
A familiar pattern is playing out in many product and engineering teams right now. Someone bought or built an LLM feature. The demo looked strong. It answered questions fluently, summarised documents, and handled broad prompts with confidence.
Then the system met a real workflow.
It could explain how to resolve a support issue, but it could not open the ticket, inspect the logs, check the knowledge base, or escalate with the right context. It could draft a compliance response, but it could not verify source records, apply policy rules, or route the case for approval. What looked like automation was often just better conversation.
That gap matters. CTOs are not buying eloquence. They are responsible for throughput, reliability, auditability, access control, and operational cost. If an AI system cannot take bounded action inside a governed architecture, it remains a useful assistant, not an operational component.
The agent models sit in that gap. Used well, they turn language models into systems that can observe state, choose from approved tools, execute tasks, and stop when risk or uncertainty becomes too high. Used badly, they create opaque loops, uncontrolled spend, brittle integrations, and governance problems that surface only after deployment.
The Problem with Today’s AI Integrations
The first generation of AI integrations usually failed in a predictable way. Teams wrapped a chat interface around a model, connected it to a few documents, and called it intelligent automation.
In practice, the result was closer to a polished help desk FAQ.
A CTO might ask for a customer operations assistant that can handle refund requests. The chatbot can explain the refund policy. It can even produce a courteous message. But when the workflow requires checking an order system, validating fraud signals, applying business rules, updating the CRM, and recording an audit trail, the illusion breaks. The model has language competence, not operational agency.
Where the disappointment comes from
Most disappointing AI projects share one or more of these flaws:
- No action layer. The model produces text, but it cannot call tools safely.
- No workflow memory. It forgets state between turns or stores it inconsistently.
- No system grounding. It speaks confidently without checking current data.
- No approval model. Sensitive actions happen without clear controls, or nothing happens because the team is afraid to permit action at all.
The result is awkward. Staff still perform the core work manually, while the AI produces summaries or suggestions around the edges.
A useful production system does not just generate answers. It completes work inside constraints.
Why this is becoming urgent
The shift from passive AI to agentic systems is not a niche trend. Gartner’s October 2024 report forecasts that the integration of agentic AI in enterprise software applications will rise from less than 1% in 2024 to 33% by 2028 according to this eMarketer summary of Gartner’s forecast.
That forecast matters because it points to an architectural transition. Enterprise teams are moving from “ask the model” to “delegate a bounded task to a governed system”. The difference is not cosmetic. It changes how software must be designed, tested, secured, monitored, and funded.
Beyond Chatbots What Are The Agent Models
An agent model is not just a bigger chatbot. It is a software pattern in which an AI system receives a goal, evaluates the current state, decides what to do next, uses approved tools, and continues until it reaches a stopping condition.
That sounds abstract until you compare it with a normal LLM call.
A simple LLM behaves like a consultant who writes a memo when asked. An agent behaves more like a junior operator who can read instructions, use software, gather missing information, and carry a task forward under supervision. It still needs guardrails. It still makes mistakes. But it can participate in execution, not just explanation.
The core parts of an agent
Most production agents are built from a small set of components.
- The reasoning model. This is the LLM that interprets the goal and chooses the next action.
- Tools. These are controlled interfaces such as APIs, databases, search layers, queues, or internal services.
- Memory and state. The system needs working memory for the current task and, in some cases, durable state for longer-running workflows.
- Policy constraints. Access control, approval rules, rate limits, and action boundaries define what the agent may do.
- An execution loop. The system repeats a cycle of observe, decide, act, and reassess.
A normal prompt-response integration usually stops after the first step. An agent keeps going until it reaches completion, requests human input, or hits a defined limit.
What makes an agent useful in business systems
The practical value of the agent models comes from three traits.
First, the agent can use tools instead of pretending. If the task requires current customer status, current inventory, or current policy text, the right answer is not “best effort from model memory”. The right answer is a governed call to the relevant source.
Second, the agent can handle multi-step work. Real business processes rarely fit into a single prompt. A support triage flow may require classification, retrieval, validation, action, escalation, and recordkeeping.
Third, the agent can stop safely. A reliable agent does not need unlimited autonomy. In most enterprises, the better pattern is bounded autonomy with explicit handoff points.
A simple mental model
Think of the execution loop like this:
-
Receive goal “Check overnight support messages and identify any incident-level issues.”
-
Inspect context Read current tickets, service status, internal runbooks, and recent alerts.
-
Choose action Search the incident knowledge base, correlate logs, draft a summary, create a ticket.
-
Execute through tools Use Jira, Slack, log search, and an internal status API.
