
Quando devi annullare le modifiche di uno specifico commit in un repository condiviso, il comando più sicuro e professionale è git revert <commit-hash>. Questa azione crea un commit interamente nuovo che annulla le modifiche originali, mantenendo la cronologia del progetto pulita, intatta e stabile per tutto il team.
Il problema: conseguenze indesiderate nei repository condivisi
In qualsiasi progetto software, da una piattaforma SaaS a un complesso sistema di AI, l’introduzione di bug è una certezza operativa. Uno sviluppatore potrebbe pushare un commit che degrada le prestazioni dell’API, rompe una funzionalità critica o introduce una vulnerabilità di sicurezza. L’impatto sul business può essere immediato e grave.
La sfida non è prevenire tutti gli errori, ma avere un processo robusto e prevedibile per correggerli senza interrompere il team di sviluppo o corrompere il codebase. Un approccio ingenuo — come riscrivere forzatamente la cronologia — può trasformare un singolo commit errato in un guasto di sincronizzazione a livello di team. È qui che padroneggiare git revert su un commit specifico diventa una competenza imprescindibile per la leadership tecnica.
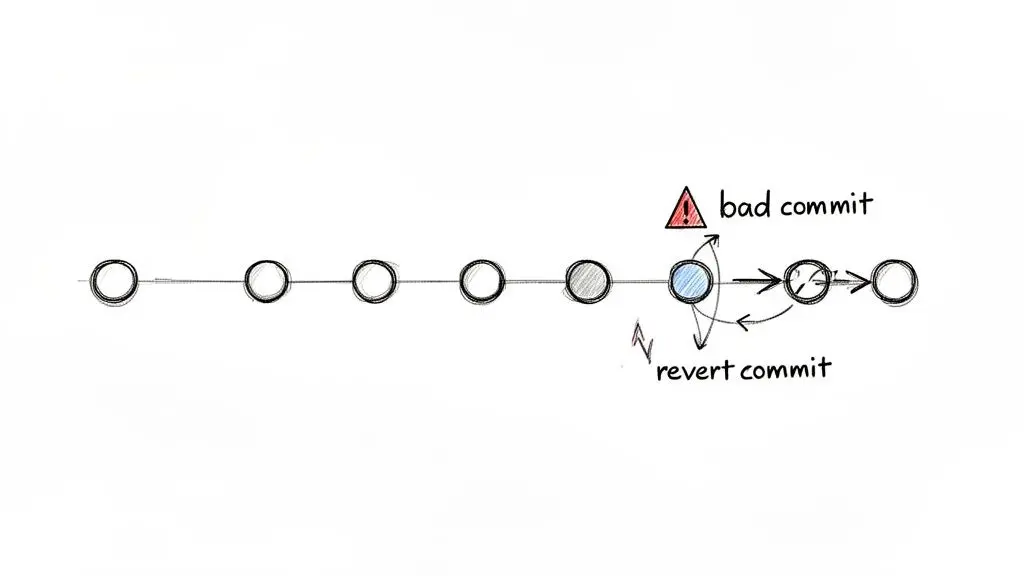
Architettura della soluzione: Revert vs. Reset
Prima di implementare la soluzione, è fondamentale capire la differenza architetturale fondamentale tra git revert e il suo corrispettivo distruttivo, git reset. Sebbene entrambi i comandi annullino modifiche, il loro impatto sulla cronologia di un progetto collaborativo è profondamente diverso.
