
Un modello familiare si sta manifestando proprio ora in molti team di prodotto e ingegneria. Qualcuno ha acquistato o costruito una funzionalità LLM. La demo sembrava forte. Rispondeva alle domande con fluidità, riassumeva i documenti e gestiva prompt ampi con sicurezza.
Poi il sistema si è confrontato con un flusso di lavoro reale.
Poteva spiegare come risolvere un problema di supporto, ma non poteva aprire il ticket, ispezionare i log, controllare la knowledge base o inoltrare il caso con il contesto giusto. Poteva redigere una risposta di conformità, ma non poteva verificare i record sorgente, applicare le regole di policy o instradare il caso per l’approvazione. Quello che sembrava automazione era spesso solo una conversazione migliore.
Quel divario conta. I CTO non stanno acquistando eloquenza. Sono responsabili di throughput, affidabilità, auditabilità, controllo degli accessi e costo operativo. Se un sistema AI non può eseguire azioni delimitate all’interno di un’architettura governata, rimane un assistente utile, non un componente operativo.
I modelli agentici si collocano in quel divario. Usati bene, trasformano i modelli linguistici in sistemi che possono osservare lo stato, scegliere tra strumenti approvati, eseguire attività e fermarsi quando il rischio o l’incertezza diventano troppo elevati. Usati male, creano loop opachi, spese incontrollate, integrazioni fragili e problemi di governance che emergono solo dopo il deployment.
Il problema delle integrazioni AI di oggi
La prima generazione di integrazioni AI di solito falliva in modo prevedibile. I team avvolgevano un’interfaccia chat attorno a un modello, lo collegavano ad alcuni documenti e lo chiamavano automazione intelligente.
In pratica, il risultato era più simile a una FAQ raffinata per l’help desk.
Un CTO potrebbe chiedere un assistente per le operations clienti in grado di gestire le richieste di rimborso. Il chatbot può spiegare la policy sui rimborsi. Può persino produrre un messaggio cortese. Ma quando il flusso di lavoro richiede il controllo di un sistema ordini, la validazione dei segnali di frode, l’applicazione di regole di business, l’aggiornamento del CRM e la registrazione di una traccia di audit, l’illusione si rompe. Il modello ha competenza linguistica, non agenzia operativa.
Da dove nasce la delusione
La maggior parte dei progetti AI deludenti condivide uno o più di questi difetti:
- Nessun livello di azione. Il modello produce testo, ma non può chiamare strumenti in sicurezza.
- Nessuna memoria del flusso di lavoro. Dimentica lo stato tra un turno e l’altro o lo memorizza in modo incoerente.
- Nessun ancoraggio al sistema. Parla con sicurezza senza controllare i dati attuali.
- Nessun modello di approvazione. Le azioni sensibili avvengono senza controlli chiari, oppure non avviene nulla perché il team ha paura di consentire qualsiasi azione.
Il risultato è scomodo. Il personale continua a svolgere manualmente il lavoro principale, mentre l’AI produce riassunti o suggerimenti ai margini.
Un sistema di produzione utile non si limita a generare risposte. Completa il lavoro entro vincoli.
Perché sta diventando urgente
Il passaggio dall’AI passiva ai sistemi agentici non è una tendenza di nicchia. Il rapporto di Gartner dell’ottobre 2024 prevede che l’integrazione dell’AI agentica nelle applicazioni software enterprise passerà da meno dell’1% nel 2024 al 33% entro il 2028 secondo questo riepilogo di eMarketer della previsione di Gartner.
Questa previsione conta perché indica una transizione architetturale. I team enterprise stanno passando da “chiedi al modello” a “delegha un’attività delimitata a un sistema governato”. La differenza non è cosmetica. Cambia il modo in cui il software deve essere progettato, testato, protetto, monitorato e finanziato.
Oltre i chatbot: cosa sono i modelli agentici
Un modello agentico non è solo un chatbot più grande. È un pattern software in cui un sistema AI riceve un obiettivo, valuta lo stato corrente, decide cosa fare dopo, utilizza strumenti approvati e continua fino a raggiungere una condizione di arresto.
Sembra astratto finché non lo si confronta con una normale chiamata LLM.
