
Per i leader tecnici, le Informazioni Personali Identificabili (PII) non sono soltanto un termine di conformità; sono una classificazione critica dei dati che determina l’architettura del sistema, i protocolli di sicurezza e le procedure di gestione dei dati. La cattiva gestione delle PII introduce un significativo debito tecnico, vulnerabilità di sicurezza e rischio normativo.
Cosa significano le PII per l’architettura del sistema
Il problema fondamentale è che trattare le PII come una semplice casella di controllo legale porta a una progettazione del sistema difettosa. Nell’ingegneria del software, le PII sono un flag tecnico che indica che sono necessari controlli specifici e non negoziabili. Un approccio ingenuo—non distinguere tra diversi tipi di PII—genera sistemi che sono o insicuri o inutilmente complessi.
Gestire male le PII porta a rigidità architettonica, danni reputazionali e sanzioni significative. Un approccio pragmatico prevede di mappare i dati non solo in base alla loro funzione, ma anche in base alla loro capacità di identificare una persona—direttamente o quando combinati con altri punti dati.
Questo va oltre le semplici definizioni. Il nome completo di un utente è ovviamente PII. La sfida più complessa consiste nel gestire gruppi di dati apparentemente anonimi—come CAP, data di nascita e genere—che possono essere aggregati per re-identificare una persona con un’elevata accuratezza. Questo concetto di “rischio di re-identificazione” è centrale nell’ingegneria moderna della privacy dei dati.
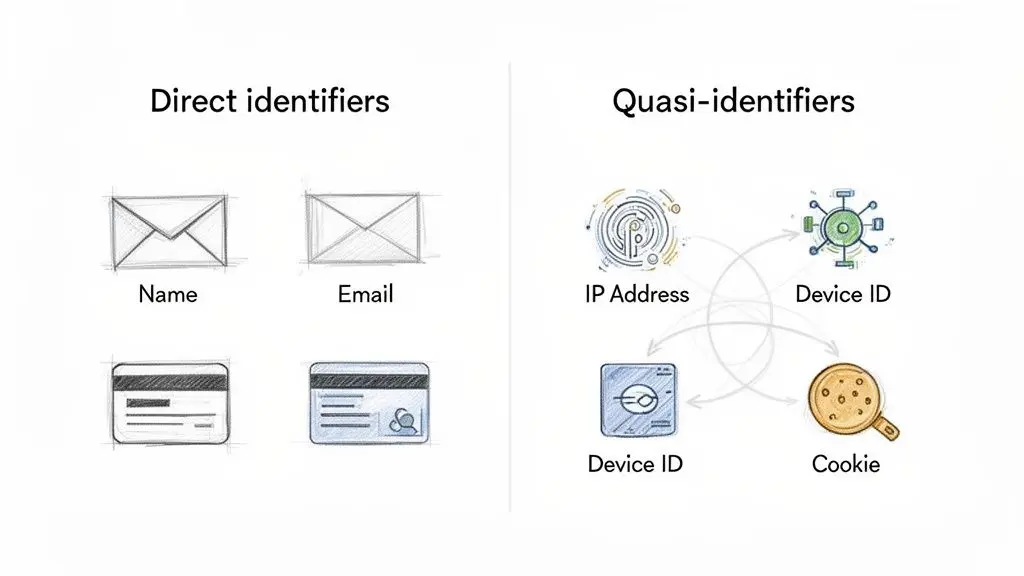
Identificatori diretti vs. quasi-identificatori
Per costruire sistemi sicuri, le PII devono essere classificate in due categorie pratiche. Questa distinzione guida direttamente le decisioni architetturali, ad esempio se i dati richiedono crittografia, pseudonimizzazione o isolamento in un ambiente altamente ristretto.
- Identificatori diretti: Dati che individuano senza ambiguità una singola persona. Questa è la categoria più sensibile e richiede il massimo livello di protezione, come la crittografia dei dati a riposo e in transito, oltre a controlli di accesso rigorosi. Esempi includono nomi completi, indirizzi email e numeri di documenti governativi.
- Quasi-identificatori (identificatori indiretti): Punti dati che non sono univoci da soli ma possono essere combinati per identificare una persona. Un indirizzo IP, un ID dispositivo o una posizione geografica generica sono esempi comuni presenti nei log delle applicazioni e nei sistemi di analytics.
Questo diagramma illustra la distinzione fondamentale.

Sebbene gli identificatori diretti rappresentino un rischio evidente, la sfida architetturale più sottile deriva dalla gestione dell’accumulo di quasi-identificatori nei sistemi distribuiti.
