
Una sequenza familiare si ripete nelle aziende di prodotto. Un team rilascia una nuova funzionalità di IA, magari ricerca semantica, riepilogo dell’assistenza o analisi dei documenti tramite un’API di un modello di terze parti. Poche settimane dopo, l’ufficio legale inoltra una lettera formale di un’autorità di controllo. La richiesta non è astratta. Chiede la base giuridica, la mappa dei flussi di dati, la logica di conservazione, la catena dei responsabili del trattamento e le evidenze che il sistema sia stato progettato per minimizzare l’esposizione dei dati personali.
A quel punto, la roadmap smette di essere il problema principale. Il problema principale è che l’ingegneria ora deve spiegare un sistema in esercizio sotto pressione normativa e con tempi stretti. Se l’architettura è opaca, se i log sono incompleti o se nessuno sa dire esattamente cosa esce dallo SEE e perché, l’art. 58 del GDPR diventa molto rapidamente molto concreto.
L’articolo 58 rappresenta il punto in cui il GDPR passa dal linguaggio delle policy al potere operativo. Le autorità possono chiedere informazioni, ispezionare sistemi e sedi, ordinare modifiche, sospendere il trattamento ed elevare a più livello le sanzioni. Per founder e CTO, questo significa che il rischio privacy non è solo una voce legale. Influisce sulla velocità di rilascio, sulla selezione dei fornitori, sull’architettura dei dati, sulla risposta agli incidenti e sull’accesso al mercato.
I team che se la cavano meglio raramente sono quelli con la libreria di policy più lunga. Sono quelli i cui sistemi sono comprensibili. Possono mostrare quali dati vengono raccolti, dove vanno, chi può accedervi e quali controlli esistono intorno al trattamento ad alto rischio. Trattano la privacy come una proprietà dell’ingegneria, un po’ come l’osservabilità o la resilienza.
È anche per questo che la progettazione del DPO e le linee di riporto contano prima di quanto molte startup si aspettino. Se ti serve una visione pratica di quel ruolo, questa guida all’articolo 37 del GDPR e agli obblighi del DPO è un utile complemento.
Il colpo alla porta dell’articolo 58
Il primo shock in un’interazione ai sensi dell’articolo 58 di solito non è la teoria giuridica. È l’interruzione operativa.
Un product manager vuole mantenere il rilascio in linea con i tempi. Un responsabile di ingegneria ha bisogno che gli sviluppatori completino una migrazione. Poi un’autorità di controllo chiede risposte dettagliate su una funzionalità costruita in più sprint da più team, con un fornitore sostituito a metà progetto e uno strato di prompt aggiunto tardi in fase di QA. Improvvisamente, persone che non si aspettavano mai di scrivere evidenze di conformità stanno ricostruendo decisioni di progettazione da ticket, pull request e vecchi thread Slack.
Cosa di solito mette in evidenza la richiesta
La richiesta stessa spesso rivela debolezze di base nel modo in cui l’azienda sviluppa software:
- Nessun inventario affidabile dei sistemi: i team conoscono l’applicazione principale, ma non tutti i processi in background, gli eventi di analytics, i webhook o le integrazioni di supporto.
- Debole tracciabilità dei dati: i dati personali entrano da un’interfaccia e poi compaiono nei log, negli archivi di embedding, nelle sincronizzazioni con il CRM e negli strumenti di supporto senza un unico owner che ne segua l’intero percorso.
- Assunzioni sui fornitori: qualcuno ha dato per scontato che un elenco di subprocessori o termini standard risolvesse il problema, senza verificare quali misure tecniche di sicurezza esistano.
- Punti ciechi sull’IA: il team sa descrivere l’esperienza utente, ma non gli input di training, la gestione dei prompt, gli output del modello o il comportamento di conservazione del servizio sottostante.
Regola pratica: se i tuoi ingegneri non riescono a spiegare un flusso di trattamento su una lavagna in dieci minuti, probabilmente non riusciranno a difenderlo nemmeno in un’indagine.
Per le aziende software, non si tratta di una preoccupazione di nicchia. L’articolo 58 si applica dal 25 maggio 2018 e attribuisce alle autorità di controllo ampi poteri di indagine, correzione e consulenza in tutta l’UE. In Italia, dove ci sono oltre 85.000 aziende di software e servizi IT secondo il riepilogo dei dati verificati, questi poteri sono chiaramente rilevanti per piattaforme SaaS, applicazioni web custom e servizi abilitati dall’IA.
Perché i CTO dovrebbero considerarlo un tema di continuità operativa
L’errore comune è vedere l’enforcement della privacy come un rischio legale remoto. In pratica, l’articolo 58 può trascinare nello stesso flusso di lavoro urgente ingegneri senior, personale di sicurezza, consulenti legali, product owner e team operations.
