
Un pattern familiare si ripete nei team SaaS. Il product aggiunge analytics, il marketing installa un tag di retargeting, il support embedda un widget di chat e l’ingegneria inserisce uno strumento di session recording per diagnosticare le frizioni nell’onboarding. Il lancio va bene. Poi qualcuno pone una domanda semplice: quali di questi script impostano cookie prima del consenso, in quali regioni e chi può dimostrarlo?
Pochi team sanno rispondere in modo pulito.
Questo è il problema centrale della legge sui cookie del web. Raramente inizia con avvocati che leggono gli statuti. Inizia con percorsi di codice, dipendenze di terze parti e velocità di rilascio. Un banner viene aggiunto alla fine del ciclo, ma l’applicazione è già stata configurata per caricare librerie di tracciamento al primo paint. A quel punto, la conformità non è una modifica al testo. È una revisione del caricamento frontend, del routing degli eventi backend, della gestione dello stato del consenso e dell’auditabilità.
Per CTO e leader di prodotto, la lezione è diretta. La conformità ai cookie rientra nella stessa categoria dell’autenticazione, del logging e del controllo degli accessi. Se la tratti come una questione di design, puoi costruire controlli puliti. Se la tratti come una patch post-lancio, erediti rischi nascosti e costosi retrofit.
Perché la conformità ai cookie è un problema architetturale
Molti team affrontano il lavoro sui cookie come un problema di banner. Comprano un popup di consenso, incollano uno script nella shell del sito e danno per scontato che la questione legale sia risolta.
Di solito non è così.
La modalità di fallimento è semplice. Il banner appare, ma analytics, pixel pubblicitari, strumenti di A/B testing, embed social o widget di supporto sono già stati caricati. Alcuni impostano cookie immediatamente. Altri attivano chiamate di rete che equivalgono a tracciamento anche prima che l’utente abbia fatto una scelta. L’interfaccia dice “gestisci le preferenze”, ma l’architettura ha già preso la decisione.
Gli script di terze parti creano responsabilità nascoste
Lo stack web moderno ha normalizzato questo comportamento nel corso degli anni di crescita del tracciamento nel browser. Il Web Privacy Census di UC Berkeley Law ha rilevato che i cookie sui primi 100 siti web più popolari sono aumentati da 3.602 nel 2009 a 5.675 nel 2011, un aumento del 57%, con i cookie di terze parti a guidare gran parte di questa espansione. Entro il 2011, quasi tutti i principali siti web utilizzavano cookie, rendendoli parte dell’infrastruttura web di base e un bersaglio diretto della regolamentazione sulla privacy (UC Berkeley Law Web Privacy Census).
Questa storia è importante perché molti prodotti SaaS ereditano ancora presupposti di quell’epoca:
- Caricamento frontend-first: gli script sono bundle o iniettati globalmente.
- Impostazioni predefinite del vendor: gli strumenti presuppongono l’attivazione immediata, salvo disattivazione da parte degli engineer.
- Ownership debole: marketing, product e engineering aggiungono tracker senza un unico percorso di approvazione.
- Nessun controllo runtime: non esiste un gate affidabile tra la scelta dell’utente e l’esecuzione dello script.
Un problema di privacy diventa un problema di ingegneria nel momento in cui uno script non essenziale può eseguire prima del consenso.
Regola pratica: se uno script di terze parti può essere eseguito prima che lo stato del consenso sia risolto, il tuo banner è solo cosmetico.
Le correzioni superficiali creano debito tecnico
Le correzioni tardive sono costose perché il problema si diffonde nello stack. Potrebbe essere necessario refactorare il caricamento dei tag, separare servizi essenziali e non essenziali, ridisegnare il modello di consenso per gli utenti autenticati e interrompere il forwarding a valle degli eventi verso vendor che non avrebbero mai dovuto ricevere i dati.
Questo influisce anche su performance e manutenzione. Un’architettura consapevole del consenso spesso riduce l’esecuzione inutile di script lato client. Vale anche il contrario. I tracker non controllati aumentano il peso della pagina, complicano il debug e rendono più difficile investigare gli incidenti.
Cosa funziona e cosa no
Cosa funziona:
- Governance centralizzata degli script
- Percorsi di caricamento consapevoli del consenso
- Gestione delle policy per regione
- Registri che mostrano cosa ha scelto l’utente e quando
Cosa non funziona:
- Un unico toggle globale “accetta cookie” senza categorie
- Divulgazione post hoc dopo che gli script sono già partiti
- Affidarsi alle dichiarazioni del vendor senza testare il comportamento runtime
- Trattare la produzione come il primo ambiente di audit
I team che costruiscono tutto questo correttamente non partono dal design del banner. Partono mappando i flussi di dati e decidendo quali componenti possono eseguire prima che esista il consenso.
Comprendere i principi fondamentali della regolamentazione dei cookie
I requisiti della legge sui cookie del web spesso hanno più senso quando smetti di leggerli come formalità legali e inizi a leggerli come vincoli di sistema.