Framework di classificazione delle PII per i team di ingegneria
Questa tabella fornisce un framework pratico per la mappatura dei dati e gli audit di sicurezza. Suddivide i tipi di PII, le loro posizioni comuni in uno stack software tipico e i relativi livelli di rischio.
| Categoria PII | Esempi | Posizioni comuni nel sistema | Livello di rischio associato |
|---|---|---|---|
| Identificatori diretti | Nome completo, indirizzo email, numero di previdenza sociale, numero di patente | Profili utente, servizi di autenticazione, tabelle di fatturazione, log dell’assistenza clienti | Alto |
| Quasi-identificatori | Data di nascita, CAP, genere, indirizzo IP, ID dispositivo, titolo professionale | Eventi di analytics, file di log, sistemi di marketing automation, tabelle delle preferenze utente | Medio (Alto se combinato) |
| PII sensibili (SPII) | Dati sanitari, dati biometrici, origine razziale o etnica, convinzioni religiose, orientamento sessuale | Funzionalità specializzate (ad es. monitoraggio della salute), documenti caricati dagli utenti, sistemi HR | Critico |
| Identificatori collegati | ID utente, ID sessione, ID ordine | Quasi ogni tabella nel database, log delle applicazioni, metadati delle richieste API | Basso (Alto se collegato ad altre PII) |
Questo framework dovrebbe essere trattato come un documento vivo. Man mano che si sviluppano nuove funzionalità o si integrano servizi di terze parti, la mappa dei dati e le corrispondenti classificazioni PII devono essere aggiornate.
Informazioni Personali Identificabili Sensibili (SPII)
Un sottoinsieme delle PII, le Informazioni Personali Identificabili Sensibili (SPII), comporta un livello di rischio critico. La loro esposizione potrebbe causare danni diretti, discriminazione o disagio personale. Normative come il GDPR impongono requisiti di trattamento significativamente più severi per questa categoria di dati.
Le SPII sono qualsiasi informazione che, se smarrita o compromessa, potrebbe causare un danno significativo o un’ingiustizia nei confronti di una persona. Ciò include dati che rivelano l’origine razziale o etnica, opinioni politiche, convinzioni religiose, dati sanitari o informazioni riguardanti la vita sessuale o l’orientamento sessuale di una persona.
Il nome di un utente è PII; la sua diagnosi medica è SPII. Questa distinzione ha conseguenze architetturali immediate. La memorizzazione di SPII può richiedere database separati e isolati (un’architettura “vault”), crittografia end-to-end con chiavi gestite dal cliente e meccanismi espliciti e granulari di consenso dell’utente. Non distinguere tra PII generali e SPII nella progettazione del sistema è una svista comune e costosa. L’obiettivo è una mappa dei dati chiara in cui ogni campo sia classificato e i relativi protocolli di gestione siano dettati dal suo livello di rischio.
Come le normative sulla privacy plasmano l’architettura del sistema
La conformità è un driver architettonico fondamentale, non una casella di controllo legale. Normative come il GDPR in Europa e il CCPA in California non sono testi legali astratti; sono mandate tecnici che influenzano direttamente il modo in cui il software viene progettato, costruito e mantenuto. Ignorarle introduce un debito tecnico che diventa esponenzialmente più costoso da risolvere nel tempo.
Il problema di trattare la privacy come un ripensamento—qualcosa da “aggiungere” prima del rilascio—è che non affronta i difetti di progettazione fondamentali. Un banner di consenso inserito all’ultimo minuto non corregge un modello di dati insicuro. La vera conformità si ottiene attraverso il Privacy by Design, in cui la protezione dei dati è integrata nella logica centrale del sistema fin dall’inizio.
Tradurre i principi legali in pratiche di ingegneria
I principi normativi chiave devono essere tradotti in requisiti ingegneristici concreti. Due dei più critici sono la minimizzazione dei dati e la limitazione della finalità. Questi principi dovrebbero guidare ogni decisione architetturale, dalla progettazione dello schema del database ai contratti API.
- Minimizzazione dei dati: Raccogliere ed elaborare solo i dati personali assolutamente necessari per una finalità specifica. In pratica, ogni campo in una tabella utente deve avere una giustificazione chiara e documentata. Raccogliere la data di nascita di un utente “per sicurezza” viola questo principio e crea rischi inutili.
