
First-party data is the information your organization collects directly from users through your own applications, websites, and digital systems, with their consent. This direct relationship makes it the most accurate, reliable, and compliant data asset available.
As reliance on third-party data becomes a significant architectural and business risk, building a robust first-party data strategy is no longer optional. It is a foundational requirement for creating resilient, compliant, and intelligent software systems.
The Problem: Why Third-Party Data is a Systemic Risk
For years, digital systems have been built on a foundation of third-party data, primarily from cookies and external data aggregators. This model is now obsolete, creating critical vulnerabilities for any modern B2B platform.
This is not a marketing problem; it is a core engineering and compliance challenge. Systems dependent on third-party data are inherently fragile. Their functionality is tied to external platforms that can—and do—change their rules without notice. For technical leaders, this dependency must be recognized as a critical architectural liability.
The End of the Third-Party Era
The deprecation of third-party cookies by major browsers is the definitive signal that the old model is broken. Concurrently, stringent privacy regulations like GDPR, NIS2, and DORA make the use of externally sourced data a minefield of compliance risks and potential liabilities. A single misstep can lead to severe fines and reputational damage.
Relying on third-party data is like building on rented land where the lease terms can change at any moment. A first-party data strategy means owning the land your digital presence is built on, providing control, stability, and a foundation for scalable growth.
This external dependency forces a strategic pivot. A proactive strategy for collecting, governing, and activating first-party data is now the only reliable path forward. It transforms data from a risky afterthought into a primary business asset.
From Fragility to a Foundational Asset
Viewing first-party data as a core asset means applying the same architectural rigor to it as to any other critical infrastructure. The benefits extend beyond marketing metrics, influencing product development, security posture, and overall business strategy.
A robust first-party data asset delivers:
- Architectural Resilience: It decouples your systems from the unpredictable changes of ad-tech and data broker platforms, significantly reducing systemic risk.
- Enhanced Compliance: Direct data collection with explicit user consent simplifies the process of managing and demonstrating compliance with regulations like GDPR.
- Reliable AI and Personalization: High-quality, trusted data is the only viable fuel for accurate AI models and meaningful personalization. It enables effective automation without reliance on opaque, third-party sources.
- Durable Competitive Advantage: While competitors struggle to adapt to a world without third-party cookies, an owned data asset becomes a strategic moat that is difficult for others to replicate.
The ultimate objective is to build a closed-loop system where you collect, govern, and activate your own data to engineer better products and customer experiences. This is the new foundation for sustainable, compliant growth.
Architecting Your First-Party Data Foundation
Designing a first-party data strategy requires moving beyond abstract concepts to concrete architectural decisions. It’s about building the technical plumbing that unifies data without creating a new layer of unmanageable complexity.
From a software engineering perspective, the primary enemy is fragmentation. User behavior data resides in the application logs, transactional records are in a payment gateway like Stripe, and user preferences are siloed in a CRM. Attempting to build a coherent customer view from these disparate sources is a common failure pattern. The goal is to construct a well-organized data library, not a disorganized pile of disconnected information.
Categorizing Your Core Data Assets
Before unifying data, you must inventory and categorize what you collect. Most first-party data falls into three distinct types. A clear understanding of these categories is the first step toward a coherent data collection and governance plan.
-
Behavioral Data: This is what users do. It includes the stream of page views, button clicks, feature interactions, and session durations. This is the ground truth for understanding product engagement.
-
Transactional Data: This is what users transact. It encompasses purchases, subscription renewals, cancellations, and support ticket submissions. This data provides a clear commercial view of the customer relationship.
-
Declared Data: This is what users tell you. It is the information they explicitly provide, such as their role during onboarding, notification preferences, or survey responses.
These data types are not just an inventory; they form a hierarchy of intelligence. A solid foundation of clean, organized data enables effective personalization, which in turn fuels the AI and growth engines that drive the business.
Without the foundational layer of well-governed data, any system built on top becomes unstable and unreliable.
Choosing Your Architectural Pattern
Once data sources are mapped, the next architectural decision is how to unify them. There are two primary approaches, each with significant trade-offs.
