
Il disaster recovery nel cloud computing non è una polizza assicurativa IT; è una disciplina strategica dell’ingegneria. L’obiettivo è sfruttare l’infrastruttura cloud per ripristinare dati, applicazioni e funzioni aziendali essenziali dopo un guasto catastrofico. Invece di affidarsi a un secondo data centre fisico, si replicano sistemi e dati in un ambiente cloud remoto. Questo approccio è progettato per mantenere la continuità operativa con un’interruzione e una perdita di dati minime e prevedibili, offrendo un vantaggio significativo rispetto al costo e alla rigidità delle soluzioni tradizionali on-premises.
Il problema: quantificare il vero costo dei tempi di inattività

Prima di progettare una soluzione di disaster recovery (DR), è fondamentale comprendere l’impatto a cascata di un guasto di sistema. Le vaghe nozioni di “interruzioni” non riescono a cogliere il rischio operativo e finanziario, in particolare per le aziende basate su piattaforme SaaS o sistemi guidati dall’AI. Considerare il disaster recovery come una casella da spuntare per la conformità, anziché come un componente non negoziabile dell’architettura di sistema, è un errore comune e costoso.
L’impatto finanziario
La perdita diretta di ricavi durante un’interruzione è solo l’inizio. Considerate una piattaforma SaaS multi-tenant in cui si guasta un database primario. L’impatto finanziario immediato include la perdita di ricavi da abbonamento, potenziali rimborsi per credito SLA e il notevole costo opportunità di distogliere gli ingegneri senior dallo sviluppo prodotto alla risposta all’incidente.
Il danno finanziario secondario è spesso ancora più grave. La perdita di dati rimane una minaccia pervasiva, con uno studio recente che mostra che il 67,7% delle organizzazioni ha sperimentato incidenti significativi di perdita di dati. Con il costo medio di un’interruzione IT stimato a 33.333 $ al minuto e le aziende che spendono in media 1,9 milioni di $ all’anno in risposta agli incidenti, il caso economico diventa chiaro. Queste statistiche sono dettagliate nel report di Crashplan.com sulla perdita di dati.
Un piano di disaster recovery non è una spesa; è un investimento diretto nella preservazione dei ricavi e nella credibilità sul mercato. La domanda operativa non è se potete permettervi di implementare un DR robusto, ma se la vostra azienda può sopravvivere senza.
I costi nascosti oltre il bilancio
I costi intangibili di un’interruzione spesso causano il danno più duraturo. Quando una piattaforma logistica va in tilt, non si limita a bloccare l’attività per un giorno; erode la fiducia di partner e clienti che dipendono dalla disponibilità del vostro sistema per le proprie operazioni.
Questi costi nascosti si manifestano in diversi modi:
- Danno reputazionale: un guasto pubblico peggiora la percezione del mercato sulla vostra affidabilità, complicando l’acquisizione dei clienti e creando rischio di abbandono.
- Perdita della fiducia dei clienti: per qualsiasi azienda software B2B, l’uptime è la valuta della fiducia. Una volta persa, è difficile e costosa da recuperare.
- Multe normative: il mancato rispetto dei requisiti di disponibilità dei dati previsti da normative come GDPR, NIS2 o DORA può comportare sanzioni finanziarie che superano di gran lunga il costo di un’architettura DR conforme.
- Morale del team ridotto: una cultura di costante lotta agli incendi porta al burnout degli ingegneri, soffoca l’innovazione e favorisce un ambiente reattivo e ad alto stress.
Una strategia ben progettata di disaster recovery nel cloud computing è un elemento fondamentale di un business sostenibile. Trasforma l’organizzazione da una posizione di vulnerabilità a una di resilienza operativa, assicurando che, quando si verifica un guasto, l’impatto sia controllato, prevedibile e gestibile.
Definire gli obiettivi di ripristino: RTO e RPO
Un solido piano di disaster recovery cloud inizia con una valutazione del rischio a livello di business, non con una scelta tecnologica. Due metriche guidano l’intero processo: il Recovery Time Objective (RTO) e il Recovery Point Objective (RPO). Non si tratta di gergo tecnico; sono la traduzione diretta del rischio aziendale in vincoli ingegneristici.
