
Una scadenza familiare arriva tardi nello sprint. Uno sviluppatore ha un branch pieno di logging temporaneo, fix testati solo in parte, un refactoring abbandonato e una modifica di configurazione che conta davvero. Il codice gira ancora in locale, ma nessuno può dire con sicurezza quali modifiche debbano restare e quali debbano sparire.
Non è un problema banale di manutenzione. In un sistema aziendale, uno stato locale disordinato rallenta le revisioni, crea commit difettosi e introduce rischi evitabili nel lavoro di rilascio. La situazione è peggiore nelle piattaforme SaaS, nelle integrazioni AI e negli ambienti regolamentati, dove i team hanno bisogno di un resoconto chiaro di ciò che è cambiato, del motivo per cui è cambiato e di ciò che non avrebbe mai dovuto lasciare un laptop.
Git offre diversi modi per annullare il lavoro locale. Il problema è che non risolvono tutti la stessa cosa. Alcuni comandi puliscono la working directory. Altri toccano solo l’area di staging. Altri riscrivono la cronologia locale. Alcuni sono sicuri nei branch collaborativi, e alcuni assolutamente no.
Questa capacità decisionale conta perché Git fa parte del lavoro ingegneristico quotidiano di quasi ogni team software moderno. Il 95,7% degli sviluppatori usa Git ogni giorno, secondo il 2023 Stack Overflow Developer Survey, e un report GitHub Octoverse del 2022 ha osservato che i repository in Nord America avevano in media il 28% dei commit che coinvolgevano azioni di annullamento come i reset, evidenziando quanto queste operazioni siano centrali nei flussi di consegna (riepilogo di GeeksforGeeks e riferimenti citati).
Un team forte non considera il revert come un recupero di panico. Lo considera come controllo di routine. Gli sviluppatori dovrebbero poter sperimentare liberamente, scartare in sicurezza e mantenere pulita la cronologia prima che il codice raggiunga i branch condivisi. Questo è il nucleo pratico di git come ripristinare le modifiche locali. Usa il comando meno distruttivo che risolve esattamente il problema che hai davanti.
Introduzione Il caos inevitabile dello sviluppo locale
Spesso tutto inizia con una piccola modifica ragionevole.
Un ingegnere aggiunge trace logging per inseguire un fallimento intermittente della coda. Poi prova un percorso di retry diverso. Poi regola un template di prompt collegato a una chiamata LLM. Poi modifica una configurazione locale per far passare un test di integrazione oltre un disallineamento di dipendenza. Qualche ora dopo, il branch contiene progressi reali, esperimenti usa e getta e modifiche che dovrebbero restare su una sola macchina.
Questo è sviluppo ordinario. Il rischio nasce dal fraintendere che tipo di modifica locale si abbia.
In pratica, i team perdono tempo quando trattano ogni problema di pulizia come lo stesso problema. Un file modificato nell’albero di lavoro richiede un comando. Un file messo in staging per errore ne richiede un altro. Un commit locale non ancora pushato pone una domanda diversa: mantenere le modifiche o rimuoverle con il commit.
Perché il disordine locale diventa un problema aziendale
In un progetto personale, uno stato locale disordinato è di solito solo una seccatura. In una codebase di produzione, influisce sulla delivery, sulla qualità delle revisioni e sulla verificabilità.
La pressione del rilascio fa emergere rapidamente il problema. Uno sviluppatore che prepara un hotfix non può permettersi di indovinare se restore, reset o una riscrittura della cronologia sia la mossa giusta. Una scelta sbagliata può cancellare lavoro che ha richiesto ore, oppure lasciare dietro di sé modifiche parziali che finiscono nel commit successivo. Su iniziative condivise, quel tipo di confusione si trasforma in churn del branch, revisioni rumorose e ritardi evitabili.
Le questioni di sicurezza e conformità peggiorano la situazione. Credenziali temporanee, flag di debug, artefatti generati e modifiche solo per i test hanno l’abitudine di finire in staging quando qualcuno ha troppa fretta con git add .. Una volta accaduto, la pulizia diventa più difficile e aumenta la probabilità di un commit errato.
I rischi che si presentano ripetutamente sono tre:
- Rischio di delivery: il lavoro di rilascio rallenta perché gli ingegneri non riescono a tornare rapidamente a uno stato locale noto e valido.
- Rischio di integrità: modifiche temporanee o non revisionate vengono commitate e successivamente mergeate.
- Rischio di collaborazione: gli sviluppatori usano comandi distruttivi nel contesto sbagliato e creano conflitti di branch o perdono lavoro recuperabile.
Regola pratica: scegli il comando meno distruttivo che risolve esattamente lo stato che hai davanti.
Su cosa ottimizzano i team forti
I team solidi non trattano il revert locale come una mossa di panico. Lo trattano come un controllo di routine su tre livelli separati dello stato di Git: working directory, index e cronologia dei commit locali.
