L’architettura di rete di un data center non è un semplice diagramma tecnico; è il progetto strategico che definisce come i dati si muovono tra server, storage e sistemi esterni. Questa architettura determina la velocità, la resilienza e la sicurezza delle tue applicazioni, costituendo la base delle tue operazioni digitali.
Il problema: quando l’architettura di rete diventa un collo di bottiglia per il business
È un errore critico considerare la rete del data center come un semplice componente IT o un centro di costo operativo. Per qualsiasi azienda digitale moderna, essa rappresenta la base architettonica. Può consentire innovazione e scalabilità rapide oppure diventare il vincolo principale che blocca la crescita.
La sfida centrale è un cambiamento fondamentale nei modelli di traffico dati. Storicamente, il traffico di rete era prevedibile e fluiva dagli utenti esterni al data center verso i server interni: un modello noto come traffico north-south. I tradizionali design di rete a tre livelli (core, aggregazione, accesso) erano adeguati per questo modello.
Tuttavia, la proliferazione di microservizi, database distribuiti, orchestrazione di container e workload di IA ha causato un’esplosione della comunicazione server-to-server all’interno del data center.
Il nuovo predominio del traffico east-west
Questa realtà operativa moderna è dominata dal traffico east-west, in cui i dati si muovono lateralmente tra migliaia di servizi interni. Una rete non progettata esplicitamente per questa comunicazione ad alto volume e bassa latenza verrà rapidamente sopraffatta.
Le conseguenze di un disallineamento architetturale sono gravi e hanno un impatto diretto sul business:
- Degrado delle prestazioni delle applicazioni: latenza elevata e perdita di pacchetti rendono inefficaci anche i server più potenti, peggiorando direttamente l’esperienza utente e incidendo sui processi critici per il business.
- Scalabilità limitata: una rete rigida e gerarchica impedisce l’aggiunta fluida di nuovi servizi o la scalabilità di quelli esistenti. Questa frizione architetturale erode la capacità di rispondere alle richieste del mercato.
- Aumento del sovraccarico operativo: i team di ingegneria rimangono intrappolati in un ciclo reattivo di troubleshooting, configurazione manuale e sviluppo di workaround per limitazioni di rete fondamentali, con un impatto diretto su budget e talento.
Un’architettura di rete ben progettata è un vantaggio competitivo decisivo. Fornisce la base per costruire sistemi digitali scalabili, resilienti ed اقتصادي efficienti, elevando il network design da dettaglio di implementazione IT a decisione strategica fondamentale. Questa guida offre una panoramica pragmatica delle topologie, delle tecnologie e dei compromessi che definiscono il networking dei data center moderni.
Pattern architetturali di base: dai livelli legacy ai fabric moderni
La topologia di rete di un data center è il progetto che determina il flusso delle informazioni, i limiti di scalabilità e i punti in cui emergeranno i colli di bottiglia delle prestazioni. Scegliere il pattern corretto è una decisione fondamentale con conseguenze dirette su costi, resilienza e agilità operativa.
Lo standard moderno: architettura spine-leaf
Per qualsiasi data center che supporti workload moderni, la conversazione inizia con l’architettura spine-leaf. Questo design sostituisce gerarchie rigide e multilivello con un fabric piatto a due livelli ottimizzato per comunicazioni ad alta banda e bassa latenza.
La struttura è definita da due componenti semplici:
- Leaf switch: tipicamente posizionati in cima a ogni rack (Top-of-Rack), gli switch leaf si collegano direttamente a server, storage e altri endpoint.
- Spine switch: costituendo il core di rete ad alta velocità, ogni switch leaf si connette a ciascuno degli switch spine.
L’eleganza di questo design risiede nella sua regola rigorosa di interconnessione. Il percorso tra due server qualsiasi nel fabric è sempre di due hop (server -> leaf -> spine -> leaf -> server). Questo crea un fabric prevedibile e non bloccante con latenza estremamente bassa, essenziale per il traffico east-west incessante generato da cluster di IA, microservizi e applicazioni hyperscale.
L’inversione del traffico: perché l’east-west conta
Il diagramma seguente illustra perché i design legacy non sono più praticabili.