Questo ha conseguenze oltre la risposta formale:
- i piani di sprint vengono rielaborati
- i deployment sui sistemi interessati possono richiedere revisione o pausa
- i contratti con i fornitori diventano vincoli architetturali
- le rassicurazioni ai clienti improvvisamente necessitano di prove tecniche
- la documentazione debole si trasforma in una costosa indagine interna
La lezione immediata è semplice. Nel momento in cui un regolatore fa domande, la tua architettura sta già parlando per te. Se è stata progettata solo per la velocità, le lacune emergono rapidamente.
Una lettura tecnica dei poteri dell’autorità di controllo
L’articolo 58 raggruppa i poteri dell’autorità di controllo in tre categorie: poteri di indagine, poteri correttivi e poteri di autorizzazione o consultivi. Per i responsabili di ingegneria, questo si traduce in tre domande operative. Cosa può richiedere un regolatore al sistema? Cosa può costringere l’azienda a cambiare? Quali segnali sta dando sui design che è più probabile accetti?
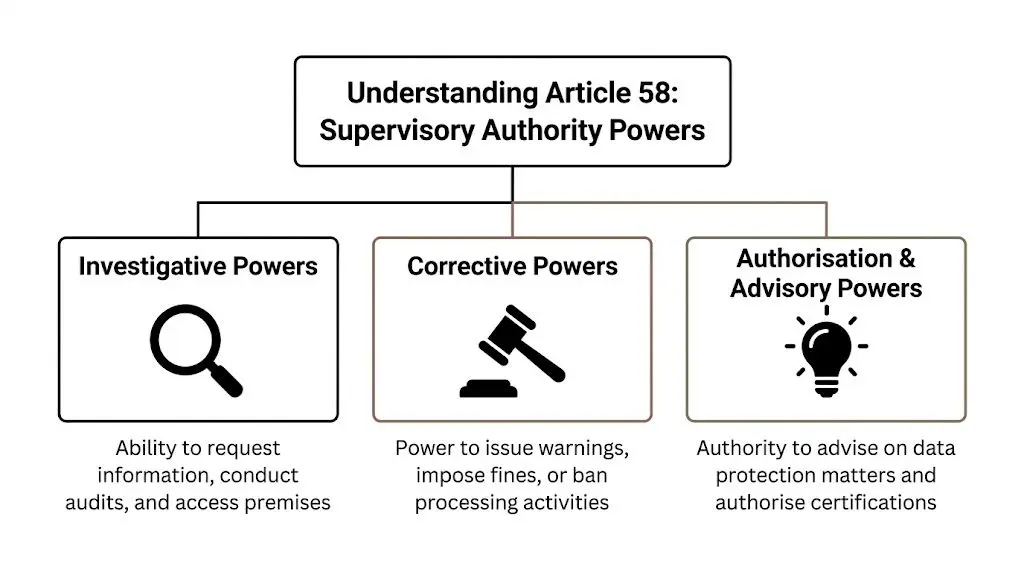
I poteri di indagine in termini di sistema
I poteri di indagine colpiscono le parti dello stack che i team spesso lasciano non documentate. Le autorità possono richiedere informazioni, ottenere accesso ai dati personali e alla documentazione, svolgere audit e ispezionare le strutture. In un’azienda software moderna, questo va ben oltre un’informativa privacy o una voce del RoPA. Può includere pipeline di eventi, strumenti di supporto, input dei modelli, conservazione dei backup, subprocessori e i controlli che li riguardano.
Per un CTO, “fornire informazioni” significa di solito produrre evidenze che corrispondano alla realtà di produzione:
- Registri dei trattamenti: descrizioni del trattamento allineate ai servizi, ai dataset e alle finalità reali
- Diagrammi architetturali: API, data store, code, regioni, subprocessori e interfacce di amministrazione
- Modelli di autorizzazione: chi può accedere ai dati grezzi, ai dati derivati, alle esportazioni, ai prompt e agli output del modello
- Logiche di conservazione e cancellazione: cancellazione pianificata, legal hold, backup ed eccezioni note
- Documentazione dei sistemi IA: fonti di training, flussi di inferenza, passaggi di revisione umana e confini della registrazione
Un design debole del sistema diventa rapidamente evidente. Se gli ingegneri non riescono a tracciare i dati personali dalla raccolta alla cancellazione attraverso fornitori e servizi interni, l’azienda si trova a discutere per ipotesi. I regolatori di solito chiedono prove.