RTO definisce il massimo tempo di inattività accettabile dopo un disastro. Risponde alla domanda: “Qual è la durata massima per cui possiamo restare offline prima di causare un danno aziendale inaccettabile?”
RPO definisce il massimo volume di dati che è accettabile perdere, misurato nel tempo. Chiede: “Quanti dati, in minuti o ore, siamo disposti a perdere in modo permanente?”
Definire con precisione queste metriche è fondamentale, poiché determinano direttamente la complessità e il costo dell’architettura di ripristino richiesta.
Allineare gli stakeholder tecnici e di business
RTO e RPO non possono essere definiti in un vuoto ingegneristico. Il processo richiede un workshop mirato con i product owner, i leader di business e il personale tecnico senior. L’obiettivo è andare oltre affermazioni generiche come “il sistema deve essere sempre disponibile” e stabilire obiettivi concreti e quantificabili, allineati con le realtà aziendali.
Un approccio pragmatico consiste nell’analizzare il sistema servizio per servizio. Non tutti i componenti di un’applicazione hanno lo stesso peso. Per una piattaforma SaaS B2B, l’API rivolta ai clienti e il database primario degli utenti sono molto più critici di una dashboard di analytics interna che si aggiorna ogni notte.
La resilienza è un esercizio di compromessi. Perseguire zero downtime e zero perdita di dati per ogni componente non è solo finanziariamente proibitivo, ma anche un’allocazione inefficiente delle risorse ingegneristiche. L’obiettivo è una resilienza adeguata, non assoluta.
Un framework per la classificazione dei servizi
Per strutturare questa analisi, classificate i vostri servizi in livelli in base al loro impatto sul business, considerando ricavi, operazioni dei clienti e obblighi di conformità. Questo framework fornisce una motivazione chiara per investire maggiormente nella protezione di alcuni servizi rispetto ad altri.
Un modello comune di classificazione dei servizi include:
- Livello 0 (Mission-critical): servizi essenziali il cui guasto rende l’intera piattaforma inutilizzabile. Esempi includono autenticazione utenti, database primari e gateway di pagamento.
- Livello 1 (Business-critical): servizi essenziali per funzioni aziendali chiave che possono tollerare brevi interruzioni. Questo può includere funzionalità core dell’applicazione o pipeline critiche di ingestione dati.
- Livello 2 (Business-operational): servizi che supportano le operazioni interne o funzionalità non critiche per i clienti, come una dashboard amministrativa o un processore di job asincroni.
- Livello 3 (Non critico): servizi la cui indisponibilità ha un impatto minimo sul business. Questo livello include tipicamente ambienti di sviluppo o basi di conoscenza interne.
Con i servizi classificati per livelli, potete assegnare obiettivi RTO e RPO realistici a ciascuno. È qui che avvengono le conversazioni critiche sui compromessi.
La tabella seguente fornisce un framework pratico per mappare l’impatto sul business sui livelli RTO/RPO, che a sua volta informa le decisioni architetturali.
Mappare l’impatto sul business sui livelli RTO/RPO
| Livello del servizio | Servizi di esempio | RPO tipico | RTO tipico | Implicazione architetturale |
|---|---|---|---|---|
| Livello 0 | Autenticazione utenti, gateway di pagamento, database OLTP primario | < 1 minuto | < 15 minuti | Richiede un’architettura multi-region Active-Active o Hot Standby con replica continua dei dati. |
| Livello 1 | Logica applicativa core, API dei dati clienti | < 1 ora | < 4 ore | Spesso è sufficiente un modello Warm Standby o Pilot Light, basato su snapshot recenti e failover scriptato. |
| Livello 2 | Dashboard amministrativa, servizi di reporting, job asincroni | < 12 ore | < 24 ore | Di solito è conveniente una semplice strategia di Backup and Restore, automatizzata tramite infrastructure-as-code. |
| Livello 3 | Ambienti Dev/Test, base di conoscenza interna | 24 ore | 48+ ore | Backup di base e periodici archiviati in object storage a basso costo sono in genere adeguati. Il ripristino manuale può essere accettabile. |
Questo esercizio di mappatura impone chiarezza. Il business può tollerare la perdita di fino a un’ora di dati transazionali (RPO = 1 ora) per il proprio database di Livello 0? Una finestra di ripristino di quattro ore (RTO = 4 ore) è accettabile per i server applicativi di Livello 1?