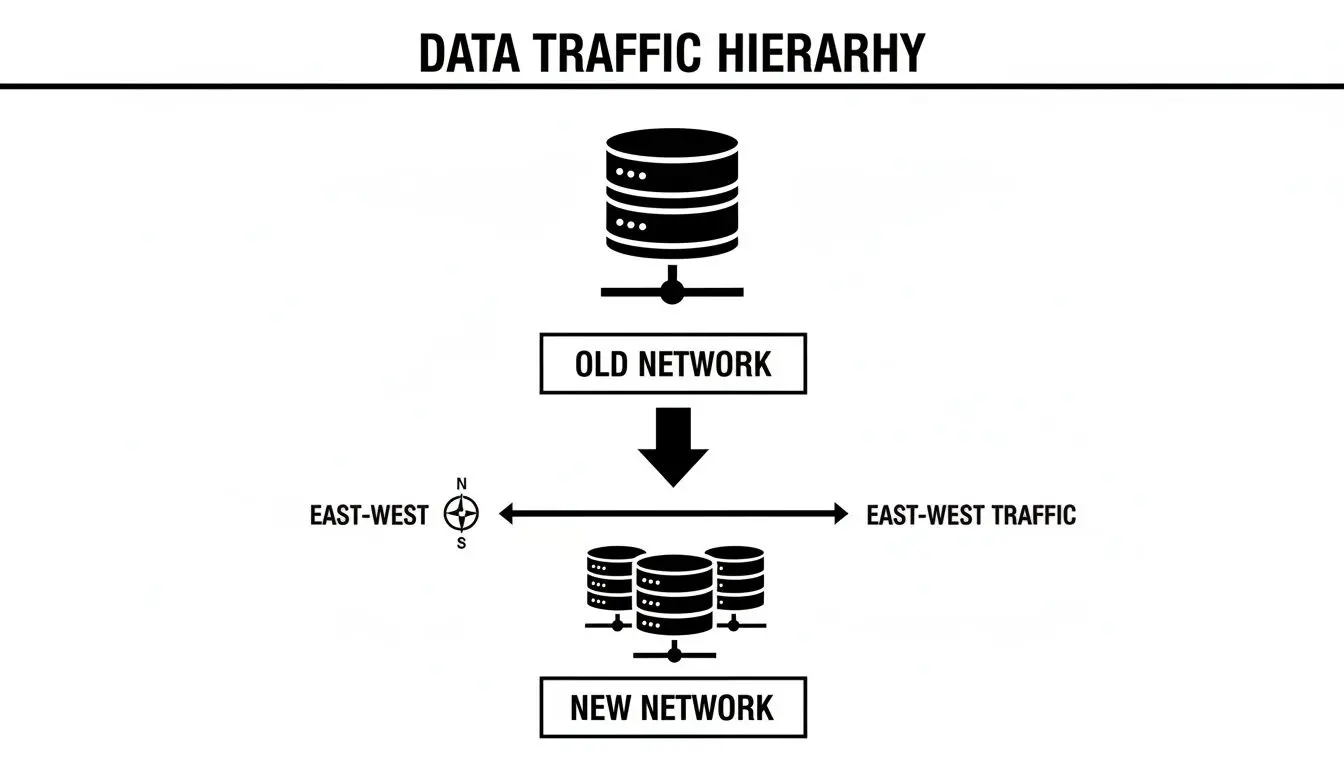
Le reti legacy erano costruite per il traffico north-south: dati in ingresso e in uscita dal data center. Oggi, la grande maggioranza del traffico è east-west, poiché le applicazioni distribuite e i modelli di IA generano volumi enormi di comunicazione interna.
Il modello spine-leaf è progettato per questa realtà e offre una scalabilità orizzontale senza soluzione di continuità. Per aggiungere capacità di calcolo, un nuovo rack con uno switch leaf viene semplicemente collegato agli switch spine. Questo amplia il fabric senza creare nuovi colli di bottiglia o richiedere una revisione invasiva del core di rete.
Questo è un netto contrasto con la architettura a tre livelli legacy (accesso, aggregazione, core). Pur essendo adatta all’era client-server, i suoi colli di bottiglia intrinseci ai livelli di aggregazione e core sono fatali per i moderni workload east-west.
