
L’articolo 14 del GDPR specifica le informazioni che devi fornire agli interessati quando tratti i loro dati personali senza ottenerli direttamente da loro. Questo diritto all’informazione è la pietra angolare della trasparenza ogni volta che acquisisci dati da fonti di terze parti, come API di partner, servizi di arricchimento dati o database pubblici. Garantisce che le persone siano consapevoli di chi tratta i loro dati e per quale finalità.
Questa guida è scritta per i responsabili tecnici—CTO, architetti e product manager—che progettano e gestiscono sistemi software reali. Andremo oltre la teoria giuridica e ci concentreremo sui modelli architetturali e sulle realtà operative dell’implementazione dell’articolo 14.
Il Problema: La Sfida Architetturale dei “Dati Nascosti”
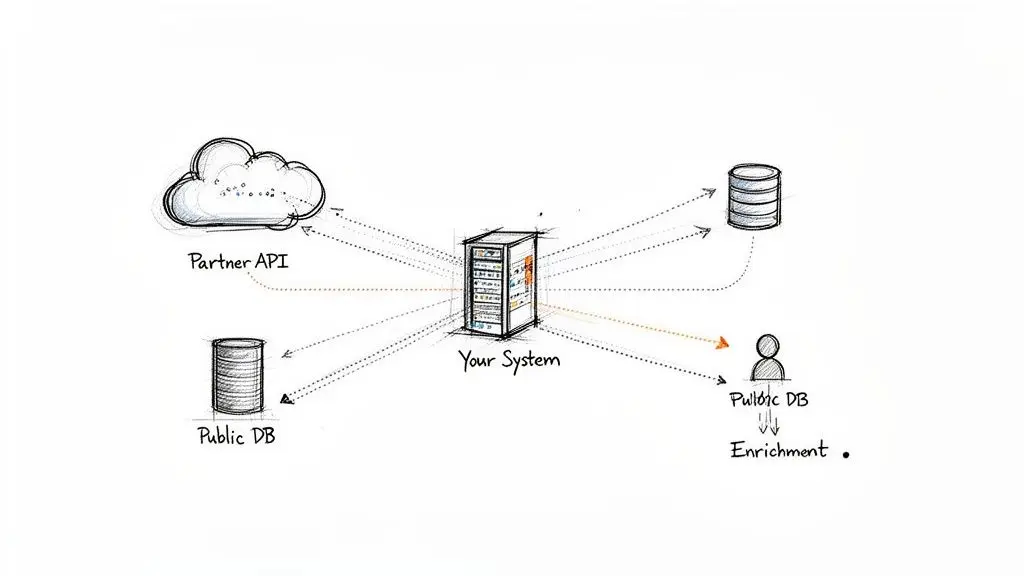
Considera uno scenario comune: il tuo sistema acquisisce dati da un’API di un partner, esegue lo scraping di un database pubblico per ricerca o utilizza un servizio di terze parti per arricchire i profili utente. Ora detieni e tratti dati personali di persone con cui non hai alcun rapporto diretto. Questo crea un significativo divario di trasparenza.
Questo è esattamente il problema affrontato dall’articolo 14 del GDPR. Per le moderne piattaforme B2B SaaS e AI, questo non è un caso limite astratto di conformità; è una sfida operativa centrale. La maggior parte dei sistemi complessi è progettata per aggregare dati da molteplici fonti esterne al fine di fornire valore. Ogni volta che la tua applicazione acquisisce dati che un utente non ha fornito direttamente, si attivano gli obblighi dell’articolo 14.
Perché gli Approcci Superficiali Falliscono
Ignorare la provenienza dei dati raccolti indirettamente è un rischio significativo sia architetturale sia commerciale. Va oltre la minaccia di sanzioni regolatorie. Da un punto di vista tecnico, questi “dati nascosti” introducono complessità e debito tecnico. Senza una strategia robusta per gestirli, costruisci il tuo sistema su fondamenta instabili di dati non tracciabili e non conformi.
I rischi di un approccio ingenuo o superficiale sono sostanziali:
- Sanzioni per la Conformità: Le autorità di controllo possono imporre multe fino a 20 milioni di euro o al 4% del fatturato annuo globale per violazioni della trasparenza.
