
Il disaster recovery nel cloud computing non riguarda i backup. Si tratta di progettare sistemi completi architettati per resistere a guasti significativi e riprendere le operazioni con una minima interruzione per il business. Una strategia robusta va oltre la semplice replica dei dati per rispondere a due domande critiche: in quanto tempo il sistema deve essere ripristinato (Recovery Time Objective) e quanti dati l’azienda può permettersi di perdere (Recovery Point Objective)?
In definitiva, le risposte sono determinate dai requisiti di business, dagli obblighi normativi e dai vincoli di budget.
Il guasto del sistema è un quando, non un se
Il problema è una questione di certezza statistica: in qualsiasi architettura cloud distribuita, i componenti si guasteranno. La complessa interazione tra microservizi, API di terze parti e dipendenze di rete significa che un singolo punto di guasto può innescare una reazione a catena in tutto il sistema. Per i responsabili tecnici, l’obiettivo deve spostarsi dal prevenire tutti i guasti al progettare per quelli inevitabili.
Questa realtà è amplificata dalle crescenti aspettative dei clienti per un uptime del 100% e da un controllo normativo sempre più stringente. Un’interruzione del servizio non è più un inconveniente tecnico; è una minaccia diretta a ricavi, reputazione del marchio e conformità normativa.
La distinzione critica: Alta disponibilità vs. Disaster Recovery
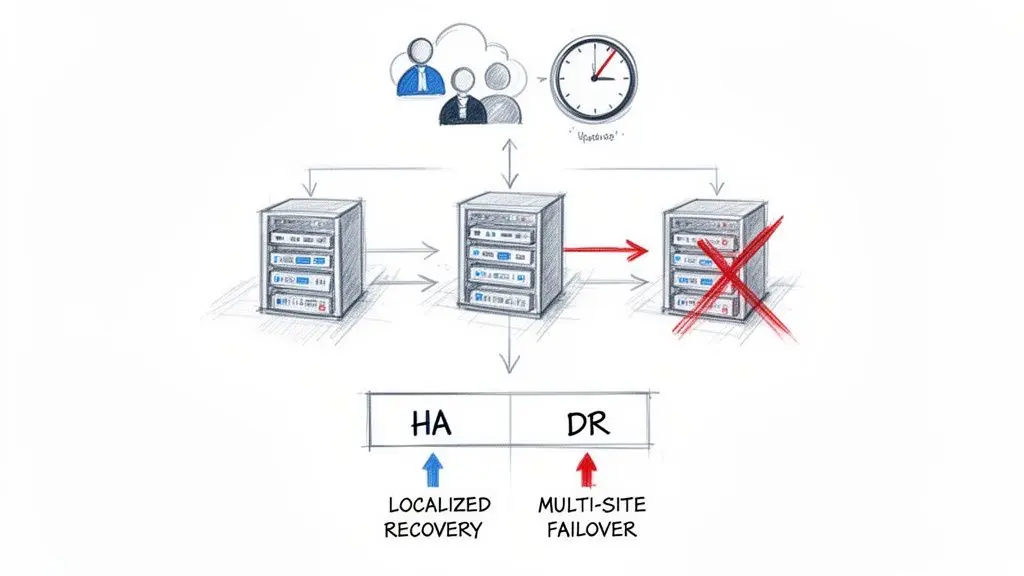
Un malinteso comune e pericoloso è confondere l’alta disponibilità (HA) con il disaster recovery (DR). Sono concetti correlati, ma risolvono problemi fondamentalmente diversi. Riconoscere questa distinzione è il primo passo per costruire una reale resilienza del sistema.
-
Alta disponibilità (HA) è la difesa contro guasti di piccola scala e localizzati. Questo include il crash di un singolo server, il guasto di un’istanza di database o un malfunzionamento del load balancer. Le architetture HA utilizzano la ridondanza—tipicamente all’interno di un singolo data center o di una singola zona di disponibilità—per mantenere la continuità del servizio senza un impatto percepibile per l’utente.
