
A product team finds a new AI API on Tuesday. By Wednesday, they have a prototype. By Thursday, procurement asks a simple question: where is the data protection agreement?
That moment catches many software teams off guard. The feature looks straightforward. The API docs are clear. Authentication works. The commercial terms are acceptable. Then the legal and security review starts, and progress stops because nobody has translated the vendor relationship into data handling obligations.
For CTOs, this is not paperwork getting in the way of engineering. It is engineering reality arriving later than expected. The moment a third party processes personal data for your product, your architecture now includes an external system, an external control boundary, and an external risk surface. If that third party is an AI provider, the risk surface usually gets wider because prompts, embeddings, logs, model outputs, and tool calls all create more places where personal data can move or persist.
Modern regulation has made this more explicit, but the practical problem exists even without regulation. If your vendor stores user data longer than you expect, uses it for a purpose you did not approve, cannot delete it when asked, or cannot tell you what happened during an incident, your internal controls are not enough. You still own the product relationship with your customers.

Introduction Why Your Next API Integration Starts with a Legal Document
The common pattern looks like this. A company wants to add document analysis, support automation, identity verification, fraud checks, or a chatbot. The fastest route is a third party service. The team evaluates latency, pricing, SDK quality, and uptime. Those matter. But for any integration that touches customer data, the document that decides whether the integration is operationally safe is often the DPA.
A data protection agreement is where a vendor relationship stops being aspirational and becomes testable. It tells you what data is processed, why it is processed, which party decides the purpose, what security controls exist, who else receives the data, how incidents are handled, and what happens when the contract ends.
This is important as software supply chains are now privacy supply chains. By 2026, 179 out of 240 jurisdictions globally are projected to have implemented data protection frameworks, covering approximately 80% of the world’s population according to Secureframe’s data privacy statistics. For a software company shipping across borders, the DPA is not a niche enterprise requirement. It is a standard operating document.
Where teams usually get stuck
The friction rarely comes from the idea of signing a DPA. It comes from discovering that the DPA exposes design decisions nobody documented properly.
A few examples:
- Undefined data flows: The team cannot clearly describe whether the vendor receives raw user input, metadata, or derived data.
- Weak deletion paths: The product supports account deletion in the UI, but backups, logs, queues, and external services are not included.
- Unclear AI boundaries: The vendor says customer content is “not used to improve services” in one document, but another policy leaves room for broader internal use.
- Subprocessor sprawl: Security approved one vendor, but that vendor relies on multiple cloud and analytics providers.
A DPA review often fails for technical reasons disguised as legal ones. The contract is just the first place those gaps become visible.
What Is a Data Protection Agreement and Why Does It Matter
A data protection agreement exists because responsibility and execution are usually split.
Your company may decide why personal data is collected and how it supports the product. That usually makes you the controller. A third party vendor may host, analyse, transform, or store that data for you. That usually makes them the processor. The controller keeps the core accountability, even when the processor runs the infrastructure or application component.
That is the central problem. You can outsource processing. You cannot outsource responsibility.
Think of it as a subcontractor agreement for data
The cleanest analogy is construction.
A controller is the general contractor. The processor is the subcontractor. The building owner will not accept “the electrician handled that” as an answer if the wiring is unsafe. The general contractor has to show that the work was defined, supervised, and carried out to the required standard.
A DPA plays the same role for software and data flows. It specifies:
- what the processor may do
- what the processor may not do
- what safeguards must exist
- what evidence the controller can request
- what happens if something goes wrong
Without that agreement, teams rely on assumptions. Assumptions fail quickly when a regulator, enterprise customer, or security incident forces precision.
Why this is now normal, not exceptional
The legal environment has moved in one direction for years. More jurisdictions have adopted privacy frameworks, and cross-border software delivery means even small teams interact with multiple privacy regimes. The practical result is simple. If your product uses external infrastructure, analytics, support tooling, CRM systems, or AI APIs, a DPA becomes part of routine vendor management.
