
A familiar sequence plays out in product companies. A team ships a new AI feature, perhaps semantic search, support summarisation, or document analysis through a third-party model API. A few weeks later, legal forwards a formal letter from a supervisory authority. The request isn’t abstract. It asks for the lawful basis, the data flow map, the retention logic, the processor chain, and evidence that the system was designed to minimise personal data exposure.
At that point, the roadmap stops being the main problem. The primary problem is that engineering now has to explain a live system under regulatory time pressure. If the architecture is opaque, if logs are incomplete, or if nobody can say exactly what leaves the EEA and why, art 58 gdpr becomes very concrete very quickly.
Article 58 represents the point where GDPR transitions from policy language into operational power. Authorities can ask for information, inspect systems and premises, order changes, suspend processing, and escalate to fines. For founders and CTOs, that means privacy risk isn’t just a legal line item. It affects release velocity, vendor selection, data architecture, incident response, and market access.
The teams that cope best are rarely the ones with the longest policy library. They’re the ones whose systems are understandable. They can show what data is collected, where it goes, who can access it, and what controls exist around high-risk processing. They treat privacy as an engineering property, much like observability or resilience.
That’s also why DPO design and reporting lines matter earlier than many startups expect. If you need a practical view of that role, this guide to GDPR Article 37 and DPO obligations is a useful companion.
The Article 58 Knock on the Door
The first shock in an Article 58 interaction is usually not the legal theory. It’s the operational disruption.
A product manager wants to keep a release on track. An engineering lead needs developers to finish a migration. Then a supervisory authority asks for detailed answers about a feature that was built across several sprints by multiple teams, with one vendor swapped mid-project and a prompt layer added late in QA. Suddenly, people who never expected to write compliance evidence are reconstructing design decisions from tickets, pull requests, and old Slack threads.
What the request usually exposes
The request itself often reveals basic weaknesses in how the company builds software:
- No reliable system inventory: Teams know the main application but not every background worker, analytics event, webhook, or support integration.
- Weak data lineage: Personal data enters through one interface and then appears in logs, embeddings stores, CRM syncs, and support tools without a single owner tracking the full path.
- Vendor assumptions: Someone assumed a subprocesser list or standard terms solved the problem, without checking what technical safeguards exist.
- AI blind spots: The team can describe the user experience, but not the training inputs, prompt handling, model outputs, or storage behaviour of the underlying service.
Practical rule: If your engineers can’t explain a processing flow on a whiteboard in ten minutes, they probably can’t defend it in an investigation either.
For software businesses, this isn’t a niche concern. Article 58 has applied since 25 May 2018, and it gives supervisory authorities broad investigative, corrective, and advisory powers across the EU. In Italy, where there are over 85,000 software and IT services companies according to the verified data summary, those powers have obvious relevance to SaaS platforms, custom web applications, and AI-enabled services.
Why CTOs should treat this as a continuity issue
The common mistake is to see privacy enforcement as a remote legal risk. In practice, Article 58 can pull senior engineers, security staff, legal counsel, product owners, and operations teams into the same urgent workstream.
That has consequences beyond the formal response:
- sprint plans get reworked
- deployments on affected systems may need review or pause
- vendor contracts become architectural constraints
- customer assurances suddenly need technical proof
- weak documentation turns into expensive internal investigation
The immediate lesson is simple. By the time a regulator asks questions, your architecture is already speaking for you. If it was designed for speed alone, the gaps show up fast.
A Technical Breakdown of Supervisory Authority Powers
Article 58 groups supervisory authority powers into three buckets: investigative, corrective, and authorisation or advisory powers. For engineering leaders, that translates into three operational questions. What can a regulator demand from the system? What can they force the company to change? What signals are they giving about designs they are more likely to accept?