You can build a custom data pipeline. This involves integrating tools like event streaming platforms (Apache Kafka), developing custom ETL/ELT scripts, and loading everything into a central data warehouse like Snowflake or Google BigQuery. This route offers maximum control and flexibility but demands significant and ongoing engineering resources for development and maintenance.
The alternative is to buy a Customer Data Platform (CDP). A CDP is a commercial, off-the-shelf system designed to ingest data from multiple sources, unify it into customer profiles, and syndicate those profiles to other tools. It offers faster time-to-value and requires less upfront engineering but introduces vendor dependency and potential constraints on customization.
This is the classic build-versus-buy trade-off. The decision depends on your engineering team’s capacity, budget, and the degree of customisation your systems require. A poor choice can result in an over-engineered, costly system or a rigid platform that impedes future development.
For B2B software companies, market data indicates a clear trend. With U.S. B2B martech spending projected to reach $14 billion by 2027, CDPs are capturing a growing share. Approximately 20% of B2B companies plan to invest in a CDP this year, highlighting a strategic shift toward these platforms for unifying first-party data. You can examine these figures in recent analyses of martech trends and first-party data.
The following table summarizes the trade-offs between these two architectural approaches.
Data Collection Architecture Comparison
| Approach | Best For | Key Benefits | Implementation Considerations |
|---|---|---|---|
| Custom Pipeline | Enterprises, tech-heavy SMBs | Maximum control, flexibility, no vendor lock-in | High upfront/ongoing engineering cost, slow time-to-value |
| Customer Data Platform (CDP) | Startups, SMBs, non-tech-first Enterprises | Fast implementation, lower initial cost, pre-built integrations | Vendor dependency, potential inflexibility, recurring subscription fees |
There is no single correct answer. A startup with a small engineering team will make a different choice than a large enterprise with a dedicated data engineering department. The key is to select an architecture that aligns with your company’s scale, resources, and long-term vision.
Technical Patterns for Data Collection and Storage
A successful first-party data strategy requires translating theory into robust technical implementation. The architectural patterns you select for data collection and storage will determine the reliability, scalability, and utility of your data asset. The core engineering challenge is to capture high-fidelity signals without creating a fragile, unmaintainable system.
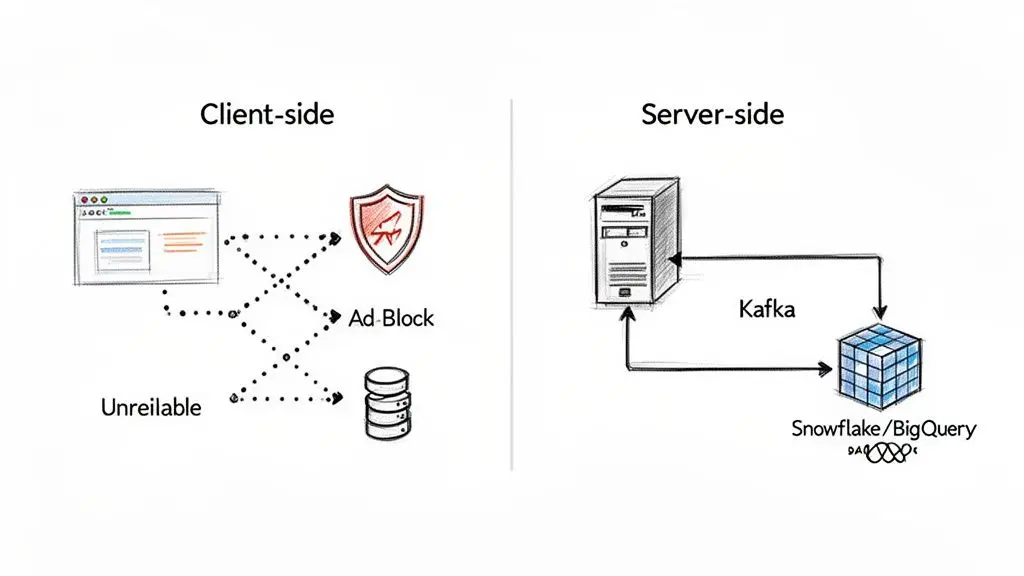
A common but naive starting point is client-side tracking. This involves deploying a JavaScript snippet in the user’s browser to send events directly to analytics endpoints. This approach is notoriously unreliable, vulnerable to ad-blockers, network issues, and browser privacy features, often resulting in signal loss of 30% or more. Relying solely on client-side events provides an incomplete and often inaccurate view of user behavior.