-
Disaster Recovery (DR) affronta eventi catastrofici su larga scala. Questo include il guasto completo di un data center, un’interruzione regionale del cloud provider o un attacco ransomware che compromette un intero ambiente. Un piano DR presuppone che il sito operativo primario non sia più disponibile e definisce il processo di failover verso una posizione secondaria geograficamente separata.
Un sistema può essere altamente disponibile ma non avere alcun piano di disaster recovery. Affidarsi a gruppi di auto-scaling o a server ridondanti all’interno di una sola regione non offre alcuna protezione quando quell’intera regione va offline.
I driver di business e i compromessi fondamentali
La spinta verso una strategia DR robusta va oltre le best practice ingegneristiche. I moderni framework di conformità ora impongono la resilienza operativa come requisito legale. Regolamenti come il Digital Operational Resilience Act (DORA) nel settore finanziario e NIS2 per le infrastrutture critiche richiedono esplicitamente alle organizzazioni di dimostrare la propria capacità di riprendersi da gravi interruzioni.
Ogni strategia di disaster recovery rappresenta un compromesso tra tre fattori interdipendenti:
- Velocità di ripristino: il tempo massimo accettabile per il ripristino del sistema.
- Perdita di dati: il volume massimo di dati recenti che l’azienda può permettersi di perdere in modo permanente.
- Costo: il budget per l’infrastruttura e l’overhead operativo necessari a raggiungere gli obiettivi di ripristino.
Definire questi parametri è una decisione di business, non un compito ingegneristico. Questa decisione determinerà l’intero approccio tecnico. Le sezioni seguenti illustrano come definire questi obiettivi e selezionare i modelli architetturali appropriati per raggiungerli.
Definire gli obiettivi di ripristino e il budget
Prima che un team di ingegneria scriva una riga di codice o provisioni qualsiasi infrastruttura, il business deve rispondere a una domanda fondamentale: che cosa significa “ripristino” in senso quantificabile? Un piano di disaster recovery costruito sull’ambiguità è solo un esercizio teorico. L’intera strategia si basa su due metriche specifiche che traducono le esigenze di business in vincoli tecnici.
Queste metriche sono il Recovery Time Objective (RTO) e il Recovery Point Objective (RPO). Non si tratta di gergo tecnico; sono decisioni aziendali critiche con importanti implicazioni tecniche e finanziarie.
Comprendere RTO e RPO
I concetti sono semplici, ma il loro impatto è profondo.
-
Recovery Time Objective (RTO): è la durata massima accettabile per cui un’applicazione può rimanere offline dopo un disastro. Risponde alla domanda: “In quanto tempo dobbiamo tornare operativi?”
-
Recovery Point Objective (RPO): definisce la quantità massima di perdita di dati che l’azienda può tollerare, misurata nel tempo. Risponde alla domanda: “Quanti dati del periodo immediatamente precedente al disastro possiamo permetterci di perdere?”
Applichiamo questo a uno scenario reale. Consideriamo un’azienda SaaS B2B che offre uno strumento di project management.
Scenario di esempio: Il team dirigenziale stabilisce che i clienti tollereranno un downtime massimo di un’ora. Qualsiasi durata superiore rischia violazioni contrattuali e danni alla reputazione. Questo stabilisce un RTO di 1 ora.
Il team analizza anche i modelli di utilizzo dei dati. Conclude che perdere più di cinque minuti di nuovi commenti, caricamenti di file e aggiornamenti delle attività creerebbe un problema di integrità dei dati irrecuperabile per i clienti. Questo fissa il loro RPO a 5 minuti.
Con questi due valori, la missione non è più un astratto “costruire un piano DR”. Diventa una sfida ingegneristica concreta: “progettare un sistema che possa essere ripristinato بالكامل entro 60 minuti con non più di 5 minuti di perdita di dati”.
Come RTO e RPO guidano architettura e costi
La relazione tra questi obiettivi e la spesa cloud è diretta e inflessibile. Ridurre RTO e RPO—richiedendo un ripristino più rapido e una minore perdita di dati—aumenta in modo esponenziale la complessità architetturale e i costi.
