
For technical leaders, Personal Identifiable Information (PII) is not merely a compliance term; it is a critical data classification that dictates system architecture, security protocols, and data handling procedures. Mismanagement of PII introduces significant technical debt, security vulnerabilities, and regulatory risk.
What PII Means for System Architecture
The fundamental problem is that treating PII as a simple legal checkbox leads to flawed system design. In software engineering, PII is a technical flag indicating that specific, non-negotiable controls are required. A naive approach—failing to distinguish between different types of PII—results in systems that are either insecure or unnecessarily complex.
Mishandling PII leads to architectural inflexibility, reputational damage, and significant fines. A pragmatic approach involves mapping data not just by its function but by its potential to identify an individual—either directly or when combined with other data points.
This moves beyond simple definitions. A user’s full name is obviously PII. The more complex challenge lies in handling clusters of seemingly anonymous data—such as a postal code, date of birth, and gender—which can be aggregated to re-identify an individual with high accuracy. This concept of “re-identification risk” is central to modern data privacy engineering.
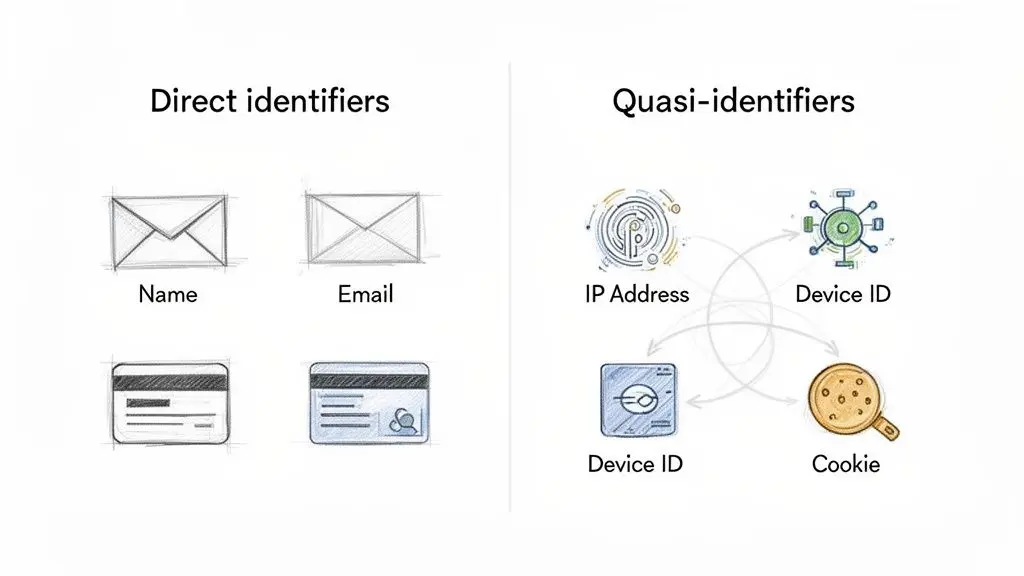
Direct vs. Quasi-Identifiers
To build secure systems, PII must be classified into two practical categories. This distinction directly informs architectural decisions, such as whether data requires encryption, pseudonymisation, or isolation within a highly restricted environment.
- Direct Identifiers: Data that unambiguously points to a single individual. This is the most sensitive category and requires the highest level of protection, such as encryption at rest and in transit, and strict access controls. Examples include full names, email addresses, and government ID numbers.
- Quasi-Identifiers (Indirect Identifiers): Data points that are not unique on their own but can be combined to identify an individual. An IP address, device ID, or broad geographic location are common examples found in application logs and analytics systems.
This diagram illustrates the fundamental distinction.

While direct identifiers pose an obvious risk, the more subtle architectural challenge comes from managing the accumulation of quasi-identifiers across distributed systems.