Differenze operative chiave tra Git Revert e Git Reset
| Aspetto | git revert | git reset --hard |
|---|---|---|
| Cronologia | Crea un commit nuovo per annullare le modifiche. Non distruttivo. | Elimina commit dalla cronologia del ramo. Distruttivo. |
| Sicurezza | Sicuro per rami condivisi (main, develop). | Estremamente rischioso su rami condivisi; sicuro per lavoro solo locale. |
| Collaborazione | Mantiene la cronologia coerente per tutti i membri del team. | Costringe tutti i membri del team a correggere manualmente i loro repository locali. |
| Tracciabilità | Mantiene un registro completo e trasparente di tutte le azioni. | Cancella la traccia dell’errore originale e della sua rimozione. |
In breve, revert fornisce un registro trasparente di ciò che è successo e del motivo per cui è stato corretto. Al contrario, reset tenta di cancellare l’errore dal registro, una pratica incompatibile con lo sviluppo software professionale e collaborativo.
Il compromesso: preservare la cronologia per collaborazione e audit
A differenza dei comandi distruttivi, git revert non riscrive la cronologia; la aggiunge. Questo approccio non distruttivo è lo standard professionale per il rollback delle modifiche su rami condivisi come main o develop per ragioni critiche:
- Crea una traccia verificabile. Ogni azione, incluso il rollback, viene registrata. Questa cronologia trasparente è essenziale per code review, debugging e collaborazione del team. Risponde non solo a cosa è cambiato, ma perché è stato annullato.
- Previene la divergenza del repository. Riscrivere la cronologia di un ramo condiviso con
git resetè caotico. Costringe gli altri sviluppatori a eseguire comandi complessi e soggetti a errori per riallineare il lavoro locale. Il revert evita tutto questo. - Supporta governance e conformità. Per organizzazioni soggette a normative come GDPR o a standard come DORA, un registro immutabile delle modifiche al codice non è una preferenza tecnica ma un requisito di business. Una cronologia pulita basata su revert fornisce quella chiara traccia di audit.
Questo approccio disciplinato riflette una cultura ingegneristica matura. Un’analisi del 2023 ha rilevato che il 92% degli sviluppatori ha dovuto effettuare un rollback del codice. Per i team focalizzati sulla manutenibilità, git revert è il metodo standard perché preserva la cronologia lineare necessaria per audit e revisioni di sicurezza.
Scegliere
git revertinvece digit resetsu un ramo condiviso è una decisione architetturale. Prioritizza la sicurezza del progetto e la sincronizzazione del team rispetto alla comodità a breve termine di una cronologia riscritta.
In definitiva, padroneggiare git revert riguarda la gestione del rischio. Offre un modo sicuro, documentato e collaborativo per correggere errori, assicurando che un singolo errore non si trasformi in un problema a livello di team. Questo è in linea con i principi di un ambiente di sviluppo robusto e trasparente, parte centrale di una solida cultura ingegneristica. Puoi rafforzare queste pratiche esplorando la nostra guida su come creare un codice di condotta per i team di engineering e AI.
Eseguire un revert standard di un singolo commit
Immagina che gli alert di produzione stiano suonando. Un push recente ha introdotto una grave regressione di performance su un endpoint API critico. La risposta professionale è un’azione precisa e controllata: revertare il singolo commit che causa il problema. Questo annulla in modo pulito la modifica dannosa senza interrompere la cronologia del progetto o creare caos per il resto del team.
Passo 1: Individuare il commit target
Per prima cosa, devi identificare esattamente il commit da annullare. Lo strumento più efficace per questo è git log. Il flag --oneline fornisce una vista scansionabile, una riga per ogni commit, mostrando il suo hash e il messaggio.
git log --onelineL’output fornisce una chiara timeline delle modifiche recenti.
c8d32a9 (HEAD -> main) Fix: Update user authentication flow
a5b2e1f Feat: Add caching layer for product endpointse4d8c7b Perf: Refactor query logic for user profiles <- The problematic commit
f9a1b3d Docs: Update API documentation for v2.1
...Una rapida revisione dei messaggi dei commit di solito indica direttamente la fonte del problema. In questo scenario, e4d8c7b è il commit che ha degradato le ricerche dei profili utente. Questo hash di sette caratteri è tutto ciò di cui hai bisogno per il passo successivo.
