
I dati di prima parte sono le informazioni che la tua organizzazione raccoglie direttamente dagli utenti tramite le tue applicazioni, i tuoi siti web e i tuoi sistemi digitali, con il loro consenso. Questa relazione diretta li rende l’asset dati più accurato, affidabile e conforme disponibile.
Man mano che la dipendenza dai dati di terze parti diventa un rischio significativo sia architetturale sia di business, costruire una solida strategia di first-party data non è più opzionale. È un requisito fondamentale per creare sistemi software resilienti, conformi e intelligenti.
Il problema: perché i dati di terze parti sono un rischio sistemico
Per anni, i sistemi digitali sono stati costruiti su una base di dati di terze parti, principalmente cookie e aggregatori di dati esterni. Questo modello è ormai obsoleto e crea vulnerabilità critiche per qualsiasi piattaforma B2B moderna.
Questo non è un problema di marketing; è una sfida fondamentale di ingegneria e conformità. I sistemi dipendenti da dati di terze parti sono intrinsecamente fragili. La loro funzionalità è legata a piattaforme esterne che possono — e lo fanno — cambiare le proprie regole senza preavviso. Per i leader tecnici, questa dipendenza deve essere riconosciuta come una responsabilità architetturale critica.
La fine dell’era delle terze parti
La deprecazione dei cookie di terze parti da parte dei principali browser è il segnale definitivo che il vecchio modello è rotto. Allo stesso tempo, normative stringenti sulla privacy come GDPR, NIS2 e DORA rendono l’uso di dati provenienti da fonti esterne un terreno minato di rischi di conformità e potenziali responsabilità. Un singolo passo falso può portare a sanzioni severe e danni reputazionali.
Affidarsi ai dati di terze parti è come costruire su un terreno in affitto, dove i termini del contratto possono cambiare in qualsiasi momento. Una strategia di dati di prima parte significa possedere il terreno su cui è costruita la tua presenza digitale, offrendo controllo, stabilità e una base per una crescita scalabile.
Questa dipendenza esterna impone una svolta strategica. Una strategia proattiva per raccogliere, governare e attivare i dati di prima parte è ora l’unica strada affidabile da seguire. Trasforma i dati da un ripensamento rischioso in un asset primario di business.
Dalla fragilità a un asset fondamentale
Considerare i dati di prima parte come un asset centrale significa applicare lo stesso rigore architetturale di qualsiasi altra infrastruttura critica. I benefici vanno oltre le metriche di marketing e influenzano lo sviluppo del prodotto, il profilo di sicurezza e la strategia complessiva del business.
Un solido asset di dati di prima parte offre:
- Resilienza architetturale: Disaccoppia i tuoi sistemi dai cambiamenti imprevedibili delle piattaforme ad-tech e dei data broker, riducendo significativamente il rischio sistemico.
- Conformità migliorata: La raccolta diretta dei dati con il consenso esplicito dell’utente semplifica il processo di gestione e dimostrazione della conformità a normative come il GDPR.
- AI e personalizzazione affidabili: Dati di alta qualità e affidabili sono l’unico carburante realmente valido per modelli di AI accurati e una personalizzazione significativa. Consentono un’automazione efficace senza dipendere da fonti opache di terze parti.
- Vantaggio competitivo duraturo: Mentre i concorrenti faticano ad adattarsi a un mondo senza cookie di terze parti, un asset dati di proprietà diventa un moat strategico difficile da replicare per gli altri.
L’obiettivo finale è costruire un sistema a ciclo chiuso in cui raccogli, governi e attivi i tuoi dati per progettare prodotti ed esperienze cliente migliori. Questa è la nuova base per una crescita sostenibile e conforme.
Progettare la tua base di dati di prima parte
Progettare una strategia di first-party data richiede di andare oltre i concetti astratti e arrivare a decisioni architetturali concrete. Si tratta di costruire l’infrastruttura tecnica che unifica i dati senza creare un nuovo livello di complessità ingestibile.