Questo è particolarmente importante per i prodotti IA. Un team può sapere cosa fa la funzionalità dal punto di vista dell’utente, pur non avendo alcun controllo di base sulla memorizzazione dei prompt, sugli input di fine-tuning, sulla telemetria, sui shadow log o sulle chiamate API transfrontaliere verso i provider di modelli. L’articolo 58 offre alle autorità un canale per chiedere direttamente questi dettagli.
Un regolatore non ha bisogno che la tua architettura sia elegante. Ha bisogno che sia spiegabile, dimostrabile e controllabile.
I poteri correttivi e il loro impatto sui piani di prodotto
I poteri correttivi rappresentano il lato più incisivo dell’articolo 58. Le autorità possono emettere avvertimenti e richiami, ordinare a un titolare o a un responsabile del trattamento di conformarsi, richiedere la rettifica o la cancellazione, imporre limiti temporanei o definitivi al trattamento, sospendere i flussi di dati e attivare sanzioni amministrative ai sensi dell’articolo 83.
Ciascuno di questi esiti modifica le priorità ingegneristiche.
Un avvertimento spesso diventa un programma di remediation pianificato con scadenze, responsabilità e reporting. Un richiamo può costringere i team di prodotto e sicurezza a riscrivere controlli che erano stati considerati un rischio accettabile. Un ordine di modifica del trattamento può significare ridisegnare la raccolta dati, la logica di una funzionalità, i default di conservazione o i flussi rivolti ai clienti. Una sospensione può disattivare da un giorno all’altro un’integrazione con un fornitore o un intero percorso funzionale.
Il compromesso è di solito tra velocità e reversibilità. I team rilasciano più rapidamente quando centralizzano il logging, copiano i dati di produzione negli ambienti di test e spingono i dati in pipeline analytics o IA multiuso. Queste scelte rendono anche più costosi da implementare gli ordini correttivi, perché i dati personali si distribuiscono su più sistemi, più responsabili del trattamento e più giurisdizioni.
Un modo pratico per leggere i poteri correttivi è questo:
| Tipo di potere | Come si manifesta nel software |
|---|---|
| Avvertimento | Il servizio resta online, ma il backlog riceve lavoro di remediation imposto dal regolatore |
| Richiamo | La non conformità viene formalizzata, con possibili verifiche da parte di clienti, board e procurement |
| Ordine di modificare il trattamento | Raccolta dati, modelli di accesso, regole di conservazione o flussi utente devono essere riprogettati |
| Sanzione | La penalità è visibile, ma il costo maggiore è spesso il tempo di ingegneria, la revisione legale e il ritardo sulla roadmap |
| Sospensione o divieto | Una funzionalità, un percorso di trasferimento o una dipendenza da un fornitore si ferma finché il divario di controllo non viene colmato |
L’architettura transfrontaliera è il punto in cui tutto questo diventa molto concreto. Se un prodotto si basa su hosting al di fuori dello SEE, accesso del supporto da paesi terzi, telemetria esterna o API LLM che spostano prompt e output fuori dallo SEE, un ordine correttivo può richiedere il reindirizzamento del traffico, la regionalizzazione dello storage, il cambio di fornitore o la disattivazione di parte del servizio per gli utenti UE. Questo è un problema di infrastruttura, non di formulazione delle policy.
I poteri consultivi e di autorizzazione influenzano anch’essi le scelte tecniche
I team spesso ignorano il lato più morbido dell’articolo 58 perché non sembra urgente. È un errore. I poteri consultivi e di autorizzazione influenzano quali controlli le autorità si aspettano di vedere attorno ai meccanismi di certificazione, agli accordi contrattuali e ai pattern di trattamento più rischiosi.
Questo incide sulle scelte progettuali sin dall’inizio. Se due architetture producono lo stesso risultato di prodotto, quella con una limitazione della finalità più rigorosa, meno trasferimenti successivi, una separazione tra tenant più chiara e una logica decisionale verificabile è in genere più facile da difendere. Lo stesso vale per i sistemi assistiti dall’IA. Un flusso di modello che tiene gli attributi sensibili fuori dai prompt, limita la conservazione, registra gli override umani e mantiene una traccia di audit crea generalmente meno rischio di enforcement rispetto a un modello di terze parti racchiuso in modo approssimativo con logging ampio e uso downstream poco chiaro.