- Erosione della Fiducia: Quando gli utenti scoprono che i loro dati vengono utilizzati senza che ne siano a conoscenza, la fiducia nel tuo prodotto e nel tuo brand viene immediatamente compromessa. Questo è particolarmente dannoso nelle relazioni B2B, dove la gestione dei dati è fondamentale.
- Fragilità del Sistema: La mancanza di una chiara data lineage rende quasi impossibile gestire i diritti degli interessati (DSR) di accesso o cancellazione, eseguire il debug di problemi relativi ai dati o evolvere la piattaforma senza introdurre vulnerabilità di conformità.
Trattare l’articolo 14 del GDPR come una checklist burocratica è un errore comune ma pericoloso. Un approccio migliore è considerarlo un vincolo architetturale che ti costringe a costruire software più trasparente, affidabile e manutenibile. La conformità proattiva è un sottoprodotto di una buona ingegneria.
Questa guida riformula la sfida dell’articolo 14 per un pubblico tecnico. Trasformeremo i requisiti legali in modelli pratici di implementazione per sistemi che gestiscono correttamente i dati acquisiti indirettamente a livello architetturale.
Cosa Richiede l’Articolo 14 del GDPR al Tuo Sistema

Quando il tuo sistema ottiene dati personali da una terza parte, l’articolo 14 impone di colmare il conseguente divario informativo. L’interessato deve essere informato del fatto che ora disponi dei suoi dati e deve comprendere cosa intendi farne. Informative vaghe, incomplete o mancanti sono tra le violazioni di conformità al GDPR più comuni e costose.
Quali Informazioni Devi Fornire
Il GDPR è altamente specifico. I seguenti elementi costituiscono una checklist non negoziabile per qualsiasi informativa sulla privacy progettata per essere conforme all’articolo 14.
Ogni informativa deve essere chiara, concisa e includere:
- Identità e Dati di Contatto: La ragione sociale della tua azienda e i dati di contatto del tuo Responsabile della protezione dei dati (DPO), se nominato.
- Finalità del Trattamento: Una spiegazione specifica e inequivocabile del perché stai utilizzando i dati. “Per arricchire i lead di vendita con dati di affiliazione professionale” è una finalità valida; “Per migliorare i nostri servizi” non lo è.
- Base Giuridica del Trattamento: Il tuo fondamento giuridico per il trattamento, come il “legittimo interesse”. Se utilizzi il legittimo interesse, devi anche descrivere quale sia tale interesse.
- Categorie di Dati Personali: I tipi specifici di dati che hai ottenuto (ad es. “informazioni di contatto professionali”, “storia lavorativa pubblicamente disponibile”).
Un requisito critico e unico dell’articolo 14 è l’obbligo di comunicare la fonte dei dati. Devi essere trasparente riguardo a dove hai ottenuto le informazioni.
Ciò significa essere il più precisi possibile, ad esempio indicando “dati ottenuti dall’API di lead generation di Partner X”. Se ciò non è fattibile, devi almeno descrivere il tipo di fonte, ad esempio “da siti di networking professionale accessibili al pubblico”. Omettere di specificare la fonte costituisce una violazione diretta dei principi di trasparenza ed è un frequente obiettivo di controllo da parte delle autorità.
Checklist di Divulgazione delle Informazioni dell’Articolo 14 del GDPR
Questa tabella traduce i requisiti legali dell’articolo 14 in considerazioni tecniche e operative per il tuo sistema software. Usala come schema per verificare i flussi di dati e progettare le tue informative sulla privacy.
