
Se c’è una parte del GDPR che richiede l’attenzione dei leader tecnologici, è l’Articolo 9. Disciplina ciò che il regolamento definisce “dati appartenenti a categorie particolari”—le informazioni personali più sensibili che un sistema può elaborare.
Per qualsiasi software, e in particolare per i sistemi di IA, gestire in modo errato questi dati non è soltanto un problema di conformità; è una minaccia diretta alla sostenibilità del tuo prodotto e alla reputazione della tua azienda.
Il problema: le poste in gioco elevate dei dati appartenenti a categorie particolari
Per founder, CTO e product leader, comprendere l’Articolo 9 non è una formalità legale da delegare interamente. È un vincolo architetturale fondamentale. Costruire un sistema che elabora questi dati senza una strategia chiara e difendibile porta spesso a prodotti non conformi per progettazione, costringendo a costose riprogettazioni o esponendo l’azienda a un rischio regolatorio significativo.
La sfida principale è che l’Articolo 9 opera secondo un principio di divieto per impostazione predefinita. Il punto di partenza è che ti è vietato elaborare questi dati. Puoi procedere solo se soddisfi una delle poche condizioni specifiche e rigorosamente definite. Questo ribalta il tipico modello di trattamento dei dati e impone obblighi rigorosi sin dall’inizio.
Che cosa sono i dati appartenenti a categorie particolari?
I dati appartenenti a categorie particolari sono distinti perché la loro esposizione non autorizzata potrebbe compromettere gravemente i diritti e le libertà fondamentali di una persona. È la differenza tra conoscere l’indirizzo di spedizione di un utente e conoscere la sua diagnosi medica.
L’Art. 9 del GDPR fornisce un elenco specifico di ciò che costituisce dati appartenenti a categorie particolari.
| Categoria di dati | Definizione e contesto software |
|---|---|
| Origine razziale o etnica | Dati che rivelano il background di una persona. Possono essere inferiti nell’analisi dei profili utente o negli strumenti di monitoraggio della diversità. |
| Opinioni politiche | Informazioni sulle opinioni politiche di una persona. Spesso presenti nell’analisi del sentiment sui social media o nelle piattaforme di sondaggi. |
| Convinzioni religiose o filosofiche | Dati sul sistema spirituale o di credenze di un individuo. Possono comparire nei forum di community o nei questionari delle app lifestyle. |
| Appartenenza sindacale | Informazioni che confermano l’appartenenza di una persona a un sindacato. Direttamente rilevanti per i sistemi HR e payroll. |
| Dati genetici | Dati derivati dall’analisi del DNA. Utilizzati nell’health-tech, nei servizi di ascendenza e nelle piattaforme di ricerca biomedica. |
| Dati biometrici per l’identificazione | Dati utilizzati per l’identificazione univoca (ad es. impronte digitali, scansioni facciali). Comuni nei sistemi di sicurezza, autenticazione e controllo accessi. |
| Dati relativi alla salute | Informazioni sulla salute fisica o mentale, inclusi anamnesi e trattamenti. Il cuore di qualsiasi app health-tech o wellness. |
| Dati relativi alla vita sessuale o all’orientamento sessuale | Informazioni private sulla vita personale di un individuo. Possono essere inferite o raccolte in app di dating o piattaforme social. |
Un approccio ingenuo o superficiale comporta un rischio significativo. Per esempio, uno strumento HR apparentemente innocuo che analizza il morale del team potrebbe inferire involontariamente condizioni di salute o simpatie sindacali, ricadendo così l’intero sistema sotto la rigorosa disciplina dell’Articolo 9.
Il messaggio critico per qualsiasi leader tecnico è questo: l’Articolo 9 ti impone di trattare determinati dati come altamente sensibili. Devono essere identificati, isolati e gestiti con misure tecniche e organizzative specifiche, supportate da una giustificazione esplicita e giuridicamente valida. Un approccio “elaboriamo prima, facciamo domande dopo” è una ricetta per la non conformità.