Un’analogia utile è costruire il controllo degli accessi per una piattaforma interna. Non concederesti a ogni servizio permessi ampi per poi spiegare l’eccesso in un documento di policy. Definiresti i privilegi in anticipo. La regolamentazione dei cookie segue la stessa logica.
Il consenso significa una scelta reale
La domanda centrale è se l’utente abbia avuto una reale possibilità di decidere prima dell’inizio del tracciamento non essenziale. Questo è il significato pratico di consenso informato.
Per i team di ingegneria, questo ha conseguenze dirette:
- La scelta deve avvenire prima dell’attivazione nei regimi basati sul consenso.
- L’interfaccia deve spiegare cosa accade con un linguaggio comprensibile agli utenti.
- Il sistema deve rispettare il risultato in modo coerente in tutta l’applicazione.
Se il percorso “rifiuta” è nascosto, ritardato o più debole del percorso “accetta”, l’implementazione può sembrare completa pur fallendo ancora il principio alla base della regola.
La limitazione della finalità funziona come il principio del privilegio minimo
La limitazione della finalità è l’equivalente privacy del privilegio minimo. I dati raccolti per un motivo non dovrebbero essere automaticamente riutilizzati per un altro solo perché lo stack lo rende comodo.
Ciò significa che un team di prodotto dovrebbe separare funzioni come:
| Principio | Interpretazione ingegneristica |
|---|---|
| Consenso | Non eseguire tracciamenti non essenziali finché non esiste l’azione utente richiesta |
| Trasparenza | Descrivere categorie e finalità con un linguaggio semplice nel momento della scelta |
| Limitazione della finalità | Non riutilizzare identificatori di analytics o advertising per flussi di lavoro non correlati |
| Minimizzazione dei dati | Caricare meno tracker, raccogliere meno dati, conservare meno per impostazione predefinita |
Molti prodotti deragliano a questo punto. Uno strumento viene introdotto per l’analytics, poi riutilizzato per audience building, attribution o personalizzazione senza una nuova revisione della base giuridica, della divulgazione all’utente o del routing del vendor.
La trasparenza è un compito di product design
La trasparenza non si risolve con una lunga pagina di policy. Gli utenti hanno bisogno di un contesto sufficiente nel momento in cui scelgono.
Le implementazioni buone dicono agli utenti:
- Quali categorie esistono
- Perché viene usata ciascuna categoria
- Se sono coinvolte terze parti
- Come modificare la decisione in seguito
Ecco anche perché la distinzione tra opt-in e opt-out conta molto nella pratica. Se il tuo team sta decidendo quale modello si applica in un mercato, la spiegazione di Devisia sugli approcci opt-in e opt-out è un riferimento operativo utile.
Una buona privacy engineering traduce i principi legali in controlli runtime, non in documentazione.
La minimizzazione dei dati è un filtro architetturale
I team spesso si concentrano troppo sulla raccolta del consenso e troppo poco sul fatto che il tracker serva davvero. La minimizzazione dei dati pone una domanda più difficile: il prodotto può raggiungere l’obiettivo con meno cookie, meno vendor o un controllo first-party maggiore?
In pratica, questo può significare sostituire ampi tag marketing di terze parti con analytics first-party, limitare la retention o spostare parte della telemetria in sistemi server-side dove i dati possono essere governati in modo più rigoroso.
L’assetto di conformità più forte spesso inizia eliminando la complessità, non documentandola.
Navigare l’ambiente globale della legge sui cookie del web
Un team SaaS lancia negli Stati Uniti, aggiunge iscrizioni self-serve dalla Germania sei mesi dopo, poi scopre che il proprio stack di analytics si attiva prima che venga memorizzata qualsiasi scelta di consenso. È il punto in cui la legge sui cookie smette di essere un problema di policy e diventa un problema di sistemi.
Le regole legali cambiano da regione a regione, ma la domanda ingegneristica è costante. Quali script vengono eseguiti, a quali condizioni, per quale utente e come puoi dimostrarlo in seguito?
Il modello UE richiede controllo preventivo
Nell’UE, la base operativa è semplice da enunciare e facile da violare. I cookie non essenziali e tecnologie di tracciamento simili richiedono generalmente un consenso informato preventivo prima di essere impostati. Un ampio studio di misurazione della legge UE sui cookie ha rilevato che il 49% dei siti web misurati installava ancora cookie di profilazione prima di ottenere il consenso.
Per i team di ingegneria, questo significa:
- i tag non essenziali non possono caricarsi al rendering della pagina
- le scelte di consenso devono corrispondere al comportamento runtime reale
- la revoca deve interrompere l’elaborazione futura e impedire nuove scritture
- i registri devono mostrare cosa ha visto l’utente e cosa ha fatto il sistema
Molti team falliscono qui per ragioni prevedibili. I tag manager vengono caricati globalmente. Un SDK di product analytics si inizializza nella shell dell’app. Un widget di supporto deposita identificatori prima che il livello di consenso abbia finito la valutazione. Nulla di tutto questo viene risolto aggiornando il testo del banner.
Il modello USA crea una logica a rami
Le norme statali statunitensi sono meno uniformi e questo influisce sull’architettura. California e altri stati spesso si concentrano più su notice, diritti di opt-out, definizioni di vendita o condivisione e gestione dei dati sensibili che su un modello di consenso preventivo in stile UE per ogni cookie non essenziale.