Le risposte diventano il progetto della vostra strategia DR cloud. Un RPO aggressivo di minuti per un database di Livello 0 richiede una soluzione come la replica continua dei dati. Al contrario, un RPO di 24 ore per un database analytics di Livello 3 può essere soddisfatto con un semplice backup notturno. Questo approccio deliberato, basato sul rischio, garantisce che il vostro budget DR sia allocato per proteggere ciò che conta davvero.
Selezionare un’architettura di disaster recovery cloud
Con gli obiettivi RTO e RPO stabiliti, il passo successivo è selezionare il pattern architetturale appropriato. Non esiste un’unica soluzione corretta. L’obiettivo è allineare costo e complessità della strategia DR con il valore di business di ciascuna applicazione. Applicare universalmente un pattern ad alta resilienza e alto costo è una strada rapida verso sforamenti di budget, mentre sotto-dimensionare un sistema critico crea un rischio inaccettabile.
Questo albero decisionale illustra il compromesso principale: i tempi di inattività sono davvero critici per questo servizio?
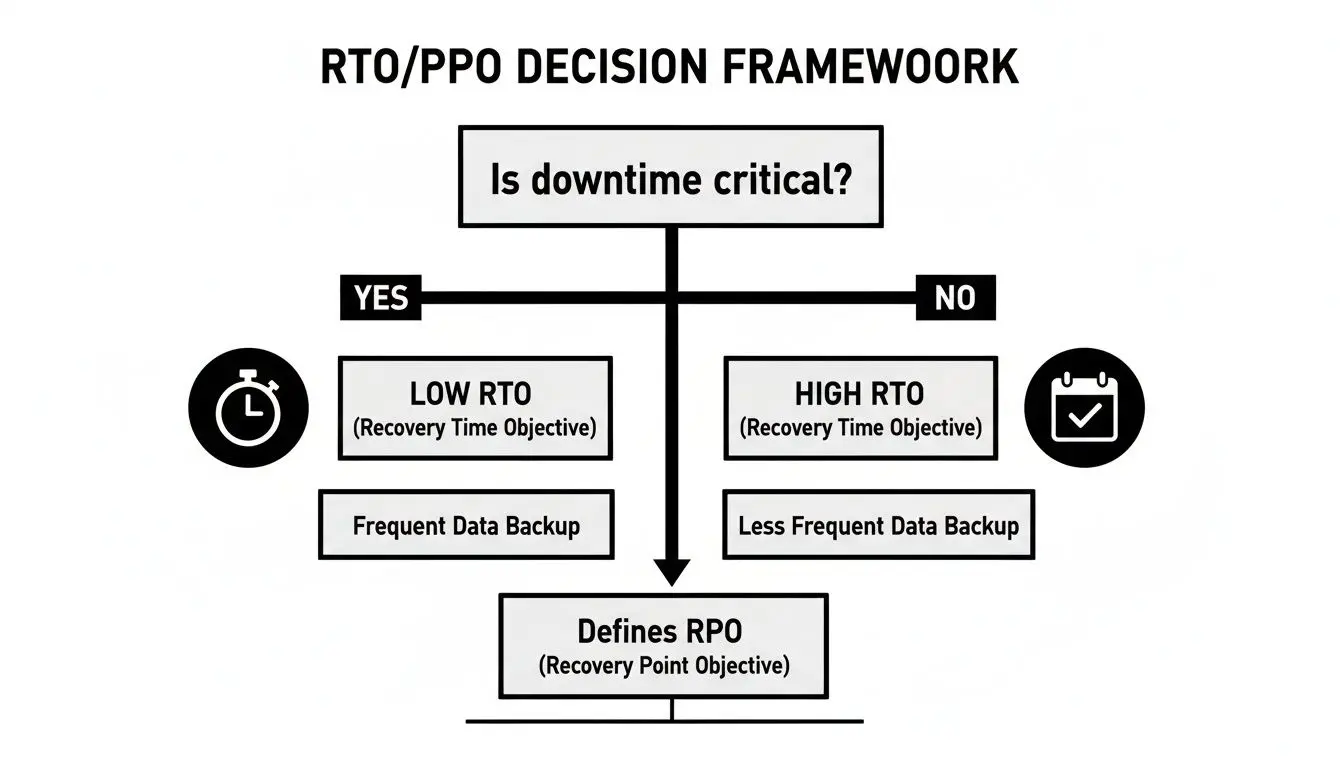
I servizi in cui i tempi di inattività sarebbero catastrofici richiedono RTO bassi, portando ad architetture più sofisticate e costose. I servizi meno critici possono tollerare RTO più lunghi, consentendo modelli di ripristino più semplici ed economici.
