
If there’s one part of GDPR that demands the attention of technology leaders, it’s Article 9. It governs what the regulation calls ‘special category data’—the most sensitive personal information a system can process.
For any software, and particularly for AI systems, mishandling this data is not merely a compliance issue; it’s a direct threat to your product’s viability and your company’s reputation.
The Problem: The High Stakes of Special Category Data
For founders, CTOs, and product leaders, understanding Article 9 isn’t a legal formality to be delegated entirely. It’s a fundamental architectural constraint. Building a system that processes this data without a clear, defensible strategy often leads to products that are non-compliant by design, forcing expensive redesigns or exposing the company to significant regulatory risk.
The core challenge is that Article 9 operates on a principle of prohibition by default. The starting point is that you are forbidden from processing this data. You can only proceed if you meet one of a handful of specific, narrowly defined conditions. This inverts the typical data processing model and imposes strict upfront obligations.
What Is Special Category Data?
Special category data is set apart because its unauthorized exposure could severely impact an individual’s fundamental rights and freedoms. It is the difference between knowing a user’s shipping address and knowing their medical diagnosis.
GDPR Art 9 provides a specific list of what constitutes special category data.
| Data Category | Definition and Software Context |
|---|---|
| Racial or ethnic origin | Data revealing a person’s background. Can be inferred in user profile analysis or diversity monitoring tools. |
| Political opinions | Information about a person’s political views. Often found in social media sentiment analysis or survey platforms. |
| Religious or philosophical beliefs | Data on an individual’s spiritual or belief system. May appear in community forums or lifestyle app questionnaires. |
| Trade union membership | Information confirming a person belongs to a trade union. Directly relevant for HR and payroll systems. |
| Genetic data | Data from DNA analysis. Used in health-tech, ancestry services, and biomedical research platforms. |
| Biometric data for identification | Data used for unique identification (e.g., fingerprints, facial scans). Common in security, authentication, and access control systems. |
| Data concerning health | Information on physical or mental health, including medical history and treatments. The core of any health-tech or wellness app. |
| Data concerning sex life or sexual orientation | Private information about an individual’s personal life. Can be inferred or collected in dating apps or social platforms. |
A naive or superficial approach presents a significant risk. For instance, a seemingly harmless HR tool that analyzes team morale could unintentionally infer health conditions or trade union sympathies, pulling the entire system under the strict purview of Article 9.
The critical takeaway for any technical leader is this: Article 9 forces you to treat certain data as highly sensitive. It must be identified, isolated, and handled with specific technical and organizational measures, backed by an explicit and legally sound justification. A “process first, ask questions later” approach is a recipe for non-compliance.
The Business Implications of Non-Compliance
Failure to comply with Article 9 extends beyond fines, which can reach up to €20 million or 4% of annual global turnover. It erodes customer trust and can render a product unsellable in the EU. A SaaS product processing health data without a valid legal basis, such as explicit consent, is fundamentally non-compliant.
This guide provides a pragmatic roadmap for engineering and product teams. We will break down how to identify this data in real-world software, explain the lawful grounds for processing it, and present architectural patterns for building compliant systems.
Identifying Special Category Data in Your Systems
Knowing the GDPR Article 9 definitions is one thing; identifying special category data within a live software environment is another. For engineers and product managers, this is not a legal abstraction. It is about recognizing high-risk data flowing through your APIs, residing in your databases, or being processed by your AI models—often without a clear “sensitive” label.
A superficial approach, assuming data isn’t “special” unless explicitly tagged, is a significant compliance risk. Your systems may be processing this information implicitly, and under GDPR, ignorance is not a defense.
Obvious Use Cases
Some applications are straightforward. When a product’s core function is built around sensitive information, identifying special category data is the easy part. The challenge lies in ensuring the entire architecture is designed to handle it from the outset.
- Data Concerning Health: A wellness app tracking stress levels, sleep patterns, or calorie intake is processing health data. An AI diagnostic tool analyzing medical images is also squarely under Article 9.
