
Privacy by design e by default non sono compiti di conformità da svolgere in fase avanzata; sono una filosofia architetturale fondamentale. Questo approccio integra la protezione dei dati nel cuore dei tuoi sistemi software fin dall’inizio, invece di considerarla una funzionalità aggiuntiva. Stabilisce la privacy come requisito non funzionale che informa ogni decisione, dalla scoperta iniziale alla messa in produzione e alla manutenzione.
Oltre la conformità: da funzionalità a fondamento
Nella ingegneria del software, trattare un requisito fondamentale come una funzionalità dell’ultimo minuto crea inevitabilmente debito tecnico. Quando quel requisito è la privacy, il debito non è solo tecnico ma anche finanziario e reputazionale.
Il problema è che molte organizzazioni continuano a vedere la protezione dei dati attraverso la lente ristretta della conformità—una checklist per soddisfare normative come il GDPR. Questo atteggiamento reattivo è sia costoso che inefficace. Aggiungere misure di privacy a un sistema preesistente porta a soluzioni fragili e complesse, difficili da mantenere e spesso incapaci di affrontare le vulnerabilità di fondo.
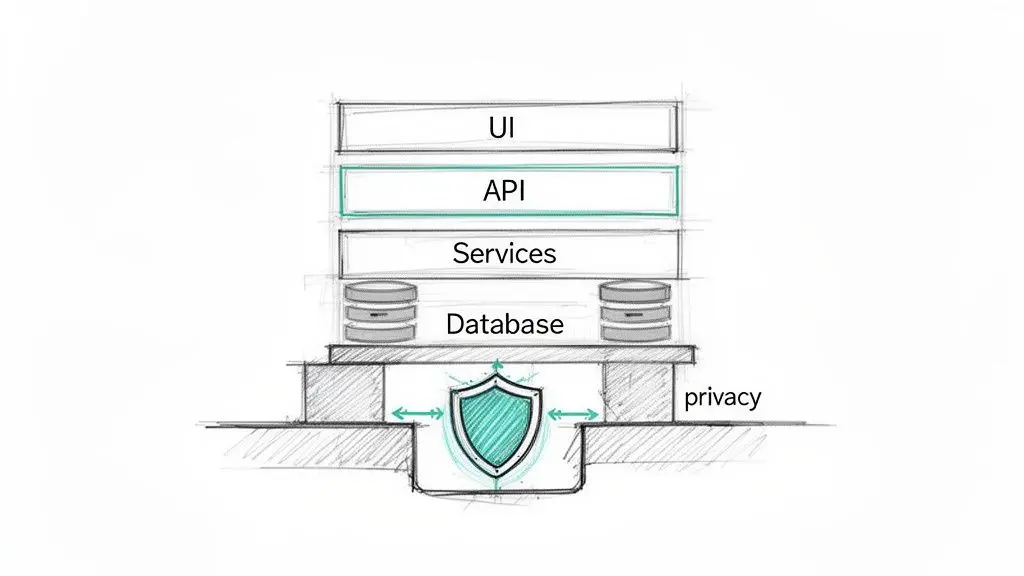
Per i leader tecnici, questo modo di operare introduce rischi significativi:
- Aumento dei costi di sviluppo: Adeguare retroattivamente i controlli di privacy in un’architettura esistente richiede molte più risorse rispetto a progettarli fin dall’inizio. Comporta refactoring complessi, estesi test di regressione e potenziali interruzioni ai servizi in produzione.
- Esperienza utente degradabile: Correzioni dell’ultimo minuto, come banner di consenso intrusivi o funzionalità ridotte, possono alienare gli utenti e erodere la fiducia nel prodotto.
- Vulnerabilità sistemiche: Toppe superficiali spesso non risolvono le debolezze architetturali sottostanti, lasciando i sistemi esposti a violazioni dei dati con conseguenze aziendali potenzialmente catastrofiche.
Il cambiamento necessario nella mentalità
Il principio della privacy by design richiede un approccio proattivo. Significa che le considerazioni sulla privacy devono essere parte integrante della raccolta dei requisiti, della progettazione del sistema e della selezione delle tecnologie. Si tratta di porsi domande critiche prima che venga scritta una singola riga di codice: quali dati sono veramente essenziali? Come li isoleremo? Come li proteggeremo durante il loro ciclo di vita?
Privacy by default, a sua volta, garantisce che le impostazioni più protettive siano abilitate automaticamente, senza richiedere alcuna azione da parte dell’utente. Questo approccio centrato sull’utente dimostra rispetto per i dati personali e costruisce fiducia fin dalla prima interazione. In pratica significa che lo stato predefinito della tua applicazione è il suo stato più sicuro.