Questo non rende l’implementazione più facile. La rende più ramificata.
Un sistema consapevole della regione potrebbe dover supportare un comportamento per i visitatori UE, un altro per i residenti in California e un fallback per gli utenti la cui posizione è incerta. Se product, web e data team non condividono lo stesso modello di classificazione, le informative si allontanano dal comportamento reale dei tag. Questo è il pattern di fallimento che crea rischio di enforcement.
I punti di rottura comuni includono:
- vendor adtech etichettati come analytics
- consenso applicato sulle pagine marketing ma non all’interno dell’app
- segnali di opt-out ignorati dal routing degli eventi downstream
- scelte sui cookie memorizzate nel browser mentre l’enrichment server-side continua a funzionare
GDPR e CCPA/CPRA a confronto nella pratica

Un CTO non ha bisogno di un lungo riassunto legale. La domanda utile è cosa il prodotto deve fare in modo diverso.
| Area di conformità | GDPR / ePrivacy (UE) | CCPA / CPRA (California) |
|---|---|---|
| Modello predefinito | Consenso preventivo per cookie non essenziali e tracker simili | Notice, disclosure e controlli di opt-out sono spesso i principali requisiti rivolti all’utente |
| Tempistica | La scelta deve esistere prima dell’attivazione | Comportamento, informative e gestione dei diritti dell’utente devono restare allineati |
| Impatto UX | Spesso ci si aspettano controlli granulari | Contano di più un avviso chiaro e percorsi di opt-out accessibili |
| Impatto ingegneristico | Blocco degli script, caricamento condizionale, inizializzazione SDK consapevole del consenso | Classificazione accurata, logica di soppressione e controlli downstream sull’uso dei dati |
| Evidenza | Log del consenso e cronologia delle configurazioni | Registri delle informative, delle scelte utente e della gestione dei vendor |
I team che necessitano di una spiegazione rivolta all’utente insieme al lavoro di implementazione dovrebbero tenere separato il riassunto legale dal design dei controlli. Una guida alla privacy e ai cookie per team SaaS aiuta sul fronte della policy, ma il lavoro più difficile resta nell’architettura dell’applicazione.
Scegli presto il tuo modello operativo
L’errore costoso è aspettare che la crescita internazionale costringa ad affrontare il problema. A quel punto, il prodotto di solito presume caricamento client-side senza restrizioni, container vendor condivisi e una separazione debole tra tool necessari e opzionali.
In pratica emergono tre modelli operativi:
-
Modalità globale rigorosa Applicare il comportamento “consent-first” in modo ampio. Questo riduce le biforcazioni e abbassa il rischio che un errore geolocale causi un tracciamento illecito. Il compromesso è una raccolta dati inferiore nelle regioni in cui la legge è più permissiva.
-
Modalità sensibile alla regione
Applicare regole diverse in base alla giurisdizione. Questo può preservare i flussi di misurazione e marketing in alcuni mercati, ma aggiunge overhead di test, incertezza geografica e più casi limite per utenti in viaggio, traffico VPN e pagine in cache. -
Modalità di tracciamento minimale
Ridurre la dipendenza dai cookie di terze parti e limitare il tracciamento opzionale. Di solito offre la posizione di conformità a lungo termine più pulita, ma i team di prodotto e growth potrebbero dover accettare un’attribuzione meno granulare.
La scelta giusta dipende dal tuo modello di vendita, dal mix di traffico e dallo stack di fornitori. Ciò che conta è fare una scelta in modo intenzionale, quindi costruire l’applicazione attorno a essa.
Dove fallisce l’implementazione
L’ambito legale è raramente la parte più difficile. La coerenza runtime lo è.
I fallimenti più grandi derivano di solito dalla proprietà frammentata tra i team. Il marketing controlla il tag manager. Il prodotto possiede la shell dell’app. L’ingegneria dei dati inoltra gli eventi lato server. Nessuno possiede la regola end-to-end che dice che un utente che ha rifiutato il tracciamento di marketing non dovrebbe attivare identificatori di marketing in nessun punto dello stack.
Fai attenzione a queste modalità di fallimento:
- Decisioni geografiche che si rompono con VPN, proxy o viaggi
- Stato del consenso che il codice frontend può leggere ma i sistemi backend no
- Script di terze parti hardcoded fuori dal framework di consenso
- Comportamenti di consenso separati tra doc, app, fatturazione e aree di supporto
- Cambiamenti dei fornitori distribuiti senza riclassificazione o revisione legale
L’approccio corretto è a livello di prodotto. Una sola tassonomia per le finalità. Una sola fonte di verità per lo stato del consenso. Un solo modello di enforcement su web, app e servizi a valle. È così che le differenze legali regionali restano gestibili invece di trasformarsi in una lista permanente di eccezioni.
Progettare esperienze di consenso e policy conformi
Il banner è la parte che gli utenti vedono, quindi i team si fissano su formulazione, colore dei pulsanti e posizionamento. Questo conta, ma non per il motivo che molti team pensano. Una buona interfaccia di consenso non serve solo a ridurre il rischio legale. Dice agli utenti se il tuo prodotto gestisce i dati in modo trasparente.