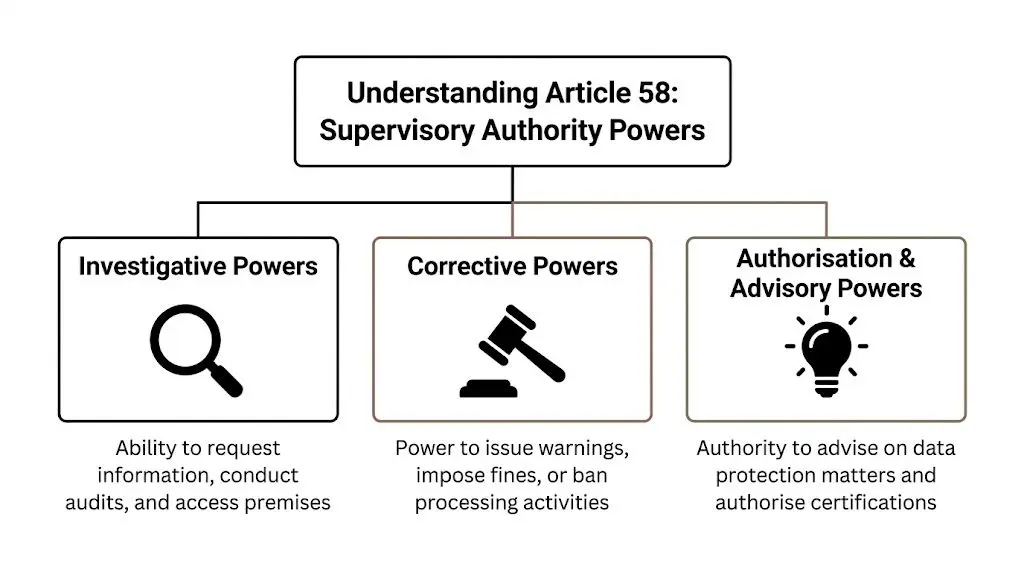
Investigative powers in system terms
Investigative powers hit the parts of the stack that teams often leave undocumented. Authorities can require information, obtain access to personal data and documentation, carry out audits, and inspect facilities. In a modern software business, that reaches far beyond a privacy notice or a RoPA entry. It can include event pipelines, support tooling, model inputs, backup retention, subprocessors, and the controls around all of them.
For a CTO, “provide information” usually means producing evidence that matches production reality:
- Processing records: descriptions of processing that line up with actual services, datasets, and purposes
- Architecture diagrams: APIs, data stores, queues, regions, subprocessors, and admin interfaces
- Permission models: who can access raw data, derived data, exports, prompts, and model outputs
- Retention and deletion logic: scheduled deletion, legal holds, backups, and known exceptions
- AI system documentation: training sources, inference flows, human review steps, and logging boundaries
Weak system design quickly becomes apparent. If engineers cannot trace personal data from collection to deletion across vendors and internal services, the company is left arguing from assumptions. Regulators usually ask for proof.
That matters for AI products in particular. A team may know what the feature does from a user perspective while still lacking basic control over prompt storage, fine-tuning inputs, telemetry, shadow logs, or cross-border API calls to model providers. Article 58 gives authorities a route to ask for those details directly.
A regulator does not need your architecture to be elegant. They need it to be explainable, evidenced, and controllable.
Corrective powers and what they do to product plans
Corrective powers carry the sharp edge of Article 58. Authorities can issue warnings and reprimands, order a controller or processor to comply, require rectification or erasure, impose temporary or definitive limits on processing, suspend data flows, and trigger administrative fines under Article 83.
Each of those outcomes changes engineering priorities.
A warning often becomes a scheduled remediation programme with deadlines, ownership, and reporting. A reprimand can force product and security teams to rewrite controls that had been treated as acceptable risk. An order to change processing can mean redesigning data collection, feature logic, retention defaults, or customer-facing workflows. A suspension can disable a vendor integration or an entire feature path overnight.
The trade-off is usually speed versus reversibility. Teams ship faster when they centralise logging, copy production data into test environments, and push data into multi-purpose analytics or AI pipelines. Those choices also make corrective orders more expensive to implement because personal data is spread across more systems, more processors, and more jurisdictions.