-
Review outcome If confidence is low or action is sensitive, ask for human approval.
That is the difference between a conversational feature and an operational system. The model is only one part. The architecture around it determines whether it is useful.
A Taxonomy of Modern AI Agents
Not all agent systems solve the same problem. Treating them as one category leads to bad design decisions, because the architecture for a support triage agent is different from the architecture for a planning agent or a simulation model.
A practical taxonomy helps teams choose the smallest pattern that fits the work.
Tool-using agents
The business problem is straightforward. The team has repetitive digital work spread across APIs and dashboards, and staff spend time copying information between systems.
A tool-using agent addresses that by exposing approved actions to the model. These actions might include creating tickets, updating records, querying a warehouse, or sending a structured message into an internal workflow.
This is often the right starting point because it keeps the design narrow. The agent is useful only to the extent that the tools are well defined and the permissions are controlled.
Use case: a support operations agent checks a failed payment event, looks up the customer account, and opens the correct case type with the right metadata.
Retrieval-augmented agents
The problem here is not action. It is grounding.
A standard model can produce plausible answers from generic training data, which is risky in domains where the truth sits in private policy documents, product documentation, internal runbooks, or regulated knowledge stores. A retrieval-augmented agent queries those sources first, then reasons over the retrieved context before acting.
This pattern works well when the organisation needs current, local truth rather than broad language ability.
Use case: an internal policy agent checks the latest security control library before drafting a response for a DORA or NIS2 evidence request.
Planning agents
Some workflows are too large to solve in one move. They require decomposition into smaller steps, conditional branching, and intermediate checks.
Planning agents are useful when the task has a goal but not a fixed path. They break larger objectives into ordered sub-tasks, execute them one by one, and adjust based on results. This approach can lead teams to become overambitious. Planning is powerful, but without limits it also creates long loops, duplicated work, and hard-to-debug failure states.
Use case: a product operations agent analyses customer complaints, clusters themes, identifies urgent defects, and prepares backlog tickets for review.
Multi-agent systems
A single agent becomes messy when one model is expected to do intake, planning, retrieval, action, validation, and reporting. Multi-agent systems split those responsibilities across specialised workers.
One agent might classify intent. Another retrieves domain evidence. A third performs the action. A fourth validates policy compliance before execution. This can improve maintainability if each agent has a narrow role, but it can also produce orchestration complexity if teams over-engineer too early.
Use case: a release governance workflow where one agent reviews change context, one checks dependency status, one validates evidence, and a final controller agent decides whether to request human approval.
Memory-enabled agents
Some tasks improve when the system can use prior interactions, known preferences, or past resolutions. That requires memory. The issue is that many teams add memory carelessly and end up mixing useful state with untrusted or stale content.
Memory-enabled agents should store only what is operationally necessary and policy-compliant. They are not better because they remember more. They are better when they remember the right things.
Use case: an IT support agent recalls that a device fleet in one office has a recurring VPN configuration issue and checks that runbook first.
A note on older agent models
The agent models did not begin with LLMs. Agent-based models have a long history in simulations, including tools such as CovidSim, and evolved from social science work in the 1990s by modelling heterogeneous agents with learning rules, as described in Wikipedia’s overview of agent-based models.
That history matters because it reminds us that agency is a systems concept, not a UI trend. Long before modern LLM agents, engineers and researchers used agents to model interactions, test scenarios, and understand emergent behaviour. The current wave adds language interfaces and tool use. It does not remove the need for clear system design.
Architecting and Orchestrating Agentic Systems
Good agentic systems are composed, not improvised. The model does not “run the workflow” on its own. An application does. That application decides how prompts are assembled, how tools are exposed, how state is stored, what requires approval, when retries happen, and how failures are surfaced.
The central design question is simple. Who is in control when the model is uncertain, wrong, slow, or unsafe?
If the answer is “the model figures it out”, the architecture is not production ready.