- Biometric Data for Identification: This includes the facial recognition engine for a login system or a fingerprint scanner API integrated for authentication. Any system using unique physical or behavioral traits to identify a person is processing biometric data.
- Genetic Data: A platform offering ancestry insights or a B2B service providing health reports from DNA analysis is directly handling genetic data.
The Hidden Risk of Inferred Data
The real architectural challenge arises from data that becomes special category through inference. A system might not directly ask for sensitive information but can deduce it from other, seemingly innocuous data points. This is a common blind spot for many technical teams.
An AI model analyzing user-generated content does not need a “political opinion” field to classify individuals. By processing text from forums or product reviews, it can infer a person’s political leanings, religious beliefs, or even health status.
That act of inference is processing special category data. It triggers the same strict GDPR Art 9 requirements as if you had explicitly collected the information.
Real-World Scenarios
To build robust, compliant systems, technical teams must be trained to identify these less obvious situations. Considering how data can be combined or analyzed is a critical part of privacy by design.
- A SaaS for community management: If your platform allows users to create groups, one of those might be “Local 123 Union Members.” Your system is now processing data related to trade union membership.
- An analytics feature in an e-commerce platform: An algorithm segmenting customers by purchasing habits could flag individuals buying religious texts or specific health products, potentially being seen as processing data on religious beliefs or health.
- A corporate HR platform: A tool tracking employee event attendance might reveal who participated in LGBTQ+ Pride events, thereby processing data about sexual orientation.
The objective is to foster a proactive mindset. Before processing any new dataset, ask the critical question: “Could this data, alone or combined with other information, reveal something about a person that falls under GDPR Article 9?” Making this query a standard part of your development process is a fundamental step in managing risk.
Finding a Lawful Basis for Processing
GDPR Article 9 begins with a prohibition. By default, processing any special category data is forbidden. To do so legally, you must establish a valid exception from the specific list in Article 9(2). This is a foundational decision that must be made—and documented—before your systems process this data.
Choosing an incorrect legal basis can invalidate your entire processing activity, rendering your system non-compliant by design. For most software and AI systems, only a few conditions are relevant, and each imposes significant technical and organizational requirements.