Le tendenze di mercato riflettono questa realtà. Il mercato globale del disaster recovery basato su cloud è stato valutato 298 milioni di $ nel 2024 e si prevede che raggiungerà 631 milioni di $ entro il 2032. Le soluzioni cloud possono ridurre le spese DR del 40-60% rispetto alle configurazioni tradizionali on-premises. Per le aziende che integrano l’AI, i primi adottanti segnalano fino a un miglioramento dell’80% degli RTO utilizzando il machine learning per l’analisi predittiva dei guasti e il failover automatizzato. Potete trovare maggiori dettagli in questa analisi del mercato del disaster recovery basato su cloud.
Esaminiamo i quattro principali pattern architetturali, dal più semplice al più resiliente.
Backup and Restore
Questo è l’approccio DR più fondamentale e meno costoso. Prevede il backup regolare di dati e configurazioni delle applicazioni in una regione cloud geograficamente separata. I backup sono generalmente archiviati in storage object durevole e a basso costo come Amazon S3 o Azure Blob Storage.
In uno scenario di disastro, viene avviato un processo di ripristino per predisporre nuova infrastruttura nella regione di recupero—idealmente utilizzando Infrastructure as Code (IaC)—e ripristinare i dati dal backup più recente.
- RTO/RPO: questo pattern comporta gli RTO e RPO più lunghi. Il ripristino può richiedere ore o giorni, a seconda dei tempi di provisioning dell’infrastruttura e del volume dei dati. L’RPO è determinato dalla frequenza dei backup; un backup giornaliero implica una potenziale perdita di dati fino a 24 ore.
- Ideale per: servizi di Livello 3, come ambienti di sviluppo/test o job di elaborazione batch non critici. È un punto di partenza pratico per le organizzazioni nuove al DR cloud.
- Rischio da evitare: backup incompleti. Un guasto comune è eseguire il backup solo del database, trascurando i file di configurazione, le variabili d’ambiente, i secrets e i ruoli IAM necessari al funzionamento dell’applicazione.
Pilot Light
Il pattern Pilot Light mantiene una versione minima, “scheletrica”, dell’infrastruttura core nella regione di recupero. Potrebbe trattarsi di una piccola istanza di database o di un singolo server applicativo inattivo. È sempre acceso ma consuma risorse minime.
Durante un disastro, questa infrastruttura minima viene scalata fino alla piena capacità di produzione, il DNS viene aggiornato e il traffico viene reindirizzato.
Il modello Pilot Light offre un equilibrio convincente tra costo e velocità di ripristino. Evita la spesa di un ambiente completamente duplicato, riducendo al contempo in modo significativo l’RTO rispetto a un backup freddo con ripristino.
Questa architettura richiede una replica continua dei dati verso la regione di recupero, mantenendo basso l’RPO (tipicamente minuti). Poiché l’infrastruttura core è pre-provisioned, anche l’RTO è molto più rapido.