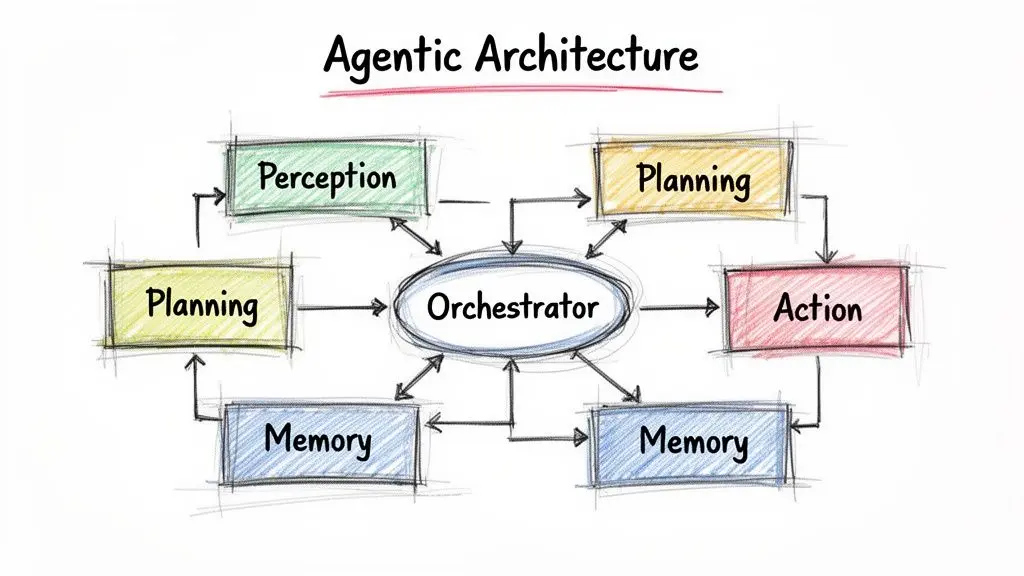
The orchestrator is the product
In production, the most important component is often not the model. It is the orchestrator.
The orchestrator manages the event loop. It gathers context, calls the model, interprets the model’s output, invokes tools, records state, and decides whether the next step is another tool call, a user question, a fallback, or a stop. It also enforces the policies the model cannot be trusted to enforce itself.
The simplest working pattern looks like this:
goal -> gather context -> ask model for next action
-> validate action against policy
-> execute approved tool
-> record result
-> ask model for next action or final responseThat is not glamorous, but it is what turns a demo into a service.
Two orchestration patterns that help
The first useful pattern is a reason and act loop. The model reasons over the current state, selects a tool, receives the result, then reasons again. This keeps the model tied to observable outcomes rather than forcing it to invent the whole plan up front.
The second is planner plus worker. One model creates a bounded plan. Separate worker agents or deterministic services execute the steps. This is often safer for longer tasks because the planner does not get direct power over all downstream actions.
A simplified example:
User goal:
"Summarise recent customer feedback and create a Jira ticket for any urgent bug."
Planner:
1. Pull feedback from approved sources
2. Cluster messages by theme
3. Identify likely defects
4. Check severity rules
5. Draft tickets for human review
Workers:
- Retrieval worker queries support data
- Analysis worker groups reports
- Rules worker applies urgency criteria
- Jira worker creates draft ticket only if approvedThis architecture separates judgement, evidence gathering, policy checks, and side effects.
Bounded autonomy beats broad autonomy
Many teams make the same mistake. They try to give one general agent broad access to everything. It feels efficient at first, because the demo is simple. It becomes expensive later, because every new integration increases the blast radius.
A better pattern is constrained capability:
- Read widely, write narrowly
- Approve destructive actions
- Separate retrieval from execution
- Expose business rules explicitly rather than hoping the model infers them
The safest agent is not the least capable one. It is the one whose capabilities are explicit, testable, and narrow enough to govern.
Why orchestration matters operationally
In IT delivery contexts, orchestration is not just an AI pattern. It affects programme execution. Autonomous orchestration can let AI agents act as project coordinators and reduce administrative overhead for human project managers by up to 70% based on predefined resource allocation rules, according to STL Digital’s article on agent-powered programmes.
The practical lesson is not that project management disappears. It is that repetitive coordination work can move into software when the rules are explicit and the state is visible.
That same principle applies to technical systems. An agent can route work, gather evidence, track progress, and trigger the next step, but only if the workflow is modelled as software rather than delegated as vague intention.
A concrete system flow
Consider a service operations workflow:
- The orchestrator ingests overnight support messages.
- A classifier decides whether each message is billing, product, incident, or noise.
- A retrieval component pulls the relevant knowledge base entries and recent service status.
- The model drafts a diagnosis and proposes the next action.
- A policy layer checks whether the action is allowed.
- If the action is low risk, the tool runs.
- If the action is high risk, the system routes to a human approver.
- Every step is logged for traceability.
That is also the kind of architecture that becomes more valuable when paired with adjacent operational systems, including AI and IoT integrations in real products, where agents may need to react to device events, telemetry, or operational thresholds instead of only text prompts.
A short visual walkthrough is useful here.
What does not work
Three designs fail repeatedly.
- The all-knowing agent. One prompt, many tools, no discipline. It becomes opaque fast.