Dal punto di vista dell’ingegneria software, il nemico principale è la frammentazione. I dati sul comportamento degli utenti risiedono nei log dell’applicazione, i record transazionali si trovano in un gateway di pagamento come Stripe e le preferenze degli utenti sono silos in un CRM. Tentare di costruire una visione coerente del cliente a partire da queste fonti disparate è un pattern di fallimento comune. L’obiettivo è costruire una libreria di dati ben organizzata, non un mucchio disordinato di informazioni scollegate.
Classificare i tuoi principali asset dati
Prima di unificare i dati, devi inventariare e classificare ciò che raccogli. La maggior parte dei dati di prima parte rientra in tre tipologie distinte. Una chiara comprensione di queste categorie è il primo passo verso un piano coerente di raccolta e governance dei dati.
-
Dati comportamentali: Sono ciò che gli utenti fanno. Includono il flusso di visualizzazioni di pagina, clic sui pulsanti, interazioni con le funzionalità e durata delle sessioni. Questa è la fonte di verità per comprendere il coinvolgimento con il prodotto.
-
Dati transazionali: Sono ciò che gli utenti transazionano. Comprendono acquisti, rinnovi di abbonamento, cancellazioni e invii di ticket di supporto. Questi dati forniscono una chiara visione commerciale della relazione con il cliente.
-
Dati dichiarati: Sono ciò che gli utenti ti dicono. Si tratta delle informazioni che forniscono esplicitamente, come il loro ruolo durante l’onboarding, le preferenze di notifica o le risposte ai sondaggi.
Queste tipologie di dati non sono solo un inventario; formano una gerarchia di intelligenza. Una solida base di dati puliti e organizzati consente una personalizzazione efficace, che a sua volta alimenta i motori di AI e crescita che guidano il business.
Senza lo strato fondamentale di dati ben governati, qualsiasi sistema costruito sopra diventa instabile e inaffidabile.
Scegliere il tuo modello architetturale
Una volta mappate le fonti dati, la decisione architetturale successiva è come unificarle. Esistono due approcci principali, ciascuno con importanti compromessi.
Puoi costruire una pipeline dati personalizzata. Questo implica integrare strumenti come piattaforme di streaming di eventi (Apache Kafka), sviluppare script ETL/ELT personalizzati e caricare tutto in un data warehouse centrale come Snowflake o Google BigQuery. Questa strada offre il massimo controllo e flessibilità, ma richiede risorse ingegneristiche significative e continue per sviluppo e manutenzione.
L’alternativa è acquistare una Customer Data Platform (CDP). Una CDP è un sistema commerciale pronto all’uso, progettato per ingerire dati da più fonti, unificarli in profili cliente e syndicare tali profili verso altri strumenti. Offre un time-to-value più rapido e richiede meno ingegneria iniziale, ma introduce dipendenza dal fornitore e potenziali limiti nella personalizzazione.
Questo è il classico compromesso tra build e buy. La decisione dipende dalla capacità del tuo team di ingegneria, dal budget e dal grado di personalizzazione richiesto dai tuoi sistemi. Una scelta sbagliata può portare a un sistema sovra-ingegnerizzato e costoso, oppure a una piattaforma rigida che ostacola lo sviluppo futuro.
Per le aziende software B2B, i dati di mercato indicano una tendenza chiara. Con la spesa martech B2B negli Stati Uniti prevista a raggiungere 14 miliardi di dollari entro il 2027, le CDP stanno conquistando una quota crescente. Circa il 20% delle aziende B2B prevede di investire in una CDP quest’anno, evidenziando una svolta strategica verso queste piattaforme per unificare i dati di prima parte. Puoi esaminare questi dati in recenti analisi sulle tendenze martech e i dati di prima parte.
La tabella seguente riassume i compromessi tra questi due approcci architetturali.
