Data center network architecture is not a mere technical diagram; it is the strategic blueprint defining how data moves between servers, storage, and external systems. This architecture dictates the speed, resilience, and security of your applications, forming the foundation of your digital operations.
The Problem: When Network Architecture Becomes a Business Bottleneck
It is a critical error to view the data center network as a simple IT component or an operational cost center. For any modern digital business, it is the architectural bedrock. It can either enable rapid innovation and scale or become the primary constraint that grinds growth to a halt.
The central challenge is a fundamental shift in data traffic patterns. Historically, network traffic was predictable, flowing from users outside the data center to servers inside—a pattern known as north-south traffic. Traditional three-tier network designs (core, aggregation, access) were adequate for this model.
However, the proliferation of microservices, distributed databases, container orchestration, and AI workloads has caused an explosion of server-to-server communication within the data center.
The New Dominance of East-West Traffic
This modern operational reality is dominated by east-west traffic, where data moves laterally between thousands of internal services. A network not explicitly designed for this high-volume, low-latency communication will quickly become overwhelmed.
The consequences of architectural misalignment are severe and business-impacting:
- Application Performance Degradation: High latency and packet loss render even the most powerful servers ineffective, directly degrading user experience and impacting business-critical processes.
- Inhibited Scalability: A rigid, hierarchical network prevents the seamless addition of new services or the scaling of existing ones. This architectural friction erodes the ability to respond to market demands.
- Increased Operational Overhead: Engineering teams become trapped in a reactive cycle of troubleshooting, manual configuration, and developing workarounds for fundamental network limitations—a direct drain on budget and talent.
A well-designed network architecture is a decisive competitive advantage. It provides the foundation for building scalable, resilient, and cost-effective digital systems, elevating network design from an IT implementation detail to a core strategic decision. This guide offers a pragmatic walkthrough of the topologies, technologies, and trade-offs that define modern data center networking.
Core Architectural Patterns: From Legacy Tiers to Modern Fabrics
A data center’s network topology is the blueprint that dictates information flow, scalability limits, and where performance bottlenecks will emerge. Choosing the correct pattern is a foundational decision with direct consequences for cost, resilience, and operational agility.
The Modern Standard: Spine-Leaf Architecture
For any data center supporting modern workloads, the conversation begins with spine-leaf architecture. This design replaces rigid, multi-layered hierarchies with a flat, two-tier fabric optimized for high-bandwidth, low-latency communication.
The structure is defined by two simple components:
- Leaf Switches: Typically located at the top of each rack (Top-of-Rack), leaf switches connect directly to servers, storage, and other endpoints.
- Spine Switches: Forming the high-speed network core, every leaf switch connects to every single spine switch.
The elegance of this design lies in its strict interconnection rule. The path between any two servers in the fabric is always two hops (server -> leaf -> spine -> leaf -> server). This creates a predictable, non-blocking fabric with extremely low latency, which is essential for the relentless east-west traffic generated by AI clusters, microservices, and hyperscale applications.
The Inversion of Traffic: Why East-West Matters
The diagram below illustrates why legacy designs are no longer viable.