| Requisito Informativo | Descrizione | Considerazioni di Implementazione del Sistema |
|---|---|---|
| Identità e Contatti del Titolare | La ragione sociale della tua azienda e i dati di contatto, più il contatto del DPO se applicabile. | Codifica in modo fisso o memorizza queste informazioni in un file di configurazione, assicurandoti che siano facilmente aggiornabili. |
| Finalità del Trattamento | Una spiegazione chiara e specifica del perché stai utilizzando i dati. | I processi back-end del tuo sistema devono essere allineati a queste finalità dichiarate. Eventuali discrepanze creano un rischio di conformità. |
| Base Giuridica del Trattamento | Il fondamento giuridico specifico ai sensi del GDPR (ad es. legittimo interesse). | Questa è una decisione strategica di prodotto e legale che determina gli obblighi del sistema. |
| Categorie di Dati Personali | I tipi di dati trattati (ad es. informazioni di contatto, dati professionali). | I tuoi modelli dati e schemi devono riflettere accuratamente queste categorie dichiarate. Evita di trattare tipi di dati non dichiarati. |
| Fonte dei Dati Personali | La terza parte specifica o la natura della fonte (ad es. fonti pubbliche, data broker). | Questo è il cuore dell’articolo 14. La tua architettura deve supportare il tracciamento della provenienza dei dati per riportarla con precisione. |
| Destinatari dei Dati | Eventuali terze parti con cui prevedi di condividere i dati. | Documenta tutte le chiamate API in uscita, le condivisioni di dati e le integrazioni che trasmettono dati personali a sistemi esterni. |
| Trasferimenti Internazionali di Dati | Se i dati vengono inviati al di fuori del SEE, devi menzionarlo insieme alle garanzie in atto. | Una considerazione critica per architetture cloud-native che utilizzano infrastrutture globali. Richiede un’attenta selezione e configurazione dei servizi. |
| Periodo di Conservazione dei Dati | Per quanto tempo conserverai i dati, o i criteri usati per determinare tale periodo. | Il tuo sistema deve disporre di meccanismi per applicare queste policy, come job di cancellazione automatica o impostazioni TTL (Time-To-Live) sui record. |
| Diritti dell’Interessato | Una dichiarazione che informi le persone dei loro diritti (accesso, rettifica, cancellazione, ecc.). | Il back-end della tua applicazione e tutti gli strumenti amministrativi interni devono essere in grado di gestire queste richieste in modo efficiente. |
| Diritto di Proporre Reclamo | Informazioni su come presentare un reclamo a un’autorità di controllo. | Questa è una dichiarazione obbligatoria e standardizzata che dimostra consapevolezza del quadro normativo. |
| Processo Decisionale Automatizzato | Se utilizzi i dati per profilazione automatizzata, devi fornire informazioni significative sulla logica coinvolta. | Per i sistemi AI/ML, questo è fondamentale. Devi essere in grado di spiegare—ad alto livello—come operano i tuoi modelli e il loro potenziale impatto. |
Requisiti Temporali: Un Vincolo Architettonico
L’articolo 14 impone scadenze rigorose per fornire queste informazioni. L’architettura del tuo sistema deve essere progettata per soddisfare automaticamente questi trigger temporali. Un processo manuale in batch a fine mese non è sufficiente.
Devi fornire le informazioni entro il primo dei seguenti eventi:
- Entro un periodo ragionevole dall’ottenimento dei dati e, in ogni caso, non oltre un mese.
- Al momento della prima comunicazione con l’interessato, se utilizzi i dati per contattarlo.
- Non oltre il momento in cui i dati personali sono comunicati per la prima volta a un altro destinatario.
Per un team di ingegneria, ciò significa che l’architettura deve essere event-driven. Deve generare notifiche basate su eventi specifici del sistema, come l’ingestione di un nuovo record da un’API di terze parti o il primo invio di un’email automatizzata a un lead di vendita arricchito.
Integrare questi trigger nella tua architettura è un principio fondamentale della Privacy by Design. Garantisce che la conformità sia automatizzata, verificabile e affidabile—non un ripensamento successivo. Questo è anche essenziale per mantenere registri accurati delle attività di trattamento, come illustrato nella nostra guida sull’articolo 30 del GDPR.
Sapere Quando l’Articolo 14 Non Si Applica
Sebbene l’impostazione predefinita sia fornire un’informativa, l’articolo 14 include alcune limitate esenzioni. Fare affidamento su un’esenzione è una decisione ad alto rischio che richiede attenta giustificazione e documentazione. L’onere della prova è sempre tuo: devi dimostrare perché si applica un’esenzione.
Le principali esenzioni includono:
- L’interessato dispone già delle informazioni: Devi essere in grado di dimostrare che l’interessato ha già ricevuto tutte le informazioni richieste da un’altra fonte.
- La comunicazione è impossibile o richiede uno sforzo sproporzionato: “Impossibile” è uno standard assoluto. “Sforzo sproporzionato” è una soglia elevata che richiede di bilanciare lo sforzo di notifica con l’impatto sui diritti dell’individuo. Ciò richiede quasi sempre una formale Valutazione d’Impatto sulla Protezione dei Dati (PIA) per essere giustificato. Sei inoltre tenuto a rendere le informazioni disponibili al pubblico tramite altri mezzi, come il tuo sito web.