Confronto tra architetture di raccolta dati
| Approccio | Ideale per | Vantaggi principali | Considerazioni di implementazione |
|---|---|---|---|
| Pipeline personalizzata | Enterprise, SMB con forte componente tecnica | Controllo massimo, flessibilità, nessun lock-in con il fornitore | Alto costo ingegneristico iniziale/continuativo, time-to-value lento |
| Customer Data Platform (CDP) | Startup, SMB, Enterprise non tech-first | Implementazione rapida, costo iniziale inferiore, integrazioni predefinite | Dipendenza dal fornitore, potenziale rigidità, costi di abbonamento ricorrenti |
Non esiste una risposta unica corretta. Una startup con un piccolo team di ingegneria farà una scelta diversa rispetto a una grande impresa con un reparto dedicato di data engineering. La chiave è selezionare un’architettura che sia allineata con la scala, le risorse e la visione a lungo termine della tua azienda.
Pattern tecnici per la raccolta e lo storage dei dati
Una strategia di first-party data di successo richiede di tradurre la teoria in un’implementazione tecnica robusta. I pattern architetturali che scegli per raccolta e storage determineranno l’affidabilità, la scalabilità e l’utilità del tuo asset dati. La sfida ingegneristica centrale è catturare segnali ad alta fedeltà senza creare un sistema fragile e difficile da mantenere.
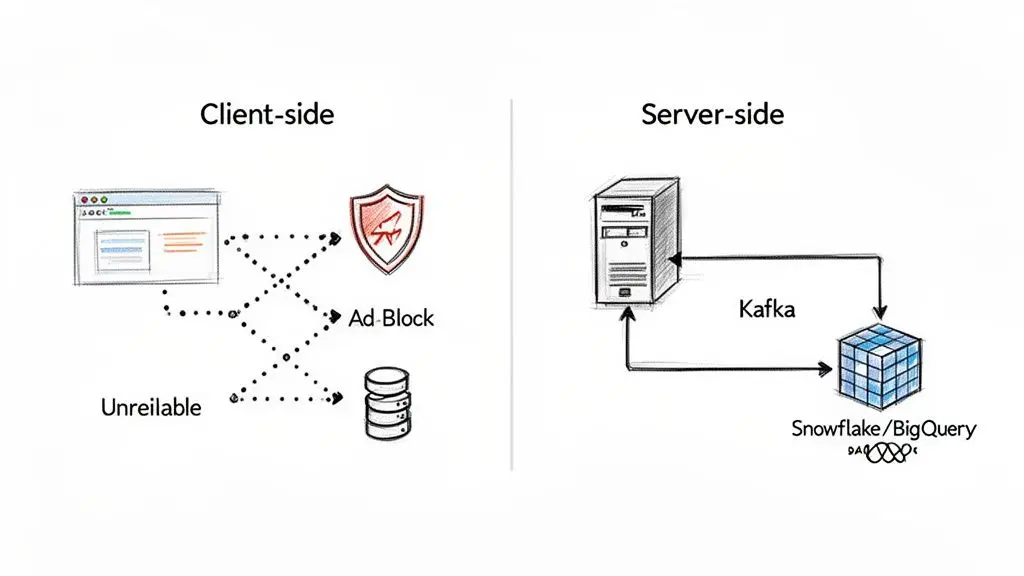
Un punto di partenza comune ma ingenuo è il tracciamento lato client. Questo comporta il deployment di uno snippet JavaScript nel browser dell’utente per inviare eventi direttamente agli endpoint di analytics. Questo approccio è notoriamente inaffidabile, vulnerabile ad ad blocker, problemi di rete e funzionalità di privacy del browser, con una perdita di segnale spesso pari al 30% o più. Affidarsi solo agli eventi lato client fornisce una visione incompleta e spesso imprecisa del comportamento degli utenti.
Per affrontare questo problema, le organizzazioni mature implementano il tracciamento lato server. In questo modello, è il server dell’applicazione stesso a inviare gli eventi agli endpoint dati. Ciò offre controllo completo, aggira le interferenze lato client e garantisce che ogni evento critico — come un pagamento di abbonamento o un’interazione chiave con una funzionalità — venga acquisito con accuratezza del 100%.
