
Cloud computing disaster recovery is not an IT insurance policy; it is a strategic engineering discipline. The objective is to leverage cloud infrastructure to restore data, applications, and core business functions after a catastrophic failure. Instead of relying on a secondary physical data centre, you replicate systems and data to a remote cloud environment. This approach is designed to maintain business continuity with minimal, predictable disruption and data loss, offering a significant advantage over the cost and rigidity of traditional on-premises solutions.
The Problem: Quantifying the True Cost of Downtime

Before designing a disaster recovery (DR) solution, it is critical to understand the cascading impact of a system failure. Vague notions of “outages” fail to capture the operational and financial risk, particularly for businesses built on SaaS platforms or AI-driven systems. Treating disaster recovery as a compliance checkbox, rather than a non-negotiable component of system architecture, is a common and costly mistake.
The Financial Impact
Direct revenue loss during an outage is only the beginning. Consider a multi-tenant SaaS platform where a primary database fails. The immediate financial impact includes lost subscription revenue, potential SLA credit payouts, and the significant opportunity cost of diverting senior engineers from product development to incident response.
The secondary financial damage is often more severe. Data loss remains a pervasive threat, with a recent study showing 67.7% of organisations experiencing significant data loss incidents. With the average cost of an IT outage estimated at $33,333 per minute and companies spending an average of $1.9 million annually on incident response, the financial case becomes clear. These statistics are detailed in Crashplan.com’s data loss report.
A disaster recovery plan is not an expense; it is a direct investment in revenue preservation and market credibility. The operative question is not whether you can afford to implement robust DR, but whether your business can survive without it.
The Hidden Costs Beyond the Balance Sheet
The intangible costs of an outage often inflict the most lasting harm. When a logistics platform fails, it doesn’t just halt business for a day; it erodes the trust of partners and customers who depend on your system’s availability for their own operations.
These hidden costs manifest in several ways:
- Reputational Damage: A public failure degrades market perception of your reliability, complicating customer acquisition and creating churn risk.
- Loss of Customer Trust: For any B2B software company, uptime is the currency of trust. Once lost, it is difficult and expensive to regain.
- Regulatory Fines: Failure to meet data availability requirements under regulations like GDPR, NIS2, or DORA can result in financial penalties that dwarf the cost of a compliant DR architecture.
- Diminished Team Morale: A culture of constant firefighting leads to engineer burnout, stifles innovation, and fosters a reactive, high-stress environment.
A well-architected cloud computing disaster recovery strategy is a foundational element of a sustainable business. It transitions the organization from a position of vulnerability to one of operational resilience, ensuring that when a failure occurs, the impact is controlled, predictable, and survivable.
Defining Recovery Objectives: RTO and RPO
A sound cloud disaster recovery plan begins with a business-level risk assessment, not a technology choice. Two metrics drive this entire process: the Recovery Time Objective (RTO) and the Recovery Point Objective (RPO). These are not technical jargon; they are the direct translation of business risk into engineering constraints.
RTO defines the maximum acceptable downtime following a disaster. It answers the question: “What is the maximum duration we can be offline before causing unacceptable business harm?”
RPO defines the maximum acceptable volume of data loss, measured in time. It asks: “How much data, in minutes or hours, are we willing to lose permanently?”
Precisely defining these metrics is paramount, as they directly dictate the complexity and cost of the required recovery architecture.
Aligning Technical and Business Stakeholders
RTO and RPO cannot be defined in an engineering vacuum. The process requires a focused workshop with product owners, business leaders, and senior technical staff. The objective is to move beyond generic statements like “the system must always be available” and establish concrete, quantifiable targets aligned with business realities.
A pragmatic approach is to analyze the system on a service-by-service basis. Not all components of an application carry equal weight. For a B2B SaaS platform, the customer-facing API and the primary user database are far more critical than an internal analytics dashboard that refreshes nightly.
Resilience is an exercise in trade-offs. Pursuing zero downtime and zero data loss for every component is not only financially prohibitive but also an inefficient allocation of engineering resources. The goal is appropriate resilience, not absolute resilience.