The first step is always classification. Are you even handling special category data? This flowchart helps clarify that initial, critical decision point.
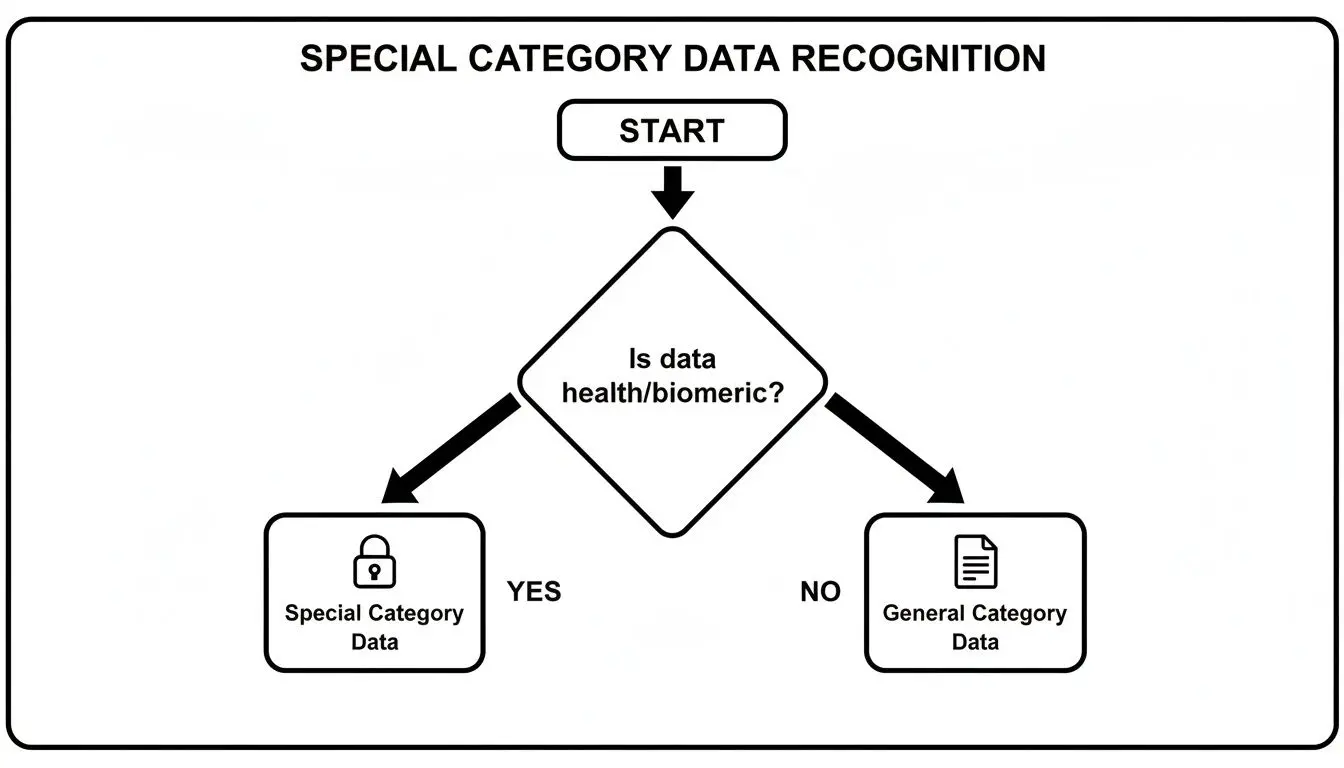
Once data crosses that ‘special’ threshold, the obligation is to find and document a specific, valid condition under Article 9 to process it.
The Standard: Explicit Consent
For most commercial software, the most reliable and defensible condition is explicit consent, as defined in Article 9(2)(a). This is a much higher standard than the consent used for marketing communications.
Explicit consent must be a freely given, specific, informed, and unambiguous indication of the user’s wishes, signified by a clear affirmative action. It must be separate from general terms and as easy to withdraw as it is to give.
This legal standard translates directly into concrete system requirements:
- Granular Choices: The UI must allow users to consent to specific processing purposes. For example, a wellness app should request separate consent for using health data for personal insights versus using it (even pseudonymized) for research.
- Unambiguous Interface: No pre-ticked boxes or bundled consent in the Terms of Service. Use clear toggles or checkboxes with plain language, such as, “I consent to my sleep data being used to power my daily recommendations.”
- Easy Withdrawal: Users must have a simple, obvious way to revoke consent in their account settings. This action must trigger an automated process to immediately cease all related data processing.
- Auditable Records: The system must maintain a robust consent ledger, logging who consented, to what, when, and how. It must also track if and when that consent was withdrawn. This is your proof of compliance.
Other Relevant Conditions for B2B Software
While explicit consent is common, a few other conditions may apply in specific contexts. These should be viewed as purpose-built tools for specific jobs, not as easier alternatives.
- Employment and Social Security Law (Article 9(2)(b)): This permits processing when necessary for obligations related to employment or social security law. An HR platform processing an employee’s health data to manage statutory sick leave would rely on this. However, the processing must be strictly necessary for a specific legal duty. It cannot be used to justify a “nice-to-have” corporate wellness feature, which would likely require explicit consent.
- Preventive or Occupational Medicine (Article 9(2)(h)): This allows processing for purposes like “preventive or occupational medicine, for the assessment of the working capacity of the employee, medical diagnosis, the provision of health or social care…” This is a cornerstone for health-tech. The critical constraint is that this processing must be done by—or under the responsibility of—a professional bound by an obligation of professional secrecy, which imposes stringent access control requirements on your architecture.