Un LLM semplice si comporta come un consulente che scrive un memo quando gli viene chiesto. Un agente si comporta più come un operatore junior che può leggere istruzioni, usare software, raccogliere informazioni mancanti e portare avanti un’attività sotto supervisione. Ha comunque bisogno di guardrail. Commette comunque errori. Ma può partecipare all’esecuzione, non solo alla spiegazione.
Le parti fondamentali di un agente
La maggior parte degli agenti in produzione è costruita a partire da un piccolo insieme di componenti.
- Il modello di ragionamento. È l’LLM che interpreta l’obiettivo e sceglie l’azione successiva.
- Gli strumenti. Sono interfacce controllate come API, database, livelli di ricerca, code o servizi interni.
- Memoria e stato. Il sistema ha bisogno di una memoria di lavoro per l’attività corrente e, in alcuni casi, di uno stato persistente per flussi di lavoro più lunghi.
- Vincoli di policy. Controllo degli accessi, regole di approvazione, limiti di frequenza e confini d’azione definiscono ciò che l’agente può fare.
- Un ciclo di esecuzione. Il sistema ripete un ciclo di osservazione, decisione, azione e rivalutazione.
Una normale integrazione prompt-risposta di solito si ferma dopo il primo passaggio. Un agente continua fino al completamento, alla richiesta di input umano o al raggiungimento di un limite definito.
Cosa rende utile un agente nei sistemi aziendali
Il valore pratico dei modelli agentici deriva da tre caratteristiche.
In primo luogo, l’agente può usare strumenti invece di fingere. Se l’attività richiede lo stato attuale del cliente, l’inventario aggiornato o il testo della policy corrente, la risposta giusta non è “il meglio possibile dalla memoria del modello”. La risposta giusta è una chiamata governata alla fonte pertinente.
In secondo luogo, l’agente può gestire lavori multi-step. I processi aziendali reali raramente rientrano in un singolo prompt. Un flusso di triage del supporto può richiedere classificazione, recupero, validazione, azione, escalation e registrazione.
In terzo luogo, l’agente può fermarsi in sicurezza. Un agente affidabile non ha bisogno di autonomia illimitata. Nella maggior parte delle aziende, il pattern migliore è un’autonomia delimitata con punti di passaggio espliciti.
Un semplice modello mentale
Pensa al ciclo di esecuzione in questo modo:
-
Ricevi l’obiettivo “Controlla i messaggi di supporto notturni e identifica eventuali problemi a livello di incidente.”
-
Ispeziona il contesto Leggi i ticket correnti, lo stato del servizio, i runbook interni e gli alert recenti.
-
Scegli l’azione Cerca nella knowledge base degli incidenti, correla i log, redigi un riepilogo, crea un ticket.
-
Esegui tramite strumenti Usa Jira, Slack, la ricerca dei log e un’API interna di stato.
-
Valuta il risultato Se la confidenza è bassa o l’azione è sensibile, chiedi l’approvazione umana.
Questa è la differenza tra una funzionalità conversazionale e un sistema operativo. Il modello è solo una parte. L’architettura intorno a esso determina se è utile.
Una tassonomia dei moderni agenti AI
Non tutti i sistemi agentici risolvono lo stesso problema. Trattarli come un’unica categoria porta a decisioni progettuali sbagliate, perché l’architettura per un agente di triage del supporto è diversa dall’architettura per un agente di pianificazione o un modello di simulazione.
Una tassonomia pratica aiuta i team a scegliere il pattern più piccolo che si adatta al lavoro.
Agenti che usano strumenti
Il problema aziendale è semplice. Il team ha lavoro digitale ripetitivo distribuito tra API e dashboard, e il personale trascorre tempo a copiare informazioni tra sistemi.
Un agente che usa strumenti affronta questo problema esponendo al modello azioni approvate. Queste azioni potrebbero includere la creazione di ticket, l’aggiornamento di record, l’interrogazione di un data warehouse o l’invio di un messaggio strutturato in un workflow interno.
Questo è spesso il punto di partenza giusto perché mantiene il design circoscritto. L’agente è utile solo nella misura in cui gli strumenti sono ben definiti e le autorizzazioni sono controllate.