Le implicazioni di business della non conformità
La mancata conformità all’Articolo 9 va oltre le sanzioni, che possono arrivare fino a 20 milioni di euro o al 4% del fatturato globale annuo. Erode la fiducia dei clienti e può rendere un prodotto invendibile nell’UE. Un prodotto SaaS che elabora dati sanitari senza una base giuridica valida, come il consenso esplicito, è sostanzialmente non conforme.
Questa guida offre una roadmap pragmatica per i team di engineering e prodotto. Spiegheremo come identificare questi dati nei software reali, illustreremo le basi giuridiche per trattarli e presenteremo modelli architetturali per costruire sistemi conformi.
Identificare i dati appartenenti a categorie particolari nei tuoi sistemi
Sapere quali sono le definizioni dell’Articolo 9 del GDPR è una cosa; identificare i dati appartenenti a categorie particolari in un ambiente software reale è un’altra. Per ingegneri e product manager, non si tratta di un’astrazione legale. Si tratta di riconoscere dati ad alto rischio che fluiscono attraverso le API, risiedono nei database o vengono elaborati dai modelli di IA—spesso senza un’etichetta chiara di “sensibile”.
Un approccio superficiale, che presume che i dati non siano “particolari” se non vengono etichettati esplicitamente, rappresenta un rischio significativo di conformità. I tuoi sistemi potrebbero elaborare queste informazioni in modo implicito e, secondo il GDPR, l’ignoranza non è una difesa.
Casi d’uso evidenti
Alcune applicazioni sono semplici. Quando la funzione principale di un prodotto è costruita attorno a informazioni sensibili, identificare i dati appartenenti a categorie particolari è la parte più facile. La sfida sta nel garantire che l’intera architettura sia progettata per gestirli fin dall’inizio.
- Dati relativi alla salute: Un’app wellness che monitora livelli di stress, schemi di sonno o apporto calorico sta elaborando dati sanitari. Anche uno strumento diagnostico basato su IA che analizza immagini mediche ricade chiaramente nell’Articolo 9.
- Dati biometrici per l’identificazione: Includono il motore di riconoscimento facciale per un sistema di accesso o un’API per scanner di impronte digitali integrata per l’autenticazione. Qualsiasi sistema che utilizza caratteristiche fisiche o comportamentali univoche per identificare una persona elabora dati biometrici.
- Dati genetici: Una piattaforma che offre informazioni sull’ascendenza o un servizio B2B che fornisce report sanitari da analisi del DNA gestisce direttamente dati genetici.
Il rischio nascosto dei dati inferiti
La vera sfida architetturale nasce dai dati che diventano appartenenti a categorie particolari tramite inferenza. Un sistema potrebbe non richiedere direttamente informazioni sensibili, ma può dedurle da altri dati apparentemente innocui. Questo è un punto cieco comune per molti team tecnici.
Un modello di IA che analizza contenuti generati dagli utenti non ha bisogno di un campo “opinione politica” per classificare gli individui. Elaborando testi provenienti da forum o recensioni di prodotto, può inferire orientamenti politici, convinzioni religiose o persino lo stato di salute di una persona.
Quell’atto di inferenza è trattamento di dati appartenenti a categorie particolari. Attiva gli stessi rigorosi requisiti dell’Art. 9 del GDPR come se le informazioni fossero state raccolte esplicitamente.
Scenari reali
Per costruire sistemi robusti e conformi, i team tecnici devono essere formati a riconoscere queste situazioni meno ovvie. Considerare come i dati possano essere combinati o analizzati è una parte fondamentale della privacy by design.
- Un SaaS per la gestione delle community: Se la tua piattaforma consente agli utenti di creare gruppi, uno di questi potrebbe essere “Membri del sindacato Locale 123”. Il tuo sistema sta ora elaborando dati relativi all’appartenenza sindacale.
- Una funzionalità di analytics in una piattaforma e-commerce: Un algoritmo che segmenta i clienti in base alle abitudini di acquisto potrebbe segnalare persone che comprano testi religiosi o specifici prodotti per la salute, potenzialmente interpretato come trattamento di dati relativi a convinzioni religiose o salute.
- Una piattaforma HR aziendale: Uno strumento che monitora la partecipazione degli dipendenti agli eventi aziendali potrebbe rivelare chi ha preso parte a eventi Pride LGBTQ+, trattando così dati sull’orientamento sessuale.
