
Disaster recovery in cloud computing is not about backups. It’s about designing entire systems architected to withstand significant failure and resume operations with minimal business disruption. A robust strategy moves beyond simple data replication to answer two critical questions: how quickly must the system be restored (Recovery Time Objective), and how much data can the business afford to lose (Recovery Point Objective)?
Ultimately, the answers are dictated by business requirements, regulatory obligations, and budget constraints.
System Failure is a When, Not an If
The problem is one of statistical certainty: in any distributed cloud architecture, components will fail. The complex interplay of microservices, third-party APIs, and network dependencies means a single point of failure can trigger a cascade across the entire system. For technical leaders, the objective must shift from preventing all failures to architecting for inevitable ones.
This reality is amplified by rising customer expectations for 100% uptime and increasing regulatory scrutiny. A service outage is no longer a technical inconvenience; it’s a direct threat to revenue, brand reputation, and regulatory compliance.
The Critical Distinction: High Availability vs. Disaster Recovery
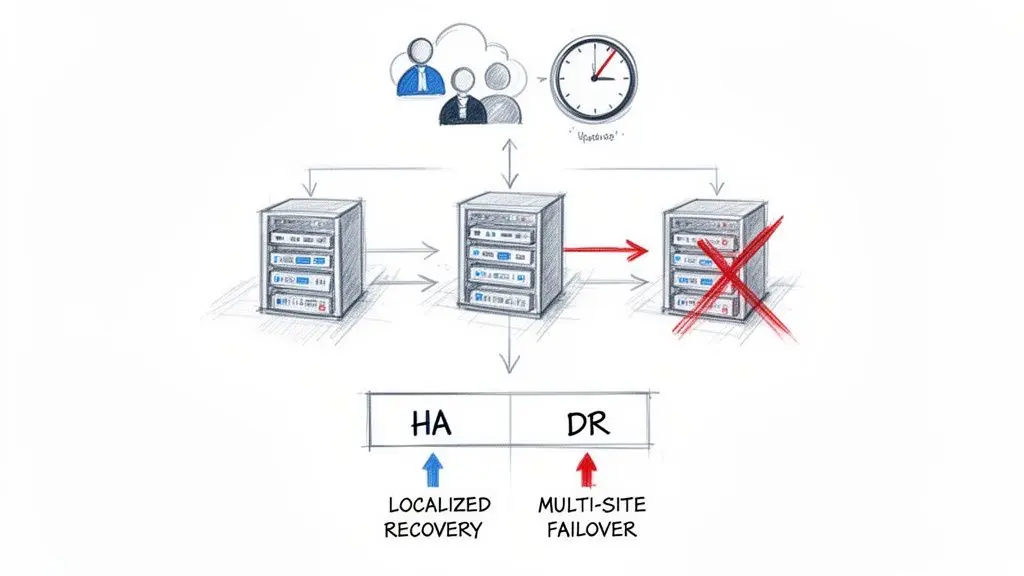
A common and dangerous misconception is to conflate high availability (HA) and disaster recovery (DR). They are related concepts but solve fundamentally different problems. Acknowledging this distinction is the first step toward building genuine system resilience.
-
High Availability (HA) is the defense against small-scale, localized failures. This includes a single server crash, a database instance failure, or a load balancer malfunction. HA architectures use redundancy—typically within a single data center or availability zone—to maintain service continuity without perceptible user impact.
-
Disaster Recovery (DR) addresses large-scale, catastrophic events. This includes the complete failure of a data center, a regional cloud provider outage, or a ransomware attack that compromises an entire environment. A DR plan assumes the primary operational site is gone and defines the process for failing over to a secondary, geographically separate location.
A system can be highly available yet have no disaster recovery plan. Relying on auto-scaling groups or redundant servers within one region offers no protection when that entire region goes offline.
Business Drivers and Core Trade-offs
The impetus for a robust DR strategy extends beyond engineering best practices. Modern compliance frameworks now mandate operational resilience as a legal requirement. Regulations such as the Digital Operational Resilience Act (DORA) in the financial sector and NIS2 for critical infrastructure explicitly require organizations to prove their ability to recover from major disruptions.
Every disaster recovery strategy represents a trade-off between three interdependent factors:
- Recovery Speed: The maximum acceptable time for the system to be restored.