A Framework for Service Tiering
To structure this analysis, classify your services into tiers based on their business impact—considering revenue, customer operations, and compliance obligations. This framework provides a clear rationale for investing more heavily in the protection of certain services over others.
A common service tiering model includes:
- Tier 0 (Mission-Critical): Core services whose failure renders the entire platform unusable. Examples include user authentication, primary databases, and payment gateways.
- Tier 1 (Business-Critical): Services essential for key business functions that can tolerate brief interruptions. This could include core application features or critical data ingestion pipelines.
- Tier 2 (Business-Operational): Services that support internal operations or non-critical customer features, such as an admin dashboard or an asynchronous job processor.
- Tier 3 (Non-Critical): Services whose unavailability has minimal business impact. This tier typically includes development environments or internal knowledge bases.
With services tiered, you can assign realistic RTO and RPO targets to each. This is where the critical conversations about trade-offs occur.
The table below provides a practical framework for mapping business impact to RTO/RPO, which in turn informs architectural decisions.
Mapping Business Impact to RTO/RPO Tiers
| Service Tier | Example Services | Typical RPO | Typical RTO | Architectural Implication |
|---|---|---|---|---|
| Tier 0 | User Authentication, Payment Gateway, Primary OLTP Database | < 1 minute | < 15 minutes | Requires an Active-Active or Hot Standby multi-region architecture with continuous data replication. |
| Tier 1 | Core Application Logic, Customer Data API | < 1 hour | < 4 hours | A Warm Standby or Pilot Light model is often sufficient, relying on recent snapshots and scripted failover. |
| Tier 2 | Admin Dashboard, Reporting Services, Asynchronous Jobs | < 12 hours | < 24 hours | A simple Backup and Restore strategy, automated via infrastructure-as-code, is usually cost-effective. |
| Tier 3 | Dev/Test Environments, Internal Knowledge Base | 24 hours | 48+ hours | Basic, periodic backups stored in low-cost object storage are typically adequate. Manual recovery may be acceptable. |
This mapping exercise forces clarity. Can the business tolerate the loss of up to one hour of transaction data (RPO = 1 hour) for its Tier 0 database? Is a four-hour recovery window (RTO = 4 hours) acceptable for the Tier 1 application servers?
The answers become the blueprint for your cloud DR strategy. An aggressive RPO of minutes for a Tier 0 database necessitates a solution like continuous data replication. In contrast, a 24-hour RPO for a Tier 3 analytics database can be met with a simple nightly backup. This deliberate, risk-based approach ensures your DR budget is allocated to protect what truly matters.
Selecting a Cloud Disaster Recovery Architecture
With RTO and RPO targets established, the next step is to select the appropriate architectural pattern. There is no single correct solution. The goal is to align the cost and complexity of the DR strategy with the business value of each application. Applying a high-resilience, high-cost pattern universally is a rapid path to budget overruns, while under-provisioning a critical system creates unacceptable risk.
This decision tree illustrates the core trade-off: is downtime truly critical for this service?