Caso d’uso: un agente per le operations del supporto controlla un evento di pagamento fallito, cerca l’account del cliente e apre il tipo di caso corretto con i metadati giusti.
Agenti con retrieval augmentato
Qui il problema non è l’azione. È il grounding.
Un modello standard può produrre risposte plausibili da dati di addestramento generici, il che è rischioso in domini in cui la verità si trova in documenti di policy privati, documentazione di prodotto, runbook interni o archivi di conoscenza regolamentati. Un agente con retrieval augmentato interroga prima queste fonti, poi ragiona sul contesto recuperato prima di agire.
Questo pattern funziona bene quando l’organizzazione ha bisogno di verità attuale e locale piuttosto che di una generica capacità linguistica.
Caso d’uso: un agente per le policy interne controlla la libreria più recente dei controlli di sicurezza prima di redigere una risposta a una richiesta di evidenza DORA o NIS2.
Agenti di pianificazione
Alcuni flussi di lavoro sono troppo grandi per essere risolti in una sola mossa. Richiedono scomposizione in passaggi più piccoli, diramazioni condizionali e controlli intermedi.
Gli agenti di pianificazione sono utili quando l’attività ha un obiettivo ma non un percorso fisso. Suddividono obiettivi più grandi in sotto-attività ordinate, le eseguono una per una e si adattano in base ai risultati. Questo approccio può portare i team a essere eccessivamente ambiziosi. La pianificazione è potente, ma senza limiti crea anche loop lunghi, lavoro duplicato e stati di errore difficili da diagnosticare.
Caso d’uso: un agente di operations di prodotto analizza i reclami dei clienti, raggruppa i temi, identifica i difetti urgenti e prepara ticket di backlog per la revisione.
Sistemi multi-agente
Un singolo agente diventa disordinato quando un modello è chiamato a gestire intake, pianificazione, retrieval, azione, validazione e reporting. I sistemi multi-agente suddividono tali responsabilità tra lavoratori specializzati.
Un agente potrebbe classificare l’intento. Un altro recupera le evidenze di dominio. Un terzo esegue l’azione. Un quarto convalida la conformità alle policy prima dell’esecuzione. Questo può migliorare la manutenibilità se ogni agente ha un ruolo ristretto, ma può anche produrre complessità di orchestrazione se i team esagerano troppo presto.
Caso d’uso: un flusso di governance delle release in cui un agente esamina il contesto delle modifiche, uno controlla lo stato delle dipendenze, uno convalida le evidenze e un agente controller finale decide se richiedere l’approvazione umana.
Agenti con memoria
Alcune attività migliorano quando il sistema può utilizzare interazioni precedenti, preferenze note o risoluzioni passate. Ciò richiede memoria. Il problema è che molti team aggiungono memoria senza attenzione e finiscono per mescolare stato utile con contenuti non affidabili o obsoleti.
Gli agenti con memoria dovrebbero memorizzare solo ciò che è operativamente necessario e conforme alle policy. Non sono migliori perché ricordano di più. Sono migliori quando ricordano le cose giuste.
Caso d’uso: un agente di supporto IT ricorda che una flotta di dispositivi in un ufficio ha un problema ricorrente di configurazione VPN e controlla prima quel runbook.
Una nota sui modelli agentici precedenti
I modelli agentici non sono nati con gli LLM. I modelli basati su agenti hanno una lunga storia nelle simulazioni, inclusi strumenti come CovidSim, ed sono evoluti dal lavoro delle scienze sociali negli anni ‘90 modellando agenti eterogenei con regole di apprendimento, come descritto in questa panoramica dei modelli basati su agenti su Wikipedia.
Questa storia conta perché ci ricorda che l’agency è un concetto di sistema, non una tendenza di interfaccia. Molto prima dei moderni agenti LLM, ingegneri e ricercatori usavano agenti per modellare interazioni, testare scenari e comprendere comportamenti emergenti. L’ondata attuale aggiunge interfacce linguistiche e uso di strumenti. Non elimina la necessità di una progettazione chiara del sistema.
Progettare e orchestrare sistemi agentici
I buoni sistemi agentici si compongono, non si improvvisano. Il modello da solo non “gestisce il workflow”. Lo fa un’applicazione. Quell’applicazione decide come vengono assemblati i prompt, come vengono esposti gli strumenti, come viene memorizzato lo stato, cosa richiede approvazione, quando avvengono i retry e come vengono esposti i guasti.