Warm Standby
Un’architettura Warm Standby è un’evoluzione del modello Pilot Light. Mantiene una copia ridotta ma completamente funzionale dell’ambiente di produzione in una regione secondaria. Questo ambiente di standby è sempre attivo e può gestire una piccola quantità di traffico.
I dati vengono replicati attivamente nel database di standby, garantendo che rimanga aggiornato. In caso di disastro, il processo di failover consiste principalmente nel reindirizzare il traffico utente verso l’ambiente warm standby e nel scalarlo per gestire il carico completo di produzione.
- RTO/RPO: L’RTO è notevolmente ridotto, spesso a pochi minuti, perché le attività dispendiose in termini di tempo per il provisioning e la configurazione dei server sono già completate. Anche l’RPO è molto basso—da secondi a minuti—grazie alla replica attiva dei dati.
- Best For: Servizi business-critical di Tier 1 per i quali pochi minuti di inattività sono tollerabili, ma ore causerebbero danni significativi. Questo è uno schema comune per applicazioni SaaS e piattaforme e-commerce. Per saperne di più su questa transizione, consulta la nostra guida su on-premises vs cloud architectures.
- Implementation Note: L’automazione è fondamentale. Per ottenere il basso RTO promesso da questo schema, il processo di failover DNS, il ridimensionamento delle risorse e la convalida dello stato di salute devono essere completamente scriptati e testati regolarmente.
Multi-Region Active-Active
Questo è il pattern DR più resiliente — e più costoso. Un’architettura Active-Active esegue l’intero stack applicativo in due o più regioni cloud contemporaneamente. Un bilanciatore di carico globale distribuisce il traffico tra tutte le regioni attive.
Non esiste un “failover” nel senso tradizionale. Se una regione si guasta, il bilanciatore di carico instrada automaticamente il traffico verso le regioni integre senza alcun intervento manuale.
Questa architettura è complessa da progettare, implementare e gestire. Richiede strategie sofisticate di replica e coerenza dei dati, e l’applicazione deve essere progettata per un ambiente distribuito.
- RTO/RPO: Questo pattern offre RTO e RPO prossimi allo zero. Poiché un’altra regione sta già gestendo il traffico live, un guasto regionale ha un impatto minimo o nullo visibile all’utente.
- Best For: Sistemi mission-critical di Tier 0 per i quali qualsiasi downtime è inaccettabile, come gateway di pagamento globali o servizi di autenticazione core.
- Cost and Complexity: I costi operativi sono almeno raddoppiati, e la complessità ingegneristica è di un ordine di grandezza superiore rispetto agli altri pattern. Riservalo ai servizi per i quali il business case è incontrovertibile.
Comparison of Cloud DR Architectural Patterns
Questa tabella riassume il confronto tra i quattro pattern rispetto alle metriche chiave. Ognuno rappresenta un diverso punto nello spettro di costo, complessità e velocità di ripristino.
| Pattern | RTO | RPO | Costo Relativo | Best For |
|---|---|---|---|---|
| Backup & Restore | Ore o giorni | Ore (ciclo di backup) | Basso | App non critiche, ambienti dev/test, archivi. |
| Pilot Light | Da decine di minuti a ore | Secondi o minuti | Basso-Medio | Servizi importanti ma non business-critical. |
| Warm Standby | Minuti | Secondi o minuti | Medio-Alto | Applicazioni business-critical che possono tollerare brevi downtime. |
| Active-Active | Quasi zero | Quasi zero | Molto alto | Sistemi mission-critical per i quali qualsiasi downtime è inaccettabile. |
Scegliere il pattern giusto è una decisione strategica. La chiave è evitare un approccio valido per tutti e applicare invece il livello appropriato di protezione a ciascun workload in base al suo valore per il business.