- Data Loss: The maximum volume of recent data the business can afford to lose permanently.
- Cost: The budget for the infrastructure and operational overhead required to meet recovery objectives.
Defining these parameters is a business decision, not an engineering task. This decision will dictate the entire technical approach. The following sections detail how to define these objectives and select the appropriate architectural patterns to achieve them.
Defining Recovery Objectives and Budget
Before an engineering team writes a line of code or provisions any infrastructure, the business must answer a fundamental question: what does “recovery” mean in a quantifiable sense? A disaster recovery plan built on ambiguity is merely a theoretical exercise. The entire strategy hinges on two specific metrics that translate business needs into technical constraints.
These metrics are the Recovery Time Objective (RTO) and the Recovery Point Objective (RPO). These are not technical jargon; they are critical business decisions with significant technical and financial implications.
Understanding RTO and RPO
The concepts are straightforward, but their impact is profound.
-
Recovery Time Objective (RTO): This is the maximum acceptable duration for an application to be offline following a disaster. It answers the question, “How quickly must we be back in service?”
-
Recovery Point Objective (RPO): This defines the maximum amount of data loss the business can tolerate, measured in time. It answers, “How much data from the period immediately preceding the disaster can we afford to lose?”
Let’s apply this to a real-world scenario. Consider a B2B SaaS company providing a project management tool.
Example Scenario: The leadership team determines that customers will tolerate a maximum downtime of one hour. Any longer risks contract violations and reputational damage. This establishes an RTO of 1 hour.
The team also analyzes data usage patterns. They conclude that losing more than five minutes of new comments, file uploads, and task updates would create an unrecoverable data integrity problem for their clients. This sets their RPO to 5 minutes.
With these two values, the mission is no longer an abstract “build a DR plan.” It becomes a concrete engineering challenge: “design a system that can be fully restored within 60 minutes with no more than 5 minutes of data loss.”
How RTO and RPO Drive Architecture and Cost
The relationship between these objectives and cloud expenditure is direct and unforgiving. Lowering the RTO and RPO—demanding faster recovery and less data loss—exponentially increases architectural complexity and cost.
Achieving near-zero downtime and zero data loss is technically feasible with modern cloud services, but the cost can be orders of magnitude higher than a more moderate strategy. This is the central trade-off every founder and CTO must navigate: balancing the cost of downtime against the cost of prevention. A four-hour RTO may be acceptable for an internal analytics platform but would be catastrophic for a customer-facing payment processing service.
The following table illustrates this relationship, mapping recovery objectives to specific architectural patterns and their relative costs. Understanding this spectrum is key to making a pragmatic decision that aligns resilience goals with the budget.
How RTO and RPO Influence Architecture and Cost
| Recovery Tier | Example RTO / RPO | Architectural Pattern | Relative Cloud Cost | Use Case |
|---|---|---|---|---|
| Low Priority | 24 hours / 24 hours | Backup and Restore | Low | Internal tools, development environments, non-critical systems. |
| Business Critical | 1-4 hours / < 1 hour | Pilot Light | Medium | Core SaaS applications, e-commerce platforms, B2B services. |
| Mission Critical | < 15 mins / < 5 mins | Warm Standby (Scaled) | High | High-traffic applications with significant direct revenue impact. |
| Zero Downtime | Seconds / Near-Zero | Hot Standby (Active-Active) | Very High | Financial trading platforms, payment gateways, critical infrastructure. |
Ultimately, selecting an RTO and RPO is an exercise in risk management. By defining these objectives upfront, you provide technical teams with clear constraints, enabling them to design a disaster recovery solution that is both technically sound and financially sustainable.
Exploring Cloud Disaster Recovery Patterns
Once RTO and RPO are defined, the next step is to select an architectural pattern that meets these targets without exceeding the budget. Cloud providers offer a flexible toolkit for disaster recovery, with most strategies falling into one of four primary patterns. These exist on a spectrum: from low cost and slow recovery to near-instantaneous recovery at a premium cost.
The key is to match the technical implementation to business reality. An internal reporting tool does not require an expensive active-active architecture, just as a global payment gateway cannot rely on nightly backups.