La domanda progettuale centrale è semplice. Chi ha il controllo quando il modello è incerto, sbaglia, è lento o non è sicuro?
Se la risposta è “il modello lo capisce da solo”, l’architettura non è pronta per la produzione.
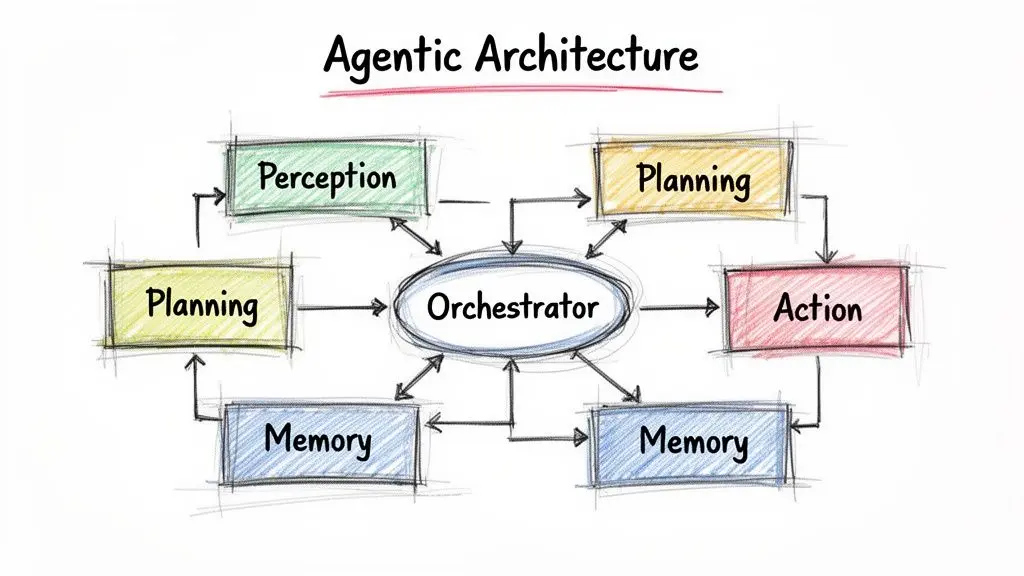
L’orchestratore è il prodotto
In produzione, il componente più importante spesso non è il modello. È l’orchestratore.
L’orchestratore gestisce il ciclo eventi. Raccoglie il contesto, chiama il modello, interpreta l’output del modello, invoca gli strumenti, registra lo stato e decide se il passo successivo è un’altra chiamata a uno strumento, una domanda all’utente, un fallback o un arresto. Applica anche le policy che non ci si può fidare del modello stesso di far rispettare.
Il pattern funzionante più semplice è questo:
obiettivo -> raccogli contesto -> chiedi al modello l’azione successiva
-> valida l’azione rispetto alla policy
-> esegui lo strumento approvato
-> registra il risultato
-> chiedi al modello l’azione successiva o la risposta finaleNon è glamour, ma è ciò che trasforma una demo in un servizio.
Due pattern di orchestrazione utili
Il primo pattern utile è un ciclo ragiona e agisci. Il modello ragiona sullo stato attuale, seleziona uno strumento, riceve il risultato e poi ragiona di nuovo. Questo mantiene il modello ancorato a risultati osservabili invece di costringerlo a inventare l’intero piano in anticipo.
Il secondo è planner più worker. Un modello crea un piano delimitato. Agenti worker separati o servizi deterministici eseguono i passaggi. Questo è spesso più sicuro per attività più lunghe perché il planner non ottiene il potere diretto su tutte le azioni a valle.
Un esempio semplificato:
Obiettivo dell’utente:
"Riassumi i feedback recenti dei clienti e crea un ticket Jira per qualsiasi bug urgente."