L’obiettivo è promuovere una mentalità proattiva. Prima di elaborare un nuovo dataset, poni la domanda cruciale: “Questo dato, da solo o combinato con altre informazioni, potrebbe rivelare qualcosa su una persona che rientra nell’Articolo 9 del GDPR?” Rendere questa domanda una parte standard del processo di sviluppo è un passo fondamentale nella gestione del rischio.
Trovare una base giuridica per il trattamento
L’Articolo 9 del GDPR inizia con un divieto. Per impostazione predefinita, l’elaborazione di qualsiasi dato appartenente a categorie particolari è vietata. Per farlo legalmente, devi stabilire una deroga valida dall’elenco specifico dell’Articolo 9(2). Questa è una decisione fondamentale che deve essere presa—e documentata—prima che i tuoi sistemi elaborino questi dati.
Scegliere una base giuridica errata può invalidare l’intera attività di trattamento, rendendo il tuo sistema non conforme per progettazione. Per la maggior parte dei software e dei sistemi di IA, solo poche condizioni sono rilevanti, e ciascuna impone requisiti tecnici e organizzativi significativi.
Il primo passo è sempre la classificazione. Stai davvero gestendo dati appartenenti a categorie particolari? Questo diagramma di flusso aiuta a chiarire quel punto decisionale iniziale e critico.
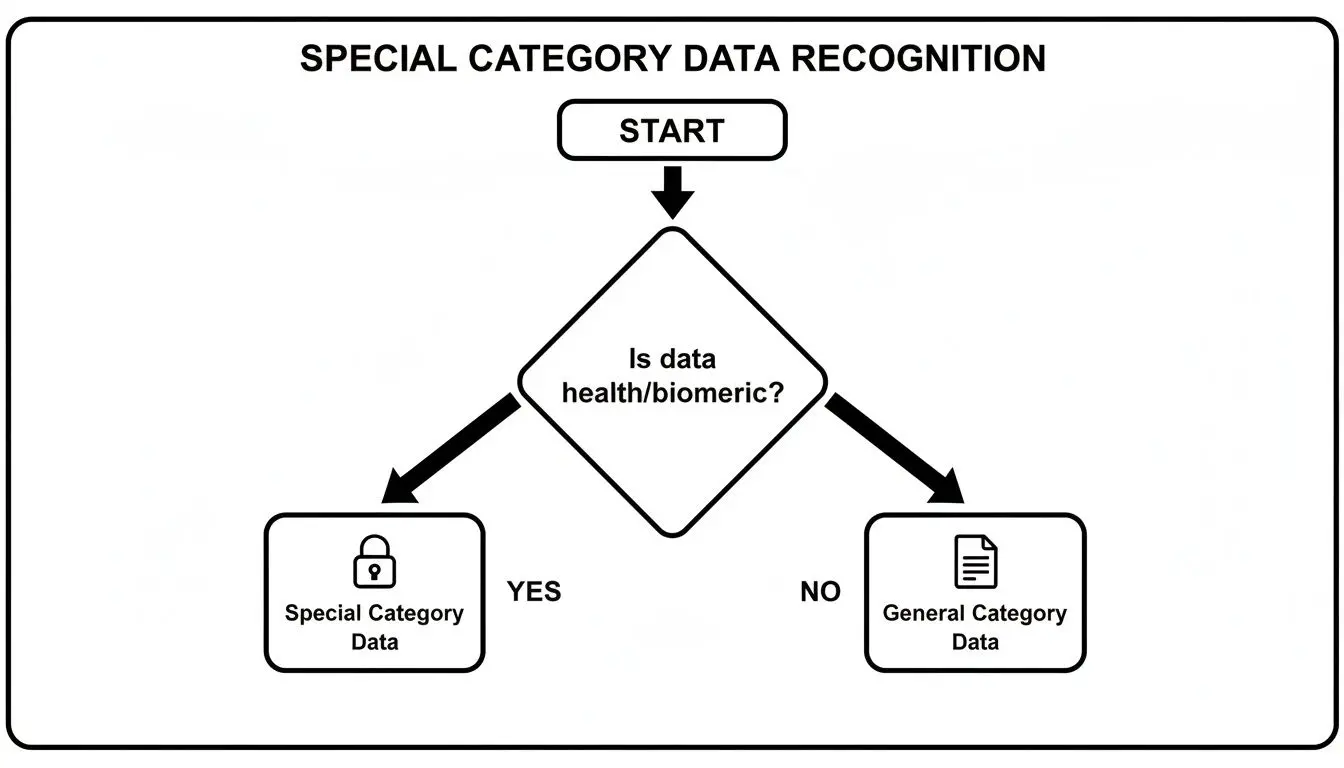
Una volta che i dati superano quella soglia “speciale”, l’obbligo è trovare e documentare una condizione specifica e valida ai sensi dell’Articolo 9 per trattarli.