Cosa tende a resistere al controllo
Alcuni pattern tecnici rendono più gestibile l’esposizione all’articolo 58:
- Confini chiari dei servizi: finalità, owner e contratti dei dati definiti tra i sistemi
- Controllo regionale: sedi esplicite di storage e trattamento per i dati UE
- Accesso verificabile: accesso basato sui ruoli, approvazioni per le esportazioni e log conservati a lungo abbastanza per indagare
- Cancellazione by design: regole di conservazione implementate nel codice, non affidate alla pulizia manuale
- Guardrail per l’IA: filtraggio dei prompt, valutazioni dei fornitori, percorsi di revisione degli output e separazione tra dati di inferenza e dati di training
Altri pattern creano rischi evitabili:
- Esportazioni nascoste e workaround del supporto
- Dataset condivisi riutilizzati per analytics, test e sviluppo del modello
- Telemetria generica che cattura dati personali senza una finalità definita
- Integrazioni IA generiche in cui nessuno sa dire cosa venga memorizzato, dove vada o chi possa recuperarlo
Il punto pratico è semplice. L’articolo 58 non è un potere astratto del regolatore esterno al prodotto. Entra direttamente in architettura, selezione dei fornitori, deployment dell’IA e progettazione transfrontaliera dei dati. I team che costruiscono per la tracciabilità e il contenimento hanno più margine di risposta. I team che costruiscono per la velocità senza quei controlli di solito finiscono per ricostruire i propri sistemi sotto pressione.
Anatomia di un’indagine ai sensi dell’articolo 58
L’indagine di solito inizia in un normale giorno feriale. L’ufficio legale inoltra una lettera o un’email da parte di un’autorità di controllo. La prima richiesta sembra circoscritta, spesso formulata come una richiesta di informazioni, ma si trasforma immediatamente in un problema di ingegneria perché l’autorità sta verificando se l’azienda è in grado di descrivere il proprio trattamento in un modo che corrisponda al sistema effettivamente in funzione.
La fase della richiesta
La prima scadenza di presentazione è il punto in cui emerge una debole ingegneria della privacy.
Le autorità in genere chiedono materiale che dovrebbe già esistere se i controlli sulla privacy fanno parte della delivery invece di essere un’attività di pulizia dopo il lancio:
- Materiale RoPA: quali trattamenti avvengono, per quali finalità, su quale base giuridica e con quali destinatari
- Prove DPIA: soprattutto per profilazione, monitoraggio su larga scala, uso di dati sensibili e decisioni supportate dall’IA
- Mappe tecniche dei flussi di dati: flussi reali tra servizi, responsabili del trattamento, regioni di archiviazione, API e percorsi di trasferimento
- Prove dei controlli: autenticazione, autorizzazione, conservazione, cancellazione, registrazione dei log e risposta agli incidenti
- Registri di governance: chi ha approvato la funzionalità, quali rischi sono stati sollevati e come sono state riesaminate le modifiche successive
Il problema pratico è il drift. Il prodotto cambia più velocemente della documentazione. Il supporto ottiene un percorso di esportazione. L’analitica aggiunge un nuovo flusso di eventi. Una funzionalità di IA invia prompt a un endpoint di un fornitore che non è mai stato aggiunto alla revisione originale. Nel momento in cui l’autorità chiede un resoconto pulito del trattamento, l’azienda sta cercando di ricostruire sei mesi di eccezioni da ticket, thread Slack, cronologia di Terraform e impostazioni del fornitore.
Cosa accade all’interno dell’azienda
Un’indagine ai sensi dell’Articolo 58 non viene mai gestita dal solo consulente privacy. Coinvolge i team che hanno costruito, gestito e modificato il sistema.
| Team | Cosa viene loro tipicamente richiesto |
|---|---|
| Engineering | architettura del sistema, archivi dati, log, percorsi di accesso, logica di conservazione, integrazioni |
| Security | modello dei permessi, monitoraggio, progettazione dei controlli, registri degli incidenti, cronologia degli accessi amministrativi |
| Product | finalità della funzionalità, impostazioni predefinite, flussi utente, cronologia delle release, giustificazione di business |
| Legal o privacy | base giuridica, informative, contratti, termini del responsabile del trattamento, DPIA, analisi dei trasferimenti |
| Operations o support | procedure di esportazione, gestione delle eccezioni, pratiche di accesso agli account, registri dei reclami |
La modalità di fallimento è familiare. Ogni team ha una parte della risposta, ma nessuno ha un modello aggiornato dell’intera catena di trattamento. Lo vedo più spesso negli stack in cui i dati personali attraversano troppi confini senza contratti solidi tra i servizi. Gli strumenti interni di amministrazione aggirano i controlli normali. Le pipeline di eventi raccolgono più di quanto chiunque intendesse. I fornitori di IA ricevono prompt, file o metadati tramite SDK che l’ingegneria ha integrato rapidamente e non ha mai isolato dietro un gateway interno.
È lì che l’indagine diventa costosa. Il costo non è solo la revisione legale. I senior engineer vengono distolti per raccolta di prove, interpretazione dei log e spiegazione dell’architettura nel momento esatto in cui l’azienda vorrebbe che stessero implementando correzioni.