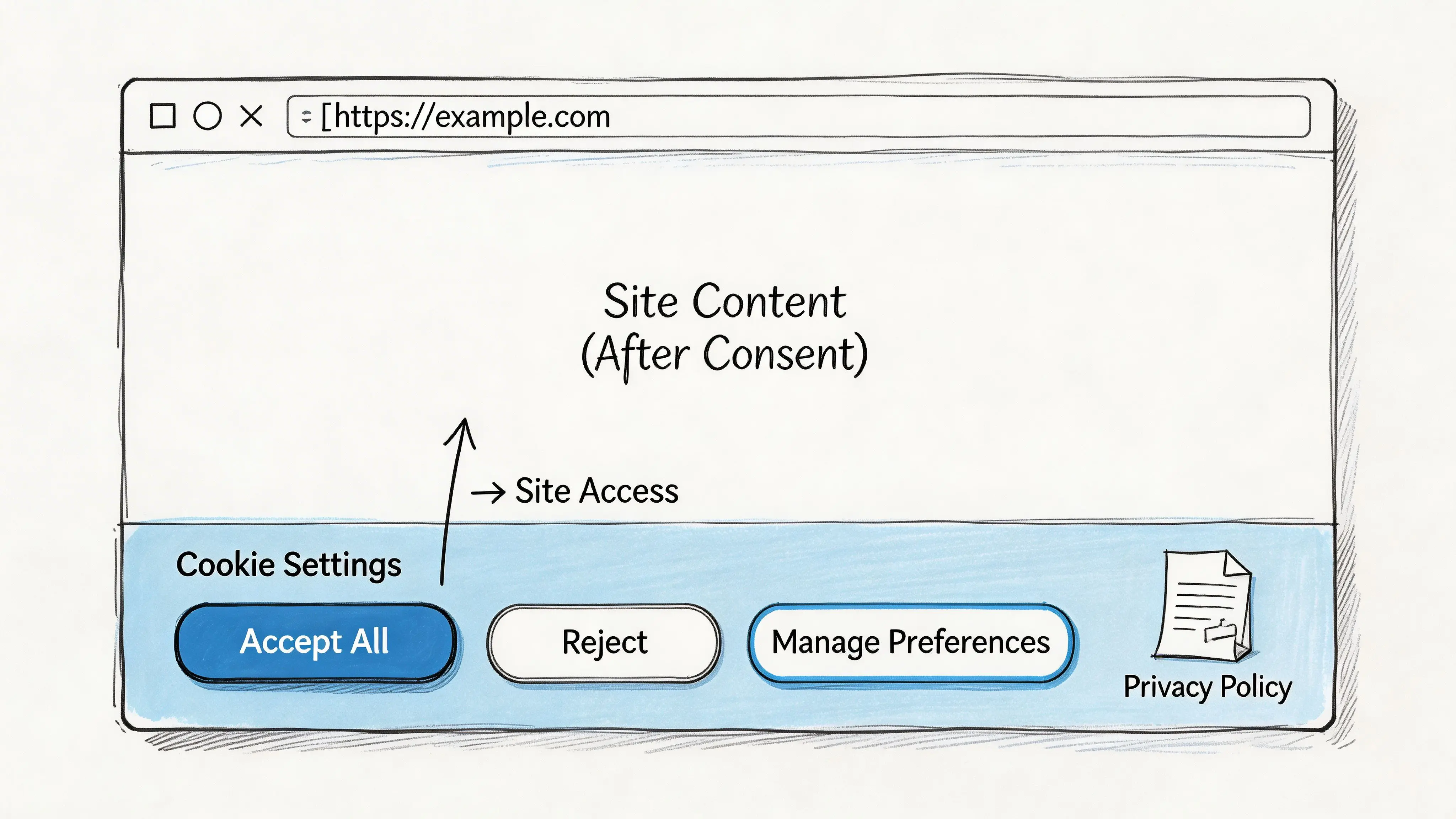
Se la prima interazione sulla privacy sembra manipolatoria, gli utenti lo notano. Anche gli acquirenti enterprise se ne accorgono, soprattutto durante l’approvvigionamento e la revisione di sicurezza.
I dark pattern sono un problema legale e di prodotto
Ai sensi della Sezione 5 del FTC Act e del CPRA, i banner dei cookie che utilizzano dark pattern, come caselle di controllo preselezionate o il rendere il rifiuto materialmente più difficile dell’accettazione, sono considerati ingannevoli. Uno studio ha rilevato che il 62% degli avvisi di consenso utilizzava un linguaggio vago, il che crea rischio normativo e mina la comprensione da parte degli utenti (analisi dei dark pattern negli avvisi di consenso dei cookie).