Lo standard: consenso esplicito
Per la maggior parte dei software commerciali, la condizione più affidabile e difendibile è il consenso esplicito, come definito nell’Articolo 9(2)(a). Questo è uno standard molto più elevato rispetto al consenso utilizzato per le comunicazioni di marketing.
Il consenso esplicito deve essere un’indicazione della volontà dell’utente libera, specifica, informata e inequivocabile, espressa mediante un’azione positiva chiara. Deve essere separato dai termini generali ed essere facile da revocare quanto da concedere.
Questo standard giuridico si traduce direttamente in requisiti concreti di sistema:
- Scelte granulari: L’interfaccia deve consentire agli utenti di acconsentire a finalità specifiche di trattamento. Per esempio, un’app wellness dovrebbe richiedere un consenso separato per utilizzare i dati sanitari per insight personalizzati rispetto all’utilizzo degli stessi dati (anche se pseudonimizzati) per la ricerca.
- Interfaccia inequivocabile: Niente caselle preselezionate o consenso “in blocco” nei Termini di servizio. Usa toggle o checkbox chiari con un linguaggio semplice, come: “Acconsento all’utilizzo dei miei dati sul sonno per alimentare le mie raccomandazioni quotidiane.”
- Revoca semplice: Gli utenti devono avere un modo semplice e immediato per revocare il consenso nelle impostazioni del proprio account. Questa azione deve attivare un processo automatizzato per interrompere immediatamente ogni trattamento dei dati correlato.
- Registri verificabili: Il sistema deve mantenere un registro robusto dei consensi, annotando chi ha acconsentito, a cosa, quando e come. Deve inoltre tracciare se e quando quel consenso è stato revocato. Questa è la tua prova di conformità.
Altre condizioni rilevanti per il software B2B
Sebbene il consenso esplicito sia comune, in contesti specifici possono applicarsi altre condizioni. Queste vanno considerate come strumenti progettati per compiti specifici, non come alternative più facili.
- Diritto del lavoro e della sicurezza sociale (Articolo 9(2)(b)): Consente il trattamento quando necessario per obblighi relativi al diritto del lavoro o della sicurezza sociale. Una piattaforma HR che tratta i dati sanitari di un dipendente per gestire un congedo per malattia previsto dalla legge si baserebbe su questa disposizione. Tuttavia, il trattamento deve essere strettamente necessario per uno specifico obbligo legale. Non può essere usato per giustificare una funzionalità di benessere aziendale “piacevole da avere”, che probabilmente richiederebbe un consenso esplicito.
- Medicina preventiva o del lavoro (Articolo 9(2)(h)): Consente il trattamento per finalità come “medicina preventiva o del lavoro, valutazione della capacità lavorativa del dipendente, diagnosi medica, prestazione di assistenza o cure sanitarie o sociali…”. Questo è un pilastro per l’health-tech. Il vincolo critico è che tale trattamento deve essere effettuato da, o sotto la responsabilità di, un professionista soggetto all’obbligo del segreto professionale, il che impone requisiti rigorosi di controllo degli accessi alla tua architettura.
Un errore comune e costoso è l’applicazione errata delle basi giuridiche. Ad esempio, il “legittimo interesse” non è una base valida per il trattamento dei dati appartenenti a categorie particolari. È una condizione dell’Articolo 6 per i dati personali generali, ma non rientra tra le eccezioni approvate nell’Articolo 9.