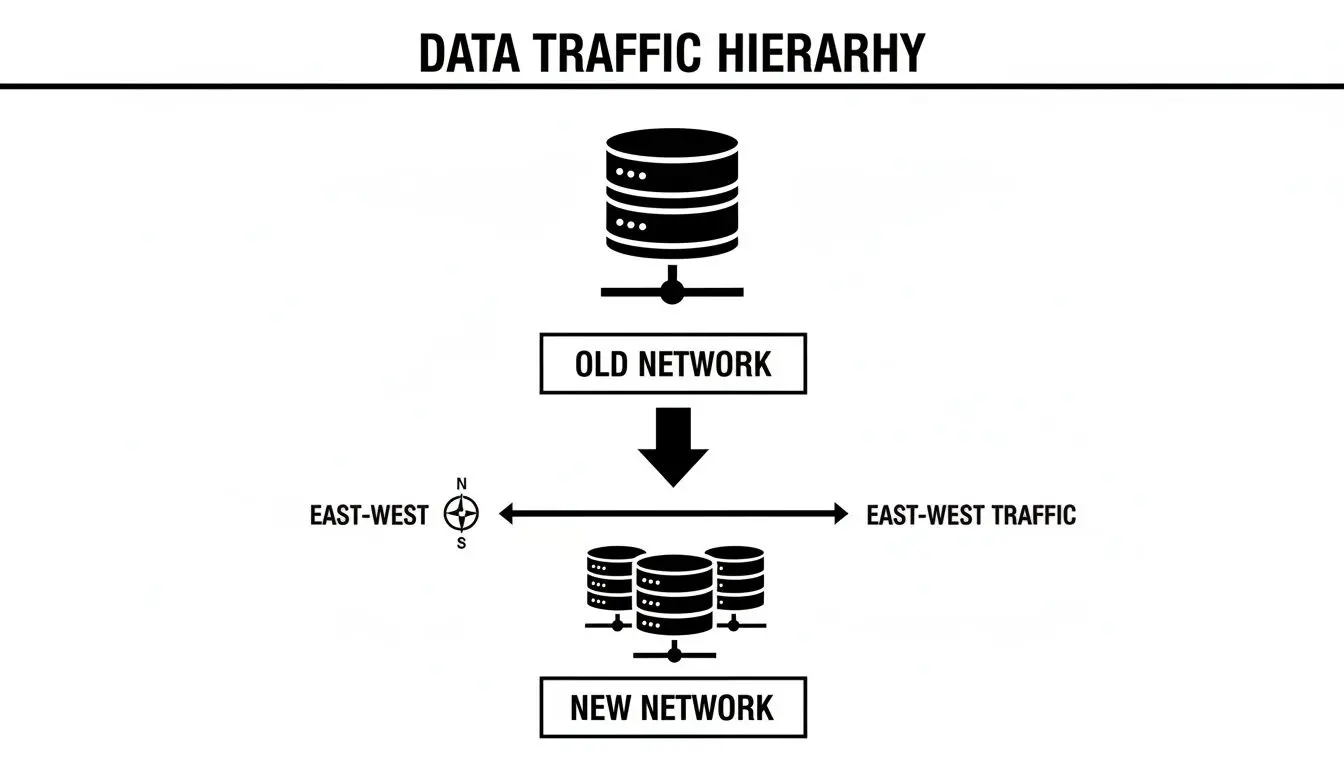
Legacy networks were built for north-south traffic—data entering and exiting the data center. Today, the vast majority of traffic is east-west, as distributed applications and AI models generate immense volumes of internal communication.
The spine-leaf model is engineered for this reality, offering seamless horizontal scalability. To add compute capacity, a new rack with a leaf switch is simply connected to the spine switches. This expands the fabric without creating new bottlenecks or requiring a disruptive overhaul of the core network.
This is a stark contrast to the legacy three-tier architecture (access, aggregation, core). While suitable for the client-server era, its inherent chokepoints at the aggregation and core layers are fatal for modern east-west workloads.
Implementation Risk: Attempting to run a modern microservices or AI workload on a three-tier network is a recipe for failure. It will create immediate performance bottlenecks, starve expensive compute resources of data, and cripple application potential from day one.
The Pragmatic Compromise: Collapsed Core
Not every environment requires a full-scale spine-leaf fabric. A collapsed core architecture offers a pragmatic middle ground for specific use cases. It merges the core and aggregation layers of the traditional three-tier model, simplifying the design and reducing initial costs.
This makes it a viable choice for smaller data centers, large branch offices, or edge deployments with predictable traffic patterns. However, it is crucial to recognize that it inherits the fundamental scaling limitations of its three-tier ancestor. It is a cost-effective solution for well-defined, contained environments, not a foundation for large-scale growth.
Architectural Trade-offs: A Comparative Analysis
This table provides a high-level comparison of the primary topologies, focusing on key architectural trade-offs.
| Characteristic | Three-Tier (Hierarchical) | Collapsed Core | Spine-Leaf (Two-Tier Fabric) |
|---|---|---|---|
| Primary Use Case | Legacy enterprise; north-south dominant traffic | Small to mid-sized DCs, branch offices | Modern DCs, AI/ML, cloud-native apps |
| Scalability | Poor; requires disruptive core upgrades | Limited; scales to a fixed point | Excellent; scales out horizontally |
| Latency | High and unpredictable | Moderate; core can be a chokepoint | Low, consistent, and predictable |
| Resilience | Moderate; relies on stateful failover at each layer | Lower; core is a single point of failure | High; multiple active-equal-cost paths |
| Cost | Lower initial cost, high scaling cost | Lowest initial cost for small deployments | Higher port density cost, but efficient scaling |
| Traffic Optimization | North-South | Mixed, but constrained for East-West | East-West |
The “best” topology is determined by the workload it must support. While spine-leaf is the superior choice for performance and scale, a collapsed core can be the right pragmatic decision when cost and simplicity are the primary constraints. The physical topology, however, is only the foundation. Upon it, we must build a logical network fabric—the combination of protocols and software-defined intelligence that makes the entire network operate as a single, programmable system.