Raggiungere un downtime quasi nullo e una perdita di dati pari a zero è tecnicamente possibile con i moderni servizi cloud, ma il costo può essere di ordini di grandezza superiore rispetto a una strategia più moderata. Questo è il compromesso centrale che ogni founder e CTO deve gestire: bilanciare il costo del downtime con il costo della prevenzione. Un RTO di quattro ore può essere accettabile per una piattaforma di analisi interna, ma sarebbe catastrofico per un servizio di elaborazione pagamenti rivolto ai clienti.
La tabella seguente illustra questa relazione, mappando gli obiettivi di ripristino a specifici modelli architetturali e ai loro costi relativi. Comprendere questo spettro è fondamentale per prendere una decisione pragmatica che allinei gli obiettivi di resilienza al budget.
Come RTO e RPO influenzano architettura e costi
| Livello di ripristino | Esempio RTO / RPO | Modello architetturale | Costo cloud relativo | Caso d’uso |
|---|---|---|---|---|
| Priorità bassa | 24 ore / 24 ore | Backup e ripristino | Basso | Strumenti interni, ambienti di sviluppo, sistemi non critici. |
| Critico per il business | 1-4 ore / < 1 ora | Pilot Light | Medio | Applicazioni SaaS core, piattaforme e-commerce, servizi B2B. |
| Mission Critical | < 15 min / < 5 min | Warm Standby (scalato) | Alto | Applicazioni ad alto traffico con un impatto significativo sui ricavi diretti. |
| Zero downtime | Secondi / quasi zero | Hot Standby (attivo-attivo) | Molto alto | Piattaforme di trading finanziario, gateway di pagamento, infrastrutture critiche. |
In definitiva, selezionare un RTO e un RPO è un esercizio di gestione del rischio. Definendo questi obiettivi fin dall’inizio, fornisci ai team tecnici vincoli chiari, consentendo loro di progettare una soluzione di disaster recovery tecnicamente solida e finanziariamente sostenibile.
Esplorare i pattern di disaster recovery nel cloud
Una volta definiti RTO e RPO, il passo successivo è selezionare un modello architetturale che soddisfi questi obiettivi senza superare il budget. I provider cloud offrono un toolkit flessibile per il disaster recovery, e la maggior parte delle strategie rientra in uno dei quattro pattern principali. Questi si collocano su uno spettro: dal costo ridotto e dal ripristino lento al ripristino quasi istantaneo con un costo premium.
La chiave è abbinare l’implementazione tecnica alla realtà di business. Uno strumento di reporting interno non richiede una costosa architettura active-active, così come un gateway di pagamento globale non può affidarsi ai backup notturni.
Backup e ripristino
Questo è il pattern DR più fondamentale ed economico. Il principio è semplice: eseguire regolarmente il backup dei dati e della configurazione dell’applicazione in una posizione durevole fuori sede. In un contesto cloud, ciò comporta tipicamente l’archiviazione di snapshot del database e delle macchine virtuali in servizi di object storage come Amazon S3, Azure Blob Storage, o Google Cloud Storage.
In uno scenario di disastro, il processo di ripristino è manuale. Un ingegnere deve provisionare una nuova infrastruttura in una regione secondaria, distribuire l’applicazione dai backup di configurazione e quindi ripristinare i dati dall’ultimo snapshot disponibile.
- Casi d’uso: ideale per ambienti di sviluppo, strumenti interni e applicazioni con RTO e RPO flessibili (ad es. 12–24 ore).
- Compromessi: il principale vantaggio è il basso costo, poiché si paga solo per l’archiviazione. Il principale svantaggio è un RTO elevato; il ripristino può richiedere ore, a seconda del volume di dati e della complessità dell’infrastruttura. L’RPO è determinato dalla frequenza dei backup: una pianificazione di backup giornaliera implica una potenziale perdita di dati fino a 24 ore.
Questo diagramma mostra come le esigenze di business per RTO e RPO plasmino direttamente le tue scelte architetturali e, in definitiva, i tuoi costi.