Questa distinzione conta perché ogni livello ha un costo di recupero diverso. Annullare una modifica di file non ancora staged è di solito a basso rischio. Annullare il lavoro staged richiede attenzione, perché potresti voler mantenere la modifica mentre la rimuovi dal commit successivo. Riscrivere i commit locali è ancora sicuro prima del push, ma solo se l’ingegnere è esplicito sul fatto che le modifiche ai file debbano rimanere nell’albero in seguito.
Una semplice tabella decisionale tiene i team lontani dai guai:
| Situazione | Preoccupazione principale | Direzione sicura |
|---|---|---|
| File modificato ma non staged | Rimuovere le modifiche indesiderate | Ripristinare il working tree |
| File staged per errore | Separare l’index dalle modifiche locali | Prima unstage, poi scarta |
| Commit presente localmente ma non pushato | Riscrivere con attenzione la cronologia locale | Reset con un percorso di recupero esplicito |
La prospettiva dell’ingegnere senior
Il comando giusto dipende da dove si trova l’errore.
Se il problema è solo nella working directory, evita modifiche alla cronologia. Se il problema è nell’index, separa lo staging dal contenuto del file prima di cancellare qualcosa. Se il problema è un commit locale, decidi in anticipo se devi preservare il codice per ulteriori modifiche oppure rimuoverlo completamente.
Questo processo decisionale mantiene veloce la sperimentazione senza lasciare che gli errori di pulizia si trasformino in ritardi di progetto o in una cronologia difettosa.
Scenario 1 Ripristinare le modifiche non staged nella working directory
Uno sviluppatore modifica app.js per tracciare un bug che si manifesta solo in produzione, ritocca un file di configurazione locale per raggiungere un servizio di staging, poi si rende conto che nessuno di quei lavori dovrebbe sopravvivere al pomeriggio. È il caso di revert più pulito in Git, ma solo se si conferma che le modifiche non sono staged prima di scartarle.
Le modifiche non staged vivono solo nella working directory. Nessuna cronologia dei commit è stata riscritta. L’index rappresenta ancora l’ultimo stato intenzionale. Per il software critico per il business, questo rende questo percorso di rollback il meno rischioso, e anche quello che i team usano in modo improprio agendo troppo in fretta.

Verifica lo stato prima di cancellare il lavoro
Parti da qui:
git statusQuesto comando risponde alla decisione che conta: le modifiche sono solo nell’albero di lavoro, oppure qualcuno ha già messo in staging parte del lavoro?
Se il file appare sotto Changes not staged for commit, puoi ripristinarlo senza toccare l’index o la cronologia locale. Se appare tra le modifiche staged, fermati e usa invece il flusso di lavoro per gli staged. I team perdono lavoro utile quando saltano questa distinzione e lanciano un comando di discard per abitudine.
Usa git restore quando l’obiettivo è chiaro
Nelle versioni attuali di Git, git restore <file> è il comando più sicuro, in linguaggio semplice, per scartare le modifiche non staged in un file tracciato.
git restore app.jsGit sostituisce la copia di lavoro con la versione attualmente registrata nell’index. Questo comportamento è esattamente quello che vuoi quando un esperimento locale è fallito, una modifica di debug non serve più, o uno sviluppatore ha cambiato il file sbagliato andando di fretta.
Esempi:
- Rimuovere modifiche temporanee alla configurazione:
git restore .env.example - Scartare il logging di debug da un controller:
git restore src/controllers/orders.js - Eliminare tutte le modifiche tracciate non staged nel repository:
git restore .
git restore . è efficiente, ma merita una regola di team. Usalo solo dopo aver controllato l’elenco dei file e deciso che ogni modifica non staged sia sacrificabile. Su branch grandi, un comando ampio può cancellare una correzione utile mescolata a modifiche usa e getta.
Riconosci la sintassi più vecchia, ma preferisci quella più chiara
Vedrai ancora documentazione più datata, cronologie di shell e runbook interni che usano git checkout, <file>.
git checkout, <file>Per esempio:
git checkout, app.jsQuesta sintassi funziona ancora per ripristinare un file tracciato dall’index. Il problema non è la capacità. Il problema è l’ambiguità. checkout cambia anche branch e può influenzare lo stato di HEAD, quindi chiede agli ingegneri di dedurre l’intento dal contesto. Nei team con livelli di seniority misti, questa è una fonte evitabile di errori.
git restore riduce quell’ambiguità. Dice esattamente cosa sta accadendo, il che rende più puliti il code review, il debug in coppia e la risposta agli incidenti.
Un modello operativo pratico per i team
Usa una sequenza breve e fallo sempre allo stesso modo:
- Ispeziona:
git status - Ripristina l’ambito giusto:
git restore <file>per una pulizia chirurgica, oppuregit restore .per uno scarto completo confermato - Verifica: di nuovo
git status
Il controllo finale non è una formalità. Conferma che il revert abbia corrisposto all’intento e che non ci siano ancora file staged o non tracciati che richiedono attenzione.