Passo 2: Eseguire il revert
Con l’hash del commit identificato, il revert in sé è un singolo comando. Stai istruendo Git a creare un nuovo commit che sia l’esatto inverso di quello problematico.
git revert e4d8c7bQuando esegui questo comando, Git calcola le modifiche inverse e apre il tuo editor di testo predefinito con un messaggio di commit precompilato. Il messaggio predefinito è funzionale ma privo di contesto critico:
Revert "Perf: Refactor query logic for user profiles"
This reverts commit e4d8c7b2a9d1c0f8e3b4f5a6d7c8e9f0a1b2c3d4.Questo è un momento cruciale per la documentazione del progetto. Un ingegnere esperto arricchirà il messaggio predefinito per spiegare perché il revert è stato necessario.
Un messaggio di revert ben scritto è un pezzo fondamentale della documentazione di progetto. Spiega il motivo tecnico o di business del rollback ai futuri sviluppatori, agli auditor e al tuo futuro io.
Un messaggio molto migliore fornisce il contesto essenziale:
Revert "Perf: Refactor query logic for user profiles"
This reverts commit e4d8c7b. The refactor introduced a severe N+1 query in the user profile API endpoint, increasing p99 latency by over 500ms under load and triggering production alerts.
Reverting to restore service stability. A new fix is being tracked in ticket [PROJ-123].Questo livello di dettaglio è inestimabile. Comunica l’impatto, giustifica l’azione e indirizza il team verso dove viene tracciato il lavoro correttivo. Una volta salvato e chiuso l’editor, Git finalizza il nuovo commit di revert.
Passo 3: Verificare la cronologia additiva
Il principale vantaggio di git revert è la sua sicurezza. Il commit originale “bad”, e4d8c7b, non viene cancellato. Rimane una parte permanente della cronologia del progetto. Eseguire nuovamente git log --oneline conferma questo processo additivo:
3f9e6a2 (HEAD -> main) Revert "Perf: Refactor query logic for user profiles"
c8d32a9 Fix: Update user authentication flow
a5b2e1f Feat: Add caching layer for product endpoints
e4d8c7b Perf: Refactor query logic for user profiles
f9a1b3d Docs: Update API documentation for v2.1
...Questo approccio crea una traccia trasparente e verificabile. Chiunque può vedere la modifica originale, il revert e il motivo dietro di esso. Questo è essenziale per:
- Collaborazione del team: Tutti pullano una cronologia coerente, evitando i problemi di sincronizzazione causati dalla riscrittura della cronologia su rami condivisi con comandi come
git reset. - Audit e conformità: In molti settori, una cronologia immutabile e completa di tutte le modifiche al codice è un requisito normativo.
- Debugging: Capire perché una modifica è stata fatta e successivamente annullata fornisce un contesto prezioso per i tentativi futuri di risolvere lo stesso problema.
Infine, dato che hai appena creato un nuovo commit sulla tua macchina locale, devi condividerlo con il team e innescare la pipeline di deployment.
git pushHai ora usato git revert per risolvere in sicurezza un problema di produzione mantenendo una cronologia del codebase pulita, stabile e verificabile.
Revertire commit già inviati e merge complessi
Quando un commit difettoso viene pushato su un ramo condiviso come main o develop, la pressione per correggerlo è immediata. A questo punto, le opzioni di rimedio si riducono significativamente. Tentare di riscrivere la cronologia pubblica è una ricetta per il caos, rendendo git revert l’unica scelta architetturalmente sensata. La situazione diventa più complessa quando si tratta di merge commit, che richiedono un approccio più sfumato.
Il rischio di riscrivere la cronologia pubblica
Una volta che il codice è su un ramo condiviso, riscriverne la cronologia non è più un’opzione praticabile. Eseguire git reset --hard su un ramo da cui il tuo team dipende è uno dei modi più rapidi per corrompere i repository locali dei colleghi. Cancella commit dal record pubblico, causando la divergenza tra la cronologia locale e quella remota.