- Limitazione della finalità: Elaborare i dati solo per le finalità specifiche ed esplicite per le quali sono stati raccolti. Dal punto di vista architetturale, ciò significa che i dati raccolti per la fatturazione dovrebbero essere separati logicamente, e spesso fisicamente, dai dati utilizzati per l’analisi di marketing.
Adottare questi principi significa chiedersi, “Abbiamo davvero bisogno di questi dati?” in ogni fase dello sviluppo. Questa singola domanda può prevenire una significativa complessità architetturale e violazioni della conformità.
Affrontare le complessità delle normative globali
Il frammentato panorama normativo globale presenta una sfida significativa. La definizione di informazioni personali identificabili e i requisiti di consenso variano notevolmente tra le giurisdizioni. Ciò che è una prassi standard in una regione può essere illegale in un’altra.
Ad esempio, il GDPR fornisce una definizione ampia di dati personali e impone un consenso esplicito e granulare. Nel frattempo, diversi stati degli Stati Uniti stanno creando un mosaico di leggi con definizioni proprie e uniche di PII “sensibili” e diritti dei consumatori. Questa crescente complessità ha conseguenze concrete per i leader IT. Secondo analisi recenti, entro il 2026, il 70% dei professionisti IT considererà le policy sulla privacy dei dati un fattore critico nella valutazione dei fornitori tecnologici. Ciò riflette un’aspettativa di base per il privacy-by-design, poiché le leggi sulla privacy multi-stato spingono ad abbandonare gli approcci incentrati sul CCPA. I team IT devono ora allineare la classificazione dei dati alle diverse definizioni statali di PII sensibili, come i framework sui dati sanitari di Washington e Nevada. Puoi trovare una analisi dettagliata su come la privacy dei dati si sta evolvendo da Founders Legal.
Costruire sistemi geograficamente consapevoli e scalabili
Per operare a livello globale, l’architettura del sistema deve essere flessibile e consapevole del contesto geografico. Un sistema monolitico con una politica unica e valida per tutti sulla gestione dei dati non è più sostenibile. La soluzione è un modello di governance dei dati in grado di adattarsi a diversi requisiti legali senza frammentare l’architettura principale.
Ciò richiede spesso l’implementazione di funzionalità come:
- Archiviare i dati degli utenti in specifiche regioni geografiche per rispettare le leggi sulla residenza dei dati.
- Implementare meccanismi di consenso dinamico che presentino opzioni diverse in base alla posizione dell’utente.
- Progettare API che possano applicare regole di accesso ai dati diverse a seconda della giurisdizione.
Costruire queste funzionalità fin dall’inizio è molto più efficiente che adattare in seguito un sistema legacy. Trattando la privacy come componente fondamentale, crei un sistema scalabile e manutenibile, pronto per un contesto normativo in continua evoluzione. Per indicazioni specifiche, puoi leggere la nostra guida dettagliata sull’Articolo 30 del GDPR e le sue implicazioni per i registri delle attività di trattamento dei dati.
Rischi comuni di esposizione delle PII e scenari di attacco
Identificare le PII è il primo passo; comprenderne le vulnerabilità è il successivo. L’esposizione delle PII raramente è un singolo evento, ma piuttosto il risultato di debolezze sistemiche che gli avversari sanno sfruttare abilmente. Per costruire sistemi resilienti, è necessario adottare una mentalità avversaria e identificare proattivamente questi punti di fallimento. I rischi più significativi spesso non sono exploit zero-day esotici, ma difetti architetturali comuni e non affrontati che possono trasformare una semplice configurazione errata in una grave violazione dei dati.
Punti di fallimento tecnici
Gli attaccanti prendono spesso di mira punti deboli prevedibili nella progettazione delle applicazioni e dell’infrastruttura. Queste vulnerabilità tecniche sono spesso occasioni facili, che forniscono un percorso diretto verso i dati sensibili.
- Endpoint API insicuri: Un difetto comune è un’API che restituisce più dati di quanti ne richieda il frontend. Per esempio, un endpoint
/user/profilepotrebbe inviare all’interfaccia utente il nome dell’utente, ma il payload JSON completo include anche l’email, la data di registrazione e l’ultimo indirizzo IP noto. Questi dati superflui sono visibili a chiunque monitori il traffico di rete. - Archiviazione cloud configurata in modo errato: I bucket di storage cloud accessibili pubblicamente sono una delle principali cause di gravi fughe di dati. Uno sviluppatore potrebbe disattivare temporaneamente i controlli di accesso su un bucket per test e dimenticare di riattivarli, lasciando esposti backup contenenti migliaia di record utente.