Planner:
1. Recupera i feedback dalle fonti approvate
2. Raggruppa i messaggi per tema
3. Identifica i probabili difetti
4. Verifica le regole di severità
5. Redigi i ticket per la revisione umana
Worker:
- Il worker di retrieval interroga i dati di supporto
- Il worker di analisi raggruppa i report
- Il worker delle regole applica i criteri di urgenza
- Il worker Jira crea una bozza di ticket solo se approvataQuesta architettura separa giudizio, raccolta delle evidenze, controlli di policy ed effetti collaterali.
L’autonomia limitata batte l’autonomia ampia
Molti team commettono lo stesso errore. Cercano di dare a un singolo agente generale ampio accesso a tutto. All’inizio sembra efficiente, perché la demo è semplice. Più avanti diventa costoso, perché ogni nuova integrazione aumenta il raggio d’impatto.
Un pattern migliore è la capacità vincolata:
- Leggere ampiamente, scrivere in modo limitato
- Approvare le azioni distruttive
- Separare il retrieval dall’esecuzione
- Esporre esplicitamente le regole di business invece di sperare che il modello le inferisca
L’agente più sicuro non è quello meno capace. È quello le cui capacità sono esplicite, verificabili e abbastanza limitate da poter essere governate.
Perché l’orchestrazione conta operativamente
Nei contesti di delivery IT, l’orchestrazione non è solo un pattern di AI. Influisce sull’esecuzione del programma. L’orchestrazione autonoma può consentire agli agenti AI di agire come coordinatori di progetto e ridurre fino al 70% il sovraccarico amministrativo per i project manager umani in base a regole predefinite di allocazione delle risorse, secondo l’articolo di STL Digital sui programmi guidati da agenti.
La lezione pratica non è che la gestione di progetto scompare. È che il lavoro ripetitivo di coordinamento può passare nel software quando le regole sono esplicite e lo stato è visibile.
Lo stesso principio si applica ai sistemi tecnici. Un agente può instradare il lavoro, raccogliere prove, tracciare i progressi e attivare il passo successivo, ma solo se il workflow è modellato come software e non delegato come intenzione vaga.
Un flusso di sistema concreto
Considera un workflow di operations del servizio:
- L’orchestratore acquisisce i messaggi di supporto notturni.
- Un classificatore decide se ciascun messaggio riguarda fatturazione, prodotto, incidente o rumore.
- Un componente di retrieval recupera le voci pertinenti della knowledge base e lo stato recente del servizio.
- Il modello redige una diagnosi e propone l’azione successiva.
- Un livello di policy verifica se l’azione è consentita.
- Se l’azione è a basso rischio, lo strumento viene eseguito.
- Se l’azione è ad alto rischio, il sistema instrada verso un approvatore umano.
- Ogni passaggio viene registrato per la tracciabilità.
Questo è anche il tipo di architettura che diventa più prezioso se affiancata a sistemi operativi adiacenti, incluse integrazioni AI e IoT in prodotti reali, dove gli agenti potrebbero dover reagire a eventi dei dispositivi, telemetria o soglie operative invece che a soli prompt testuali.
Qui è utile una breve panoramica visiva.
Cosa non funziona
Tre design falliscono ripetutamente.
- L’agente onnisciente. Un prompt, molti strumenti, nessuna disciplina. Diventa opaco in fretta.
- Il workflow nascosto. La logica vive nei prompt invece che nel codice e nelle policy. Nessuno può verificarla correttamente.
- Il loop senza stato. Il sistema non riesce a riprendersi in modo pulito dopo un’interruzione, quindi le attività a lunga esecuzione diventano fragili.
L’architettura di produzione richiede stato esplicito, permessi espliciti, contratti espliciti per gli strumenti e regole di arresto esplicite. Tutto il resto è cablaggio speranzoso.
Modelli agentici in pratica casi d’uso reali
I migliori casi d’uso per i modelli agentici non sono quelli più teatrali. Sono quelli in cui i team conoscono già il workflow, gli input sono disponibili, i sistemi di registrazione sono chiari e il costo del ritardo è reale.
Triage del supporto IT con azione controllata
Un problema comune dei service desk è che i team di prima linea spendono troppo tempo a raccogliere contesto prima ancora di poter iniziare a risolvere il problema.