Qualsiasi sviluppatore che faccia pull dopo che hai forzato un push di reset incontrerà una cascata di errori confusi. Peggio, rischia di reintrodurre involontariamente gli stessi commit che cercavi di eliminare. Questo costringe a un doloroso allineamento manuale su tutto il team, sprecando tempo ingegneristico prezioso e introducendo rischi non necessari.
Usare
git revertsu un commit pushato è una best practice non negoziabile. Crea un nuovo commit che annulla in sicurezza le modifiche errate, preservando una cronologia pulita, coerente e in avanti che tutti possono pullare in modo affidabile.
Questo approccio mantiene anche intatta la traccia di audit del progetto, spesso cruciale per conformità e revisioni di sicurezza. È una decisione pragmatica che prioritizza la stabilità del team e l’integrità del progetto rispetto alla comodità individuale.
La conclusione chiave è chiara: una volta identificato un problema su un ramo condiviso, la procedura standard è localizzare il commit responsabile e applicare un revert non distruttivo.
La complessità nel revert di un commit di merge
Revertare un singolo commit standard è semplice. Ma cosa succede quando il commit da annullare è un merge commit? Questo è uno scenario comune: un feature branch viene unito in main e si scopre successivamente che contiene un bug critico.
Se provi a eseguire un normale git revert <merge-commit-hash>, Git restituirà un errore:
error: commit <merge-commit-hash> is a merge but no mainline was specified.
fatal: revert failedQuesto errore si verifica perché un merge commit ha almeno due genitori: il ramo in cui è stato eseguito il merge (es. main) e il ramo da cui è stato fatto il merge (es. feature/new-auth). Git richiede che tu specifichi quale storia dei genitori preservare — quale lato del merge rappresenta la “mainline” che vuoi mantenere. Fornisci questa istruzione con il flag --mainline (o -m), seguito da un numero che indica il genitore.
git revert <merge-commit-hash> -m 1: Questo indica a Git di mantenere la storia del primo genitore (il ramo di destinazione, ad es.,main) e annullare le modifiche introdotte dal secondo genitore (il ramo feature).git revert <merge-commit-hash> -m 2: Questo farebbe l’opposto, che è quasi mai l’azione desiderata quando si risolve un bug sul ramo main.
In praticamente tutti gli scenari di correzione dei bug, userai -m 1.
Uno scenario pratico: annullare il merge di una feature difettosa
Supponiamo che un ramo feature/new-reporting-api sia appena stato unito in main. Il commit di merge è b3d8f1a. Pochi minuti dopo, partono gli alert di produzione: la nuova API sta causando deadlock sul database.
1. Identifica il commit di merge e i suoi genitori. Devi essere certo di quale genitore sia la mainline. Ispeziona il commit:
git log -1 --pretty=medium b3d8f1aL’output mostrerà i commit genitori. Il primo elencato è il genitore #1 (main), e il secondo è il genitore #2 (feature/new-reporting-api).
2. Esegui il revert. Con la parentela confermata, puoi ora annullare il merge, istruendo Git a mantenere il genitore #1 come mainline.
git revert b3d8f1a -m 13. Documenta e pusha. Git aprirà il tuo editor per creare il messaggio del commit di revert. Come sempre, sii descrittivo sul perché il merge è stato annullato. Dopo aver salvato il messaggio, pusha il commit di revert per condividere la correzione con il team.
git pushQuesta azione crea un nuovo commit che rimuove efficacemente il codice della feature difettosa da main senza distruggere la cronologia. Puoi trovare una guida più dettagliata di questo processo nella nostra guida a reverting commits on GitHub.
Padroneggiare questa tecnica è un segno distintivo dei team ad alte prestazioni. Mentre il tasso medio di successo sul ramo main è intorno al 82.15%, i team di livello superiore portano quel numero oltre il 90% usando strumenti come git revert per rollback precisi e sicuri. Con 72% delle aziende Fortune 50 che si affidano a GitHub Enterprise, la capacità di gestire in sicurezza la cronologia collaborativa non è solo una best practice; è fondamentale per la consegna del software moderna.