- SQL Injection: Una minaccia vecchia ma persistente, la SQL injection consente agli aggressori di aggirare la logica dell’applicazione e interagire direttamente con il database. Un modulo di ricerca vulnerabile potrebbe permettere a un aggressore di inserire comandi SQL personalizzati ed esfiltrare l’intera tabella
users. - Dati trascurati nei log e nelle cache: Le PII spesso trapelano in sistemi in cui non era mai previsto che venissero memorizzate. I log delle applicazioni potrebbero catturare involontariamente richieste API complete contenenti dati sensibili nei parametri di query. Una Content Delivery Network (CDN) potrebbe memorizzare nella cache una pagina personalizzata contenente l’indirizzo di un utente e servirla ad altri utenti.
L’elemento umano nelle violazioni dei dati personali
I controlli tecnici da soli sono insufficienti perché gli esseri umani sono parte integrante di qualsiasi sistema. L’ingegneria sociale è spesso più semplice che penetrare infrastrutture rafforzate. Questo “elemento umano” deve essere una componente centrale di qualsiasi modello di minaccia realistico.
Le minacce interne—che siano malevole o accidentali—rappresentano un rischio significativo. Un dipendente scontento con accesso al database potrebbe esfiltrare un elenco clienti. Allo stesso tempo, un addetto al supporto ben intenzionato ma non formato potrebbe essere manipolato da un attacco di social engineering fino a reimpostare la password di un account per un impostore.
Una postura di sicurezza efficace va oltre firewall e crittografia. Richiede di riconoscere che la tua più grande vulnerabilità potrebbe essere un dipendente che cade vittima di una sofisticata email di phishing.
Questa realtà sta guidando il cambiamento. Le informazioni personali identificabili sono diventate un obiettivo primario nel settore IT. Entro il 2026, si prevede che il 72% delle aziende IT e legali avrà in atto una politica formale di sicurezza dei dati. Questo cambiamento evidenzia una crescente consapevolezza del fatto che i dati personali identificabili non esistono solo nei database, ma anche in file non strutturati, piattaforme cloud e strumenti SaaS, dove il tracciamento manuale è impraticabile. Puoi saperne di più su queste tendenze della privacy dei dati nei settori legale e IT.
In definitiva, un modello di minaccia pragmatico richiede di mappare sia i vettori di attacco tecnici sia quelli umani. Comprendendo come un attaccante vede il tuo sistema—da una API vulnerabile a un dipendente persuadibile—puoi concentrare gli sforzi di sicurezza dove avranno il maggiore impatto, costruendo una difesa a più livelli, resiliente e realistica.
Pattern architetturali per la salvaguardia dei dati personali identificabili
Comprendere i rischi è necessario, ma l’obiettivo è costruire sistemi in grado di resistervi. Ciò richiede di passare dai problemi alle soluzioni adottando pattern architetturali robusti progettati per proteggere le informazioni personali fin dalle fondamenta. Non si tratta di funzionalità da aggiungere in seguito; sono scelte fondamentali che determinano come i dati si muovono, chi può accedervi e come vengono protetti a ogni livello dello stack.
Una protezione efficace dei dati personali identificabili inizia con l’assunzione che prima o poi si verificherà una violazione. Questa mentalità impone l’implementazione di difese a più livelli, garantendo che, se un componente viene compromesso, i dati più sensibili restino al sicuro. I pattern seguenti sono strategie pratiche e collaudate sul campo per costruire tali livelli.