To address this, mature organizations implement server-side tracking. In this model, the application server itself sends events to data endpoints. This provides complete control, bypasses client-side interference, and ensures that every critical event—such as a subscription payment or a key feature interaction—is captured with 100% accuracy.
Evolving Your Data Storage Architecture
Once a reliable stream of data is established, the next consideration is storage. The optimal storage pattern depends on data volume and analytical requirements. A phased approach, where the architecture evolves with the business, is almost always the most pragmatic path.
For early-stage companies, storing event data directly in a primary production database (e.g., PostgreSQL) can be a practical first step. It simplifies the architecture and minimizes costs. However, this approach has a significant trade-off: running complex analytical queries against a production database degrades application performance and does not scale.
As data volume and analytical needs grow, separating analytical workloads from the transactional database becomes non-negotiable. This is where a modern data warehouse is essential.
A data warehouse like Snowflake or Google BigQuery is not just a larger database; it is an engine purpose-built for fast, complex queries over massive datasets. Migrating analytical data to a warehouse is a critical step toward a scalable system that supports BI and product analytics without impacting application performance.
For organizations requiring real-time processing, a more advanced pattern emerges. Introducing an event streaming platform like Apache Kafka or Amazon Kinesis creates a high-throughput, durable buffer between application servers and the data warehouse.
This event-driven architecture provides several advantages:
- Decoupling: Your application can publish an event to the stream and continue processing without waiting for downstream systems.
- Real-time Ingestion: Data is available for analysis in seconds, enabling immediate insights and automation.
- Resilience: If a downstream system (e.g., the data warehouse) is temporarily offline, the streaming platform retains the events, preventing data loss.
A Practical Scenario: SaaS Feature Adoption
Consider a SaaS company launching a new “reporting” feature. The objective is to track adoption and identify user friction points.
- Collection: Using server-side tracking, the application backend sends an event to a Kafka topic each time a user generates a report. The event payload includes
user_id,report_type, andgeneration_time_ms. - Ingestion: A separate service consumes events from the Kafka topic in real-time and streams them into a dedicated table in Snowflake.
- Analysis: The product team can now query Snowflake to build dashboards showing real-time adoption rates, identify user segments with high feature usage, and detect performance issues by analyzing
generation_time_ms.
This pattern delivers reliable, actionable insights while maintaining a fast and resilient core application. As systems mature, a well-structured data management platform becomes essential for managing this complexity.
Implementing Privacy by Design in Your Data Systems
The collection of first-party data carries significant responsibility. Privacy is not a feature to be added later; it is an architectural principle that must be embedded into your systems from the outset. Retrofitting compliance is a source of technical debt, regulatory risk, and, ultimately, unusable data.
A “Privacy by Design” approach makes data protection the default state, not an exception. This is not merely about satisfying GDPR or NIS2 requirements; it is about building trustworthy systems that reduce liability and transform data into a sustainable asset rather than a critical vulnerability.
Core Tenets of a Privacy-Centric Architecture
Embedding privacy into your architecture requires a shift from a “collect everything” mindset to one of “collect only what is necessary and protect it diligently.” Three principles are fundamental.
-
Data Minimization: Collect only the data for which you have a clear, specific, and legitimate purpose. If you only need a user’s country for localization, do not collect their full street address. Every unnecessary data point increases your risk surface.
-
Purpose Limitation: Ensure that data collected for one purpose is not used for another without explicit consent. If a user provides an email for order confirmations, it cannot be unilaterally added to a marketing list. Your system architecture must enforce these boundaries.
-
Security Safeguards: Implement robust technical measures to protect the data you hold. This includes encryption at rest and in transit, strict access controls, and techniques like tokenization to de-identify sensitive information.
Failure to implement proper data governance can render your data useless. If you cannot prove how and when you obtained consent, you cannot legally use the data for analytics or AI, effectively “poisoning” your own data well.
Practical Implementation Patterns
Translating these principles into a working system requires deliberate engineering to build guardrails directly into your data infrastructure.