This is particularly important for product companies because the contract affects architecture. If the DPA limits processing purpose, your engineering team has to enforce purpose boundaries. If the DPA promises deletion at termination, your systems need deletion workflows that reach logs, replicas, and integrated services. If the DPA gives audit rights, your controls need evidence, not good intentions.
What a DPA is not
It is not your privacy policy. It is not your terms of service. It is not a generic security attachment copied from another contract.
A weak DPA usually has one of three flaws:
- It is too abstract. The security language is broad enough to sound good and vague enough to avoid commitment.
- It is disconnected from the system. The legal text says one thing, but the stack behaves differently.
- It ignores lifecycle events. It says how data enters the system, not how it changes, spreads, or gets deleted.
What a good DPA gives a CTO
For a technical leader, a strong DPA provides operational advantage:
- a basis for architecture decisions
- a checklist for vendor due diligence
- a map of where to place controls
- a trigger for involving security, platform, legal, and product early
When teams treat it as a checkbox, they get a signed document and unresolved risk. When teams treat it as a design constraint, they build software that is easier to govern.
The Anatomy of a Modern Data Protection Agreement
The fastest way to read a DPA is to ask one question over and over: what system behaviour does this clause require?
Legal text matters. But if you cannot translate the clause into controls, workflows, evidence, and ownership, it will not survive contact with production.
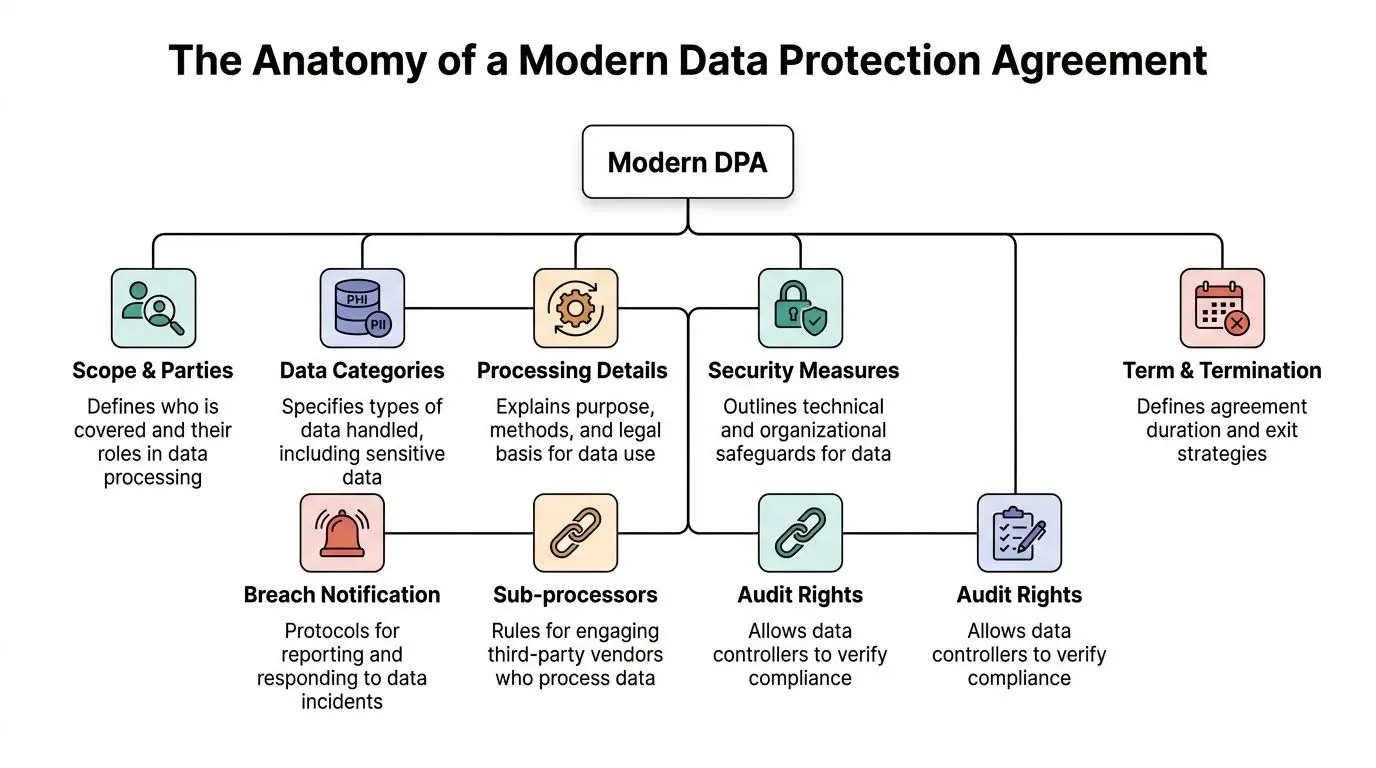
Scope and parties
Start with the basics. Who is the controller. Who is the processor. Which services are covered. Which entities in the group are bound.
