
Una pipeline CI/CD è il processo automatizzato che porta il software dal commit di uno sviluppatore attraverso le fasi di build, test e deployment fino a un ambiente di produzione. Agisce come un piano di controllo centrale per la delivery del software, imponendo qualità e coerenza ed eliminando i rischi intrinseci dell’intervento manuale. Per qualsiasi organizzazione che costruisca o gestisca sistemi software reali, una pipeline robusta non è un lusso: è un requisito fondamentale per rilasci prevedibili e di alta qualità.
Il problema: perché la consegna manuale è insostenibile
In un mercato competitivo, la velocità e l’affidabilità della delivery del software sono fattori diretti dei risultati di business. I processi di deployment manuale introducono attriti significativi, portando a ritardi inaccettabili e a un’elevata probabilità di errore umano. Ogni passaggio manuale — compilare il codice, eseguire i test, configurare gli ambienti o distribuire gli artefatti — diventa un potenziale punto di failure.
Questo attrito crea problemi sistemici:
- Cicli di rilascio imprevedibili: i processi manuali sono intrinsecamente incoerenti, rendendo difficile prevedere quando le nuove funzionalità raggiungeranno gli utenti.
- Rischio aumentato: i deployment “big bang”, che raggruppano numerose modifiche, amplificano il rischio associato a ciascun rilascio. Un singolo errore può causare downtime significativo e richiedere rollback complessi e stressanti.
- Feedback ritardato: gli sviluppatori potrebbero non scoprire che le loro modifiche hanno compromesso il sistema fino a giorni o settimane dopo il commit iniziale, rendendo il debugging costoso e inefficiente.
- Rallentamento dell’innovazione: quando i deployment vengono percepiti come eventi ad alto rischio, i team diventano riluttanti a rilasciare frequentemente. Questa cautela soffoca l’innovazione e amplia il divario tra sviluppo prodotto ed esigenze del mercato.
Per le organizzazioni che operano in settori regolamentati o gestiscono sistemi AI complessi, le conseguenze di un deployment fallito vanno oltre i problemi tecnici, impattando la fiducia dei clienti, la conformità normativa (ad es. GDPR, DORA) e la stabilità finanziaria.
La soluzione: un cambiamento strategico verso l’automazione
Una pipeline CI/CD affronta questi problemi trasformando la delivery del software da un evento manuale ad alto rischio in un flusso di lavoro automatizzato a basso rischio. Automatizzando in modo sistematico le fasi di build, test e deployment, stabilisce un percorso coerente, ripetibile e verificabile dal codice sorgente alla produzione.
Questa scelta architetturale offre vantaggi critici:
- Cicli di feedback accelerati: la pipeline fornisce feedback immediato. Se un commit introduce una regressione o fallisce una scansione di sicurezza, lo sviluppatore viene avvisato in pochi minuti, non in giorni.
- Delivery incrementale a basso rischio: l’automazione consente ai team di rilasciare modifiche piccole e incrementali. Questa pratica riduce drasticamente il “blast radius” dei potenziali failure e semplifica la risoluzione dei problemi.
- Affidabilità e conformità migliorate: l’automazione elimina la configuration drift e le procedure manuali incoerenti. Ogni deployment aderisce allo stesso processo validato, garantendo affidabilità e offrendo una chiara traccia di audit per scopi di conformità.
I dati di mercato sottolineano questo cambiamento strategico. Il mercato degli strumenti di integrazione continua è stato valutato a 1,73 miliardi di dollari nel 2025 e si prevede che raggiungerà 4,53 miliardi di dollari entro il 2030. Non si tratta di una tendenza superficiale; è un chiaro indicatore del fatto che le organizzazioni stanno investendo nell’automazione come capacità fondamentale. I team maturi rilasciano software dal 60 all’80% più velocemente rispetto a quelli che si affidano ancora a processi manuali. Puoi trovare più dati sull’adozione degli strumenti CI/CD su TechnologyMatch.com.
Una pipeline CI/CD non è semplicemente un insieme di strumenti; è un asset strategico. Consente a un’azienda di rispondere ai cambiamenti del mercato con agilità, innovare con fiducia e costruire sistemi resilienti che supportano la stabilità operativa a lungo termine.