La soluzione: automatizzare il ripristino con Infrastructure as Code
Un diagramma architetturale non è un piano di ripristino. Eseguire un failover impeccabile sotto pressione è una sfida completamente diversa. Il singolo punto di guasto più grande in qualsiasi piano DR è l’intervento manuale. Durante un’interruzione, l’errore umano non solo è possibile; è probabile. Ecco perché l’automazione tramite Infrastructure as Code (IaC) è un requisito non negoziabile per qualsiasi seria strategia di cloud computing disaster recovery.
Strumenti come Terraform, AWS CloudFormation o Azure Resource Manager ti consentono di definire l’intero ambiente di ripristino in codice versionato. Anziché eseguire manualmente un runbook di 100 passaggi, esegui uno script. Questo codifica il processo, rendendolo ripetibile, testabile e molto meno soggetto a errori.
Affidarsi a operazioni manuali da console e a comandi CLI durante un’emergenza è la ricetta per un downtime prolungato. Una regola di security group dimenticata o un endpoint database digitato in modo errato possono compromettere l’intero ripristino.
Orchestrare la sequenza di failover
Un’automazione efficace va oltre il provisioning delle macchine virtuali. Uno script di orchestrazione DR robusto deve gestire l’intera sequenza di eventi, coordinando le modifiche all’infrastruttura, la sincronizzazione dei dati e la gestione del traffico.
Un flusso di failover completo e automatizzato include in genere questi passaggi:
- Provisioning dell’infrastruttura: Per i modelli Pilot Light o Backup and Restore, i template IaC vengono usati per creare le risorse di compute, networking e storage nella regione di ripristino.
- Ripristino e sincronizzazione dei dati: Lo script promuove una replica in sola lettura a istanza primaria oppure ripristina i volumi dati dallo snapshot più recente. Deve convalidare la coerenza dei dati prima di procedere.
- Gestione della configurazione e dei secret: Lo script recupera configurazioni applicative, variabili d’ambiente e secret da uno store sicuro e replicato come AWS Secrets Manager o HashiCorp Vault.
- Reindirizzamento del traffico: Lo script aggiorna automaticamente i record DNS (usando servizi come Amazon Route 53 o Azure DNS) per indirizzare il traffico al nuovo ambiente attivo.
- Convalida dello stato di salute dell’applicazione: Dopo l’aggiornamento DNS, lo script di orchestrazione esegue controlli automatici di health sugli endpoint dell’applicazione per confermare che il sistema sia pienamente operativo.
Un failover automatizzato riuscito si definisce in base alla sua prevedibilità, non solo alla sua velocità. Codificando ogni passaggio, trasformi un evento caotico in un processo controllato e deterministico.
Il ruolo dell’osservabilità e dei trigger automatizzati
L’automazione richiede un trigger. I sistemi di osservabilità—monitoring, logging e tracing—fungono da sistema nervoso del tuo piano DR. Devono essere configurati per distinguere tra un problema di prestazioni transitorio e un vero disastro che richiede un failover.
Una configurazione di monitoraggio sofisticata potrebbe attivare un alert ad alta severità in base a una combinazione di condizioni:
- Latenza persistente: I tempi di risposta delle API superano una soglia critica per più di cinque minuti.
- Tassi di errore elevati: La percentuale di errori server 5xx supera la baseline stabilita.
- Controlli di salute falliti: Test sintetici da più località geografiche non riescono a raggiungere gli endpoint primari.
Quando si verifica questa combinazione specifica di alert, può attivare un webhook che esegue automaticamente lo script di orchestrazione DR. Questo rimuove il processo decisionale umano dal percorso critico, riducendo l’RTO da ore a minuti. Questo livello di automazione è un tratto distintivo di una mature CI/CD pipeline.
Integrando Infrastructure as Code per il provisioning, script di orchestrazione per la sequenza e osservabilità intelligente per l’attivazione, crei un sistema a circuito chiuso in grado di rispondere ai disastri in modo autonomo. Questo è lo standard moderno per costruire applicazioni cloud-native resilienti.