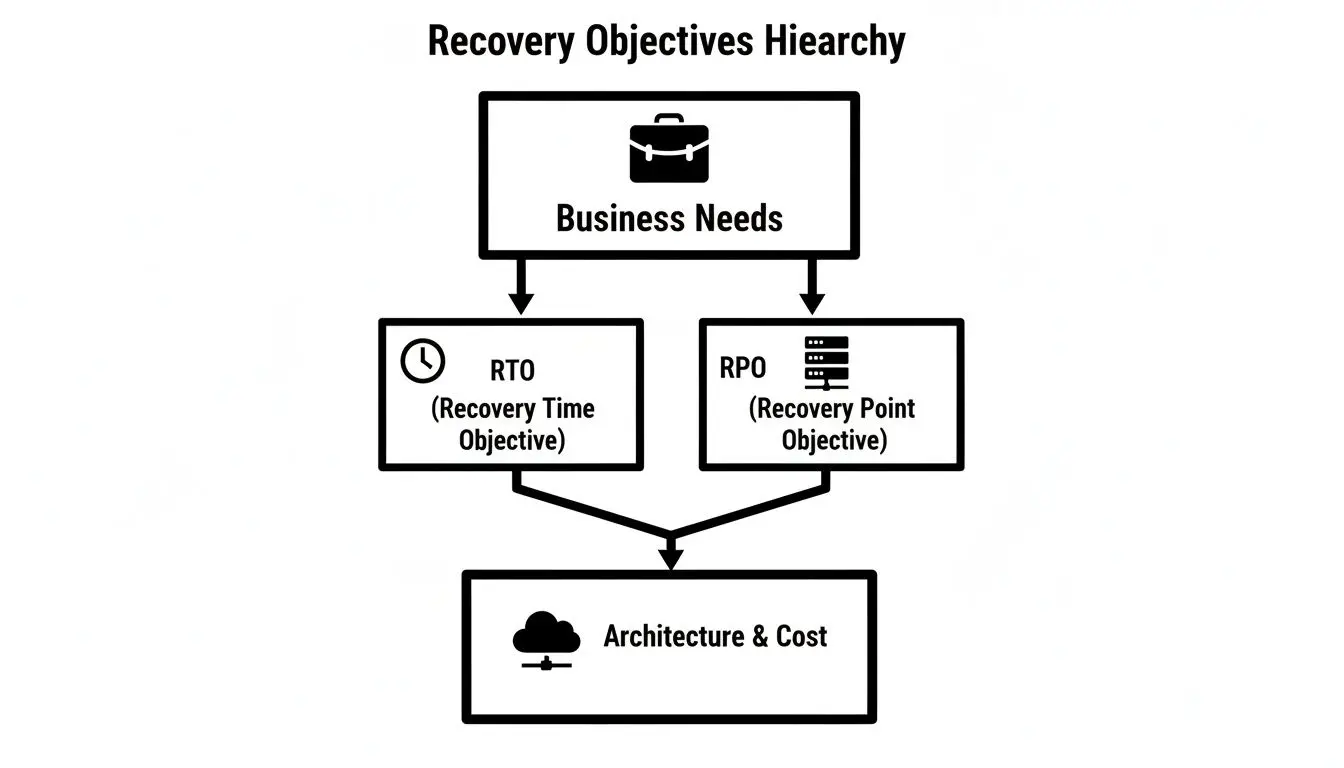
La gerarchia è chiara: i requisiti di business definiscono la strategia tecnica e i relativi costi.
Il pattern Pilot Light
Il pattern Pilot Light offre un compromesso equilibrato tra costo e velocità di ripristino. Il concetto centrale è mantenere sempre una versione minima e scheletrica dell’infrastruttura nella regione di recupero. Questa “pilot light” include componenti critici, come una piccola istanza di database che replica continuamente i dati dalla regione primaria.
Durante un disastro, “si accende la fiamma” scalando i server dell’applicazione, aggiornando il DNS per indirizzare il traffico verso la regione di recupero e promuovendo la replica del database a nuovo primario.
- Casi d’uso: una scelta valida per applicazioni critiche per il business in cui è accettabile un RTO da minuti a poche ore.
- Compromessi: i costi sono superiori rispetto a Backup e ripristino perché parte dell’infrastruttura è in esecuzione 24/7. Tuttavia, l’RTO è significativamente più basso perché i dati e i servizi principali sono già presenti. L’RPO è in genere molto basso (minuti o persino secondi) grazie alla replica quasi continua del database.