La privacy non è una funzionalità da aggiungere; è un requisito non funzionale che definisce l’integrità dell’intero sistema. Non integrarla a livello architetturale è come costruire un grattacielo e cercare di aggiungere le fondamenta alla fine.
In definitiva, adottare privacy by design e by default è una decisione strategica. Sposta la protezione dei dati da un centro di costo gestito dall’ufficio legale a una competenza core del team di ingegneria. Questo cambiamento non solo mitiga il rischio, ma diventa anche un differenziatore potente, favorendo la fiducia degli utenti essenziale per costruire prodotti digitali duraturi e affidabili.
GDPR e il caso di business per una privacy proattiva
Sebbene gli argomenti tecnici a favore di una privacy proattiva siano convincenti, i driver legali e di business sono altrettanto potenti. La privacy non è più un “nice-to-have”; è una necessità legale in molte giurisdizioni e un significativo vantaggio competitivo a livello globale.
Il Regolamento generale sulla protezione dei dati (GDPR) è stato il catalizzatore di questo cambiamento, spostando la privacy da un compito reattivo di conformità a una disciplina ingegneristica centrale. Per qualsiasi azienda che tratta i dati di residenti nell’UE, non è una proposta—è un obbligo legale.
L’obbligo legale dell’Articolo 25
L’Articolo 25 del GDPR è il fondamento giuridico della privacy by design e by default. Obbliga i titolari del trattamento a implementare “misure tecniche e organizzative adeguate” — come la pseudonimizzazione — fin dalle prime fasi di progettazione per integrare i principi di protezione dei dati direttamente nelle attività di trattamento.
Per i team di ingegneria, questo è diventato un requisito vincolante il 25 maggio 2018. Le conseguenze della non conformità sono chiare. A metà 2023, le sanzioni totali per il GDPR avevano raggiunto miliardi di euro, con una percentuale significativa di casi che riguardavano il mancato rispetto di questi principi di progettazione fondamentali.
Non progettare tenendo conto della privacy non è solo un errore di design; è una violazione diretta con gravi ripercussioni finanziarie. Le multe possono arrivare fino a 20 milioni di euro o al 4% del fatturato annuo mondiale dell’azienda, a seconda di quale importo sia maggiore.
Da onere normativo a risorsa aziendale
Considerare questo obbligo solo come un modo per evitare sanzioni significa perdere una grande opportunità strategica. Una posizione proattiva sulla privacy è un investimento in fiducia, resilienza ed efficienza operativa. Inquadra un onere legale in un vantaggio aziendale tangibile.
Considera i benefici:
- Migliore postura di cybersecurity: Privacy e sicurezza sono intrinsecamente legate. Principi come la minimizzazione dei dati—raccogliere solo ciò che è assolutamente necessario—riducendo direttamente la superficie di attacco di un sistema. Meno dati significano meno rischio di una violazione dannosa.
- Differenziazione competitiva: I clienti sono sempre più consapevoli dei propri diritti sui dati. Un prodotto che dimostra rispetto per la privacy per impostazione predefinita costruisce fiducia immediata e diventa un potente argomento di vendita che lo distingue dai concorrenti che trattano la privacy come un ripensamento.
- Riduzione dei costi a lungo termine: È sempre più economico integrare la privacy fin dall’inizio che retrofitarla in seguito. Correggere i difetti di privacy dopo il lancio comporta costosi refactor del codice, migrazioni di dati ad alto rischio e potenziali downtime dei servizi. Un approccio proattivo evita questo accumulo di debito tecnico e di conformità.
Adottare la privacy by design non riguarda solo la mitigazione del rischio; riguarda la costruzione di un prodotto più robusto, affidabile ed efficiente. Trasforma un obbligo legale in una pietra miliare dell’innovazione di prodotto e della gestione del rischio.
Questo approccio crea un circolo virtuoso. Una solida base per la privacy riduce l’esposizione legale e protegge il risultato economico. Costruisce fiducia negli utenti, che a sua volta guida adozione e fidelizzazione. E porta a un’architettura più pulita e manutenibile, abbassando i costi operativi nel lungo periodo. Per un approfondimento sugli obblighi di conservazione dei registri, consulta la nostra guida su Articolo 30 del GDPR per i team di ingegneria.
I sette principi fondamentali della privacy by design
Il concetto di privacy by design è strutturato attorno a sette principi fondamentali. Sviluppato dalla Dr. Ann Cavoukian negli anni ‘90, questo framework fornisce una guida pratica per tradurre obiettivi astratti di privacy in scelte ingegneristiche concrete.