Rischio di implementazione: provare a eseguire un workload moderno di microservizi o IA su una rete a tre livelli è una ricetta per il fallimento. Creerà immediati colli di bottiglia nelle prestazioni, priverà di dati costosi resource di calcolo e comprometterà il potenziale dell’applicazione fin dal primo giorno.
Il compromesso pragmatico: collapsed core
Non tutti gli ambienti richiedono un fabric spine-leaf su larga scala. Un’architettura collapsed core offre una via di mezzo pragmatica per casi d’uso specifici. Unisce i livelli core e aggregazione del modello tradizionale a tre livelli, semplificando il design e riducendo i costi iniziali.
Questo la rende una scelta valida per data center più piccoli, grandi sedi remote o implementazioni edge con pattern di traffico prevedibili. Tuttavia, è fondamentale riconoscere che eredita i limiti fondamentali di scalabilità del suo antenato a tre livelli. È una soluzione conveniente per ambienti ben definiti e contenuti, non una base per una crescita su larga scala.
Trade-off architetturali: un’analisi comparativa
Questa tabella offre un confronto di alto livello delle topologie principali, concentrandosi sui principali compromessi architetturali.
| Caratteristica | Tre livelli (gerarchica) | Collapsed Core | Spine-Leaf (fabric a due livelli) |
|---|---|---|---|
| Caso d’uso principale | Enterprise legacy; traffico dominato dal north-south | Data center piccoli e medi, sedi remote | Data center moderni, IA/ML, app cloud-native |
| Scalabilità | Scarsa; richiede aggiornamenti invasivi del core | Limitata; scala fino a un punto fisso | Eccellente; scala orizzontalmente |
| Latenza | Alta e imprevedibile | Moderata; il core può essere un collo di bottiglia | Bassa, costante e prevedibile |
| Resilienza | Moderata; si basa su failover stateful a ogni livello | Inferiore; il core è un singolo punto di guasto | Alta; più percorsi attivi a costo uguale |
| Costo | Costo iniziale inferiore, costo di scaling elevato | Costo iniziale più basso per distribuzioni piccole | Costo per densità di porte più elevato, ma scalabilità efficiente |
| Ottimizzazione del traffico | North-South | Misto, ma limitato per l’east-west | East-West |
La topologia “migliore” è determinata dal workload che deve supportare. Sebbene spine-leaf sia la scelta superiore per prestazioni e scala, un collapsed core può essere la decisione pragmatica giusta quando costo e semplicità sono i vincoli principali. Tuttavia, la topologia fisica è solo la base. Su di essa dobbiamo costruire un network fabric logico: la combinazione di protocolli e intelligenza software-defined che fa funzionare l’intera rete come un unico sistema programmabile.
Overlay logici: il cervello della rete moderna
Una topologia fisica ad alte prestazioni come spine-leaf fornisce la capacità di trasporto necessaria. Tuttavia, l’intelligenza, il multi-tenancy e la scala richiesti dalle applicazioni moderne sono forniti dalle tecnologie di overlay logico che operano sopra questo underlay fisico.