L’approccio Warm Standby
Spostandosi verso l’alto nello spettro della resilienza, il pattern Warm Standby mantiene una copia ridotta ma completamente funzionante dell’ambiente di produzione in una regione secondaria. A differenza del Pilot Light, tutti i servizi sono operativi, ma vengono provisionati con una capacità inferiore per contenere i costi.
Ad esempio, il gruppo di auto-scaling di produzione potrebbe eseguire dieci istanze grandi, mentre la regione warm standby opera con solo due istanze piccole. Al momento del failover, il traffico viene reindirizzato e l’infrastruttura di standby viene immediatamente scalata per gestire il carico completo di produzione. Questa transizione è molto più rapida del Pilot Light perché l’applicazione è già in esecuzione. L’efficienza del recovery cloud-native offre un vantaggio significativo rispetto alle soluzioni tradizionali on-premise. Un’analisi più approfondita di queste differenze architetturali è disponibile nella nostra guida su cloud computing vs on-premise solutions. La capacità di ripristinare più rapidamente è un fattore chiave che guida l’adozione del cloud nei settori regolamentati.
Il pattern Hot Standby (Active-Active)
Questo è il livello più elevato di resilienza. Un Hot Standby, spesso implementato come architettura active-active o multi-sito, prevede l’esecuzione simultanea di ambienti di produzione completi in due o più regioni geograficamente separate. Un bilanciatore del carico globale distribuisce il traffico tra esse, indirizzando gli utenti alla località più vicina o più sana.
Se una regione va in errore, il bilanciatore del carico reindirizza automaticamente tutto il traffico verso le regioni sane rimanenti. Non è richiesto alcun intervento manuale.
Una vera architettura Hot Standby comporta un failover quasi istantaneo, spesso impercettibile per gli utenti finali. Questo pattern offre il RTO e l’RPO più bassi possibili, tipicamente misurati in secondi.
- Casi d’uso: Essenziale per sistemi mission-critical in cui qualsiasi downtime ha conseguenze gravi, come piattaforme di transazioni finanziarie, sistemi di prenotazione aerea e servizi infrastrutturali core.
- Compromessi: Il vincolo principale è il costo. Questo pattern raddoppia di fatto la spesa infrastrutturale e introduce una complessità operativa significativa, in particolare per il mantenimento della consistenza dei dati tra i siti attivi. Tuttavia, per le aziende in cui il costo del downtime è eccezionalmente elevato, questa architettura rappresenta un investimento necessario.
Da un piano teorico a una capacità comprovata
Un piano di disaster recovery che esiste solo come documento PDF è una responsabilità, non una risorsa. Durante una crisi reale—un’interruzione regionale o un guasto critico del servizio—la pressione operativa è enorme. In ambienti ad alto stress, le procedure manuali di recovery sono soggette a fallimenti dovuti a errore umano, passaggi mancati o panico.
Per costruire una vera resilienza, un piano teorico deve essere trasformato in una capacità comprovata e testata. Questa trasformazione si basa su due pilastri: automazione e test rigorosi. Una strategia DR non testata offre un falso senso di sicurezza che svanirà nel momento in cui sarà più necessaria.
Automatizzare il recovery con Infrastructure as Code
La base di un processo DR affidabile è Infrastructure as Code (IaC). Aspettarsi che un engineer provisioni manualmente server, configuri reti e distribuisca servizi a memoria durante un’interruzione è la ricetta per un downtime prolungato e per la configurazione drift.
Strumenti come Terraform, AWS CloudFormation o Azure Resource Manager consentono di definire l’intera infrastruttura in file di configurazione dichiarativi. Questo codice diventa la fonte unica di verità per l’architettura dell’ambiente di produzione.
Durante un failover, non segui una checklist di clic nella console; esegui uno script. Questo cambia radicalmente il processo di recovery:
- Coerenza: L’ambiente di recovery è una replica esatta e priva di errori del sito primario.
- Velocità: Provisionare uno stack completo tramite IaC è ordini di grandezza più veloce rispetto agli interventi manuali.
- Ripetibilità: L’ambiente può essere smantellato e ricreato in modo coerente, aspetto essenziale per un testing efficace.