Per i leader tecnici, questi principi fungono da bussola per fare scelte architetturali che prevengano i fallimenti della privacy invece di reagire ad essi. Non si tratta di spuntare una casella di conformità; è un cambiamento fondamentale nel modo di costruire il software.
1. Proattivo, non reattivo; Preventivo, non rimediale
Questo è il principio centrale. Riformula la privacy da esercizio di gestione dei danni a vincolo primario di progettazione. L’obiettivo è anticipare i rischi per la privacy e progettarli fuori dal sistema fin dall’inizio, invece di aspettare che si verifichi una violazione dei dati e poi correre per tamponare le vulnerabilità.
Per un team software, questo significa condurre una Valutazione d’impatto sulla protezione dei dati (DPIA) durante la fase di scoperta, non come un controllo dell’ultimo minuto prima del lancio. Significa scegliere pattern architetturali e tecnologie che limitino intrinsecamente l’esposizione dei dati.
2. Privacy come impostazione predefinita
Questo principio è semplice ma potente: l’impostazione più protettiva deve essere quella predefinita. Nessun utente dovrebbe dover navigare menu complessi per mettere al sicuro i propri dati. Il sistema deve essere sicuro per impostazione predefinita.
Un esempio pratico è un modulo di registrazione SaaS. Invece di una casella già spuntata che iscrive gli utenti alle comunicazioni di marketing, quella casella deve essere non selezionata per impostazione predefinita. Lo stesso vale per lo stack tecnologico. Una chiave API appena generata dovrebbe avere le autorizzazioni minime necessarie, costringendo gli sviluppatori a concedere consapevolmente e esplicitamente accessi aggiuntivi.
3. Privacy integrata nella progettazione
La privacy non può essere un ripensamento o una funzionalità aggiunta alla fine. Deve essere integrata nell’architettura del sistema e nella logica di business con la stessa priorità della performance o della disponibilità.
Ciò significa che le considerazioni sulla privacy influenzano ogni decisione, dalla progettazione dello schema del database (es. separare i dati personali identificabili - PII - dai dati applicativi) all’implementazione dell’interfaccia utente (es. fornire avvisi sulla privacy chiari e contestuali). L’intero sistema è ingegnerizzato con la protezione dei dati come requisito non funzionale fondamentale.
4. Funzionalità completa — Somma positiva, non gioco a somma zero
Un’idea comune è che privacy e funzionalità siano in opposizione—un gioco a somma zero in cui una deve essere sacrificata per l’altra. Questo principio mette in discussione tale nozione, incoraggiando lo sviluppo di soluzioni creative che raggiungano entrambi gli obiettivi.
Per esempio, invece di raccogliere coordinate GPS raw per una funzionalità basata sulla posizione, è possibile che un geohash o dati aggregati offrano lo stesso valore per l’utente senza esporre localizzazioni individuali? La sfida ingegneristica non è scegliere tra privacy e funzionalità, ma innovare in modo da fornire entrambe.
5. Sicurezza end-to-end — Protezione per l’intero ciclo di vita
I dati devono essere protetti per tutto il loro ciclo di vita, dal momento della raccolta fino al momento della cancellazione sicura. Questo principio garantisce che non ci siano anelli deboli nella catena dei dati.
Questo comprende:
- Raccolta sicura: Crittografare i dati in transito utilizzando protocolli moderni e robusti.
- Archiviazione sicura: Usare la crittografia a riposo e implementare rigidi controlli di accesso.
- Elaborazione sicura: Assicurarsi che analisi o trasformazioni dei dati non creino inavvertitamente nuovi rischi per la privacy.
- Distruzione sicura: Utilizzare metodi come la cancellazione crittografica per garantire che, quando i dati vengono eliminati, siano irreversibilmente irrecuperabili.
6. Visibilità e trasparenza — Mantieni tutto aperto
La fiducia si costruisce sulla trasparenza. Utenti, clienti e regolatori devono poter verificare che un sistema operi come dichiarato. Questo richiede pratiche chiare, aperte e responsabili.
Ciò significa una informativa sulla privacy scritta in linguaggio semplice, non in legalese. Significa flussi di dati documentati e logiche di trattamento auditabili. Nel contesto dell’IA, questa trasparenza si estende alla chiarezza sui dati di addestramento e sui meccanismi dietro le decisioni automatizzate.
7. Rispetto della privacy dell’utente — Mantieni un approccio centrato sull’utente
In ultima analisi, la privacy by design significa mettere l’utente al primo posto. L’architettura del sistema e l’interfaccia utente dovrebbero responsabilizzare gli individui, dando loro un controllo significativo sulle proprie informazioni.