Un’autorità di controllo non si aspetta un sistema perfetto. Si aspetta però che l’azienda sappia quali dati personali vengono trattati, dove vanno, perché sono lì e chi può accedervi.
Come si amplia il perimetro
Le indagini si ampliano quando le risposte iniziali sono vaghe, incoerenti o troppo rifinite per essere credibili.
Se l’autorità chiede come funziona la cancellazione e riceve invece un documento di policy anziché un processo di cancellazione, un piano di conservazione e una prova dai sistemi di produzione, porrà domande di follow-up. Se l’azienda dichiara che una funzionalità di IA non addestra sui dati degli utenti, l’autorità potrebbe chiedere il contratto con il fornitore, la configurazione tecnica e la revisione interna a supporto di tale affermazione. Se i trasferimenti transfrontalieri vengono menzionati solo a livello contrattuale, l’autorità potrebbe chiedere i servizi effettivi, le regioni, i subfornitori e i percorsi di fallback coinvolti.
Ecco perché la compliance retroattiva spesso fallisce. I team scrivono in base alla policy che intendevano implementare, non al sistema che hanno effettivamente distribuito.
I casi transfrontalieri possono coinvolgere più di un’autorità
Alcuni CTO presumono che un’autorità di controllo capofila possa contenere operativamente il processo. È un’ipotesi troppo ottimistica, soprattutto quando sono coinvolti reclami locali, utenti locali o danni locali.
La posizione giuridica sulle autorità non capofila che avviano procedimenti ai sensi dell’Articolo 58(5) è stata esaminata dalla Corte di giustizia dell’Unione europea, e un commento pratico su questo punto compare in questa analisi della competenza delle autorità di controllo ai sensi dell’Articolo 58(5). Il messaggio operativo è semplice. Una struttura transfrontaliera non garantisce un’indagine a thread singolo. I team di prodotto, legale e ingegneria dovrebbero prepararsi a richieste che riflettano sia questioni di governance centrale sia preoccupazioni di enforcement locale.
Cosa regge sotto pressione
Le aziende che gestiscono meglio le indagini ai sensi dell’Articolo 58 non fanno affidamento su documentazione dell’ultimo minuto. Hanno prove prodotte durante la normale delivery e le normali operations:
- diagrammi dell’architettura aggiornati con le release
- classificazione dei dati nelle design review e nei ticket
- registri dei subfornitori e delle integrazioni collegati alla realtà del deployment
- log che mostrano accessi, esportazioni, cancellazioni e azioni amministrative
- motivazioni tecniche documentate per le eccezioni, incluse le scelte dei fornitori di IA e i percorsi di trasferimento
Un’indagine è comunque dirompente. Consuma sempre tempo e attenzione del management. Ma se le prove esistono già nei sistemi di ingegneria e nei workflow di revisione, l’azienda può rispondere alle domande con registri anziché con ipotesi.
Articolo 58 e sospensioni dei flussi di dati transfrontalieri
Tra i poteri previsti dall’art 58 gdpr, la capacità di sospendere i flussi di dati è una delle più dirompenti dal punto di vista operativo. Se il tuo prodotto dipende da servizi di paesi terzi, soprattutto API di IA, una sospensione può rimuovere una capacità centrale invece di aggiungere semplicemente burocrazia.
Perché questo potere conta per gli stack moderni
L’Articolo 58(2)(j) consente alle autorità di ordinare la sospensione dei flussi di dati verso paesi terzi o organizzazioni internazionali. È direttamente rilevante per i prodotti che inviano prompt, ticket di supporto, immagini, trascrizioni, eventi di analytics o profili utente a servizi ospitati al di fuori del SEE.
Questo potere è attivo nella pratica. Ai sensi dell’equivalente del UK GDPR, l’ICO ha sospeso il 15% dei flussi transfrontalieri sottoposti ad audit nel 2024 a causa di garanzie inadeguate. La sanzione di 1,2 miliardi di euro a Meta nel 2023 era direttamente collegata a questo tema. Gli stessi dati verificati indicano inoltre che un rapporto CNIL del 2025 ha rilevato che i provider SaaS che usano proxy con limitazione di velocità e basati nell’UE hanno ridotto il rischio di sospensione del 75%, come riassunto nella nota di Fieldfisher sui poteri dell’Articolo 58 GDPR.
Per i team di ingegneria, la lezione è netta. Un meccanismo di trasferimento in un contratto non risolve un design tecnico debole.