This sounds trivial, but many disputes start here. Teams sign a DPA for one product module while personal data moves through adjacent services, support systems, or managed environments that are not clearly named.
For engineering, this means maintaining a current map of:
- customer-facing services
- admin tools
- support and ticketing systems
- observability and logging platforms
- batch jobs and export pipelines
- third party APIs called by the main service
If the DPA covers “the service” but your platform sends user content to a separate enrichment or AI workflow, you need to know whether that path is in scope.
Processing details and data categories
A serious DPA describes the nature, purpose, duration, and categories of processing. It also identifies the categories of data subjects.
Teams then discover whether they understand their own product. “Customer data” is not enough. A practical specification distinguishes account data, support messages, payment metadata, usage telemetry, user-generated files, authentication artefacts, and any special handling needs.
Architecturally, this becomes:
- field-level data classification
- service boundaries based on data sensitivity
- environment segregation
- retention rules by data type
- rules for logs, analytics, and exports
A useful question for every integration is this: can the vendor perform the service with less data than we currently send? Data minimisation is not just a legal principle. It is a way to shrink blast radius.
Security measures and TOMs
This clause deserves technical scrutiny. Under GDPR Article 32, DPAs must require specific Technical and Organisational Measures, and Piwik Pro’s guidance on DPA elements points to benchmarks such as AES-256 encryption at rest, TLS 1.3 in transit, and verification through annual SOC 2 Type II audits.
The legal wording is usually broad. The engineering response must not be.
A usable TOMs annex should align to concrete controls such as:
- Encryption standards: what protects databases, object storage, backups, queues, and search indexes
- Access control: role-based access, least privilege, break-glass procedures, privileged session logging
- Environment separation: development, staging, and production isolation
- Secrets handling: vault-based storage, rotation policies, restricted operator access
- Monitoring: alerting on suspicious access, exfiltration patterns, or privilege changes
- Recovery capabilities: tested backups and restore procedures
- Change management: approvals, deployment controls, and evidence
“Industry standard security” is one of the least useful phrases in a DPA. Ask what standards, where applied, and how verified.
Here is the practical mapping.
| DPA Clause | Legal Purpose | Practical Engineering Task |
|---|---|---|
| Scope & Parties | Define who is bound and for which services | Maintain a service inventory and vendor register |
| Processing Details | Limit purpose and authorised use | Document data flows and enforce purpose boundaries in code and policy |
| Data Categories | Identify what personal data is involved | Classify fields, stores, logs, and exports by sensitivity |
| Security Measures | Require appropriate safeguards | Implement encryption, access control, monitoring, backup, and audit evidence |
| Breach Notification | Ensure timely incident communication | Build incident runbooks, contact paths, and evidence collection workflows |
| Subprocessors | Control onward sharing | Maintain subprocessor inventory, review changes, and flow down requirements |
| Audit Rights | Allow verification of compliance | Prepare audit artefacts, logs, certifications, and control narratives |
| International Transfers | Govern cross-border movement | Map transfer paths and align transfer mechanism documentation |
| Termination & Deletion | End processing cleanly | Build deletion, return, sanitisation, and verification workflows |
A broader privacy architecture also has to fit these commitments. A useful reference point is this article on data protection and privacy, especially if you are aligning contract language with system design.