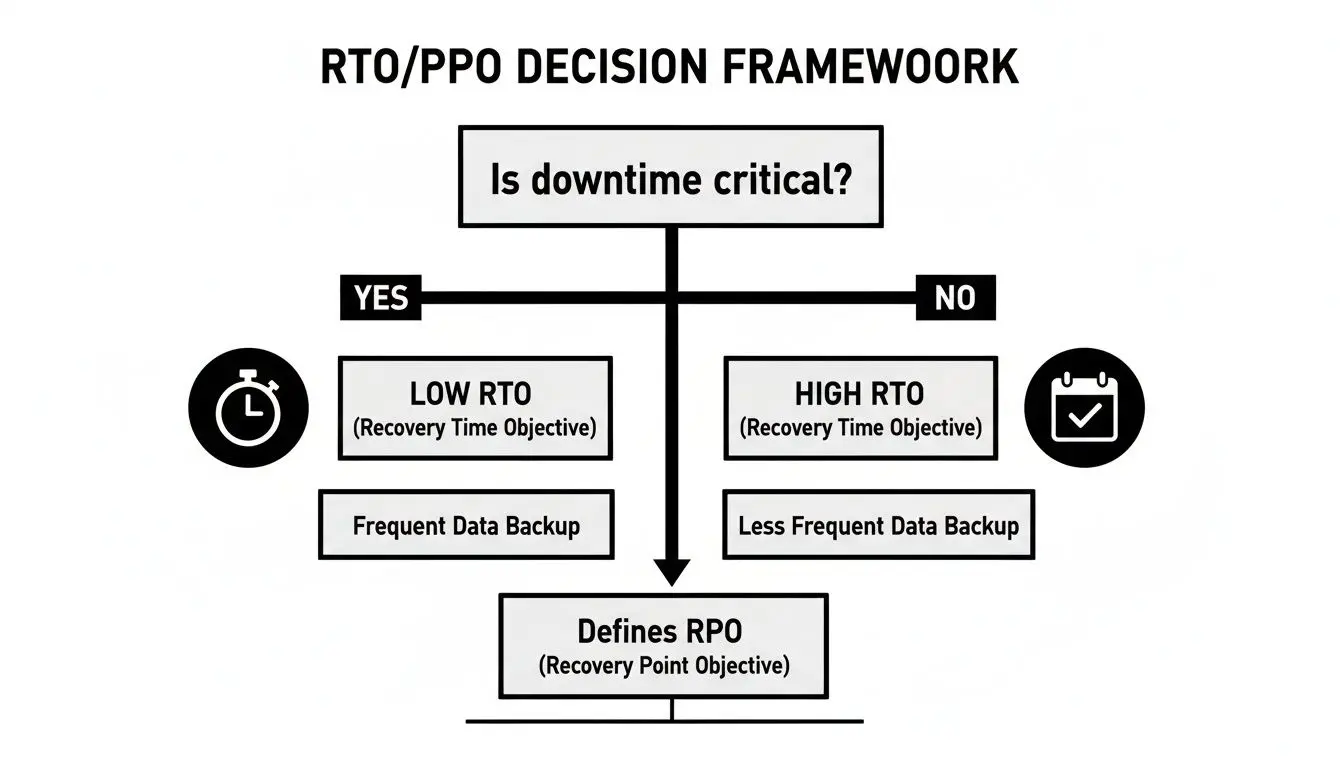
Services where downtime is catastrophic demand low RTOs, leading to more sophisticated and expensive architectures. Less critical services can tolerate longer RTOs, allowing for simpler, more cost-effective recovery models.
Market trends reflect this reality. The global cloud-based disaster recovery market was valued at $298 million in 2024 and is projected to reach $631 million by 2032. Cloud solutions can reduce DR expenditures by 40-60% compared to traditional on-premises setups. For companies integrating AI, early adopters report up to an 80% improvement in RTOs by using machine learning for predictive failure analysis and automated failover. You can find more details in this cloud-based disaster recovery market analysis.
Let’s examine the four primary architectural patterns, from simplest to most resilient.
Backup and Restore
This is the most fundamental and least expensive DR approach. It involves regularly backing up data and application configurations to a geographically separate cloud region. Backups are typically stored in durable, low-cost object storage like Amazon S3 or Azure Blob Storage.
In a disaster scenario, a recovery process is initiated to provision new infrastructure in the recovery region—ideally using Infrastructure as Code (IaC)—and restore data from the latest backup.
- RTO/RPO: This pattern results in the longest RTO and RPO. Recovery can take hours or days, depending on infrastructure provisioning time and data volume. The RPO is determined by backup frequency; a daily backup implies a potential data loss of up to 24 hours.
- Best For: Tier 3 services, such as development/test environments or non-critical batch processing jobs. It is a practical starting point for organizations new to cloud DR.
- Risk to Avoid: Incomplete backups. A common failure is backing up only the database while neglecting the configuration files, environment variables, secrets, and IAM roles required for the application to function.