La tua scelta della base giuridica determina la progettazione del sistema, dai meccanismi di consenso alle politiche di controllo degli accessi e alle regole del ciclo di vita dei dati.
Modelli architetturali per software conformi
Avere una base giuridica è un prerequisito; costruire un sistema che la faccia rispettare tecnicamente è la sfida ingegneristica. Per CTO e responsabili tecnici, un sistema conforme non riguarda solo le policy: riguarda l’architettura.
Non puoi trattare i dati appartenenti a categorie particolari come gli altri dati degli utenti. Richiedono gestione, archiviazione e controlli di accesso diversi. Questa mentalità—la privacy come scelta architetturale—è l’unico modo per costruire software affidabile e difendibile che gestisca le informazioni coperte dall’Art. 9 del GDPR.
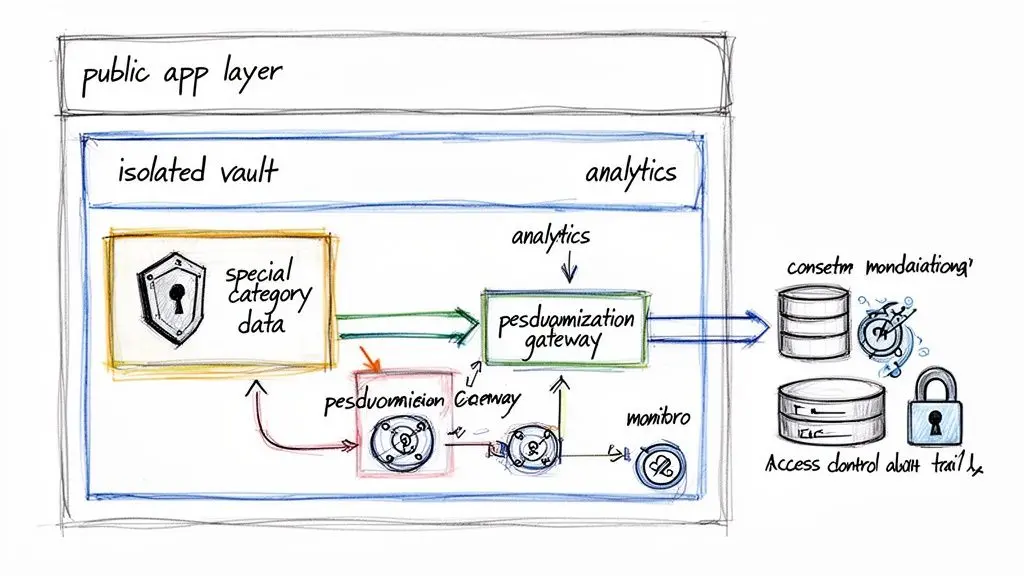
La soluzione: segregazione dei dati e modello “vault”
Un modello architetturale robusto per gestire dati sensibili è la segregazione dei dati, spesso implementata come un “data vault”. Invece di consentire ai dati sensibili di mescolarsi con i dati generali degli utenti, li isoli in un database o servizio separato, fortemente protetto.
Questo vault ha regole proprie e rigorose:
- Archiviazione isolata: Il vault dovrebbe essere uno schema di database distinto o un’istanza di database separata. Questo crea una barriera fisica o logica, riducendo al minimo il raggio di impatto se un’altra parte del sistema viene compromessa.
- API minimaliste: L’accesso viene concesso tramite un insieme limitato di API progettate per esporre solo ciò che è assolutamente necessario. Questi endpoint non dovrebbero restituire dati sensibili grezzi, a meno che non vi sia uno scopo specifico e autorizzato.
- Controlli di accesso rigorosi: Solo un numero ristretto di servizi o ruoli con privilegi elevati può accedere al vault. I servizi applicativi standard che gestiscono i profili utente non dovrebbero avere credenziali o permessi per visualizzare questi dati isolati.
- Audit intensivo: Ogni operazione di lettura o scrittura che coinvolge il vault viene registrata in una traccia di audit immutabile, che indica chi ha accesso a cosa, da dove e perché.
Questo approccio garantisce che, anche se una parte meno critica dell’applicazione viene violata, i tuoi dati più sensibili rimangano protetti. Per un approfondimento, esplora i mezzi di conformità per il software moderno.