L’obiettivo è automatizzare il processo di failover fino a renderlo routinario. Se la tua procedura di disaster recovery è un evento drammatico, che richiede la presenza di tutti, non è sufficientemente matura.
Creare runbook eseguibili
I runbook statici in documenti Word diventano rapidamente obsoleti e sono impraticabili durante una crisi. Un runbook moderno ed efficace non è un documento da leggere; è uno script da eseguire. Dovrebbe consistere in una serie di comandi automatizzati, chiamate API e template IaC.
Un runbook robusto è una componente viva del tuo codebase, versionata in Git e aggiornata insieme all’applicazione. Deve coprire l’intero ciclo di vita del failover, dalla decisione di dichiarare un disastro fino ai controlli finali di validazione che confermano il ripristino del servizio. Trattare i runbook come codice garantisce che rimangano aggiornati e soggetti agli stessi standard di revisione dell’applicazione stessa. Questo principio di workflow automatizzati e versionati è anche centrale nel nostro approccio alla costruzione di solidi CI/CD pipelines.
La necessità di test rigorosi e regolari
Un piano non testato è un piano inutile. L’unico modo per verificare che una strategia di disaster recovery funzioni è eseguirla. I test regolari fanno emergere dipendenze nascoste, configurazioni obsolete e ipotesi errate prima che possano causare un guasto durante un’interruzione reale.
Tipi di esercitazioni di Disaster Recovery:
- Tabletop Exercise: Una simulazione a basso impatto in cui il team percorre verbalmente il runbook passo dopo passo. È un modo efficace per individuare lacune logiche e confermare che i membri del team comprendano i propri ruoli e responsabilità.
- Test di guasto di componenti: Rompere deliberatamente un componente non critico in un ambiente di recovery isolato. Questo valida che gli script automatizzati di rilevamento e remediation funzionino come previsto.
- Esercitazioni di failover completo: Il test definitivo. Consiste nel simulare un guasto regionale completo reindirizzando una parte del traffico live (o tutto il traffico) verso il sito di standby. Questo è l’unico metodo per validare veramente il tuo RTO e RPO in condizioni reali.
Svolgere questi test con regolarità—trimestralmente per gli esercizi tabletop e i test dei componenti, e almeno una volta l’anno per un’esercitazione completa—costruisce la “memoria muscolare” di cui il team ha bisogno. Trasforma il disaster recovery da una procedura di emergenza temuta in una disciplina operativa praticata.
DR per sistemi AI e ad alta intensità di dati
Il problema dei piani tradizionali di disaster recovery è che sono inadeguati per le modalità di guasto uniche dei moderni sistemi AI. I playbook progettati per applicazioni stateless e database standard falliscono quando si confrontano con data lake da petabyte, grandi database vettoriali o repository complessi di modelli ML.
La sfida inizia dal volume dei dati. Tentare di copiare terabyte di dati tra regioni durante una crisi è lento, costoso e impraticabile. Ciò genera un RPO inaccettabile e richiede strategie di replica e recovery più sofisticate, native della piattaforma dati.
Proteggere i dati e l’integrità dei modelli
Il rischio maggiore si estende oltre i dati grezzi, fino all’integrità dell’intera pipeline AI. Un recovery riuscito non riguarda solo il ripristino dei byte; riguarda la garanzia che il sistema produca risultati corretti e affidabili dopo il failover. Ciò richiede di mantenere una sincronizzazione perfetta tra i dati dell’applicazione, i modelli ML e i dati delle feature usati per l’addestramento.
La mancata conservazione di questa coerenza può portare a un sistema “ripristinato” che produce output insensati, distorti o errati. Per mitigare questo rischio, il piano DR deve affrontare:
- Versioning e replica dei modelli: Il model registry è un componente stateful critico. Deve essere trattato con la stessa importanza del database primario e replicato tra le regioni. Perdere la versione del modello in produzione rende l’applicazione inutilizzabile.
- Coerenza del feature store: Lo stato del feature store deve essere sincronizzato con i database dell’applicazione. Qualsiasi drift può portare a errori predittivi catastrofici dopo un failover.