Quando fermarsi prima di ripristinare
Non ogni modifica non staged dovrebbe essere scartata immediatamente.
Fermati se il file è una configurazione locale che potrebbe contenere conoscenze specifiche dell’ambiente, una migrazione modificata a mano o una correzione parzialmente corretta che potrebbe servirti più avanti. In quei casi, copia il frammento altrove, usa lo stash in modo selettivo oppure trasforma il lavoro in un commit di bozza su un branch di prova. La pulizia rapida è utile. La pulizia recuperabile è migliore.
La stessa disciplina vale fuori da Git. Gli ingegneri che passano molto tempo negli editor da terminale di solito traggono beneficio dal conoscere anche il percorso esatto di undo lì, specialmente con workflow come annullare nell’editor Vim.
Modalità di errore comuni
Alcune abitudini creano rischi inutili:
- Scartare prima di ispezionare: veloce, ma facile da applicare male
- Usare comandi di restore su tutto il repository su un branch attivo: efficiente, ma distruttivo se un file è ancora importante
- Assumere che il lavoro non staged sia recuperabile più tardi: spesso falso una volta che la copia di lavoro viene sovrascritta
- Trattare allo stesso modo file generati e codice scritto a mano: hanno costi di recupero diversi
Lo standard professionale è semplice. Decidi a quale stato deve tornare il file, conferma dove vive la modifica, poi esegui il comando più mirato che ti porta lì.
Scenario 2 Rimuovere file dallo staging e ripristinare le modifiche staged
Un errore comune nella settimana del rilascio inizia nello stesso modo. Qualcuno esegue git add ., mettendo in staging il cambiamento di codice previsto, e anche un log, un asset generato o un fixture di test locale che non ha posto nel commit successivo.
A quel punto, la decisione non è più solo “come lo rimuovo?” La domanda chiave è dove vive lo stato indesiderato. Se il file è solo staged, toglilo dallo staging. Se sia il contenuto staged sia il file locale devono sparire, prima togli dallo staging, poi ripristina il file. Quest’ordine riduce le perdite accidentali.
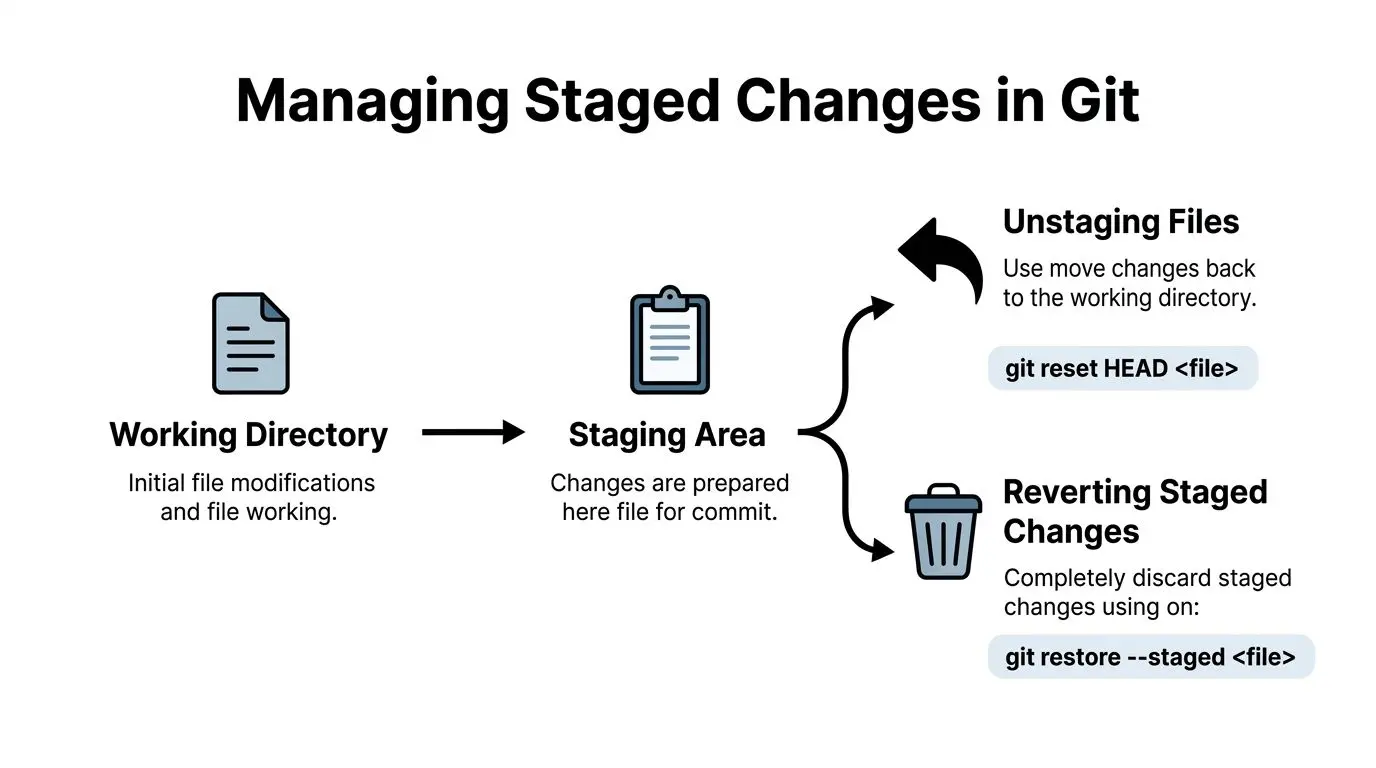
Inizia separando due decisioni
L’area di staging è un buffer di revisione. Trattala come tale.