Questo si traduce nel fornire opzioni chiare sulla privacy, nel rispettare le scelte degli utenti e nell’usare i loro dati solo per gli scopi specifici e legittimi a cui hanno acconsentito. È una mentalità centrata sull’utente che rispetta l’autonomia individuale e costruisce fiducia duratura.
Integrare la privacy nel ciclo di vita dello sviluppo software
Integrare veramente la privacy by design e by default richiede di andare oltre i principi ed entrare nei processi. Implica trattare la privacy non come un controllo una tantum ma come una disciplina continua intrecciata in ogni fase del ciclo di vita dello sviluppo software (SDLC).
Un approccio reattivo quasi garantisce la creazione di debito tecnico e un aumento del rischio. Un approccio proattivo, invece, costruisce resilienza fin dal primo giorno. Spostando le considerazioni sulla privacy il più a sinistra possibile nel processo di sviluppo—dove le modifiche sono più economiche ed efficaci—queste cessano di essere un ostacolo alla conformità e diventano un motore per l’ingegneria della qualità.
Scoperta e requisiti
Questa è la fase fondamentale in cui i rischi per la privacy vengono identificati e evitati per la prima volta. Ignorare la privacy qui significa costruire su un presupposto errato. L’obiettivo è definire quali dati sono necessari e perché molto prima di scrivere qualsiasi codice.
Azioni chiave durante questa fase includono:
- Condurre una Valutazione d’Impatto sulla Protezione dei Dati (DPIA): Un processo formale per analizzare, identificare e minimizzare sistematicamente i rischi per la protezione dei dati di un progetto. Obbliga a giustificare ogni dato che si intende raccogliere e trattare.
- Creare Diagrammi di Flusso dei Dati (DFD): Visualizzare come i dati si muovono attraverso il sistema. Mappare ogni punto di contatto, dalla raccolta e archiviazione al trattamento e cancellazione. Questo è uno strumento critico per individuare potenziali vulnerabilità precocemente.
- Applicare la minimizzazione dei dati: Questo è il principio più importante in questa fase. Porsi la domanda difficile: ‘Questi dati sono assolutamente essenziali per il funzionamento della funzionalità?’ Se la risposta non è un chiaro ‘sì’, non raccoglierli.
Architettura e progettazione
Con requisiti chiari, l’attenzione si sposta sulla progettazione di un sistema che protegga i dati intrinsecamente. Le decisioni architetturali prese qui hanno conseguenze durature sulla sicurezza e sulla privacy dell’applicazione. Qui i principi di proattività, privacy predefinita e design integrato diventano la pietra angolare della tua architettura.
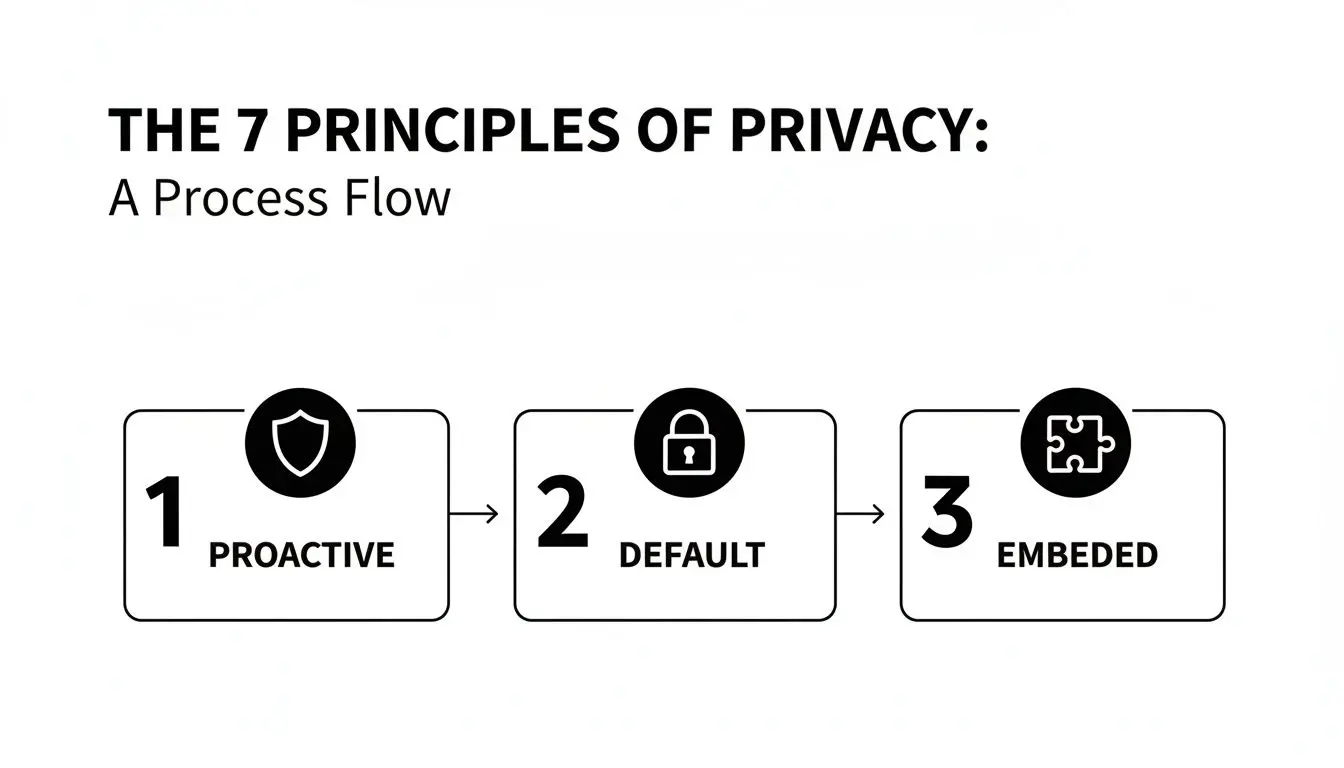
Questi tre concetti si traducono direttamente in scelte architetturali che prevengono i rischi prima che possano materializzarsi.
Importanti pattern di progettazione da considerare includono:
- Pseudonimizzazione e anonimizzazione: Progettare modelli di dati per separare le informazioni identificabili personalmente (PII) dagli altri dati ogni volta che è possibile. Usare tecniche come hashing o tokenizzazione per elaborare i dati senza esporre le informazioni sensibili grezze.
- Configurazioni sicure per impostazione predefinita: Assicurarsi che tutti i componenti del sistema, dai database alle API di terze parti, siano configurati con le impostazioni più sicure fin dall’inizio. Per esempio, un nuovo account utente dovrebbe avere le impostazioni sulla privacy più restrittive abilitate automaticamente, non come opzione da attivare manualmente.
Lo stato predefinito di un sistema riflette le sue vere priorità. Se la privacy non è il valore predefinito, non è una priorità. Questa semplice regola architetturale è un potente litmus test del vostro impegno verso la fiducia degli utenti.
Implementazione
Durante la fase di codifica, gli sviluppatori traducono l’architettura attenta alla privacy in codice sicuro e robusto. Qui i progetti teorici diventano controlli concreti. Una forte cultura ingegneristica è vitale per garantire che queste pratiche siano seguite in modo coerente. Puoi saperne di più leggendo la nostra guida pratica sulla creazione di un codice di condotta per i team di ingegneria e AI.
Le principali pratiche di sviluppo includono:
- Standard di codifica sicura: Attenersi a linee guida consolidate come l’OWASP Top 10 per prevenire vulnerabilità comuni come attacchi di injection o difetti nel controllo degli accessi.
- Librerie a tutela della privacy: Usare librerie ben verificate e affidabili per funzioni critiche come crittografia e autenticazione anziché implementarle da zero.
- Controlli di accesso robusti: Implementare Role-Based Access Control (RBAC) o Attribute-Based Access Control (ABAC) sia a livello di API sia a livello di dati. Assicurarsi che un utente o un servizio possa accedere solo ai dati specifici necessari per la sua funzione legittima.
Test e distribuzione
Le fasi finali riguardano la verifica. I controlli sulla privacy devono essere testati con la stessa rigorosità dei requisiti funzionali. I bug di privacy possono essere critici quanto qualsiasi altro bug.
Attività essenziali in questa fase sono:
- Scansione delle vulnerabilità e test di penetrazione: Sondare attivamente l’applicazione alla ricerca di punti deboli. Utilizzare una combinazione di strumenti automatizzati (SAST, DAST) e test di penetrazione manuali per scoprire falle che potrebbero compromettere i dati degli utenti.
- Audit di configurazione: Prima del deployment, verificare che gli ambienti di produzione non si siano discostati dalle loro configurazioni sicure per impostazione predefinita. Assicurarsi che le modalità di debug siano disabilitate e che tutti i segreti siano gestiti in modo sicuro.
- Test end-to-end del ciclo di vita dei dati: Creare casi di test che seguano i dati in tutto il loro percorso. Confermare che siano correttamente trattati, protetti in ogni fase e che possano essere eliminati in modo sicuro e completo su richiesta.