Implementare una minimizzazione pratica dei dati
La minimizzazione dei dati è un principio fondamentale del GDPR, ma per i dati dell’Articolo 9 è imprescindibile. L’obiettivo è ridurre l’esposizione al rischio conservando solo i dati strettamente necessari, e solo per il tempo strettamente necessario.
Una tecnica efficace è la pseudonimizzazione. Questo processo sostituisce gli identificatori personali diretti con uno pseudonimo non identificabile.
Distinzione cruciale: La pseudonimizzazione non è anonimizzazione. Con la pseudonimizzazione, i dati originali possono ancora essere re-identificati usando una chiave separata. Questo riduce il rischio pur preservando l’utilità dei dati per analisi o addestramento di modelli. La vera anonimizzazione, in cui la re-identificazione è impossibile, è molto più difficile da ottenere e spesso distrugge il valore dei dati.
Dal punto di vista della progettazione del sistema, questo significa che la tua architettura deve:
- Archiviare la chiave di mappatura che collega gli pseudonimi alle identità reali in una posizione separata e altamente sicura—idealmente, all’interno del tuo data vault.
- Eseguire attività di analisi e machine learning sul dataset pseudonimizzato, non sui dati grezzi e identificabili.
- Implementare policy automatiche di conservazione dei dati che cancellino in modo permanente i dati appartenenti a categorie particolari una volta scaduta la relativa base giuridica.
Costruire un sistema di gestione del consenso verificabile
Quando la tua base giuridica è il consenso esplicito, il sistema deve essere in grado di provarlo. Questo richiede più di una semplice checkbox nell’interfaccia; serve un database dedicato e verificabile per la gestione del consenso. Considera questo database come un registro immutabile che documenta ogni evento relativo al consenso.
| Tipo di evento | Dati da registrare | Esempio |
|---|---|---|
| Consenso fornito | ID utente, Scopo specifico del consenso, Timestamp, Versione dell’informativa/privacy policy | user_123 ha acconsentito a health_data_for_recommendations alle 2024-10-26T10:00:00Z nell’ambito di privacy_policy_v2.1 |
| Consenso revocato | ID utente, Scopo specifico revocato, Timestamp | user_123 ha revocato il consenso per health_data_for_recommendations alle 2024-11-15T14:30:00Z |
Quando un utente revoca il consenso, questo sistema deve attivare azioni automatizzate a valle, come inviare un webhook al tuo data warehouse per eliminare i dati dell’utente o aggiungere il suo ID a una lista “do not process” per l’addestramento futuro dei modelli. Questa automazione a ciclo chiuso è essenziale per rispettare i diritti degli utenti in tempo reale.
In vigore dal 25 maggio 2018, l’Articolo 9 ha rimodellato lo sviluppo software. Il suo impatto è chiaro; studi indicano che, dall’implementazione del GDPR, le aziende dell’UE hanno ridotto l’archiviazione e il trattamento dei dati rispetto alle controparti statunitensi, segnalando un cambiamento tangibile verso la minimizzazione dei dati. Puoi leggere di più sull’impatto del GDPR sui mercati digitali per comprendere queste tendenze.
Salvaguardie tecniche per AI e machine learning
Quando utilizzi AI e machine learning per trattare dati appartenenti a categorie particolari, il fattore di rischio aumenta in modo significativo. Per CTO e ingegneri ML, ciò richiede di integrare direttamente nei modelli e nelle pipeline dati specifiche e robuste misure tecniche di protezione. Un approccio ingenuo qui può essere un colpo fatale per il tuo prodotto AI.
Nel momento in cui la tua AI tocca dati coperti dall’Art. 9 del GDPR, il potenziale di uso improprio, decisioni distorte e violazioni della privacy diventa molto concreto. Le tue pratiche ingegneristiche devono essere altrettanto serie.
Il DPIA: il tuo primo passo obbligatorio
Prima di scrivere codice per addestrare un modello su dati appartenenti a categorie particolari, devi completare una Valutazione d’Impatto sulla Protezione dei Dati (DPIA). Non si tratta di documentazione facoltativa da completare dopo il lancio; è un controllo obbligatorio richiesto dal GDPR per qualsiasi trattamento ad alto rischio. L’AI che utilizza dati sensibili è per definizione ad alto rischio.