- L’ottenimento o la comunicazione sono previsti dalla legge: L’obbligo è sostituito da un requisito legale di ottenere o divulgare i dati.
- I dati devono rimanere riservati in virtù di un obbligo di segreto professionale: Ciò si applica tipicamente a professioni come quella legale o medica ed è raramente applicabile alla maggior parte delle società software.
Interpretare erroneamente queste esenzioni è una comune causa di mancata conformità. In caso di dubbio, l’azione predefinita dovrebbe sempre essere fornire l’informativa.
Modelli Architetturali per la Conformità all’Articolo 14
Una conformità efficace non può essere raggiunta tramite processi manuali. Deve essere una proprietà automatizzata e intrinseca dell’architettura del tuo sistema. Questa è l’essenza dell’implementazione della Privacy by Design. L’obiettivo è progettare pipeline di dati in cui le informative di trasparenza siano un output naturale e inevitabile dell’acquisizione dei dati.
Architettura Event-Driven per Notifiche Automatizzate
Un’architettura event-driven è un modello robusto per automatizzare le notifiche dell’articolo 14. Disaccoppia il processo di acquisizione dei dati dalla logica di notifica per la conformità, creando un sistema più resiliente, scalabile e verificabile.
Il flusso di lavoro è il seguente:
- Servizio di Acquisizione Dati: Un servizio responsabile dell’ottenimento dei dati da fonti di terze parti (ad es. un client API, un web scraper).
- Event Bus: Dopo aver acquisito con successo dati personali ottenuti indirettamente, il servizio pubblica un evento (ad es.
IndirectDataAcquired) su un bus di messaggi centrale come RabbitMQ o Apache Kafka. Il payload dell’evento deve contenere le informazioni di contatto dell’interessato, le categorie di dati acquisiti e, in modo critico, la source dei dati. - Compliance Notification Service: Un microservizio dedicato si iscrive all’evento
IndirectDataAcquired. La sua unica responsabilità è consumare questo evento, costruire l’informativa richiesta per legge dall’Articolo 14 e inviarla tramite il canale appropriato (ad es. API email).
Questo pattern disaccoppiato garantisce che la pipeline principale di acquisizione dei dati non venga bloccata dal processo di notifica. Se il servizio email è temporaneamente non disponibile, l’evento può essere ritentato senza influire sull’acquisizione dei dati. In questo modo si ottiene la conformità senza sacrificare le prestazioni o l’affidabilità del sistema.
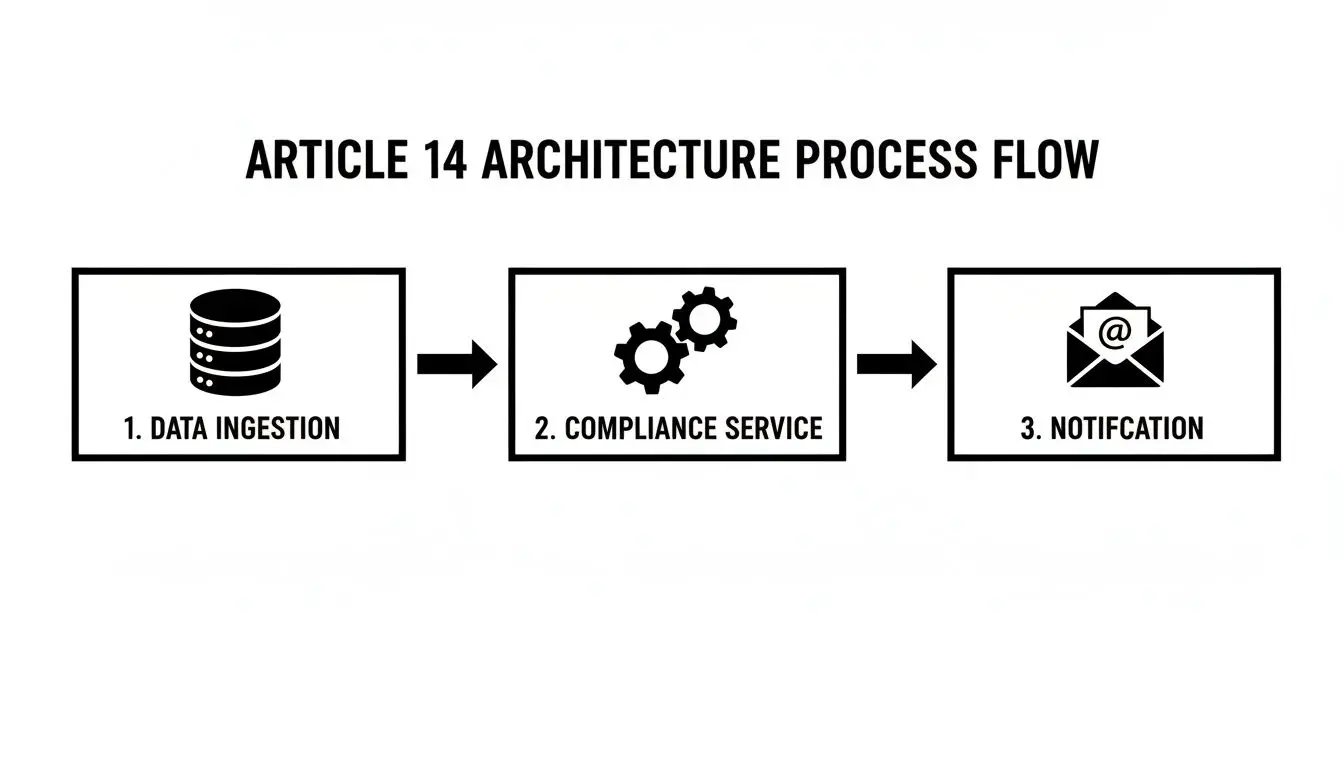
The Compliance Microservice Pattern