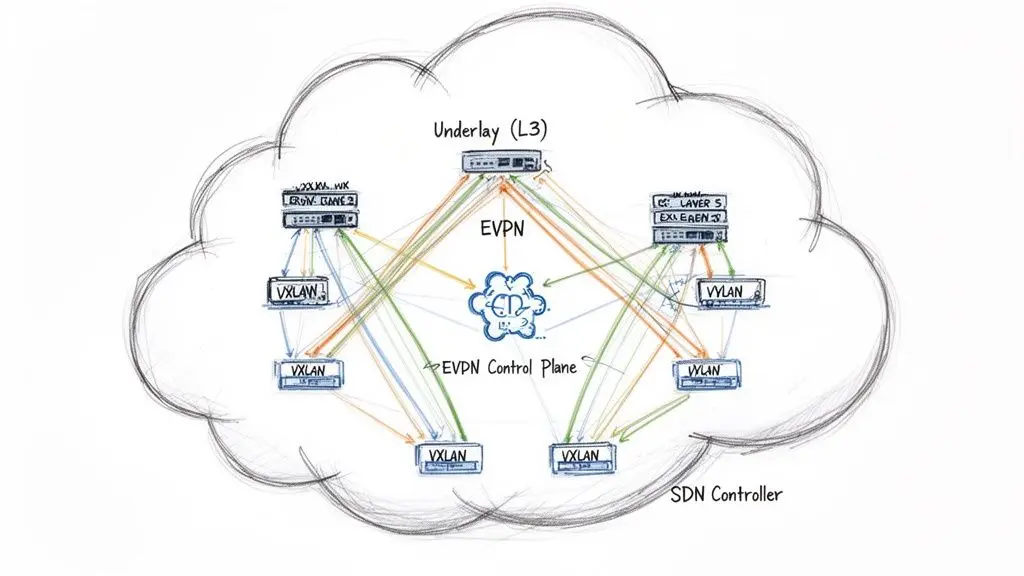
Un network overlay crea reti virtuali logicamente isolate sopra hardware fisico condiviso. Questo consente la creazione di migliaia di reti indipendenti, ciascuna con proprie politiche di sicurezza e forwarding, tutte in esecuzione su un’infrastruttura fisica comune.
VXLAN: superare i limiti della segmentazione legacy
Per decenni, le VLAN (Virtual Local Area Networks) sono state lo standard per la segmentazione di rete. Il loro limite critico è l’identificatore a 12 bit, che impone un tetto massimo di 4.094 segmenti di rete unici. Questo è del tutto insufficiente per provider cloud, piattaforme SaaS o qualsiasi ambiente multi-tenant su larga scala.
VXLAN (Virtual Extensible LAN) è stato progettato per risolvere questo problema di scalabilità. Come tecnologia overlay, incapsula frame Ethernet di Layer 2 in normali pacchetti UDP di Layer 3. Questa semplice tecnica di incapsulamento offre due vantaggi trasformativi:
- Scala massiva: il VXLAN Network Identifier (VNI) è un campo a 24 bit, che consente oltre 16 milioni di reti logiche uniche. Questo rimuove di fatto il tetto massimo sulla segmentazione.
- Indipendenza dall’underlay: poiché i pacchetti VXLAN sono traffico IP standard, possono essere instradati su qualsiasi rete Layer 3. Questo disaccoppia la rete overlay logica dall’underlay fisico, offrendo enorme flessibilità nella scelta dell’hardware e nella progettazione della topologia.
EVPN: un piano di controllo intelligente
VXLAN definisce il data plane, ovvero come i pacchetti vengono incapsulati. Ma richiede un piano di controllo per apprendere e distribuire le informazioni sugli endpoint (indirizzi MAC e IP). Le prime implementazioni VXLAN utilizzavano un flooding multicast inefficiente e complesso per l’individuazione degli endpoint.
La soluzione moderna standard del settore è EVPN (Ethernet VPN). Utilizzando Multiprotocol BGP (MP-BGP), EVPN funziona come un piano di controllo intelligente e scalabile per l’overlay VXLAN. Distribuisce in modo efficiente le informazioni di raggiungibilità degli endpoint in tutto il fabric, sostituendo gli arcaici meccanismi di “flood-and-learn” con aggiornamenti precisi e guidati dagli eventi. Questo rende la rete più stabile, scalabile e trasparente dal punto di vista operativo. Un efficace data center mapping è fondamentale per allineare queste strutture logiche con gli asset fisici.
La combinazione di EVPN come piano di controllo e VXLAN come data plane è lo standard definitivo per costruire fabric moderni di data center su larga scala. Offre la scala, la segmentazione e l’efficienza operativa richieste dalle applicazioni distribuite di oggi.
SDN: centralizzare l’intelligenza di rete
Software-Defined Networking (SDN) è il principio architetturale che porta ordine in questa complessità. SDN disaccoppia il piano di controllo della rete (l’intelligenza che decide dove deve andare il traffico) dal data plane (l’hardware che inoltra i pacchetti).
Questa separazione ha implicazioni profonde. Invece di configurare centinaia di dispositivi singolarmente, un controller SDN centralizzato programma l’intera rete da un’unica fonte autorevole di verità. Il controller definisce e invia le policy e gli switch le eseguono. Questo cambiamento è ciò che alimenta la crescita esplosiva del mercato: puoi scoprire ulteriori approfondimenti su questa crescita esplosiva da Grand View Research.