Una DPIA è un processo strutturato per affrontare domande difficili:
- Cosa stiamo esattamente trattando e perché?
- Questo trattamento è necessario e proporzionato?
- Quali sono i rischi per i diritti e le libertà delle persone?
- Quali misure tecniche e organizzative concrete adotteremo per mitigare tali rischi?
Saltare una DPIA è una violazione diretta del GDPR e segnala ai regolatori una mancanza di reale attenzione ai principi di protezione dei dati. Per un approfondimento, consulta la nostra guida su come eseguire una valutazione d’impatto sulla privacy.
Proteggere i dataset di addestramento
I dati grezzi di addestramento rappresentano una responsabilità significativa. La prima linea di difesa è ridurne la sensibilità senza distruggerne l’utilità. Una forte pseudonimizzazione è una salvaguardia pratica ed efficace. Questo significa sostituire gli identificatori diretti nei dati di addestramento con hash irreversibili o token casuali.
Un punto architetturale cruciale: la chiave che collega i token agli utenti reali deve essere conservata in un ambiente completamente separato e altamente sicuro. Il tuo ambiente di training ML non dovrebbe mai avere accesso a questa chiave.
Architetture avanzate per la privacy
Per i sistemi che trattano le informazioni più sensibili, prendi in considerazione tecnologie per il miglioramento della privacy (PET) che limitano l’esposizione dei dati per progettazione.
- Federated Learning: Invece di trasferire tutti i dati a un server centrale, il modello viene addestrato direttamente sul dispositivo dell’utente. Vengono inviati indietro solo gli aggiornamenti del modello, non i dati personali grezzi. Questo impedisce che informazioni sensibili, come le metriche di salute su un telefono, escano dal controllo dell’utente.
- Differential Privacy: Questa tecnica aggiunge “rumore” statistico a un dataset o ai risultati di una query. Consente analisi aggregate rendendo matematicamente difficile determinare se i dati di un singolo individuo abbiano fatto parte del calcolo.
Questi metodi sono complessi e comportano compromessi in termini di accuratezza del modello e impegno ingegneristico. Ma per applicazioni ad alto impatto, sono un modo potente e difendibile per dimostrare un impegno verso la privacy by design.
Il diritto a una spiegazione
Quando un’AI prende una decisione automatizzata utilizzando dati appartenenti a categorie particolari—come la valutazione di un rischio sanitario—quella decisione non può essere una scatola nera. Il GDPR riconosce agli individui il diritto a informazioni significative sulla logica alla base di tali decisioni.
Questo significa che la spiegabilità del modello non è solo una funzionalità auspicabile; è un requisito di conformità. Il tuo sistema deve essere in grado di fornire una ragione chiara per il suo output. Costruire strumenti per la spiegabilità deve essere una parte fondamentale del tuo processo di sviluppo ML fin dal primo giorno.
Conclusione: una checklist operativa
Trasformare l’Art. 9 del GDPR in pratica richiede azioni chiare e pragmatiche. Questa checklist è pensata per founder, CTO e product manager che costruiscono software reale. Non si tratta di spuntare caselle, ma di costruire sistemi affidabili e degni di fiducia dalle fondamenta.
Strategia di base
- Identifica in modo rigoroso: Non assumere. Identifica e classifica attivamente qualsiasi dato che possa rientrare nell’Articolo 9, compresi i dati dedotti.
- Predefinisci il consenso esplicito: Per la maggior parte del software commerciale, progetta i sistemi attorno al consenso esplicito come base giuridica primaria. Non tentare di usare il “legittimo interesse”: non è una condizione valida ai sensi dell’Articolo 9.
- Documenta le decisioni: Mantieni un registro chiaro di quali dati tratti, della tua base giuridica e delle salvaguardie implementate. Questa documentazione è la tua prima linea di difesa in un audit.
Azioni architetturali principali
- Costruisci un “data vault”: Isola i dati appartenenti a categorie particolari tramite una rigorosa segregazione dei dati, utilizzando database o schemi separati con accesso API minimo, strettamente controllato e con logging intensivo.