Scomporre una pipeline CI/CD pronta per la produzione
Una pipeline CI/CD pronta per la produzione è più di una sequenza di script; è una catena di assemblaggio automatizzata progettata per trasformare i commit di codice sorgente in release validate e di livello production. Ogni fase funziona come un controllo di qualità, assicurando che solo il codice affidabile proceda allo step successivo.
Questa infografica illustra il contrasto tra la natura lenta e soggetta a errori della delivery manuale e l’output prevedibile e ad alta velocità di una pipeline automatizzata ben progettata.
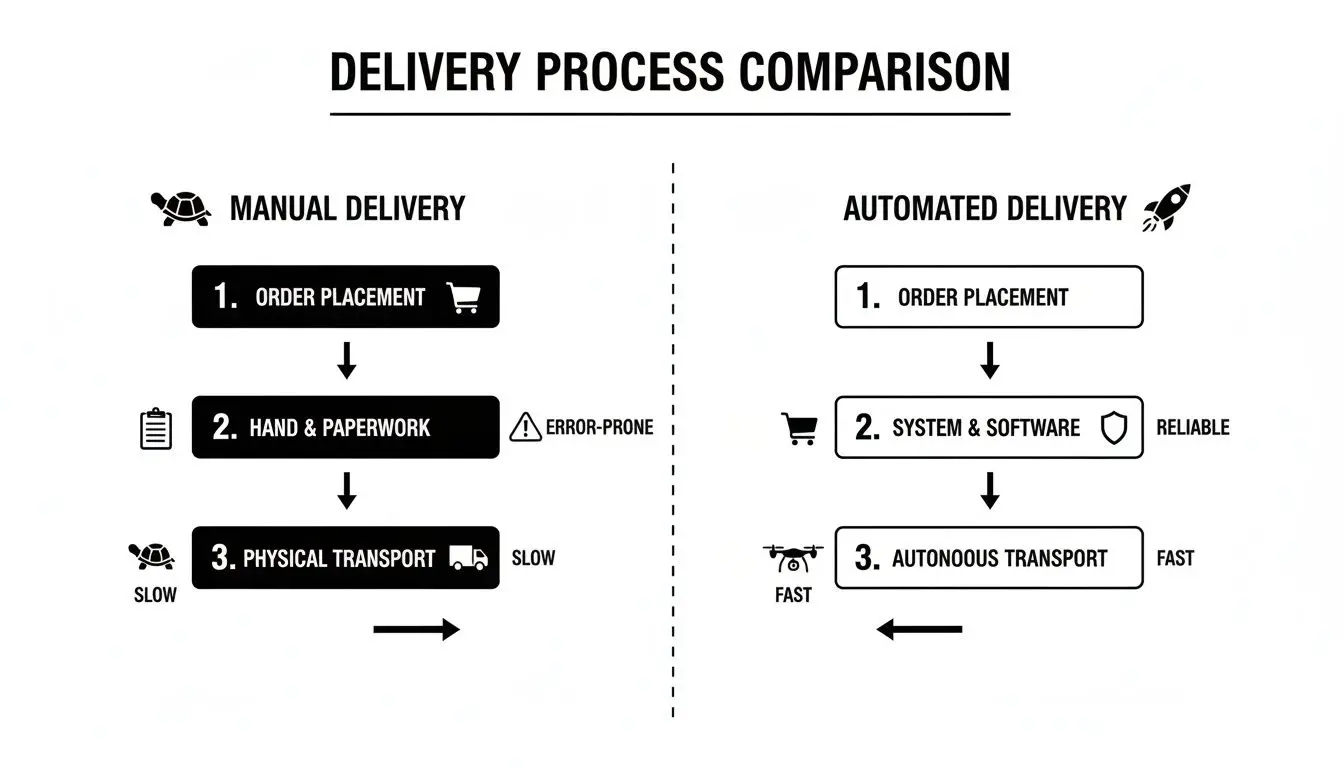
Il principio fondamentale è la sostituzione delle azioni umane incoerenti con processi deterministici e automatizzati. Questo migliora direttamente sia la velocità di delivery sia la qualità del software. Per implementare un sistema del genere, dobbiamo prima comprenderne le fasi costitutive.