Breach notification
Most vendor templates promise notification “without undue delay” or “promptly.” Those phrases need operational meaning.
For a CTO, breach notification clauses should connect to:
- incident severity criteria
- internal decision trees for escalation
- log retention sufficient for investigation
- contact routes that work outside business hours
- forensic data preservation
- obligations around updates as facts change
A DPA cannot compensate for weak detection. If the processor cannot tell whether an incident affected your tenant, the notification clause may be legally present and functionally useless.
Subprocessors
Most software vendors are processors who rely on other processors. Cloud providers, support tools, analytics products, email delivery services, identity services, and AI model providers all sit in this chain.
Subprocessor clauses should answer:
- does the controller get prior notice
- can the controller object
- are equivalent obligations flowed down
- does the processor stay responsible for the subprocessor’s conduct
For engineering teams, this creates a supply chain discipline. You need an inventory of external dependencies, and you need someone responsible for reviewing changes before they alter your risk profile.
This is one place where AI integrations complicate matters. A single prompt request can involve a model API, a safety service, logging, and storage layers controlled by different vendors.
Audit rights and evidence
Many vendors resist broad on-site audits, and in many cases that is reasonable. A customer does not need unrestricted access to a provider’s platform to assess basic compliance.
What matters is whether the DPA gives the controller a realistic way to verify claims. That usually means some combination of:
- security reports and certifications
- penetration test summaries
- policy documents
- TOMs annexes
- incident process descriptions
- answers to due diligence questionnaires
If your controls are real, you should be able to produce evidence without improvisation.
International transfers and SCCs
If personal data moves across borders, the DPA needs to reflect the transfer mechanism. For many teams this becomes relevant when an EU-based customer uses a US-based service or an AI provider with global infrastructure.
Do not treat transfer language as a boilerplate appendix. It has architectural consequences because it forces you to answer where data is stored, where support access occurs, and where subprocessors operate.
Retention, deletion, and termination
Termination clauses expose whether a platform can stop processing cleanly.
Strong deletion language should be matched by a system design that covers:
- primary databases
- object storage
- search indexes
- event streams
- replicas
- backup strategy
- support tools
- derived datasets such as embeddings or caches
If the product can “delete” a customer while leaving identifiable data in logs, vector stores, or failed-job payloads, your DPA promise is incomplete.
Liability and realism
Liability language is where commercial and legal negotiation meets technical risk. This is not only about who pays after a failure. It also shapes which controls each party takes seriously.
An extremely low liability cap paired with broad data rights and weak security language is usually a bad trade for the controller. A processor also needs protection against unlimited exposure for events outside its defined scope. Good agreements match responsibility to control.
DPA Responsibilities for Software Buyers and Sellers
A DPA looks different depending on which side of the table you sit on. Buyers want evidence and control. Sellers want repeatable terms they can operate. Both sides fail when they promise things the system cannot support.
If you are buying software as a controller
A primary question is not “does the vendor have a DPA.” The question is whether the DPA and the product behaviour match.
Ask for specifics on:
- Purpose limitation: Can the vendor use your data only to deliver the service, or are there broader internal uses?
- AI restrictions: If the service includes AI, is your data excluded from model training and evaluation beyond service delivery?
- Subprocessor visibility: Do you get notice before meaningful changes?
- Deletion and return: Can the vendor prove what happens when your contract ends?
- Incident handling: Who tells whom, through which route, and with what level of detail?
- Auditability: Can the vendor provide credible evidence without weeks of negotiation?
For buyer-side governance, one operational owner should coordinate legal, security, and platform review. Split ownership causes the classic problem where legal signs language that engineering cannot honour, or engineering approves architecture that legal has not constrained.