PII Classification Framework for Engineering Teams
This table provides a practical framework for data mapping and security audits. It breaks down PII types, their common locations in a typical software stack, and their associated risk levels.
| PII Category | Examples | Common System Locations | Associated Risk Level |
|---|---|---|---|
| Direct Identifiers | Full Name, Email Address, Social Security Number, Driver’s License Number | User profiles, authentication services, billing tables, customer support logs | High |
| Quasi-Identifiers | Date of Birth, Postal Code, Gender, IP Address, Device ID, Job Title | Analytics events, log files, marketing automation systems, user preferences tables | Medium (High when combined) |
| Sensitive PII (SPII) | Health Data, Biometric Data, Racial or Ethnic Origin, Religious Beliefs, Sexual Orientation | Specialised features (e.g., health tracking), user-uploaded documents, HR systems | Critical |
| Linked Identifiers | User ID, Session ID, Order ID | Almost every table in your database, application logs, API request metadata | Low (High when linked to other PII) |
This framework should be treated as a living document. As new features are developed or third-party services integrated, the data map and corresponding PII classifications must be updated.
Sensitive Personal Identifiable Information (SPII)
A subset of PII, Sensitive Personal Identifiable Information (SPII), carries a critical risk level. Its exposure could lead to direct harm, discrimination, or personal distress. Regulations like GDPR impose significantly stricter processing requirements for this data category.
SPII is any information that, if lost or compromised, could result in significant harm or unfairness to an individual. This includes data revealing racial or ethnic origin, political opinions, religious beliefs, health data, or information concerning a person’s sex life or sexual orientation.
A user’s name is PII; their medical diagnosis is SPII. This distinction has immediate architectural consequences. Storing SPII may mandate separate, isolated databases (a “vault” architecture), end-to-end encryption with customer-managed keys, and explicit, granular user consent mechanisms. Failing to differentiate between general PII and SPII in system design is a common and costly oversight. The objective is a clear data map where every field is classified and its handling protocols are dictated by its risk level.
How Privacy Regulations Shape System Architecture
Compliance is a core architectural driver, not a legal checkbox. Regulations like GDPR in Europe and CCPA in California are not abstract legal texts; they are technical mandates that directly influence how software is designed, built, and maintained. Ignoring them introduces technical debt that becomes exponentially more expensive to resolve over time.
The problem with treating privacy as an afterthought—something to be “bolted on” before release—is that it fails to address foundational design flaws. A last-minute consent banner does not fix an insecure data model. Real compliance is achieved through Privacy by Design, where data protection is embedded into the system’s core logic from inception.
Translating Legal Principles into Engineering Practices
Key regulatory principles must be translated into concrete engineering requirements. Two of the most critical are data minimisation and purpose limitation. These principles should guide every architectural decision, from database schema design to API contracts.
- Data Minimisation: Collect and process only the personal data absolutely necessary for a specified purpose. In practice, every field in a user table must have a clear, documented justification. Collecting a user’s date of birth “just in case” violates this principle and creates unnecessary risk.
- Purpose Limitation: Process data only for the specific, explicit purposes for which it was collected. Architecturally, this means data collected for billing should be logically, and often physically, segregated from data used for marketing analytics.
Adopting these principles means asking, “Do we absolutely need this data?” at every stage of development. This single question can prevent significant architectural complexity and compliance violations.
Navigating the Complexities of Global Regulations
The fragmented global regulatory landscape presents a significant challenge. The definition of personal identifiable information and consent requirements vary substantially across jurisdictions. What is standard practice in one region may be illegal in another.
For example, GDPR provides a broad definition of personal data and mandates explicit, granular consent. Meanwhile, various US states are creating a patchwork of laws with their own unique definitions of “sensitive” PII and consumer rights. This growing complexity has real-world consequences for IT leaders. According to recent analysis, by 2026, 70% of IT professionals will consider data privacy policies a critical factor when evaluating tech vendors. This reflects a baseline expectation for privacy-by-design, as multi-state privacy laws compel a move away from CCPA-centric approaches. IT teams must now align data classification with varying state definitions of sensitive PII, such as Washington’s and Nevada’s health data frameworks. You can find a detailed analysis on how data privacy is evolving from Founders Legal.