Evolvere la tua architettura di storage dei dati
Una volta stabilito un flusso di dati affidabile, la considerazione successiva è lo storage. Il pattern di storage ottimale dipende dal volume dei dati e dai requisiti analitici. Un approccio graduale, in cui l’architettura evolve con il business, è quasi sempre la strada più pragmatica.
Per le aziende in fase iniziale, memorizzare i dati degli eventi direttamente in un database di produzione primario (ad es. PostgreSQL) può essere un primo passo pratico. Semplifica l’architettura e minimizza i costi. Tuttavia, questo approccio ha un compromesso significativo: eseguire query analitiche complesse su un database di produzione degrada le prestazioni dell’applicazione e non scala.
Con l’aumentare del volume dei dati e delle esigenze analitiche, separare i carichi di lavoro analitici dal database transazionale diventa non negoziabile. È qui che un moderno data warehouse è essenziale.
Un data warehouse come Snowflake o Google BigQuery non è solo un database più grande; è un motore progettato appositamente per query rapide e complesse su dataset massivi. Migrare i dati analitici in un warehouse è un passaggio critico verso un sistema scalabile che supporta BI e product analytics senza impattare le prestazioni dell’applicazione.
Per le organizzazioni che richiedono elaborazione in tempo reale, emerge un pattern più avanzato. Introdurre una piattaforma di streaming degli eventi come Apache Kafka o Amazon Kinesis crea un buffer durevole ad alta capacità tra i server applicativi e il data warehouse.
Questa architettura event-driven offre diversi vantaggi:
- Disaccoppiamento: La tua applicazione può pubblicare un evento nello stream e continuare l’elaborazione senza attendere i sistemi downstream.
- Ingestione in tempo reale: I dati sono disponibili per l’analisi in pochi secondi, consentendo insight e automazione immediati.
- Resilienza: Se un sistema downstream (ad es. il data warehouse) è temporaneamente offline, la piattaforma di streaming conserva gli eventi, prevenendo la perdita di dati.
Uno scenario pratico: adozione di una funzionalità SaaS
Considera un’azienda SaaS che lancia una nuova funzionalità di “reporting”. L’obiettivo è monitorarne l’adozione e identificare i punti di attrito degli utenti.
- Raccolta: Utilizzando il tracciamento lato server, il backend dell’applicazione invia un evento a un topic Kafka ogni volta che un utente genera un report. Il payload dell’evento include
user_id,report_typeegeneration_time_ms. - Ingestione: Un servizio separato consuma gli eventi dal topic Kafka in tempo reale e li fluisce in una tabella dedicata in Snowflake.
- Analisi: Il team di prodotto può ora interrogare Snowflake per creare dashboard che mostrino i tassi di adozione in tempo reale, identificare segmenti di utenti con un elevato utilizzo della funzionalità e rilevare problemi di prestazioni analizzando
generation_time_ms.
Questo modello offre insight affidabili e utilizzabili, mantenendo al contempo un’applicazione core veloce e resiliente. Con la maturazione dei sistemi, una piattaforma di data management ben strutturata diventa essenziale per gestire questa complessità.
Implementare la Privacy by Design nei Tuoi Sistemi Dati
La raccolta di dati di prima parte comporta una responsabilità significativa. La privacy non è una funzionalità da aggiungere in seguito; è un principio architetturale che deve essere integrato nei sistemi fin dall’inizio. Riadattare la conformità in un secondo momento è una fonte di debito tecnico, rischio normativo e, in ultima analisi, di dati inutilizzabili.
Un approccio “Privacy by Design” rende la protezione dei dati lo stato predefinito, non un’eccezione. Non si tratta semplicemente di soddisfare i requisiti GDPR o NIS2; si tratta di costruire sistemi affidabili che riducano la responsabilità e trasformino i dati in un asset sostenibile invece che in una vulnerabilità critica.