Pattern architetturali per la privacy in sistemi SaaS e AI
Tradurre privacy by design and by default in software robusto richiede pattern architetturali concreti. Per i moderni sistemi SaaS e AI, questi pattern sono ciò che trasformano la privacy da una casella da spuntare per la conformità in una proprietà intrinseca della piattaforma.
Un’architettura della privacy efficace non riguarda un singolo strumento. È una combinazione deliberata di segregazione dei dati, controlli di accesso rigorosi e tecniche specializzate per carichi di lavoro unici come il machine learning. L’obiettivo è costruire un sistema in cui la privacy è una qualità intrinseca, non un’aggiunta.
Multi-tenancy e segregazione dei dati nelle piattaforme SaaS
In qualsiasi piattaforma SaaS multi-tenant, la sfida principale per la privacy è prevenire la perdita di dati tra tenant. Una violazione nell’account di un cliente non deve mai esporre i dati di un altro. Fare affidamento esclusivamente sulla logica a livello applicativo per far rispettare questa separazione è ingenuo e ad alto rischio.
La vera segregazione deve essere implementata a livello di database. I pattern più comuni includono:
- Database separati: Ogni tenant ha un’istanza di database dedicata. Questo offre l’isolamento più forte ma comporta maggior overhead operativo e costi. È più adatto per clienti enterprise di alto valore che lo richiedono.
- Schemi separati: Tutti i tenant condividono un’istanza di database, ma ciascuno ha uno schema distinto. Fornisce una forte separazione logica con un profilo di costi migliore rispetto ai database separati.
- Schema condiviso con colonna discriminante: Tutti i tenant condividono le stesse tabelle, e una colonna
TenantIDviene utilizzata in ogni query per filtrare i dati. Pur essendo conveniente in termini di costi, questo pattern richiede un’applicazione automatizzata e a prova di errore delle query per impedire a uno sviluppatore di dimenticare la clausolaWHERE TenantID = ?— un errore che potrebbe esporre tutti i dati dei clienti contemporaneamente.
La regola fondamentale della multi-tenancy è di non fidarsi mai solo del livello applicativo per far rispettare i confini dei dati. La segregazione deve essere applicata il più vicino possibile ai dati, idealmente a livello di database, per creare una strategia affidabile di difesa in profondità.
Applicare un vero Controllo di Accesso Basato sui Ruoli
Il Role-Based Access Control (RBAC) viene spesso implementato in modo superficiale, ad esempio nascondendo semplicemente un pulsante nell’interfaccia utente. Questo è pericolosamente insufficiente. Un vero RBAC deve essere applicato a livello di API e dati, assicurando che anche una chiamata API diretta e autenticata non possa aggirare i controlli sulle autorizzazioni.
Una solida implementazione RBAC segue questo schema:
- Definizione centralizzata delle politiche: Ruoli e permessi (es.,
user_can_read_invoice,admin_can_delete_user) sono definiti in un unico luogo auditabile. - Applicazione tramite API Gateway: Un API gateway o middleware intercetta ogni richiesta in arrivo. Verifica il token dell’utente e controlla i suoi permessi rispetto alla policy prima che la richiesta raggiunga la logica applicativa.
- Controlli a livello di database: Per operazioni altamente sensibili, le policy di Row-Level Security (RLS) nel database possono fornire un’ultima barriera di difesa, rendendo impossibile per un utente accedere o modificare righe per le quali non è esplicitamente autorizzato.
Pattern per la privacy nei sistemi AI e LLM
I sistemi AI, in particolare quelli che utilizzano Large Language Models (LLM), introducono nuove sfide per la privacy. Un singolo prompt formulato male potrebbe indurre un modello a divulgare informazioni riservate su cui è stato addestrato.
Pattern architetturali efficaci per l’AI includono:
- Usare embedding per dati sensibili: Invece di inviare testo grezzo e sensibile (come ticket di assistenza clienti) a un LLM, convertirlo prima in vettori numerici (embeddings). Ricerche di similarità e altre operazioni possono quindi essere eseguite su questi embeddings senza esporre il PII originale al modello o a API di terze parti.
- Implementare guardrail per l’AI: Un guardrail per l’AI funge da firewall specializzato tra gli utenti e il modello AI. Intercetta sia i prompt in ingresso sia le risposte in uscita, scansionando e bloccando prompt che richiedono dati sensibili o risposte del modello contenenti PII, parole chiave confidenziali o contenuti tossici. Per approfondire la gestione di questi rischi, esplora la nostra completa Checklist di rischio e privacy per l’AI.