Come navigare e risolvere i conflitti di revert
Anche un comando “sicuro” come git revert può causare un conflitto di merge. Questo non è una crisi, ma un’indicazione che Git richiede un intervento umano per risolvere un’ambiguità.
Un conflitto di revert si verifica quando un commit più recente ha già modificato le stesse righe di codice che stai cercando di annullare. Git si trova quindi davanti a un dilemma: dovrebbe mantenere le modifiche più recenti o dovrebbe ripristinare il codice allo stato precedente al commit che stai revertendo? Invece di fare un’assunzione potenzialmente errata, Git mette in pausa il processo e delega la decisione a te, segnalando le aree in conflitto nei file con i suoi marcatori standard (<<<<<<<, =======, >>>>>>>).

Comprendere i marcatori di conflitto
Quando si verifica un conflitto, apri il file interessato per analizzare la situazione. I marcatori delimitano le versioni in competizione:
<<<<<<< HEAD: Il codice tra questo marcatore e il divisore=======rappresenta lo stato attuale del tuo ramo (HEAD). Include le modifiche fatte dopo il commit che stai revertendo.=======: Questa linea separa le due versioni in conflitto.>>>>>>> parent of <commit-hash>...: Il codice tra il divisore e questo marcatore è ciò che il comandorevertsta tentando di reintrodurre. Questo riflette lo stato del file prima del commit che stai cercando di annullare.
Il tuo compito è fungere da arbitro finale. Devi modificare manualmente il file per produrre la versione finale corretta, quindi rimuovere i marcatori di conflitto. Questo può comportare il mantenimento di una versione, l’altra, o la creazione manuale di una nuova soluzione che integri elementi di entrambe.
Uno scenario reale di risoluzione dei conflitti
Considera una situazione comune. Un ingegnere aggiunge un nuovo feature flag in un commit iniziale. Un commit successivo refattorizza lo stesso file di configurazione e rinomina quel flag.
-
Commit originale (
a1b2c3d): Viene aggiunta una nuova impostazione."enable_beta_feature": true -
Commit successivo (
x4y5z6a): L’impostazione viene rinominata per chiarezza durante una refactor."feature_beta_enabled": true
Più tardi scopri un bug nella feature originale e devi eseguire git revert a1b2c3d. Questo innesca un conflitto. Aprendo il file appare:
<<<<<<< HEAD
"feature_beta_enabled": true,
=======
>>>>>>> parent of a1b2c3d...Git è confuso. La versione in HEAD contiene "feature_beta_enabled": true, ma il revert del commit a1b2c3d sta cercando di rimuovere "enable_beta_feature": true, una riga che non esiste più nella sua forma originale. La risoluzione corretta è cancellare manualmente l’intero blocco, inclusa la riga rifattorizzata "feature_beta_enabled": true,, poiché questo raggiunge l’intento originale del revert: disabilitare la feature.
Completare il processo di revert
Una volta modificato il file per risolvere il conflitto, devi comunicare a Git che la risoluzione è completa.
- Segna come risolto: Usa
git add <conflicted-file-name>per mettere in stage il file corretto. Questo informa Git che hai risolto quel conflitto specifico. - Continua il Revert: Finalizza il processo eseguendo
git revert --continue. Git creerà ora il commit di revert usando le tue modifiche risolte manualmente.
Se in qualsiasi momento non sei sicuro delle tue modifiche, puoi annullare in sicurezza l’intero processo eseguendo git revert --abort. Questo comando interromperà il revert e riporterà il repository allo stato precedente all’inizio dell’operazione.