Principi Fondamentali di un’Architettura Centrata sulla Privacy
Integrare la privacy nella tua architettura richiede un passaggio da una mentalità di “raccogli tutto” a una di “raccogli solo ciò che è necessario e proteggilo con attenzione”. Tre principi sono fondamentali.
-
Minimizzazione dei Dati: Raccogli solo i dati per cui hai uno scopo chiaro, specifico e legittimo. Se ti serve solo il paese di un utente per la localizzazione, non raccogliere il suo indirizzo completo. Ogni dato non necessario aumenta la tua superficie di rischio.
-
Limitazione della Finalità: Assicurati che i dati raccolti per uno scopo non vengano usati per un altro senza consenso esplicito. Se un utente fornisce un’email per le conferme d’ordine, non può essere aggiunta unilateralmente a una lista marketing. L’architettura del tuo sistema deve far rispettare questi confini.
-
Misure di Sicurezza: Implementa solide misure tecniche per proteggere i dati che conservi. Questo include la cifratura a riposo e in transito, controlli di accesso rigorosi e tecniche come la tokenizzazione per de-identificare le informazioni sensibili.
Il mancato rispetto di una corretta governance dei dati può rendere i tuoi dati inutilizzabili. Se non puoi dimostrare come e quando hai ottenuto il consenso, non puoi utilizzare legalmente i dati per analisi o AI, “avvelenando” di fatto il tuo stesso pozzo dati.
Pattern di Implementazione Pratici
Tradurre questi principi in un sistema funzionante richiede un’ingegneria deliberata per incorporare guardrail direttamente nella tua infrastruttura dati.
La Privacy by Design è la pratica di anticipare e prevenire eventi invasivi per la privacy prima che si verifichino. Sposta l’approccio dalla gestione reattiva dei danni alla prevenzione proattiva. Questo impegno architetturale costruisce la fiducia degli utenti e rende i sistemi intrinsecamente più sicuri e conformi.
I pattern architetturali concreti per implementare la privacy includono:
- Schema di Database Separati: Progetta il tuo database per archiviare le Informazioni Personali Identificabili (PII) in una tabella separata e altamente restrittiva oppure in un database completamente diverso. I sistemi analitici possono così interrogare i dati non-PII senza mai aver bisogno di accedere a campi sensibili come nomi o indirizzi email.
- Tokenizzazione dei Dati Sensibili: Sostituisci i PII grezzi (ad es. numeri di carte di credito, codici fiscali) con token segnaposto non sensibili. I dati reali vengono archiviati in un “vault” separato e altamente sicuro. Questo riduce drasticamente il rischio in caso di violazione del database principale dell’applicazione.
- Privacy Center per gli Utenti: Crea un’interfaccia dedicata in cui gli utenti possano facilmente visualizzare i dati che conservi su di loro, comprenderne l’uso, gestire il proprio consenso ed esercitare il loro “diritto all’oblio” richiedendo la cancellazione. Questa trasparenza non è solo un requisito legale ai sensi del GDPR; è un potente meccanismo per costruire la fiducia dei clienti.
Implementare questi pattern richiede lungimiranza e investimenti, ma l’alternativa è molto più costosa. Una singola violazione dei dati o una multa regolatoria può causare danni finanziari e reputazionali irreparabili. La nostra guida dettagliata sui principi della Privacy by Design offre ulteriori approfondimenti su questo approccio fondamentale.