A common and costly mistake is misapplying legal bases. For example, “legitimate interest” is not a valid basis for processing special category data. It is a condition under Article 6 for general personal data, but it is not among the approved exceptions in Article 9.
Your choice of lawful basis dictates your system’s design, from consent mechanisms to access control policies and data lifecycle rules.
Architectural Patterns for Compliant Software
Having a lawful basis is a prerequisite; building a system that technically enforces it is the engineering challenge. For CTOs and engineering leaders, a compliant system is not about policies alone—it is about architecture.
You cannot treat special category data like other user data. It requires different handling, storage, and access controls. This mindset—privacy as an architectural choice—is the only way to build reliable, defensible software that handles the information covered by GDPR Art 9.
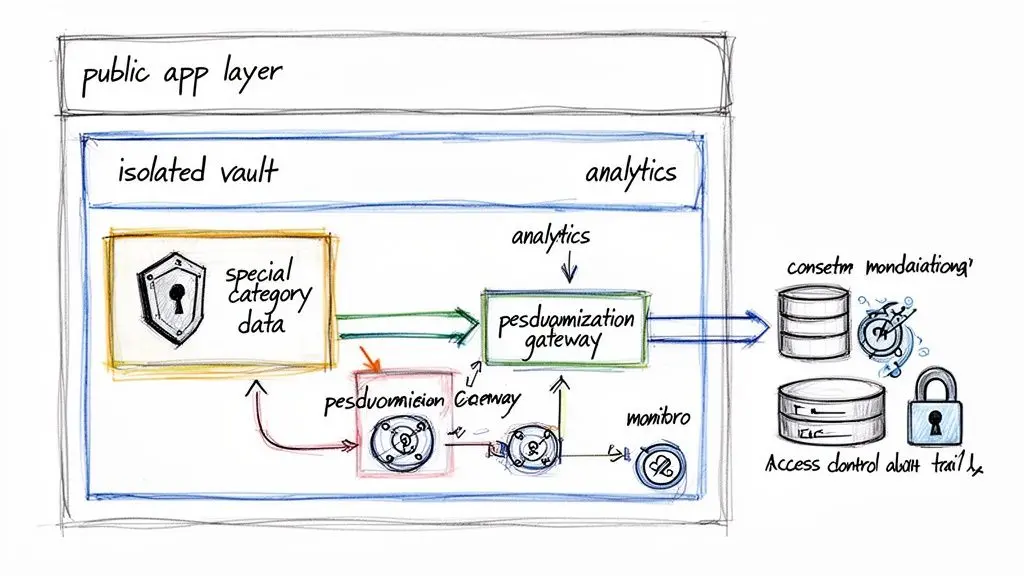
The Solution: Data Segregation and the “Vault” Model
A robust architectural pattern for handling sensitive data is data segregation, often implemented as a “data vault.” Instead of allowing sensitive information to mix with general user data, you isolate it in a separate, heavily fortified database or service.
This vault has its own strict rules:
- Isolated Storage: The vault should be a distinct database schema or a separate database instance. This creates a physical or logical barrier, minimizing the blast radius if another part of your system is compromised.
- Minimalist APIs: Access is granted through a limited set of APIs designed to expose only what is absolutely necessary. These endpoints should not return raw sensitive data unless there is a specific, authorized purpose.
- Strict Access Controls: Only a small number of highly privileged services or roles can access the vault. Standard application services that handle user profiles should have no credentials or permissions to see this isolated data.
- Intensive Auditing: Every read or write operation involving the vault is logged in an immutable audit trail, recording who accessed what, from where, and why.
This approach ensures that even if a less critical part of your application is breached, your most sensitive data remains protected. For a deeper dive, explore means of compliance for modern software.
Implementing Practical Data Minimization
Data minimization is a core GDPR principle, but for Article 9 data, it is non-negotiable. The goal is to reduce risk exposure by holding only the data you absolutely need, for only as long as you need it.