Progettare per resilienza, prestazioni e costo
Progettare una rete di data center comporta una serie di trade-off critici tra prestazioni, scalabilità, resilienza e costo totale di proprietà. Fare le scelte sbagliate fin dall’inizio porta al debito tecnico, creando una rete fragile e costosa che ostacola l’agilità del business.
Progettare per la scalabilità: crescere in orizzontale, non in verticale
La scalabilità della rete può essere affrontata in due modi. La crescita in verticale consiste nel sostituire l’hardware esistente con sistemi monolitici più grandi, più veloci e esponenzialmente più costosi. Questa strada è invasiva, costosa e alla fine incontra un rigido limite fisico e finanziario.
L’approccio moderno è la crescita in orizzontale. Ciò comporta l’aggiunta di più componenti standard (ad es. server e switch leaf) per aumentare la capacità in modo incrementale. Le architetture spine-leaf sono intrinsecamente progettate per questo modello. È possibile aggiungere interi rack al fabric senza un upgrade radicale o una riconfigurazione dell’architettura, rendendo prevedibili i costi e la crescita delle prestazioni.
Progettare per la resilienza: progettare per il guasto
La resilienza è la capacità della rete di resistere ai guasti dei componenti senza influire sulla disponibilità del servizio. In un sistema distribuito, i guasti non sono un’eccezione; sono una certezza matematica.
Principio architetturale: La vera resilienza non consiste nell’impedire i guasti, ma nel garantire che il sistema li gestisca in modo corretto e automatico. L’obiettivo è un failover senza soluzione di continuità, invisibile alle applicazioni e agli utenti.
Ciò richiede una strategia multilivello:
- Ridondanza dei percorsi: Utilizzando protocolli come Equal-Cost Multi-Path (ECMP), il traffico viene distribuito attivamente su tutti i collegamenti disponibili. Se un collegamento si interrompe, il traffico viene reindirizzato istantaneamente e automaticamente sui percorsi attivi rimanenti senza alcuna interruzione del servizio.
- Ridondanza dei dispositivi: Un fabric spine-leaf non presenta un singolo punto di guasto. La perdita di uno switch leaf ha impatto solo sul rack collegato. La perdita di uno switch spine riduce la capacità complessiva del fabric ma non causa un’interruzione, poiché tutti gli altri percorsi rimangono attivi.
- Ridondanza della struttura: Questo va oltre le apparecchiature di rete e include alimentatori ridondanti (PSU), gruppi di continuità (UPS) e alimentazioni diversificate per mitigare il rischio di eventi a livello di struttura.
Per gli ambienti ibridi, estendere questi principi è fondamentale. La nostra guida sul disaster recovery del cloud computing offre un framework per costruire sistemi resilienti che si estendono tra cloud privati e pubblici.
Bilanciare le prestazioni con i requisiti del carico di lavoro
Le prestazioni di rete non sono una singola metrica. Sono un equilibrio tra latenza (ritardo) e larghezza di banda (throughput) e devono essere progettate per corrispondere alle esigenze specifiche dei carichi di lavoro supportati.
Ad esempio, un’applicazione di trading ad alta frequenza richiede una latenza estremamente bassa e prevedibile. Al contrario, un cluster di training AI è un carico di lavoro ad alta intensità di banda, che richiede un throughput massiccio per spostare terabyte di dati tra le GPU. Un fabric ben progettato garantisce che le costose risorse di calcolo non restino mai inattive, in attesa dei dati.
Analizzare il costo totale di proprietà (TCO)
Un’analisi TCO sofisticata va oltre la spesa in conto capitale iniziale (CapEx) per l’hardware. Il costo reale di una rete include:
- Energia e raffreddamento: L’hardware ad alte prestazioni consuma molta energia e genera un notevole calore, influenzando direttamente le spese operative (OpEx).
- Licenze software: I moderni sistemi operativi di rete e le piattaforme di gestione sono spesso basati su abbonamento, rappresentando un costo ricorrente.