git add dice: “includi questo nel prossimo commit.” Non significa “questi contenuti del file sono finali”, e certamente non significa “cancella qualcosa di cui ora mi pento”. I team che separano queste scelte producono commit più puliti e si riprendono più rapidamente quando qualcuno mette in staging il file sbagliato sotto pressione.
Per Git moderno, il primo passo più chiaro è:
git restore --staged logs/debug.logQuesto rimuove il file dall’indice e lascia invariata la copia di lavoro.
Questo spesso è sufficiente. Se il file ha ancora un valore locale, fermati qui.
Se il file deve sparire completamente
A volte il file già messo in stage è puro rumore. Un log di debug, l’output di build o un’esportazione temporanea non dovrebbero rimanere nel commit né su disco. In quel caso, usa il secondo comando solo dopo aver confermato che il file sia sicuro da scartare.
git restore --staged logs/debug.log
git restore logs/debug.logIl primo comando cambia ciò che verrà commitato. Il secondo sovrascrive il file locale per farlo corrispondere a HEAD.
Questa distinzione conta nei repository business-critical. Togliere dallo stage è in genere a basso rischio. Ripristinare il contenuto del file è distruttivo.
Il vecchio flusso di lavoro funziona ancora
Molti team usano ancora la vecchia coppia di comandi:
git reset HEAD <filename>
git checkout, <filename>Per esempio:
git reset HEAD logs/debug.log
git checkout, logs/debug.logQuesto rimane valido su molti sistemi, ma è più facile usarlo male perché il secondo comando elimina immediatamente il contenuto locale. git restore rende più chiara l’intenzione, ed è per questo che lo consiglio ai team che vogliono ridurre gli errori evitabili.
Consiglio operativo: Se c’è anche solo un dubbio sul fatto che il file contenga lavoro utile, fermati dopo averlo tolto dallo stage. Rimuovere un file dal prossimo commit è una decisione più piccola che cancellarne il contenuto.
Un percorso decisionale pratico
Usa questo insieme rapido di regole quando un file già messo in stage non dovrebbe esserci:
| Situazione | Comando | Risultato |
|---|---|---|
| Messo in stage per errore, ma le modifiche locali potrebbero ancora servire | git restore --staged <file> | Rimuove dall’indice, mantiene le modifiche locali |
| Messo in stage per errore, e anche le modifiche locali devono essere scartate | git restore --staged <file> poi git restore <file> | Rimuove dall’indice, reimposta il file a HEAD |
| Incerto se il lavoro possa servire più tardi | git stash push -m "pre-discard backup" prima del ripristino | Salva una copia recuperabile prima della sovrascrittura |
Quest’ultima opzione non è una formalità. È un punto di sicurezza per le decisioni incerte, soprattutto quando il file è stato modificato durante il debug e nessuno ha confermato se parte della modifica debba sopravvivere.
Esempio: pulizia dopo git add .
Supponiamo che git add . abbia catturato sia una modifica valida al codice sia un file di log che non vuoi.
Esegui:
git status
git restore --staged logs/debug.log
git restore logs/debug.logPoi correggi la causa ricorrente, se necessario:
echo "*.log" >> .gitignore
git add .gitignoreUna pulizia una tantum risolve il problema immediato. Una regola di ignore impedisce che lo stesso errore riappaia nel patch cycle successivo.
Rischio a livello di team da monitorare
Cattive abitudini nello staging creano commit misti. I commit misti rallentano la revisione, complicano il rollback e rendono gli audit più difficili perché modifiche non correlate viaggiano insieme.
I team senior in genere evitano tre pattern:
- Usare
git add .senza controllare poigit status - Eseguire un comando di unstage e un comando di discard come se fosse un unico riflesso
- Consentire a recidivi come log, artefatti di build e file di export di restare fuori da
.gitignore
Lo standard pratico è semplice. Identifica se il problema è nell’indice, nell’albero di lavoro o in entrambi. Poi usa il comando più mirato che riporti il file allo stato corretto con il minor rischio possibile.