- The hidden workflow. Logic sits inside prompts instead of code and policies. Nobody can audit it properly.
- The no-state loop. The system cannot recover cleanly after interruption, so long-running tasks become fragile.
Production architecture needs explicit state, explicit permissions, explicit tool contracts, and explicit stopping rules. Everything else is hopeful wiring.
Agent Models in Practice Real-World Use Cases
The best use cases for the agent models are not the most theatrical ones. They are the ones where teams already know the workflow, the inputs are available, the systems of record are clear, and the cost of delay is real.
IT support triage with controlled action
A common service desk problem is that first-line teams spend too much time gathering context before they can even begin solving the issue.
A useful support agent does not try to replace the whole desk. It handles the front of the workflow. It reads the request, classifies the issue, searches the internal wiki, checks service status, inspects allowed telemetry, and suggests or executes the next approved step. If confidence is low, it escalates with a structured summary rather than a vague transcript.
The gain is operational. Humans start with context instead of collection.
Finance reporting for a SaaS operator
Finance and product teams often work from the same numbers but through different tools and timing. A reporting agent can pull current sales data, reconcile it against agreed definitions, update a forecasting workbook or service, and produce a draft weekly summary with linked evidence.
That sounds simple, but the architecture matters. The agent should not invent revenue logic. It should call known services, use locked definitions, and produce outputs that are easy to review.
The economic aspects of agent services will attract attention here. By 2026, Agent-as-a-Service is projected to hit $460/day margins per agent, but unmonitored structural holes in IT connectors can amplify failure rates by 3x, according to Spiral Scout’s discussion of production agent patterns. The takeaway is straightforward. The margin story is irrelevant if the connector layer is fragile.
Compliance operations in regulated workflows
A compliance agent can be valuable when the work is evidence-heavy and repetitive.
For example, in a fintech workflow, the agent can inspect a transaction event, pull the relevant policy rules, gather supporting data, and prepare a case file for review. It can flag anomalies, request missing information, or route to the right owner. The decision still belongs to a person where regulation or risk requires it.
That division of labour matters. Automation gathers and structures evidence. Human reviewers make accountable decisions.
Retail operations and demand signals
Retail workflows are full of fragmented signals. Product returns, stock anomalies, customer feedback, support incidents, and promotion performance often live in separate systems. An agent can normalise these inputs into one operational thread, especially when the business needs response rather than just reporting.
That pattern becomes stronger when paired with sector-specific data flows such as retail AI systems that connect operational and customer signals. The agent is not the platform. It is the coordination layer that helps teams act on what the platform already knows.
The strongest production use case is usually not “replace a team”. It is “remove the repetitive coordination work around a team”.
Production Readiness Governance Safety and Cost Control
At this stage, many agent projects either become credible software systems or remain controlled demos.
If a team cannot explain what the agent can access, what it is allowed to do, how its actions are logged, how failures are contained, and what the run cost looks like, the system is not ready for production. It may still be useful in a sandbox. It is not ready to operate against business workflows.
Observability is not optional
Traditional applications log requests, responses, errors, and performance metrics. Agent systems need more.
Teams need to see:
- Prompt and context versions. Which instructions and retrieval inputs shaped the decision.
- Tool calls. What the agent attempted, with what parameters, and with what result.
- Policy decisions. Which actions were allowed, blocked, retried, or escalated.
- Task state. Where the workflow paused, resumed, or failed.
Without this, debugging becomes guesswork. Worse, audit discussions become impossible in regulated environments.
Safety starts with capability design
A common governance mistake is trying to bolt on safety after the action layer already exists. By then, the access patterns are often too broad.
Safer systems are designed with narrow permissions from the start.
| Control area | Better pattern | Weak pattern |
|---|---|---|
| Tool access | Explicit allow-list per agent role | One broad integration token |
| Data access | Scope by task and policy | Full system visibility by default |
| Sensitive actions | Human approval or dual control | Direct execution from model output |
| Memory | Store necessary operational state | Persist everything “for later” |
This matters for privacy, security, and resilience. In practical terms, privacy by design means the agent should only touch the minimum data required for the task, and only through interfaces that can be audited.
Human in the loop is a design pattern
Teams sometimes speak about human review as if it were evidence that the system is incomplete. In practice, it is often the correct operating model.
Use human approval when:
- The action is destructive
- The business rule is contested
- The evidence is incomplete
- The regulator expects accountable review
- The cost of a wrong action is high
A good agent workflow lets software handle collection, classification, drafting, and routing, while a human validates the final commitment.
That is not a compromise. It is how many real organisations should operate.