Implementare un Compliance Microservice dedicato è un modo pratico per realizzare questa architettura. Questo servizio agisce come hub centralizzato per l’esecuzione della logica relativa alla conformità. Si iscrive a vari eventi di business nel tuo sistema e applica programmaticamente le regole sulla privacy.
Ad esempio, quando un servizio di “Lead Enrichment” recupera nuovi dati, emette un evento. Il Compliance Microservice, ascoltando questo evento, determina che è richiesta un’informativa Articolo 14 e avvia il flusso di notifica.
Un Compliance Microservice trasforma requisiti astratti sulla privacy in un componente software unico, verificabile e manutenibile. Centralizza la logica di conformità, semplifica gli aggiornamenti in risposta ai cambiamenti normativi e stabilisce una chiara ownership all’interno della codebase.
Questo pattern è particolarmente efficace per piattaforme complesse che acquisiscono dati da numerose fonti di terze parti, garantendo che gli obblighi dell’Articolo 14 siano rispettati in modo coerente e automatico. Puoi leggere di più su questa filosofia nel nostro articolo sull’integrazione dei principi del GDPR attraverso il Privacy by Design.
Immutable Audit Logs for Provability
Dimostrare di aver inviato una notifica è importante quanto inviarla. In caso di audit normativo, devi fornire un registro verificabile delle tue azioni di conformità. La soluzione tecnica più robusta è un audit log immutabile, append-only.
Quando il ComplianceNotificationService invia un’informativa, dovrebbe scrivere simultaneamente un record in un log sicuro. Ogni voce di log deve contenere:
- Un identificativo univoco per l’interessato.
- Il timestamp preciso del tentativo di notifica.
- Il canale di consegna utilizzato (ad es.
email). - Un hash del contenuto dell’informativa per dimostrare cosa è stato inviato.
- Lo stato di consegna restituito dal provider (ad es.
sent,delivered,bounced).
Archiviare questi log in un sistema come un database append-only o un bucket di cloud storage write-once (ad es. AWS S3 Object Lock) ne garantisce l’integrità. Questa scelta architetturale fornisce la prova tecnica necessaria a suffragare le tue affermazioni di conformità. Uno studio sull’impatto del GDPR sulle tecnologie di tracciamento ha rilevato che, dopo il GDPR, il numero di consumatori tracciabili tramite cookie è diminuito del 12,5%, dimostrando che l’architettura di conformità ha conseguenze aziendali misurabili.
Real-World Scenarios and Implementation
La teoria è utile, ma la conformità si realizza nel codice. Esaminiamo come applicare questi pattern architetturali a scenari software B2B comuni.