Le fasi chiave di una pipeline CI/CD e le loro funzioni principali
La seguente tabella descrive le principali fasi di una pipeline tipica. Ogni fase si basa sulla precedente, spostando metodicamente il codice dal commit alla produzione attraverso una serie di controlli qualità automatizzati.
| Fase | Obiettivo principale | Attività comuni | Considerazioni di implementazione |
|---|---|---|---|
| Source | Attivare la pipeline e imporre la qualità del codice nel punto di ingresso. | Commit del codice in un repository Git, trigger via webhook, code review obbligatorie, branch protetti. | Stabilisce un’unica fonte di verità e impedisce al codice non verificato di entrare nel branch principale di sviluppo. |
| Build | Compilare il codice sorgente in un pacchetto eseguibile e autonomo (artifact). | Compilazione del codice, esecuzione di linter, risoluzione delle dipendenze, creazione di un’immagine container Docker. | Crea un artifact coerente e portabile che si comporta in modo identico in tutti gli ambienti. |
| Test | Validare automaticamente l’artifact per correttezza, prestazioni e sicurezza. | Esecuzione di test unitari, di integrazione e end-to-end; analisi statica (SAST); scansione delle vulnerabilità delle dipendenze. | Individua i difetti in anticipo, riduce il carico manuale del QA e aumenta la fiducia nel release candidate. |
| Deploy | Rilasciare l’artifact validato in uno o più ambienti. | Pubblicazione dell’artifact su staging o produzione usando strategie come blue-green, canary o rolling deployment. | Consente una consegna rapida di nuove funzionalità agli utenti con rischi minimi e permette una raccolta controllata dei feedback. |
Un failure in qualsiasi fase interrompe il processo e fornisce feedback immediato al team di sviluppo, garantendo che i problemi vengano affrontati prima che raggiungano gli utenti.
La fase Source: il singolo punto di ingresso
L’intera pipeline viene attivata quando uno sviluppatore esegue il commit del codice in un sistema di controllo versione (VCS) come Git. Il VCS non è semplicemente un meccanismo di archiviazione; è la fonte di verità autorevole e verificabile dell’intero sistema.
In questa fase, l’integrità del processo è fondamentale. Imponendo pratiche come branch protetti e peer review obbligatorie si crea la prima linea di difesa, assicurando che gli standard di qualità del codice siano rispettati prima ancora che inizi l’automazione. Questo è controllo qualità applicato alla fonte.
La fase Build: dal codice all’artifact
Dopo un commit riuscito su un branch designato, il server di Continuous Integration (CI) (ad es. Jenkins, GitLab CI) recupera l’ultimo codice sorgente e avvia il processo di build. L’obiettivo è compilare il codice e impacchettarlo in un’unica unità immutabile e distribuibile nota come artifact.
Nelle architetture moderne, questo artifact è tipicamente un’immagine container Docker. La containerizzazione è una scelta architetturale critica perché racchiude l’applicazione insieme a tutte le sue dipendenze — librerie, runtime e file di configurazione — in un pacchetto isolato. Questo garantisce che l’applicazione venga eseguita in modo coerente in tutti gli ambienti, eliminando la classe di problemi del tipo “funziona sulla mia macchina”.
La fase Test: validazione automatizzata
Con un artifact di build disponibile, la pipeline procede ai test automatizzati. Non si tratta di un singolo test, ma di una strategia di validazione multilivello progettata per individuare i difetti il prima possibile, quando sono meno costosi da correggere. Un errore comune nell’implementazione è affidarsi a un solo tipo di test. Una pipeline robusta bilancia velocità e copertura con un mix di tipologie di test:
- Unit Tests: test rapidi che verificano componenti o funzioni individuali in isolamento. Forniscono feedback immediato agli sviluppatori ma non validano le interazioni tra componenti.
- Integration Tests: test più lenti che verificano le interazioni tra diverse parti del sistema (ad es. applicazione e database).
- End-to-End (E2E) Tests: i test più completi, che simulano i reali flussi di lavoro degli utenti dall’inizio alla fine. Offrono il massimo livello di fiducia ma sono i più lenti e fragili da mantenere.
Il compromesso è chiaro: test più veloci e più ristretti forniscono feedback rapido, mentre test più lenti e più ampi offrono maggiore fiducia. Una pipeline efficace esegue questi test in modo strategico, iniziando dai più veloci (unit test) per “fallire rapidamente” prima di investire tempo in una validazione più completa.
La fase Deploy: rilascio controllato in produzione
Una volta che un artifact supera tutti i test automatizzati, è pronto per il deployment. Questa fase di Continuous Delivery (CD) rilascia la build validata agli utenti. Una pipeline matura considera il deployment come un processo controllato e strategico, non come un evento ad alto rischio.