Building Geo-Aware and Scalable Systems
To operate globally, system architecture must be flexible and geo-aware. A monolithic system with a single, one-size-fits-all data handling policy is no longer viable. The solution is a data governance model that can adapt to different legal requirements without fracturing the core architecture.
This often requires implementing capabilities such as:
- Storing user data in specific geographic regions to comply with data residency laws.
- Implementing dynamic consent mechanisms that present different options based on a user’s location.
- Designing APIs that can enforce different data access rules depending on the jurisdiction.
Building these features from the start is far more efficient than retrofitting a legacy system. By treating privacy as a foundational component, you create a scalable, maintainable system prepared for a constantly evolving regulatory environment. For specific guidance, you can read our detailed guide on GDPR’s Article 30 and its implications for your data processing records.
Common PII Exposure Risks and Attack Scenarios
Identifying PII is the first step; understanding its vulnerabilities is the next. PII exposure is rarely a single event but rather the result of systemic weaknesses that adversaries are adept at exploiting. To build resilient systems, you must adopt an adversarial mindset and proactively identify these failure points. The most significant risks are often not exotic zero-day exploits but common, unaddressed architectural flaws that can turn a simple misconfiguration into a major data breach.
Technical Failure Points
Attackers frequently target predictable weak spots in application and infrastructure design. These technical vulnerabilities are often low-hanging fruit, providing a direct path to sensitive data.
- Insecure API Endpoints: A common flaw is an API that returns more data than the frontend requires. For instance, a
/user/profileendpoint might send the user’s name to the UI, but the full JSON payload also includes their email, sign-up date, and last known IP address. This extraneous data is visible to anyone monitoring network traffic. - Misconfigured Cloud Storage: Publicly accessible cloud storage buckets are a leading cause of major data leaks. A developer might temporarily disable access controls on a storage bucket for testing and forget to re-enable them, leaving backups containing thousands of user records exposed.
- SQL Injection: An old but persistent threat, SQL injection allows attackers to bypass application logic and interact directly with the database. A vulnerable search form could permit an attacker to inject custom SQL commands and exfiltrate the entire
userstable. - Overlooked Data in Logs and Caches: PII often leaks into systems where it was never intended to be stored. Application logs might inadvertently capture full API requests containing sensitive data in query parameters. A Content Delivery Network (CDN) might cache a personalized page containing a user’s address and serve it to other users.
The Human Element in PII Breaches
Technical controls alone are insufficient because humans are an integral part of any system. Social engineering is often easier than breaking through hardened infrastructure. This “human element” must be a core component of any realistic threat model.
Insider threats—whether malicious or accidental—pose a significant risk. A disgruntled employee with database access could exfiltrate a customer list. Simultaneously, a well-intentioned but untrained support agent could be manipulated by a social engineering attack into resetting an account password for an impersonator.
An effective security posture extends beyond firewalls and encryption. It requires acknowledging that your greatest vulnerability might be an employee falling for a sophisticated phishing email.
This reality is driving change. Personal identifiable information has become a prime target in the IT sector. By 2026, 72% of IT and legal firms are projected to have a formal data security policy in place. This shift highlights a growing awareness that PII exists not just in databases but also in unstructured files, cloud platforms, and SaaS tools, where manual tracking is infeasible. You can learn more about these data privacy trends in the legal and IT sectors.
Ultimately, a pragmatic threat model requires mapping both technical and human attack vectors. By understanding how an attacker views your system—from a leaky API to a persuadable employee—you can focus security efforts where they will have the greatest impact, building a defence that is layered, resilient, and realistic.
Architectural Patterns for Safeguarding PII
Understanding the risks is necessary, but building systems that can withstand them is the objective. This requires shifting from problems to solutions by adopting robust architectural patterns designed to protect personal information from the ground up. These are not features to be added later; they are foundational choices that dictate how data moves, who can access it, and how it is secured at every layer of the stack.