A practical way to read the corrective powers is this:
| Power type | What it looks like in software |
|---|---|
| Warning | The service stays live, but the backlog gets regulator-driven remediation work |
| Reprimand | Non-compliance is on record, which can trigger customer, board, and procurement scrutiny |
| Order to change processing | Data collection, access patterns, retention rules, or user flows need redesign |
| Fine | The penalty is visible, but the larger cost is often engineering time, legal review, and delayed roadmap work |
| Suspension or ban | A feature, transfer route, or vendor dependency stops until the control gap is fixed |
Cross-border architecture is where this becomes very concrete. If a product relies on non-EEA hosting, support access from third countries, external telemetry, or LLM APIs that move prompts and outputs outside the EEA, a corrective order may require rerouting traffic, regionalising storage, changing providers, or turning off part of the service for EU users. That is an infrastructure problem, not a policy wording problem.
Advisory and authorisation powers also shape technical choices
Teams often ignore the softer side of Article 58 because it does not sound urgent. That is a mistake. Advisory and authorisation powers influence what controls authorities expect to see around certification mechanisms, contractual arrangements, and higher-risk processing patterns.
This affects design choices early. If two architectures deliver the same product outcome, the one with tighter purpose limitation, fewer onward transfers, clearer tenant separation, and reviewable decision logic is usually easier to defend. The same applies to AI-assisted systems. A model workflow that keeps sensitive attributes out of prompts, limits retention, records human overrides, and preserves an audit trail will generally create less enforcement risk than a loosely wrapped third-party model with broad logging and unclear downstream use.
What tends to hold up under scrutiny
Some technical patterns make Article 58 exposure easier to manage:
- Clear service boundaries: defined purposes, owners, and data contracts between systems
- Regional control: explicit storage and processing locations for EU data
- Auditable access: role-based access, approvals for exports, and logs that are retained long enough to investigate
- Deletion by design: retention rules implemented in code, not left to manual clean-up
- AI guardrails: prompt filtering, vendor assessments, output review paths, and separation between inference data and training data
Other patterns create avoidable risk:
- Hidden exports and support workarounds
- Shared datasets reused for analytics, testing, and model development
- Catch-all telemetry that captures personal data without a defined purpose
- Generic AI integrations where no one can state what is stored, where it goes, or who can retrieve it
The practical point is simple. Article 58 is not abstract regulator power sitting outside the product. It reaches directly into architecture, vendor selection, AI deployment, and cross-border data design. Teams that build for traceability and containment have more room to respond. Teams that build for speed without those controls usually end up reconstructing their own systems under pressure.