Logical Overlays: The Brains of the Modern Network
A high-performance physical topology like spine-leaf provides the necessary transport capacity. However, the intelligence, multi-tenancy, and scale required by modern applications are delivered by logical overlay technologies running on top of this physical underlay.
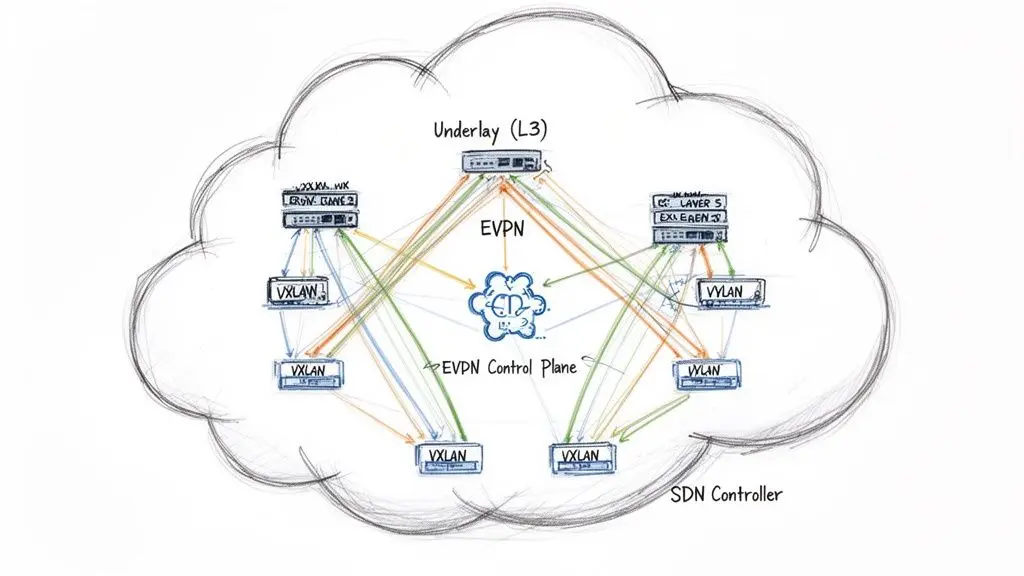
A network overlay creates virtual, logically isolated networks on top of shared physical hardware. This allows for the creation of thousands of independent networks, each with its own security and forwarding policies, all running on a common physical infrastructure.
VXLAN: Overcoming Legacy Segmentation Limits
For decades, VLANs (Virtual Local Area Networks) were the standard for network segmentation. Their critical limitation is the 12-bit identifier, which imposes a hard ceiling of 4,094 unique network segments. This is wholly insufficient for cloud providers, SaaS platforms, or any large-scale multi-tenant environment.
VXLAN (Virtual Extensible LAN) was engineered to solve this scaling problem. As an overlay technology, it encapsulates Layer 2 Ethernet frames within standard Layer 3 UDP packets. This simple encapsulation technique provides two transformative benefits:
- Massive Scale: The VXLAN Network Identifier (VNI) is a 24-bit field, allowing for over 16 million unique logical networks. This effectively removes the ceiling on segmentation.
- Underlay Independence: Because VXLAN packets are standard IP traffic, they can be routed over any Layer 3 network. This decouples the logical overlay network from the physical underlay, providing immense flexibility in hardware selection and topology design.
EVPN: An Intelligent Control Plane
VXLAN defines the data plane—how packets are encapsulated. But it requires a control plane to learn and distribute endpoint (MAC and IP address) information. Early VXLAN implementations used inefficient and complex multicast flooding for endpoint discovery.
The modern, industry-standard solution is EVPN (Ethernet VPN). Using Multiprotocol BGP (MP-BGP), EVPN functions as an intelligent, scalable control plane for the VXLAN overlay. It efficiently distributes endpoint reachability information across the fabric, replacing archaic “flood-and-learn” mechanisms with precise, event-driven updates. This makes the network more stable, scalable, and operationally transparent. Effective data center mapping is crucial for aligning these logical constructs with physical assets.