An effective technique is pseudonymization. This process replaces direct personal identifiers with a non-identifiable pseudonym.
Crucial Distinction: Pseudonymization is not anonymization. With pseudonymization, the original data can still be re-identified using a separate key. This reduces risk while preserving data utility for analytics or model training. True anonymization, where re-identification is impossible, is much harder to achieve and often destroys the data’s value.
From a systems design perspective, this means your architecture must:
- Store the mapping key that links pseudonyms back to real identities in a separate, highly secure location—ideally, inside your data vault.
- Conduct analytics and machine learning tasks on the pseudonymized dataset, not the raw, identifiable data.
- Implement automated data retention policies that permanently delete special category data once its lawful basis expires.
Building an Auditable Consent Management System
When your lawful basis is explicit consent, your system must be able to prove it. This requires more than a simple UI checkbox; you need a dedicated, auditable consent management database. Think of this database as an immutable ledger that records every consent-related event.
| Event Type | Data to Record | Example |
|---|---|---|
| Consent Given | User ID, Specific Purpose Consented To, Timestamp, Version of Privacy Policy/Notice | user_123 consented to health_data_for_recommendations at 2024-10-26T10:00:00Z under privacy_policy_v2.1 |
| Consent Withdrawn | User ID, Specific Purpose Withdrawn, Timestamp | user_123 withdrew consent for health_data_for_recommendations at 2024-11-15T14:30:00Z |
When a user withdraws consent, this system must trigger automated actions downstream, such as sending a webhook to your data warehouse to purge the user’s data or adding their ID to a “do not process” list for future model training. This closed-loop automation is essential for honoring user rights in real time.
Enforced since May 25, 2018, Article 9 has reshaped software development. Its impact is clear; studies indicate that since GDPR’s implementation, EU firms have reduced data storage and processing compared to their U.S. counterparts, signaling a tangible shift towards data minimization. You can read more about the impact of GDPR on digital markets to understand these trends.
Technical Safeguards for AI and Machine Learning
When you use AI and machine learning to process special category data, the risk factor increases significantly. For CTOs and ML engineers, this requires building specific, robust technical safeguards directly into models and data pipelines. A naive approach here can be a fatal blow to your AI product.
The moment your AI touches data covered by GDPR Art 9, the potential for misuse, biased decisions, and privacy breaches becomes very real. Your engineering practices must be equally serious.
The DPIA: Your Mandatory First Step
Before writing code to train a model on special category data, you must complete a Data Protection Impact Assessment (DPIA). This is not optional paperwork to finish after launch; it is a mandatory checkpoint required by GDPR for any high-risk processing. AI using sensitive data is the definition of high-risk.
A DPIA is a structured process to address hard questions:
- What exactly are we processing and why?
- Is this processing necessary and proportionate?
- What are the risks to individuals’ rights and freedoms?
- What concrete technical and organizational measures will we take to mitigate those risks?
Skipping a DPIA is a direct GDPR violation and signals to regulators a lack of serious engagement with data protection principles. For a deeper dive, see our guide on how to conduct a privacy impact assessment.
Protecting Training Datasets
Your raw training data is a significant liability. The first line of defense is to reduce its sensitivity without destroying its utility. Strong pseudonymization is a practical and effective safeguard. This means replacing direct identifiers in your training data with irreversible hashes or random tokens.
A crucial architectural point: the key that links tokens back to real users must be stored in a completely separate and highly secure environment. Your ML training environment should never have access to this key.
Advanced Privacy Architectures
For systems dealing with the most sensitive information, consider privacy-enhancing technologies (PETs) that limit data exposure by design.
- Federated Learning: Instead of pulling all data to a central server, the model is trained directly on the user’s device. Only model updates are sent back, not raw personal data. This keeps sensitive information, like health metrics on a phone, from leaving the user’s control.
- Differential Privacy: This technique adds statistical “noise” to a dataset or to query results. It allows for aggregate insights while making it mathematically difficult to determine if any single individual’s data was part of the calculation.