Anatomy of an Article 58 Investigation
The investigation usually begins on an ordinary weekday. Legal forwards a letter or email from a supervisory authority. The first request looks narrow, often framed as a request for information, but it immediately turns into an engineering problem because the authority is testing whether the company can describe its processing in a way that matches the system that is operational.
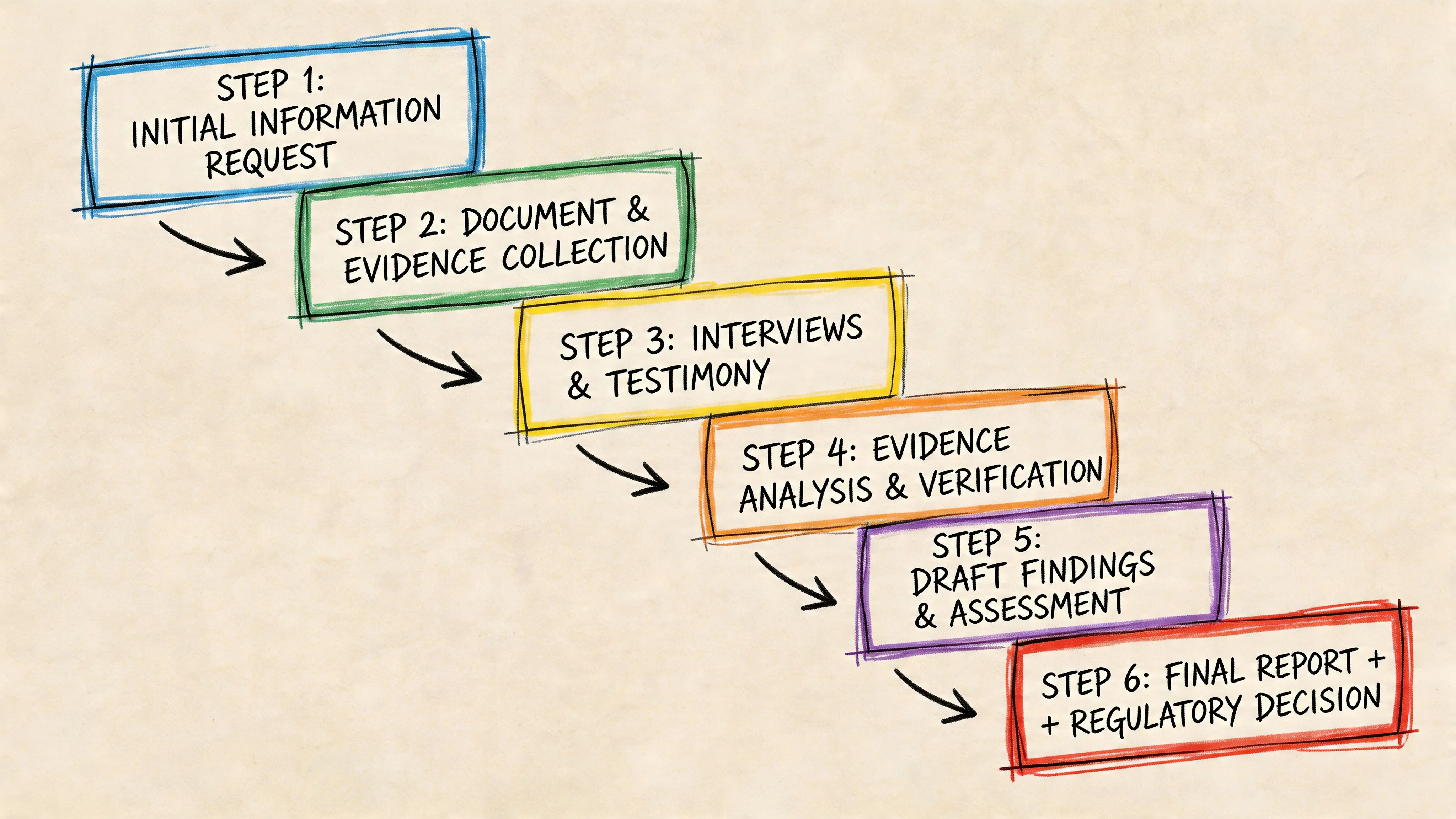
The request phase
The first submission deadline is where weak privacy engineering shows up.
Authorities typically ask for material that should already exist if privacy controls are part of delivery rather than a clean-up exercise after launch:
- RoPA material: what processing occurs, for which purposes, under which legal basis, and with which recipients
- DPIA evidence: especially for profiling, large-scale monitoring, sensitive data use, and AI-supported decisions
- Technical data flow maps: actual service-to-service flows, processors, storage regions, APIs, and transfer paths
- Control evidence: authentication, authorisation, retention, deletion, logging, and incident response
- Governance records: who approved the feature, what risks were raised, and how later changes were reviewed
The practical problem is drift. Product changes faster than documentation. Support gets an export path. Analytics adds a new event stream. An AI feature sends prompts to a vendor endpoint that was never added to the original review. By the time the authority asks for a clean account of processing, the company is trying to reconstruct six months of exceptions from tickets, Slack threads, Terraform history, and vendor settings.
What happens inside the company
An Article 58 investigation is never handled by privacy counsel alone. It pulls in the teams that built, operated, and changed the system.
| Team | What they’re typically asked for |
|---|---|
| Engineering | system architecture, data stores, logs, access paths, retention logic, integrations |
| Security | permission model, monitoring, control design, incident records, administrative access history |
| Product | feature purpose, defaults, user flows, release history, business justification |
| Legal or privacy | lawful basis, notices, contracts, processor terms, DPIAs, transfer analysis |
| Operations or support | export procedures, exception handling, account access practices, complaint records |
The failure mode is familiar. Each team has part of the answer, but no one has a current model of the whole processing chain. I see this most often in stacks where personal data crosses too many boundaries without strong contracts between services. Internal admin tools bypass normal controls. Event pipelines collect more than anyone intended. AI vendors receive prompts, files, or metadata through SDKs that engineering integrated quickly and never isolated behind an internal gateway.