- Oneri operativi: Include l’impegno ingegneristico necessario per progettare, distribuire e mantenere la rete. Investire in un’automazione robusta può ridurre in modo significativo questo costo a lungo termine.
Valutando sistematicamente questi principi, si passa dal semplice acquisto di hardware a decisioni architetturali informate che portano a una rete potente, resiliente e finanziariamente sostenibile.
Progettare per il cloud ibrido e i carichi di lavoro AI
Una rete di data center costruita oggi deve essere progettata esplicitamente per due forze dominanti: l’integrazione con il cloud ibrido e le esigenze insaziabili dell’intelligenza artificiale. Progettare una rete senza considerare questi carichi di lavoro significa costruire un costoso anacronismo che ostacolerà la strategia aziendale.
La rete come abilitatore del cloud ibrido
La rete è il tessuto connettivo di qualsiasi strategia di cloud ibrido, collegando l’infrastruttura privata on-premises con le risorse cloud pubbliche. Una semplice VPN basata su Internet non è sufficiente per i carichi di lavoro di produzione.
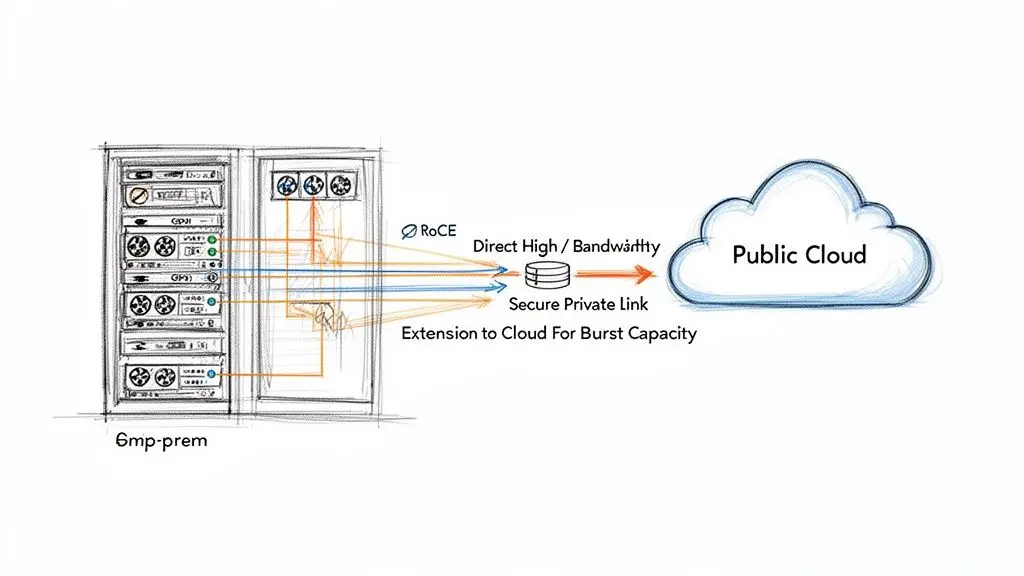
Interconnessioni private dedicate come AWS Direct Connect o Azure ExpressRoute non sono negoziabili per implementazioni ibride serie. Questi servizi forniscono un collegamento privato, ad alta banda e bassa latenza, direttamente nella rete backbone del provider cloud, offrendo le prestazioni prevedibili e la sicurezza robusta richieste dalle applicazioni business-critical.
Progettare per le esigenze dell’AI
Se i carichi di lavoro ibridi sono esigenti, i carichi di lavoro di AI e machine learning sono spietati. Un cluster di training AI rappresenta uno degli ambienti più estremi per una rete. Il collo di bottiglia principale nella maggior parte dei cluster AI non sono le GPU, ma il fabric di rete che le interconnette.
Quando una GPU completa un calcolo, deve scambiare i risultati con le altre GPU e ricevere il blocco successivo di dati. Qualsiasi ritardo in questa comunicazione significa che il vostro investimento da milioni di dollari in GPU resta inattivo, consumando energia senza svolgere lavoro utile.
Rischio di implementazione: Un fabric di rete scadente è il modo più rapido per compromettere una strategia AI. Priva i vostri asset più costosi—le GPU—dei dati di cui hanno bisogno per funzionare, portando a un grave sottoutilizzo e allungando i tempi di training da ore a giorni o persino settimane.