Pilot Light
The Pilot Light pattern maintains a minimal, “skeletal” version of the core infrastructure in the recovery region. This might involve a small database instance or a single, idle application server. It is always on but consumes minimal resources.
During a disaster, this minimal infrastructure is scaled out to full production capacity, DNS is updated, and traffic is redirected.
The Pilot Light model provides a compelling balance between cost and recovery speed. It avoids the expense of a fully duplicated environment while significantly reducing the RTO compared to a cold backup and restore.
This architecture requires continuous data replication to the recovery region, which keeps the RPO low (typically minutes). Because core infrastructure is pre-provisioned, the RTO is also much faster.
Warm Standby
A Warm Standby architecture is an evolution of the Pilot Light model. It maintains a scaled-down but fully functional copy of the production environment in a secondary region. This standby environment is always running and may handle a small amount of traffic.
Data is actively replicated to the standby database, ensuring it remains current. In a disaster, the failover process primarily involves redirecting user traffic to the warm standby environment and scaling it up to handle the full production load.
- RTO/RPO: The RTO is significantly reduced, often to minutes, because the time-consuming tasks of provisioning and configuring servers are already complete. The RPO is also very low—seconds to minutes—due to active data replication.
- Best For: Tier 1 business-critical services where a few minutes of downtime is tolerable, but hours would cause significant harm. This is a common pattern for SaaS applications and e-commerce platforms. For more on this transition, see our guide on on-premises vs cloud architectures.
- Implementation Note: Automation is critical. To achieve the low RTO this pattern promises, the process of DNS failover, resource scaling, and health validation must be fully scripted and regularly tested.
Multi-Region Active-Active
This is the most resilient—and most expensive—DR pattern. An Active-Active architecture runs the full application stack in two or more cloud regions simultaneously. A global load balancer distributes traffic across all active regions.
There is no “failover” in the traditional sense. If one region fails, the load balancer automatically routes traffic to the healthy regions with no manual intervention.
This architecture is complex to design, implement, and operate. It requires sophisticated data replication and consistency strategies, and the application must be architected for a distributed environment.
- RTO/RPO: This pattern delivers near-zero RTO and RPO. Since another region is already handling live traffic, a regional failure has little to no user-visible impact.
- Best For: Tier 0 mission-critical systems where any downtime is unacceptable, such as global payment gateways or core authentication services.
- Cost and Complexity: Operational costs are at least doubled, and the engineering complexity is an order of magnitude higher than other patterns. Reserve this for services where the business case is incontrovertible.
Comparison of Cloud DR Architectural Patterns
This table summarizes how the four patterns compare across key metrics. Each represents a different point on the spectrum of cost, complexity, and recovery speed.
| Pattern | RTO | RPO | Relative Cost | Best For |
|---|---|---|---|---|
| Backup & Restore | Hours to Days | Hours (backup cycle) | Low | Non-critical apps, dev/test environments, archives. |
| Pilot Light | 10s of Mins to Hours | Seconds to Minutes | Low-Medium | Important but not business-critical services. |
| Warm Standby | Minutes | Seconds to Minutes | Medium-High | Business-critical applications that can tolerate brief downtime. |
| Active-Active | Near-Zero | Near-Zero | Very High | Mission-critical systems where any downtime is unacceptable. |
Selecting the right pattern is a strategic decision. The key is to avoid a one-size-fits-all approach and instead apply the appropriate level of protection to each workload based on its value to the business.
The Solution: Automating Recovery with Infrastructure as Code
An architectural diagram is not a recovery plan. Executing a flawless failover under pressure is an entirely different challenge. The single greatest point of failure in any DR plan is manual intervention. During an outage, human error is not just possible; it is probable. This is why automation via Infrastructure as Code (IaC) is a non-negotiable requirement for any serious cloud computing disaster recovery strategy.
Tools like Terraform, AWS CloudFormation, or Azure Resource Manager allow you to define the entire recovery environment in version-controlled code. Instead of manually executing a 100-step runbook, you execute a script. This codifies the process, making it repeatable, testable, and far less prone to error.