Cosa va storto nelle integrazioni di IA
Il pattern rischioso è comune:
- un team aggiunge una API di modello ospitata negli Stati Uniti
- i prompt includono contenuti utente grezzi
- i metadati viaggiano con gli identificativi
- log e retry replicano il payload in più punti
- nessuno riesce a mostrare misure supplementari significative
Questo tende ad accadere perché l’integrazione viene trattata come una chiamata a una funzionalità, non come un percorso di trasferimento regolamentato. Il codice funziona. L’architettura no.
Riappaiono continuamente tre assunzioni deboli:
- “È solo transitorio.” Anche una trasmissione temporanea può comunque costituire un problema di trasferimento se i dati personali lasciano il SEE senza garanzie sufficienti.
- “Il fornitore dice di essere conforme.” Non basta se la tua implementazione invia più dati personali del necessario.
- “Faremo la redazione dei dati in un secondo momento.” Se la redazione è fuori dal percorso critico, di solito fallisce sotto traffico reale e nei casi limite.
Modelli che riducono l’esposizione
Architetture migliori di solito collocano il controllo al confine prima che i dati escano dal SEE.
| Pattern | Perché aiuta | Compromesso |
|---|---|---|
| Livello proxy basato nell’UE | centralizza routing, filtraggio ed enforcement delle policy | aggiunge latenza e un altro componente operativo |
| Pseudonimizzazione o tokenizzazione prima del trasferimento | riduce la identificabilità diretta nei payload in uscita | può limitare l’utilità del modello se il contesto viene trasformato pesantemente |
| Rate limiting ed endpoint limitati per ambito | restringe l’emissione incontrollata di dati e riduce il rischio di abuso | può limitare la reattività della funzionalità |
| Separazione regionale del processing | mantiene locali le fasi ad alto rischio e invia solo un contesto ridotto | aumenta la complessità architetturale |
| Osservabilità rigorosa sulle richieste in uscita | rende visibile e verificabile il comportamento dei trasferimenti | richiede una progettazione disciplinata dei log per evitare di registrare payload sensibili |
Un design pratico spesso utilizza un proxy UE per rimuovere gli identificativi diretti, applicare controlli di policy, imporre limiti di velocità e mantenere un log auditabile delle categorie in uscita invece del contenuto grezzo. Non è una soluzione miracolosa, ma è sostanzialmente più forte del fatto che ciascun servizio chiami direttamente un’API di un paese terzo.
Qui è utile un breve video esplicativo sull’enforcement dei trasferimenti:
Cosa vorranno vedere le autorità
Se un percorso di trasferimento viene contestato, le prove più solide tendono a includere:
- diagrammi chiari dei flussi in uscita
- le esatte categorie di dati personali inviate
- perché ogni categoria è necessaria
- quale trasformazione tecnica avviene prima del trasferimento
- come l’azienda monitora e limita tali flussi
- quale fallback esiste se il percorso di trasferimento deve interrompersi
I sistemi che si basano su API dirette verso paesi terzi con dati personali grezzi e senza un livello di astrazione sono economici da lanciare e costosi da difendere.
Il compromesso importante è che un’architettura sicura per i trasferimenti aggiunge attrito in fase iniziale. Ma offre al business delle opzioni quando regolatori, clienti o team procurement iniziano a porre domande difficili.
Come le autorità esaminano l’IA e i sistemi automatizzati
Molti team inquadrano ancora il rischio GDPR attorno a banner di consenso, informative privacy e richieste degli interessati. È troppo ristretto per i sistemi moderni. Le autorità si interessano sempre più a come l’IA e il trattamento automatizzato funzionano in produzione.
La difesa della scatola nera non funziona
Quando un’autorità esamina una funzionalità abilitata dall’IA nell’ambito dei poteri dell’Articolo 58, le domande vanno oltre le informative front-end. Possono includere:
- quali dati entrano nel modello o nel workflow
- se i dati erano necessari per la finalità dichiarata
- in che modo gli output influenzano gli individui
- quale revisione umana esiste
- come vengono rilevati errori, bias o output dannosi
- se l’organizzazione è in grado di spiegare un determinato risultato abbastanza bene da giustificare il trattamento Questo vale per un’ampia gamma di sistemi. Un motore di raccomandazione può influenzare quali opportunità vede un utente. Un filtro di recruiting può influenzare chi viene selezionato per il colloquio. Un assistente di supporto può riassumere o classificare i messaggi dei clienti in modi che incidono sulla qualità del servizio o sull’escalation.