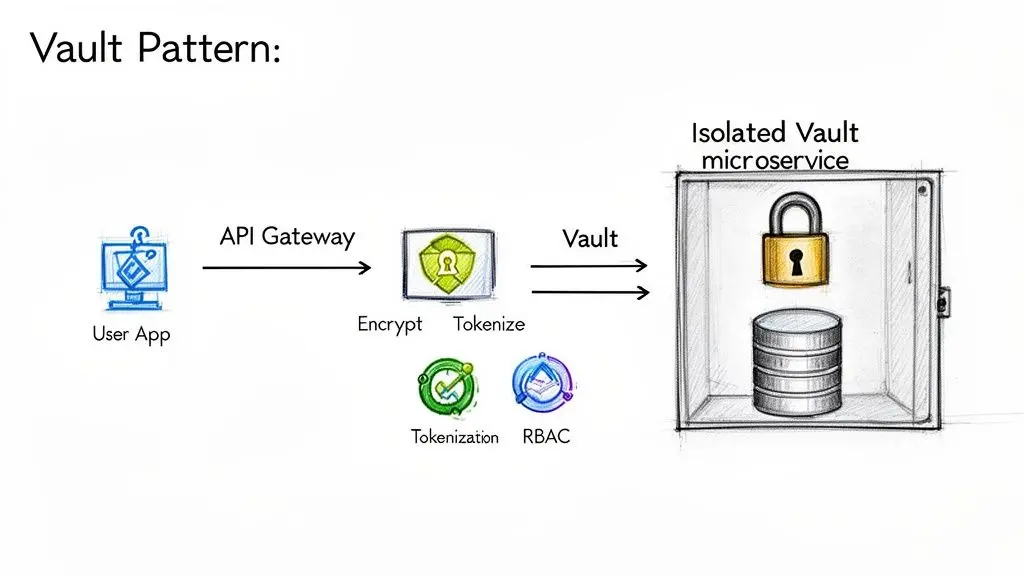
Il pattern Vault: isolare ciò che conta di più
Uno dei modelli architetturali più efficaci per proteggere i dati personali identificabili è il pattern Vault. Il concetto consiste nell’isolamento fisico e logico dei dati personali dal resto dell’applicazione. Invece di consentire che le informazioni degli utenti si diffondano tra più microservizi e database, vengono centralizzate in un unico servizio altamente protetto: il vault.
Questo servizio vault espone un’API estremamente ridotta e strettamente controllata. Tutti gli altri servizi che devono interagire con i dati personali identificabili devono passare attraverso un gateway API sicuro che applica autenticazione e autorizzazione. Questo design riduce drasticamente la superficie di attacco.
I componenti chiave del pattern Vault includono:
- Microservizio isolato: Un servizio dedicato con la sola responsabilità di archiviare e gestire i dati personali identificabili. Ha un proprio database, inaccessibile a qualsiasi altro servizio.
- Gateway API rigoroso: Tutte le richieste al vault vengono instradate attraverso un gateway che gestisce autenticazione, autorizzazione e logging completo.
- Tokenizzazione: Invece di trasmettere dati personali identificabili grezzi tra i servizi, il vault emette un token non sensibile (ad es. un UUID) che rappresenta l’utente. Gli altri servizi utilizzano questo token per svolgere le proprie funzioni senza mai trattare i dati personali identificabili effettivi.
Il pattern Vault trasforma una sfida distribuita di protezione dei dati personali identificabili in un problema centralizzato e gestibile. Invece di mettere in sicurezza dieci servizi diversi che trattano dati personali identificabili, proteggi un solo vault e i suoi punti di accesso strettamente controllati.
Implementare la crittografia end-to-end
La crittografia è un livello di difesa non negoziabile. Un errore comune è crittografare solo i dati a riposo. Una strategia robusta implementa la crittografia end-to-end, proteggendo i dati indipendentemente dalla loro posizione o stato.
Questo significa proteggere i dati in tre stati distinti:
- Dati in transito: Usa protocolli TLS forti (TLS 1.2 o superiore) per tutte le comunicazioni tra servizi, API e client, al fine di impedire l’intercettazione dei dati durante il transito sulle reti.
- Dati a riposo: Crittografa i dati archiviati in database, object storage e backup. La maggior parte dei provider cloud offre servizi di crittografia gestita che semplificano questo processo.
- Dati in uso: Questo è lo stato più difficile da proteggere, poiché i dati devono essere decrittografati per l’elaborazione, creando una breve finestra di vulnerabilità. Tecniche emergenti come il confidential computing utilizzano enclave sicure per elaborare i dati mentre rimangono crittografati, anche se introducono una complessità significativa.
Controllo degli accessi basato sui ruoli e principio del minimo privilegio
La tecnologia da sola non può risolvere i rischi legati agli esseri umani. Una forte Identity and Access Management (IAM) è essenziale. Il principio guida è il Principio del minimo privilegio: qualsiasi utente, servizio o sistema dovrebbe avere i permessi minimi necessari per svolgere la propria funzione e nessuno in più.
Questo viene implementato tramite il Controllo degli accessi basato sui ruoli (RBAC). Invece di assegnare permessi ai singoli utenti, si definiscono ruoli (ad es. “SupportAgent”, “BillingAdmin”, “ReadOnlyAnalyst”) e si concedono a tali ruoli permessi specifici e granulari. A ciascun dipendente viene quindi assegnato un ruolo che corrisponde direttamente alle sue responsabilità.