Implementazione: validare il tuo piano con test realistici
Un piano di disaster recovery non testato è soltanto un’ipotesi. Per avere fiducia nella tua capacità di ripristino, devi passare dalla teoria alla pratica con una validazione rigorosa, regolare e realistica. Il test è l’unico modo per scoprire assunzioni errate e difetti latenti nel processo di ripristino. Senza di esso, i tuoi script di automazione e gli ambienti standby rappresentano risorse non verificate. Una cultura di test continui è quindi centrale per qualsiasi strategia efficace di cloud computing disaster recovery.
Passare dalla simulazione al failover completo
Un programma di test maturo costruisce fiducia in modo incrementale, iniziando con esercizi semplici e aumentando gradualmente ambito e realismo.
-
Tabletop Exercises: Il team di incident response si riunisce per analizzare uno scenario di disastro passo dopo passo. Questo esercizio a basso rischio è efficace per identificare lacune nei protocolli di comunicazione e nelle definizioni dei ruoli all’interno del runbook.
-
Partial Failover Tests: Il passo successivo è testare componenti individuali in un ambiente isolato, non di produzione. Ad esempio, potresti simulare un guasto del database e testare solo lo script di failover del database. Questo convalida una specifica parte dell’automazione senza impattare il traffico di produzione.
-
Full Production Failover: Questo è il test definitivo della preparazione. Un failover completo comporta il reindirizzamento di tutto il traffico di produzione verso il sito di ripristino durante una finestra di manutenzione pianificata. È l’unico metodo per validare davvero i tuoi obiettivi di RTO e RPO sotto carichi e condizioni reali.
Un piano di ripristino non testato è una fonte di rischio non quantificato. Regolari esercitazioni DR trasformano quel rischio sconosciuto in una capacità nota, misurata e in continuo miglioramento.
Abbracciare il caos controllato
Per costruire sistemi veramente resilienti, devi andare oltre le esercitazioni pianificate e adottare i principi della chaos engineering. Questa pratica consiste nell’iniettare in modo proattivo e intenzionale guasti controllati nel tuo ambiente di produzione per osservare la risposta del sistema.
Invece di aspettare che una dipendenza si guasti, usi strumenti per simulare quel guasto—ad esempio bloccando l’accesso di rete a una API chiave o terminando un’istanza server. L’obiettivo è scoprire debolezze nascoste e guasti a catena che un tabletop exercise non può rivelare.
Il mercato per questo livello di resilienza sta crescendo rapidamente. Si prevede che il mercato Disaster Recovery as a Service (DRaaS) crescerà da $23.08 billion nel 2026 a $83.15 billion entro il 2034. Tuttavia, il downtime rimane una minaccia critica, con aziende per cui il downtime costa tra $10K and $5M per hour che considerano sempre più pratiche come la chaos engineering essenziali. Puoi approfondire queste dinamiche di mercato in this Fortune Business Insights report.
Creare il ciclo di feedback
Ogni test deve generare risultati concreti e utilizzabili. Un post-mortem o una revisione post-azione è una parte non negoziabile del processo. Il team deve documentare ciò che ha funzionato come previsto, ciò che è fallito e dove i processi non erano chiari. I risultati devono essere misurati rispetto agli obiettivi definiti.
- Abbiamo raggiunto il nostro RTO? In caso contrario, quali erano i colli di bottiglia?
- Abbiamo raggiunto il nostro RPO? C’è stata una perdita di dati imprevista?
- I runbook e gli script di automazione sono stati eseguiti senza intervento manuale?
Le risposte a queste domande rientrano direttamente nel vostro piano. Il risultato di ogni test dovrebbe essere un insieme di task ingegneristici specifici per migliorare l’automazione, aggiornare la documentazione e perfezionare l’architettura. Questo ciclo continuo di feedback trasforma un piano DR statico in una pratica viva di resilienza.
Conclusione: Progettare per la Resilienza, Non Solo per il Ripristino
Un efficace disaster recovery non è un progetto una tantum; è una pratica ingegneristica continua intrecciata nella cultura organizzativa. L’obiettivo strategico è passare dal semplice ripristino dopo un guasto alla costruzione di sistemi intrinsecamente resilienti per progettazione. Questo rappresenta un cambiamento fondamentale da un atteggiamento reattivo a uno proattivo.