- Mettere in sicurezza gli agenti che chiamano strumenti: Quando gli agenti AI possono chiamare strumenti esterni o API, devono operare sotto un rigoroso modello di sicurezza di minimo privilegio. Ogni agente dovrebbe avere le proprie chiavi API sandboxate con permessi strettamente limitati. Questo impedisce a un agente compromesso di accedere a parti del sistema non previste.
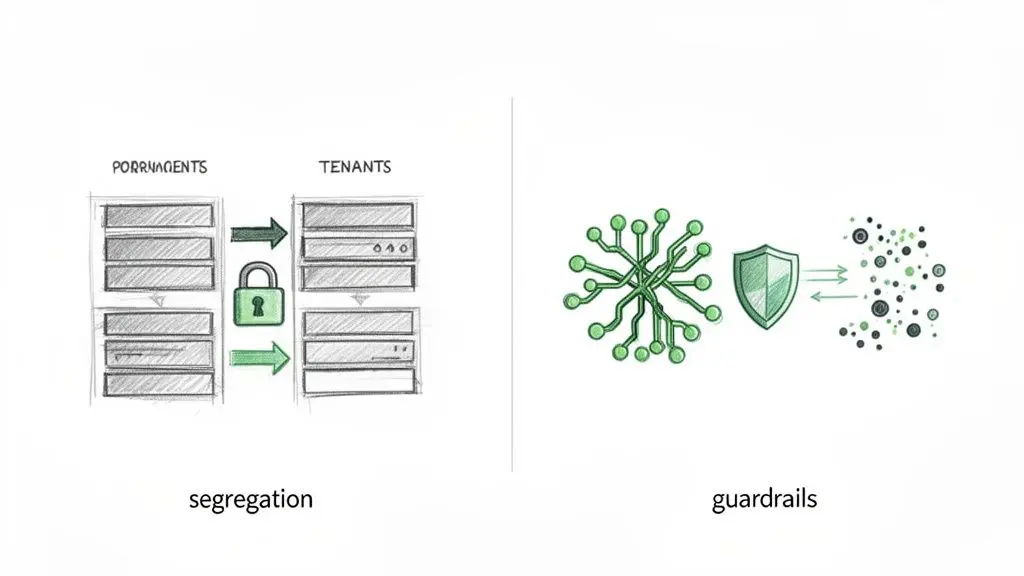
Ognuno di questi pattern comporta compromessi in termini di complessità, costo e prestazioni. Tuttavia, implementarli in modo proattivo è molto meno costoso che gestire le conseguenze di una perdita di privacy. Scegliendo i giusti pattern architetturali, incorpori la privacy direttamente nel DNA del sistema.
Lista di controllo pratica per i team di ingegneria
Conoscere i principi è una cosa; incorporarli nel flusso di lavoro quotidiano di un team è un’altra. Questa checklist non è per un audit di conformità. È una guida pratica per aiutare i team di ingegneria, prodotto e design a porsi le domande giuste al momento giusto durante l’intero ciclo di vita dello sviluppo del software (SDLC).
Scoperta e requisiti
Questa è la migliore opportunità per prevenire il debito di privacy. Gli errori commessi qui sono esponenzialmente più costosi da correggere in seguito.
- Minimizzazione dei dati: Abbiamo messo in discussione ogni dato che intendiamo raccogliere? Possiamo fornire la funzionalità principale con meno dati?
- Limitazione della finalità: Lo scopo specifico e legittimo per ciascun dato è documentato e concordato? Giustificazioni vaghe sono insufficienti.
- Mappatura dei dati: Abbiamo tracciato l’intero ciclo di vita dei dati personali, dalla raccolta alla cancellazione, inclusi tutti i servizi di terze parti e le chiamate API?
- Scatto del DPIA: Il trattamento pianificato determina la necessità di una Valutazione d’Impatto sulla Protezione dei Dati (DPIA) formale ai sensi del GDPR?
Architettura e progettazione
Le decisioni architetturali prese qui definiranno la tua postura sulla privacy per gli anni a venire.
Le impostazioni predefinite del tuo sistema sono una diretta riflessione dei valori della tua azienda. Se l’opzione più privata non è quella predefinita, stai comunicando che la privacy degli utenti non è una priorità.
- Impostazioni predefinite: Tutte le impostazioni rivolte agli utenti e le configurazioni interne sono impostate sull’opzione più privata di default?
- Segregazione dei dati: In un sistema multi-tenant, i dati dei clienti sono adeguatamente isolati a livello di database (es., utilizzando schemi separati o Row-Level Security)?
- Pseudonimizzazione: Possiamo raggiungere l’obiettivo utilizzando token, hash o altre tecniche che evitino di esporre dati personali identificabili (PII)?