Una pipeline CI/CD matura consente al deployment di essere un’operazione di routine e a basso rischio. L’obiettivo è rilasciare con fiducia minimizzando il potenziale impatto di eventuali problemi imprevisti.
Le strategie moderne di deployment limitano il “blast radius” di un nuovo rilascio. Invece di un aggiornamento “big bang” ad alto rischio, i team utilizzano pattern come:
- Blue-Green Deployment: il traffico viene commutato istantaneamente da una vecchia versione dell’applicazione a una nuova.
- Canary Releases: la nuova versione viene distribuita inizialmente a un piccolo sottoinsieme di utenti. Se il monitoraggio indica stabilità, il rilascio viene gradualmente esteso all’intera base utenti. Questo approccio trasforma i rilasci da eventi stressanti a operazioni aziendali di routine.
Scegliere il giusto pattern architetturale per la tua pipeline
Il pattern architetturale scelto per il tuo sistema pipeline ci cd è una decisione fondamentale che influisce direttamente sulla produttività degli sviluppatori, sulle prestazioni della build e sulla manutenibilità a lungo termine. La scelta ruota attorno alla struttura del repository, che a sua volta determina come le pipeline vengono organizzate, attivate e gestite. Non esiste una risposta universalmente corretta; la scelta ottimale dipende dalla struttura del team, dalla complessità del progetto e dagli obiettivi strategici.
I due pattern architetturali dominanti sono il monorepo e il multi-repo, ciascuno con trade-off distinti.
Monorepo: l’approccio centralizzato
Un monorepo consolida tutto il codice di un’organizzazione in un unico repository. Tutti i servizi, le applicazioni e le librerie condivise coesistono.
- Vantaggio chiave: semplifica le modifiche trasversali e la gestione delle dipendenze. Le modifiche che interessano più servizi possono essere apportate in un unico commit atomico, garantendo la coerenza a livello di sistema. Esiste una sola versione di qualsiasi libreria condivisa, mitigando il problema del “dependency hell”.
- Vincolo principale: può soffrire di problemi di prestazioni man mano che il repository cresce. Senza strumenti intelligenti che costruiscano solo ciò che è cambiato, i tempi di build possono diventare proibitivamente lenti. La sola scala può inoltre porre sfide sia per gli sviluppatori sia per il sistema CI.
Multi-repo: il modello distribuito
In un’architettura multi-repo, ogni servizio o applicazione ha il proprio repository dedicato. Questo modello promuove l’autonomia dei team, consentendo a ciascun team di gestire il proprio codebase, le dipendenze e il ciclo di rilascio.
- Vantaggio chiave: le pipeline sono in genere più veloci e più mirate, poiché sono limitate a un singolo servizio. I team possono operare in modo indipendente senza interferenze.
- Vincolo principale: la gestione delle dipendenze e il coordinamento delle modifiche tra i repository rappresentano una sfida significativa. L’aggiornamento di una libreria condivisa può innescare una cascata di modifiche su più servizi, richiedendo un’orchestrazione e un versionamento complessi. Questo sovraccarico operativo non va sottovalutato.
I dati di settore confermano l’adozione diffusa di queste pratiche. Oggi, l’83% dei decision-maker IT ha implementato DevOps. Il mercato degli strumenti lo riflette, con piattaforme come Atlassian Bitbucket che detengono una quota di mercato del 18,61% e CircleCI al 5,72%. I team maturi che sfruttano l’automazione delle pipeline liberano il 33% di tempo in più per attività infrastrutturali critiche. Altre statistiche DevOps sono disponibili su Spacelift.io.
Pipelines-as-Code: una pratica non negoziabile
Indipendentemente dalla struttura del repository, una pratica è essenziale: definire la propria pipeline usando Pipelines-as-Code. Ciò comporta il commit della definizione della pipeline—tipicamente un file YAML per strumenti come GitHub Actions o GitLab CI/CD—nello stesso repository del codice dell’applicazione.
Trattando la configurazione della pipeline come codice, la trasformi da un processo fragile e configurato manualmente in un asset versionato, verificabile e recuperabile. Questo è un principio fondamentale per costruire sistemi software resilienti e manutenibili.