Un agente di supporto utile non cerca di sostituire l’intero desk. Gestisce l’inizio del workflow. Legge la richiesta, classifica il problema, cerca nel wiki interno, controlla lo stato del servizio, ispeziona la telemetria consentita e suggerisce o esegue il passo successivo approvato. Se la confidenza è bassa, inoltra una sintesi strutturata invece di una trascrizione vaga.
Il vantaggio è operativo. Gli esseri umani partono dal contesto invece che dalla raccolta.
Reporting finanziario per un operatore SaaS
I team finance e product spesso lavorano sugli stessi numeri ma attraverso strumenti e tempistiche diverse. Un agente di reporting può estrarre i dati di vendita correnti, riconciliarli con le definizioni concordate, aggiornare un foglio di previsione o un servizio e produrre una bozza di riepilogo settimanale con evidenze collegate.
Sembra semplice, ma l’architettura conta. L’agente non dovrebbe inventare la logica dei ricavi. Dovrebbe chiamare servizi noti, usare definizioni bloccate e produrre output facili da revisionare.
Gli aspetti economici dei servizi agentici attireranno qui l’attenzione. Entro il 2026, Agent-as-a-Service dovrebbe raggiungere margini di 460 dollari al giorno per agente, ma falle strutturali non monitorate nei connettori IT possono amplificare i tassi di guasto di 3 volte, secondo la discussione di Spiral Scout sui pattern di agenti in produzione. La conclusione è semplice. La storia del margine è irrilevante se il livello dei connettori è fragile.
Operazioni di compliance in workflow regolamentati
Un agente di compliance può essere utile quando il lavoro richiede molte prove ed è ripetitivo.
Per esempio, in un workflow fintech, l’agente può ispezionare un evento di transazione, recuperare le regole di policy pertinenti, raccogliere i dati di supporto e preparare un case file per la revisione. Può segnalare anomalie, richiedere informazioni mancanti o instradare al responsabile corretto. La decisione spetta comunque a una persona quando la regolamentazione o il rischio lo richiedono.
Questa divisione del lavoro conta. L’automazione raccoglie e struttura le evidenze. I revisori umani prendono decisioni di cui sono responsabili.
Operazioni retail e segnali di domanda
I workflow retail sono pieni di segnali frammentati. Resi di prodotto, anomalie di stock, feedback dei clienti, incidenti di supporto e performance delle promozioni spesso vivono in sistemi separati. Un agente può normalizzare questi input in un unico flusso operativo, soprattutto quando l’azienda ha bisogno di risposta e non solo di reporting.
Questo pattern diventa più forte se affiancato a flussi di dati specifici del settore come sistemi AI per il retail che collegano segnali operativi e dei clienti. L’agente non è la piattaforma. È il livello di coordinamento che aiuta i team ad agire su ciò che la piattaforma sa già.
Il caso d’uso in produzione più forte di solito non è “sostituire un team”. È “eliminare il lavoro ripetitivo di coordinamento attorno a un team”.
Governance, sicurezza e controllo dei costi della prontezza alla produzione
A questo punto, molti progetti agentici diventano sistemi software credibili oppure restano demo controllate.
Se un team non riesce a spiegare a cosa l’agente può accedere, cosa gli è permesso fare, come vengono registrate le sue azioni, come vengono contenuti i guasti e come appaiono i costi di esecuzione, il sistema non è pronto per la produzione. Potrebbe essere ancora utile in un sandbox. Non è pronto a operare sui workflow aziendali.
L’osservabilità non è opzionale
Le applicazioni tradizionali registrano richieste, risposte, errori e metriche di performance. I sistemi agentici hanno bisogno di più.
I team devono vedere:
- Versioni del prompt e del contesto. Quali istruzioni e input di retrieval hanno modellato la decisione.
- Chiamate agli strumenti. Cosa ha tentato l’agente, con quali parametri e con quale risultato.
- Decisioni di policy. Quali azioni sono state consentite, bloccate, ritentate o inoltrate.
- Stato dell’attività. Dove il workflow si è fermato, ripreso o è fallito.
Senza questo, il debugging diventa un tiro a indovinare. Peggio ancora, le discussioni di audit diventano impossibili in ambienti regolamentati.
La sicurezza inizia dalla progettazione delle capacità
Un errore comune di governance è cercare di aggiungere la sicurezza dopo che il livello di azione esiste già. A quel punto, i pattern di accesso sono spesso troppo ampi.