Questo si manifesta in scelte di design come:
- Accetta tutto al primo livello, ma rifiuto solo dopo diversi clic
- etichette come “migliora l’esperienza” senza una finalità concreta
- descrizioni di categoria che nascondono pubblicità o tracciamento cross-site
- banner che implicano che i cookie non siano attivi quando lo sono già
Questi pattern non creano solo esposizione. Producono un cattivo comportamento di prodotto. Gli utenti diventano meno propensi a fidarsi della dashboard, delle impostazioni dell’account e del resto delle comunicazioni sulla privacy.
Come appare un banner usabile
Un banner conforme di solito condivide alcune caratteristiche:
-
Azioni bilanciate Accetta e rifiuta dovrebbero essere entrambe visibili e facili da usare.
-
Categorie chiare I casi strettamente necessari, analitici, pubblicitari e funzionali dovrebbero essere comprensibili senza traduzione legale.
-
Linguaggio specifico Dì cosa fa la categoria. Non nasconderti dietro frasi generiche.
-
Controlli persistenti Gli utenti hanno bisogno di un modo affidabile per rivedere la decisione.
Ecco un modo semplice per pensarci.
| Pattern debole | Pattern forte |
|---|---|
| “Usiamo i cookie per migliorare la tua esperienza” | “Usiamo cookie di analisi per misurare l’uso delle funzionalità e cookie pubblicitari per l’attribuzione delle campagne” |
| Link di rifiuto minuscolo | Rifiuta e accetta presentati con simile evidenza |
| Un’unica scelta di consenso aggregata | Controlli a livello di categoria quando la legge o il profilo di rischio lo richiedono |
| Pagina impostazioni nascosta | Link al centro preferenze sempre disponibile |
Nota di design: se l’accuratezza legale e la semplicità dell’interfaccia sono in conflitto, semplifica prima l’architettura. Non nascondere la complessità nel banner.
La scrittura della policy dovrebbe supportare l’interfaccia
La tua cookie policy non dovrebbe ripetere il banner in forma più lunga. Dovrebbe rispondere al livello successivo di domande:
- quali categorie vengono usate
- a cosa serve ciascuna categoria
- se vengono impostate da prima parte o da terze parti
- come gli utenti possono modificare le preferenze
- come questo si collega alla privacy policy più ampia
Una policy chiara riduce l’attrito nei questionari di sicurezza e nella due diligence dei fornitori. Fornisce inoltre ai team di supporto e compliance qualcosa di accurato a cui fare riferimento quando i clienti chiedono quale tracciamento sia attivo all’interno del prodotto.
Per i team che rivedono il proprio modello di documentazione, la guida di Devisia alla struttura di privacy policy e cookie policy è un punto di riferimento pratico.
Una buona UX può ridurre il carico operativo
Una forte esperienza di consenso riduce i problemi successivi. Meno utenti confusi significano meno ticket di supporto sul tracciamento, meno disaccordi interni su cosa significhi il banner e meno pressione sugli ingegneri per giustificare un comportamento che avrebbe dovuto essere esplicito.
Questo breve walkthrough è utile se il tuo team sta esaminando pattern e formulazioni del banner prima dell’implementazione:
In pratica, il miglior banner è quello che i tuoi ingegneri possono applicare in modo coerente. I centri preferenze troppo elaborati non aiutano se gli script sottostanti ignorano le scelte.
Architettura tecnica per la conformità dei cookie
A questo punto la conformità smette di essere teoria. Se il tuo stack non riesce a impedire il tracciamento non essenziale prima della corretta azione dell’utente, il resto è solo facciata.
Il requisito ingegneristico fondamentale è il blocco preventivo. La conformità al GDPR richiede un’architettura di blocco preventivo, il che significa che i siti web devono impedire tecnicamente il caricamento di tutti gli script e cookie non essenziali finché l’utente non fornisce un consenso esplicito. Questo spesso richiede modifiche al codice di tutto il sito e non è facile da adattare a posteriori, motivo per cui dovrebbe far parte della progettazione iniziale dell’applicazione (architettura di blocco preventivo per la conformità dei cookie).