Questo approccio offre vantaggi immediati:
- Controllo di versione: tutte le modifiche alla pipeline vengono tracciate in Git, fornendo una cronologia completa.
- Auditabilità: la definizione della pipeline viene revisionata e approvata attraverso lo stesso processo di pull request utilizzato per il codice dell’applicazione.
- Riproducibilità: un nuovo ambiente può essere provisionato o ripristinato istantaneamente, poiché la definizione della pipeline è archiviata nel controllo sorgente.
La scelta tra monorepo e multi-repo è una decisione strategica basata su compromessi organizzativi. Tuttavia, adottare Pipelines-as-Code è una necessità tattica per qualsiasi team che costruisca un processo di delivery robusto.
Integrare sicurezza e osservabilità nella tua pipeline
Una pipeline di base automatizza la delivery, ma una moderna pipeline CI/CD costruisce fiducia e resilienza nel ciclo di vita del software. L’obiettivo non è semplicemente rilasciare codice più velocemente, ma rilasciarlo in modo sicuro e con una chiara comprensione del suo comportamento in produzione. Ciò richiede l’integrazione diretta dei principi di DevSecOps e osservabilità nella pipeline, rendendoli proprietà intrinseche del processo di delivery e non considerazioni secondarie.
Questa filosofia “shift-left” prevede di spostare i controlli di sicurezza e qualità il più presto possibile nel ciclo di sviluppo. Invece di scoprire una vulnerabilità critica settimane dopo il deployment, l’obiettivo è rilevarla pochi minuti dopo un commit. Questo approccio proattivo è essenziale per costruire sistemi sicuri e manutenibili.
Spostare a sinistra con scansioni di sicurezza integrate
Gli strumenti di sicurezza automatizzati integrati nella pipeline sono il modo più efficace per far rispettare le policy di sicurezza. Non si tratta di creare barriere burocratiche, ma di fornire agli sviluppatori un feedback immediato e azionabile. Gli audit di sicurezza manuali sono troppo lenti e costosi per essere la linea di difesa principale.
Una pipeline DevSecOps robusta include diversi livelli di scansione automatizzata:
- Static Application Security Testing (SAST): analizza il codice sorgente alla ricerca di vulnerabilità note (ad es. SQL injection, gestione non sicura degli errori) prima della compilazione.
- Dependency Scanning: controlla tutte le librerie di terze parti rispetto a database di vulnerabilità note (CVE), segnalando qualsiasi pacchetto che introduca rischio.
- Container Analysis: analizza le immagini container Docker per individuare vulnerabilità nel sistema operativo di base o nei pacchetti installati e configurazioni di sicurezza errate.
Incorporando questi controlli, stabilisci una baseline di sicurezza rispetto alla quale viene valutato ogni commit. Non si tratta solo di una best practice tecnica; è una strategia critica di gestione del rischio. Puoi iniziare identificando i potenziali punti deboli con la nostra gratuita AI Risk & Privacy Checklist.
Trattare la tua pipeline come un prodotto
Una pipeline CI/CD è un prodotto interno i cui clienti sono i team di ingegneria. Come ogni prodotto, richiede manutenzione, monitoraggio e miglioramento continuo. Ciò richiede di integrare l’osservabilità nella pipeline stessa.
Una pipeline senza metriche è una scatola nera. Non puoi migliorare ciò che non misuri. L’obiettivo è raccogliere dati azionabili che ti aiutino a identificare i colli di bottiglia e ad aumentare la produttività degli sviluppatori.
Le metriche chiave da monitorare includono:
- Durata della build: quanto tempo impiega un’esecuzione della pipeline dal commit al completamento? Picchi improvvisi possono indicare test inefficienti o vincoli di risorse.
- Tasso di fallimento: quale percentuale di esecuzioni della pipeline fallisce? Un tasso di fallimento elevato spesso indica test “flaky” che erodono la fiducia degli sviluppatori nell’automazione.
- Tempo di ripristino: quando una pipeline si interrompe, quanto tempo serve per riportarla a uno stato funzionante? Questa metrica riflette la manutenibilità del tuo sistema.