I principi fondamentali restano invariati. Dovete definire il rischio di business con chiari obiettivi RTO e RPO. Dovete selezionare il modello architetturale appropriato per ciascun servizio, evitando un costoso approccio uguale per tutti. Dovete automatizzare i processi di failover e failback per eliminare l’errore umano sotto pressione. E dovete testare continuamente.
La resilienza è una scelta architetturale intenzionale. È il risultato di decisioni deliberate prese in ogni fase del ciclo di vita dello sviluppo — dalla progettazione del sistema alla gestione operativa — garantendo che i vostri sistemi possano resistere e adattarsi a guasti imprevisti.
Questo impegno protegge i ricavi, rafforza la fiducia dei clienti e costruisce un significativo vantaggio competitivo. Quando il disaster recovery viene trattato come un principio fondamentale dell’ingegneria del software, state costruendo un’azienda più solida e affidabile.
Per ulteriori approfondimenti sulla progettazione di sistemi con componenti indipendenti e resilienti, consultate il nostro articolo su Architettura Orientata ai Servizi (SOA).
DR su Cloud: Le Vostre Domande Trovano Risposta
Ecco le risposte alle domande più comuni che riceviamo dai responsabili tecnologici riguardo all’implementazione pratica del disaster recovery nel cloud.
Come giustifichiamo il costo di un DR avanzato?
La giustificazione dovrebbe essere formulata in termini di rischio di business, non di funzionalità tecniche. Confrontate il costo della soluzione DR con il costo quantificato di un’interruzione significativa.
Per prima cosa, calcolate il costo di un’ora di inattività. Tenete conto della perdita diretta di ricavi, delle penali SLA, del danno reputazionale e del costo opportunità delle ore di engineering distolte dalla risposta all’incidente. Se un’interruzione costa alla vostra azienda €50.000 all’ora, una soluzione warm standby a €5.000 al mese è un investimento solido. Si ripaga prevenendo anche solo pochi minuti di inattività in un anno. Utilizzate la vostra analisi RTO/RPO per mostrare agli stakeholder esattamente come l’investimento protegge i servizi che generano ricavi.
I provider cloud come AWS o Azure non gestiscono già tutto questo?
No. Questa è una falsa convinzione critica e pericolosa. I provider cloud operano secondo un modello di responsabilità condivisa. Sono responsabili della resilienza della loro infrastruttura globale — il “cloud” stesso. Voi siete responsabili al 100% della resilienza della vostra applicazione in esecuzione nel cloud.
Un’interruzione regionale, un deployment difettoso che corrompe il database di produzione o un attacco ransomware sono vostre responsabilità da mitigare. Il vostro piano di disaster recovery per il cloud computing affronta i guasti che si verificano nell’ambito della vostra area di responsabilità.
In che modo il disaster recovery differisce per i sistemi AI?
Le applicazioni basate sull’AI introducono nuove dipendenze che il vostro piano DR deve considerare. Oltre ai server applicativi e ai database tradizionali, dovete tenere conto di database vettoriali, endpoint di inferenza dei modelli e grandi cache di dati.
Un piano DR per un sistema AI deve coprire scenari come:
- Il failover verso un database vettoriale secondario in un’altra regione.
- Il reindirizzamento delle chiamate API a un endpoint di modello replicato o a un provider di modelli alternativo.
- Avere un processo testato per ricostruire gli indici di ricerca o riscaldare le cache dopo il ripristino.
Sebbene l’RPO per un database vettoriale possa essere più tollerante rispetto a quello di un database transazionale, il suo RTO è spesso critico, poiché il suo guasto può disabilitare funzionalità chiave del prodotto.
In Devisia, crediamo che la resilienza sia una scelta architetturale, non un ripensamento dell’ultimo minuto. Progettiamo e realizziamo sistemi software affidabili e manutenibili con un chiaro focus sui vostri obiettivi di business a lungo termine. Se avete bisogno di un partner tecnico per trasformare la vostra visione in un prodotto digitale robusto, parliamone.