Privacy by Design is the practice of anticipating and preventing privacy-invasive events before they occur. It shifts the posture from reactive damage control to proactive prevention. This architectural commitment builds user trust and makes systems inherently more secure and compliant.
Concrete architectural patterns for implementing privacy include:
- Segregated Database Schemas: Design your database to store Personally Identifiable Information (PII) in a separate, highly restricted table or an entirely different database. Analytical systems can then query non-PII data without ever needing access to sensitive fields like names or email addresses.
- Tokenization for Sensitive Data: Replace raw PII (e.g., credit card numbers, national IDs) with non-sensitive placeholder tokens. The actual data is stored in a separate, highly secure “vault.” This dramatically reduces risk in the event of a breach of your main application database.
- User-Facing Privacy Centers: Build a dedicated interface where users can easily view the data you hold on them, understand its use, manage their consent, and exercise their “right to be forgotten” by requesting deletion. This transparency is not just a legal requirement under GDPR; it is a powerful mechanism for building customer trust.
Implementing these patterns requires foresight and investment, but the alternative is far more costly. A single data breach or regulatory fine can cause irreparable financial and reputational damage. Our detailed guide on the principles of Privacy by Design provides further insights into this foundational approach.
Powering AI and SaaS Tools with First-Party Data
A well-architected first-party data foundation is more than a compliance asset; it is high-octane fuel for your most critical business systems. This is where the investment pays off, transforming clean, unified data into intelligent automation and superior product experiences.
Feeding AI models and SaaS tools a diet of rich, proprietary data elevates them from generic utilities to precise, context-aware systems that create a sustainable competitive advantage.
From Data to Actionable Intelligence
The primary architectural goal is to create a reliable pipeline that feeds unified customer profiles into downstream applications. This enables the construction of systems that act on accurate, near real-time signals about user behavior and intent.
In this pattern, the data warehouse or CDP serves as the central “system of intelligence,” pushing curated data to various tools and models to trigger specific actions.
Key applications include:
- Predictive Churn Modeling: By analyzing historical feature adoption, support ticket frequency, and login patterns, a machine learning model can predict which customers are at high risk of churn, enabling proactive intervention.
- Dynamic Personalization: A user’s behavioral history can be used to tailor their in-app experience, for example, by showing a power-user an advanced feature tutorial while guiding a new user toward core onboarding tasks.
- Accurate Lead Scoring: Instead of relying solely on firmographic data, leads can be scored based on their actual product engagement during a free trial. This focuses sales efforts on prospects who have demonstrated genuine buying intent.
Integrating First-Party Signals with LLMs
The effectiveness of Large Language Models (LLMs) is often limited by their knowledge cut-off dates and lack of specific user context. Augmenting them with your proprietary first-party data is the key to creating genuinely powerful and differentiated AI assistants.
A generic chatbot can describe what your product does. A contextual AI agent, powered by first-party data, can inform a specific user why their recent export failed and guide them to a resolution. This is the difference between a novelty and a truly useful tool.
Architecturally, this is often implemented using a pattern called Retrieval-Augmented Generation (RAG). When a user asks a question, the system first retrieves relevant data about that user from your database, such as recent activity or subscription tier. This context is then injected into the prompt sent to the LLM.
This enables you to build:
- Agentic Workflows: AI agents that can perform tasks on behalf of a user, like re-running a failed process or suggesting an account upgrade based on usage patterns.
- Contextual Chatbots: Support bots that provide personalized answers grounded in the user’s actual history, dramatically reducing resolution times.
Maintaining Reliability and Controlling Costs
As data is integrated into more systems, two operational risks become prominent: reliability and cost. An API failure in a third-party tool or a runaway query can cause cascading problems or significant, unexpected bills.
Robust system design requires built-in observability and control mechanisms.
- Caching Layers: Frequently accessed user data should be cached to reduce latency and minimize the load on your primary data warehouse, ensuring a fast personalization engine.
- Observability: Implement detailed monitoring and logging for all data pipelines to immediately detect failures, performance degradation, or cost spikes from AI model inference.
- Rate Limiting and Fallbacks: Enforce rate limits on API calls to external services to control costs and prevent abuse. Design systems with fallback logic, so if a personalization service fails, the application gracefully degrades to a standard experience.