That is where the investigation gets expensive. The cost is not only legal review. Senior engineers are pulled into evidence collection, log interpretation, and architecture explanation at the exact moment the company wants them shipping fixes.
A supervisory authority does not expect a flawless system. It does expect the company to know what personal data is processed, where it goes, why it is there, and who can access it.
How scope expands
Investigations widen when the initial answers are vague, inconsistent, or too polished to be credible.
If the authority asks how deletion works and gets a policy document instead of a deletion job, retention schedule, and proof from production systems, it will ask follow-up questions. If the company states that an AI feature does not train on user data, the authority may ask for the vendor contract, technical configuration, and internal review that supports that statement. If cross-border transfers are mentioned only at the contract level, the authority may ask for the actual services, regions, subprocessors, and fallback paths involved.
This is why retroactive compliance often fails. Teams write from the policy they meant to implement, not from the system they deployed.
Cross-border cases can involve more than one authority
CTOs sometimes assume that a lead supervisory authority will contain the process operationally. That is too optimistic, especially when local complaints, local users, or local harms are involved.
The legal position on non-lead authorities bringing proceedings under Article 58(5) has been examined by the Court of Justice of the European Union, and practical commentary on that point appears in this analysis of supervisory authority competence under Article 58(5). The operational takeaway is straightforward. A cross-border structure does not guarantee a single-threaded investigation. Product, legal, and engineering teams should prepare for requests that reflect both central governance questions and local enforcement concerns.
What holds up under pressure
The companies that handle Article 58 investigations best do not rely on last-minute documentation. They have evidence produced during normal delivery and operations:
- architecture diagrams updated with releases
- data classification in design reviews and tickets
- records of subprocessors and integrations tied to deployment reality
- logs that show access, export, deletion, and administrative actions
- documented technical reasons for exceptions, including AI vendor choices and transfer paths
An investigation is still disruptive. It always consumes time and leadership attention. But if the evidence already exists in engineering systems and review workflows, the company can answer questions with records instead of guesses.
Article 58 and Cross-Border Data Flow Suspensions
Among the powers in art 58 gdpr, the ability to suspend data flows is one of the most operationally disruptive. If your product depends on third-country services, especially AI APIs, a suspension can remove a core capability rather than merely add paperwork.