Implementazione e testing
Implementazione e testing
Questo è il punto in cui i progetti architetturali diventano codice funzionante e sicuro.
- Codifica sicura: Gli sviluppatori seguono attivamente standard di sicurezza consolidati come l’OWASP Top 10 per prevenire vulnerabilità comuni?
- Controllo degli accessi: Il Controllo degli Accessi Basato sui Ruoli (RBAC) è applicato al gateway API e ai livelli di database, non solo nell’interfaccia utente?
- Crittografia: La nostra strategia di crittografia è applicata in modo coerente per i dati a riposo (in archiviazione) e in transito (attraverso le reti)?
- Limitazioni per l’IA: Per eventuali funzionalità di IA, sono in atto misure di contenimento per prevenire sia iniezioni malevole di prompt sia la divulgazione accidentale di informazioni personali identificabili (PII) nelle risposte del modello?
Deployment and Maintenance
La privacy è una disciplina continua, non una funzionalità da attivare una tantum al lancio.
- Configurazione sicura: Abbiamo verificato i nostri ambienti di produzione? Gli strumenti di debug sono disabilitati? I segreti sono gestiti da un opportuno gestore di segreti?
- Cancellazione dei dati: Abbiamo un processo affidabile, automatizzato e verificabile per soddisfare completamente le richieste di cancellazione dei dati?
- Gestione degli incidenti: Il nostro piano di risposta agli incidenti viene testato regolarmente? In caso di violazione è necessaria memoria muscolare, non un documento.
Domande frequenti
Quando si implementano privacy by design e privacy by default, i responsabili tecnici e di business spesso incontrano le stesse domande pratiche. Ecco risposte chiare alle domande comuni di CTO, fondatori e responsabili della compliance.
Qual è la vera differenza tra privacy by design e privacy by default?
Pensalo come la costruzione di un edificio. Privacy by Design è il progetto architettonico. È il lavoro proattivo svolto in anticipo per incorporare la protezione dei dati nelle fondamenta del sistema, influenzando ogni scelta dai modelli di dati alle strutture delle API.
Privacy by Default è lo stato dell’edificio quando consegni le chiavi. È il risultato visibile all’utente di quel progetto. Garantisce che quando un utente interagisce per la prima volta con il sistema, le sue impostazioni siano configurate automaticamente per il livello più alto di privacy senza richiedere alcuna azione da parte sua.
Ad esempio, il vostro lavoro di progettazione potrebbe prevedere la creazione di una funzione per condividere l’attività dell’utente. L’implementazione predefinita assicura che questa funzione sia disattivata quando viene creato un nuovo account.
Come si applica questo quando si utilizzano API di terze parti?
La tua responsabilità per la protezione dei dati non termina al confine del tuo sistema. Quando integri un’API di terze parti, resti responsabile dei dati che trasmetti.
Le considerazioni chiave includono:
- Minimizzazione dei dati: Invia solo il minimo indispensabile di dati richiesto per il funzionamento della chiamata API. Non trasmettere un intero oggetto utente quando l’API ha bisogno solo di un ID utente.
- Garanzie contrattuali: I tuoi contratti con i fornitori devono definire chiaramente le loro responsabilità in materia di protezione dei dati, incluso come trattano i dati e i loro obblighi in caso di violazione.
- Controllo della sicurezza: Valuta le pratiche di sicurezza dell’API come se fossero le tue. Valuta i loro standard di crittografia e i meccanismi di controllo degli accessi. Tratta il servizio di terze parti come un’estensione diretta della tua architettura.
Questo è rilevante solo per la conformità al GDPR?
No. Mentre l’Articolo 25 del GDPR ha stabilito privacy by design e privacy by default come obbligo legale per il trattamento dei dati dei residenti nell’UE, i principi sono ormai una best practice globale. Concetti simili sono alla base di normative in tutto il mondo, dalla PIPEDA canadese alla LGPD brasiliana.
Oltre alla conformità, questi principi sono semplicemente buone pratiche di ingegneria e gestione del rischio. Implementarli riduce la probabilità di una dannosa violazione dei dati, costruisce la fiducia fondamentale degli utenti e riduce il costo a lungo termine della manutenzione del sistema. È una decisione ingegneristica strategica, non solo un requisito legale.
Costruire prodotti digitali affidabili con la privacy al centro è un compito complesso ma essenziale. In Devisia, aiutiamo le aziende a trasformare la loro visione in software manutenibile e sistemi abilitati all’IA, con un chiaro focus su architettura pragmatica e valore misurabile.
Scopri come possiamo costruire la tua prossima piattaforma con la privacy come scelta fondamentale.