Il blocco preventivo cambia il modo in cui carichi l’app
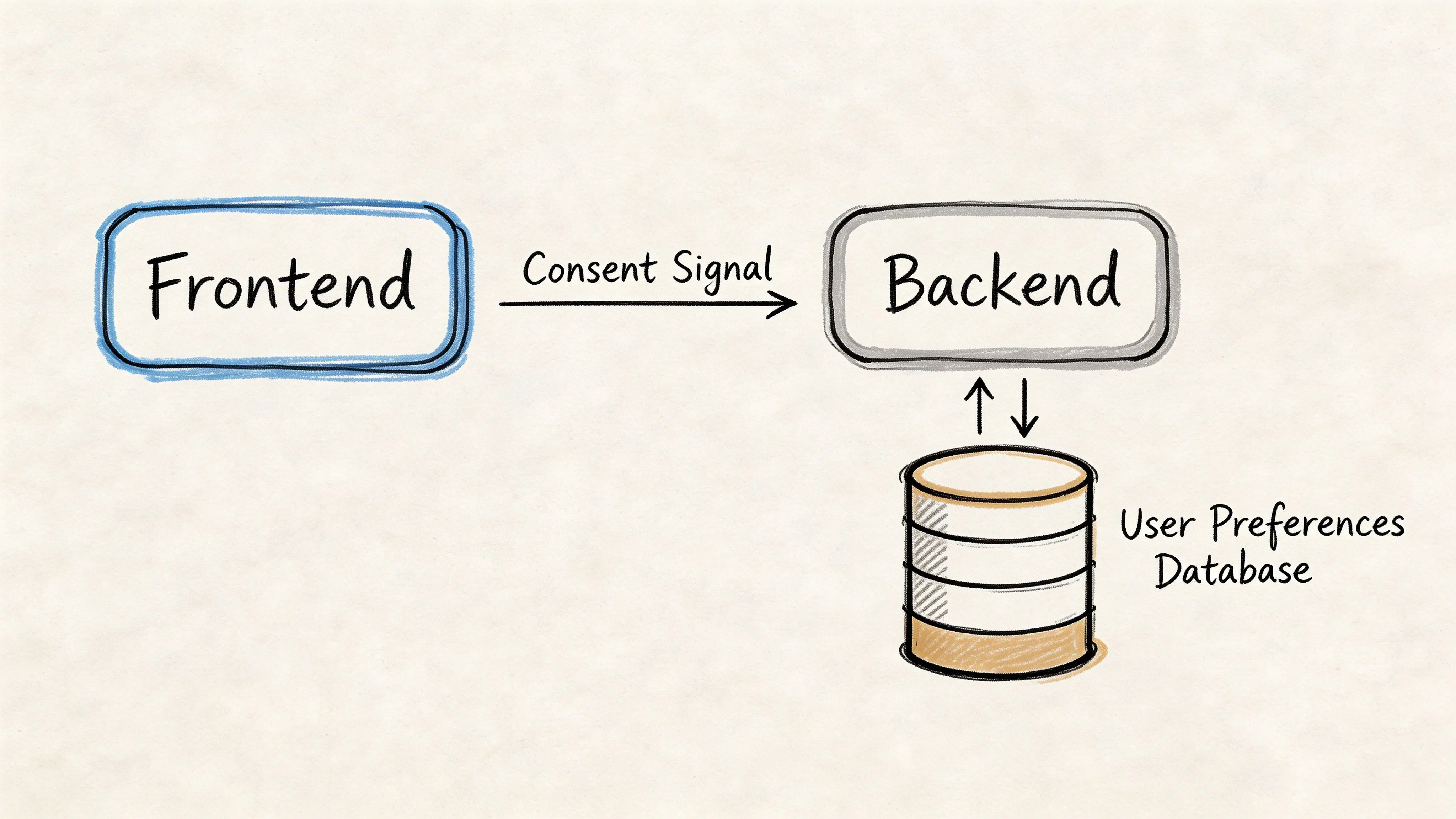
In un design conforme, il consenso è un segnale di controllo. Non è semplicemente una preferenza memorizzata da qualche parte nello stato locale.
Quel segnale deve influenzare:
- Il rendering frontend, così le categorie bloccate non inizializzano
- La gestione dei tag, così gli script dei fornitori non vengono iniettati troppo presto
- La gestione degli eventi backend, così l’inoltro lato server rispetta la stessa decisione
- La persistenza, così il sistema può ricordare e verificare la scelta
- La coerenza tra superfici, così le pagine marketing e le aree di prodotto autenticate si comportano allo stesso modo
Un anti-pattern comune è caricare tutti i fornitori e poi cercare di sopprimere alcuni comportamenti a posteriori. A quel punto, le richieste di rete potrebbero essere già partite e i cookie potrebbero già esistere.
Blocco lato client contro controllo lato server
Esistono due grandi pattern di implementazione. La maggior parte dei sistemi maturi li combina.
Controllo lato client
Questo è il livello visibile. Il browser controlla lo stato attuale del consenso e decide quali script caricare.
Funziona bene quando:
- serve un’attivazione semplice basata su categorie
- il set di fornitori è relativamente piccolo
- il team può mantenere regole rigorose di registrazione degli script
Fallisce quando:
- gli sviluppatori aggiungono tag al di fuori del loader approvato
- le librerie di terze parti caricano a catena script aggiuntivi
- l’app ha più punti di ingresso con bootstrap incoerente
Tagging lato server e routing degli eventi
Questo pattern sposta più controllo fuori dal browser. Invece di permettere a ogni fornitore di eseguire direttamente sul client, l’applicazione invia eventi first-party limitati a servizi backend che decidono cosa può essere inoltrato e a chi.
I vantaggi includono:
- Governance più rigorosa sui fornitori a valle
- Minore proliferazione di script lato client
- Migliore osservabilità di quali dati escono dai tuoi sistemi
- Enforcement più pulito quando il consenso cambia dopo il caricamento iniziale della pagina
I compromessi contano. Il tagging lato server aggiunge complessità operativa. Servono schemi chiari, logica di routing consapevole del consenso e disciplina su ciò che entra nella pipeline fin dall’inizio.
Se non riesci a spiegare quale livello applica il consenso per ciascun fornitore, non hai un’architettura di consenso affidabile.