Scenario 1: Sales Intelligence SaaS Platform
Problem: Una piattaforma SaaS arricchisce lead di vendita recuperando dati professionali (ruolo, azienda) dall’API di un fornitore di dati di terze parti. Questo è un chiaro trigger dell’Articolo 14.
Implementation:
- Event Trigger: Il servizio di arricchimento dati, al ricevimento di una risposta API positiva dal provider, pubblica un evento
ProfileEnriched. Il payload include l’email del lead e un identificatore specifico del fornitore di dati (ad es.provider_name: "Clearbit"). - Queued Notification: Un servizio di conformità consuma questo evento e inserisce un task di notifica in una coda dedicata. Questo disaccoppia i sistemi e garantisce resilienza.
- Timed Dispatch: Un processo worker invia un’informativa via email entro il termine di un mese (idealmente molto prima). Il template dell’email indica esplicitamente l’identità della tua azienda, la finalità (arricchimento dei lead di vendita), le categorie di dati e nomina il fornitore terzo come source.
Scenario 2: AI-Powered Recruiting Tool
Problem: Una piattaforma AI estrae dati da fonti pubbliche come GitHub e siti di networking professionale per identificare potenziali candidati. La “source” non è una singola API, ma un insieme distribuito di pagine web pubbliche.
Implementation:
- Log Data Provenance: Il motore di scraping deve essere progettato per registrare lo specifico URL di origine per ogni dato che raccoglie. Memorizzare un attributo
source_urlinsieme al record del dato è imprescindibile per la tracciabilità. - Automate First Contact Notice: Il sistema è configurato in modo che la primissima comunicazione inviata a un candidato (ad es. un’email di contatto) includa automaticamente l’informativa dell’Articolo 14. Questo soddisfa il requisito temporale “al momento del primo contatto”.
- Provide Clear Source Information: L’informativa deve essere diretta: “Abbiamo identificato il tuo profilo professionale su fonti disponibili pubblicamente, incluse piattaforme come GitHub e siti di networking professionale, per valutare l’idoneità a ruoli presso i nostri clienti.” Questa trasparenza è fondamentale. Documentare questo processo è anche un input critico per una Privacy Impact Assessment.
Scenario 3: B2B Analytics Platform
Problem: Una piattaforma di business intelligence integra dati dei clienti di un’azienda partner via API per fornire analytics congiunte. Si tratta di un classico scambio di dati da titolare a titolare che rientra nell’Articolo 14.
Implementation:
- Contractual Clarity: L’accordo di condivisione dei dati con il partner deve definire esplicitamente ruoli e responsabilità per la fornitura delle informative dell’Articolo 14.
- Automated Ingestion Workflow: La pipeline di acquisizione dei dati è progettata per gestire questo caso. Quando i dati arrivano dall’API del partner, vengono etichettati con l’identità del partner come source.
- Targeted Notification: Il sistema attiva una notifica agli interessati. L’informativa dichiara chiaramente che i loro dati sono stati ricevuti dal partner specificato per la finalità di analytics congiunte.
In tutti gli scenari, il principio unificante è la tracciabilità architetturale. Il tuo sistema deve essere in grado di tracciare da dove proviene ogni dato acquisito indirettamente e attivare una notifica documentata e automatizzata. Un sistema che non è in grado di farlo non è solo un rischio di conformità, ma è anche architetturalmente carente.
Conclusion: Privacy as an Architectural Choice
Per fondatori, CTO e leader di prodotto, le complessità dell’Articolo 14 GDPR si riducono a un principio fondamentale: la privacy è una scelta architetturale, non una funzionalità.
Un approccio reattivo e manuale alla conformità non è sostenibile. Genera debito tecnico, introduce rischi e compromette la fiducia degli utenti, essenziale per il successo a lungo termine. L’unica strategia scalabile e difendibile è incorporare trasparenza e accountability nel tessuto stesso dei tuoi sistemi software.
Key Takeaways for Technical Leaders
- Map All Indirect Data Inflows: Non puoi gestire ciò che non misuri. Il primo passo è creare un inventario completo di tutte le fonti di dati di terze parti. Se non riesci a tracciare i dati fino alla loro origine, hai un difetto architetturale critico.
- Automate Compliance Workflows: Implementa sistemi event-driven che attivino e registrino automaticamente le informative dell’Articolo 14 al momento dell’acquisizione dei dati. I processi manuali sono inaffidabili e non scalano.