The combination of EVPN as the control plane and VXLAN as the data plane is the definitive standard for building modern, large-scale data center fabrics. It delivers the scale, segmentation, and operational efficiency required by today’s distributed applications.
SDN: Centralizing Network Intelligence
Software-Defined Networking (SDN) is the architectural principle that brings order to this complexity. SDN decouples the network’s control plane (the intelligence that decides where traffic should go) from the data plane (the hardware that forwards packets).
This separation has profound implications. Instead of configuring hundreds of devices individually, a centralized SDN controller programs the entire network from a single, authoritative source of truth. The controller defines and pushes policies, and the switches execute them. This shift is what’s fueling the market’s explosive growth—you can discover more insights on this explosive growth from Grand View Research.
Architecting for Resilience, Performance, and Cost
Designing a data center network involves a series of critical trade-offs between performance, scalability, resilience, and total cost of ownership. Making the wrong choices early on leads to technical debt, creating a brittle and expensive network that impedes business agility.
Designing for Scalability: Scaling Out, Not Up
Network scalability can be approached in two ways. Scaling up involves replacing existing hardware with larger, faster, and exponentially more expensive monolithic systems. This path is disruptive, costly, and ultimately hits a hard physical and financial ceiling.
The modern approach is scaling out. This involves adding more standard components (e.g., servers and leaf switches) to grow capacity incrementally. Spine-leaf architectures are inherently designed for this model. You can add entire racks to the fabric without a forklift upgrade or re-architecture, making cost and performance growth predictable.
Engineering for Resilience: Designing for Failure
Resilience is the network’s ability to withstand component failures without impacting service availability. In a distributed system, failures are not an exception; they are a mathematical certainty.
Architectural Principle: True resilience is not about preventing failures, but ensuring the system handles them gracefully and automatically. The goal is a seamless failover that is invisible to applications and users.
This requires a multi-layered strategy:
- Path Redundancy: Using protocols like Equal-Cost Multi-Path (ECMP), traffic is actively distributed across all available links. If a link fails, traffic is instantly and automatically rerouted over the remaining active paths without any service interruption.
- Device Redundancy: A spine-leaf fabric has no single point of failure. The loss of a leaf switch impacts only the connected rack. The loss of a spine switch reduces total fabric capacity but does not cause an outage, as all other paths remain active.
- Facility Redundancy: This extends beyond network equipment to include redundant power supplies (PSUs), uninterruptible power supplies (UPS), and diverse power feeds to mitigate the risk of facility-level events.
For hybrid environments, extending these principles is critical. Our guide on cloud computing disaster recovery offers a framework for building resilient systems that span private and public clouds.
Balancing Performance with Workload Requirements
Network performance is not a single metric. It is a balance between latency (delay) and bandwidth (throughput), and it must be engineered to match the specific demands of the workloads it supports.
For example, a high-frequency trading application demands extremely low and predictable latency. In contrast, an AI training cluster is a bandwidth-intensive workload, requiring massive throughput to shuttle terabytes of data between GPUs. A well-designed fabric ensures expensive compute resources are never left idle, waiting for data.
Analyzing Total Cost of Ownership (TCO)
A sophisticated TCO analysis looks beyond the initial capital expenditure (CapEx) for hardware. The true cost of a network includes:
- Power and Cooling: High-performance hardware consumes significant power and generates substantial heat, directly impacting operational expenditures (OpEx).
- Software Licensing: Modern network operating systems and management platforms are often subscription-based, representing a recurring cost.
- Operational Overhead: This includes the engineering effort required to design, deploy, and maintain the network. Investing in robust automation can dramatically reduce this long-term cost.
By systematically evaluating these principles, you move from simply procuring hardware to making informed architectural decisions that result in a powerful, resilient, and financially sustainable network.
Designing for Hybrid Cloud and AI Workloads
A data center network built today must be explicitly engineered for two dominant forces: hybrid cloud integration and the insatiable demands of artificial intelligence. Designing a network without considering these workloads means building an expensive anachronism that will hinder business strategy.
The Network as the Hybrid Cloud Enabler
The network is the connective tissue for any hybrid cloud strategy, bridging private on-premises infrastructure with public cloud resources. A simple internet-based VPN is insufficient for production workloads.