L’analisi di queste metriche aiuta a identificare i punti di attrito. I dati mostrano che le organizzazioni mature spesso utilizzano più strumenti CI/CD (il 32% ne usa due, il 9% ne usa tre o più), con GitHub Actions in testa con un’adozione del 33% e Azure DevOps al 24%. Ciò riflette una strategia di selezione dei migliori strumenti della categoria per esigenze specifiche come sicurezza e osservabilità. Il ROI è significativo, con il 44% dei leader che riporta un ritorno 5x e risparmi superiori a 2,5 milioni di dollari in tre anni individuando i problemi in anticipo. Altre statistiche CI/CD possono essere trovate su Integrate.io.
Questa mentalità da prodotto—affinare continuamente la pipeline sulla base dei dati—è ciò che distingue un semplice script di automazione da un asset strategico che moltiplica l’efficacia dell’ingegneria.
Evitare le insidie comuni e gli anti-pattern delle pipeline
Implementare una pipeline CI/CD è un importante miglioramento architetturale, ma l’automazione da sola non garantisce il successo. Senza una progettazione e una manutenzione attente, una nuova toolchain può diventare una fonte di attrito e fallimento. Questi problemi, o anti-pattern, in genere non derivano da limitazioni tecniche, ma dal trascurare la pipeline come un sistema vivo che richiede miglioramento continuo.
La pipeline flaky
Una “pipeline flaky” è una pipeline che fallisce per ragioni non deterministiche e non correlate alla modifica del codice, come timeout di rete, problemi transitori dell’ambiente o test scritti male. Questo è estremamente dannoso per il morale del team.
Quando gli sviluppatori non possono più fidarsi del fatto che una build rossa indichi un problema reale, iniziano a ignorare tutti i fallimenti di build. L’automazione diventa rumore e il suo valore viene perso. Lo standard deve essere una affidabilità del 100%: la pipeline fallisce solo quando esiste un problema genuino da affrontare. Ciò richiede di identificare aggressivamente e mettere in quarantena i test non deterministici.
Cicli di feedback lenti
Una pipeline che impiega un’ora per fornire feedback è un grave ostacolo alla produttività. I lunghi cicli di build e test costringono gli sviluppatori a cambiare contesto, interrompendo il loro flusso di lavoro e rallentando lo slancio del team. Inoltre, i lunghi cicli di feedback aumentano la probabilità che modifiche in conflitto si accumulino nel branch principale, complicando l’integrazione.
È necessaria un’ottimizzazione incessante:
- Parallelizzare l’esecuzione dei test: eseguire in parallelo le suite di test indipendenti per ridurre il tempo totale di esecuzione.
- Ottimizzare il caching della build: configurare il processo di build per riutilizzare artefatti e dipendenze compilati in precedenza.
- Fallire in fretta: strutturare la pipeline in modo che esegua prima i test più rapidi (ad es. linters, test unitari) per fornire un feedback immediato sugli errori semplici.
Il collo di bottiglia del deployment
Questo anti-pattern è spesso più culturale che tecnico. Si verifica quando l’automazione viene implementata fino al punto di deployment, ma il rilascio finale in produzione è bloccato da gate di approvazione manuali, riunioni del change advisory board o da una cultura della paura attorno ai rilasci.
Una pipeline è veloce solo quanto il suo gate più restrittivo. Se l’automazione termina con un comitato di approvazione manuale, hai ottenuto l’integrazione continua ma sei ancora lontano dalla delivery continua.
La soluzione consiste nel costruire fiducia nell’automazione. Implementa rilasci progressivi come i canary release, investi in una solida osservabilità per monitorare le prestazioni in tempo reale e dai ai team l’autonomia di distribuire i propri servizi. Questo è un aspetto centrale del miglioramento continuo, un argomento che esploriamo nella nostra guida su come i progetti Kaizen mantengono i sistemi esistenti.
Gestione inadeguata dei secret
Codificare hardcoded i secret—chiavi API, credenziali del database, certificati—direttamente negli script della pipeline o nel controllo sorgente è una grave vulnerabilità di sicurezza. Espone credenziali critiche a chiunque abbia accesso al repository o ai log di build.
Questo non è negoziabile: una pipeline deve integrarsi con uno strumento dedicato alla gestione dei secret come HashiCorp Vault, AWS Secrets Manager o Azure Key Vault. Le credenziali dovrebbero essere iniettate dinamicamente nell’ambiente di build a runtime e non devono mai essere memorizzate in testo semplice.