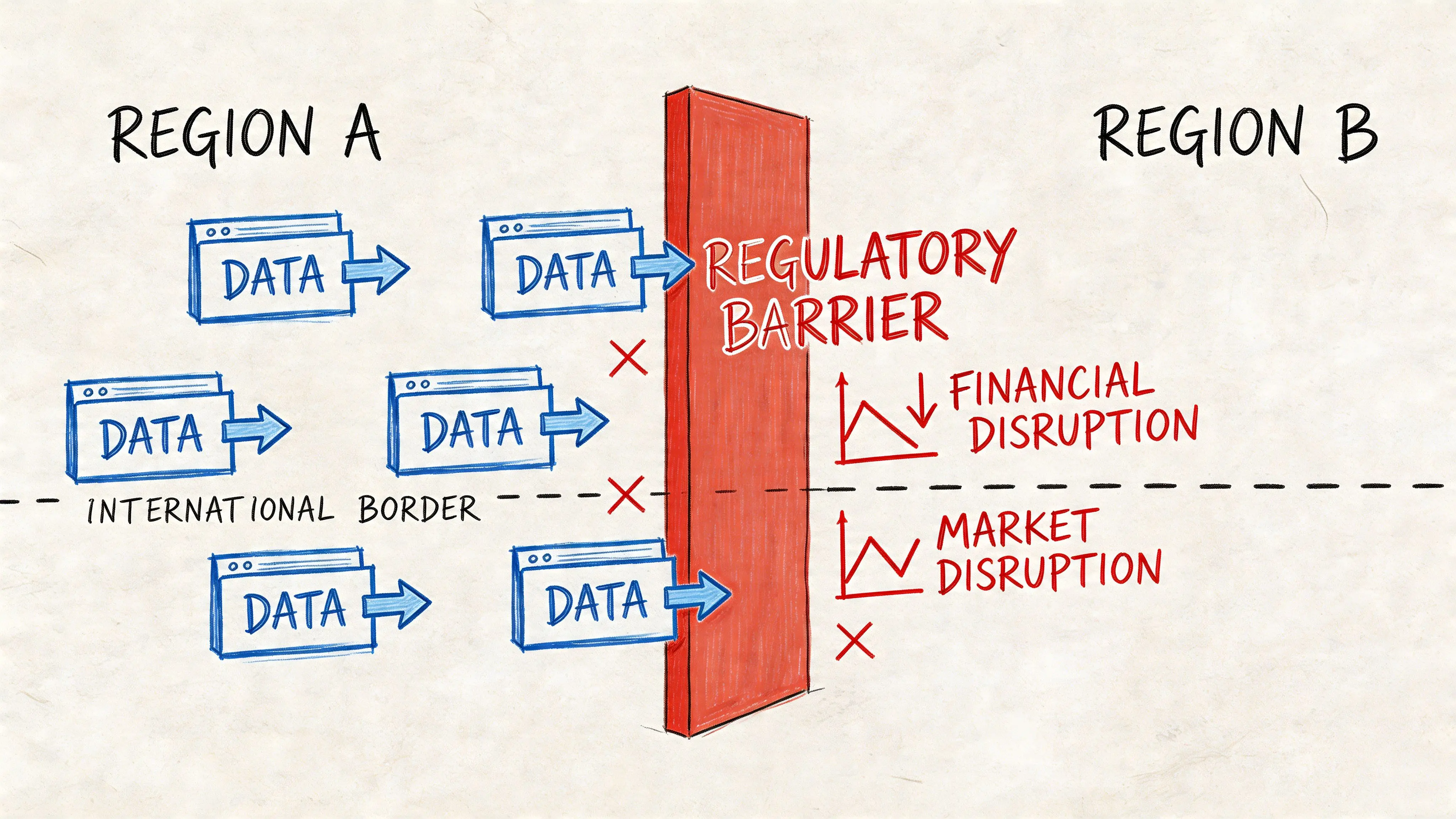
Why this power matters to modern stacks
Article 58(2)(j) allows authorities to order the suspension of data flows to third countries or international organisations. That’s directly relevant to products that send prompts, support tickets, images, transcripts, analytics events, or user profiles to services hosted outside the EEA.
This power is active in practice. Under the UK GDPR equivalent, the ICO suspended 15% of audited cross-border flows in 2024 due to inadequate safeguards. The 2023 Meta fine of €1.2B was directly related to this issue. The same verified data also states that a 2025 CNIL report found SaaS providers using rate-limited, EU-based proxies cut suspension risk by 75%, as summarised in the linked Fieldfisher note on Article 58 GDPR powers.
For engineering teams, the lesson is blunt. A transfer mechanism in a contract doesn’t fix a weak technical design.
What goes wrong in AI integrations
The risky pattern is common:
- a team adds a US-hosted model API
- prompts include raw user content
- metadata travels with identifiers
- logs and retries replicate the payload in several places
- nobody can show meaningful supplementary safeguards
This tends to happen because the integration is treated as a feature call, not a regulated transfer path. The code works. The architecture doesn’t.
Three weak assumptions show up again and again:
- “It’s only transient.” Temporary transmission can still be a transfer problem if personal data leaves the EEA without sufficient safeguards.
- “The vendor says they’re compliant.” That isn’t enough if your implementation sends more personal data than necessary.
- “We’ll redact later.” If redaction sits outside the critical path, it usually fails under real traffic and edge cases.
Patterns that reduce exposure
Better architectures usually place control at the boundary before data leaves the EEA.
| Pattern | Why it helps | Trade-off |
|---|---|---|
| EU-based proxy layer | centralises routing, filtering, and policy enforcement | adds latency and another operational component |
| Pseudonymisation or tokenisation before transfer | reduces direct identifiability in outbound payloads | can limit model utility if context is heavily transformed |
| Rate limiting and scoped endpoints | narrows uncontrolled data emission and lowers misuse risk | can constrain feature responsiveness |
| Regional processing split | keeps high-risk steps local and sends only reduced context onward | increases architectural complexity |
| Strict observability on outbound requests | makes transfer behaviour visible and reviewable | requires disciplined logging design to avoid logging sensitive payloads |
A practical design often uses an EU proxy to strip direct identifiers, apply policy checks, enforce rate limits, and maintain an auditable log of outbound categories rather than raw content. That isn’t a silver bullet, but it’s materially stronger than having each service call a third-country API directly.