- Recovery del database vettoriale: Per le applicazioni che usano semantic search o Retrieval-Augmented Generation (RAG), il database vettoriale è mission-critical. Il suo piano di recovery deve garantire che gli embedding siano perfettamente allineati con il contenuto sorgente per evitare di rendere inutile la funzionalità di ricerca.
Costruire resilienza per le dipendenze da API di terze parti
Molte applicazioni AI dipendono da API di terze parti fornite da provider come OpenAI, Anthropic o Google, creando una dipendenza critica al di fuori del controllo dell’organizzazione. Un’interruzione presso uno di questi provider può disabilitare funzionalità core dell’applicazione.
Una strategia DR robusta deve tenere conto di questo rischio legato al provider. Aspettare passivamente che la terza parte risolva il problema non è una strategia.
Affidarsi a un singolo provider AI senza un fallback è una vulnerabilità architetturale critica. La domanda non è se l’API avrà un’interruzione, ma cosa farà il tuo sistema quando ciò accadrà.
Le strategie efficaci per gestire questo rischio di dipendenza includono:
- Implementare circuit breaker: Questo pattern di progettazione rileva automaticamente quando un’API esterna sta fallendo e sospende temporaneamente le richieste, impedendo che l’applicazione venga sopraffatta dai timeout.
- Progettare i fallback: Progettare il sistema per eseguire il failover verso un modello o provider alternativo. Se l’API LLM primaria non è disponibile, le richieste possono essere instradate verso un modello secondario, anche se offre prestazioni leggermente inferiori.
- Degradazione graduale delle funzionalità: Se un fallback non è fattibile, il sistema dovrebbe degradare in modo controllato. Invece di mostrare un errore criptico, potrebbe disabilitare temporaneamente la funzionalità basata su AI e notificare l’utente, consentendo al resto dell’applicazione di rimanere operativo.
Al contrario, l’AI può anche migliorare le capacità DR. Il machine learning può essere usato per l’analisi predittiva dei guasti e per lo spostamento automatizzato dei carichi di lavoro, un fattore chiave alla base della crescente analisi del mercato del disaster recovery basato su cloud.
Queste modalità di guasto uniche sono fondamentali da affrontare durante la progettazione del sistema. La nostra gratuita AI Risk & Privacy Checklist è stata sviluppata per aiutare i team a identificare e mitigare questi rischi specializzati.
Bilanciare conformità e costi
Per qualsiasi CTO o responsabile della compliance, una strategia di disaster recovery è un artefatto aziendale critico che deve soddisfare sia i regolatori sia il dipartimento finanziario. Un’architettura tecnicamente robusta ma non conforme o finanziariamente insostenibile è una strategia fallita.
Le normative moderne non si limitano a suggerire la resilienza; la richiedono. Framework come GDPR, NIS2 e DORA includono requisiti specifici e legalmente vincolanti per la continuità operativa e la protezione dei dati. Un piano DR deve dimostrare la capacità di mantenere la resilienza operativa e proteggere l’integrità dei dati durante un guasto.
Progettare per la sovranità dei dati e la regolamentazione
La compliance deve essere parte integrante dell’architettura DR, non un ripensamento. Ciò richiede un’attenta considerazione della residenza e del trattamento dei dati, anche durante un’emergenza.
- GDPR e sovranità dei dati: I requisiti del GDPR seguono i dati dei cittadini dell’UE ovunque vengano trattati. Un sito di recovery deve offrire lo stesso livello di protezione dei dati del sito primario. Eseguire il failover verso una regione DR al di fuori dell’UE, ad esempio, potrebbe costituire un trasferimento di dati ad alto rischio e non conforme, attirando l’attenzione delle autorità di regolamentazione.
- DORA e resilienza operativa: Per il settore dei servizi finanziari, DORA è esplicito. Richiede alle aziende non solo di avere un piano DR, ma di testarlo regolarmente per dimostrare che le funzioni aziendali critiche possano essere ripristinate entro tempi predefiniti. Un piano non testato è un piano non conforme.
Un’architettura che esegue il failover verso una regione non conforme non risolve un disastro. Trasforma una crisi tecnica in una legale. La strategia di DR deve rispettare i confini geografici e giuridici associati ai dati che protegge.