Backup and Restore
This is the most fundamental and cost-effective DR pattern. The principle is simple: regularly back up application data and configuration to a durable, off-site location. In a cloud context, this typically involves storing database and virtual machine snapshots in object storage services like Amazon S3, Azure Blob Storage, or Google Cloud Storage.
In a disaster scenario, the recovery process is manual. An engineer must provision new infrastructure in a secondary region, deploy the application from its configuration backups, and then restore the data from the most recent snapshot.
- Use Cases: Ideal for development environments, internal tools, and applications with lenient RTOs and RPOs (e.g., 12–24 hours).
- Trade-offs: The primary advantage is low cost, as you only pay for storage. The major disadvantage is a high RTO; recovery can take hours, depending on data volume and infrastructure complexity. The RPO is determined by backup frequency—a daily backup schedule implies a potential data loss of up to 24 hours.
This diagram shows how business needs for RTO and RPO directly shape your architectural choices and, ultimately, your costs.
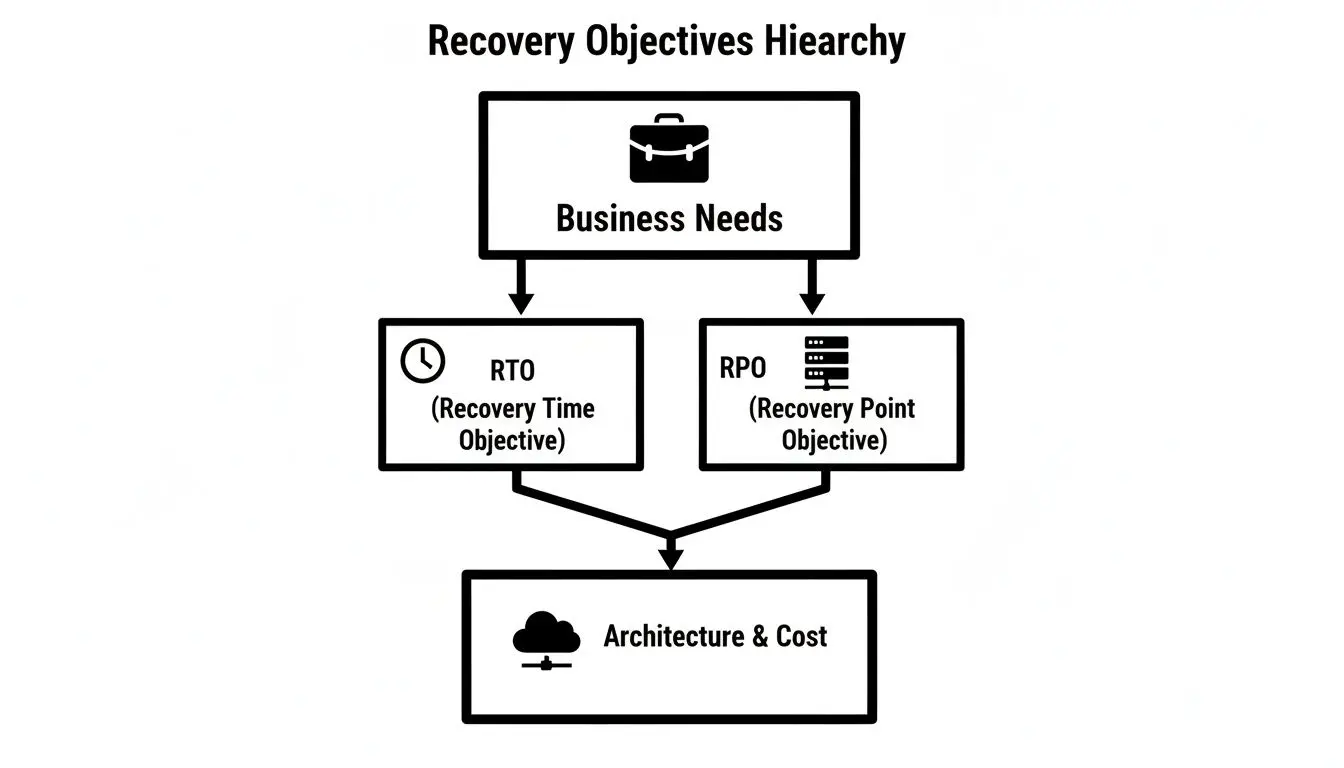
The hierarchy is clear: business requirements define the technical strategy and its associated costs.