Relying on manual console operations and CLI commands during an emergency is a recipe for extended downtime. A forgotten security group rule or a mistyped database endpoint can derail the entire recovery.
Orchestrating the Failover Sequence
Effective automation extends beyond provisioning virtual machines. A robust DR orchestration script must manage the entire sequence of events, coordinating infrastructure changes, data synchronization, and traffic management.
A complete, automated failover workflow typically includes these steps:
- Infrastructure Provisioning: For Pilot Light or Backup and Restore models, IaC templates are used to build out the compute, networking, and storage resources in the recovery region.
- Data Restoration and Synchronization: The script promotes a read replica to a primary instance or restores data volumes from the latest snapshot. It must validate data consistency before proceeding.
- Configuration and Secrets Management: The script retrieves application configurations, environment variables, and secrets from a secure, replicated store like AWS Secrets Manager or HashiCorp Vault.
- Traffic Rerouting: The script automatically updates DNS records (using services like Amazon Route 53 or Azure DNS) to direct traffic to the newly active environment.
- Application Health Validation: Following the DNS update, the orchestration script executes automated health checks against application endpoints to confirm the system is fully operational.
A successful automated failover is defined by its predictability, not just its speed. By codifying every step, you transform a chaotic event into a controlled, deterministic process.
The Role of Observability and Automated Triggers
Automation requires a trigger. Observability systems—monitoring, logging, and tracing—serve as the nervous system of your DR plan. They must be configured to distinguish between a transient performance issue and a genuine disaster warranting a failover.
A sophisticated monitoring configuration might trigger a high-severity alert based on a combination of conditions:
- Sustained Latency: API response times exceed a critical threshold for more than five minutes.
- Elevated Error Rates: The percentage of 5xx server errors surpasses the established baseline.
- Failed Health Checks: Synthetic tests from multiple geographic locations fail to reach primary endpoints.
When this specific combination of alerts occurs, it can trigger a webhook that executes the DR orchestration script automatically. This removes human decision-making from the critical path, reducing RTO from hours to minutes. This level of automation is a hallmark of a mature CI/CD pipeline.
By integrating Infrastructure as Code for provisioning, orchestration scripts for sequencing, and intelligent observability for triggering, you create a closed-loop system capable of responding to disasters autonomously. This is the modern standard for building resilient cloud-native applications.
Implementation: Validating Your Plan with Realistic Testing
An untested disaster recovery plan is merely a hypothesis. To have confidence in your ability to recover, you must move from theory to practice with rigorous, regular, and realistic validation. Testing is the only way to uncover flawed assumptions and latent defects in your recovery process. Without it, your automation scripts and standby environments represent unverified assets. A culture of continuous testing is therefore central to any effective cloud computing disaster recovery strategy.
Progressing from Simulation to Full Failover
A mature testing program builds confidence incrementally, starting with simple exercises and gradually increasing in scope and realism.
-
Tabletop Exercises: The incident response team convenes to walk through a disaster scenario step-by-step. This low-risk exercise is effective for identifying gaps in communication protocols and role definitions within the runbook.
-
Partial Failover Tests: The next step is to test individual components in an isolated, non-production environment. For example, you might simulate a database failure and test only the database failover script. This validates a specific piece of automation without impacting production traffic.
-
Full Production Failover: This is the ultimate test of readiness. A full failover involves redirecting all production traffic to your recovery site during a planned maintenance window. It is the only method to truly validate your RTO and RPO targets under real-world load and conditions.
An untested recovery plan is a source of unquantified risk. Regular DR drills transform that unknown risk into a known, measured, and continuously improving capability.
Embracing Controlled Chaos
To build truly resilient systems, you must move beyond planned drills and adopt the principles of chaos engineering. This practice involves proactively and intentionally injecting controlled failures into your production environment to observe the system’s response.
Instead of waiting for a dependency to fail, you use tools to simulate that failure—for example, by blocking network access to a key API or terminating a server instance. The objective is to uncover hidden weaknesses and cascading failures that a tabletop exercise cannot reveal.