Controllers should review the DPA with the same care they review the vendor’s API limits, uptime terms, and pricing model. All four affect product risk.
A buyer checklist that surfaces real issues
A short checklist catches more problems than a long generic questionnaire.
- Check data paths first: Ask the vendor to describe what enters, where it is stored, and who can access it.
- Inspect defaults: Retention, logging, support access, and optional analytics often create risk through default settings.
- Test deletion claims: If a customer requests erasure, can the vendor support it across raw and derived data?
- Review operational contacts: Incident and privacy contacts should be current and reachable.
- Read the attachments: Subprocessor lists and security annexes often matter more than the main DPA body.
This is also where the role of the privacy owner matters. If your organisation is formalising that function, this explanation of a data protection manager is a useful operational reference.
If you are selling software as a processor
Vendors lose trust when they treat every DPA request as a one-off legal exception. Buyers expect a ready position.
A mature processor usually has:
- a standard DPA
- a maintained subprocessor list
- a security annex tied to real controls
- a deletion and retention policy that engineering can execute
- a rights fulfilment workflow for customer requests
- a clear position on international transfers
- an escalation path for unusual customer requirements
Processors also need systems that can help controllers satisfy rights requests. Dastra’s guide to essential DPA points notes that processors should enable DSR automation with response SLAs under 48 hours, and that this can reduce manual overhead for access or deletion handling by up to 85%.
That is not a legal efficiency gain. It changes product requirements. If customers will ask for access, deletion, or export, your platform should expose those operations through admin tooling, APIs, or clearly documented support workflows.
A practical example is a multi-tenant SaaS platform with ticket history, uploaded files, and AI-generated summaries. If a customer asks for deletion, support staff should not be opening consoles and guessing which tables to purge. The service needs a controlled deletion job, audit logging, and a way to confirm completion.
A short explainer on the topic can help non-legal stakeholders align on the basics before negotiation:
Where buyers and sellers usually misalign
The most common mismatch is between contractual ambition and operational maturity.
Buyers ask for unlimited rights without considering proportionality. Sellers offer sweeping commitments without checking whether their stack, support model, or vendor chain can support them.
The better approach is narrower and more precise. If you need prior notice of subprocessor changes, define it. If deletion excludes immutable backups until the next rotation cycle, say so clearly. If tenant-specific audit evidence can be provided through reports rather than physical inspections, structure it that way.
Negotiating a DPA and Handling Standard Clauses
A DPA negotiation usually becomes real the first time legal asks a simple question and engineering cannot answer it with confidence: where does this data go after it leaves our app? That gap is where standard clauses become operational risk.
Vendor templates are rarely fixed. The headline commitments often look acceptable, but significant exposure sits in definitions, annexes, and exceptions. For a CTO, the job is not to argue abstract privacy principles. It is to stop contract language from promising controls the system does not have, or accepting data uses the architecture cannot constrain.
Terms worth challenging
Start with the clauses that change how the service can be built, supported, and audited.
- Vague security language: If the DPA says the vendor will apply “appropriate measures” and stops there, ask for a security annex or a referenced control set. You need enough detail to assess whether their controls match the sensitivity of the data and your own customer commitments.
- Unilateral changes: Terms that let a vendor change subprocessors or privacy conditions at its own discretion create downstream risk. Notice periods, objection rights, and a defined process matter more than broad assurances.
- Broad service improvement rights: This is a common fault line in AI and analytics products. “Improving the service” can cover model training, human review, feature testing, or internal benchmarking unless the clause is narrowed.
- Weak deletion wording: “May delete” or “delete in accordance with internal policy” leaves too much room for drift. The agreement should say what is deleted, what is returned, what remains in backups, and on what schedule.
- Low liability caps for high-risk processing: If the service handles regulated data, production logs, customer communications, or model prompts, a low general cap may not reflect the full exposure.
- Undefined assistance obligations: Support for access requests, incident investigations, regulator enquiries, and transfer assessments should be described in a way the operations team can execute.