Avere un processo chiaro per i conflitti è fondamentale. Studi mostrano che gli sviluppatori possono passare circa il 10% del loro tempo solo a risolvere conflitti di merge. Per i team che padroneggiano il loro workflow di controllo versione, tuttavia, la produttività può aumentare del 20%. Un approccio strutturato alla gestione dei conflitti di
git revertè una parte importante per minimizzare tale attrito. Puoi trovare più dati in questa ricerca completa sulle statistiche dello sviluppo basato su Git.
Costruire un workflow ingegneristico favorevole al revert
Il comando git revert è uno strumento potente, ma la sua efficacia dipende da un workflow ingegneristico progettato per la resilienza. Per CTO e responsabili tecnici, questo significa favorire una cultura disciplinata in cui annullare un errore sia un’operazione di routine a basso impatto. Una strategia di rollback efficace è un segno di un processo di sviluppo maturo, costruito sulla chiarezza e sull’impegno per la salute del sistema a lungo termine.
Pratica fondamentale: commit piccoli e messaggi chiari
La pietra angolare di un workflow favorevole ai revert sono i commit piccoli e atomici. Un singolo commit enorme con il messaggio “WIP updates” che include tre feature, una correzione e una refactor è quasi impossibile da revertare pulitamente.
Imporre commit piccoli, ciascuno focalizzato su una singola modifica logica, trasforma la storia di Git da un diario disordinato in un registro preciso e ricercabile. Ogni commit diventa un’unità di lavoro indipendente e reversibile. Questa disciplina deve essere accompagnata da messaggi di commit chiari e descrittivi che spieghino:
- Cosa fa la modifica.
- Perché era necessaria (ad es., bug fix, nuova feature).
- Contesto, come un link a un ticket di gestione progetto (ad es.,
[PROJ-451]).
Questo trasforma un’investigazione d’incidente stressante in una rapida ricerca con git log per trovare la modifica esatta da annullare.
Linee guida architetturali per la stabilità
Sebbene le buone abitudini siano importanti, è una solida architettura di processo che rende i revert prevedibili. L’obiettivo è intercettare i problemi prima che richiedano un revert e rendere il revert stesso a prova di errore quando inevitabilmente sfugge qualcosa.
Una strategia di rollback efficace è proattiva, non reattiva. È una scelta progettuale intenzionale che riflette l’impegno di un’azienda nel costruire software manutenibile e affidabile.
Implementare linee guida chiave è imprescindibile. Le regole di protezione dei rami su piattaforme come GitHub o GitLab sono essenziali. Impediscono i push diretti su rami critici come main o develop, costringendo ogni modifica a passare attraverso un processo controllato e auditabile.
Il ruolo di CI/CD e delle pull request
Il livello successivo di difesa è la revisione obbligatoria tramite pull request (PR). Questo requisito semplice assicura che almeno un altro ingegnere riveda il codice prima che venga unito, fungendo da checkpoint critico per qualità, condivisione della conoscenza e rispetto degli standard.
Questo processo è potenziato da una solida pipeline Continuous Integration/Continuous Deployment (CI/CD). Ogni PR dovrebbe attivare automaticamente una suite completa di test automatici—unitari, di integrazione e end-to-end—per convalidare le modifiche. Puoi scoprire di più su come costruire un sistema di delivery resiliente nella nostra guida completa alle pipeline CI/CD.
Questa validazione automatizzata agisce come una rete di sicurezza critica. Se i test falliscono, il merge viene bloccato. Se comunque passa un bug, la combinazione di commit atomici e una cronologia PR chiara rende l’operazione git revert rapida e precisa. Secondo approfondimenti sui team di ingegneria ad alte prestazioni, i team d’élite mantengono il rework sotto il 3% e conservano un New Work Rate oltre l’86%, in parte perché usano strumenti come git revert per correggere i difetti senza creare nuovo debito tecnico. Con il 74% delle organizzazioni che praticano continuous deployment che si affidano al controllo versione, un workflow favorevole al revert è chiaramente collegato a qualità superiore e recupero più rapido.