A short explainer on transfer enforcement is useful here:
What authorities will want to see
If a transfer path is questioned, the strongest evidence tends to include:
- clear diagrams of outbound flows
- the exact categories of personal data sent
- why each category is necessary
- what technical transformation happens before transfer
- how the company monitors and limits those flows
- what fallback exists if the transfer path must stop
Systems that rely on direct third-country APIs with raw personal data and no abstraction layer are cheap to launch and expensive to defend.
The important trade-off is that transfer-safe architecture usually adds friction up front. But it gives the business options when regulators, customers, or procurement teams start asking hard questions.
How Authorities Scrutinise AI and Automated Systems
Many teams still frame GDPR risk around consent banners, privacy notices, and data subject requests. That’s too narrow for modern systems. Authorities increasingly care about how AI and automated processing work in production.
The black box defence doesn’t work
When an authority examines an AI-enabled feature under Article 58 powers, the questions move beyond front-end notices. They can include:
- what data enters the model or workflow
- whether the data was necessary for the stated purpose
- how outputs affect individuals
- what human review exists
- how errors, bias, or harmful outputs are detected
- whether the organisation can explain a particular result well enough to justify the processing
That applies across a wide range of systems. A recommender engine may shape what opportunities a user sees. A recruitment filter may influence who gets shortlisted. A support assistant may summarise or classify customer messages in ways that affect service quality or escalation.
What strong answers look like
A strong answer usually isn’t “the model vendor handles that”. It’s a combination of technical and governance evidence:
- Input controls: what data classes are allowed into prompts, embeddings, or model context
- Output constraints: how the system validates, filters, or routes generated content
- Human review design: when a person must confirm, override, or reject an automated output
- Testing records: how the team checked for harmful or unreliable behaviour in realistic scenarios
- Version traceability: which model, prompt template, workflow, or rule set produced a given output
The most useful discipline here is often a proper impact assessment before deployment. For teams working through that, this practical privacy impact assessment guide is a good starting point.
If an AI feature affects people in a meaningful way, “we can’t explain it” is not a technical answer. It’s a governance failure.
Common mistakes in AI product teams
A few patterns repeatedly create trouble:
| Mistake | Why it fails under scrutiny |
|---|---|
| Using production user data for evaluation without clear boundaries | purpose limitation and minimisation become hard to defend |
| Logging prompts and outputs by default | creates secondary personal data stores with poor retention discipline |
| No distinction between assistive and decision-shaping use | hides where human oversight is actually required |
| Treating vendor documentation as your entire control framework | leaves major gaps in accountability and implementation detail |
The useful mindset shift is that AI systems need privacy architecture, not just model orchestration. The better the team can trace inputs, reasoning steps, tool calls, outputs, and human interventions, the easier it is to answer regulatory questions in concrete terms.
A Pragmatic Compliance Checklist for Engineering Teams
If you want to be ready for Article 58 powers, don’t start with templates. Start with the system. The goal is to make the product explainable, auditable, and containable under pressure.
For teams trying to make that operational, Devisia’s guide to means of compliance is a useful companion to the checklist below.
Keep a living data map
Static privacy diagrams age badly. Your data map needs to track real systems, not idealised ones.
Include:
- entry points: forms, APIs, imports, support tools, telemetry
- transformation points: enrichment, classification, embeddings, exports
- storage layers: databases, object storage, queues, caches, search indexes
- egress paths: vendors, subprocessors, analytics, AI APIs, customer exports
The trade-off is maintenance effort. But without this, every investigation starts with internal fact-finding instead of response.
Log processing events, not just security events
Security logging is widespread. Fewer have privacy-relevant logging. You need records that show when personal data was accessed, exported, transformed, deleted, or sent to an external service.