By 2026, first-party data ecosystems will be the backbone of AI-driven martech. With 80% of marketers already using AI for content and 75% for media production, high-quality owned data is the essential fuel. The tangible benefits are clear, with predictions of a 22% ROAS boost from owned attribution models. This level of integration transforms first-party data from a simple reporting tool into an active, operational asset. For instance, detailed insights from product interaction can inform AI-driven retail strategies, a topic we cover in our guide on AI in the retail sector.
Building Your Competitive Moat with Data Ownership
A first-party data strategy is not a short-term marketing fix; it is a long-term investment in a core business asset that demands the same architectural discipline as your most critical software. In an environment of regulatory change and signal unreliability, owning your data infrastructure is the only dependable way to build maintainable, scalable, and intelligent products.
This is where all the components—solid collection architecture, privacy by design, and intelligent integrations—converge to create a competitive moat that is difficult for others to replicate.
From Cost Center to Revenue Driver
The business case for this investment is compelling. Analysts predict that by 2027, companies with a mature first-party strategy will see 30-40% lower customer acquisition costs compared to those still relying on third-party signals. This is a direct result of more efficient targeting and higher conversion rates. You can read more on how IT firms are stabilising revenue with first-party data.
Owning your data transforms infrastructure from a cost center into a strategic asset that actively drives growth. It is the foundation for efficiency, innovation, and resilience.
Your Pragmatic First Steps
Getting started does not require a complete overhaul of your existing systems. A phased, pragmatic approach that demonstrates value quickly is the most effective path.
A practical roadmap begins with these initial steps:
- Audit Your Data Sources: Map every system where you collect data—your application database, CRM, analytics tools, etc. Document what you collect, where it is stored, and who has access.
- Identify Gaps and Noise: Determine what critical information is missing. Equally important, identify where you are collecting low-quality or irrelevant data that adds complexity and risk. This is data minimization in practice.
- Plan in Phases: Develop a roadmap that begins with small, high-impact wins. This could be implementing server-side tracking for a single, critical user journey or consolidating two disparate data sources into one clean view.
This methodical process creates a solid foundation, ensuring your first-party data strategy becomes an enduring asset, not just another project.
Your First-Party Data Questions, Answered
Here we address practical questions that CTOs, founders, and product leaders ask when considering a first-party data strategy, providing straightforward, engineering-focused answers.
What’s the Real Difference Between First-Party and Zero-Party Data?
First-party data is inferred by observing user behavior within your digital properties (e.g., page views, feature clicks, purchase history).
Zero-party data is what users explicitly and intentionally share with you. This includes information like their job role during onboarding, preference selections in a settings panel, or consent choices.
One is observed; the other is declared. Both are valuable, but zero-party data provides unambiguous intent directly from the source.
How Much Engineering Effort Does It Really Take to Start?
Significantly less than often assumed, provided you adopt a pragmatic approach. A common mistake is attempting to design a perfect, all-encompassing data platform from day one, which often leads to projects that never ship.
Start small. A practical first step is to implement server-side tracking for a single, high-value user journey, like your signup or checkout process. This might require only a few days of engineering effort but immediately provides a reliable source of truth. From there, you can incrementally build out your infrastructure as you demonstrate value.
Don’t try to boil the ocean. A small-scale proof-of-concept that delivers one reliable data stream is infinitely better than a grand, multi-quarter architecture that never sees the light of day. Capture one high-value signal first, then expand.
Does This Mean We Get Rid of All Our Third-Party Tools?
No. The goal is not to replace every third-party tool but to fundamentally change your relationship with them. Instead of being the source of your data, they become destinations for it.
Your own data infrastructure becomes the central system of record. From this single source of truth, you push clean, consistent, and governed data out to your CRM, analytics platforms, or advertising partners via server-to-server integrations.
This model gives you complete control over data syndication, dramatically reduces vendor lock-in, and improves the quality of signals sent to every tool in your stack.
Building a robust first-party data strategy is an architectural decision that creates a durable competitive advantage. At Devisia, we specialize in designing and implementing the reliable digital systems needed to turn your data into a foundational asset.
Start building your maintainable software foundation with Devisia.