I sistemi più sicuri vengono progettati fin dall’inizio con permessi limitati.
| Area di controllo | Pattern migliore | Pattern debole |
|---|---|---|
| Accesso agli strumenti | Allow-list esplicita per ruolo dell’agente | Un unico token di integrazione ampio |
| Accesso ai dati | Ambito per attività e policy | Visibilità completa del sistema per impostazione predefinita |
| Azioni sensibili | Approvazione umana o doppio controllo | Esecuzione diretta dall’output del modello |
| Memoria | Memorizzare solo lo stato operativo necessario | Persistire tutto “per dopo” |
Questo conta per privacy, sicurezza e resilienza. In termini pratici, privacy by design significa che l’agente dovrebbe toccare solo il minimo di dati richiesto per l’attività, e solo tramite interfacce che possono essere verificate.
L’human in the loop è un pattern di progettazione
I team a volte parlano di revisione umana come se fosse la prova che il sistema è incompleto. In pratica, spesso è il modello operativo corretto.
Usa l’approvazione umana quando:
- L’azione è distruttiva
- La regola di business è contestata
- Le evidenze sono incomplete
- Il regolatore si aspetta una revisione responsabile
- Il costo di un’azione errata è alto
Un buon workflow agentico permette al software di gestire raccolta, classificazione, redazione e instradamento, mentre un umano convalida l’impegno finale.
Non è un compromesso. È il modo in cui molte organizzazioni reali dovrebbero operare.
Il controllo dei costi deriva dall’architettura
I costi fuori controllo raramente iniziano dal modello stesso. Di solito iniziano da una cattiva progettazione del workflow.
La ricerca ripetuta, i loop inutili, le finestre di contesto sovradimensionate, le chiamate duplicate agli strumenti e i modelli costosi usati per sotto-attività banali aumentano tutti i costi. Il controllo dei costi è quindi una questione di ingegneria, non un ripensamento finanziario.
Per i modelli agentici su scala enterprise, l’inferenza a bassa latenza con LLM compatti come Mistral Small è fondamentale, e l’industrializzazione richiede una stima anticipata dei costi, con esempi come $0.01-0.05 per 1K token per Mixtral, integrando al contempo monitoraggio, fallback e controlli human-in-the-loop, secondo l’analisi di McKinsey sul vantaggio dell’AI agentica.
La lezione pratica è scegliere il modello più piccolo che esegua in modo affidabile il sotto-compito. Un planner può avere bisogno di ragionamenti più robusti. Un classificatore o un formatter di solito no.
Una checklist di controllo per la produzione
Un sistema serio dovrebbe avere tutto quanto segue prima di un rilascio su larga scala:
- Esecuzione degli strumenti consapevole dell’identità. L’agente opera tramite un’identità di servizio o un contesto utente delegato che può essere verificato.
- Soglie di policy. Lettura, scrittura, approvazione ed eliminazione sono capacità separate.
- Percorsi di fallback. Se il retrieval fallisce o la fiducia del modello è debole, il flusso di lavoro degrada in modo pulito.
- Limiti di velocità e budget. Il sistema dovrebbe sapere quando smettere di spendere.
- Prompt e strumenti versionati. Le modifiche richiedono la stessa disciplina delle release applicative.
- Testing con casi avversari. Includere input malformati, evidenze conflittuali, record obsoleti e interruzioni parziali.
- Mappatura della conformità. Le evidenze di controllo dovrebbero allinearsi a framework come GDPR, NIS2 e DORA, dove pertinente.
Per i team che formalizzano tali controlli, è utile considerarli parte del più ampio mezzi di conformità nei sistemi digitali, non come un tema secondario specifico dell’AI.
Un agente senza osservabilità è difficile da fidare. Un agente con ampio accesso e controlli deboli è difficile da giustificare.
Un percorso pragmatico per adottare modelli agentici
La maggior parte delle organizzazioni non dovrebbe iniziare con una grande piattaforma multi-agente. Dovrebbe iniziare con un unico workflow ripetitivo, di valore e governabile.
Il giusto primo obiettivo di solito non è l’autonomia rivolta al cliente. È un processo interno con regole chiare, fonti dati chiare e sforzo misurabile.