Alimentare gli Strumenti AI e SaaS con i Dati di Prima Parte
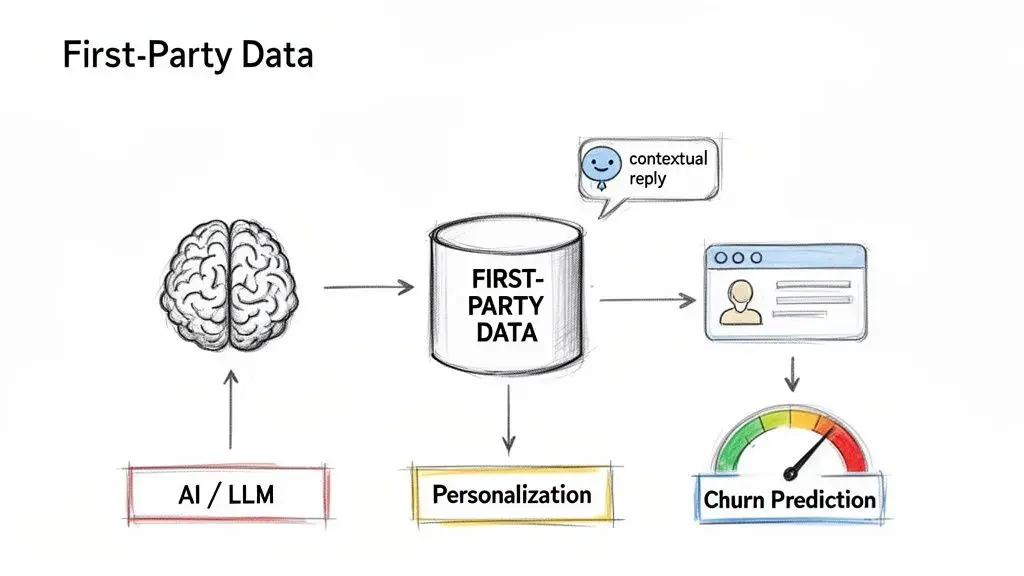
Una base dati di prima parte ben progettata è più di un asset di conformità; è carburante ad alto ottano per i tuoi sistemi aziendali più critici. È qui che l’investimento dà i suoi frutti, trasformando dati puliti e unificati in automazione intelligente e in esperienze di prodotto superiori.
Alimentare modelli AI e strumenti SaaS con dati proprietari e ricchi li eleva da utilità generiche a sistemi precisi e consapevoli del contesto, creando un vantaggio competitivo sostenibile.
Dai Dati all’Intelligenza Azionabile
L’obiettivo architetturale principale è creare una pipeline affidabile che alimenti profili cliente unificati verso le applicazioni downstream. Questo consente di costruire sistemi che agiscono su segnali accurati, quasi in tempo reale, sul comportamento e sull’intento degli utenti.
In questo modello, il data warehouse o il CDP fungono da centrale “system of intelligence”, distribuendo dati curati a diversi strumenti e modelli per attivare azioni specifiche.
Le applicazioni chiave includono:
- Modellazione Predittiva del Churn: Analizzando l’adozione storica delle funzionalità, la frequenza dei ticket di supporto e i pattern di accesso, un modello di machine learning può prevedere quali clienti sono ad alto rischio di abbandono, consentendo interventi proattivi.
- Personalizzazione Dinamica: La cronologia comportamentale di un utente può essere utilizzata per personalizzare la sua esperienza in-app, ad esempio mostrando a un utente esperto un tutorial su funzionalità avanzate mentre guida un nuovo utente verso i task di onboarding principali.
- Lead Scoring Accurato: Invece di basarsi solo sui dati firmografici, i lead possono essere valutati in base al loro effettivo engagement con il prodotto durante una prova gratuita. Questo concentra gli sforzi di vendita sui prospect che hanno dimostrato una reale intenzione d’acquisto.
Integrare i Segnali di Prima Parte con gli LLM
L’efficacia dei Large Language Models (LLM) è spesso limitata dalle date di cutoff della loro conoscenza e dalla mancanza di un contesto specifico dell’utente. Arricchirli con i tuoi dati proprietari di prima parte è la chiave per creare assistenti AI davvero potenti e differenziati.
Un chatbot generico può descrivere cosa fa il tuo prodotto. Un agente AI contestuale, alimentato dai dati di prima parte, può informare un utente specifico perché il suo export recente è fallito e guidarlo verso una soluzione. Questa è la differenza tra una curiosità e uno strumento davvero utile.