Decisioni build vs buy
Le organizzazioni in genere scelgono tra tre modelli.
| Modello | Quando è adatto | Rischio principale |
|---|---|---|
| Framework di consenso completamente personalizzato | Prodotti con forte engineering di piattaforma interna e requisiti insoliti | Peso di manutenzione a lungo termine e deriva legale |
| CMP commerciale | Team che hanno bisogno di un rollout più rapido e controlli standard | Integrazione debole se trattata come un plug-in invece che come parte dell’app |
| Approccio ibrido | Piattaforme SaaS con pipeline di eventi personalizzate e UI di consenso standardizzata | Proprietà frammentata tra prodotto, marketing e engineering |
Una piattaforma di gestione del consenso può aiutare, ma solo se è integrata nei punti di enforcement. Un’opzione è la piattaforma di gestione del consenso di Devisia, che acquisisce le scelte dell’utente, memorizza le preferenze di consenso nei cookie di prima parte e valida lo stato del consenso prima che proseguano le richieste o l’elaborazione da parte di terzi. Questo tipo di strumento è utile quando agisce come controllo di sistema, non semplicemente come generatore di banner.
Un pattern di implementazione pratico
Un pattern SaaS efficace spesso appare così:
-
Classifica ogni cookie e tracker Necessari, analitici, pubblicitari, funzionali e qualsiasi categoria a rischio speciale rilevante per il tuo prodotto.
-
Crea un servizio di consenso unico Un’unica fonte di verità per stato corrente, cronologia delle modifiche e regole sensibili alla regione.
-
Blocca per impostazione predefinita I fornitori restano disabilitati a meno che non esista la condizione richiesta.
-
Carica tramite wrapper approvati Nessun embedding diretto di script nei template del prodotto o nei componenti ad hoc.
-
Trasmetti il consenso a valle I job backend, i bus degli eventi e i connettori dei fornitori dovrebbero ricevere lo stesso segnale di policy.
-
Supporta correttamente la revoca Fermare gli eventi futuri fa parte del lavoro. Anche ripulire gli identificatori persistiti può esserlo.
Dove di solito i retrofit si rompono
I sistemi legacy spesso nascondono tracker in punti che il team principale dell’app non governa:
- template CMS
- embed del centro assistenza
- vecchie landing page
- portali di fatturazione
- container del tag manager con accesso di modifica ampio
Ecco perché il privacy-by-design conta. Non è uno slogan. È il riconoscimento che la logica di consenso deve essere intrecciata fin dall’inizio con caricamento, routing e gestione dello stato.
Implementare audit e governance continua
MARKDOWN Un modello di fallimento comune appare così. Il team rilascia un flusso di consenso conforme, il reparto legale approva e tutti vanno avanti. Nei successivi sprint, il marketing aggiunge un nuovo pixel tramite il tag manager, il prodotto abilita un modulo SDK che imposta identificatori di default e il supporto lancia un embed del centro assistenza al di fuori della shell principale dell’app. Il banner continua a essere visualizzato. La policy continua a esistere. Il comportamento effettivo del sistema è cambiato.
Ecco perché il lavoro di audit deve essere operativo, non annuale.
Gli audit dovrebbero verificare il comportamento runtime
Un audit dei cookie utile controlla ciò che il prodotto fa in condizioni reali, non ciò che la policy dice che dovrebbe accadere. Per i team SaaS, significa testare tra stati di consenso, stati utente e superfici di prodotto, quindi confrontare richieste osservate, attività di storage ed elaborazione downstream con le regole previste.
Testa almeno questi casi:
- Prima visita senza scelta di consenso
- Rifiuto esplicito
- Accettazione parziale per categoria
- Revoca del consenso dopo un’accettazione precedente
- Sessioni autenticate
- Sito marketing rispetto alla shell dell’app rispetto agli strumenti incorporati
Includi i percorsi browser e server nella stessa revisione. Vedo regolarmente team bloccare correttamente i tag front-end mentre i servizi backend continuano a inviare dati evento ad analytics o alle piattaforme pubblicitarie perché il consenso non è mai arrivato al consumer della coda, al gestore webhook o alla sincronizzazione con il data warehouse.
Inserisci la governance nel sistema di delivery
La conformità ai cookie si rompe nella gestione delle modifiche molto prima di rompersi nel testo della policy. I nuovi vendor arrivano tramite procurement. I nuovi script arrivano tramite blocchi CMS, strumenti di sperimentazione e widget di supporto. Gli engineer aggiungono SDK per una sola funzionalità e si ritrovano a ereditare un comportamento di tracking che non avevano intenzione di rilasciare.
Il punto di controllo è il flusso di delivery.
Aggiungi release gate che gli engineer utilizzeranno
La revisione privacy funziona meglio quando sfrutta il processo esistente invece di creare un sistema di approvazione parallelo.
-
Definition of ready Qualsiasi nuovo script, SDK o integrazione con vendor necessita di uno scopo dichiarato, categoria cookie, destinatario dei dati, owner e comportamento regionale previsto prima dell’inizio dell’implementazione.
-
Definition of done Le story che introducono tracking necessitano di test sullo stato di consenso, evidenza del comportamento bloccato dove richiesto e conferma che la revoca funzioni dopo l’accettazione.