Useful practice includes:
- separating metadata from sensitive payloads
- tracking actor, system, purpose, and destination
- retaining enough context to reconstruct decisions
- avoiding logs that become shadow datasets
A lot of teams often overcorrect. They either log too little to prove anything, or too much and create a second compliance problem.
Make AI flows inspectable
If you ship AI features, build observability around the workflow, not just the model call.
That usually means keeping a controlled record of:
- prompt template version
- model or service version
- tool invocation path
- guardrail or policy decisions
- human review events
- output disposition, such as shown, blocked, edited, or discarded
The point isn’t to preserve every piece of user content indefinitely. The point is to be able to explain how the system behaved and why.
Operational test: Pick one user-visible AI output from last week. If your team can’t trace how it was produced, your compliance posture is weaker than it looks.
Treat cross-border transfer controls as defaults
Don’t leave transfer mitigation to legal review after the integration is done. Build controls into the integration path:
- Route through a managed boundary. A proxy or gateway inside the EEA gives you one place to filter, redact, and enforce policy.
- Strip what the vendor doesn’t need. Names, emails, free-text identifiers, and full histories often travel out of convenience rather than necessity.
- Prepare a fallback mode. If a transfer path is challenged, the product should degrade predictably rather than fail chaotically.
This often costs more engineering time up front. It saves far more if a service needs to be swapped, regionalised, or paused.
Automate evidence where possible
The strongest compliance evidence is generated by routine engineering work. Pull it from systems already used to build and deploy.
Examples:
| Engineering source | Compliance value |
|---|---|
| Infrastructure as code | shows regions, services, network boundaries, and dependencies |
| Service catalogues | identifies owners, integrations, and data classes |
| CI pipelines | proves when controls ran and what was deployed |
| Schema annotations | helps derive personal data categories and retention flags |
| Ticket workflows | records approvals and risk decisions for feature changes |
A manual spreadsheet can still be useful. It shouldn’t be your only source of truth.
Run a regulator-readiness drill
Most organisations run incident exercises. Fewer simulate a regulatory request. They should.
A simple drill asks one cross-functional team to answer questions such as:
- show the full data flow for one high-risk feature
- identify all processors and subprocessors involved
- explain the lawful basis and retention logic
- produce evidence of safeguards for any external transfer
- demonstrate who can access the data and how that is audited
This exercise usually exposes the actual gap. It isn’t the absence of policy language. It’s the absence of fast, reliable evidence.
Give ownership to people who can change systems
Compliance work fails when ownership sits only with legal or only with security. Article 58 risk lives in architecture, delivery, and operations. The people responsible for services need clear accountability for data flows, retention, access design, and third-party integrations.
A practical model is to assign privacy ownership at service or domain level, backed by central guidance from privacy and security. That avoids the common pattern where everybody is consulted and nobody is responsible.
Conclusion Building Resilient Systems not Legal Defences
Article 58 matters because it turns GDPR into an operational reality. Supervisory authorities can ask for information, inspect how systems work, order changes, suspend problematic flows, and escalate when organisations can’t justify their processing. For software businesses, that reaches directly into product design and infrastructure choices.
The companies that handle this well don’t rely on polished after-the-fact narratives. They build systems that are easier to explain. Their data flows are mapped. Their integrations are bounded. Their AI features are observable. Their teams know which vendor receives what data and why. When a request arrives, they respond with evidence rather than reconstruction.
That’s the practical reading of art 58 gdpr for CTOs and product leaders. The issue isn’t whether the legal department can draft a response. The issue is whether engineering can stand behind the architecture under scrutiny.
The strongest long-term posture is straightforward:
- design for minimisation before data leaves your boundary
- make processing visible through usable logs and data maps
- add human control where automated systems affect people
- keep transfer safeguards in the default architecture, not as an afterthought
- test your ability to answer regulatory questions before you have to
Privacy isn’t a feature layer you bolt on near launch. It’s a property of systems that were designed to be legible, controlled, and maintainable. That’s also what makes them more resilient when enforcement becomes real.
If you’re building SaaS, AI-enabled workflows, or custom platforms and want privacy handled as an architectural concern from the start, Devisia helps teams design and deliver maintainable systems that are easier to operate, audit, and evolve under real regulatory pressure.