Dal punto di vista architetturale, questo viene spesso implementato usando un pattern chiamato Retrieval-Augmented Generation (RAG). Quando un utente pone una domanda, il sistema recupera prima i dati rilevanti su quell’utente dal tuo database, come l’attività recente o il livello di abbonamento. Questo contesto viene poi inserito nel prompt inviato all’LLM.
Questo ti consente di costruire:
- Workflow Agentici: Agenti AI che possono eseguire attività per conto di un utente, come rilanciare un processo fallito o suggerire un upgrade dell’account in base ai pattern di utilizzo.
- Chatbot Contestuali: Bot di supporto che forniscono risposte personalizzate basate sulla reale cronologia dell’utente, riducendo drasticamente i tempi di risoluzione.
Mantenere l’Affidabilità e Controllare i Costi
Man mano che i dati vengono integrati in più sistemi, emergono due rischi operativi principali: affidabilità e costo. Un guasto API in uno strumento di terze parti o una query fuori controllo possono causare problemi a cascata o fatture significative e inattese.
Una progettazione robusta del sistema richiede osservabilità integrata e meccanismi di controllo.
- Livelli di Caching: I dati utente a cui si accede frequentemente dovrebbero essere memorizzati in cache per ridurre la latenza e minimizzare il carico sul tuo data warehouse principale, garantendo un motore di personalizzazione veloce.
- Osservabilità: Implementa monitoraggio e logging dettagliati per tutte le pipeline dati, così da rilevare immediatamente guasti, degradazione delle prestazioni o picchi di costo dovuti all’inferenza dei modelli AI.
- Rate Limiting e Fallback: Applica limiti di rate alle chiamate API verso servizi esterni per controllare i costi e prevenire abusi. Progetta i sistemi con logica di fallback, così che se un servizio di personalizzazione fallisce, l’applicazione degradi in modo elegante verso un’esperienza standard.
Entro il 2026, gli ecosistemi di dati di prima parte saranno la spina dorsale del martech guidato dall’AI. Con l’80% dei marketer già impegnati nell’uso dell’AI per i contenuti e il 75% per la produzione media, i dati proprietari di alta qualità sono il carburante essenziale. I benefici tangibili sono chiari, con previsioni di un aumento del 22% del ROAS grazie ai modelli di attribuzione proprietari. Questo livello di integrazione trasforma i dati di prima parte da semplice strumento di reporting in un asset operativo attivo. Ad esempio, insight dettagliati dalle interazioni con il prodotto possono informare strategie retail guidate dall’AI, un tema che trattiamo nella nostra guida su AI nel settore retail.
Costruire il Tuo Vantaggio Competitivo con la Proprietà dei Dati
Una strategia di dati di prima parte non è una soluzione di marketing a breve termine; è un investimento a lungo termine in un asset core del business che richiede la stessa disciplina architetturale del tuo software più critico. In un contesto di cambiamenti normativi e inaffidabilità dei segnali, possedere la tua infrastruttura dati è l’unico modo affidabile per costruire prodotti manutenibili, scalabili e intelligenti.
È qui che tutti i componenti—una solida architettura di raccolta, la privacy by design e integrazioni intelligenti—convergono per creare un vantaggio competitivo difficile da replicare per gli altri.
Da Centro di Costo a Motore di Ricavi
Il business case di questo investimento è convincente. Gli analisti prevedono che entro il 2027 le aziende con una strategia di prima parte matura vedranno costi di acquisizione cliente inferiori del 30-40% rispetto a quelle che si affidano ancora ai segnali di terze parti. Questo è il risultato diretto di un targeting più efficiente e di tassi di conversione più elevati. Puoi leggere di più su come le società IT stanno stabilizzando i ricavi con i dati di prima parte.
Possedere i tuoi dati trasforma l’infrastruttura da centro di costo a asset strategico che guida attivamente la crescita. È la base per efficienza, innovazione e resilienza.
I Tuoi Primi Passi Pragmatici
Iniziare non richiede una revisione completa dei sistemi esistenti. Un approccio graduale e pragmatico, che dimostri rapidamente valore, è il percorso più efficace.