Come appaiono risposte solide
Una risposta solida di solito non è “ci pensa il fornitore del modello”. È una combinazione di evidenze tecniche e di governance:
- Controlli sugli input: quali classi di dati possono entrare nei prompt, negli embedding o nel contesto del modello
- Vincoli sugli output: come il sistema convalida, filtra o instrada i contenuti generati
- Progettazione della revisione umana: quando una persona deve confermare, annullare o rifiutare un output automatico
- Registri di test: come il team ha verificato comportamenti dannosi o inaffidabili in scenari realistici
- Tracciabilità delle versioni: quale modello, template di prompt, workflow o set di regole ha prodotto un dato output
La disciplina più utile qui è spesso una valutazione d’impatto adeguata prima del deployment. Per i team che ci stanno lavorando, questa guida pratica alla valutazione d’impatto sulla privacy è un buon punto di partenza.
Se una funzionalità AI influisce sulle persone in modo significativo, “non sappiamo spiegarla” non è una risposta tecnica. È un fallimento di governance.
Errori comuni nei team di prodotto AI
Alcuni schemi creano problemi ripetutamente:
| Errore | Perché fallisce al vaglio |
|---|---|
| Usare dati degli utenti in produzione per la valutazione senza confini chiari | la limitazione della finalità e la minimizzazione diventano difficili da difendere |
| Registrare prompt e output per impostazione predefinita | crea archivi secondari di dati personali con una scarsa disciplina di conservazione |
| Nessuna distinzione tra uso di supporto e uso che orienta le decisioni | nasconde dove è davvero richiesta la supervisione umana |
| Trattare la documentazione del fornitore come intero framework di controllo | lascia lacune importanti in materia di responsabilità e dettagli di implementazione |
Il cambio di mentalità utile è che i sistemi AI hanno bisogno di un’architettura privacy, non solo di orchestrazione del modello. Più il team riesce a tracciare input, passaggi di ragionamento, chiamate agli strumenti, output e interventi umani, più sarà facile rispondere a domande regolatorie in termini concreti.
Una checklist pratica di conformità per i team di engineering
Se vuoi essere pronto ai poteri dell’Articolo 58, non partire dai template. Parti dal sistema. L’obiettivo è rendere il prodotto spiegabile, verificabile e contenibile sotto pressione.
Per i team che cercano di renderlo operativo, la guida di Devisia ai mezzi di conformità è un utile complemento alla checklist qui sotto.
Mantieni una mappa dei dati aggiornata
I diagrammi statici sulla privacy invecchiano male. La tua mappa dei dati deve tracciare i sistemi reali, non quelli idealizzati.
Includi:
- punti di ingresso: form, API, importazioni, strumenti di supporto, telemetria
- punti di trasformazione: arricchimento, classificazione, embedding, esportazioni
- livelli di archiviazione: database, object storage, code, cache, indici di ricerca
- percorsi di uscita: vendor, sub-responsabili, analytics, API AI, esportazioni ai clienti
Il compromesso è lo sforzo di manutenzione. Ma senza questo, ogni indagine parte da una raccolta interna di fatti invece che dalla risposta.
Registra gli eventi di trattamento, non solo gli eventi di sicurezza
La registrazione di sicurezza è diffusa. Sono meno comuni i log rilevanti per la privacy. Servono registri che mostrino quando i dati personali sono stati consultati, esportati, trasformati, eliminati o inviati a un servizio esterno.
Una pratica utile include:
- separare i metadati dai payload sensibili
- tracciare attore, sistema, finalità e destinazione
- conservare abbastanza contesto per ricostruire le decisioni
- evitare log che diventino dataset ombra
Molti team spesso esagerano nella correzione. O registrano troppo poco per dimostrare qualcosa, oppure troppo e creano un secondo problema di conformità.
Rendi ispezionabili i flussi AI
Se rilasci funzionalità AI, costruisci osservabilità attorno al workflow, non solo alla chiamata del modello.
Questo di solito significa mantenere un record controllato di:
- versione del template del prompt
- versione del modello o del servizio
- percorso di invocazione degli strumenti
- decisioni dei guardrail o delle policy
- eventi di revisione umana
- esito dell’output, ad esempio mostrato, bloccato, modificato o scartato
L’obiettivo non è conservare indefinitamente ogni contenuto dell’utente. L’obiettivo è poter spiegare come ha operato il sistema e perché.
Test operativo: prendi un output AI visibile all’utente della scorsa settimana. Se il tuo team non riesce a tracciare come è stato prodotto, la tua postura di conformità è più debole di quanto sembri.
Tratta i controlli sui trasferimenti transfrontalieri come impostazione predefinita
Non lasciare la mitigazione del trasferimento alla revisione legale dopo che l’integrazione è stata completata. Inserisci i controlli nel percorso di integrazione:
- Instrada attraverso un perimetro gestito. Un proxy o gateway all’interno dello SEE ti dà un punto unico in cui filtrare, redigere e far rispettare le policy.
- Elimina ciò che il fornitore non necessita. Nomi, email, identificatori in testo libero e cronologie complete spesso viaggiano per comodità più che per necessità.