L’implementazione dell’RBAC comporta dei compromessi. Pur migliorando la sicurezza, progettare e mantenere una gerarchia di ruoli granulare richiede un impegno continuo. Tuttavia, il rischio che un singolo account compromesso ottenga un accesso esteso al sistema è troppo alto per essere ignorato.
Per un’analisi più approfondita dell’integrazione di questi principi fin dall’inizio, esplora i concetti di Privacy by Design nel nostro articolo dedicato. Scegliere i pattern architetturali giusti è un primo passo critico per costruire sistemi sicuri di default.
Gestire i dati personali identificabili nell’AI e nei modelli linguistici di grandi dimensioni
L’introduzione dell’AI, in particolare dei Large Language Models (LLM), altera in modo fondamentale le sfide legate alla gestione delle informazioni personali. Il problema è che i paradigmi tradizionali di gestione dei dati non si applicano. In un database convenzionale, i dati personali identificabili sono archiviati in campi prevedibili e possono essere interrogati o eliminati direttamente. Con i modelli AI, i dati sensibili possono diventare incorporati nei parametri del modello in modi non ovvi e incontrollabili.
Gli LLM vengono addestrati su dataset enormi. Se questi dati di training contengono dati personali identificabili—anche involontariamente—il modello potrebbe “memorizzarli”. Una query utente apparentemente innocua potrebbe quindi attivare il modello a restituire un nome, un indirizzo email o altri dettagli privati che non avrebbe mai dovuto conservare. Questo rischio di “rigurgito dei dati” è una delle principali preoccupazioni.
I rischi unici dei sistemi AI
La sicurezza tradizionale si concentra sulla protezione degli archivi dati. Con l’AI, la superficie di attacco si espande includendo gli input del modello, gli output e le sue rappresentazioni interne dei dati.
- Memorizzazione del modello: I modelli possono memorizzare e richiamare dati personali identificabili dai dati di training, creando un rischio latente che può manifestarsi anche molto tempo dopo il deployment.
- Attacchi di prompt injection: Un attore malevolo può costruire un prompt che induce il modello a bypassare i propri protocolli di sicurezza, rivelando potenzialmente informazioni sensibili dai dati di training o dalla conversazione in corso.
- Inferenza dei dati: I modelli AI eccellono nel riconoscimento di schemi. Possono inferire dati personali identificabili da una serie di input non sensibili, creando nuovi rischi per la privacy a partire da attività utente apparentemente anonime.
Un approccio ingenuo che integri un LLM come se fosse un’API qualsiasi espone un’organizzazione a sanzioni significative per mancata conformità e a danni reputazionali. La privacy nell’AI deve essere una decisione architetturale fin dal primo giorno, non una funzionalità aggiunta in un secondo momento.
Strategie di mitigazione per AI e LLM
Proteggere i dati personali identificabili nei sistemi AI richiede una difesa a più livelli che copra i dati in ogni fase del ciclo di vita del modello. Anche il panorama normativo sta evolvendo rapidamente. Ad esempio, gli aggiornamenti 2025 al COPPA stanno ampliando la definizione di dati personali identificabili per includere biometria e documenti di identità governativi. Questo impone una rivalutazione di come il software gestisce i dati dei bambini, con stati come New York che introducono proprie leggi sul design appropriato all’età. Per strumenti basati su AI che profilano i minori, come le app educative, ciò attiva nuovi requisiti rigorosi di consenso e trasparenza.
Controlli pratici per l’implementazione
Costruire sistemi AI sicuri richiede un passaggio da misure reattive a una governance proattiva, che comprenda sia controlli tecnici sia procedurali.