Una roadmap pratica inizia con questi primi passi:
- Mappa le Tue Fonti Dati: Censisci ogni sistema in cui raccogli dati—il database della tua applicazione, il CRM, gli strumenti di analytics, ecc. Documenta cosa raccogli, dove viene archiviato e chi vi ha accesso.
- Identifica Lacune e Rumore: Determina quali informazioni critiche mancano. Altrettanto importante, individua dove stai raccogliendo dati di bassa qualità o irrilevanti che aggiungono complessità e rischio. Questa è la minimizzazione dei dati in pratica.
- Pianifica per fasi: Sviluppa una roadmap che inizi con piccoli successi ad alto impatto. Questo potrebbe consistere nell’implementare il tracciamento lato server per un singolo percorso utente critico o nel consolidare due fonti di dati distinte in un’unica vista pulita.
Questo processo metodico crea una solida base, garantendo che la tua strategia di dati di prima parte diventi una risorsa duratura, non solo un altro progetto.
Le tue domande sui dati di prima parte, con risposta
Qui affrontiamo domande pratiche che CTO, fondatori e leader di prodotto pongono quando prendono in considerazione una strategia di dati di prima parte, fornendo risposte chiare, orientate all’ingegneria.
Qual è la vera differenza tra dati di prima parte e dati zero-party?
I dati di prima parte vengono inferiti osservando il comportamento degli utenti all’interno delle tue proprietà digitali (ad es. visualizzazioni di pagina, clic sulle funzionalità, cronologia degli acquisti).
I dati zero-party sono ciò che gli utenti condividono esplicitamente e intenzionalmente con te. Questo include informazioni come il loro ruolo professionale durante l’onboarding, le selezioni di preferenze in un pannello delle impostazioni o le scelte di consenso.
Uno è osservato; l’altro è dichiarato. Entrambi sono preziosi, ma i dati zero-party forniscono un intento inequivocabile direttamente dalla fonte.
Quanto impegno di engineering serve davvero per iniziare?
Significativamente meno di quanto spesso si pensi, a patto di adottare un approccio pragmatico. Un errore comune è cercare di progettare fin dal primo giorno una piattaforma dati perfetta e onnicomprensiva, il che spesso porta a progetti che non vengono mai rilasciati.
Inizia in piccolo. Un primo passo pratico è implementare il tracciamento lato server per un singolo percorso utente ad alto valore, come il processo di registrazione o di checkout. Questo potrebbe richiedere solo pochi giorni di lavoro di engineering, ma fornisce immediatamente una fonte affidabile di verità. Da lì, puoi costruire gradualmente la tua infrastruttura man mano che dimostri il valore.
Non cercare di bollire l’oceano. Un proof-of-concept su piccola scala che fornisce un flusso di dati affidabile è infinitamente meglio di una grande architettura distribuita su più trimestri che non vede mai la luce. Cattura prima un segnale ad alto valore, poi espandi.
Questo significa che elimineremo tutti i nostri strumenti di terze parti?
No. L’obiettivo non è sostituire ogni strumento di terze parti, ma cambiare radicalmente il tuo rapporto con essi. Invece di essere la fonte dei tuoi dati, diventano destinazioni per essi.
La tua infrastruttura dati diventa il sistema centrale di riferimento. Da questa singola fonte di verità, invii dati puliti, coerenti e governati al tuo CRM, alle piattaforme di analytics o ai partner pubblicitari tramite integrazioni server-to-server.
Questo modello ti offre il controllo completo sulla syndication dei dati, riduce drasticamente il lock-in del fornitore e migliora la qualità dei segnali inviati a ogni strumento del tuo stack.
Costruire una strategia robusta di dati di prima parte è una decisione architetturale che crea un vantaggio competitivo duraturo. In Devisia, siamo specializzati nella progettazione e nell’implementazione dei sistemi digitali affidabili necessari per trasformare i tuoi dati in una risorsa fondamentale.
Inizia a costruire con Devisia la tua base software mantenibile.