Per evitare questa carenza di dati, i fabric AI richiedono capacità di rete specifiche:
- Ethernet lossless: L’Ethernet standard scarta i pacchetti in caso di congestione, imponendo ritrasmissioni che introducono ritardi inaccettabili (jitter). Un fabric lossless utilizza protocolli come Priority-Flow Control (PFC) per prevenire del tutto la perdita di pacchetti.
- Fabric ad alta banda e bassa latenza: I design spine-leaf realizzati con interfacce 100 Gbps, 400 Gbps o persino 800 Gbps sono la base minima. Qualsiasi soluzione inferiore creerà un collo di bottiglia immediato.
- RDMA over Converged Ethernet (RoCE): Il Remote Direct Memory Access consente alle GPU di comunicare direttamente con la memoria reciproca, bypassando la CPU del server host e il kernel del sistema operativo. Questo è fondamentale per una comunicazione GPU-to-GPU efficiente e a bassa latenza.
Come puoi scoprire di più su queste tendenze del mercato delle reti per data center, diventa chiaro che progettare per l’AI non è più opzionale. Comprendere i compromessi tra ospitare questi potenti sistemi in sede e utilizzare servizi cloud è una decisione strategica critica. Se stai valutando le opzioni, il nostro confronto dettagliato tra infrastruttura on-premises e cloud può fornire un contesto utile.
Integrare sicurezza, automazione e osservabilità
Una moderna rete di data center deve essere sicura by design, automatizzata per la semplicità operativa e trasparente attraverso una profonda osservabilità. Questi non sono aspetti da aggiungere in seguito; sono requisiti architetturali fondamentali.
Dalla sicurezza perimetrale alla micro-segmentazione
Il modello di sicurezza tradizionale di un firewall perimetrale forte che protegge una rete interna fidata è obsoleto. Questo approccio “castello e fossato” fallisce una volta che un attaccante ottiene un primo punto d’appoggio, poiché può poi muoversi lateralmente attraverso una rete interna piatta e senza difese.
Il paradigma moderno è il Zero Trust, che presume che nessun traffico sia affidabile per impostazione predefinita, indipendentemente dalla sua origine. Questo viene implementato attraverso la micro-segmentazione.
Utilizzando tecnologie overlay come VXLAN, possiamo creare migliaia di reti logiche isolate su un’infrastruttura fisica condivisa, avvolgendo di fatto ogni applicazione o carico di lavoro nella propria bolla sicura definita dalle policy. Il fabric di rete stesso diventa il firewall distribuito.
Ciò offre due potenti vantaggi di sicurezza:
- Contenimento della violazione: Se un attaccante compromette un server, resta confinato in quel micro-segmento. La sua capacità di eseguire scansioni alla ricerca di altri sistemi vulnerabili o di muoversi lateralmente è fortemente limitata, riducendo drasticamente il raggio d’impatto di un incidente.
- Applicazione dinamica delle policy: Le policy di sicurezza sono collegate al carico di lavoro, non a un indirizzo IP statico o a una porta fisica. Man mano che i carichi di lavoro vengono creati, distrutti o spostati, le relative policy di sicurezza li seguono automaticamente.
L’imperativo dell’Infrastructure as Code
La configurazione manuale dei dispositivi di rete tramite CLI è lenta, soggetta a errore umano e non scala. È una responsabilità operativa in qualsiasi data center moderno.
L’approccio definitivo è l’Infrastructure as Code (IaC). L’intero stato desiderato della rete—ogni switch, interfaccia, tunnel VXLAN e policy di routing—è definito in file di configurazione dichiarativi. Questi file sono gestiti in un sistema di controllo versione (come Git) e applicati da strumenti di automazione come Ansible o Terraform.
Trattare la configurazione della rete come codice trasforma le operazioni di rete. Rende le distribuzioni ripetibili, testabili e verificabili. È l’unico metodo praticabile per gestire un’architettura di rete di data center su larga scala senza un team di ingegneria eccessivamente grande.