Cost control comes from architecture
Runaway cost rarely starts with the model itself. It usually starts with poor workflow design.
Repeated retrieval, unnecessary loops, oversized context windows, duplicate tool calls, and expensive models used for trivial sub-tasks all increase cost. Cost control is therefore an engineering concern, not a finance afterthought.
For enterprise-scale agentic models, low-latency inference with compact LLMs such as Mistral Small is critical, and industrialisation requires estimating costs upfront, with examples such as $0.01-0.05 per 1K tokens for Mixtral, while integrating monitoring, fallbacks, and human-in-the-loop controls, according to McKinsey’s analysis of the agentic AI advantage.
The practical lesson is to choose the smallest model that reliably performs the sub-task. A planner may need stronger reasoning. A classifier or formatter usually does not.
A production control checklist
A serious system should have all of the following before broad rollout:
- Identity-aware tool execution. The agent acts through a service identity or delegated user context that can be audited.
- Policy gates. Read, write, approve, and delete are separate capabilities.
- Fallback paths. If retrieval fails or the model confidence is weak, the workflow degrades cleanly.
- Rate limits and budgets. The system should know when to stop spending.
- Versioned prompts and tools. Changes need the same discipline as application releases.
- Testing with adversarial cases. Include malformed input, conflicting evidence, stale records, and partial outages.
- Compliance mapping. Control evidence should align with frameworks such as GDPR, NIS2, and DORA where relevant.
For teams formalising those controls, it helps to treat them as part of the wider means of compliance in digital systems, not as an AI-specific side topic.
An agent without observability is hard to trust. An agent with broad access and weak controls is hard to justify.
A Pragmatic Path to Adopting Agent Models
Most organisations should not start with a grand multi-agent platform. They should start with one workflow that is repetitive, valuable, and governable.
The right first target is usually not customer-facing autonomy. It is an internal process with clear rules, clear data sources, and measurable effort.
Start with a bounded workflow
Choose work that has these traits:
- Frequent enough to matter
- Structured enough to model
- Low enough risk to test safely
- Visible enough that users can judge the result
Support triage, internal knowledge retrieval, compliance evidence gathering, and backlog preparation are all better candidates than broad autonomous decision-making.
Build proof of value, not theatre
A proof of concept often proves only that a model can say the right things in a controlled setting.
A proof of value is different. It runs against a real workflow, in a sandbox or limited production environment, with actual users and actual system boundaries. It records failure modes, review effort, missed edge cases, and operational cost.
A good first release is often plain:
- One agent
- A small set of approved tools
- Strong logging
- Human approval for side effects
- A clear rollback path
This is enough to learn whether the workflow deserves deeper investment.
Expand through evidence
Once the first workflow performs well, expansion should follow the logs.
If users keep correcting the same classification error, improve the classifier. If the agent spends too much time on retrieval, fix the search and context assembly. If approvals are almost always granted, automate the lower-risk branch first. If the agent gets stuck on edge cases, narrow the scope rather than widening the prompt.
This is slower than hype-driven rollout, but it produces systems that remain maintainable.
Keep the platform small until the pattern is clear
Many teams build too much platform too early. They create agent registries, memory layers, complex planners, and abstract orchestration frameworks before they have one stable workflow.
It is usually better to harden one useful path, extract the repeated components, and only then decide what deserves to become platform infrastructure.
The agent models reward restraint. Every extra capability adds policy, testing, and operational burden. If the business problem does not need it, leave it out.
Conclusion Building Tomorrow’s Systems with Engineering Discipline
The agent models matter because they shift AI from passive response to bounded action. That opens far more business value than a standalone chatbot can deliver, but it also raises the standard for architecture.
The winning pattern is not “pick the smartest model and give it access”. It is to engineer a system where the model reasons inside a controlled environment. Tools are explicit. Permissions are narrow. State is durable. Costs are visible. Humans remain in the loop where judgement, accountability, or regulation require it.
That is why the conversation should move away from novelty and toward systems design.
Reliable agents are built the same way reliable software is built. With clear contracts, tested workflows, strong observability, release discipline, and governance that exists before the incident, not after it. The model is important, but it is not the whole product. The orchestration, safety design, and operational controls are what decide whether the system creates lasting value or operational drag.
For CTOs and product leaders, the practical takeaway is simple. Treat the agent models as software components with unusual behaviour, not as magic. When they are engineered that way, they become useful colleagues inside a modern digital architecture. When they are not, they become expensive demonstrations.
If your team is assessing where agentic systems fit into real operations, Devisia helps organisations design and build governed AI-enabled software with the engineering discipline needed for long-term reliability, maintainability, and compliance.