The Pilot Light Pattern
The Pilot Light pattern offers a balanced trade-off between cost and recovery speed. The core concept is to maintain a minimal, skeletal version of the infrastructure in the recovery region at all times. This “pilot light” includes critical components, such as a small database instance that continuously replicates data from the primary region.
During a disaster, you “ignite the flame” by scaling out the application servers, updating DNS to route traffic to the recovery region, and promoting the replica database to become the new primary.
- Use Cases: A strong choice for business-critical applications where an RTO of minutes to a few hours is acceptable.
- Trade-offs: Costs are higher than Backup and Restore because some infrastructure is running 24/7. However, the RTO is significantly lower because core data and services are already in place. The RPO is typically very low (minutes or even seconds) due to near-continuous database replication.
The Warm Standby Approach
Moving up the resilience spectrum, the Warm Standby pattern maintains a scaled-down but fully functional copy of the production environment in a secondary region. Unlike Pilot Light, all services are operational, but they are provisioned with lower capacity to manage costs.
For example, the production auto-scaling group might run ten large instances, while the warm standby region operates with just two small ones. Upon failover, traffic is redirected, and the standby infrastructure is immediately scaled up to handle the full production load. This transition is much faster than Pilot Light because the application is already running.
The efficiency of cloud-native recovery provides a significant advantage over traditional on-premise solutions. A deeper analysis of these architectural differences is available in our guide on cloud computing vs on-premise solutions. The ability to recover faster is a key driver for cloud adoption in regulated industries.
The Hot Standby (Active-Active) Pattern
This is the highest tier of resilience. A Hot Standby, often implemented as an active-active or multi-site architecture, involves running full-scale production environments in two or more geographically separate regions simultaneously. A global load balancer distributes traffic between them, routing users to the closest or healthiest location.
If one region fails, the load balancer automatically redirects all traffic to the remaining healthy regions. No manual intervention is required.
A true Hot Standby architecture results in a near-instantaneous failover that is often imperceptible to end-users. This pattern delivers the lowest possible RTO and RPO, typically measured in seconds.
- Use Cases: Essential for mission-critical systems where any downtime has severe consequences, such as financial transaction platforms, airline reservation systems, and core infrastructure services.
- Trade-offs: The primary constraint is cost. This pattern effectively doubles infrastructure expenditure and introduces significant operational complexity, particularly around maintaining data consistency across active sites. However, for businesses where the cost of downtime is exceptionally high, this architecture is a necessary investment.
From a Theoretical Plan to a Proven Capability
A disaster recovery plan existing only as a PDF document is a liability, not an asset. During a real crisis—a regional outage or critical service failure—the operational pressure is immense. In such high-stress environments, manual recovery procedures are prone to failure due to human error, missed steps, or panic.
To build genuine resilience, a theoretical plan must be transformed into a proven, tested capability. This transformation relies on two pillars: automation and rigorous testing. An untested DR strategy provides a false sense of security that will evaporate at the moment it is needed most.
Automating Recovery with Infrastructure as Code
The foundation of a reliable DR process is Infrastructure as Code (IaC). Expecting an engineer to manually provision servers, configure networks, and deploy services from memory during an outage is a recipe for extended downtime and configuration drift.
Tools like Terraform, AWS CloudFormation, or Azure Resource Manager allow you to define your entire infrastructure in declarative configuration files. This code becomes the single source of truth for your production environment’s architecture.
During a failover, you don’t follow a checklist of console clicks; you execute a script. This fundamentally changes the recovery process:
- Consistency: The recovery environment is an exact, error-free replica of the primary site.
- Speed: Provisioning a full stack via IaC is orders of magnitude faster than manual efforts.
- Repeatability: The environment can be torn down and rebuilt consistently, which is essential for effective testing.
The objective is to automate the failover process to the point of being routine. If your disaster recovery procedure is a high-drama, all-hands-on-deck event, it is not sufficiently mature.
Building Runbooks That Are Executable
Static runbooks in Word documents are quickly outdated and impractical during a crisis. A modern, effective runbook is not a document to be read; it is a script to be executed. It should consist of a series of automated commands, API calls, and IaC templates.