- Prioritize Data Provenance: Progetta i tuoi modelli dati e le tue pipeline per tracciare la source di ogni dato personale. Questa è la base della conformità dimostrabile.
- Document Everything: Documenta in modo meticoloso la tua base giuridica per il trattamento, i flussi di dati e le giustificazioni per eventuali esenzioni. Questa documentazione è la tua prima linea di difesa in caso di audit.
Vedere l’Articolo 14 non come un onere normativo ma come un insieme di vincoli ingegneristici porta a un software migliore. I sistemi progettati per la trasparenza e l’accountability sono intrinsecamente più robusti, manutenibili e affidabili — i tratti distintivi di qualsiasi prodotto costruito per durare.
Frequently Asked Questions About Article 14
Do we need to send a notice for publicly available data?
Sì, in quasi tutti i contesti commerciali. Il fatto che i dati siano disponibili pubblicamente (ad es. su un sito di networking professionale) non ti esonera dagli obblighi come titolare del trattamento. Nel momento in cui raccogli e tratti quei dati per le tue finalità, fai scattare gli obblighi informativi dell’Articolo 14. Devi informare l’individuo che stai trattando i suoi dati e dichiarare che li hai ottenuti da una fonte pubblica.
How specific must we be about the data source?
Il più specifici possibile. L’obiettivo è la trasparenza.
- Best practice: Indicare il nome specifico dell’azienda o della piattaforma (ad es. “Abbiamo ottenuto le tue informazioni di contatto professionali da Data Provider X”).
- Acceptable minimum: Se indicare la fonte specifica non è fattibile, devi descrivere il tipo di fonte (ad es. “da piattaforme di networking professionale accessibili pubblicamente”).
Una dichiarazione generica come “da fonti di terze parti” è insufficiente e dimostra un mancato rispetto del requisito di trasparenza. La tua architettura di sistema dovrebbe essere progettata per tracciare la provenance, rendendo possibile un’attribuzione specifica.
Can we combine Article 14 notices with marketing emails?
Sì, questo può essere un modo efficace per rispettare la scadenza “al momento del primo contatto”. Tuttavia, l’informativa deve essere chiara, ben visibile e distinta dal contenuto di marketing. Nascondere le informazioni in caratteri piccoli all’interno di un messaggio promozionale non è conforme. Una best practice è utilizzare una sezione chiaramente etichettata (ad es. “Informazioni sui tuoi dati”) all’inizio dell’email per presentare le informative richieste prima del contenuto promozionale.
What if we have no contact information for the data subject?
Questa è una delle poche situazioni in cui l’esenzione per “impossibilità” può realmente applicarsi. Se hai ottenuto dati personali ma non disponi di un indirizzo email, un numero di telefono o di altri mezzi per contattare l’individuo, potrebbe essere impossibile fornire una notifica diretta. Tuttavia, ciò non equivale a una rinuncia completa. Sei comunque tenuto a rendere pubblicamente disponibili le informazioni dell’Articolo 14, in genere tramite un’informativa sulla privacy dettagliata sul tuo sito web che descriva questa specifica attività di trattamento. Devi essere pronto a documentare e giustificare rigorosamente questa decisione.
How does Article 14 relate to the upcoming AI Act?
L’articolo 14 del GDPR e l’AI Act dell’UE condividono l’obiettivo della trasparenza, ma operano a livelli diversi. Il diritto all’informazione del GDPR, in particolare il diritto a “informazioni significative sulla logica coinvolta” nel processo decisionale automatizzato (articolo 15), crea già una base. L’AI Act si fonderà su questa imponendo obblighi di trasparenza più specifici ai fornitori di sistemi di IA ad alto rischio. Un’implementazione solida dell’articolo 14, che documenti chiaramente le fonti dei dati e le finalità del trattamento per l’addestramento e il funzionamento dei modelli di IA, è un passo critico e necessario per rendere i vostri sistemi a prova di futuro e conformi all’AI Act.
Costruire software robusto, conforme e scalabile richiede un partner che comprenda che la privacy è un principio architetturale. Devisia è specializzata nello sviluppo di prodotti digitali ad alto impatto e di sistemi abilitati dall’IA in cui affidabilità e fiducia sono fondamentali.
Scopri come aiutiamo le aziende a trasformare la loro visione in software resiliente e pronto per il mercato su https://www.devisia.pro.