These are contract points, but they also map directly to engineering work. If a seller agrees to customer deletion within a fixed period, they may need job orchestration, backup handling rules, and evidence that the deletion completed. If a buyer asks for notice before subprocessor changes, procurement needs a current inventory and engineering needs to know which services touch personal data.
SCCs are only one layer
For international transfers, Standard Contractual Clauses often appear to solve the problem by default. They do not solve anything on their own if nobody can explain the transfer path.
The practical review starts with system facts:
- which legal entity exports the data
- which entity receives it
- where hosting, support, and monitoring teams operate
- whether remote administrative access creates a cross-border transfer
- what technical safeguards apply before, during, and after transfer. Architecture either strengthens the legal position or weakens it in this context. A clean regional design, limited support access, field-level encryption, and tokenisation give legal something concrete to defend. A stack with shared logs, global admin access, and unclear vendor dependencies makes every transfer clause harder to stand behind.
Bring architecture into the negotiation
The strongest DPA reviews I have seen happen when legal, security, and engineering work from the same data-flow map. That changes the discussion from generic redlines to specific implementation choices.
A CTO should be ready to answer questions like these:
- what categories of personal data leave the core product
- whether identifiers can be minimised before transfer
- where logs, traces, and backups are stored
- which subprocessors process live customer content versus metadata
- what can be deleted immediately and what follows a scheduled retention cycle
- what evidence the team can produce after an incident, deletion request, or vendor audit
Retention terms deserve special attention because they often look precise on paper and remain messy in production. If policy says data is deleted after contract termination, the system needs matching rules for databases, object storage, backups, caches, search indexes, and derived artifacts. This guide to setting data retention policies that match system behavior is a useful reference when tightening those clauses.
A good negotiation position is operational clarity. Vendors can resist preference-based edits. It is much harder to dismiss a clause change tied to a specific processor, a specific data flow, and a specific failure mode in the system.
Special Considerations for AI Systems and Modern Architectures
A team signs a DPA for a new AI feature, then discovers the feature sends customer text to an LLM, stores embeddings in a separate vector database, logs prompts for debugging, and calls external tools during retrieval. The legal document looked standard. The system is not.
AI systems put pressure on every clause that assumes a simple processor relationship and a short, traceable data path. Personal data can be copied into prompts, transformed into embeddings, enriched with metadata, routed through safety filters, and resurfaced in outputs long after the original record changed or should have been deleted.

LLM providers change the usual vendor review
The first question is operational. What exactly leaves your boundary when the application calls the model provider?
For many teams, the answer is broader than expected. A prompt may include raw user input, account context, system instructions, retrieved knowledge base text, prior conversation state, and internal identifiers added by middleware. If the provider retains any of that for training, abuse review, or service improvement, the DPA has to match that reality.
Review these points before approving an integration:
- whether prompts and outputs are retained, and for how long
- whether retained content is used for training or model improvement
- whether safety, abuse, or moderation systems inspect the payload
- whether human reviewers or support personnel can access request data
- whether request caching creates another copy outside the primary processing path
Those answers drive architecture, not just procurement language. If terms are too broad, reduce what you send. Strip identifiers before prompt assembly, isolate high-risk fields, keep sensitive workflows on infrastructure you control, or split tasks so the external model sees only the minimum context required.
Embeddings and vector databases create deletion complexity
Derived data still creates obligations. That point becomes concrete in retrieval systems.
An embedding may not be readable by a person, but it can remain linked to a user record, a document chunk, or a tenant knowledge base. The same applies to chunk metadata, ranking caches, retrieval logs, and generated summaries built from the original content. If the DPA promises deletion or erasure support, the engineering question is whether the pipeline can remove those downstream artifacts with enough precision to honor the promise.