In ultima analisi, costruire questo workflow significa trattare il tuo processo di sviluppo come un componente dell’architettura del prodotto—un sistema progettato per la resilienza, dove git revert to specific commit è solo una parte ben oliata di una macchina costruita per il successo a lungo termine.
Domande frequenti su Git Revert
Una volta compresa la teoria di git revert, sorgono domande pratiche durante la sua applicazione in un contesto di team. Usare il comando con fiducia richiede di comprenderne il comportamento in scenari reali. Ecco le domande comuni dei team di ingegneria, con risposte pragmatiche.
Posso annullare un commit di revert?
Sì. Un commit di revert è solo un altro commit nella tua storia; contiene semplicemente le modifiche inverse di un commit precedente.
Se ti rendi conto che il revert è stato un errore, puoi eseguire git revert di nuovo, prendendo come target l’hash del commit di revert stesso. Questo creerà un nuovo commit che riapplica le modifiche originali, annullando di fatto il tuo undo. Questo è un metodo pulito, sicuro e completamente documentato per correggere la rotta.
Qual è la differenza tra annullare un singolo commit e un intervallo?
Annullare un singolo commit con git revert <commit-hash> è un’operazione chirurgica. Punta a un singolo set di modifiche e crea un singolo nuovo commit per annullarlo. Questo è l’approccio standard per errori isolati.
Annullare un intervallo è usato per ripristinare un’intera sequenza di lavoro, come una feature che si è estesa su più commit. Il comando git revert <oldest-hash>^..<newest-hash> lo realizza camminando a ritroso dal commit più recente al più vecchio, creando un commit di revert separato per ciascuno nell’intervallo. Questo preserva una cronologia granulare del rollback, invece di creare un unico revert monolitico.
Git Revert elimina il commit originale?
No. Questo è il concetto più critico da comprendere su git revert e la fonte della sua sicurezza negli ambienti collaborativi. Esso non altera né elimina la cronologia esistente del progetto.
Invece di cancellare il passato, git revert crea un nuovo commit che applica l’inverso delle modifiche specificate. Il commit originale “cattivo” resta intatto nel tuo log, disponibile per audit e analisi.
Questo approccio additivo garantisce che la storia del progetto rimanga completa e immutabile. Per qualsiasi team interessato alla collaborazione, alla conformità o semplicemente a capire cosa è successo, questo comportamento non distruttivo è imprescindibile.
Quando dovrei usare Revert invece di Reset?
Questa distinzione è centrale per mantenere un flusso di lavoro collaborativo e ordinato. La regola è semplice e pragmatica:
- Usa
git revertper qualsiasi modifica che è stata inviata a un ramo condiviso e pubblico (comemainodevelop). Revert è sicuro per la storia pubblica perché vi aggiunge senza riscriverla. - Usa
git resetsolo per modifiche locali sui tuoi rami privati che non hai ancora condiviso. Usareresetsu un ramo condiviso forza una riscrittura della storia, il che può creare problemi di sincronizzazione significativi per l’intero team.
Con Git che detiene una quota di mercato del 76% e alimenta il 99% dei progetti open-source, padroneggiare questi principi fondamentali di sicurezza è essenziale. I professionisti usano comandi come git revert to specific commit per mantenere una storia pulita e verificabile, una pratica che contribuisce a un aumento della produttività del 20% per i team che usano bene il controllo di versione, secondo i risultati sulle statistiche dello sviluppo basato su Git. Questa disciplina mantiene l’intero team che procede su una base stabile.
A Devisia, crediamo che pratiche di sviluppo robuste siano il fondamento di software affidabili. Collaboriamo con le aziende per creare prodotti digitali manutenibili e sistemi di IA, trasformando la visione in realtà con una mentalità che mette l’architettura al primo posto.
Scopri come il nostro approccio pragmatico può aiutarti a costruire il tuo prossimo prodotto