Effective PII protection starts with the assumption that a breach will eventually occur. This mindset forces the implementation of layered defenses, ensuring that if one component is compromised, the most sensitive data remains secure. The following patterns are practical, battle-tested strategies for building those layers.
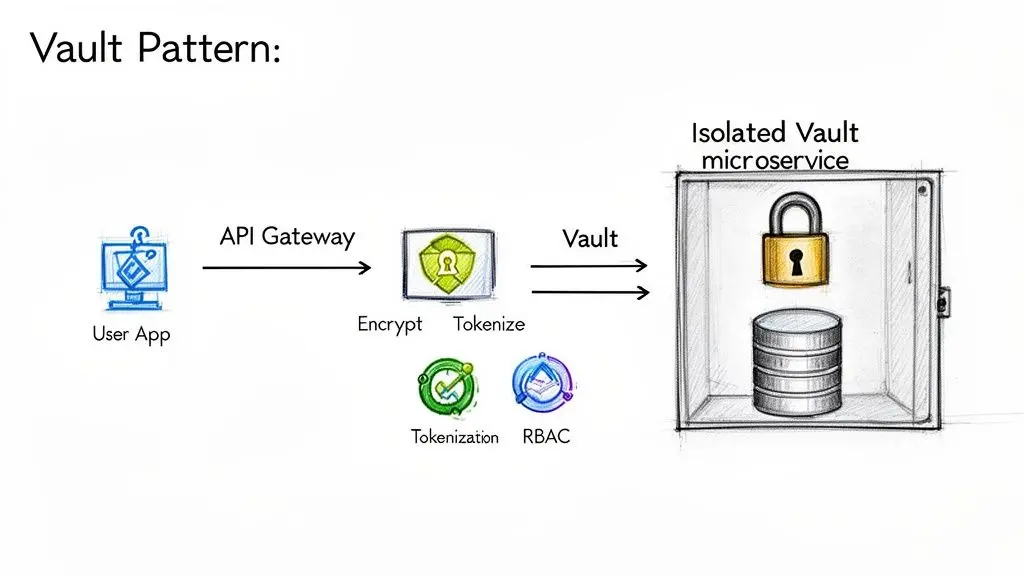
The Vault Pattern: Isolate What Matters Most
One of the most effective architectural models for protecting PII is the Vault Pattern. The concept is to physically and logically isolate personal data from the rest of the application. Instead of allowing user information to proliferate across multiple microservices and databases, it is centralized in a single, highly secured service—the vault.
This vault service exposes an extremely small and strictly controlled API. All other services that need to interact with PII must pass through a secure API gateway that enforces authentication and authorisation. This design radically reduces the attack surface.
Key components of the Vault Pattern include:
- Isolated Microservice: A dedicated service with the sole responsibility of storing and managing PII. It has its own database, which is inaccessible to any other service.
- Strict API Gateway: All requests to the vault are routed through a gateway that handles authentication, authorisation, and comprehensive logging.
- Tokenisation: Instead of passing raw PII between services, the vault issues a non-sensitive token (e.g., a UUID) that represents the user. Other services use this token to perform their functions without ever handling the actual PII.
The Vault Pattern transforms a distributed PII protection challenge into a centralized, manageable problem. Instead of securing ten different services that handle PII, you secure one vault and its tightly controlled entry points.
Implementing End-to-End Encryption
Encryption is a non-negotiable layer of defense. A common mistake is to only encrypt data at rest. A robust strategy implements end-to-end encryption, protecting data regardless of its location or state.
This means securing data in three distinct states:
- Data in Transit: Use strong TLS protocols (TLS 1.2 or higher) for all communication between services, APIs, and clients to prevent eavesdropping on data as it traverses networks.
- Data at Rest: Encrypt data stored in databases, object storage, and backups. Most cloud providers offer managed encryption services that simplify this process.
- Data in Use: This is the most challenging state to protect, as data must be decrypted for processing, creating a brief window of vulnerability. Emerging techniques like confidential computing use secure enclaves to process data while it remains encrypted, though they introduce significant complexity.