A robust runbook is a living component of your codebase, version-controlled in Git and updated alongside the application. It must cover the entire failover lifecycle, from the decision to declare a disaster to the final validation checks confirming service restoration. Treating runbooks as code ensures they remain current and are subject to the same review standards as the application itself. This principle of automated, version-controlled workflows is also central to our approach to building robust CI/CD pipelines.
The Necessity of Rigorous and Regular Testing
An untested plan is a useless plan. The only way to verify that a disaster recovery strategy works is to execute it. Regular testing uncovers hidden dependencies, outdated configurations, and flawed assumptions before they can cause failure during a real outage.
Types of Disaster Recovery Drills:
- Tabletop Exercises: A low-impact simulation where the team verbally walks through the runbook step-by-step. This is an effective way to identify logical gaps and confirm that team members understand their roles and responsibilities.
- Component Failure Tests: Deliberately breaking a non-critical component in a sandboxed recovery environment. This validates that automated detection and remediation scripts function as expected.
- Full Failover Drills: The definitive test. This involves simulating a complete regional failure by redirecting a subset of live traffic (or all traffic) to the standby site. This is the only method to truly validate your RTO and RPO under real-world conditions.
Conducting these tests on a regular schedule—quarterly for tabletop and component tests, and at least annually for a full drill—builds the “muscle memory” the team needs. It transforms disaster recovery from a dreaded emergency procedure into a practiced operational discipline.
DR for AI and Data-Intensive Systems
The problem with traditional disaster recovery plans is that they are inadequate for the unique failure modes of modern AI systems. Playbooks designed for stateless applications and standard databases fail when confronted with petabyte-scale data lakes, large vector databases, or complex ML model repositories.
The challenge begins with data volume. Attempting to copy terabytes of data across regions during a crisis is slow, costly, and impractical. This creates an unacceptable RPO and demands more sophisticated replication and recovery strategies that are native to the data platform.
Protecting Data and Model Integrity
The greater risk extends beyond raw data to the integrity of the entire AI pipeline. A successful recovery is not just about restoring bytes; it is about ensuring the system produces correct, reliable results post-failover. This requires maintaining perfect synchronization between application data, ML models, and the feature data used for training.
A failure to maintain this consistency can result in a “recovered” system that produces nonsensical, biased, or incorrect outputs. To mitigate this risk, the DR plan must address:
- Model Versioning and Replication: The model registry is a critical stateful component. It must be treated with the same importance as the primary database and replicated across regions. Losing the production model version renders the application useless.
- Feature Store Consistency: The state of the feature store must be synchronized with application databases. Any drift can lead to catastrophic prediction errors after a failover.
- Vector Database Recovery: For applications using semantic search or Retrieval-Augmented Generation (RAG), the vector database is mission-critical. Its recovery plan must ensure that embeddings are perfectly aligned with their source content to avoid rendering the search functionality useless.
Building Resilience for Third-Party API Dependencies
Many AI applications depend on third-party APIs from providers like OpenAI, Anthropic, or Google, creating a critical dependency outside of the organization’s control. An outage at one of these providers can disable core application features.
A robust DR strategy must account for this provider risk. Passively waiting for the third party to resolve the issue is not a strategy.
Relying on a single AI provider without a fallback is a critical architectural vulnerability. The question is not if the API will have an outage, but what your system will do when it does.
Effective strategies for managing this dependency risk include:
- Implementing Circuit Breakers: This design pattern automatically detects when an external API is failing and temporarily halts requests, preventing the application from being overwhelmed by timeouts.
- Architecting for Fallbacks: Design the system to failover to an alternative model or provider. If the primary LLM API is unavailable, requests can be routed to a secondary model, even if it provides slightly lower performance.
- Graceful Feature Degradation: If a fallback is not feasible, the system should degrade gracefully. Instead of displaying a cryptic error, it could temporarily disable the AI-powered feature and notify the user, allowing the rest of the application to remain functional.
Conversely, AI can also enhance DR capabilities. Machine learning can be used for predictive failure analysis and automated workload shifting, which is a key driver behind the growing cloud-based disaster recovery market analysis.
These unique failure modes are critical to address during system design. Our free AI Risk & Privacy Checklist was developed to help teams identify and mitigate these specialized risks.