Questo cambiamento eleva il ruolo degli ingegneri di rete da operatori manuali a sviluppatori di un sistema resiliente e automatizzato.
Dal monitoraggio reattivo all’osservabilità proattiva
Il monitoraggio di base ti dice se un dispositivo è attivo o inattivo: è reattivo. L’osservabilità, al contrario, è la capacità di comprendere lo stato interno del sistema e porre domande arbitrarie sul suo comportamento in tempo reale.
Invece di eseguire polling sui dispositivi ogni pochi minuti, l’osservabilità moderna si basa sulla telemetria in streaming. I dispositivi di rete inviano un flusso continuo e ad alta fedeltà di dati operativi—flussi di traffico, latenze dei pacchetti, utilizzo dei buffer—a una piattaforma di analisi centralizzata.
Questo ricco flusso di dati consente di:
- Rilevamento proattivo dei problemi: identificare microburst transitori o congestione graduale prima che incidano sulle prestazioni delle applicazioni.
- Risoluzione rapida dei problemi: tracciare il percorso di un singolo pacchetto attraverso il fabric per individuare in pochi secondi, non ore, l’esatta origine di latenza o perdita.
- Gestione di capacità e costi: ottenere una visibilità precisa su quali applicazioni consumano risorse di rete, aspetto essenziale per dimensionare correttamente l’infrastruttura e gestire i costi.
L’osservabilità trasforma la rete da una scatola nera opaca in un sistema trasparente e comprensibile che funge da base affidabile per il business.
Domande frequenti sull’architettura
Ecco risposte concise alle domande più comuni di CTO e responsabili tecnici.
Quando è ancora accettabile una tradizionale architettura a tre livelli?
Il suo caso d’uso è estremamente limitato. Un design a tre livelli può essere adeguato per un ambiente aziendale piccolo e statico, con traffico prevedibile, prevalentemente north-south e senza piani per carichi di lavoro cloud-native o AI. Tuttavia, dovete essere certi che questo ambito limitato non diventi un vincolo per il business. Scegliere questa strada è una decisione deliberata per ottimizzare il costo iniziale a scapito della flessibilità futura.
Qual è la differenza tra un fabric di rete e una topologia spine-leaf?
Questa è una distinzione fondamentale.
- Spine-leaf si riferisce alla topologia fisica—il progetto di come gli switch sono interconnessi fisicamente in una struttura a due livelli, non bloccante. È lo scheletro della rete.
- Una network fabric è un costrutto logico. Descrive l’intera rete che opera come un unico sistema coerente e programmabile. La fabric è costruita utilizzando una topologia spine-leaf, ma include anche il piano di controllo (ad es. EVPN), il piano dati overlay (ad es. VXLAN) e gli strumenti di automazione e osservabilità che la gestiscono.
In breve: lo spine-leaf è il progetto fisico; la fabric è il sistema intelligente e automatizzato costruito su di esso.
In che modo l’architettura di rete influisce sulla conformità al GDPR o al DORA?
L’architettura di rete è un elemento fondamentale delle vostre misure tecniche e organizzative per la conformità normativa.
- Per il GDPR, la micro-segmentazione tramite VXLAN è uno strumento potente per dimostrare la protezione dei dati fin dalla progettazione. Consente di creare segmenti di rete verificabilmente isolati per l’elaborazione dei dati personali, applicando i controlli di accesso granulari richiesti dalla normativa.
- Per normative finanziarie come il DORA (Digital Operational Resilience Act), l’attenzione è rivolta alla resilienza dimostrabile. L’elevata disponibilità intrinseca di una fabric EVPN-VXLAN su una topologia spine-leaf, combinata con ricchi dati di osservabilità, fornisce le evidenze tecniche necessarie per dimostrare resilienza, capacità di rilevamento delle minacce e una risposta agli incidenti precisa. Raggiungere questo risultato su una rete legacy flat è impegnativo sia operativamente sia legalmente.
At Devisia, crediamo che un sistema ben progettato sia la base di qualsiasi prodotto digitale affidabile. Collaboriamo con le aziende per tradurre la loro visione di business in software scalabile, sicuro e manutenibile, dalle piattaforme SaaS ai sistemi abilitati all’AI. Scopri di più su https://www.devisia.pro.