Anti-pattern delle pipeline CI/CD e strategie di mitigazione
| Anti-pattern | Impatto negativo | Strategia di mitigazione consigliata |
|---|---|---|
| La pipeline flaky | Gli sviluppatori perdono fiducia nei risultati della build e iniziano a ignorare i fallimenti, rendendo la pipeline inutile. | Identificare aggressivamente e mettere in quarantena i test non deterministici. Puntare a una build affidabile al 100%. |
| Cicli di feedback lenti | Gli sviluppatori cambiano contesto, la produttività cala e l’integrazione diventa più complessa e rischiosa. | Parallelizzare i test, ottimizzare il caching e strutturare la pipeline per “fallire in fretta” eseguendo prima i test rapidi. |
| Il collo di bottiglia del deployment | Il valore dell’automazione viene perso a causa di gate manuali e di una cultura guidata dalla paura, impedendo una vera delivery continua. | Costruire fiducia tramite l’osservabilità, adottare rilasci progressivi (ad es. canary release) e responsabilizzare i team. |
| Gestione inadeguata dei secret | Espone credenziali sensibili nel codice o nei log, creando una grave vulnerabilità di sicurezza. | Integrarsi con un secret manager dedicato per iniettare le credenziali dinamicamente a runtime. Non codificare mai i secret hardcoded. |
Evitare queste insidie richiede di trattare la pipeline non solo come uno strumento tecnico, ma come un processo critico che richiede disciplina, manutenzione e raffinamento continuo.
Principi essenziali per un’implementazione CI/CD di successo
Un’implementazione CI/CD di successo è più di un esercizio tecnico; è un’iniziativa strategica che richiede un cambiamento nella cultura e nelle pratiche ingegneristiche. Attenersi ad alcuni principi fondamentali garantisce che la pipeline fornisca un valore aziendale tangibile invece di diventare un ulteriore livello di complessità.
Inizia dal problema, non dallo strumento
Prima di valutare gli strumenti CI/CD, definisci chiaramente il problema che stai cercando di risolvere. Il problema principale sono cicli di rilascio lenti? Alti tassi di failure in produzione? Flussi di lavoro degli sviluppatori inefficienti? Una dichiarazione del problema ben definita garantisce che la tua strategia pipeline ci cd sia focalizzata sull’affrontare vincoli aziendali specifici, evitando l’adozione della tecnologia per il semplice gusto di farlo.
Considera la tua pipeline come un prodotto
La tua pipeline è un prodotto interno e i tuoi ingegneri ne sono i clienti. Richiede una chiara responsabilità, una roadmap di manutenzione e un perfezionamento continuo basato sul feedback degli utenti. Misura le sue prestazioni, identifica i colli di bottiglia e investe tempo ingegneristico per renderla più veloce, più affidabile e più facile da usare.
Una pipeline di cui gli sviluppatori non si fidano è peggio di nessuna pipeline. Deve essere affidabile, efficiente e mantenuta attivamente per generare valore. Altrimenti, diventa solo un’altra fonte di frustrazione.
Integra la sicurezza fin dal primo giorno
La sicurezza non può essere un ripensamento. Deve essere una parte automatizzata e integrante della pipeline fin dal primo commit. Integra direttamente nel flusso di lavoro strumenti per l’analisi statica (SAST), l’analisi della composizione del software (SCA) per le dipendenze e la scansione dei container. Questo approccio “shift-left” fornisce agli sviluppatori un feedback immediato sulla sicurezza e favorisce una cultura di responsabilità condivisa in materia di sicurezza.
Promuovi una cultura di iterazione e fiducia
L’efficacia di una pipeline è determinata in ultima analisi dalla cultura organizzativa. L’automazione deve essere accompagnata dalla sicurezza psicologica, dando ai team la possibilità di distribuire piccole modifiche frequenti senza timore di essere incolpati. Ciò richiede l’implementazione di post-mortem senza colpe e la promozione di un senso di responsabilità operativa condivisa. Questo principio è una pietra angolare di una sana cultura ingegneristica, che approfondiamo nella nostra guida alla creazione di un codice di condotta per team di engineering e AI.
Domande frequenti
Di seguito trovi risposte pratiche alle domande comuni che emergono quando si pianifica o si perfeziona una strategia pipeline ci cd, pensate per guidare i leader tecnici.
Come scegliere gli strumenti CI/CD giusti?
