica e resiliente, scopri di più sul nostro approccio.