These methods are complex and come with trade-offs in model accuracy and engineering effort. But for high-stakes applications, they are a powerful and defensible way to demonstrate a commitment to privacy by design.
The Right to an Explanation
When an AI makes an automated decision using special category data—such as assessing a health risk—that decision cannot be a black box. GDPR gives individuals a right to meaningful information about the logic behind these decisions.
This means model explainability is not just a desirable feature; it is a compliance requirement. Your system must be able to provide a clear reason for its output. Building tools for explainability must be a core part of your ML development process from day one.
Conclusion: An Actionable Checklist
Turning GDPR Art 9 into practice requires clear, pragmatic actions. This checklist is for founders, CTOs, and product managers building real software. This is not about ticking boxes but about building reliable, trustworthy systems from the ground up.
Foundational Strategy
- Identify Rigorously: Do not assume. Actively identify and classify any data that could fall under Article 9, including inferred data.
- Default to Explicit Consent: For most commercial software, design your systems around explicit consent as the primary lawful basis. Do not attempt to use “legitimate interest”—it is not a valid condition under Article 9.
- Document Decisions: Maintain a clear record of what data you process, your lawful basis, and the safeguards implemented. This documentation is your first line of defense in an audit.
Core Architectural Actions
- Build a “Data Vault”: Isolate special category data through strict data segregation using separate databases or schemas with minimal, tightly controlled API access and intensive logging.
- Embed Pseudonymization: Make pseudonymization a default step in your data pipelines for analytics and model training. Secure the re-identification key separately.
- Automate Consent and Retention: Implement an auditable consent management system that logs all consent-related events and triggers automated workflows to honor user choices and enforce data retention policies.
High-Risk Project Governance
- Mandate a DPIA: A Data Protection Impact Assessment (DPIA) must be the mandatory first step for any new system processing special category data. Do not start development without it.
- Plan for Explainability: If using AI for automated decisions, build model explainability tools from day one to provide clear reasons for outcomes.
- Review Regularly: Compliance is not a one-time project. Schedule regular reviews of your data processing activities, especially as your product evolves, to ensure your safeguards and lawful bases remain valid.
By integrating these steps, you build a robust framework for handling sensitive user information. For a detailed tool to assess your systems, consider our free AI Risk & Privacy Checklist.
GDPR Art 9 FAQ
Technical teams often face the same practical questions when implementing Article 9. Here are straightforward answers to common queries.
What is the real difference between anonymization and pseudonymization?
Anonymized data has had all personal identifiers irreversibly removed, so it cannot be traced back to an individual. It falls outside the scope of GDPR.
Pseudonymized data is still personal data. Direct identifiers are replaced with a substitute (e.g., a user token), but the data can be re-identified using a separate key. This makes pseudonymization an effective risk-reduction technique, as it allows for data processing (like model training) without exposing raw personal information in development environments. The re-identification key must be stored in a separate, highly secure location.
Can we use “legitimate interest” for special category data?
No. This is a critical and dangerous misconception.
‘Legitimate interest’ is a lawful basis for processing general personal data under Article 6. It does not apply to the special category data covered by Article 9. To process special category data, you must meet one of the specific conditions listed in Article 9(2), such as explicit consent.
How do we handle consent withdrawal for AI models?
When a user withdraws consent, you must cease processing their data from that point forward. At a minimum, you must flag their data and exclude it from any future model training or retraining.
The more complex issue is data already incorporated into a trained model. Regulators increasingly view a model’s continued use of that information as ongoing processing. This may require you to be able to retrain your model from scratch, excluding that person’s data. The ability to handle consent withdrawal must be a core architectural consideration in your MLOps strategy from the beginning.
Building reliable, compliant software requires more than just following rules; it demands a product mindset and a commitment to long-term maintainability. Devisia specialises in turning complex business visions into robust digital products and AI-enabled systems, with privacy and security as core architectural choices. Learn more about our approach.