Check the full chain:
- source files used to generate embeddings
- chunked text stored for retrieval
- vectors in the index
- metadata that ties vectors to users, tenants, or documents
- caches that keep recent retrieval results
- outputs or summaries persisted elsewhere in the application
Weak deletion design becomes evident quickly in this area. Deleting the source object is easy. Deleting the source object, its vectors, its cache entries, and any stored outputs that reproduced the content is harder. If the system cannot do that reliably, the DPA should not imply that it can.
Agent workflows increase the subprocessor chain
Agentic systems turn one request into a sequence of processor relationships. A user asks one question. The system may call an LLM, a search service, a ticketing platform, a CRM, and a document repository in the same workflow.
That has two consequences. The first is contractual. Your approved subprocessor list may be incomplete the moment a new tool is enabled. The second is architectural. Tool access control becomes part of privacy compliance because each tool call is a transfer decision.
Useful controls include:
- explicit allow-lists for tools an agent may call
- per-tool rules for what fields may be sent
- policy checks before external requests are executed
- tenant-scoped logs of tool calls and returned data
- human approval for actions that touch regulated or high-risk data
- hard disablement for tools that lack approved terms
In practice, I advise CTOs to treat agent tools as outbound integrations with autonomy attached. That means they need stricter review, not lighter review.
Governance has to cover transformations, not just storage
AI programs often grow faster than the operating model around them. Product teams ship useful features first. Legal, privacy, and platform teams catch up once customers ask harder questions about training, retention, auditability, and deletion.
A DPA will not fix weak AI governance, but it is a good forcing function. It should state whether customer data can be used for training, whether new subprocessors require notice or approval, whether certain workflows need human review, and whether deletion obligations apply to derived data as well as source records.
For modern architectures, I would add one more test. Can the team explain the full lifecycle of a data element after it enters an AI workflow, including each transformation, each external call, each stored derivative, and each deletion path? If that answer is vague, the contract is ahead of the system.
In AI systems, the DPA should describe not only where data goes, but how it is transformed, copied, and retired across the full pipeline.
Conclusion Your DPA as an Architectural Blueprint
The best way to treat a data protection agreement is not as a document that legal files after signature. Treat it as a blueprint for how your systems, vendors, and teams are allowed to handle personal data.
That shift changes the quality of both your contracts and your architecture.
A weak DPA usually signals one of two problems. Either the vendor cannot explain how its service works at the level required for trust, or your own team has not mapped the data path through the product. Both are fixable, but neither is solved by faster paperwork.
For software buyers, the core discipline is due diligence that reaches the system level. Read the DPA, but also ask where data is stored, how subprocessors are managed, whether rights requests can be fulfilled, and how deletion works across raw and derived data.
For software sellers, the job is operational honesty. Publish terms that match reality. Keep a current subprocessor list. Build deletion, export, audit evidence, and incident response workflows that support what your contract promises.
A final practical checklist
For controllers buying software
- Map the integration: Know exactly what personal data enters the vendor system.
- Confirm permitted use: Ensure service delivery is the limit unless broader use is explicitly acceptable.
- Check the subprocessor chain: Review who else may receive the data.
- Verify deletion mechanics: Ask how the vendor handles logs, backups, and derived data.
- Test incident readiness: Confirm how breach notice and follow-up support will work.
- Review transfer terms: Make sure cross-border processing has the right contractual support.
For processors selling software
- Keep a standard DPA ready: Avoid ad hoc drafting for routine deals.
- Tie contract language to real controls: Security annexes should reflect actual implementation.
- Support rights fulfilment: Make access, deletion, and export operational, not manual improvisation.
- Maintain evidence: Be ready to provide certifications, policies, and control summaries.
- Manage subprocessors actively: Notice, approval paths, and flow-down obligations should be current.
- Design for exit: Contract termination should trigger a clear return or deletion path.
A sound DPA does not slow delivery. It prevents the kind of hidden design debt that turns a simple integration into a customer incident, an enterprise deal blocker, or a compliance failure.
If you are building a SaaS platform, integrating AI, or reviewing vendor risk in a live product environment, Devisia can help you translate privacy obligations into practical architecture, delivery decisions, and maintainable controls.