Scenario 3 Ripristinare commit locali non ancora pushati
Fai un commit di una correzione a fine giornata, esegui un altro test e ti rendi conto che il branch contiene ora la modifica sbagliata del timeout, rumore di debug e un unico miglioramento valido. A quel punto, il compito non è più ripulire i file. È scegliere il modo meno rischioso per riscrivere la cronologia locale senza perdere il lavoro che il team potrebbe ancora servire domani.
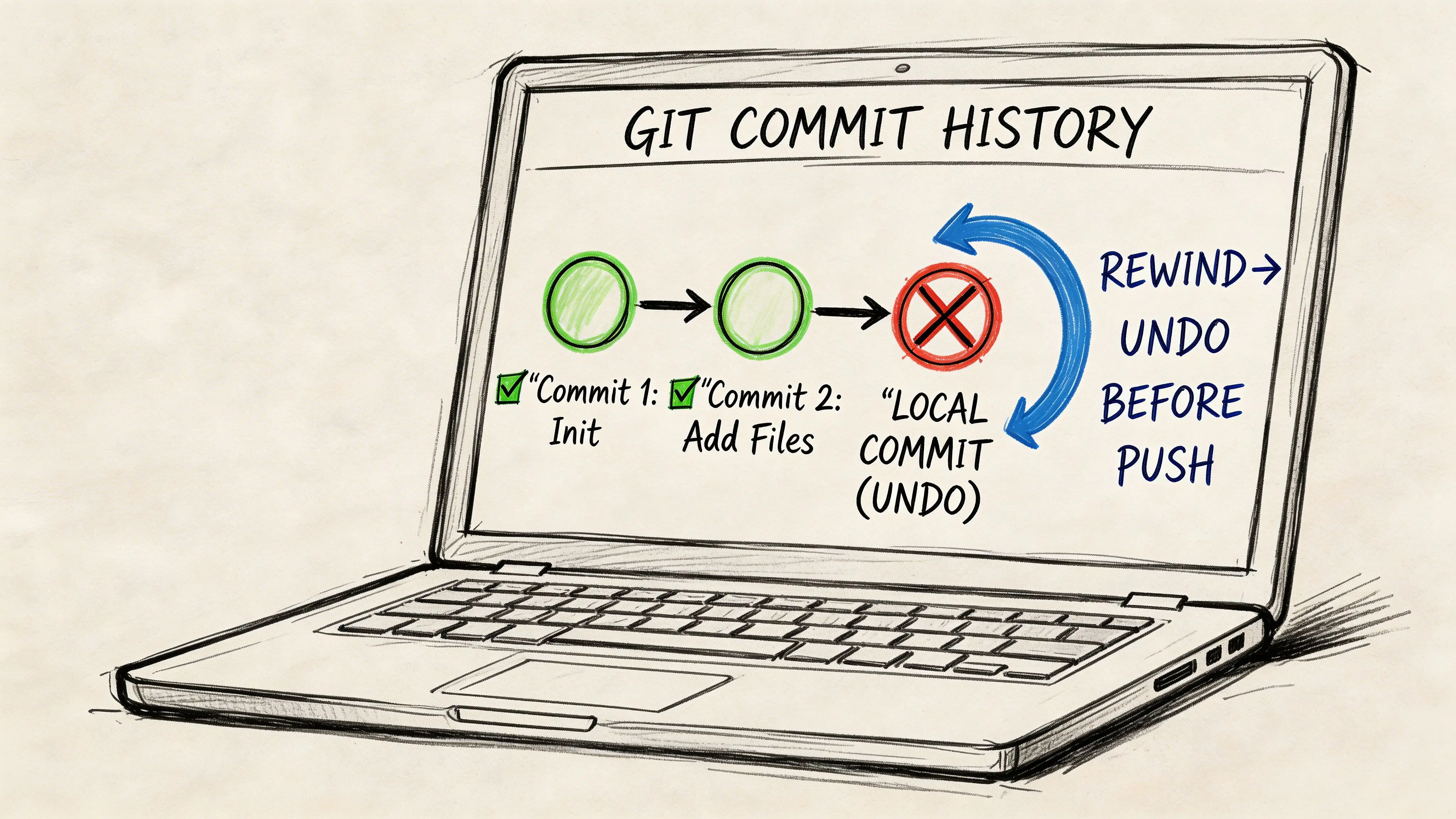
git reset è in genere lo strumento giusto qui, ma il nome del comando non è la decisione. La decisione è cosa deve sopravvivere al reset: i commit, le modifiche al codice o nessuno dei due.
Parti dalla domanda di sopravvivenza
Prima di digitare qualcosa, rispondi a questo:
Le modifiche al codice devono rimanere disponibili dopo la rimozione del commit?