- Integra la pseudonimizzazione: Rendi la pseudonimizzazione un passaggio predefinito nelle tue pipeline dati per analisi e addestramento dei modelli. Proteggi separatamente la chiave di re-identificazione.
- Automatizza consenso e conservazione: Implementa un sistema di gestione del consenso verificabile che registri tutti gli eventi relativi al consenso e attivi workflow automatizzati per rispettare le scelte degli utenti e applicare le policy di conservazione dei dati.
Governance dei progetti ad alto rischio
- Rendi obbligatoria la DPIA: Una Valutazione d’Impatto sulla Protezione dei Dati (DPIA) deve essere il primo passo obbligatorio per qualsiasi nuovo sistema che tratti dati appartenenti a categorie particolari. Non iniziare lo sviluppo senza di essa.
- Pianifica la spiegabilità: Se usi l’AI per decisioni automatizzate, costruisci fin dal primo giorno strumenti di spiegabilità del modello per fornire motivazioni chiare dei risultati.
- Rivedi regolarmente: La conformità non è un progetto una tantum. Pianifica revisioni regolari delle tue attività di trattamento dei dati, soprattutto mentre il prodotto evolve, per garantire che le tue salvaguardie e basi giuridiche rimangano valide.
Integrando questi passaggi, costruisci un framework robusto per gestire informazioni sensibili degli utenti. Per uno strumento dettagliato con cui valutare i tuoi sistemi, considera la nostra gratuita AI Risk & Privacy Checklist.
FAQ sull’Art. 9 del GDPR
I team tecnici si trovano spesso ad affrontare le stesse domande pratiche quando implementano l’Articolo 9. Ecco risposte dirette alle domande più comuni.
Qual è la vera differenza tra anonimizzazione e pseudonimizzazione?
I dati anonimizzati hanno avuto tutti gli identificatori personali rimossi in modo irreversibile, quindi non possono essere ricondotti a una persona. Escono dall’ambito di applicazione del GDPR. I dati pseudonimizzati sono comunque dati personali. Gli identificatori diretti vengono sostituiti con un sostituto (ad es. un token utente), ma i dati possono essere re-identificati tramite una chiave separata. Questo rende la pseudonimizzazione una tecnica efficace di riduzione del rischio, poiché consente l’elaborazione dei dati (come l’addestramento di modelli) senza esporre informazioni personali grezze negli ambienti di sviluppo. La chiave di re-identificazione deve essere conservata in una posizione separata e altamente sicura.
Possiamo usare il “legittimo interesse” per i dati di categoria speciale?
No. Questa è una convinzione critica e pericolosa.
‘Legittimo interesse’ è una base giuridica per il trattamento di dati personali generali ai sensi dell’Articolo 6. Non si applica ai dati di categoria speciale disciplinati dall’Articolo 9. Per trattare dati di categoria speciale, è necessario soddisfare una delle condizioni specifiche elencate nell’Articolo 9(2), come il consenso esplicito.
Come gestiamo la revoca del consenso per i modelli di IA?
Quando un utente revoca il consenso, devi cessare di trattare i suoi dati da quel momento in poi. Al minimo, devi contrassegnare i suoi dati ed escluderli da qualsiasi addestramento o riaddestramento futuro del modello.
La questione più complessa riguarda i dati già incorporati in un modello addestrato. Le autorità di regolamentazione considerano sempre più spesso il continuo utilizzo di tali informazioni da parte di un modello come trattamento in corso. Ciò potrebbe richiederti di poter riaddestrare il modello da zero, escludendo i dati di quella persona. La capacità di gestire la revoca del consenso deve essere una considerazione architetturale fondamentale nella tua strategia MLOps fin dall’inizio.
Costruire software affidabile e conforme richiede più che seguire semplicemente le regole; richiede una mentalità orientata al prodotto e un impegno verso la manutenibilità a lungo termine. Devisia è specializzata nel trasformare visioni aziendali complesse in prodotti digitali robusti e sistemi abilitati all’IA, con privacy e sicurezza come scelte architetturali fondamentali. Scopri di più sul nostro approccio.