Role-Based Access Control and the Principle of Least Privilege
Technology alone cannot solve human-related risks. Strong Identity and Access Management (IAM) is essential. The guiding principle is the Principle of Least Privilege: any user, service, or system should have the minimum permissions required to perform its function and no more.
This is implemented through Role-Based Access Control (RBAC). Instead of assigning permissions to individual users, you define roles (e.g., “SupportAgent,” “BillingAdmin,” “ReadOnlyAnalyst”) and grant specific, granular permissions to those roles. An employee is then assigned a role that maps directly to their responsibilities.
Implementing RBAC involves trade-offs. While it enhances security, designing and maintaining a granular role hierarchy requires ongoing effort. However, the risk of a single compromised account with sweeping system access is too high to ignore.
For a deeper analysis of integrating these principles from inception, explore the concepts of Privacy by Design in our dedicated article. Choosing the right architectural patterns is a critical first step toward building systems that are secure by default.
Handling PII in AI and Large Language Models
The introduction of AI, particularly Large Language Models (LLMs), fundamentally alters the challenges of handling personal information. The problem is that traditional data management paradigms do not apply. In a conventional database, PII is stored in predictable fields and can be queried or deleted directly. With AI models, sensitive data can become embedded within the model’s parameters in non-obvious and uncontrollable ways.
LLMs are trained on massive datasets. If this training data contains PII—even inadvertently—the model may “memorize” it. A seemingly innocuous user query could then trigger the model to output a name, email address, or other private detail it was never intended to retain. This risk of “data regurgitation” is a primary concern.
The Unique Risks of AI Systems
Traditional security focuses on protecting data stores. With AI, the attack surface expands to include the model’s inputs, its outputs, and its internal data representations.
- Model Memorisation: Models can memorize and recall PII from their training data, creating a latent risk that can manifest long after deployment.
- Prompt Injection Attacks: A malicious actor can craft a prompt that tricks the model into bypassing its safety protocols, potentially revealing sensitive information from its training data or the current conversation.
- Data Inference: AI models excel at pattern recognition. They can infer PII from a series of non-sensitive inputs, creating new privacy risks from seemingly anonymous user activity.
A naive approach of integrating an LLM as just another API exposes an organization to significant compliance penalties and reputational damage. Privacy in AI must be an architectural decision from day one, not a feature added as an afterthought.
Mitigation Strategies for AI and LLMs
Protecting PII in AI systems requires a layered defense that covers data at every stage of the model lifecycle. The legal landscape is also evolving rapidly. For example, the 2025 updates to COPPA are expanding the definition of PII to include biometrics and government IDs. This forces a re-evaluation of how software handles children’s data, with states like New York introducing their own age-appropriate design laws. For AI-powered tools that profile minors, such as educational apps, this triggers strict new consent and transparency requirements.
Practical Controls for Implementation
Building secure AI systems requires a shift from reactive measures to proactive governance, encompassing both technical and procedural controls.
Technical Guardrails
- PII Redaction in Prompts: Before user input reaches the model, it should be processed by a PII detection and redaction service to strip out sensitive information.
- Input/Output Filtering: Implement guardrails that scan both user inputs and model outputs for PII. If sensitive data is detected, the request or response should be blocked.
- Synthetic Data for Fine-Tuning: When fine-tuning a model, use high-quality synthetic data that mimics the structure and patterns of real data but contains no actual PII.
Procedural Controls
- Human-in-the-Loop (HITL) Workflows: For high-stakes processes involving sensitive PII, an AI’s output should never be the final decision. A human must review and approve it.
- Secure Handling of Embeddings: Be aware that embeddings—the numerical vector representations of data—can implicitly encode PII. Although not human-readable, they could potentially be used to reconstruct sensitive information. Treat embeddings with the same security level as raw PII.
Proactive AI governance is a necessity. A structured framework is essential for identifying and managing these risks. You can start by using our free AI Risk & Privacy Checklist to assess your systems.