-
Release review Verifica se la release modifica l’inventario dei cookie, le destinazioni delle richieste, la configurazione del tag manager o i default lato vendor.
Questo è importante nei team di prodotto in rapida evoluzione, soprattutto dove le leggi statali sulla privacy continuano ad ampliarsi, come osservato in precedenza. La parte più difficile è assicurarsi che i rilasci settimanali non aggirino i controlli che hai già costruito.
Aggiungi automazione dove il drift è prevedibile
La revisione manuale intercetta i problemi evidenti. L’automazione intercetta le regressioni che compaiono due settimane dopo.
-
Scanning automatizzato Esegui test browser in staging e in ambienti simili alla produzione per rilevare cookie, scritture su local storage e richieste in uscita in ciascuno stato di consenso.
-
Avvisi di regressione Genera alert su qualsiasi attività di categoria analytics, advertising o funzionale che compaia prima che sia soddisfatta la condizione di consenso richiesta.
-
Controllo della configurazione Limita i diritti di pubblicazione nei tag manager, negli strumenti di consenso, nei template CMS e nei dashboard dei vendor. Gli audit log contano qui.
Un record di consenso aiuta solo se puoi collegarlo al comportamento del sistema che ne è seguito.
Conserva registri che rispondano alle domande sugli incidenti
Quando il reparto legale, un regolatore o un cliente enterprise chiede cosa è successo in una data specifica, il team ha bisogno di più di un flag booleano di consenso. Il record utile è ricostruibile.
Conserva abbastanza dettagli per rispondere a:
- cosa è stato mostrato all’utente
- cosa ha selezionato l’utente
- quando la selezione è stata registrata
- quali categorie, script e flussi di dati sono stati abilitati in base a quella selezione
- se l’utente ha successivamente cambiato la scelta
Di solito ciò significa versionare il testo del consenso, conservare nel tempo le definizioni delle categorie e registrare la decisione di enforcement restituita dal servizio di consenso. Senza tale cronologia, i team possono dimostrare che una scelta è stata raccolta ma non che la piattaforma l’abbia rispettata correttamente.
Assegna la responsabilità prima che lo stack cresca
La governance fallisce quando la responsabilità è implicita invece che nominata. In pratica, la conformità ai cookie coinvolge troppi sistemi perché un solo team possa gestirla da solo, ma ogni area ha comunque bisogno di un decisore chiaro.
Un modello praticabile di solito appare così:
| Area | Owner |
|---|---|
| Interpretazione legale | Responsabile privacy o legale |
| UX e wording del consenso | Product e design |
| Enforcement tecnico | Engineering |
| Inventario dei vendor | Condiviso tra engineering, marketing e procurement |
| Audit continui | Security, privacy o operations della piattaforma |
Se la proliferazione dei vendor, le modifiche al tag manager e gli strumenti incorporati non hanno owner espliciti, i controlli sui cookie deriveranno nel tempo. Il banner sarà l’ultima cosa a rompersi, ed è proprio per questo che il problema sopravvive così a lungo inosservato.
Conclusione Integrare la privacy nel DNA dei tuoi prodotti
La normativa sui cookie web non è difficile perché il banner è difficile da progettare. È difficile perché i moderni prodotti SaaS sono pieni di dipendenze nascoste, giurisdizioni sovrapposte e comportamenti di tracking che si diffondono tra codice frontend, servizi backend e integrazioni con vendor.
Ecco perché il punto di partenza corretto è l’architettura.
I team che fanno bene questo lavoro prendono alcune decisioni disciplinate fin dall’inizio. Classificano chiaramente il tracking. Bloccano per default le tecnologie non essenziali dove richiesto. Rendono il consenso un controllo runtime, non un gesto visivo. Mantengono allineate policy e banner con il comportamento del sistema. Poi eseguono audit continui, perché gli stack di prodotto non restano fermi.
L’approccio opposto è comune e costoso. Un team aggiunge un banner in ritardo, mantiene embed diretti di terze parti ovunque e spera che la disclosure compensi un’esecuzione non controllata. Non funzionerà. Quel modello crea esposizione legale, incoerenza di prodotto e debito tecnico che diventa sempre più difficile da eliminare man mano che la piattaforma cresce.
Per founder e CTO, il punto strategico è semplice. La privacy è una scelta architetturale, non una funzionalità. Quando la tratti in questo modo, il lavoro di conformità diventa più manutenibile. Migliora anche la chiarezza del sistema. Meno script non controllati, flussi di dati più puliti, una migliore supervisione dei vendor e controlli rivolti all’utente più affidabili sono tutti segnali di un prodotto più sano.
La postura privacy più forte raramente deriva dall’aggiungere più strumenti. Di solito deriva dal fare meno assunzioni, caricare meno per default e costruire sistemi che possano dimostrare di aver rispettato la scelta dell’utente.
Se stai costruendo un prodotto SaaS o modernizzando una piattaforma esistente, Devisia può aiutarti a progettare un’architettura consapevole del consenso, flussi di dati allineati alla privacy e pattern di implementazione manutenibili che si adattino ai vincoli reali di delivery.