- Prepara una modalità di fallback. Se un percorso di trasferimento viene contestato, il prodotto dovrebbe degradarsi in modo prevedibile invece di fallire in modo caotico.
Questo spesso costa più tempo di engineering all’inizio. Ne fa risparmiare molto di più se un servizio deve essere sostituito, regionalizzato o sospeso.
Automatizza le evidenze dove possibile
La prova di conformità più forte viene generata dal lavoro ordinario di engineering. Estraila dai sistemi già usati per build e deployment.
Esempi:
| Fonte ingegneristica | Valore per la conformità |
|---|---|
| Infrastructure as code | mostra regioni, servizi, confini di rete e dipendenze |
| Cataloghi di servizi | identifica owner, integrazioni e classi di dati |
| Pipeline CI | dimostra quando i controlli sono stati eseguiti e cosa è stato distribuito |
| Annotazioni di schema | aiuta a derivare categorie di dati personali e flag di conservazione |
| Workflow dei ticket | registra approvazioni e decisioni di rischio per le modifiche alle funzionalità |
Un foglio di calcolo manuale può ancora essere utile. Non dovrebbe essere la tua unica fonte di verità.
Esegui un drill di prontezza regolatoria
La maggior parte delle organizzazioni fa esercitazioni sugli incidenti. Meno organizzazioni simulano una richiesta regolatoria. Dovrebbero farlo.
Un semplice drill chiede a un team cross-funzionale di rispondere a domande come:
- mostra il flusso completo dei dati per una funzionalità ad alto rischio
- identifica tutti i responsabili del trattamento e sub-responsabili coinvolti
- spiega la base giuridica e la logica di conservazione
- produci evidenze delle misure di sicurezza per qualsiasi trasferimento esterno
- dimostra chi può accedere ai dati e come ciò viene verificato
Questo esercizio di solito fa emergere il vero gap. Non è l’assenza di testo nelle policy. È l’assenza di evidenze rapide e affidabili.
Affida la responsabilità a persone che possono cambiare i sistemi
Il lavoro di conformità fallisce quando la responsabilità ricade solo su legal o solo su security. Il rischio dell’Articolo 58 vive nell’architettura, nel delivery e nelle operations. Le persone responsabili dei servizi devono avere una chiara accountability per i flussi di dati, la conservazione, la progettazione degli accessi e le integrazioni con terze parti.
Un modello pratico consiste nell’assegnare la ownership della privacy a livello di servizio o dominio, supportata da linee guida centrali da parte di privacy e security. In questo modo si evita il modello comune in cui tutti vengono consultati e nessuno è responsabile.
Conclusione Costruire sistemi resilienti non difese legali
L’Articolo 58 è importante perché trasforma il GDPR in una realtà operativa. Le autorità di controllo possono chiedere informazioni, ispezionare il funzionamento dei sistemi, ordinare modifiche, sospendere flussi problematici ed eseguire escalation quando le organizzazioni non riescono a giustificare il proprio trattamento. Per le aziende software, questo entra direttamente nelle scelte di product design e di infrastruttura.
Le aziende che gestiscono bene questo aspetto non si affidano a narrazioni raffinate ex post. Costruiscono sistemi più facili da spiegare. I loro flussi di dati sono mappati. Le loro integrazioni sono delimitate. Le loro funzionalità AI sono osservabili. I team sanno quale vendor riceve quali dati e perché. Quando arriva una richiesta, rispondono con evidenze invece che con una ricostruzione.
Questa è la lettura pratica dell’art 58 gdpr per CTO e product leader. La questione non è se il reparto legale riesca a redigere una risposta. La questione è se l’ingegneria possa sostenere l’architettura sotto esame.
L’impostazione più forte sul lungo periodo è semplice:
- progetta per la minimizzazione prima che i dati escano dal tuo perimetro
- rendi visibile il trattamento attraverso log e mappe dei dati utilizzabili
- aggiungi controllo umano dove i sistemi automatici incidono sulle persone
- mantieni le tutele sui trasferimenti nell’architettura predefinita, non come ripensamento
- testa la tua capacità di rispondere alle domande regolatorie prima di doverlo fare
La privacy non è un livello di funzionalità da aggiungere vicino al lancio. È una proprietà dei sistemi progettati per essere leggibili, controllati e manutenibili. È anche ciò che li rende più resilienti quando l’enforcement diventa reale.
Se stai costruendo SaaS, workflow abilitati dall’AI o piattaforme custom e vuoi che la privacy sia gestita fin dall’inizio come una questione architetturale, Devisia aiuta i team a progettare e realizzare sistemi manutenibili, più facili da operare, verificare ed evolvere sotto una reale pressione regolatoria.