Salvaguardie tecniche
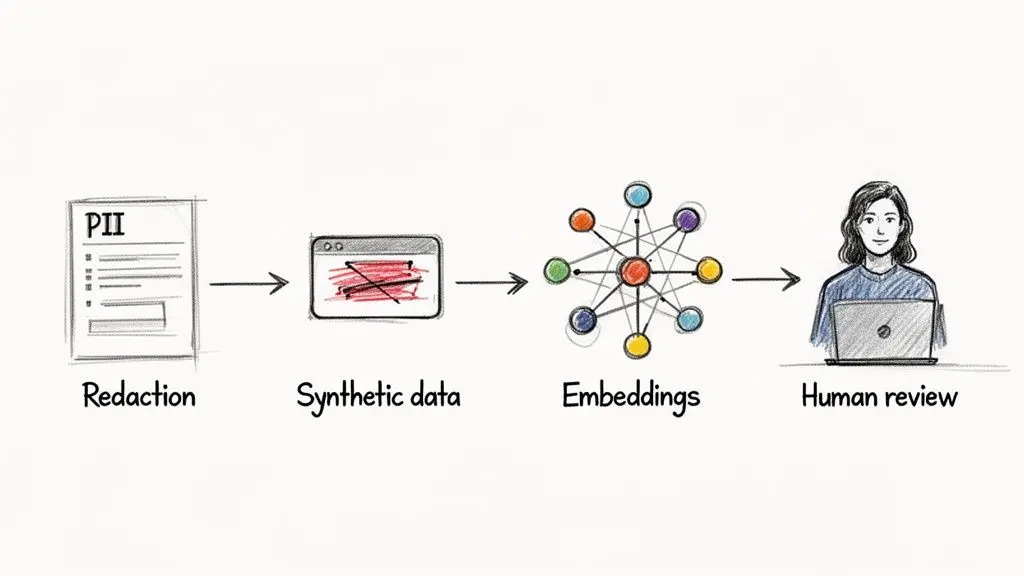
- Redazione dei dati personali identificabili nei prompt: Prima che l’input dell’utente raggiunga il modello, dovrebbe essere elaborato da un servizio di rilevamento e redazione dei dati personali identificabili per rimuovere le informazioni sensibili.
- Filtraggio di input/output: Implementa salvaguardie che analizzino sia gli input degli utenti sia gli output del modello alla ricerca di dati personali identificabili. Se vengono rilevati dati sensibili, la richiesta o la risposta dovrebbe essere bloccata.
- Dati sintetici per il fine-tuning: Quando si esegue il fine-tuning di un modello, utilizza dati sintetici di alta qualità che imitino la struttura e i modelli dei dati reali ma non contengano alcun dato personale identificabile effettivo.
Controlli procedurali
- Workflow human-in-the-loop (HITL): Per processi ad alto impatto che coinvolgono dati personali identificabili sensibili, l’output di un’AI non dovrebbe mai essere la decisione finale. Deve essere rivisto e approvato da una persona.
- Gestione sicura degli embedding: Tieni presente che gli embedding—le rappresentazioni vettoriali numeriche dei dati—possono codificare implicitamente dati personali identificabili. Sebbene non siano leggibili dall’uomo, potrebbero potenzialmente essere usati per ricostruire informazioni sensibili. Tratta gli embedding con lo stesso livello di sicurezza dei dati personali identificabili grezzi.
Una governance proattiva dell’AI è una necessità. Un framework strutturato è essenziale per identificare e gestire questi rischi. Puoi iniziare utilizzando la nostra gratuita AI Risk & Privacy Checklist per valutare i tuoi sistemi.
Mettere in pratica la governance dei dati personali identificabili: una checklist operativa
Tradurre i principi di privacy in pratica ingegneristica richiede un processo strutturato e ripetibile. Questa checklist è uno strumento pragmatico per team tecnici e di prodotto, progettato per verificare e rafforzare le procedure di gestione dei dati personali. Funziona come guida operativa per promuovere miglioramenti concreti e costruire sistemi sicuri e affidabili by design.
Questa checklist è strutturata per coprire l’intero ciclo di vita dei dati, dalla discovery alla risposta agli incidenti, fornendo domande concrete per guidare l’implementazione.