Questa sola risposta separa la pulizia sicura della cronologia dalla perdita di dati evitabile. Nei team di delivery che lavorano su sistemi business-critical, la tratto come una questione di igiene del rilascio, non di preferenza personale su Git. Un cattivo reset locale può cancellare lavoro di investigazione, prove di test o una correzione parziale che conta ancora.
git reset --soft
Usa --soft quando il commit deve sparire, ma le modifiche devono rimanere già messe in stage per il commit successivo.
git reset --soft HEAD~1Usalo quando:
- il messaggio del commit è sbagliato
- più commit locali dovrebbero diventare un unico commit pulito
- il codice è corretto, ma il confine del commit è sbagliato
Questo è il rewrite con il minor attrito perché Git mantiene le modifiche già in stage e pronte per essere ricommitate.
git reset --mixed
Usa --mixed quando il commit deve sparire e il codice deve restare, ma vuoi riesaminare o dividere di nuovo le modifiche.
git reset HEAD~1oppure esplicitamente:
git reset --mixed HEAD~1Questo riporta HEAD indietro e lascia le modifiche dei file nella working directory, non messe in stage. In pratica, questo è il default giusto per la pulizia locale perché ti offre un ulteriore punto di controllo prima del commit successivo.
Lo uso quando il codice può essere in parte corretto ma il commit è stato assemblato male. Succede spesso dopo sessioni di debug, patch urgenti o modifiche ampie fatte sotto pressione di tempo.
git reset --hard
Usa --hard solo quando sia il commit sia le modifiche sottostanti dei file devono essere rimossi dallo stato corrente del branch.
git reset --hard HEAD~1Oppure per puntare a un commit specifico:
git log --oneline -10
git reset --hard abc1234È veloce. È anche distruttivo.
Su un branch locale privato, può essere accettabile se l’intenzione è chiara e il branch non è stato pushato. Su qualsiasi branch che un altro ingegnere potrebbe usare, le riscritture della cronologia richiedono più disciplina. Se devi puntare a un punto precedente della cronologia con maggiore precisione, questa guida su ripristinare a un commit specifico in Git copre in modo più dettagliato il lato della selezione del commit.
Riscrivi la cronologia locale solo quando sei certo che nessun altro sviluppatore dipenda da essa.
Scegli il comando in base al risultato
| Se il tuo obiettivo è | Usa | Cosa conserva Git |
|---|---|---|
| Ricommitare immediatamente le stesse modifiche | git reset --soft <target> | Le modifiche restano in stage |
| Rielaborare le modifiche prima di un nuovo commit | git reset --mixed <target> | Le modifiche restano nella working directory |
| Rimuovere i commit e le modifiche | git reset --hard <target> | Non restano né modifiche in stage né nella working directory |
Questo schema funziona bene nei team perché associa il comando al risultato di delivery. Gli ingegneri fanno meno errori quando decidono in base a ciò che deve rimanere recuperabile.
git reflog è la rete di sicurezza
Anche gli sviluppatori esperti a volte scelgono la modalità di reset sbagliata. git reflog esiste esattamente per questa situazione.
Esegui:
git reflogGit registra i movimenti recenti di HEAD, inclusi reset, checkout e rebase. Se trovi lo stato che ti serve, ripristinalo con:
git reset --hard HEAD@{N}Sostituisci N con la voce corretta del reflog.
Il recupero è spesso possibile perché il riferimento del commit di solito esiste ancora nel reflog per un certo periodo di tempo. Questo non rende i reset distruttivi sicuri di default. Significa che hai un piano di recupero se agisci in fretta e sai quale stato stai ripristinando.
Una breve spiegazione visiva aiuta se stai insegnando questo a un team o stai formando sviluppatori meno esperti:
Un percorso decisionale realistico
Supponiamo che uno sviluppatore faccia tre commit locali durante il debug di un’integrazione di billing:
- il commit 1 aggiunge una validazione utile
- il commit 2 aggiunge tracing temporaneo
- il commit 3 modifica la gestione del timeout nella direzione sbagliata
Se l’obiettivo è mantenere tutto il codice ma ricostruire in modo pulito la cronologia dei commit, git reset --mixed HEAD~3 è di solito la scelta più sicura. Le modifiche restano nella working tree e lo sviluppatore può separare il lavoro valido dal rumore di debug prima di ricommitare.
Se l’obiettivo è mantenere solo il commit 1 e scartare i commit 2 e 3, git reset --hard <commit-1> può essere corretto. Usalo solo dopo aver confermato che quei commit successivi non sono mai stati pushati e che nessun altro ne ha bisogno per l’analisi.
Questo incarna la disciplina per il ripristino dei commit locali: decidi cosa deve sopravvivere, conferma se il branch è ancora privato e scegli il reset più mirato che ti riporti a uno stato pulito.