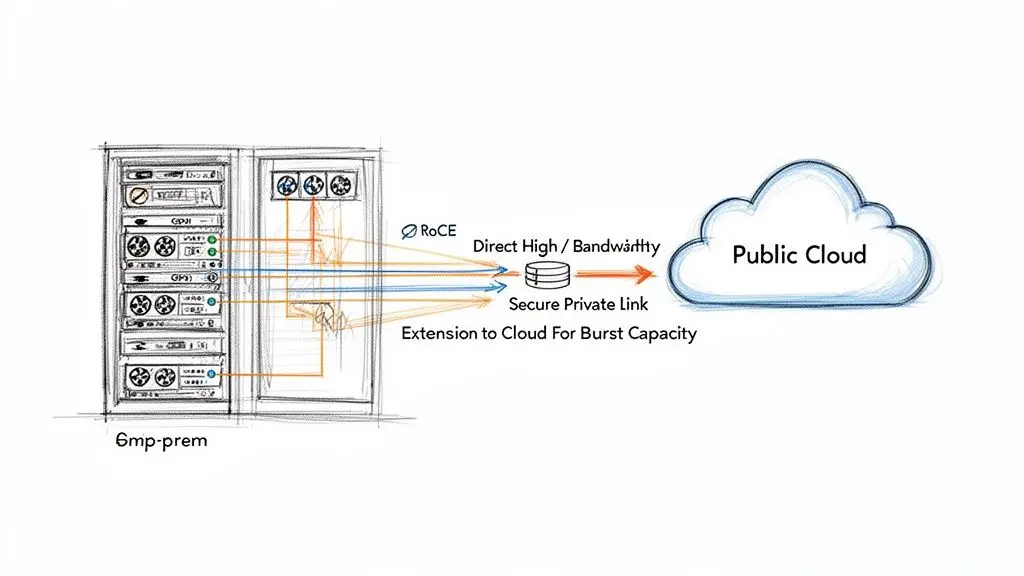
Dedicated private interconnects like AWS Direct Connect or Azure ExpressRoute are non-negotiable for serious hybrid deployments. These services provide a private, high-bandwidth, low-latency link directly into the cloud provider’s backbone network, delivering the predictable performance and robust security required for business-critical applications.
Architecting for the Demands of AI
If hybrid workloads are demanding, AI and machine learning workloads are punishing. An AI training cluster represents one of the most extreme environments for a network. The primary bottleneck in most AI clusters is not the GPUs, but the network fabric that interconnects them.
When a GPU completes a computation, it must exchange results with other GPUs and receive the next block of data. Any delay in this communication means your multi-million-dollar GPU investment sits idle—burning power without performing useful work.
Implementation Risk: A substandard network fabric is the fastest way to cripple an AI strategy. It starves your most expensive assets—the GPUs—of the data they need to function, leading to gross underutilisation and stretching training times from hours to days or even weeks.
To prevent this data starvation, AI fabrics require specific network capabilities:
- Lossless Ethernet: Standard Ethernet drops packets under congestion, forcing retransmissions that introduce unacceptable delays (jitter). A lossless fabric uses protocols like Priority-Flow Control (PFC) to prevent packet drops entirely.
- High-Bandwidth, Low-Latency Fabric: Spine-leaf designs built with 100 Gbps, 400 Gbps, or even 800 Gbps interfaces are the baseline. Anything less will create an immediate bottleneck.
- RDMA over Converged Ethernet (RoCE): Remote Direct Memory Access allows GPUs to communicate directly with each other’s memory, bypassing the host server’s CPU and operating system kernel. This is critical for efficient, low-latency GPU-to-GPU communication.
As you can learn more about these data centre networking market trends, it becomes clear that building for AI is no longer optional. Understanding the trade-offs between hosting these powerful systems in-house versus using cloud services is a critical strategic decision. If you’re weighing your options, our detailed comparison of on-premises vs. cloud infrastructure can provide valuable context.
Integrating Security, Automation, and Observability
A modern data center network must be secure by design, automated for operational simplicity, and transparent through deep observability. These are not features to be added later; they are foundational architectural requirements.
From Perimeter Security to Micro-segmentation
The legacy security model of a strong perimeter firewall protecting a trusted internal network is obsolete. This “castle-and-moat” approach fails once an attacker gains an initial foothold, as they can then move laterally across a flat, undefended internal network.