Checklist di governance e implementazione dei dati personali identificabili
| Dominio | Voce della checklist | Azione/domanda chiave |
|---|---|---|
| Scoperta e classificazione dei dati | Inventario dei dati personali identificabili | Manteniamo una mappa completa e aggiornata di tutti i dati personali identificabili e SPII in tutti i sistemi, inclusi database, log e servizi di terze parti? |
| Giustificazione dei dati | Possiamo giustificare ogni dato personale identificabile che raccogliamo con una specifica finalità aziendale documentata? In caso contrario, possiamo eliminarlo? | |
| Revisione architetturale e di sicurezza | Flussi di dati sicuri | Possiamo tracciare l’intero ciclo di vita dei dati personali identificabili dall’ingestione alla cancellazione? Ogni punto di contatto è protetto con crittografia end-to-end? |
| Controlli di accesso | Stiamo applicando rigorosamente il Principio del Minimo Privilegio usando i Controlli di Accesso Basati sui Ruoli (RBAC)? | |
| Isolamento dei dati personali | Per i dati ad alto rischio (ad es. finanziari, sanitari), stiamo usando modelli architetturali come il Vault model per isolarli? | |
| Ciclo di sviluppo | Privacy nella revisione del codice | I nostri template di pull request includono una checklist per la gestione dei dati personali (PII)? Gli ingegneri sono formati per identificare e mitigare i rischi per la privacy? |
| Impostazioni predefinite sicure | I nostri ambienti di sviluppo e staging utilizzano dati realistici ma completamente anonimizzati o sintetici invece dei dati personali di produzione? | |
| Risposta agli incidenti e manutenzione | Piano di risposta testato | Disponiamo di un piano specifico e collaudato di risposta agli incidenti per le violazioni dei dati personali (PII), incluse le notifiche alle autorità di regolamentazione entro 72 ore come richiesto dal GDPR? |
| Conservazione automatizzata | Le policy di conservazione dei dati sono automatizzate? Abbiamo script che garantiscono che i dati personali (PII) vengano eliminati in modo sicuro e permanente secondo una pianificazione definita? |
Questa checklist non è un’attività una tantum, ma un framework per una vigilanza continua sulla privacy. Incorporando questi controlli nelle revisioni dell’architettura, nei cicli di sviluppo e nella pianificazione operativa, potete passare da un approccio alla conformità reattivo a un approccio proattivo, guidato dall’ingegneria, alla protezione dei dati.
PII nella pratica: risposte alle domande comuni
Gli aspetti teorici dei dati personali (PII) diventano rapidamente domande pratiche ad alta criticità durante lo sviluppo dei sistemi. Ecco le risposte alle domande più comuni di CTO, ingegneri e responsabili di prodotto.
Un indirizzo IP è considerato PII?
Sì. In base a normative come il GDPR, un indirizzo IP è considerato dato personale. Sebbene possa non rivelare direttamente il nome di una persona, è un quasi-identificatore che può essere usato per individuare un dispositivo specifico e, di conseguenza, la persona che lo utilizza.
Dal punto di vista architetturale, questo significa che gli indirizzi IP devono essere gestiti con la stessa attenzione di email o numeri di telefono. Devono essere registrati, protetti e gestiti correttamente secondo le policy di conservazione dei dati. Si tratta di un requisito non negoziabile per la progettazione di sistemi moderni.
In che modo l’anonimizzazione dei dati differisce dalla pseudonimizzazione?
Comprendere questa distinzione è fondamentale per la progettazione dei sistemi, poiché i due concetti hanno implicazioni tecniche e legali profondamente diverse.
Anonimizzazione è il processo di rimozione o modifica irreversibile dei dati personali in modo che un individuo non possa più essere reidentificato. È l’equivalente, per i dati, della distruzione dei record originali.
Pseudonimizzazione, al contrario, sostituisce gli identificatori diretti con un token o un alias reversibile. I dati identificativi originali vengono archiviati separatamente e in modo sicuro, consentendo la reidentificazione solo con l’accesso alla chiave specifica.
Raccomandiamo spesso la pseudonimizzazione per l’analisi interna e l’elaborazione dei dati. Preserva l’utilità dei dati per l’analisi riducendo drasticamente il rischio immediato di esposizione. La vera anonimizzazione è molto più difficile da ottenere e spesso distrugge il valore analitico dei dati.
Possiamo memorizzare dati personali (PII) nei log dell’applicazione?
Memorizzare dati personali grezzi nei log dell’applicazione è un rischio di sicurezza significativo e una fonte comune di perdite di dati. I log sono spesso meno sicuri dei database di produzione, vengono frequentemente replicati su più sistemi e possono essere esposti involontariamente tramite configurazioni errate.
La vostra architettura dovrebbe imporre una policy rigorosa di filtraggio o mascheramento dei dati personali (PII) prima che vengano scritti in un file di log. Per il debug, utilizzate ID di correlazione non sensibili. Questi ID consentono di tracciare l’attività di un utente senza esporre dati sensibili. Se necessario, possono essere collegati a un utente all’interno di un sistema sicuro con controllo degli accessi. Questa è un’applicazione diretta del principio del minimo privilegio e impedisce la proliferazione di dati sensibili nella vostra infrastruttura.
At Devisia, crediamo che una privacy solida sia una scelta architetturale, non una funzionalità dell’ultimo minuto. Realizziamo prodotti digitali affidabili e sistemi abilitati all’IA con sicurezza e manutenibilità al centro. Scoprite come possiamo aiutarvi a realizzare la vostra visione con fiducia.