Scenari avanzati di ripristino e protocolli di sicurezza
Un branch di release è verde in CI, ma l’ambiente locale di un ingegnere continua a fallire perché file generati, reset parziali e una worktree secondaria hanno lasciato il branch in uno stato che nessuno riesce a riprodurre. È il punto in cui la pulizia locale smette di essere una preferenza personale e diventa un rischio operativo.
La regola pratica è semplice. Abbina il comando al tipo di stato che stai correggendo, poi aggiungi un controllo di sicurezza prima di qualsiasi operazione distruttiva. I team che rilasciano software business-critical hanno bisogno di abitudini ripetibili qui, soprattutto nei repo che generano output di build, usano worktree o mantengono branch di release a lunga durata.
git clean per i file non tracciati
git restore e git reset gestiscono solo i contenuti tracciati. Non rimuovono file o directory non tracciati, che spesso sono una fonte primaria di confusione dopo esecuzioni locali di test, generazione di asset o build di framework.
Usa:
git clean -fdAnteprima prima:
git clean -fdnQuel dry run dovrebbe essere una policy di team, non un extra facoltativo. I file non tracciati sono spesso eliminabili, ma non sempre. Vedo regolarmente dump SQL locali, script di debug, fixture esportate ed evidenze di incidenti fuori dal version control. Un git clean -fd cieco rimuove tutto.
Se il repo ignora anche l’output di build, controlla se stai per rimuovere anche i file ignorati. In quel caso, i team a volte ricorrono a git clean -fdx, che è più distruttivo e più facile da usare male.
git stash prima di operazioni distruttive
Usa stash quando la decisione è ancora incerta.
git stash push -m "backup"Funziona bene prima di ripristini ampi di file, reset hard o pulizie in una working tree rumorosa. Offre allo sviluppatore un punto di controllo mentre decide cosa appartiene al branch finale e cosa deve sparire.
Lo stash ha dei limiti. Non dovrebbe sostituire piccoli commit disciplinati su un branch privato. È una misura di sicurezza a breve termine per stati incerti, non una registrazione duratura dell’intenzione.
Usalo immediatamente in tre casi:
- Prima di scarti ampi: quando più file stanno per essere ripristinati o eliminati
- Prima di
git reset --hard: quando i commit locali possono contenere ancora lavoro utile di investigazione - Prima di una pulizia mixed: quando file generati, modifiche già in stage e modifiche manuali sono tutti presenti insieme
I worktree richiedono disciplina extra sui branch
I Git worktree cambiano il modo in cui si manifesta il guasto. Un revert in un worktree può essere tecnicamente corretto e creare comunque confusione, perché i metadati del repository sono condivisi mentre ogni checkout presenta un contesto di branch diverso.
Il rischio è di solito procedurale, non magico. Un engineer esegue un reset di un branch in un worktree, presume che un altro worktree non ne sia influenzato, poi scopre che il puntatore del branch si è spostato e che le aspettative locali non corrispondono più a CI, commenti di review o note di rilascio.
Un protocollo sicuro per i worktree include:
- Verifica del branch: confermare il branch corrente prima di qualsiasi operazione di reset, restore o clean
- Controlli di stato per ogni worktree: eseguire
git statusnel worktree modificato e in ogni worktree fratello collegato allo stesso lavoro - Validazione post-revert: ricostruire o rieseguire il percorso di test più ristretto e rilevante prima di considerare pulito lo stato locale
I team che usano i worktree per hotfix e preparazione dei rilasci dovrebbero documentare questi controlli nello stesso modo in cui documentano i passaggi di deploy.
Non correggere la cronologia condivisa con reset
git reset serve per la cronologia privata. Una volta che un commit è su un branch condiviso, il percorso di correzione più sicuro è:
git revert <commit-hash>Questo preserva la traccia di audit ed evita di costringere altri sviluppatori a riconciliare una cronologia riscritta. Si adatta anche ad ambienti in cui la tracciabilità è importante per la revisione degli incidenti, l’approvazione delle modifiche o la delivery regolamentata.
Per i team che confondono ancora la linea tra pulizia locale e correzione di un branch condiviso, questa guida su GitHub revert to previous commit è un riferimento utile per workflow che preservano la cronologia.
Una policy di sicurezza compatta per i team
Una policy di team dovrebbe stare in una sola schermata ed essere facile da applicare nella code review:
| Situazione | Abitudine sicura per il team |
|---|---|
| Non sei sicuro che il lavoro locale abbia ancora valore | Fare stash prima di eliminare o resettare |
| Rimozione di file non tracciati | Eseguire git clean -fdn prima di git clean -fd |
| Revert della cronologia locale privata | Scegliere la modalità di reset meno distruttiva che risolve il problema |
| Annullare un commit già condiviso | Usare git revert, preservare la cronologia |
L’obiettivo non è la cautela fine a sé stessa. L’obiettivo è un ripristino rapido senza perdita accidentale di dati, confusione tra branch o ritardi di delivery evitabili.