The market for this level of resilience is growing rapidly. The Disaster Recovery as a Service (DRaaS) market is projected to grow from $23.08 billion in 2026 to $83.15 billion by 2034. Yet, downtime remains a critical threat, with businesses where downtime costs between $10K and $5M per hour increasingly viewing practices like chaos engineering as essential. You can explore more on these market dynamics in this Fortune Business Insights report.
Creating the Feedback Loop
Every test must generate actionable outcomes. A post-mortem or after-action review is a non-negotiable part of the process. The team must document what functioned as expected, what failed, and where processes were unclear. The results must be measured against your defined objectives.
- Did we meet our RTO? If not, what were the bottlenecks?
- Did we meet our RPO? Was there any unexpected data loss?
- Were the runbooks and automation scripts executed without manual intervention?
The answers to these questions feed directly back into your plan. The output of every test should be a set of specific engineering tasks to improve automation, update documentation, and refine your architecture. This continuous feedback loop transforms a static DR plan into a living practice of resilience.
Conclusion: Building for Resilience, Not Just Recovery
Effective disaster recovery is not a one-time project; it is a continuous engineering practice woven into the organizational culture. The strategic goal is to shift from merely recovering after a failure to building systems that are inherently resilient by design. This represents a fundamental shift from a reactive to a proactive posture.
The core principles remain constant. You must define business risk with clear RTO and RPO targets. You must select the appropriate architectural pattern for each service, avoiding a costly one-size-fits-all approach. You must automate the failover and failback processes to eliminate human error under pressure. And you must test continuously.
Resilience is an intentional architectural choice. It’s the outcome of deliberate decisions made at every stage of the development lifecycle — from system design to operational management — ensuring your systems can withstand and adapt to unexpected failures.
This commitment protects revenue, strengthens customer trust, and builds a significant competitive advantage. When disaster recovery is treated as a core tenet of software engineering, you are building a more robust and reliable business.
For further reading on designing systems with independent, resilient components, see our article on Service-Oriented Architecture (SOA).
Cloud DR: Your Questions Answered
Here are answers to common questions we receive from technology leaders regarding the practical implementation of cloud disaster recovery.
How do we justify the cost of advanced DR?
The justification should be framed in terms of business risk, not technical features. Compare the cost of the DR solution against the quantified cost of a significant outage.
First, calculate the cost of one hour of downtime. Factor in direct revenue loss, SLA penalties, reputational damage, and the opportunity cost of engineering hours diverted to incident response. If an outage costs your company €50,000 per hour, a warm standby solution at €5,000 per month is a sound investment. It pays for itself by preventing just a few minutes of downtime over a year. Use your RTO/RPO analysis to show stakeholders exactly how the investment protects revenue-generating services.
Don’t cloud providers like AWS or Azure already handle this?
No. This is a critical and dangerous misconception. Cloud providers operate on a shared responsibility model. They are responsible for the resilience of their global infrastructure—the “cloud” itself. You are 100% responsible for the resilience of your application running in the cloud.
A regional outage, a faulty deployment that corrupts your production database, or a ransomware attack are your responsibilities to mitigate. Your cloud computing disaster recovery plan addresses failures that occur within your area of responsibility.
How does disaster recovery differ for AI systems?
AI-powered applications introduce new dependencies that your DR plan must address. Beyond application servers and traditional databases, you must account for vector databases, model inference endpoints, and large data caches.
A DR plan for an AI system must cover scenarios such as:
- Failing over to a secondary vector database in another region.
- Redirecting API calls to a replicated model endpoint or an alternative model provider.
- Having a tested process to rebuild search indexes or warm up caches post-recovery.
While the RPO for a vector database may be more tolerant than for a transactional database, its RTO is often critical, as its failure can disable core product features.
At Devisia, we believe resilience is an architectural choice, not an afterthought. We design and build reliable, maintainable software systems with a clear focus on your long-term business goals. If you need a technical partner to turn your vision into a robust digital product, let’s talk.