Lo strumento “migliore” è quello che si adatta meglio al tuo ecosistema tecnico, all’esperienza del team e ai requisiti di scalabilità. L’obiettivo è ridurre l’attrito per gli sviluppatori, non adottare l’ultima tendenza.
Considera questi fattori:
- Integrazione con l’ecosistema: Se la tua organizzazione utilizza GitHub, GitHub Actions offre un’integrazione senza soluzione di continuità. Per chi cerca una piattaforma tutto in uno, GitLab combina controllo del codice sorgente, CI/CD e registry.
- Personalizzazione vs. manutenzione: Per flussi di lavoro complessi e su misura, Jenkins offre un’ampia personalizzazione ma comporta un maggiore carico di manutenzione.
- Allineamento con il cloud provider: I principali provider cloud—AWS, Azure e GCP—offrono servizi CI/CD nativi e maturi che si integrano strettamente con le rispettive offerte infrastrutturali.
Seleziona strumenti che si allineino ai tuoi flussi di lavoro esistenti e li migliorino.
Qual è la differenza tra Continuous Delivery e Continuous Deployment?
Questi termini descrivono due livelli distinti di automazione nel processo di rilascio. La distinzione è fondamentale per definire obiettivi strategici chiari per la tua pipeline.
- Continuous Delivery garantisce che ogni modifica che supera tutti i test automatizzati venga rilasciata automaticamente in un ambiente simile allo staging. Tuttavia, il deployment finale in produzione richiede approvazione manuale. Questo modello offre controllo sul momento esatto dei rilasci.
- Continuous Deployment è la completa automazione dell’intero processo di rilascio. Ogni modifica che supera tutti i test automatizzati viene distribuita automaticamente in produzione senza intervento umano. Ciò richiede un livello estremamente elevato di fiducia nelle capacità di test, monitoraggio e rollback automatico.
Come possiamo misurare il ROI di una pipeline CI/CD?
Il ritorno sull’investimento (ROI) di una pipeline CI/CD si misura attraverso metriche che riflettono miglioramenti tangibili nelle prestazioni di delivery, nella qualità e nell’efficienza ingegneristica. Le quattro metriche DORA chiave sono lo standard del settore per misurare le prestazioni di un’organizzazione di software delivery:
- Frequenza di deployment: Con quale frequenza un’organizzazione rilascia con successo in produzione.
- Lead time per le modifiche: Il tempo necessario affinché un commit arrivi in produzione.
- Tasso di fallimento delle modifiche: La percentuale di deployment che causano un failure in produzione.
- Tempo di ripristino del servizio (MTTR): Quanto tempo serve per recuperare da un failure in produzione.
I miglioramenti in queste metriche forniscono una base quantitativa per il ROI, che può essere integrata con dati qualitativi come le ore risparmiate dagli sviluppatori su attività manuali e i costi evitati grazie alla riduzione degli incidenti in produzione.
In che modo CI/CD si applica ai modelli AI e ML?
I principi di una pipeline ci cd sono alla base delle Machine Learning Operations (MLOps), ma vengono estesi per gestire il ciclo di vita specifico dei modelli AI/ML. L’obiettivo resta l’automazione e l’affidabilità, ma il processo deve gestire asset oltre al codice sorgente, ovvero dati e modelli addestrati.
Una pipeline MLOps include le fasi CI standard ma ne aggiunge di nuove:
- Validazione dei dati: Controlli automatizzati sulla qualità, lo schema e le proprietà statistiche dei dati di addestramento.
- Addestramento e validazione del modello: Riaddestramento automatico dei modelli e valutazione programmatica rispetto a benchmark di prestazione.
- Deployment del modello: Pacchettizzazione del modello validato come servizio o API scalabile.
- Monitoraggio in produzione: Tracciamento continuo delle prestazioni del modello nel mondo reale per rilevare “concept drift” o degrado dei dati che richiedono un nuovo addestramento.
MLOps adatta il paradigma CI/CD per gestire l’intero ciclo di vita di dati, modelli e codice come un sistema coerente.
At Devisia, crediamo che una pipeline CI/CD robusta sia la base di qualsiasi prodotto digitale affidabile. Collaboriamo con le aziende per costruire sistemi software manutenibili e scalabili con una mentalità product che garantisca valore a lungo termine. Scopri come possiamo aiutarti a trasformare la tua visione in realtà su https://www.devisia.pro.
_Articolo creato utilizzando Outrank