Balancing Compliance and Cost
For any CTO or compliance officer, a disaster recovery strategy is a critical business artifact that must satisfy both regulators and the finance department. An architecture that is technically robust but non-compliant or financially unsustainable is a failed strategy.
Modern regulations do not merely suggest resilience; they demand it. Frameworks such as GDPR, NIS2, and DORA include specific, legally binding requirements for business continuity and data protection. A DR plan must demonstrate the ability to maintain operational resilience and protect data integrity during a failure.
Architecting for Data Sovereignty and Regulation
Compliance must be an integral part of the DR architecture, not an afterthought. This requires careful consideration of data residency and processing, even during an emergency.
- GDPR and Data Sovereignty: The requirements of GDPR follow EU citizen data wherever it is processed. A recovery site must provide the same level of data protection as the primary site. Failing over to a DR region outside the EU, for instance, could constitute a high-risk, non-compliant data transfer that will attract regulatory scrutiny.
- DORA and Operational Resilience: For the financial services sector, DORA is explicit. It requires firms not only to have a DR plan but to regularly test it to prove that critical business functions can be restored within predefined timeframes. An untested plan is a non-compliant plan.
An architecture that fails over to a non-compliant region does not solve a disaster. It trades a technical crisis for a legal one. The DR strategy must respect the geographical and legal boundaries associated with the data it protects.
Managing Cloud Costs Sustainably
While resilience is non-negotiable, a naive implementation can lead to unsustainable cloud costs. A hot-standby site that mirrors the production environment also mirrors its cost, effectively doubling infrastructure spend. Financial governance is essential to making a DR strategy viable long-term.
Cloud platforms provide numerous mechanisms to control costs without compromising recovery objectives.
Practical cost optimization strategies include:
- Use Reserved Instances or Savings Plans: For compute resources that must run continuously (as in Pilot Light or Warm Standby patterns), committing to a one- or three-year plan can yield significant discounts over on-demand pricing.
- Leverage Serverless Architectures: Where possible, use serverless functions (e.g., AWS Lambda or Azure Functions) and managed services. This minimizes the cost of idle resources, as you only pay for execution during a test or an actual failover.
- Implement Rigorous Tagging and Monitoring: You cannot control what you do not measure. Meticulously tag all DR-related resources to track their costs. Configure billing alerts to detect spending anomalies before they become significant issues.
The rapid growth of the Disaster Recovery as a Service (DRaaS) market underscores the need to balance resilience with cost-effectiveness. The market is projected to expand significantly, driven by the demand for efficient public cloud solutions, as detailed in recent disaster recovery statistics and trends. This industry shift reflects a move toward DR solutions that are scalable, compliant, and financially pragmatic.
Building Resilience by Design
Effective disaster recovery is not an add-on product; it is an intrinsic characteristic of a well-architected system. The process begins with a business-level discussion to define the Recovery Time Objective (RTO) and Recovery Point Objective (RPO). These two metrics serve as the primary constraints for all subsequent technical decisions, dictating architectural complexity, operational readiness, and cost.
Core Principles for Resilient Architecture
A spectrum of architectural patterns—from Backup and Restore to Hot Standby—exists to meet these RTO and RPO targets, each with a different cost profile. The correct choice is a deliberate trade-off between the level of resilience required and the budget available.
However, a chosen pattern is only valuable if it is proven to work. An effective DR strategy must be automated with Infrastructure as Code (IaC) and validated through regular, rigorous testing. An untested DR plan creates a false sense of security that is functionally equivalent to having no plan at all.
Disaster recovery is an operational capability, not a static document. It requires automation to eliminate human error under pressure and relentless testing to build organizational muscle memory.
Finally, modern systems present unique challenges. AI and data-intensive applications require specialized recovery strategies that address data consistency, model integrity, and third-party API dependencies.
The conclusion is clear: resilience must be a conscious design choice. It requires balancing precise technical implementation with the practical realities of the business, ensuring systems are engineered not just to run, but to survive.
At Devisia, we help organizations build resilience directly into their software architecture. If you need a technical partner to design and implement a pragmatic, maintainable, and cost-effective disaster recovery strategy for your digital products, we can help.
Learn more about our approach to building reliable software systems at devisia.pro