Putting PII Governance Into Practice: An Actionable Checklist
Translating privacy principles into engineering practice requires a structured, repeatable process. This checklist is a pragmatic tool for technical and product teams, designed to audit and strengthen personal data handling procedures. It serves as an operational guide to drive tangible improvements and build systems that are secure and trustworthy by design.
This checklist is structured to cover the entire data lifecycle, from discovery to incident response, providing concrete questions to guide implementation.
PII Governance and Implementation Checklist
| Domain | Checklist Item | Key Action/Question |
|---|---|---|
| Data Discovery & Classification | PII Inventory | Do we maintain a comprehensive, up-to-date data map of all PII and SPII across all systems, including databases, logs, and third-party services? |
| Data Justification | Can we justify every piece of PII we collect with a specific, documented business purpose? If not, can we eliminate it? | |
| Architectural & Security Review | Secure Data Flows | Can we trace the entire lifecycle of PII from ingestion to deletion? Is every touchpoint secured with end-to-end encryption? |
| Access Controls | Are we strictly enforcing the Principle of Least Privilege using Role-Based Access Controls (RBAC)? | |
| PII Isolation | For high-risk data (e.g., financial, health), are we using architectural patterns like the Vault model to segregate it? | |
| Development Lifecycle | Privacy in Code Review | Do our pull request templates include a checklist for PII handling? Are engineers trained to identify and mitigate privacy risks? |
| Secure Defaults | Are our development and staging environments using realistic but fully anonymised or synthetic data instead of production PII? | |
| Incident Response & Maintenance | Tested Response Plan | Do we have a specific, rehearsed incident response plan for PII breaches, including regulatory notifications within 72 hours as required by GDPR? |
| Automated Retention | Are data retention policies automated? Do we have scripts that ensure PII is securely and permanently deleted according to a defined schedule? |
This checklist is not a one-time task but a framework for continuous privacy vigilance. By embedding these checks into architecture reviews, development cycles, and operational planning, you can shift from a reactive compliance posture to a proactive, engineering-driven approach to data protection.
PII in Practice: Common Questions Answered
The theoretical aspects of PII quickly become practical, high-stakes questions during system development. Here are answers to common queries from CTOs, engineers, and product leaders.
Is an IP Address Considered PII?
Yes. Under regulations like GDPR, an IP address is considered personal data. While it may not directly reveal an individual’s name, it is a quasi-identifier that can be used to single out a specific device and, by extension, the person using it.
Architecturally, this means IP addresses must be handled with the same care as emails or phone numbers. They should be properly logged, secured, and managed according to data retention policies. This is a non-negotiable requirement for modern system design.
How Does Data Anonymisation Differ from Pseudonymisation?
Understanding this distinction is critical for system design, as the two concepts have vastly different technical and legal implications.
Anonymisation is the process of irreversibly removing or altering PII so that an individual can no longer be re-identified. It is the data equivalent of destroying the original records.
Pseudonymisation, in contrast, replaces direct identifiers with a reversible token or alias. The original identifying data is stored separately and securely, allowing for re-identification only with access to the specific key.
We often recommend pseudonymisation for internal analytics and data processing. It preserves the utility of the data for analysis while dramatically reducing the immediate risk of exposure. True anonymisation is far more difficult to achieve and often destroys the data’s analytical value.
Can We Store PII in Application Logs?
Storing raw PII in application logs is a significant security risk and a common source of data leaks. Logs are often less secure than production databases, are frequently replicated across multiple systems, and can be inadvertently exposed through misconfigurations.
Your architecture should enforce a strict policy of filtering or masking PII before it is written to a log file. For debugging, use non-sensitive correlation IDs. These IDs allow you to trace a user’s activity without exposing sensitive data. If necessary, they can be linked back to a user within a secure, access-controlled system. This is a direct application of the principle of least privilege and prevents the proliferation of sensitive data across your infrastructure.
At Devisia, we believe that robust privacy is an architectural choice, not a last-minute feature. We build reliable digital products and AI-enabled systems with security and maintainability at their core. Learn how we can help you build your vision with confidence.