The modern paradigm is Zero Trust, which assumes no traffic is trusted by default, regardless of its origin. This is implemented through micro-segmentation.
Using overlay technologies like VXLAN, we can create thousands of isolated logical networks on a shared physical infrastructure, effectively wrapping each application or workload in its own secure, policy-defined bubble. The network fabric itself becomes the distributed firewall.
This provides two powerful security benefits:
- Breach Containment: If an attacker compromises a server, they are confined to that micro-segment. Their ability to scan for other vulnerable systems or move laterally is severely restricted, dramatically reducing the blast radius of an incident.
- Dynamic Policy Enforcement: Security policies are tied to the workload, not a static IP address or physical port. As workloads are created, destroyed, or moved, their security policies follow them automatically.
The Imperative of Infrastructure as Code
Manual, CLI-based configuration of network devices is slow, prone to human error, and does not scale. It is an operational liability in any modern data center.
The definitive approach is Infrastructure as Code (IaC). The entire desired state of the network—every switch, interface, VXLAN tunnel, and routing policy—is defined in declarative configuration files. These files are managed in a version control system (like Git) and applied by automation tools such as Ansible or Terraform.
Treating your network configuration as code transforms network operations. It makes deployments repeatable, testable, and auditable. It is the only viable method for managing a large-scale data center network architecture without an unmanageably large engineering team.
This shift elevates the role of network engineers from manual operators to developers of a resilient, automated system.
From Reactive Monitoring to Proactive Observability
Basic monitoring tells you if a device is up or down—it is reactive. Observability, in contrast, is the ability to understand the internal state of the system and ask arbitrary questions about its behavior in real-time.
Instead of polling devices every few minutes, modern observability relies on streaming telemetry. Network devices push a continuous, high-fidelity stream of operational data—traffic flows, packet latencies, buffer utilization—to a central analytics platform.
This rich data stream enables:
- Proactive Issue Detection: Identify transient microbursts or creeping congestion before they impact application performance.
- Rapid Troubleshooting: Trace a single packet’s path across the fabric to pinpoint the exact source of latency or loss in seconds, not hours.
- Capacity and Cost Management: Gain precise visibility into which applications are consuming network resources, which is essential for rightsizing infrastructure and managing costs.
Observability transforms the network from an opaque black box into a transparent, understandable system that serves as a reliable foundation for the business.
Frequently Asked Architectural Questions
Here are concise answers to common questions from CTOs and technical leaders.
When is a traditional three-tier architecture still acceptable?
Its use case is extremely limited. A three-tier design might be adequate for a small, static business environment with predictable, north-south dominant traffic and no plans for cloud-native or AI workloads. However, you must be certain that this limited scope will not become a business constraint. Choosing this path is a deliberate decision to optimize for initial cost over future flexibility.
What is the difference between a network fabric and a spine-leaf topology?
This is a critical distinction.
- Spine-leaf refers to the physical topology—the blueprint for how switches are physically interconnected in a two-tier, non-blocking layout. It is the network’s skeleton.
- A network fabric is a logical construct. It describes the entire network operating as a single, cohesive, programmable system. The fabric is built using a spine-leaf topology but also includes the control plane (e.g., EVPN), the overlay data plane (e.g., VXLAN), and the automation and observability tools that manage it.
In short: Spine-leaf is the physical blueprint; the fabric is the intelligent, automated system built upon it.
How does network architecture impact GDPR or DORA compliance?
Network architecture is a cornerstone of your technical and organizational measures for regulatory compliance.
- For GDPR, micro-segmentation via VXLAN is a powerful tool for demonstrating data protection by design. It allows you to create verifiably isolated network segments for processing personal data, enforcing the granular access controls required by the regulation.
- For financial regulations like the DORA (Digital Operational Resilience Act), the focus is on provable resilience. The inherent high availability of an EVPN-VXLAN fabric on a spine-leaf topology, combined with rich observability data, provides the technical evidence needed to demonstrate resilience, threat detection capabilities, and precise incident response. Achieving this on a legacy, flat network is operationally and legally challenging.
At Devisia, we believe that a well-architected system is the foundation of any reliable digital product. We partner with companies to translate their business vision into scalable, secure, and maintainable software, from SaaS platforms to AI-enabled systems. Learn more at https://www.devisia.pro.