Gestire i costi del cloud in modo sostenibile
Sebbene la resilienza non sia negoziabile, un’implementazione ingenua può portare a costi cloud insostenibili. Un sito hot-standby che replica l’ambiente di produzione replica anche il suo costo, raddoppiando di fatto la spesa infrastrutturale. La governance finanziaria è essenziale per rendere una strategia di DR sostenibile nel lungo periodo.
Le piattaforme cloud forniscono numerosi meccanismi per controllare i costi senza compromettere gli obiettivi di ripristino.
Le strategie pratiche di ottimizzazione dei costi includono:
- Usare Reserved Instances o Savings Plans: per le risorse di calcolo che devono essere eseguite continuamente (come nei pattern Pilot Light o Warm Standby), impegnarsi in un piano da uno o tre anni può garantire sconti significativi rispetto ai prezzi on-demand.
- Sfruttare architetture serverless: ove possibile, utilizzare funzioni serverless (ad es. AWS Lambda o Azure Functions) e servizi gestiti. Questo riduce al minimo il costo delle risorse inattive, poiché si paga solo per l’esecuzione durante un test o un failover effettivo.
- Implementare tagging e monitoraggio rigorosi: non si può controllare ciò che non si misura. Taggare meticolosamente tutte le risorse legate al DR per tracciarne i costi. Configurare avvisi di fatturazione per rilevare anomalie di spesa prima che diventino problemi significativi.
La rapida crescita del mercato Disaster Recovery as a Service (DRaaS) sottolinea la necessità di bilanciare resilienza ed efficienza dei costi. Si prevede che il mercato si espanderà significativamente, spinto dalla domanda di soluzioni cloud pubbliche efficienti, come dettagliato nelle recenti statistiche e tendenze sul disaster recovery. Questo cambiamento del settore riflette una tendenza verso soluzioni di DR scalabili, conformi e finanziariamente pragmatiche.
Costruire la resilienza fin dalla progettazione
Un disaster recovery efficace non è un prodotto aggiuntivo; è una caratteristica intrinseca di un sistema ben progettato. Il processo inizia con una discussione a livello di business per definire il Recovery Time Objective (RTO) e il Recovery Point Objective (RPO). Queste due metriche fungono da vincoli primari per tutte le decisioni tecniche successive, dettando la complessità architetturale, la prontezza operativa e il costo.
Principi fondamentali per un’architettura resiliente
Esiste uno spettro di pattern architetturali, dal Backup and Restore all’Hot Standby, per soddisfare questi obiettivi di RTO e RPO, ciascuno con un diverso profilo di costo. La scelta corretta è un compromesso deliberato tra il livello di resilienza richiesto e il budget disponibile.
Tuttavia, un pattern scelto è utile solo se si dimostra che funziona. Una strategia di DR efficace deve essere automatizzata con Infrastructure as Code (IaC) e convalidata tramite test regolari e rigorosi. Un piano DR non testato crea un falso senso di sicurezza che è, di fatto, equivalente ad avere nessun piano.
Il disaster recovery è una capacità operativa, non un documento statico. Richiede automazione per eliminare l’errore umano sotto pressione e test incessanti per costruire la memoria muscolare dell’organizzazione.
Infine, i sistemi moderni presentano sfide uniche. Le applicazioni AI e ad alta intensità di dati richiedono strategie di ripristino specializzate che affrontino la coerenza dei dati, l’integrità del modello e le dipendenze da API di terze parti.
La conclusione è chiara: la resilienza deve essere una scelta progettuale consapevole. Richiede di bilanciare un’implementazione tecnica precisa con le realtà pratiche del business, assicurando che i sistemi siano progettati non solo per funzionare, ma per sopravvivere.
At Devisia, aiutiamo le organizzazioni a integrare la resilienza direttamente nell’architettura del loro software. Se avete bisogno di un partner tecnico per progettare e implementare una strategia di disaster recovery pragmatica, manutenibile e conveniente per i vostri prodotti digitali, possiamo aiutarvi.
Scopri di più sul nostro approccio alla costruzione di sistemi software affidabili su devisia.pro