Iniziare con un workflow delimitato
Scegliete un lavoro che abbia queste caratteristiche:
- Abbastanza frequente da contare
- Abbastanza strutturato da poter essere modellato
- Con un rischio abbastanza basso da poter essere testato in sicurezza
- Abbastanza visibile da consentire agli utenti di giudicare il risultato
Triage del supporto, retrieval di conoscenze interne, raccolta di evidenze di conformità e preparazione del backlog sono tutti candidati migliori di un’ampia presa di decisioni autonome.
Costruire prova di valore, non teatro
Una proof of concept spesso dimostra solo che un modello può dire le cose giuste in un contesto controllato.
Una proof of value è diversa. Opera su un workflow reale, in un ambiente sandbox o in un ambiente di produzione limitato, con utenti reali e confini di sistema reali. Registra le modalità di fallimento, l’effort di revisione, i casi limite mancati e il costo operativo.
Una buona prima release è spesso semplice:
- Un agente
- Un piccolo insieme di strumenti approvati
- Logging robusto
- Approvazione umana per gli effetti collaterali
- Un chiaro percorso di rollback
Questo è sufficiente per capire se il workflow merita un investimento più profondo.
Espandere sulla base delle evidenze
Una volta che il primo workflow funziona bene, l’espansione dovrebbe seguire i log.
Se gli utenti continuano a correggere lo stesso errore di classificazione, migliorate il classificatore. Se l’agente passa troppo tempo sul retrieval, sistemate la ricerca e l’assemblaggio del contesto. Se le approvazioni vengono quasi sempre concesse, automatizzate prima il ramo a minor rischio. Se l’agente si blocca sui casi limite, restringete il perimetro invece di ampliare il prompt.
Questo è più lento di un rollout guidato dall’hype, ma produce sistemi che restano manutenibili.
Mantenere la piattaforma piccola finché il pattern non è chiaro
Molti team costruiscono troppa piattaforma troppo presto. Creano registry di agenti, livelli di memoria, planner complessi e framework di orchestration astratti prima di avere un workflow stabile.
Di solito è meglio consolidare un percorso utile, estrarre i componenti ricorrenti e solo allora decidere cosa merita di diventare infrastruttura di piattaforma.
I modelli agentici premiano la moderazione. Ogni capacità aggiuntiva introduce policy, testing e oneri operativi. Se il problema di business non ne ha bisogno, lasciatela fuori.
Conclusione Costruire i sistemi di domani con disciplina ingegneristica
I modelli agentici contano perché spostano l’AI dalla risposta passiva all’azione delimitata. Questo apre un valore di business molto maggiore di quello che può offrire un chatbot standalone, ma alza anche il livello richiesto per l’architettura.
Il pattern vincente non è “scegli il modello più intelligente e dagli accesso”. È progettare un sistema in cui il modello ragiona all’interno di un ambiente controllato. Gli strumenti sono espliciti. I permessi sono limitati. Lo stato è persistente. I costi sono visibili. Gli esseri umani restano nel loop dove giudizio, responsabilità o regolamentazione lo richiedono.
Ecco perché la conversazione dovrebbe spostarsi dalla novità al system design.
Gli agenti affidabili si costruiscono allo stesso modo in cui si costruisce software affidabile. Con contratti chiari, workflow testati, forte osservabilità, disciplina di rilascio e governance che esiste prima dell’incidente, non dopo. Il modello è importante, ma non è l’intero prodotto. L’orchestrazione, la progettazione della sicurezza e i controlli operativi sono ciò che decide se il sistema crea valore duraturo o attrito operativo.
Per CTO e product leader, il messaggio pratico è semplice. Trattate i modelli agentici come componenti software con comportamento insolito, non come magia. Quando sono progettati in questo modo, diventano colleghi utili all’interno di un’architettura digitale moderna. Quando non lo sono, diventano dimostrazioni costose.
Se il vostro team sta valutando dove i sistemi agentici si inseriscono nelle operazioni reali, Devisia aiuta le organizzazioni a progettare e costruire software abilitato all’AI e governato, con la disciplina ingegneristica necessaria per affidabilità, manutenibilità e conformità a lungo termine.