Conclusione: costruire un workflow locale resiliente
Una cattiva decisione di revert di solito inizia con una diagnosi affrettata. Un engineer vede uno stato locale rotto, afferra il primo comando familiare e trasforma una piccola attività di pulizia in lavoro perso, un branch confuso o un passaggio di consegne ritardato. La soluzione è semplice. Identificare prima dove si trova la modifica indesiderata, poi scegliere il comando più ristretto che risolva quel problema specifico.
Quest’ordine decisionale conta nei team professionali. Le modifiche non stage richiedono il ripristino di file o directory. Le modifiche stage richiedono una decisione separata sull’index prima di decidere se scartare le modifiche sottostanti. I commit locali che non sono stati pushati richiedono reset, ma solo dopo aver deciso cosa deve sopravvivere nel working tree. La cronologia condivisa richiede revert perché preservare l’auditabilità conta più della comodità.
Per la pulizia a livello di file, i team moderni dovrebbero standardizzarsi su git restore. I repository legacy e i runbook più vecchi possono ancora usare git checkout, <file>, ma quella sintassi è più facile da usare male perché checkout serve anche a cambiare branch. Comandi più chiari riducono gli errori evitabili, soprattutto durante la risposta a un incidente o la preparazione di un rilascio.
Si tratta tanto di disciplina del workflow quanto di competenze Git. I team che gestiscono bene i revert locali mantengono più pulita la cronologia dei branch, riducono il rumore nelle review e dedicano meno tempo al recupero da errori autoindotti. Gli engineer possono testare un’idea, annullarla in sicurezza e tornare a rilasciare senza trasformare la pulizia locale in un problema di coordinamento.
Annullare il lavoro locale è normale. Ciò che distingue i team stabili da quelli più inclini agli errori non è se i revert avvengono, ma se le persone scelgono i comandi deliberatamente, capiscono cosa distrugge ciascun comando e integrano piccoli controlli di sicurezza nel lavoro quotidiano.
Un workflow locale resiliente dà al team velocità senza perdita di dati dovuta a negligenza. È così che si mantiene alta l’integrità del codice e basso il rischio di delivery.
Domande frequenti
Qual è la differenza tra git reset e git revert
git reset riscrive la cronologia locale del branch spostando HEAD su un altro commit. A seconda della modalità, può anche mantenere o scartare le modifiche stage e quelle nel working directory.
git revert fa qualcosa di diverso. Crea un nuovo commit che annulla un commit precedente preservando la cronologia esistente. Per questo revert è l’opzione più sicura sui branch condivisi.
Usa reset per la cronologia locale privata. Usa revert per la cronologia pubblica collaborativa.
Dovrei usare git restore o git checkout, <file>
Per i revert a livello di file, preferisci git restore nei workflow moderni perché l’intento è più chiaro.
git checkout, <file> funziona ancora e resta comune nei repository più vecchi, negli script e nella documentazione interna. Il problema è che checkout ha più significati. Può cambiare branch oltre che ripristinare file, il che rende più facile il suo uso improprio da parte di sviluppatori meno esperti.
Se il tuo team vuole un linguaggio operativo più chiaro, standardizzatevi su git restore.
Posso recuperare da un git reset --hard accidentale
A volte, sì.
Il primo comando da provare è:
git reflogMostra i movimenti recenti di HEAD. Se lo stato del commit precedente appare ancora lì, di solito puoi fare il reset per tornare a quello.
git reset --hard HEAD@{N}Sostituisci N con la voce corretta del reflog. Il recupero non è garantito in ogni situazione, ma reflog è il primo posto da controllare.
git clean è pericoloso
Sì. Può rimuovere in modo permanente file e directory non tracciati.
Per questo l’abitudine sicura è fare prima un’anteprima:
git clean -fdnPoi, solo se l’elenco sembra corretto:
git clean -fdTratta git clean come uno strumento di igiene del repository, non come un comando di comodità da usare casualmente.
Cosa dovrebbe standardizzare un team
Una convenzione di team efficace di solito è così:
- Per le modifiche non stage:
git statuspoigit restore - Per gli errori stage: prima togliere dallo stage, poi scartare
- Per i commit locali: scegliere
--soft,--mixedo--hardin base all’intento - Per i branch condivisi: usare
git revert - Per l’incertezza: fare stash prima di operazioni distruttive
Quelle piccole convenzioni riducono la confusione in modo più efficace che aggiungere altra teoria Git alle slide di onboarding.
Se il tuo team sta costruendo una piattaforma SaaS, un dashboard interno o un sistema abilitato all’AI e desidera un workflow di engineering più pulito attorno all’integrità dei rilasci, alla disciplina dei branch e a una delivery mantenibile, Devisia aiuta le organizzazioni a progettare sistemi software che restano affidabili man mano che la complessità cresce.